




Améliorer votre RAG avec des graphes de connaissances en utilisant KnowHow
La Retrieval Augmented Generation (RAG) est une technique populaire qui fournit au LLM des connaissances supplémentaires et des mémoires à long terme par le biais d'une base de données vectorielle comme Milvus et Zilliz Cloud (Milvus entièrement géré). Un RAG de base peut résoudre de nombreux problèmes liés au LLM, mais il est insuffisant si vous avez des besoins plus avancés tels que la personnalisation ou un plus grand contrôle des résultats récupérés.
Lors de notre récent Unstructured Data Meetup, Chris Rec, cofondateur de WhyHow, a expliqué comment il incorpore les graphes de connaissances (KG) dans le pipeline RAG pour améliorer les performances et la précision. Le blog couvrira les points clés de son exposé, y compris une vue d'ensemble des graphes de connaissances, des RAG et de la façon d'intégrer les graphes de connaissances dans les systèmes RAG pour de meilleures performances.
Si vous souhaitez en savoir plus sur ce sujet, nous vous recommandons de regarder l'intégralité de la conférence sur [YouTube] (https://www.youtube.com/watch?v=6pjObdJdyFs).
Un aperçu de RAG et de ses défis
Le RAG est une méthode qui exploite les forces des systèmes d'intelligence artificielle basés sur la recherche et génératifs. Un RAG vanille comprend généralement une base de données vectorielle comme Milvus, un modèle d'intégration et un grand modèle linguistique (LLM).
Un système RAG utilise d'abord le modèle d'intégration pour transformer les documents en intégrations vectorielles et les stocker dans une base de données vectorielle. Ensuite, il récupère les informations pertinentes de cette [base de données vectorielles] (https://zilliz.com/learn/what-is-vector-database) et fournit les résultats récupérés au LLM. Enfin, le LLM utilise les informations récupérées comme contexte pour générer des résultats plus précis.
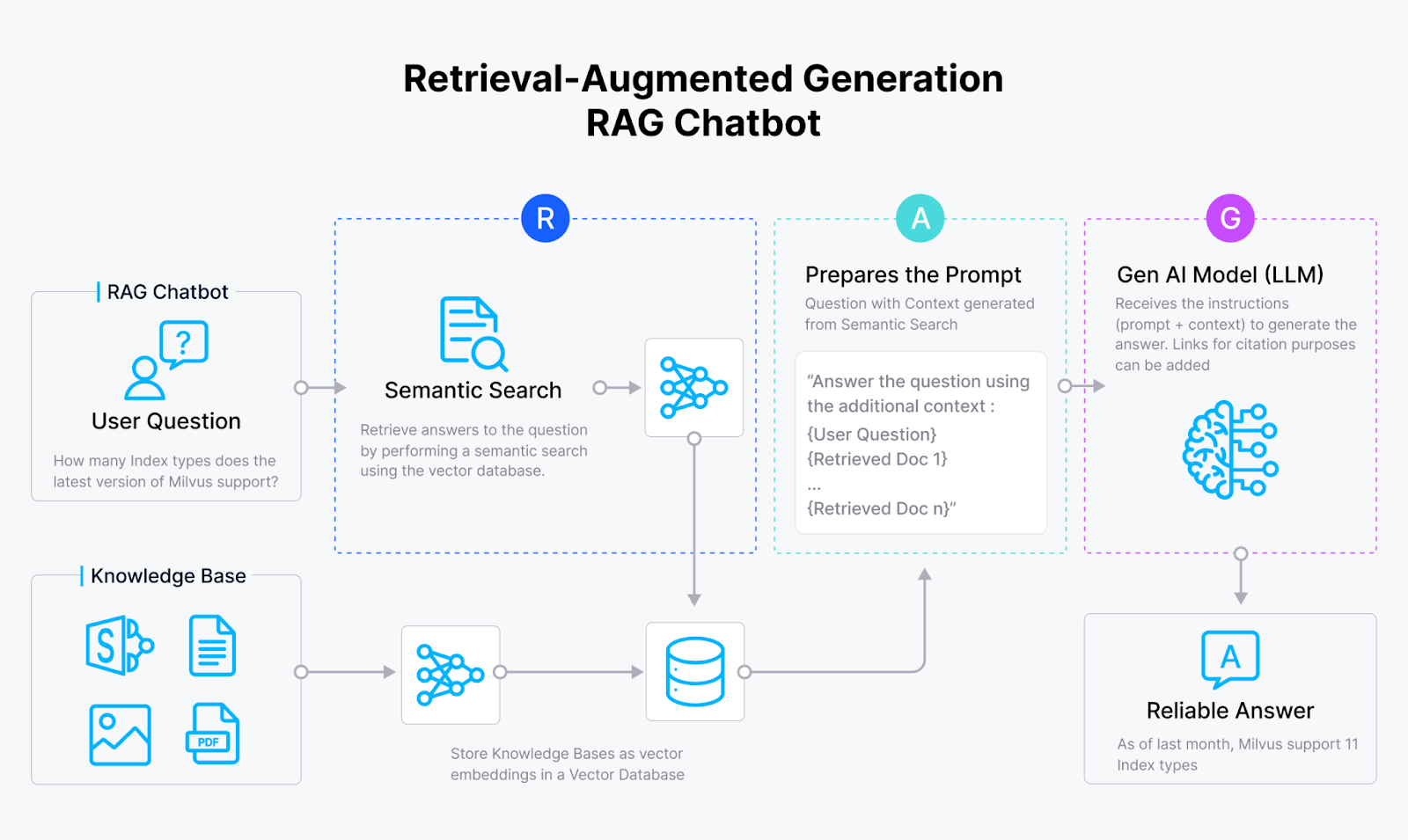 Flux de travail RAG
Flux de travail RAG
Fig 1 : Fonctionnement de RAG
Bien qu'un RAG vanille permette de générer des résultats plus récents et plus précis, il présente encore plusieurs limites.
