




Des mots aux vecteurs : Comprendre Word2Vec dans le traitement du langage naturel (NLP)
Des mots aux vecteurs : Comprendre Word2Vec dans le traitement du langage naturel (NLP)
Qu'est-ce que Word2Vec ?
Word2Vec est un modèle d'apprentissage automatique qui convertit les mots en [représentations vectorielles] numériques (https://zilliz.com/glossary/vector-embeddings) afin de saisir leur signification en fonction du contexte dans lequel ils apparaissent. Développé par Tomas Mikolov et son équipe chez Google, il utilise de grands ensembles de données textuelles pour comprendre les relations entre les mots et représenter les similitudes sémantiques et syntaxiques. Contrairement aux approches traditionnelles telles que l'encodage à une touche, Word2Vec crée des enchâssements denses et significatifs où les mots similaires sont positionnés plus près les uns des autres dans un espace vectoriel continu. Word2Vec est largement utilisé dans les applications de traitement du langage naturel telles que l'analyse des sentiments et les systèmes de recommandation.
Pourquoi avons-nous besoin de Word2Vec ?
Comprendre les relations et les significations des mots est un défi majeur dans le [Traitement du langage naturel (NLP)] (https://zilliz.com/ai-faq/what-is-natural-language-processing-nlp). Les méthodes traditionnelles, comme l'encodage à une touche, représentent les mots comme des vecteurs épars à haute dimension où chaque mot est indépendant des autres. Cette approche ne permet pas de saisir les relations sémantiques ou syntaxiques entre les mots. Par exemple, dans le cas d'un encodage à une dimension, les vecteurs pour "roi" et "reine" apparaîtraient complètement sans rapport, même si leurs significations sont étroitement liées.
En outre, ces représentations éparses sont inefficaces sur le plan informatique, en particulier pour les grands vocabulaires, et ne se généralisent pas bien à des mots ou des contextes non vus. Cette limitation a rendu difficile la compréhension réelle du langage par les machines, entravant les progrès dans des tâches telles que la traduction automatique, l'analyse des sentiments et le classement des recherches.
Word2Vec résout ces problèmes en créant des [word embeddings] (https://zilliz.com/ai-faq/what-is-word-embedding) compacts et denses qui représentent les relations entre les mots en fonction de la façon dont ils apparaissent dans le texte. En capturant à la fois le sens des mots et leur contexte, Word2Vec a transformé la façon dont les machines interprètent et traitent le langage humain, le rendant plus efficace et plus significatif.
Comment fonctionne Word2Vec ?
Au cœur de Word2Vec se trouvent les ancrages de mots, qui sont des [vecteurs denses] de faible dimension (https://zilliz.com/learn/dense-vector-in-ai-maximize-data-potential-in-machine-learning) qui capturent les propriétés sémantiques et syntaxiques des mots. Word2Vec fonctionne en analysant de grands volumes de texte pour apprendre les relations entre les mots. Il s'agit essentiellement d'un [réseau neuronal] peu profond (https://zilliz.com/learn/Neural-Networks-and-Embeddings-for-Language-Models) qui génère des représentations vectorielles pour les mots, capturant leurs significations sémantiques et syntaxiques. Le modèle identifie des modèles de cooccurrence des mots dans les phrases et utilise ces informations pour rapprocher les mots apparentés dans un espace vectoriel continu.
Le concept principal est que les vecteurs similaires représentent des mots ayant des significations ou des contextes d'utilisation similaires. Par exemple, les mots "roi" et "reine" auront des vecteurs étroitement liés, avec des différences qui encodent des distinctions sémantiques spécifiques, comme le genre.
