




Observabilité : Suivre au-delà de la surveillance
Observabilité : Suivre au-delà de la surveillance
Qu'est-ce que l'observabilité ?
L'observabilité consiste à comprendre ce qui se passe à l'intérieur d'un système sur la base des données qu'il produit. Il s'agit de la capacité à "regarder à l'intérieur" d'un système logiciel et à comprendre son état et son comportement. Elle permet de répondre à des questions telles que "Tout fonctionne-t-il comme prévu ?" ou "Pourquoi quelque chose ne va pas ?". Au lieu de deviner les causes des problèmes, l'observabilité fournit des informations claires grâce à des données telles que les journaux, les mesures et les traces.
Pourquoi l'observabilité est-elle importante ?
Les systèmes logiciels modernes deviennent de plus en plus complexes. Avec l'essor de technologies telles que les microservices, l'informatique en nuage et la conteneurisation, les systèmes sont désormais constitués de nombreuses parties interconnectées qui peuvent être réparties sur différents sites. Il est donc difficile de les surveiller et de les dépanner.
Les outils de surveillance traditionnels sont souvent insuffisants : ils peuvent vous dire que quelque chose ne va pas, mais pas pourquoi. L'observabilité comble cette lacune en offrant une visibilité sur l'état interne des systèmes afin d'identifier rapidement les problèmes.
Les piliers de l'observabilité
Observability repose sur trois piliers qui fonctionnent ensemble pour fournir une image claire de ce qui se passe à l'intérieur d'un système. Décomposons-les :
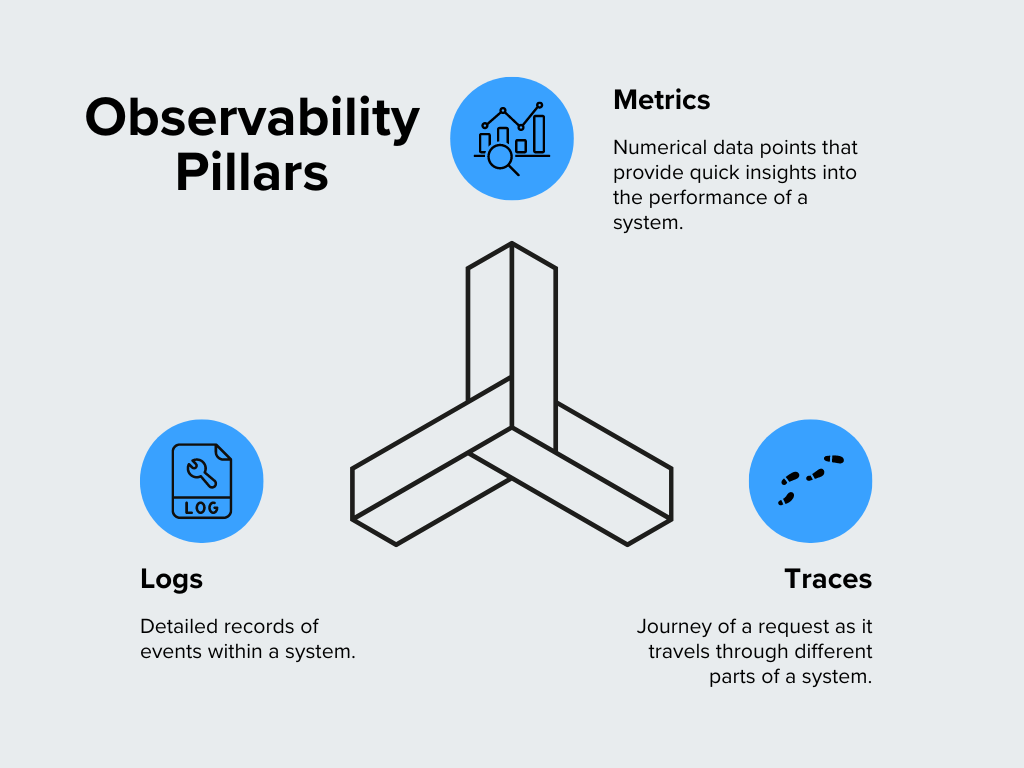 Figure- Piliers de l'observabilité.png
Figure- Piliers de l'observabilité.png
Figure : Piliers de l'observabilité
Métriques
Les métriques sont des points de données numériques qui donnent un aperçu rapide des performances d'un système. Ce sont les signes vitaux de votre système qui montrent comment les choses fonctionnent. Les mesures les plus courantes sont l'utilisation de l'unité centrale, la consommation de mémoire, les taux de requête et les temps de réponse. Par exemple, si vous remarquez un pic inhabituel dans l'utilisation de l'unité centrale, cela peut indiquer un problème qui nécessite une attention particulière. Les mesures sont très utiles pour identifier les tendances et voir comment un système se comporte au fil du temps.
