




Creación de RAG con Milvus, vLLM y Llama 3.1
La Universidad de California - Berkeley donó vLLM, una biblioteca rápida y fácil de usar para la inferencia y el servicio de LLM, a LF AI & Data Foundation como proyecto en fase de incubación en julio de 2024. Como proyecto miembro, nos gustaría dar la bienvenida a vLLM a la familia de LF AI & Data. 🎉
Los grandes modelos lingüísticos (LLMs) y las bases de datos vectoriales suelen emparejarse para construir la Generación Aumentada de Recuperación (RAG), una arquitectura de aplicación de IA popular para hacer frente a las Alucinaciones de IA. Este blog le mostrará cómo construir y ejecutar una RAG con Milvus, vLLM y Llama 3.1. Más concretamente, te mostraré cómo incrustar y almacenar información de texto como vector embeddings en Milvus y utilizar este almacén de vectores como base de conocimiento para recuperar de forma eficiente trozos de texto relevantes para las preguntas de los usuarios. Por último, aprovecharemos vLLM para utilizar el modelo Llama 3.1-8B de Meta para generar respuestas enriquecidas con el texto recuperado. ¡A trabajar!
Introducción a Milvus, vLLM y Meta's Llama 3.1
Base de datos vectorial Milvus
Milvus es una base de datos vectorial distribuida, de código abierto y creada específicamente para almacenar, indexar y buscar vectores para cargas de trabajo de Inteligencia Artificial Generativa (GenAI). Su capacidad para realizar búsquedas híbridas filtrado de metadatos, reordenación y gestión eficiente de billones de vectores convierte a Milvus en la elección perfecta para cargas de trabajo de IA y aprendizaje automático. Milvus puede ejecutarse localmente, en un clúster o alojarse en la Nube de Zilliz totalmente gestionada.
vLLM
vLLM es un proyecto de código abierto iniciado en UC Berkeley SkyLab centrado en optimizar el rendimiento del servicio LLM. Utiliza una gestión eficiente de la memoria con PagedAttention, batching continuo y kernels CUDA optimizados. En comparación con los métodos tradicionales, vLLM mejora el rendimiento del servicio hasta 24 veces y reduce el uso de memoria de la GPU a la mitad.
Según el artículo "Efficient Memory Management for Large Language Model Serving with PagedAttention", la caché de KV utiliza alrededor del 30% de la memoria de la GPU, lo que puede provocar problemas de memoria. La caché KV se almacena en memoria contigua, pero el cambio de tamaño puede provocar la fragmentación de la memoria, lo que resulta ineficiente para el cálculo.

Imagen 1. Gestión de la memoria caché KV en los sistemas existentes (2023 Paged Attention_ paper)
Al utilizar memoria virtual para la caché KV, vLLM sólo asigna memoria física de la GPU cuando es necesario, lo que elimina la fragmentación de la memoria y evita la preasignación. En las pruebas, vLLM superó a HuggingFace Transformers (HF) y Text Generation Inference (TGI), logrando hasta 24 veces más rendimiento que HF y 3,5 veces más que TGI en las GPU NVIDIA A10G y A100.
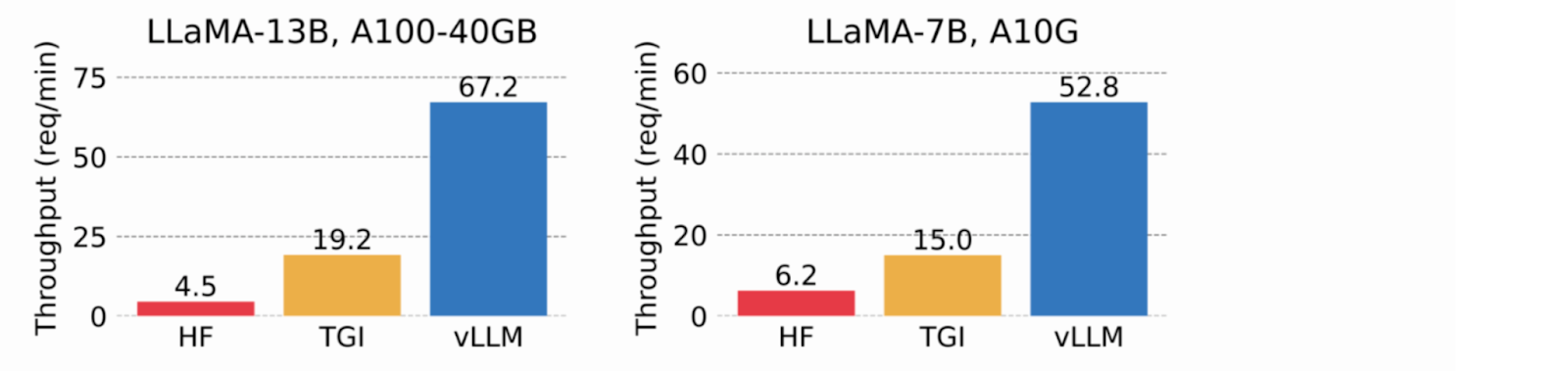
Imagen 2. vLLM alcanza un rendimiento 8,5x-15x superior al de HF y 3,3x-3,5x superior al de TGI (2023_ blog de vLLM_).
Llama de Meta 3.1
El 23 de julio de 2024 se anunció Meta's Llama 3.1. El modelo 405B ofrece un rendimiento de vanguardia en varias pruebas comparativas públicas y tiene una ventana de contexto de 128.000 tokens de entrada con varios usos comerciales permitidos. Junto con el modelo de 405.000 millones de parámetros, Meta lanzó una versión actualizada de Llama3 70B (70.000 millones de parámetros) y 8B (8.000 millones de parámetros). Los pesos del modelo pueden descargarse en el sitio web de Meta.
Una de las principales conclusiones fue que el ajuste de los datos generados puede aumentar el rendimiento, pero los ejemplos de mala calidad pueden degradarlo. El equipo de Llama trabajó intensamente para identificar y eliminar estos malos ejemplos utilizando el propio modelo, modelos auxiliares y otras herramientas.
Construir y realizar la recuperación RAG con Milvus
Prepare su conjunto de datos
He utilizado la documentación oficial de Milvus como conjunto de datos para esta demostración, que he descargado y guardado localmente.
from langchain.document_loaders import DirectoryLoader
# Cargar archivos HTML ya guardados en un directorio local
path = "../../RAG/rtdocs_new/"
global_pattern = '*.html'
loader = DirectoryLoader(ruta=ruta, glob=patrón_global)
docs = loader.load()
# Imprimir documentos numéricos y una vista previa.
print(f "cargados {len(docs)} documentos")
print(docs[0].contenido_página)
pprint.pprint(docs[0].metadata)
cargado 22 docs](https://assets.zilliz.com/loaded_22_docs_03edd158e2.png)
Descargar un modelo de incrustación
A continuación, descarga un modelo de incrustación gratuito y de código abierto de HuggingFace.
importar torch
de sentence_transformers import SentenceTransformer
# Inicializar la configuración de torch para código agnóstico de dispositivo.
N_GPU = torch.cuda.device_count()
DEVICE = torch.device('cuda:N_GPU' if torch.cuda.is_available() else 'cpu')
# Descarga el modelo desde el hub de modelos huggingface.
model_name = "BAAI/bge-large-es-v1.5"
encoder = SentenceTransformer(nombre_modelo, dispositivo=DEVICE)
# Obtener los parámetros del modelo y guardarlos para más tarde.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Inspeccionar los parámetros del modelo.
print(f "nombre_modelo: {nombre_modelo}")
print(f "EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f "LONGITUD_SEQ_MAX: {LONGITUD_SEQ_MAX}")

Trocea y codifica tus datos personalizados como vectores.
Usaré una longitud fija de 512 caracteres con un solapamiento del 10%.
from langchain.separador_texto import Separador_texto_caracteres_recursivo
TAMAÑO_TROZO = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f "chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# Definir el divisor.
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=chunk_overlap)
# Trocea los documentos.
chunks = child_splitter.split_documents(docs)
print(f"{len(docs)} documentos divididos en {len(chunks)} documentos hijos.")
# La entrada del codificador es doc.page_content como cadenas.
list_of_strings = [doc.page_content for doc in chunks if hasattr(doc, 'page_content')].
# Inferencia de incrustación utilizando el codificador HuggingFace.
embeddings = torch.tensor(encoder.encode(list_of_strings))
# Normaliza las incrustaciones.
embeddings = np.array(embeddings / np.linalg.norm(embeddings))
# Milvus espera una lista de `numpy.ndarray` de números `numpy.float32`.
valores_convertidos = list(map(np.float32, embeddings))
# Crear dict_list para inserción Milvus.
dict_list = []
for chunk, vector in zip(chunks, valores_convertidos):
# Ensamblar vector de inserción, trozo de texto original, metadatos.
chunk_dict = {
'chunk': chunk.page_content,
'fuente': chunk.metadata.get('fuente', ""),
'vector': vector,
}
dict_list.append(chunk_dict)

Guardar los vectores en Milvus
Ingesta la incrustación del vector codificado en la base de datos de vectores Milvus.
# Conectar un cliente al servidor Milvus Lite.
from pymilvus import MilvusClient
mc = MilvusClient("milvus_demo.db")
# Crear una colección con esquema flexible y AUTOINDEX.
NOMBRE_COLECCIÓN = "MilvusDocs"
mc.create_collection(NOMBRE_COLECCIÓN,
EMBEDDING_DIM,
consistency_level="Eventually",
auto_id=True,
overwrite=True)
# Insertar datos en la colección Milvus.
print("Empezar a insertar entidades")
start_time = time.time()
mc.insert(
NOMBRE_COLECCION,
data=lista_dict,
barra_progreso=True)
end_time = time.time()
print(f "Milvus insertar tiempo para {len(dict_list)} vectores: ", end="")
print(f"{round(hora_fin - hora_inicio, 2)} segundos")

Realizar una búsqueda vectorial
Formule una pregunta y busque los trozos vecinos más cercanos de su base de conocimientos en Milvus.
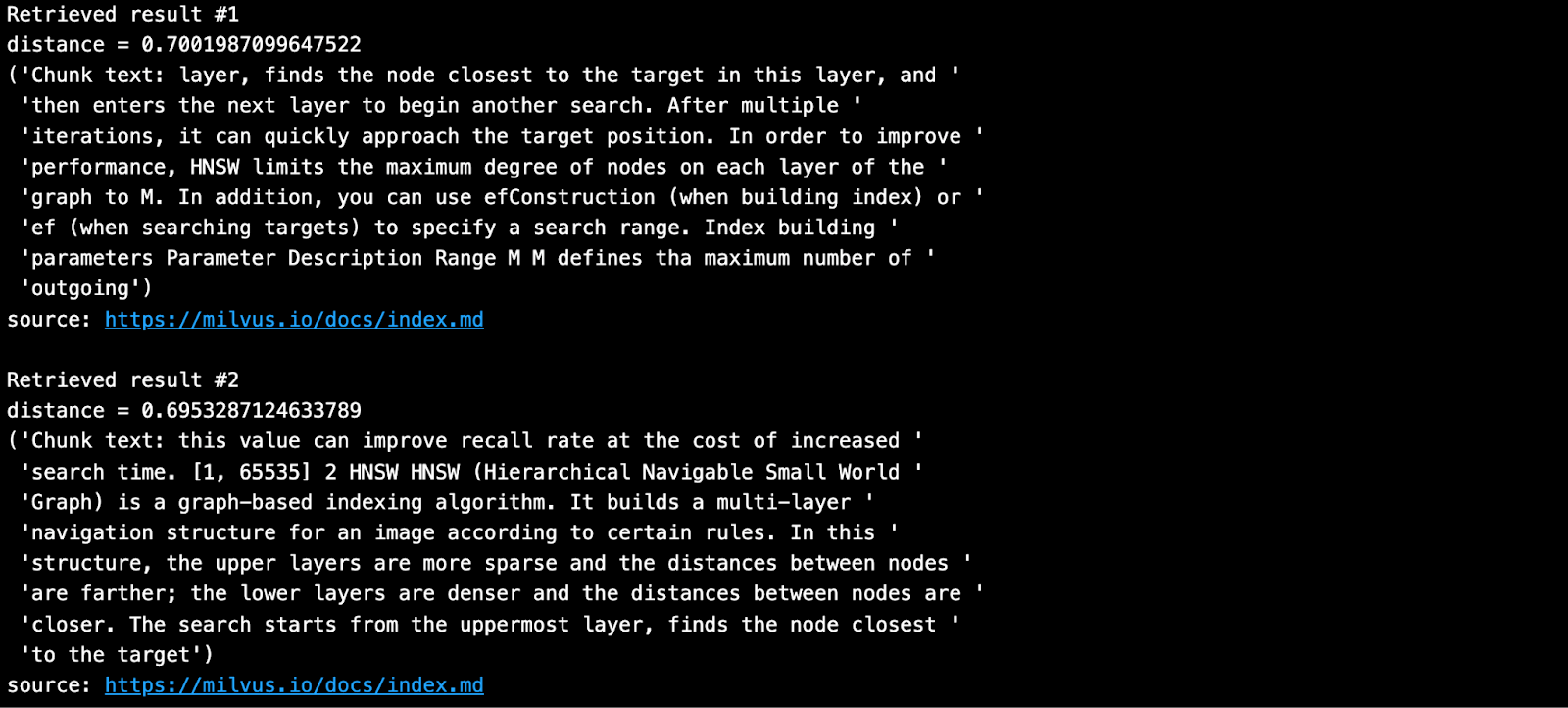
SAMPLE_QUESTION = "¿Qué significan los parámetros para HNSW?"
# Incrusta la pregunta usando el mismo codificador.
query_embeddings = torch.tensor(encoder.encode(SAMPLE_QUESTION))
# Normaliza las incrustaciones a longitud unitaria.
query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
# Convertir las incrustaciones a lista de lista de np.float32.
query_embeddings = list(map(np.float32, query_embeddings))
# Definir los campos de metadatos sobre los que se puede filtrar.
OUTPUT_FIELDS = list(dict_list[0].keys())
OUTPUT_FIELDS.remove('vector')
# Define cuántos resultados top-k quieres recuperar.
TOP_K = 2
# Ejecute la búsqueda semántica de vectores utilizando su consulta y la base de datos de vectores.
resultados = mc.search(
NOMBRE_COLECCIÓN,
data=consulta_embeddings,
campos_salida=campos_salida,
limit=TOP_K,
nivel_consistencia="Eventualmente")
El resultado obtenido es el que se muestra a continuación.
Construir y realizar la generación RAG con vLLM y Llama 3.1-8B
Instalar vLLM y los modelos de HuggingFace
vLLM descarga por defecto grandes modelos lingüísticos de HuggingFace. En general, cada vez que desee utilizar un modelo nuevo en HuggingFace, debe hacer un pip install--update o -U. Además, necesitará una GPU para ejecutar la inferencia de los modelos Llama 3.1 de Meta con vLLM.
Para obtener una lista completa de todos los modelos compatibles con vLLM, consulte esta página de documentación.
# (Recomendado) Crea un nuevo entorno conda.
conda create -n myenv python=3.11 -y
conda activate myenv
# Instalar vLLM con CUDA 12.1.
pip install -U vllm transformers torch
import vllm, torch
from vllm import LLM, SamplingParams
# Borra la caché de memoria de la GPU.
torch.cuda.empty_cache()
# Comprueba la GPU.
!nvidia-smi
Para obtener más información sobre cómo instalar vLLM, consulte su página installation.
Obtener un token HuggingFace
Algunos modelos en HuggingFace, como Meta Llama 3.1, requieren que el usuario acepte su licencia antes de poder descargar los pesos. Por lo tanto, debe crear una cuenta en HuggingFace, aceptar la licencia del modelo y generar un token.
Al visitar esta página Llama3.1 en HuggingFace, aparecerá un mensaje pidiéndote que aceptes los términos. Haz clic en "Aceptar licencia" para aceptar los términos de Meta antes de descargar los pesos del modelo. La aprobación suele tardar menos de un día.
Después de recibir la aprobación, debes generar un nuevo token HuggingFace. Tus antiguos tokens no funcionarán con los nuevos permisos.
Antes de instalar vLLM, inicia sesión en HuggingFace con tu nuevo token. A continuación, he utilizado Colab secrets para almacenar el token.
# Inicia sesión en HuggingFace usando tu nuevo token.
from huggingface_hub import login
from google.colab import userdata
hf_token = userdata.get('HF_TOKEN')
login(token = hf_token, add_to_git_credential=True)
Ejecutar la generación RAG
En la demo, ejecutamos el modelo Llama-3.1-8B, que requiere GPU y memoria considerable para girar. El siguiente ejemplo se ejecutó en Google Colab Pro (10$/mes) con una GPU A100. Para obtener más información sobre cómo ejecutar vLLM, puedes consultar la Documentación de inicio rápido.
# 1. Elija un modelo
MODELTORUN = "meta-llama/Meta-Llama-3.1-8B-Instruct"
# 2. Borra la caché de memoria de la GPU, ¡vas a necesitarla toda!
torch.cuda.empty_cache()
# 3. Instanciar una instancia del modelo vLLM.
llm = LLM(model=MODELTORUN,
enforce_eager=True,
dtype=torch.bfloat16,
gpu_memory_utilization=0.5,
max_model_len=1000,
seed=415,
max_num_batched_tokens=3000)

Escriba un aviso utilizando contextos y fuentes recuperados de Milvus.
# Separa todos los contextos juntos por espacio.
contextos_combinados = ' '.join(contextos)
# Lance Martin, LangChain, dice que pongas los mejores contextos al final.
contextos_combinados = ' '.join(reversed(contexts))
# Separa todas las fuentes únicas juntas por coma.
fuente_combinada = ' '.join(reversed(list(dict.fromkeys(fuentes))))
SYSTEM_PROMPT = f"""Primero, comprueba si el Contexto proporcionado es relevante para la pregunta del usuario.
la pregunta del usuario. En segundo lugar, sólo si el Contexto proporcionado es muy relevante, responda a la pregunta utilizando el Contexto. De lo contrario, si el contexto no es muy relevante, responde a la pregunta sin utilizarlo.
Sea claro, conciso y pertinente. Responde con claridad, en menos de 2 frases.
Fuentes de información: {fuente_combinada}
Contexto: {contextos_combinados}
Pregunta del usuario: {SAMPLE_QUESTION}
"""
prompts = [SYSTEM_PROMPT]
Ahora, genera una respuesta usando los trozos recuperados y la pregunta original rellenada en el prompt.
# Parámetros de muestreo
sampling_params = SamplingParams(temperature=0.2, top_p=0.95)
# Invocar el modelo vLLM.
outputs = llm.generate(prompts, sampling_params)
# Imprime los resultados.
para salida en salidas:
pregunta = pregunta.salida
texto_generado = salida.salidas[0].texto
# !r llama a repr(), que imprime una cadena entre comillas.
imprimir()
print(f "Pregunta: {SAMPLE_QUESTION!r}")
pprint.pprint(f "Texto generado: {texto_generado!r}")

La respuesta anterior me parece perfecta.
Si estás interesado en esta demo, no dudes en probarla por ti mismo y hacernos saber tu opinión. También puedes unirte a nuestra comunidad Milvus en Discord para conversar directamente con todos los desarrolladores de GenAI.
Referencias
2023 vLLM paper on Paged Attention](https://arxiv.org/pdf/2309.06180)
Presentación de 2023 vLLM](https://www.youtube.com/watch?v=80bIUggRJf4) en la Cumbre Ray
Blog de vLLM: vLLM: Servicio LLM fácil, rápido y barato con PagedAttention
Blog útil sobre la ejecución del servidor vLLM: Despliegue de vLLM: guía paso a paso
La manada de modelos Llama 3 | Investigación - AI en Meta](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/)

Sigue leyendo

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.