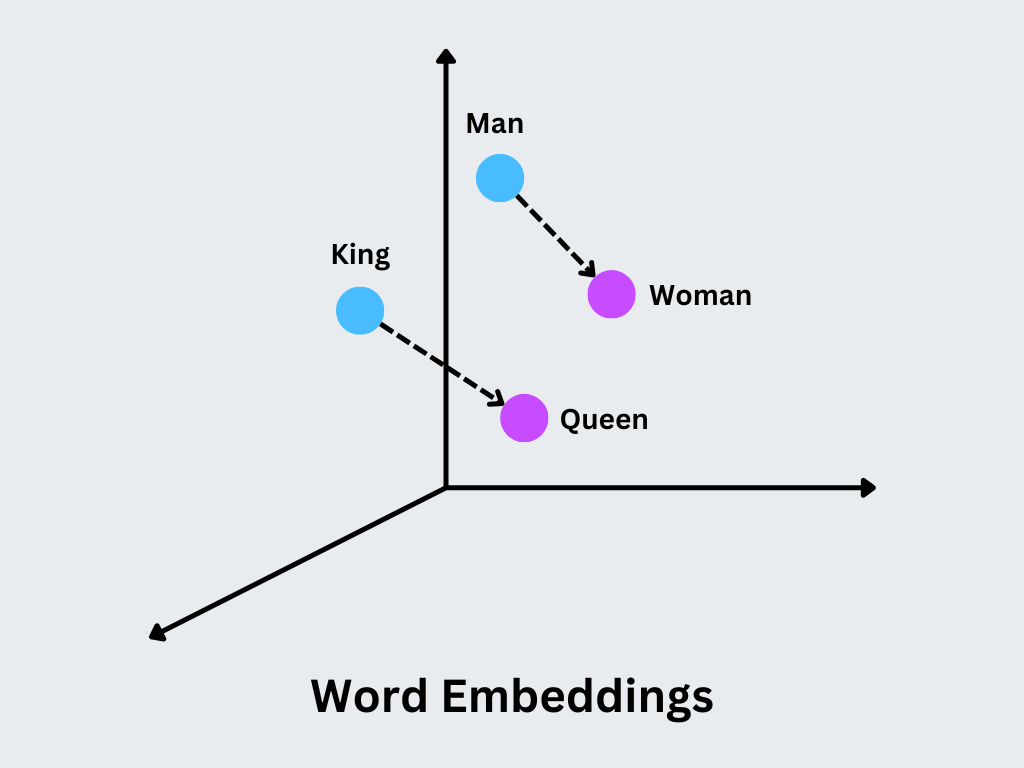 Figure- Word Embeddings.png
Figure- Word Embeddings.png
Figure: Word Embeddings
Word2Vec propose deux approches pour générer des embeddings, en fonction de la manière dont le contexte est traité :
Sac de mots continu (CBOW)
Le [sac de mots] continu (https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models#Bag-of-Words-Models) se concentre sur la prédiction d'un mot cible en fonction des mots qui l'entourent. Par exemple, dans la phrase "Les pommes sont douces et juteuses", CBOW utilise les mots du contexte ("Pommes", "sont", "et" et "juteuses") pour prédire le mot cible, tel que "douces".
CBOW est efficace d'un point de vue informatique car il fait la moyenne des mots du contexte pour prédire le mot cible. Cependant, elle est plus performante avec les mots fréquents et peut rencontrer des difficultés avec les termes rares.
**CBOW est couramment utilisé dans des applications telles que l'autocomplétion et la vérification orthographique, où il est nécessaire de prédire un mot manquant ou suivant.
Modèle Skip-Gram
Le modèle Skip-Gram inverse le processus de prédiction. Au lieu de prédire un mot cible à partir de son contexte, il prédit les mots du contexte sur la base d'un mot cible. Par exemple, si le mot cible est "sweet", Skip-Gram prédit les mots contextuels "Apples", "are", "and" et "juicy".
Skip-Gram gère mieux les mots rares et est particulièrement efficace pour capturer des relations plus nuancées lorsque l'on travaille avec de grands ensembles de données.
Use Case: Skip-Gram est précieux dans des tâches telles que la construction de systèmes de recommandation ou le regroupement de termes similaires dans des domaines spécialisés.