Journaux
Les journaux sont des enregistrements détaillés des événements qui se produisent au sein d'un système. Considérez-les comme un journal qui capture ce qui se passe dans votre logiciel. Chaque fois qu'une erreur se produit, qu'un utilisateur se connecte ou qu'une transaction est traitée, elle est généralement enregistrée dans un journal. Les journaux fournissent un contexte permettant de diagnostiquer les problèmes et de comprendre le comportement du système. Par exemple, lorsque quelque chose ne fonctionne pas, les journaux peuvent aider à déterminer ce qui s'est passé juste avant et après l'apparition du problème.
Traces
**Dans une configuration complexe où plusieurs services travaillent ensemble, une trace vous montre le chemin parcouru par une requête unique et le temps qu'elle passe dans chaque service. Les traces permettent d'identifier les goulets d'étranglement ou les retards dans le processus. Si vous constatez qu'une requête prend plus de temps que prévu, les traces peuvent vous aider à déterminer l'origine du ralentissement.
Comment fonctionne l'observabilité ?
L'observabilité suit quelques étapes importantes. Voici comment cela fonctionne :
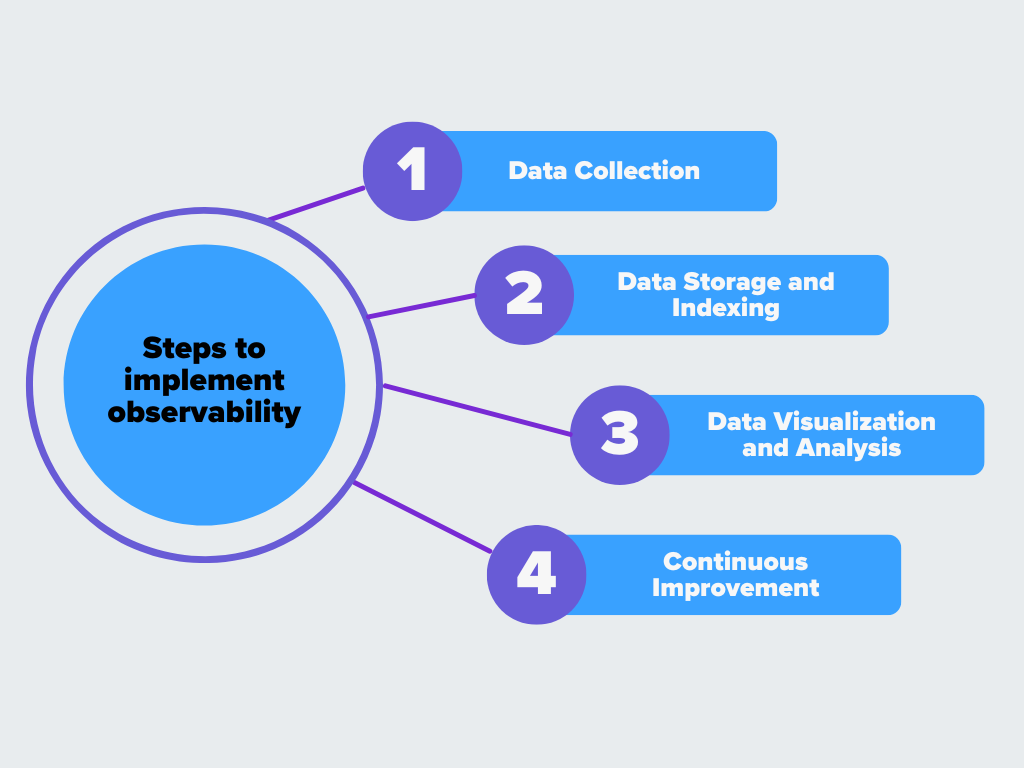 Figure- Etapes de la mise en œuvre de l'observabilité.png
Figure- Etapes de la mise en œuvre de l'observabilité.png
Figure : Étapes de la mise en œuvre de l'observabilité
Collecte des données
La première étape consiste à recueillir des données de toutes les parties du système. Cela inclut la collecte de métriques (comme
l'utilisation du processeur), les logs (enregistrements détaillés des événements) et les traces (le chemin emprunté par les requêtes à travers les services). L'objectif est de capturer tout ce qui peut donner un aperçu des performances, des problèmes ou du comportement général du système. Ces données proviennent de diverses sources, telles que les serveurs, les applications, les bases de données et les interactions des utilisateurs.
