




Valutazione RAG con l'uso di Ragas
*Questo post è stato scritto da Christy Bergman, Shahul Es e Jithin James.
Il recupero è una componente cruciale dei sistemi di IA generativa e le sue sfide sono particolarmente evidenti nella Retrieval Augmented Generation (RAG). La Retrieval Augmented Generation migliora i chatbot alimentati dall'IA generando risposte basate su dati estesi su cui sono stati addestrati modelli linguistici di grandi dimensioni (LLM). Nonostante la sofisticazione dei sistemi RAG, l'accuratezza del reperimento rimane un ostacolo significativo, come evidenziato dai bassi punteggi ottenuti da benchmark come WikiEval. Per superare queste sfide, è essenziale stabilire un quadro di valutazione completo e impegnarsi in una sperimentazione approfondita per mettere a punto i parametri delle RAG e ottenere prestazioni ottimali.
**Tuttavia, prima di poter sperimentare le RAG, è necessario un modo per valutare quali esperimenti hanno dato i risultati migliori!
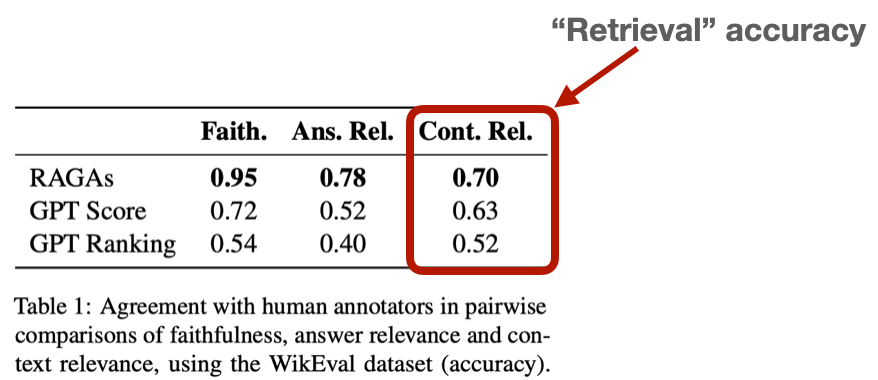
Fonte immagine: https://arxiv.org/abs/2309.15217
Che cos'è il Ragas?
Ragas è un framework di valutazione specializzato progettato per valutare le prestazioni dei sistemi Retrieval Augmented Generation (RAG). Fornisce un approccio strutturato per valutare l'efficacia delle implementazioni RAG sfruttando come giudici i Large Language Models (LLM) avanzati. Ragas si concentra sull'automazione del processo di valutazione, offrendo soluzioni scalabili ed economiche per valutare le risposte generate dall'intelligenza artificiale. Il framework mira a risolvere i pregiudizi e a offrire punteggi continui e spiegabili per le risposte in linguaggio naturale. Ragas semplifica la valutazione di sistemi RAG complessi, fornendo metriche intuitive e snellendo il processo di valutazione della qualità del reperimento.
Importanza della valutazione dei sistemi RAG
Valutare efficacemente i sistemi RAG è fondamentale per perfezionare le risposte dell'IA. Un solido quadro di valutazione garantisce che gli esperimenti producano risultati affidabili e che l'IA fornisca risposte accurate e contestualmente appropriate. L'automazione del processo di valutazione può snellire e accelerare questo compito, rendendolo più economico e scalabile.
Sfruttare i LLM come giudici