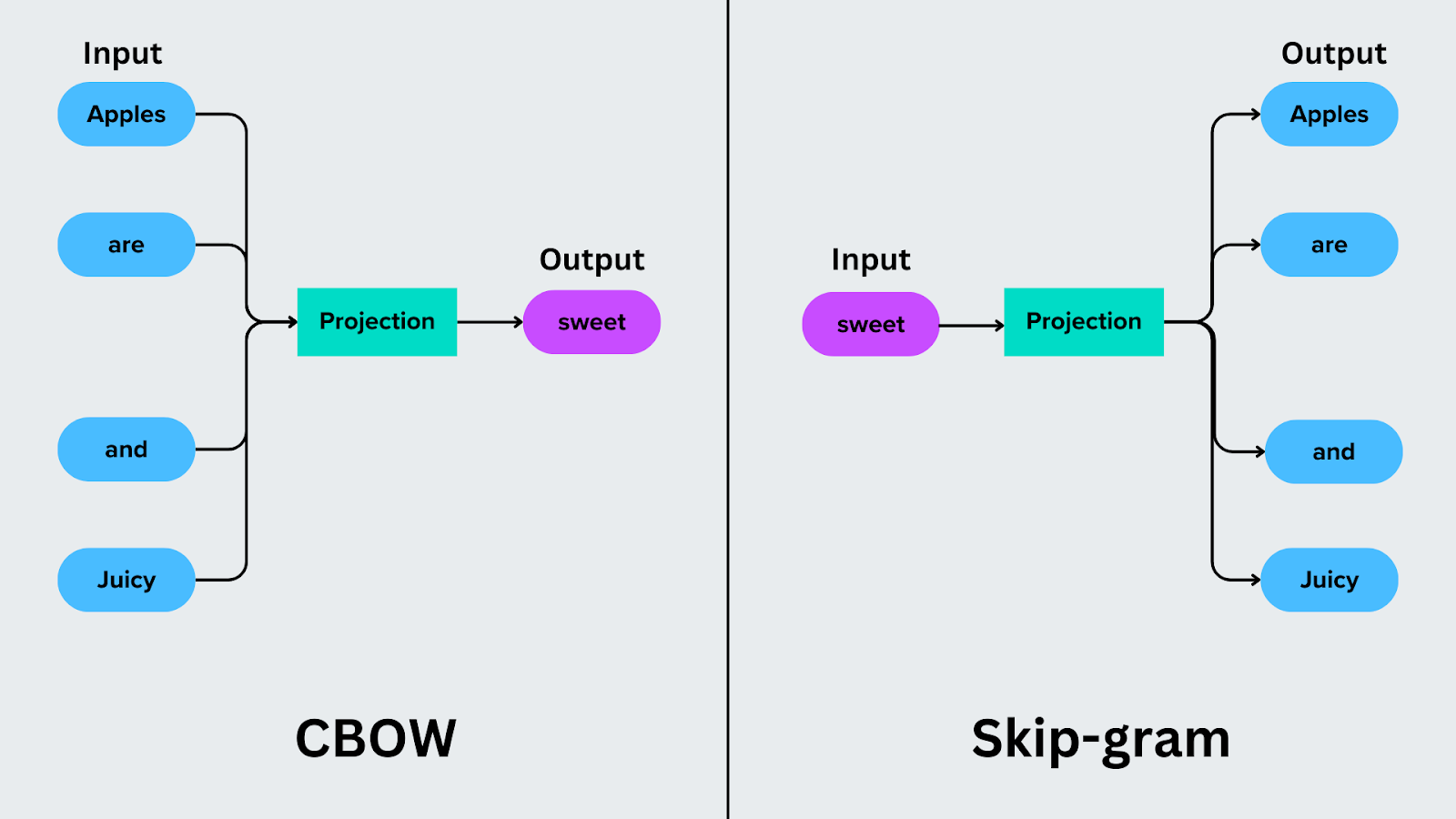 Figure- CBOW vs Skip-gram.png
Figure- CBOW vs Skip-gram.png
Figure: CBOW vs Skip-gram
Différence entre le modèle CBOW et le modèle Skip-Gram
Si les modèles CBOW et Skip-Gram visent tous deux à représenter les mots de manière significative, ils diffèrent dans la manière dont ils traitent et prédisent les mots en fonction du contexte. La comparaison ci-dessous met en évidence les principales différences entre ces deux approches :
| La comparaison ci-dessous met en évidence les principales différences entre ces deux approches.
| ---------------------------- | --------------------------------------------------------- | -------------------------------------------------------- |
| L'objectif est de déterminer le mot cible à l'aide du contexte environnant. | Prédit les mots du contexte en fonction du mot cible. |
Efficacité | Entraînement plus rapide. | Plus lent à former. |
Focalisation | Fonctionne bien avec les mots fréquents. | Traite efficacement les mots rares. |
Complexité | Plus simple et plus efficace en termes de calcul. | Plus complexe et intensif en termes de calcul. |
Cas d'utilisation | Convient à des tâches telles que la prédiction de mots et l'autocorrection. | Idéal pour des tâches spécialisées telles que les systèmes de recommandation.
| Fenêtre contextuelle** | Considère la moyenne de tous les mots contextuels. | Les mots contextuels individuels sont évalués séparément.
| Les performances sont bonnes sur des ensembles de données de petite taille. | Les performances sont meilleures avec les grands ensembles de données. |
| Exemple de prédiction de "aboiement" à partir de "Le chien est ___". | Prédit "Le", "chien" et "est" à partir de "aboiement".