Stockage et indexation des données
Une fois les données collectées, elles doivent être stockées efficacement. Un stockage adéquat permet de retrouver et d'utiliser rapidement les données en cas de besoin. L'indexation des données permet de rechercher et d'extraire plus rapidement des informations spécifiques. Par exemple, lorsqu'un problème survient, les ingénieurs doivent être en mesure d'extraire facilement les journaux ou les mesures liés à cet incident, sans délai. De bonnes pratiques de stockage sont essentielles pour garder les données organisées et accessibles.
Visualisation et analyse des données
Collecter des données est une chose, les exploiter en est une autre. Les outils de visualisation et les tableaux de bord jouent un rôle essentiel à cet égard. Ils transforment les données brutes en graphiques, diagrammes et alertes faciles à comprendre. La visualisation aide les équipes à voir rapidement les tendances, les modèles ou tout comportement inhabituel dans le système. Les tableaux de bord facilitent la détection des problèmes de performance et permettent d'approfondir les détails si quelque chose semble anormal. Les systèmes d'alerte peuvent également informer les équipes en temps réel lorsque les mesures franchissent certains seuils ou lorsque des erreurs se produisent.
Amélioration continue
Les données issues de l'observabilité ne servent pas uniquement à résoudre les problèmes, mais aussi à améliorer le système. En examinant régulièrement les données collectées, les équipes peuvent identifier les domaines qui nécessitent une amélioration ou une optimisation. La boucle de rétroaction continue incorpore des améliorations afin que le système fonctionne plus efficacement. Les données d'observabilité peuvent guider les décisions relatives à l'augmentation des ressources, ce qui améliore l'expérience de l'utilisateur et prévient les problèmes futurs.
Cas d'utilisation de l'observabilité
L'observabilité a un fort impact sur les applications du monde réel. Voici quelques cas d'utilisation pratiques qui montrent comment l'observabilité fait la différence :
Surveillance des performances dans les systèmes distribués
Les problèmes de performance peuvent être difficiles à identifier dans un système distribué où plusieurs services travaillent ensemble. L'observabilité permet de fournir des mesures, des journaux et des traces qui donnent une image claire de la façon dont les différents services interagissent. Par exemple, si un seul microservice ralentit l'ensemble de l'application, les outils d'observabilité peuvent rapidement mettre en évidence le service qui est à l'origine du décalage.
Débogage et dépannage des défaillances
Lorsqu'un système tombe en panne, les équipes cherchent à savoir ce qui n'a pas fonctionné. L'observabilité facilite grandement ce processus en fournissant des journaux détaillés et des traces d'événements. Par exemple, si un serveur tombe en panne ou si une requête échoue, les journaux peuvent montrer exactement ce qui s'est passé juste avant la panne. Les traces aident les équipes à voir comment le problème se propage dans les différents services.
Fiabilité et disponibilité
L'observabilité joue un rôle important dans la réalisation des objectifs de niveau de service (SLO) et des accords de niveau de service (SLA). Il s'agit d'engagements concernant la fiabilité et la disponibilité d'un système. En suivant l'état de santé du système au moyen de mesures et d'alertes, les équipes peuvent atteindre ces objectifs. Par exemple, si les temps de réponse commencent à ralentir, l'observabilité aide les équipes à agir avant que les utilisateurs ne soient affectés, ce qui permet de maintenir un service fiable.
Planification de la capacité et mise à l'échelle
Au fur et à mesure que les systèmes se développent, ils ont besoin de plus de ressources, comme des serveurs ou de la mémoire. L'observabilité facilite la planification de la capacité en suivant les mesures qui montrent comment le système est utilisé. Par exemple, le suivi de l'utilisation de l'unité centrale ou de la charge de la base de données au fil du temps peut aider à prévoir quand il faudra augmenter la capacité. Grâce à la planification et à la mise à l'échelle de la capacité, le système fonctionne bien, sans surprise.