L'uso di modelli linguistici di grandi dimensioni (LLM), come il GPT-4, per la [valutazione] (https://arxiv.org/pdf/2306.05685) si è diffuso grazie alla loro capacità di valutare vari aspetti della qualità del reperimento, tra cui la rilevanza e la precisione. Sebbene possa sembrare insolito che un LLM ne valuti un altro, la ricerca indica che GPT-4 si allinea con le valutazioni umane per circa l'80% del tempo, il che corrisponde al "limite bayesiano "** dell'accordo umano. Questo metodo automatizza il processo di valutazione, offrendo scalabilità e riducendo i costi rispetto all'etichettatura umana manuale.
Approcci alla valutazione basata su LLM
Esistono due approcci principali all'uso dei LLM come giudici per la valutazione RAG:
MT-Bench utilizza un LLM per giudicare solo le coppie domanda-risposta verificate come verità di base umana. Gli esseri umani esaminano inizialmente le domande e le risposte per assicurarsi che le domande siano sufficientemente complesse per effettuare test degni di nota, prima che l'LLM utilizzi le 80 coppie Q-A per valutare diversi decodificatori (componenti generativi dell'intelligenza artificiale). Carta, codice, classifica.
Ragas è costruito sull'idea che i LLM possano valutare efficacemente i risultati del linguaggio naturale formando paradigmi che superano i pregiudizi dell'uso diretto dei LLM come giudici e fornendo punteggi continui che sono spiegabili e intuitivi da capire). Paper, Code, Docs.
Il resto di questo blog presenterà Ragas, che enfatizza l'automazione e la scalabilità delle valutazioni RAG.
Dati di valutazione necessari per Ragas
Secondo la documentazione di Ragas, la valutazione della pipeline RAG necessita di quattro dati chiave.
Domanda: La domanda posta.
Contesti: I pezzi di testo dei dati che meglio corrispondono al significato della domanda.
Risposta: Risposta generata dal chatbot RAG alla domanda.
Risposta vera: Risposta attesa alla domanda.
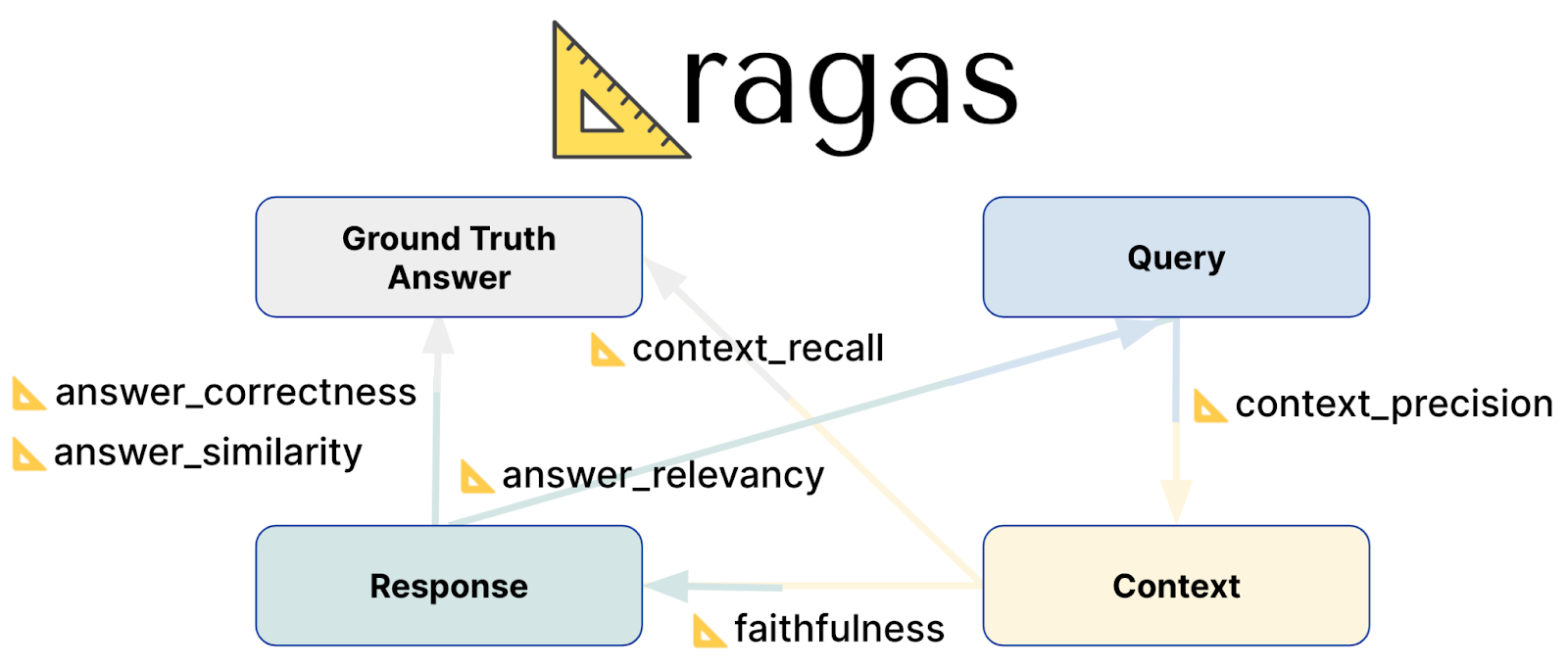 Metriche di valutazione delle razze
Metriche di valutazione delle razze
Metriche chiave di valutazione
Le spiegazioni di ciascuna metrica di valutazione, comprese le formule sottostanti, sono riportate nella documentazione. Ad esempio, fedeltà. Ragas fornisce una serie di punteggi di valutazione per misurare l'efficacia dei sistemi RAG:
Fedeltà: Questo punteggio valuta l'accuratezza con cui la risposta generata riflette le informazioni nel contesto fornito. Misura l'accuratezza fattuale della risposta, assicurando che sia in linea con il contesto da cui è stata ricavata. I punteggi vanno da 0 a 1, con valori più alti che indicano maggiore accuratezza e coerenza.
Rilevanza delle risposte: La metrica della pertinenza della risposta valuta la rispondenza della risposta generata alla richiesta. Si concentra sulla completezza e sulla pertinenza della risposta, penalizzando le risposte incomplete o ridondanti. Il punteggio di pertinenza deriva dalla domanda, dal contesto e dalla risposta, con punteggi più alti che riflettono un migliore allineamento con il prompt.
Ricordo del contesto: Il richiamo del contesto misura l'efficacia della corrispondenza tra il contesto recuperato e la risposta vera e propria. Calcola la percentuale di pezzi rilevanti recuperati con successo rispetto a quanto ci si aspettava. I punteggi vanno da 0 a 1, con valori più alti che indicano che è stata recuperata una porzione maggiore di contesto pertinente.
Precisione del contesto: Questa metrica valuta se gli elementi di contesto più rilevanti sono classificati più in alto rispetto a quelli meno rilevanti. Controlla se tutti i pezzi di contesto pertinenti appaiono in cima all'elenco. La precisione del contesto è determinata utilizzando la domanda, la verità di base e i contesti, con punteggi più alti che indicano una migliore classificazione delle informazioni pertinenti.
Rilevanza del contesto: Questo punteggio di pertinenza del contesto valuta la pertinenza del contesto recuperato rispetto alla domanda. Misura il grado di corrispondenza del contesto con l'intento della query. La metrica va da 0 a 1, con valori più alti che indicano che il contesto è più pertinente alla domanda.
- Ricordo dell'entità del contesto: Questa metrica calcola la capacità del contesto recuperato di catturare le entità menzionate nella verità di base. Misura la proporzione di entità trovate sia nel contesto che nella verità di base rispetto al numero totale di entità nella verità di base. Punteggi più alti indicano una migliore cattura di entità importanti nel contesto.
I dettagli sul calcolo di queste metriche sono disponibili nel loro [paper] (https://arxiv.org/abs/2309.15217).
Esempio di codice di valutazione RAG
Questo codice di valutazione presuppone che abbiate già una demo RAG. Per la mia demo, ho creato un chatbot RAG utilizzando Milvus Technical documentation e il database vettoriale Milvus per il reperimento. Il codice completo della mia demo RAG notebook e Eval notebook sono su GitHub.
Utilizzando la demo RAG, ho posto delle domande, ho ottenuto i contesti RAG da Milvus e ho generato risposte bot da un LLM (si vedano le ultime due colonne qui sotto). Inoltre, fornisco le risposte di "verità di base" alle stesse domande (colonna "contesti" in basso).
È necessario installare OpenAI, il dataset (HuggingFace), ragas, langchain e pandas.
# ! pip install openai dataset ragas langchain pandas
importare pandas come pd
eval_df = pd.read_csv("data/milvus_ground_truth.csv")
display(eval_df.head())

Converte il dataframe pandas in un dataset HuggingFace.
da dataset import Dataset
def assemble_ragas_dataset(input_df):
lista_domande, lista_verità, lista_contesto = [], [], []
lista_domande = input_df.Question.to_list()
lista_verità = eval_df.ground_truth_answer.to_list()
context_list = input_df.Custom_RAG_context.to_list()
context_list = [[context] for context in context_list]
rag_answer_list = input_df.Custom_RAG_answer.to_list()
# Creare un Dataset HuggingFace dalle liste di verità a terra.
ragas_ds = Dataset.from_dict({"question": question_list,
"contesti": elenco_contesti,
"risposta": rag_answer_list,
"verità di fondo": elenco_verità
})
restituire ragas_ds
# Creare un dataset Ragas HuggingFace dal df di pandas.
ragas_input_ds = assemble_ragas_dataset(eval_df)
display(ragas_input_ds)

Il modello LLM predefinito utilizzato da Ragas è gpt-3.5-turbo-16k di OpenAI e il modello di incorporamento è text-embedding-ada-002. È possibile cambiare entrambi i modelli con quello che si desidera.
Cambierò il modello LLM-as-judge con il modello gpt-3.5-turbo, dato che l'ultimo blog di OpenAI ha annunciato che questo è il più economico. Ho anche cambiato il modello di embedding in text-embedding-3-small poiché il blog ha notato che questi nuovi embedding supportano la modalità di compressione.
Nel codice che segue, utilizzo solo la metrica di valutazione RAG context per concentrarmi sulla misurazione della qualità di recupero dei documenti rilevanti.
importare os, openai, pprint
da openai importare OpenAI
# Salva la chiave api in una variabile env.
openai_api_key=os.environ['OPENAI_API_KEY']
# Scegliere le metriche che si vogliono vedere.
da ragas.metrics import ( context_recall, context_precision, faithfulness, )
metrics = ['context_recall', 'context_precision', 'faithfulness']
# Cambia l'llm-as-critic.
da ragas.llms import llm_factory
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = llm_factory(model=LLM_NAME)
# Cambiare anche gli embeddings.
da langchain_openai.embeddings import OpenAIEmbeddings
da ragas.embeddings importare LangchainEmbeddingsWrapper
lc_embeddings = OpenAIEmbeddings( model="text-embedding-3-small", dimensions=512 )
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# Cambiare i modelli predefiniti usati per ogni metrica.
per metrica in metrics:
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# Valutare il dataset.
da ragas importiamo evaluate
ragas_result = evaluate( ragas_input_ds,
metriche=[ context_precision, context_recall, faithfulness, ],
llm=ragas_llm,
)
# Visualizzare le valutazioni.
ragas_output_df = ragas_result.to_pandas()
ragas_output_df.head()

È possibile vedere il codice completo della mia demo RAG notebook e Eval notebook su GitHub.
Conclusione
Questo blog ha esplorato le sfide attuali del reperimento nell'IA generativa, con un'enfasi particolare sulle tecniche di Retrieval Augmented Generation (RAG per far progredire i sistemi di IA in linguaggio naturale. Una sperimentazione efficace è essenziale per ottimizzare i parametri RAG in base a dati e casi d'uso specifici, garantendo le migliori prestazioni. La valutazione dei sistemi RAG può ora essere notevolmente migliorata grazie all'automazione dei LLM come valutatori. Abbiamo trattato le principali metriche di valutazione delle RAG e i loro metodi di calcolo, offrendo approfondimenti sulle loro applicazioni pratiche. Inoltre, è stato evidenziato un esempio di implementazione che utilizza il database vettoriale Milvus insieme al pacchetto Ragas, dimostrando come questi strumenti possano essere efficacemente utilizzati per migliorare e scalare i vostri framework di valutazione RAG. Questo approccio non solo semplifica il processo di valutazione, ma aumenta anche l'efficacia complessiva del recupero del contesto nelle soluzioni guidate dall'intelligenza artificiale. Per ulteriori approfondimenti, si consiglia di studiare applicazioni reali, affrontare le sfide, esplorare le direzioni future, aderire alle best practice e accedere a risorse aggiuntive per approfondire la comprensione della valutazione dei sistemi RAG e perfezionare la propria pipeline RAG.

Continua a leggere

From Vector Database to Vector Lakebase
Zilliz offers a fully managed Vector Lakebase powered by Milvus, unifying real-time vector search, lake-scale discovery, and Al data operations.

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Why Context Engineering Is Becoming the Full Stack of AI Agents
Discover how context engineering unifies prompts, RAG, and tools to build smarter, production-ready AI agents powered by Milvus.