Tableau: CBOW vs Skip-Gram
Implémentation de Word2Vec en Python
Vous trouverez ci-dessous l'implémentation Python de Word2Vec en utilisant les méthodes CBOW et Skip-Gram. Ce code s'entraîne sur un petit ensemble de données personnalisé pour apprendre les enchâssements de mots, démontrant comment les deux méthodes fonctionnent pour capturer les relations entre les mots en fonction de leur contexte. Les deux sections du code sont conçues pour comparer comment CBOW et Skip-Gram apprennent différemment les relations entre les mots, mais elles partagent les mêmes paramètres pour une comparaison équitable. Vous pouvez trouver l'implémentation ci-dessous dans ce [Kaggle notebook] (https://www.kaggle.com/code/fariba999/word2vec-implementation).
Code
from gensim.models import Word2Vec
# Petit corpus ciblé
corpus = [
["chat", "chien", "aboyé"],
["dog", "chased", "cat"],
["chat", "assis", "mat"],
["chien", "couru", "rapide"],
["chat", "couru", "rapide"],
["chien", "assis", "mat"]
]
# Former un modèle CBOW
cbow_model = Word2Vec(
sentences=corpus,
vector_size=10, # Taille du vecteur plus petite pour plus de simplicité
window=2, # Taille de la fenêtre contextuelle
min_count=1, # Inclut tous les mots
sg=0 # Fixer sg=0 pour CBOW
)
# Entraînement d'un modèle Skip-Gram
skipgram_model = Word2Vec(
sentences=corpus,
vector_size=10, # Taille du vecteur plus petite pour plus de simplicité
window=2, # Taille de la fenêtre contextuelle
min_count=1, # Inclut tous les mots
sg=1 # Définir sg=1 pour Skip-Gram
)
# Fonction pour afficher les vecteurs de mots et les mots similaires
def display_model_results(model, model_name) :
print(f"\n--- {nom_modèle} ---")
pour mot dans ["chat", "chien"] :
print(f "Vecteur de mots pour '{mot}' : {model.wv[mot][:5]}...") # Affiche les 5 premières valeurs du vecteur
mots_similaires = model.wv.most_similar(word, topn=3)
print(f "Le plus similaire à '{mot}' : {[(w, round(sim, 2)) for w, sim in similar_words]}")
# Afficher les résultats du modèle CBOW
display_model_results(cbow_model, "CBOW Model")
# Afficher les résultats du modèle Skip-Gram
display_model_results(skipgram_model, "Skip-Gram Model")
Sortie :
--- Modèle CBOW ---
Vecteur de mots pour "cat" : [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Les plus similaires à 'chat' : [('chien', 0.54), ('rapide', 0.33), ('aboyé', 0.23)] Vecteur de mots pour "chien" : [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Les plus proches de 'chien' : [('chat', 0.54), ('rapide', 0.3), ('couru', 0.1)]
--- Modèle Skip-Gram ---
Vecteur de mots pour 'cat' : [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Les plus similaires à 'chat' : [('chien', 0.54), ('rapide', 0.33), ('aboyé', 0.23)] Vecteur de mots pour "chien" : [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Les plus proches de 'chien' : [('chat', 0.54), ('rapide', 0.3), ('couru', 0.1)]
Dans la partie CBOW du code :
Le modèle est entraîné en utilisant le paramètre sg=0, qui indique à Word2Vec d'utiliser la méthode des sacs de mots continus.
CBOW détermine un mot en utilisant le contexte des mots qui l'entourent. Par exemple, dans la phrase ["dog", "chased", "cat"], le modèle pourrait utiliser "dog" et "cat" pour prédire "chased".
Le paramètre vector_size=10 définit la taille des enchâssements de mots (le nombre de chiffres représentant chaque mot).