**Par exemple, le terme "capacité des véhicules" peut se référer soit au nombre de passagers qu'une voiture peut contenir, soit au nombre de voitures qui peuvent tenir sur une route, ce qui crée une ambiguïté.
Deuxièmement, il est difficile de traiter avec précision différents types de requêtes. Par exemple, répondre à des requêtes basées sur la localisation telles que "Je veux aller à Londres" diffère considérablement de répondre à des requêtes plus abstraites liées au bien-être, telles que "Je suis stressé au travail et je veux prendre des vacances".
Troisièmement, il n'est pas facile de faire la distinction entre similitude et pertinence. Par exemple, il peut être difficile de faire la différence entre une "maison de plage" située à un kilomètre du rivage et une "maison de bord de mer" située directement sur le sable.
**L'extraction de toutes les informations pertinentes pour des questions exhaustives peut s'avérer difficile, en particulier pour les requêtes complexes, telles que la liste de tous les commanditaires d'un fonds qui ont investi au moins 10 millions de dollars et qui disposent de droits d'accès spéciaux aux données.
Enfin, les requêtes multi-sauts ajoutent un autre niveau de complexité, car elles nécessitent de combiner avec précision plusieurs éléments d'information. Cette approche nécessite de décomposer une requête en plusieurs sous-requêtes, chacune avec des conditions spécifiques, afin de s'assurer que la réponse finale est précise et complète.
Alors que des solutions telles que l'amélioration de la rapidité, les stratégies de regroupement avancées, les modèles d'intégration améliorés et le reclassement peuvent répondre à de nombreux défis associés au RAG, WhyHow adopte une approche différente en incorporant les graphes de connaissances dans le pipeline RAG.
Que sont les graphes de connaissances (KG) ?
Un graphe de connaissances (KG) est un type de structure de données qui ne se contente pas de stocker des données, mais qui relie également des données similaires ou dissemblables en fonction de leur relation. Cette approche permet de disposer d'une collection d'éléments (qui peuvent être n'importe quel type de données) liés d'une manière qui peut fournir des informations connexes ou pertinentes.
Un graphe de connaissances se compose de nœuds, d'arêtes et de propriétés.
Fig. 2 - Éléments constitutifs d'un graphe de connaissances] (https://assets.zilliz.com/Fig_2_Building_Blocks_of_a_Knowledge_Graph_3a3c13c822.png)
Fig 2 : Éléments constitutifs d'un graphe de connaissances
Nœuds:
Représentent les entités ou les objets du graphe.
Les valeurs stockées par ces entités peuvent être n'importe quel type de données.
Edges:
Représentent les relations entre les entités.
Ils contiennent des informations sur la nature de la relation entre les nœuds connectés.
Propriétés: Caractéristiques ou traits associés aux entités individuelles.
Contrairement aux bases de données tabulaires traditionnelles, les graphes de connaissances utilisent une structure graphique pour une représentation flexible des relations et se concentrent sur la compréhension sémantique. Cette approche permet d'effectuer des requêtes complexes et d'extraire plus facilement des informations spécifiques.
Avantages de l'intégration des graphes de connaissances dans les systèmes RAG
En intégrant les graphes de connaissances dans le pipeline RAG, nous pouvons améliorer de manière significative les capacités d'extraction du système et la qualité des réponses, ce qui se traduit par des performances, une précision, une traçabilité et une exhaustivité supérieures. Voici les principaux avantages d'un système RAG basé sur les graphes de connaissances :
Compréhension contextuelle améliorée
Les graphes de connaissances fournissent une représentation riche et interconnectée de l'information, permettant au système RAG de saisir les relations complexes entre les entités. Cette meilleure compréhension du contexte permet d'apporter des réponses plus nuancées et plus pertinentes.