Détection proactive des problèmes
L'une des meilleures utilisations de l'observabilité consiste à détecter les problèmes avant qu'ils ne deviennent des problèmes majeurs. La surveillance et l'alerte en temps réel permettent aux équipes de détecter des schémas ou des pics inhabituels, comme l'augmentation des taux d'erreur ou des temps de réponse. Cette approche proactive permet d'éviter les temps d'arrêt et de maintenir une expérience utilisateur fluide. Par exemple, si les outils d'observabilité détectent rapidement une fuite de mémoire, les équipes peuvent y remédier avant que le système ne s'effondre.
Surveillance de l'expérience utilisateur
L'observabilité ne concerne pas seulement le backend ; elle permet également de suivre les interactions et le comportement des utilisateurs. Le suivi des mesures de l'expérience utilisateur, telles que les temps de chargement des pages, les temps de réponse aux boutons et les messages d'erreur, permet aux équipes d'identifier et de résoudre rapidement les problèmes rencontrés par les utilisateurs. Par exemple, si une nouvelle fonctionnalité ralentit le chargement des pages, les données d'observabilité le montreront immédiatement.
Optimisation des coûts dans les environnements en nuage
Les environnements en nuage impliquent souvent une tarification à l'usage, ce qui signifie que vous êtes facturé pour les ressources que vous utilisez. L'observabilité peut aider les équipes à optimiser les coûts en suivant les parties du système qui utilisent le plus de ressources. Par exemple, si un microservice donné consomme une grande quantité de bande passante, les outils d'observabilité peuvent le mettre en évidence, ce qui permet à l'équipe d'optimiser ou de remanier le service pour réduire les coûts.
Outils et technologies pour l'observabilité
Prometheus] (https://prometheus.io/) est un outil de surveillance open-source qui collecte et stocke des métriques sous forme de séries de données temporelles. Il est largement utilisé pour la surveillance des performances des systèmes et des applications grâce à ses capacités d'interrogation flexibles.
Grafana](https://grafana.com/) est un outil de visualisation souvent associé à Prometheus. Il crée des tableaux de bord interactifs qui aident à visualiser Prometheus metrics, à interpréter facilement les données, à surveiller les tendances et à configurer des alertes pour le comportement du système.
Jaeger](https://www.jaegertracing.io/) est un outil de traçage distribué qui permet de suivre les demandes au fur et à mesure qu'elles circulent dans les microservices. Il permet également de suivre les latences et d'identifier les goulots d'étranglement dans les systèmes complexes et distribués.
AWS CloudWatch](https://aws.amazon.com/cloudwatch/) est l'outil de surveillance et d'observabilité d'Amazon qui suit les mesures, collecte les journaux et fournit des alertes pour les ressources du nuage AWS. Il s'intègre parfaitement aux autres services AWS pour surveiller et gérer votre infrastructure.
Google Cloud Monitoring] (https://cloud.google.com/monitoring) offre une visibilité sur les applications et les services exécutés sur Google Cloud. Il propose des mesures, des tableaux de bord et des alertes pour surveiller l'état et les performances des ressources en nuage.
Azure Monitor] (https://azure.microsoft.com/en-us/products/monitor) est un outil qui offre une observabilité complète des ressources et des applications du nuage Azure. Il recueille des mesures, des journaux et des traces pour aider les équipes à analyser les performances et à résoudre rapidement les problèmes.
Les outils d'observabilité modernes utilisent l'IA et l'apprentissage automatique pour détecter les anomalies et prédire les problèmes futurs. Ces outils avancés peuvent automatiquement identifier des modèles et alerter les équipes en cas de comportement inhabituel.
Défis de l'observabilité
Évolutivité et volume de données
La collecte, le stockage et le traitement de grandes quantités de mesures, de journaux et de traces peuvent devenir un défi dans un système en pleine croissance. Une gestion efficace des données et des solutions de stockage évolutives sont essentielles pour gérer cette croissance.
Surcharge de données
Trop de données peuvent submerger les équipes et rendre difficile la recherche d'informations utiles. Pour éviter le bruit, il est important de filtrer et de se concentrer sur les données exploitables qui aident directement à diagnostiquer et à résoudre les problèmes, plutôt que de suivre chaque petit détail.