La fenêtre=2 spécifie la [fenêtre contextuelle] (https://zilliz.com/glossary/context-window), ce qui signifie qu'elle prend en compte jusqu'à 2 mots avant et après le mot cible.
Dans la partie Skip-Gram du code :
Le modèle est entraîné en utilisant le paramètre sg=1, qui fait passer Word2Vec à la méthode Skip-Gram.
La méthode Skip-Gram identifie les mots environnants à partir d'un mot cible donné. Par exemple, si le mot cible est "chased", le modèle prédit "dog" et "cat" comme ses voisins.
Similaire à CBOW :
vector_size=10 définit la taille des enchâssements de mots.
window=2 définit la plage de mots contextuels à prendre en compte.
Avantages de Word2Vec
Voici quelques avantages clés qui font de Word2Vec une technique fondamentale du NLP :
Capture des relations sémantiques : Word2Vec crée des enchâssements où des mots sémantiquement similaires (par exemple, "roi" et "reine") sont positionnés à proximité les uns des autres dans l'espace vectoriel afin d'analyser et d'utiliser ces relations dans les tâches de TAL.
Compréhension du contexte** : En analysant la cooccurrence des mots dans de larges corpus, Word2Vec capture les relations dépendantes du contexte, permettant aux modèles de mieux comprendre la signification des mots dans des contextes spécifiques.
Représentation efficace** : Les enchâssements de mots sont denses et de faible dimension par rapport aux représentations éparses telles que l'encodage à une touche, ce qui en fait une technique efficace en termes de mémoire et de coûts de calcul.
Prise en charge de vocabulaires volumineux** : Contrairement aux techniques plus anciennes, Word2Vec s'adapte efficacement aux grands ensembles de données et aux vocabulaires, ce qui le rend pratique pour les applications du monde réel.
Prise en charge de l'apprentissage par transfert** : Les ancrages Word2Vec pré-entraînés peuvent être réutilisés dans de multiples tâches, ce qui permet d'économiser du temps et des ressources informatiques tout en améliorant les résultats.
L'arithmétique sur les mots** : Word2Vec prend en charge l'arithmétique vectorielle significative pour des analogies telles que "roi - homme + femme = reine", qui peuvent être calculées directement à l'aide d'encastrements.
Cas d'utilisation de Word2Vec
Word2Vec a un large éventail d'applications pour les tâches de NLP. Voici quelques-uns de ses cas d'utilisation pratiques et efficaces :
Traduction automatique : Améliore le mappage des mots entre les langues en utilisant les embeddings pour aligner les mots ayant des significations similaires afin d'améliorer la précision de la traduction.
Analyse des sentiments** : Identifie le ton du texte en analysant les relations entre les mots et le contexte pour classer les sentiments positifs, négatifs ou neutres.
Classement des recherches** : Améliore les moteurs de recherche en comprenant la similarité entre les requêtes de recherche et le contenu indexé, ce qui permet d'obtenir des résultats plus pertinents.
Recommandations de produits** : Fait correspondre les préférences de l'utilisateur avec des produits ou des services en analysant les descriptions textuelles et en trouvant des articles similaires.
Modélisation de sujets** : Organise et analyse de grands ensembles de données textuelles en regroupant les documents en grappes sur la base de la similarité des enchâssements de mots.
Autocomplétion de texte** : Suggère des mots ou des phrases pertinents en prédisant des mots similaires au contexte, améliorant ainsi l'expérience de l'utilisateur dans les outils de saisie ou de codage.
Chatbots** : Permet une meilleure compréhension des entrées et du contexte de l'utilisateur, aidant les chatbots à générer des réponses précises et pertinentes.
Limites de Word2Vec
Malgré ses avantages, Word2Vec a ses limites :
manque de prise en compte du contexte : Word2Vec génère une seule représentation pour chaque mot, quel que soit son contexte. Par exemple, le mot "banque" aura la même représentation vectorielle, qu'il désigne une rive ou une institution financière.
Dépendance à l'égard des données** : Une formation efficace nécessite des ensembles de données textuelles volumineux et de haute qualité. Des ensembles de données mal traités ou de petite taille peuvent conduire à des encastrements sous-optimaux.
Traitement des mots rares** : Difficultés avec les mots peu fréquents ou les termes hors vocabulaire, car ils peuvent ne pas apparaître suffisamment dans les données d'apprentissage pour générer des encastrements significatifs.
Pas de représentation au niveau de la phrase** : Word2Vec se concentre sur les ancrages au niveau des mots et ne fournit pas de représentations pour des phrases ou des documents entiers, ce qui limite son champ d'application à des tâches NLP spécifiques.
Ignore l'ordre des mots** : Le modèle prend en compte les mots dans une fenêtre contextuelle mais ne tient pas compte de leur ordre, ce qui peut affecter la compréhension de la grammaire ou de la structure de la phrase.
Obsolète par rapport aux modèles modernes** : Word2Vec a été principalement remplacé par des modèles avancés tels que BERT, GLoVE, et GPT, qui fournissent des encastrements contextuels et plus robustes.
Combler le fossé : de Word2Vec à GloVe, BERT et GPT
Les modèles prédictifs tels que Word2Vec créent des enchâssements de mots en se concentrant sur le contexte local à l'aide de réseaux neuronaux. Cependant, leur dépendance à l'égard des paires de mots proches présente une limite : Ils ne parviennent pas à capturer des relations plus larges et globales dans l'ensemble d'un corpus de textes. Par exemple, si Word2Vec excelle dans l'identification des associations de mots proches, il manque souvent des connexions sémantiques plus étendues.
Pour remédier à ce problème, [GloVe (Global Vectors for Word Representation)] (https://zilliz.com/glossary/glove) utilise des statistiques de cooccurrence globales pour créer des enchâssements de mots. Il analyse la fréquence à laquelle les mots apparaissent ensemble dans l'ensemble du corpus afin de saisir à la fois le contexte local et les relations sémantiques plus larges pour une représentation plus complète de la langue.
Plus récemment, des modèles tels que BERT (Bidirectional Encoder Representations from Transformers) et GPT (Generative Pre-trained Transformer) sont allés au-delà des encastrements statiques. BERT a introduit des enchâssements contextuels, représentant les mots différemment en fonction de leur utilisation dans une phrase, tandis que GPT s'est concentré sur la génération d'un texte cohérent en comprenant le contexte séquentiel. Ces modèles ont transformé le NLP en incorporant des représentations dynamiques et contextuelles, ce qui a permis de remédier aux limites des méthodes antérieures telles que Word2Vec et GloVe.
Word2Vec with Milvus : Efficient Vector Search for NLP Applications (Word2Vec avec Milvus : recherche vectorielle efficace pour les applications de TAL)
Word2Vec permet de créer des enchâssements de mots qui sont essentiels pour des tâches telles que la [recherche sémantique] (https://zilliz.com/glossary/semantic-search), la similarité des documents et les systèmes de recommandation, où la compréhension des relations entre les mots est cruciale. Cependant, la gestion et l'interrogation efficaces de vastes collections d'enchâssements peuvent constituer un défi.
C'est là qu'intervient Milvus, la base de données vectorielles open-source développée par Zilliz. Milvus fournit une solution robuste pour le stockage, l'indexation et l'interrogation des embeddings Word2Vec ou de tout autre type d'embeddings à grande échelle pour une intégration transparente dans les flux de travail NLP. Voici comment Word2Vec et Milvus fonctionnent ensemble :
Gestion efficace des incorporations de mots: Word2Vec génère des incorporations à haute dimension pour les mots du vocabulaire, dont la taille peut augmenter de manière significative avec les grands ensembles de données. Milvus gère efficacement ces encastrements en.. :
Stockage évolutif : Stockage de millions d'enchâssements de mots sans dégradation des performances.
Récupération rapide : Des algorithmes optimisés garantissent une recherche rapide d'embeddings similaires, ce qui est crucial pour les applications NLP en temps réel telles que les systèmes de recommandation ou les chatbots.
Recherche sémantique améliorée : Les embeddings Word2Vec excellent dans la capture des relations entre les mots. Combinés à Milvus, ces embeddings peuvent permettre une recherche sémantique avancée. Par exemple :
Recherche de synonymes ou de termes apparentés (par exemple, la recherche de "roi" permet d'obtenir des enregistrements tels que "reine" ou "prince").
Mise en œuvre de systèmes de recherche robustes tels que [Retrieval Augmented Generation (RAG)] (https://zilliz.com/learn/Retrieval-Augmented-Generation) qui s'appuient sur la similarité des mots pour obtenir de meilleurs résultats.