Amélioration de la précision et de la cohérence des faits
La nature structurée des graphes de connaissances permet de maintenir la cohérence factuelle du contenu généré. En ancrant les réponses à des informations vérifiées dans le graphique, le système peut réduire les erreurs et les hallucinations courantes dans les modèles linguistiques traditionnels.
Capacités de raisonnement multi-sauts
Les graphes de connaissances permettent au système RAG d'effectuer des raisonnements à sauts multiples, en reliant des éléments d'information disparates par des voies logiques. Cette capacité permet de répondre à des requêtes plus sophistiquées et de générer des inférences.
Recherche d'informations efficace
La structure du graphe facilite la recherche rapide et précise d'informations, même pour des requêtes complexes. Cette efficacité se traduit par des temps de réponse plus rapides et une génération de contenu plus pertinent. En outre, les systèmes RAG basés sur les graphes de connaissances permettent une approche de recherche hybride, combinant la traversée des graphes avec des [recherches vectorielles et par mot-clé] (https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus), des capacités fournies par des bases de données vectorielles telles que Milvus et Zilliz Cloud.
Plus précisément, cette approche hybride permet :
une correspondance précise entre les entités et les relations grâce à la navigation dans les graphes
la mise en correspondance par [similarité sémantique] (https://zilliz.com/glossary/semantic-similarity) à l'aide de [vector embeddings] (https://zilliz.com/glossary/vector-embeddings)
Recherche traditionnelle par mot-clé pour les contenus à forte teneur en texte
Cette stratégie de recherche à multiples facettes améliore la capacité du système à trouver les informations les plus pertinentes dans différents types et structures de données, ce qui permet d'obtenir des réponses plus complètes et plus précises.
Des résultats transparents et traçables
Avec les graphes de connaissances, le système peut fournir une provenance claire des informations utilisées pour générer les réponses. Cette traçabilité renforce la confiance des utilisateurs et facilite le contrôle des faits et la vérification.
Synthèse des connaissances interdomaines
En représentant divers domaines au sein d'une structure graphique unique, les systèmes RAG basés sur les graphes de connaissances peuvent plus facilement synthétiser des informations dans différents domaines, ce qui permet d'obtenir des informations plus complètes et interdisciplinaires.
Amélioration du traitement de l'ambiguïté
La structure relationnelle des graphes de connaissances aide à désambiguïser les entités et les concepts, réduisant ainsi la confusion dans les situations où les termes ou les noms peuvent avoir plusieurs significations ou références.
En tirant parti de ces avantages, les applications RAG améliorées par des graphes de connaissances peuvent fournir des réponses plus précises, plus pertinentes sur le plan contextuel et plus complètes aux requêtes des utilisateurs.
Qu'est-ce que WhyHow ? Comment améliore-t-il les RAG avec les graphes de connaissances ?
[WhyHow] (https://www.whyhow.ai/) est une plateforme permettant de construire et de gérer des graphes de connaissances afin de faciliter la recherche de données complexes. La construction de graphes de connaissances complets est un défi et prend du temps. WhyHow résout ce problème en créant de petits GCS et en itérant sur eux plusieurs fois jusqu'à ce qu'un GCS satisfaisant pour un domaine spécifique émerge. Cette approche permet de rendre les KG très spécifiques à un domaine, plus simples et plus faciles à utiliser, car les KG sont complexes.
WhyHow fournit également aux développeurs les éléments de base pour organiser, contextualiser et récupérer de manière fiable des données non structurées afin d'effectuer des RAG complexes. En intégrant WhyHow dans vos pipelines RAG existants alimentés par une base de données vectorielle, vous pouvez rendre votre système RAG plus structuré, plus cohérent et mieux contrôlé. Le diagramme ci-dessous montre comment fonctionne un RAG enrichi d'un graphe de connaissances.
Fig 3- Intégration de RAG avec WhyHow](https://assets.zilliz.com/Fig_3_Integration_of_RAG_with_Why_How_b893400b28.png)
Fig 3 : Intégration du RAG avec WhyHow
En intégrant WhyHow dans votre flux de travail RAG, vous pouvez adopter une approche hybride graphique et vectorielle en tirant parti du meilleur des graphes de connaissances et des capacités de recherche vectorielle offertes par les [bases de données vectorielles] (https://zilliz.com/learn/what-is-vector-database).
Pour un guide plus détaillé sur la façon de construire un RAG amélioré par un graphe de connaissances avec WhyHow, nous vous recommandons de regarder [la démo en direct] (https://www.youtube.com/watch?v=6pjObdJdyFs&list=PLPg7_faNDlT7SC3HxWShxKT-t-u7uKr--&index=3) partagée par Chris lors de la rencontre sur les données non structurées organisée par [Zilliz] (https://zilliz.com/).
Avoir plus de contrôle sur vos flux de recherche dans RAG en utilisant WhyHow et Zilliz Cloud
En plus de rendre les applications RAG plus performantes et traçables, de nombreux développeurs espèrent également avoir un meilleur contrôle sur ce que leur RAG récupère. En effet, les applications RAG ne parviennent pas toujours à récupérer les bons blocs de données lorsque les utilisateurs envoient des requêtes mal formulées ou lorsqu'ils ont besoin d'inclure dans leurs réponses des données contextuellement pertinentes mais sémantiquement différentes.
Pour résoudre ces problèmes, WhyHow construit un Rule-based Retrieval Package en intégrant Zilliz Cloud. Ce package Python permet aux développeurs de construire des flux de recherche plus précis avec des capacités de filtrage avancées, leur donnant plus de contrôle sur le flux de recherche dans les pipelines RAG. Ce paquetage s'intègre à OpenAI pour la génération de texte et à Zilliz Cloud pour le stockage et une recherche de similarité vectorielle efficace avec filtrage des métadonnées.
La solution de recherche basée sur des règles exécute ces tâches :
Création d'un magasin de vecteurs: Création d'une collection Milvus pour le stockage des chunk embeddings.
Splitting, Chunking, and Embedding: Divise, fragmente et crée automatiquement des embeddings pour les documents téléchargés en utilisant PyPDFLoader et RecursiveCharacterTextSplitter de LangChain, et prend en charge le modèle text-embedding-3-small d'OpenAI.
Insertion de données: Chargement des embeddings et des métadonnées vers Milvus ou Zilliz Cloud.
Filtrage automatique: Construit un filtre de métadonnées basé sur des règles définies par l'utilisateur pour affiner les requêtes dans le magasin de vecteurs.
Le flux de travail est le suivant :
![Comment WhyHow et Zilliz Cloud fonctionnent ensemble] (https://assets.zilliz.com/How_Why_How_and_Zilliz_Cloud_work_together_8510ecf053.png)
Fig 4 : Flux de travail de la solution de recherche basée sur des règles
Les données sources sont transformées en encastrements vectoriels à l'aide du modèle d'encastrement d'OpenAI et intégrées dans Zilliz Cloud pour le stockage et l'extraction. Lorsqu'une requête est faite par un utilisateur, elle est également transformée en encastrements vectoriels et envoyée à Zilliz Cloud pour rechercher les résultats les plus pertinents. WhyHow définit des règles et ajoute des filtres à la recherche vectorielle. Les résultats récupérés, ainsi que la requête originale de l'utilisateur, sont ensuite envoyés au LLM, qui génère des résultats plus précis et les envoie à l'utilisateur.
Conclusion
Les LLM nous ont vraiment facilité la tâche en nous aidant à trouver des réponses à divers problèmes. Ils sont suffisamment intelligents pour comprendre la requête fournie mais hallucinent, et il est difficile de les maintenir à jour en raison des contraintes de ressources. C'est pourquoi la technique de génération augmentée de recherche (RAG) leur donne plus de pouvoir en fournissant un contexte à la requête ; cependant, les systèmes RAG ont également des limites, comme nous l'avons vu.
WhyHow a identifié ces limites, en soulignant que la solution réside dans l'incorporation de graphes de connaissances dans les pipelines de RAG. En améliorant les RAG avec des graphes de connaissances, vos systèmes RAG peuvent récupérer des informations plus pertinentes et contextuelles et générer des réponses plus déterminables avec moins d'hallucinations et une grande précision.
Si vous souhaitez approfondir ce sujet, regardez [la présentation de Chris sur YouTube] (https://www.youtube.com/watch?v=6pjObdJdyFs).
Ressources complémentaires
Qu'est-ce que le RAG ? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Optimisation du RAG avec les Rerankers : le rôle et les compromis
Full RAG : une architecture moderne pour l'hyperpersonnalisation] (https://zilliz.com/blog/full-rag-modern-architecture-for-hyperpersonalization)
Construire des applications RAG intelligentes avec LangServe, LangGraph et Milvus
Construire un RAG avec Milvus et Snowpark Container Services auto-déployés
Exploration de DSPy et de son intégration avec Milvus pour créer des pipelines RAG très efficaces

Continuer à lire

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.