Intégration entre les services
Les systèmes modernes utilisent souvent plusieurs outils et composants. Une bonne intégration est nécessaire pour maintenir une observabilité transparente entre ces différents services. Sans cela, des informations critiques peuvent être manquées et du temps peut être perdu à passer d'un outil à l'autre.
Meilleures pratiques en matière d'observabilité
Pour tirer le meilleur parti des avantages de l'observabilité, veillez à suivre les meilleures pratiques suivantes :
Construire en tenant compte de l'observabilité
Dès le départ, concevez des systèmes facilement observables. Intégrez des mesures, des journaux et des traces dans votre architecture pour faciliter le suivi et la compréhension du comportement du système. Cette approche proactive simplifie le dépannage et l'optimisation des performances.
Vue unifiée des systèmes
Consolidez toutes les données d'observabilité dans une seule plateforme ou un seul tableau de bord. Une vue unifiée permet aux équipes d'identifier rapidement les problèmes et d'acquérir une compréhension globale de la manière dont les différents services interagissent, réduisant ainsi le temps passé à rassembler des informations provenant de sources multiples.
Stratégies d'alerte et de notification
Mettez en place des alertes claires, significatives et exploitables. Évitez la lassitude des alertes en ne ciblant que les événements critiques liés à des actions spécifiques et nécessaires. L'objectif est d'informer efficacement l'équipe, et non de la submerger de bruit.
Observabilité et surveillance
Bien qu'elles soient souvent mentionnées ensemble, l'observabilité et la surveillance ne sont pas identiques. Le tableau ci-dessous met en évidence les principales différences entre les deux :
Aspect | Observabilité | Surveillance | Surveillance | | ------------------ | ------------------------------------------------------------------------ | -------------------------------------------------------------------- | | Le tableau ci-dessous met en évidence les principales différences entre les deux : Aspect, Observabilité, Surveillance, Monitoring. | La surveillance permet de suivre des paramètres spécifiques afin de détecter des problèmes ou des anomalies. | | Les données collectées rassemblent les métriques, les journaux et les traces pour une analyse détaillée. | Les métriques prédéfinies telles que l'utilisation du processeur, la mémoire et les erreurs sont collectées. | | Approche exploratoire : aide à comprendre "pourquoi" un problème s'est produit. | Réactive ; notifie lorsqu'un problème connu se produit. | | L'analyse de la performance est un processus qui permet de comprendre le comportement global du système et d'obtenir des informations sur les performances. | L'analyse se concentre sur les mesures individuelles pour mesurer la santé du système. | | Résolution des problèmes | Permet d'identifier rapidement les problèmes inconnus et les causes profondes. | Les alertes sur les problèmes connus, mais peuvent manquer de contexte pour une analyse plus approfondie. | | Analyse en temps réel | Prend en charge l'analyse des données en temps réel pour suivre le comportement du système en direct. | L'analyse des données en temps réel permet de suivre en direct le comportement du système. | | Flexibilité des données | Permet une exploration flexible et approfondie des données au-delà des mesures prédéfinies. | Les systèmes de gestion des données permettent de surveiller des mesures spécifiques et présélectionnées sans contexte plus large. |
Différences d'observabilité et de surveillance
Observabilité dans Milvus et Zilliz Cloud : Suivi des performances de la base de données vectorielle
Milvus est une base de données vectorielle open-source conçue pour traiter efficacement des données non structurées à l'échelle du milliard. Elle est idéale pour les applications de recherche sémantique, de recherche par similarité et de GenAI. L'observabilité joue un rôle crucial dans la gestion et l'optimisation des performances de Milvus. En utilisant les pratiques d'observabilité, vous pouvez vous assurer que votre base de données vectorielle fonctionne de manière fluide et efficace, qu'il s'agisse de recommandations en temps réel ou de tâches retrieval-augmented generation (RAG) .
Le logiciel libre Milvus intègre Prometheus pour surveiller ses performances et Grafana pour visualiser toutes les mesures. Milvus s'intègre de manière transparente à Prometheus par le biais de :
Prometheus Endpoint : Collecte des données à partir de divers exportateurs.
Prometheus Operator : Rationalise la gestion des configurations de surveillance Prometheus.
Kube-Prometheus : Simplifie la surveillance complète des clusters Kubernetes pour un fonctionnement robuste.
Avec Prometheus, vous pouvez suivre les mesures critiques des performances de Milvus, telles que les temps de réponse des requêtes et l'utilisation des ressources (CPU, GPU et mémoire), ce qui permet une résolution proactive des problèmes et une optimisation du système. En outre, l'intégration de Prometheus avec Grafana améliore encore votre cadre de surveillance, en fournissant des tableaux de bord détaillés pour une analyse approfondie et une maintenance efficace des déploiements Milvus adaptés aux applications GenAI et recherche par similarité.
Pour obtenir des conseils complets sur la configuration de Prometheus pour Milvus et la visualisation des mesures avec Grafana, consultez les ressources ci-dessous :
Zilliz Cloud est la version gérée de Milvus avec des fonctionnalités plus avancées et des performances 10 fois supérieures. Elle offre des fonctionnalités de surveillance et d'observabilité encore plus claires et plus faciles. Zilliz Cloud a récemment introduit [de solides fonctions de surveillance et d'observabilité] (https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud) pour aider les utilisateurs à suivre les performances des bases de données vectorielles. Le tableau de bord des métriques fournit une vue d'ensemble de la santé du cluster, y compris l'utilisation des ressources (CPU, mémoire, stockage), les performances (QPS, VPS, latences) et les métriques de données (collecte et nombre d'entités), toutes personnalisables pour une analyse plus approfondie. Le tableau de bord présente les métriques de manière très intuitive pour une compréhension rapide.
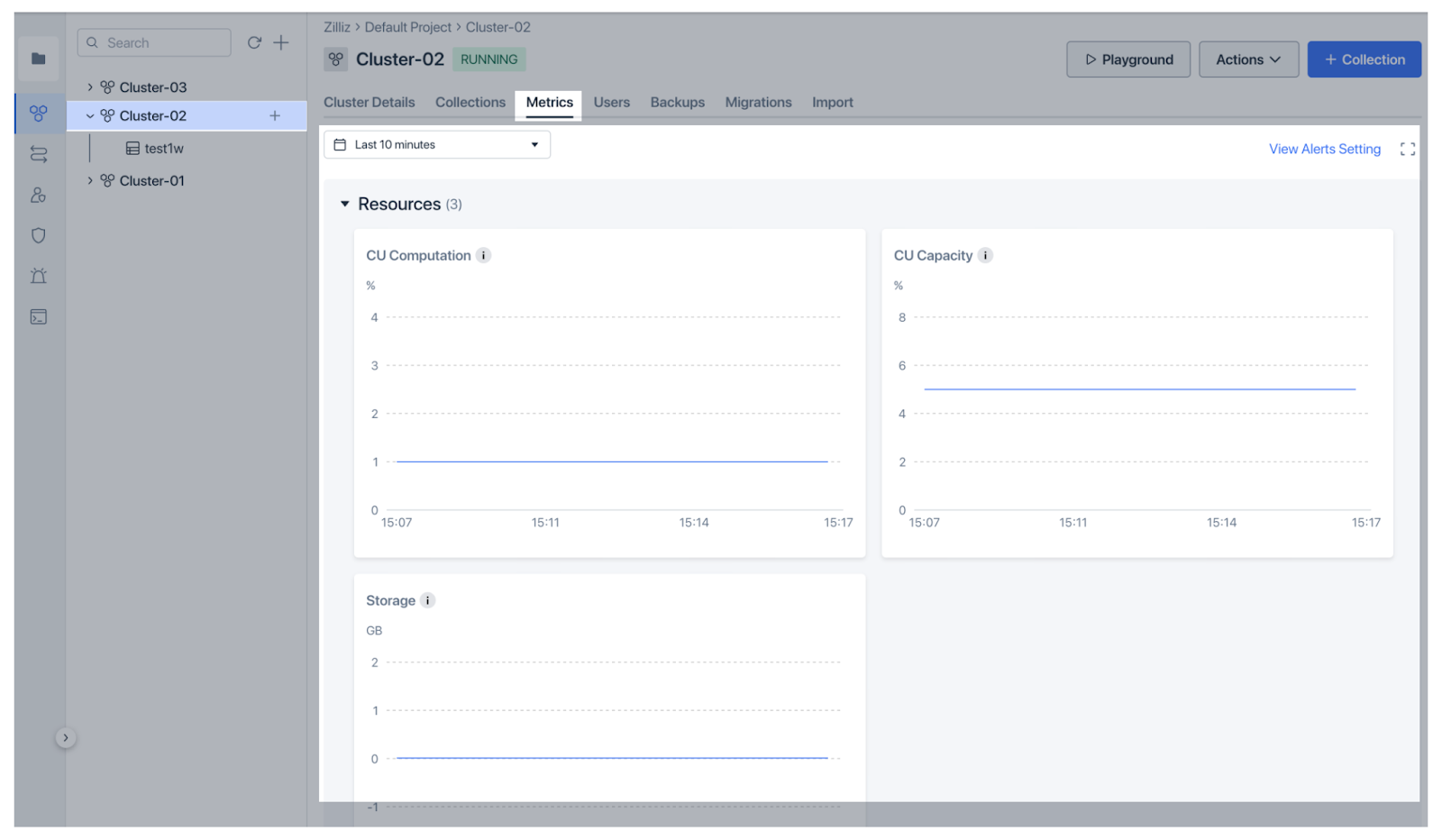 Figure : Zilliz Cloud Monitoring Metrics
Figure : Zilliz Cloud Monitoring Metrics
Figure : Mesures de surveillance du nuage de Zilliz
Pour détecter rapidement les problèmes, Zilliz Cloud propose des alertes d'organisation pour les questions de facturation et des alertes de projet pour les facteurs opérationnels tels que l'utilisation de l'UC et la latence, avec des seuils flexibles et des paramètres de sévérité.
Figure : Alertes d'organisation dans Zilliz Cloud](https://assets.zilliz.com/Figure_2_Screenshot_of_Organization_Alerts_493efb0dbc.png)
Figure : Alertes d'organisation dans Zilliz Cloud
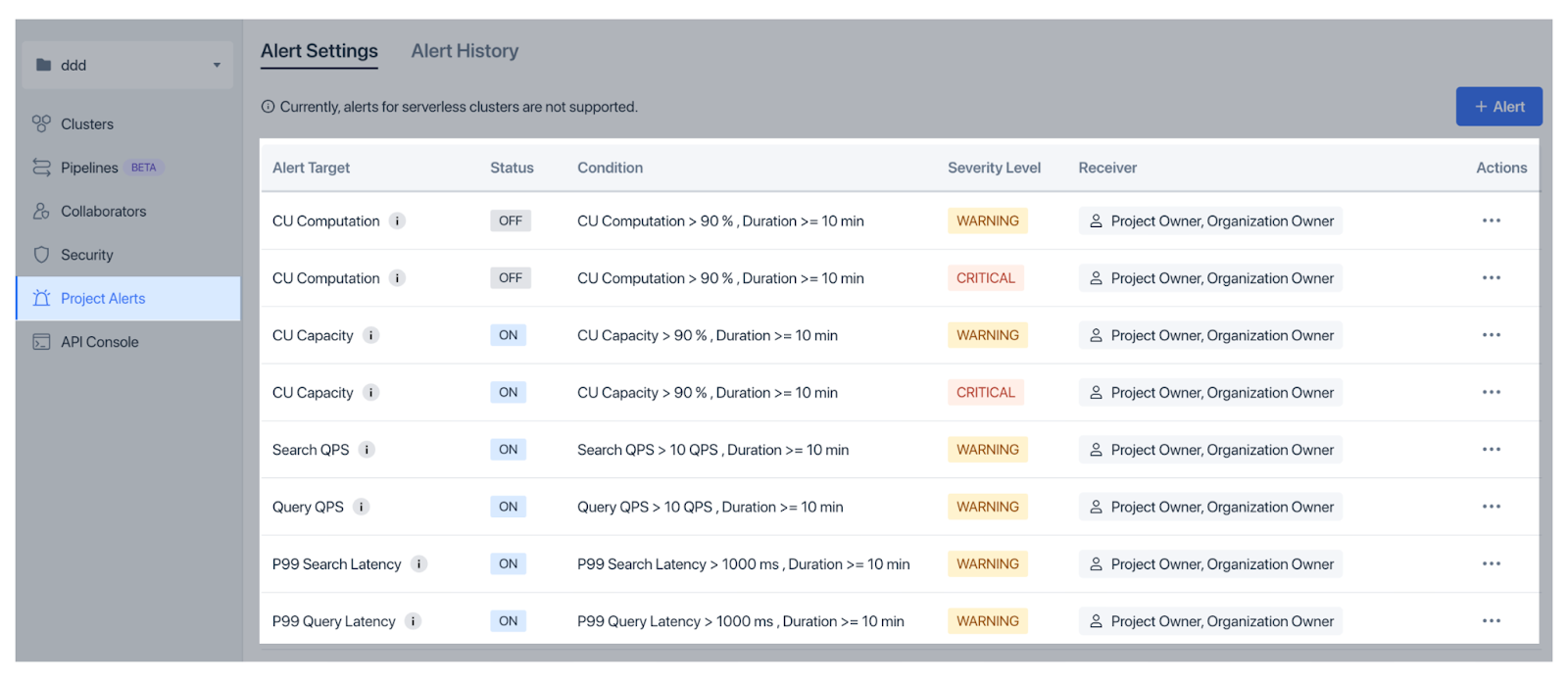 Figure : Alertes sur les projets dans Zilliz Cloud
Figure : Alertes sur les projets dans Zilliz Cloud
Figure : Alertes sur les projets dans Zilliz Cloud
Fonctionnalités principales
Surveillance en temps réel** pour un retour d'information instantané sur les performances du cluster.
Tableaux de bord personnalisables** adaptés à vos indicateurs clés.
Alertes flexibles** pour une détection précoce des problèmes potentiels.
Plusieurs canaux de notification** (email, Slack, PagerDuty).
Données historiques** pour analyser les tendances de performance pour une planification à long terme.
Conclusion
L'observabilité est une approche qui permet de comprendre et de maintenir la santé des systèmes modernes et complexes. En utilisant des mesures, des journaux et des traces, les équipes peuvent garantir des performances fiables, résoudre rapidement les problèmes et améliorer l'expérience des utilisateurs. Au fur et à mesure que les systèmes se développent et évoluent, il est important d'adopter les meilleures pratiques en matière d'observabilité afin de rester à l'affût des problèmes et de s'adapter efficacement. Qu'il s'agisse d'exécuter des microservices distribués ou de créer des applications basées sur l'IA avec des outils tels que Milvus, l'observabilité offre la visibilité nécessaire pour que tout fonctionne de manière fluide et fiable.
FAQ sur l'observabilité
L'observabilité consiste à comprendre l'état interne d'un système en collectant et en analysant des données telles que des métriques, des journaux et des traces. Elle est importante pour diagnostiquer les problèmes, surveiller les performances et maintenir la fiabilité du système, en particulier dans les configurations modernes complexes telles que les microservices et les applications cloud-natives.
En quoi l'observabilité diffère-t-elle de la surveillance ? ** Alors que la surveillance suit des métriques spécifiques pour détecter les problèmes, l'observabilité va plus loin en fournissant des informations sur le "pourquoi" de ces problèmes. La surveillance est comme une liste de contrôle, tandis que l'observabilité est comme une enquête complète sur le comportement et l'état du système.
Les trois piliers de l'observabilité sont les métriques (données numériques sur les performances du système), les logs (enregistrements détaillés des événements) et les traces (chemins empruntés par les requêtes à travers les services). Ces éléments combinés offrent une vue d'ensemble de la santé et de la performance d'un système.
Pourquoi l'observabilité est-elle essentielle pour les systèmes distribués ? Les systèmes distribués, comme ceux construits sur des microservices ou des plateformes cloud, ont de multiples composants qui interagissent. L'observabilité permet de surveiller et de déboguer les problèmes entre ces composants, ce qui facilite le suivi des problèmes de performance, l'identification des goulets d'étranglement et le maintien de la santé du système.
Ressources supplémentaires
- Qu'est-ce que l'observabilité ?
- Pourquoi l'observabilité est-elle importante ?
- Les piliers de l'observabilité
- Comment fonctionne l'observabilité ?
- Cas d'utilisation de l'observabilité
- Outils et technologies pour l'observabilité
- Défis de l'observabilité
- Meilleures pratiques en matière d'observabilité
- Observabilité et surveillance
- Observabilité dans Milvus et Zilliz Cloud : Suivi des performances de la base de données vectorielle
- Conclusion
- FAQ sur l'observabilité
- Ressources supplémentaires
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement