




Come scegliere la giusta modalità di distribuzione di Milvus per le vostre applicazioni AI
Milvus è un database vettoriale open-source che memorizza, indicizza e recupera embeddings vettoriali su scala miliardaria. È anche un componente indispensabile della retrieval augmented generation (RAG), una tecnica popolare ed efficace per attenuare i problemi di allucinazione nei modelli linguistici di grandi dimensioni (LLMs.
A differenza di altri progetti open-source di ricerca vettoriale come Qdrant, Weaviate e Chroma, Milvus offre agli sviluppatori tre principali opzioni di implementazione che si adattano a insiemi di dati di diverse dimensioni, casi d'uso e requisiti aziendali. Sebbene la possibilità di scegliere tra più opzioni sia un vantaggio, può anche essere un po' opprimente. Molti sviluppatori non sanno come selezionare la modalità di distribuzione migliore per le loro applicazioni AI specifiche. In questo blog post, forniremo una guida chiara e dettagliata per aiutarvi a scegliere la versione di Milvus più adatta ai vostri progetti.
Milvus Lite vs. Standalone vs. Distribuito
Milvus offre tre opzioni di distribuzione: Milvus Lite, Standalone e Distribuito**.
Milvus Lite
Milvus Lite è una libreria Python e una versione ultraleggera di Milvus. È perfetta per la prototipazione rapida in ambienti Python o notebook e per esperimenti locali su piccola scala. Si può installare direttamente attraverso il pacchetto pymilvus con una semplice riga di pip install pymilvus. Non è necessario eseguire un server separato e gestisce la persistenza dei dati utilizzando file locali, il che lo rende facile da configurare e utilizzare.
Milvus Standalone
Milvus Standalone è l'opzione di distribuzione a singolo nodo per Milvus, che utilizza un modello client-server. Si può pensare che sia l'equivalente di Milvus di MySQL, mentre Milvus Lite è come SQLite. Tutti i componenti di Milvus Standalone vengono forniti in un'immagine Docker, rendendo semplice la distribuzione del server. L'esecuzione di una singola istanza di Milvus Standalone su una macchina con memoria sufficiente funziona bene per la maggior parte dei progetti che non richiedono un'ampia scalabilità. Inoltre, Milvus Standalone offre un'elevata disponibilità con una modalità di backup primaria, che lo rende una scelta affidabile per gli ambienti di produzione.
Milvus distribuito
Milvus Distributed è la modalità distribuita di Milvus, ideale per gli utenti aziendali che costruiscono sistemi di database vettoriali su larga scala o piattaforme di dati vettoriali. Adotta un'architettura cloud-native con separazione lettura-scrittura per ottimizzare le prestazioni. I componenti chiave di Milvus Distributed sono dotati di backup integrati e di istanze aggiuntive, per cui se una parte si guasta, le altre possono subentrare senza problemi, assicurando che il sistema rimanga ininterrotto. Questo livello di ridondanza aumenta l'affidabilità e garantisce la [disponibilità continua] (https://zilliz.com/learn/ensuring-high-availability-of-vector-databases). Delle tre opzioni di implementazione, Milvus Distributed offre la massima scalabilità e disponibilità. Offre inoltre un'elasticità a livello di componenti, consentendo di scalare in modo indipendente Proxy, nodi di interrogazione e nodi indice in base ai requisiti di carico aziendali specifici.
La tabella seguente riassume e confronta le principali funzionalità di Milvus Lite, Milvus Standalone e Milvus Distributed.
| Capabilities | Milvus Lite | Milvus Standalone | Milvus Distributed | |
| SDK | Python | Python, Go, Java, Node.js, C#, RESTful | Python, Go, Java, Node.js, C#, RESTful | |
| Tipi di dati | Vettori densiVettori sparsiVettori binari Scalari booleani Scalari integrali Scalari fluttuanti Strings Arrays JSON | Vettori densi Vettori sparsi Vettori binari Scalari booleani Scalari integrali Scalari fluttuanti Strings Arrays JSON | Vettori densi Vettori sparsi Vettori binari Scalari booleani Scalari integrali Scalari fluttuanti Strings Arrays JSON | |
| Ricerca | Ricerca vettoriale (ANN search)Ricerca vettoriale filtrata Range searchHybrid search Scalar expression query Primary key query (get) | Ricerca vettoriale (ANN search)Ricerca vettoriale filtrata Range searchHybrid search Scalar expression query Primary key query (get) | Ricerca vettoriale (ANN search)Ricerca vettoriale filtrata Range searchHybrid search Scalar expression query Primary key query (get) | |
| Capacità CRUD di base | ✔️ | ✔️ | ✔️ | ✔️ |
| Capacità avanzate | - | RBAC (controllo dell'accesso basato sui ruoli) | RBAC (controllo dell'accesso basato sui ruoli) Sharding Partizione Chiave di partizione Raggruppamento fisico delle risorse | |
| Consistenza | Forte | Strong Bounded staleness Session Eventually | Strong Bounded staleness Session Eventually |
Tabella: Confronto tra Milvus Lite, Milvus Standalone e Milvus Distributed_
Come scegliere la giusta distribuzione di Milvus per ogni fase di sviluppo
La scelta dell'opzione di distribuzione Milvus appropriata dipende dalla fase di sviluppo dell'applicazione. Queste fasi comprendono Prototipazione rapida, Prima distribuzione di produzione e Distribuzione di produzione su larga scala. Analizziamo ogni fase in dettaglio.
Milvus Lite per la prototipazione rapida di applicazioni AI
Quando si sviluppano e prototipano applicazioni di IA come un assistente personale, un motore di ricerca semantica o un RAG end-to-end, la velocità e la flessibilità dell'applicazione sono di solito prioritarie rispetto alle prestazioni e alla stabilità. Pertanto, Milvus Lite è la scelta ideale in questa fase. Permette di costruire rapidamente funzionalità end-to-end in un ambiente notebook e di condurre esperimenti leggeri incentrati sulla verifica dell'efficacia.
Passaggio a Milvus Standalone per la validazione su grandi insiemi di dati
Milvus Standalone è il passo successivo se avete bisogno di convalidare i vostri risultati su un grande insieme di dati. Milvus Lite e Standalone sono stati progettati per lavorare insieme senza problemi, offrendo una facile transizione dalla prototipazione locale alla validazione basata su server. Poiché Milvus Lite, Standalone e Distributed condividono la stessa interfaccia client, è possibile riutilizzare la stessa logica aziendale per la validazione dei dati sia a livello locale che su larga scala. Inoltre, Milvus Standalone supporta più utenti, rendendo più facile per i team di sviluppo agile collaborare o condividere i dati utilizzando una singola istanza.
Milvus Standalone per la distribuzione in prima produzione
Nelle prime fasi della produzione di un'applicazione, quando il progetto è appena stato lanciato e sta ancora trovando il suo adattamento al mercato, le richieste aziendali e i volumi di dati sono relativamente bassi. L'attenzione dovrebbe essere rivolta all'efficacia e alla competitività del business piuttosto che all'infrastruttura. Milvus Standalone è adatto a questa fase. Per i servizi online, l'implementazione di Milvus in una modalità di backup primario ad alta disponibilità garantisce l'affidabilità. Per gli ambienti di test, di solito è sufficiente una distribuzione a singolo nodo.
**Nota: ** Milvus Standalone non offre l'isolamento fisico delle risorse tra le tabelle. Se avete due applicazioni critiche e sensibili alle prestazioni, è meglio isolare i loro dati usando istanze Milvus Standalone separate. Anche se questo potrebbe comportare una certa inefficienza delle risorse, rimane più conveniente rispetto alla gestione di una configurazione Milvus Distributed in questa fase.
È possibile continuare a usare Milvus Lite per compiti specifici di debug, ma evitare di farlo nell'ambiente di produzione in cui è distribuito Milvus Standalone, perché potrebbe introdurre rischi di prestazioni e stabilità.
Milvus Distributed per la produzione su larga scala
Quando i dati superano la capacità di un singolo server o sono in rapida espansione, è il momento di prepararsi alla scalabilità futura. In questa fase, Milvus Distributed diventa essenziale.
Questa best practice prevede l'esecuzione simultanea di entrambe le istanze di Milvus Standalone e Milvus Distributed all'inizio e lo spostamento graduale del traffico dati da Standalone a Distributed. Assicuratevi di monitorare il sistema per almeno un mese, finché Milvus Distributed non funziona in modo stabile.
Durante questa fase, dovrete anche migliorare la gestione delle operazioni. Milvus Distributed supporta nativamente Prometheus e offre strumenti di gestione come Attu. Sebbene Milvus fornisca un'ampia gamma di strumenti operativi dedicati e integrazioni dell'ecosistema, la gestione di un grande sistema distribuito può essere impegnativa. Vi invitiamo a unirvi alla comunità Milvus, aperta e attiva, per chiedere supporto, contribuire al codice, partecipare agli eventi e dare molti altri preziosi contributi.
Come scegliere la giusta distribuzione per i vostri insiemi di dati vettoriali
Milvus è stato progettato per scalare con il vostro progetto, offrendo diverse modalità di distribuzione per soddisfare le esigenze in evoluzione del vostro set di dati. Per chiarire le loro differenze, analizzeremo come Milvus Lite, Standalone e Distributed si confrontano tra loro e, soprattutto, con altri database vettoriali open-source presenti sul mercato, come Chroma, Weaviate e Qdrant.
Chroma ha guadagnato terreno tra gli sviluppatori a partire dall'anno scorso, in particolare per i progetti su piccola scala. Come Milvus Lite, Chroma è un database vettoriale leggero. È più adatto alle applicazioni che gestiscono meno di centinaia di migliaia di vettori. Chroma offre funzionalità di base come l'inserimento di dati vettoriali e la ricerca di somiglianze, che lo rendono un'opzione leggera per la prototipazione rapida. Tuttavia, le sue funzionalità limitate e la mancanza di disponibilità alla produzione fanno sì che anche Milvus Lite offra funzionalità più robuste.
Per le soluzioni pronte per la produzione, Milvus Standalone e Distributed, insieme a Weaviate e Qdrant, sono le scelte più valide. Weaviate è noto per la sua integrazione con le applicazioni di AI, fornendo un supporto nativo per diversi modelli upstream. Qdrant, invece, si concentra sulle funzionalità principali dei database vettoriali, ponendo l'accento sulle prestazioni della ricerca vettoriale. Tuttavia, secondo VectorDBBench, uno strumento di benchmarking open-source per database vettoriali, Milvus supera ancora Qdrant in prestazioni di ricerca, rendendolo uno dei principali contendenti in questo spazio.
Ecco una ripartizione delle scale di dati adatte per ciascun database vettoriale:
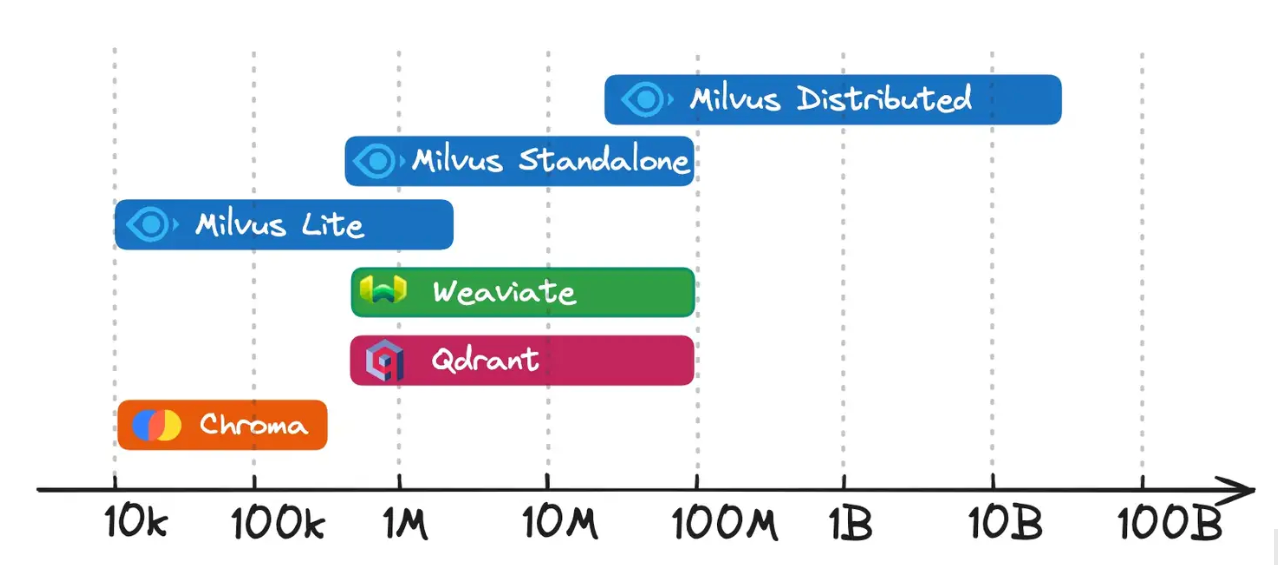 Figura 2- Milvus vs. Chroma vs. Qdrant vs. Weaviate per l'archiviazione e il recupero di vettori
Figura 2- Milvus vs. Chroma vs. Qdrant vs. Weaviate per l'archiviazione e il recupero di vettori
Milvus Lite e Chroma** sono ideali per la scalabilità dei dati fino a un milione di vettori. Sono progettati per la facilità d'uso, sacrificando alcune funzionalità del sistema per la semplicità.
Milvus Standalone, Weaviate e Qdrant: I migliori per le scale di dati che vanno da un milione a decine di milioni di vettori. Questi database raggiungono un equilibrio tra le potenti capacità del sistema e la facilità d'uso, rendendoli adatti alla produzione in fase iniziale.
Milvus Distributed: Progettato per gestire scale di dati di decine di milioni e oltre_. La comunità di Milvus ha convalidato il suo supporto per casi d'uso su scala miliardaria e ora è in fase di implementazione per situazioni che coinvolgono decine di miliardi di vettori.
Sebbene altri database vettoriali come Chroma, Weaviate e Qdrant abbiano i loro punti di forza, spesso non offrono lo stesso livello di flessibilità, scalabilità e supporto a lungo termine di Milvus. Con la crescita del progetto, cambiare database vettoriale può diventare costoso e complesso. Milvus, con le sue versatili opzioni di implementazione, supporta flussi di lavoro misti su varie scale di dati, assicurando che la soluzione di database non diventi obsoleta.
Componenti di base di Milvus Lite, Standalone e Distribuito
Milvus offre un'esperienza utente coerente e un'evoluzione uniforme in tutte e tre le sue modalità di distribuzione, grazie ai componenti sottostanti condivisi. Questo design garantisce che si possa beneficiare delle stesse funzionalità di base, sia che si utilizzi Milvus Lite per attività leggere o Milvus Distributed per operazioni su larga scala.
Il diagramma seguente illustra i componenti funzionali coperti da ciascuna delle modalità di distribuzione di Milvus:
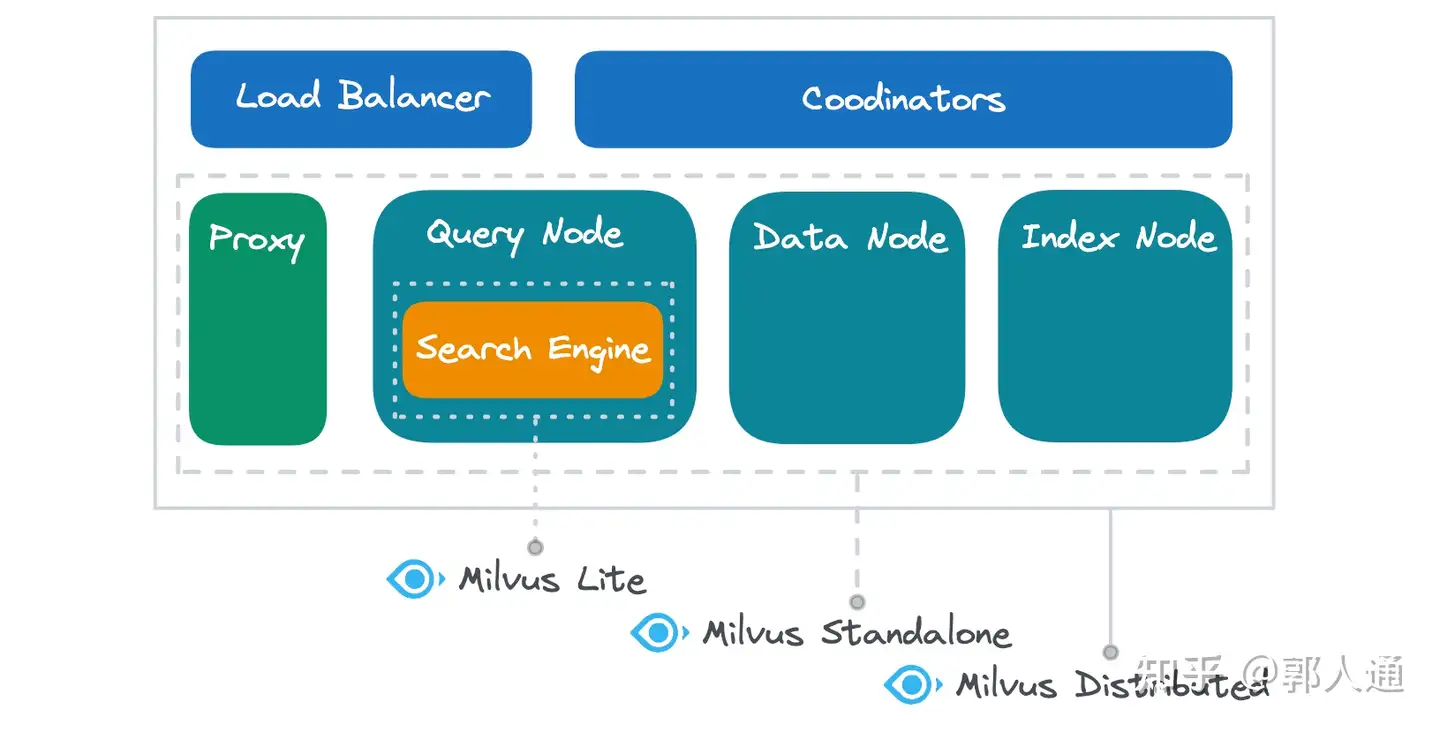 Figura 2- Milvus Lite vs. Standalone vs. Distribuito sui componenti sottostanti
Figura 2- Milvus Lite vs. Standalone vs. Distribuito sui componenti sottostanti
Milvus Lite incapsula principalmente il motore di ricerca e offre anche implementazioni locali per compiti essenziali come l'inserimento dei dati, la persistenza, la creazione di indici e la gestione dei metadati. Considerate Milvus Lite come una potente libreria piuttosto che come un semplice strumento. Rispetto a librerie più semplici come Chroma, il motore di ricerca di Milvus Lite offre prestazioni e capacità di interrogazione superiori, rendendolo ideale per le incorporazioni vettoriali. Se state cercando un'alternativa a FAISS o HNSWLib, Milvus Lite è un candidato forte, in quanto integra in modo nativo le principali librerie di algoritmi vector search ed è stato sottoposto a un'ampia ottimizzazione sia per le prestazioni che per la funzionalità.
Il Milvus Standalone include tutti i componenti funzionali del sistema Milvus, tranne il bilanciamento del carico e la gestione di più nodi (coordinatori). Questi componenti operano all'interno dello stesso ambiente Docker, facilitando una comunicazione locale efficiente e riducendo al minimo la latenza del server.
Milvus Distributed vanta una gamma completa di componenti funzionali. Mentre entrambe le modalità Standalone e Distributed contengono un Proxy, un Query Node, un Data Node e un Index Node con funzionalità identiche, Milvus Distributed offre una maggiore flessibilità di distribuzione. Ogni componente funzionale può essere distribuito più volte per gestire carichi più elevati e più componenti possono essere distribuiti sullo stesso nodo fisico per condividere le risorse o su nodi diversi per garantire l'isolamento delle risorse. Inoltre, la modalità distribuita permette di scalare in modo indipendente ciascun componente, consentendo di adattarsi alle diverse caratteristiche di carico e di migliorare efficacemente l'utilizzo delle risorse.
Riepilogo
In questo post abbiamo esplorato le tre opzioni di distribuzione offerte da Milvus: Milvus Lite, Standalone e Distributed. Ciascuna modalità di distribuzione è stata pensata per soddisfare le diverse fasi di sviluppo, le dimensioni dei dati e i casi d'uso, assicurando che Milvus possa scalare insieme al vostro progetto.
Milvus Lite** è ideale per la prototipazione rapida e gli esperimenti su piccola scala in ambienti Python. È facile da configurare e da usare, il che lo rende perfetto per gli sviluppatori che hanno bisogno di una soluzione leggera ma potente per i test e lo sviluppo.
Milvus Standalone è il passo successivo per chi è pronto a passare dalla prototipazione alla produzione. Questa opzione di distribuzione a singolo nodo fornisce tutti i componenti necessari per i primi ambienti di produzione, bilanciando prestazioni ed efficienza delle risorse. È adatta a progetti con dati di dimensioni moderate e richieste crescenti da parte degli utenti.
Milvus Distributed è progettato per implementazioni di produzione su larga scala che richiedono alta disponibilità, scalabilità e flessibilità. È la scelta ideale per le aziende e le applicazioni che gestiscono enormi quantità di dati, garantendo che il vostro database vettoriale possa crescere con le vostre esigenze aziendali.
Ulteriori risorse

Continua a leggere

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.