**Milvus simplifie les flux de travail NLP impliquant Word2Vec grâce à :
permettant de stocker et d'interroger efficacement les enchâssements Word2Vec pré-entraînés.
En prenant en charge l'intégration avec des cadres d'apprentissage automatique pour le regroupement, la similarité des documents et la recherche en temps réel.
Conclusion
Word2Vec a transformé la façon dont nous travaillons avec les données linguistiques en introduisant des enchâssements de mots qui capturent le sens et les relations des mots. Il a résolu de nombreux problèmes posés par les méthodes traditionnelles, comme l'incapacité à saisir les similitudes sémantiques et syntaxiques. Il est utilisé dans des applications telles que l'analyse des sentiments, la traduction et les systèmes de recommandation. Malgré ses limites, Word2Vec a jeté les bases de nombreuses avancées dans le domaine et a influencé le développement de modèles plus sophistiqués tels que GLoVE, BERT et GPT.
FAQ sur Word2Vec
- **Qu'est-ce que Word2Vec et pourquoi est-il important ?
Word2Vec est un modèle d'apprentissage automatique qui crée des représentations vectorielles denses des mots, appelées "word embeddings", en fonction de leur contexte. Il est important parce qu'il capture les relations et les significations des mots pour les tâches NLP telles que l'analyse des sentiments, la traduction et la recherche.
- **En quoi Word2Vec diffère-t-il des méthodes traditionnelles de représentation des mots ?
Contrairement aux méthodes traditionnelles telles que l'encodage à une touche, qui représentent les mots comme des vecteurs épars sans relations inhérentes, Word2Vec crée des enchâssements denses qui capturent les similarités sémantiques et syntaxiques entre les mots, ce qui le rend beaucoup plus efficace et significatif.
- **Quelles sont les principales architectures utilisées dans Word2Vec ?
Word2Vec a deux architectures principales : Continuous Bag of Words (CBOW) et Skip-Gram. CBOW détermine un mot cible à partir de son contexte environnant, tandis que Skip-Gram identifie les mots du contexte à partir d'un mot cible donné. Chacune de ces architectures a ses avantages en fonction du cas d'utilisation et de l'ensemble de données.
- **Quels sont les principaux cas d'utilisation de Word2Vec ?
Word2Vec est utilisé dans des applications telles que l'analyse des sentiments, la traduction automatique, les systèmes de recommandation, le classement des recherches, la modélisation des sujets et le développement de chatbots. Sa capacité à comprendre les relations entre les mots le rend polyvalent pour diverses tâches de NLP.
- **Quelles sont les limites de Word2Vec ?
Word2Vec présente plusieurs limites, notamment son manque de prise en compte du contexte (par exemple, il ne fait pas la différence entre les différents sens d'un même mot), sa dépendance à l'égard de grands ensembles de données pour l'entraînement et son incapacité à saisir l'ordre des mots ou le sens au niveau de la phrase. Ces inconvénients ont conduit au développement de modèles plus avancés tels que GloVe, BERT et GPT.
Ressources connexes
Les 10 meilleures techniques NLP que tout scientifique des données devrait connaître
[Les 10 meilleurs outils et plates-formes de traitement du langage naturel] (https://zilliz.com/learn/top-10-natural-language-processing-tools-and-platforms)
20 ensembles de données ouvertes populaires pour le traitement du langage naturel
[Révéler la puissance du traitement du langage naturel : Les 10 meilleures applications dans le monde réel] (https://zilliz.com/learn/top-5-nlp-applications)
GloVe : un algorithme d'apprentissage automatique pour décoder les connexions entre les mots] (https://zilliz.com/glossary/glove)
- Qu'est-ce que Word2Vec ?
- Pourquoi avons-nous besoin de Word2Vec ?
- Comment fonctionne Word2Vec ?
- Implémentation de Word2Vec en Python
- Avantages de Word2Vec
- Cas d'utilisation de Word2Vec
- Limites de Word2Vec
- Combler le fossé : de Word2Vec à GloVe, BERT et GPT
- Word2Vec with Milvus : Efficient Vector Search for NLP Applications (Word2Vec avec Milvus : recherche vectorielle efficace pour les applications de TAL)
- Conclusion
- FAQ sur Word2Vec
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement