




Milvus 2.4 presenta CAGRA: mejora de la búsqueda vectorial con indexación de última generación en la GPU
¿Qué es un índice basado en la GPU?
La búsqueda vectorial es intrínsecamente computacional. Milvus se sitúa a la vanguardia como la base de datos vectorial de mayor rendimiento y destina más del 80% de sus recursos computacionales a sus bases de datos vectoriales y su motor de búsqueda, Knowhere. Dadas las exigencias computacionales de la informática de alto rendimiento, las GPU se perfilan como un elemento fundamental de nuestra plataforma de bases de datos vectoriales, especialmente en el ámbito de la búsqueda vectorial.
Milvus sentó un precedente al convertirse en la primera base de datos vectorial en aprovechar la aceleración de la GPU con su Milvus versión 1.1 en 2021. En la versión 2.3, al aprovechar la biblioteca RAFT de NVIDIA para la búsqueda vectorial, Milvus introdujo índices acelerados en la GPU e integración con el marco de recomendación NVIDIA Merlin (utilizado para crear sistemas de recomendación). La introducción de los índices IVFFLAT e IVFPQ en esta versión supuso notables mejoras de rendimiento.
A pesar de estos avances, persisten retos como la optimización del rendimiento de las consultas de lotes pequeños y la mejora de la rentabilidad de los índices basados en GPU, lo que obliga a seguir explorando soluciones innovadoras. El giro de la industria hacia los [algoritmos de búsqueda vectorial] basados en grafos (https://zilliz.com/learn/popular-machine-learning-algorithms-behind-vector-search), reconocidos por su mayor rendimiento frente a los métodos basados en FIV, supone una evolución fundamental. Sin embargo, la adaptación de estos algoritmos a las GPU no es sencilla debido a sus patrones de ejecución secuencial y acceso aleatorio a la memoria, lo que dificulta la implementación eficiente en la GPU de algoritmos como GGNN y SONG.
Para resolver estos problemas, la última innovación de NVIDIA, el índice de grafos basado en la GPU CAGRA, representa un hito importante. Con la ayuda de NVIDIA, Milvus ha integrado soporte para CAGRA en su versión 2.4, lo que supone un importante paso adelante en la superación de los obstáculos que dificultan la implementación eficiente de la GPU en la búsqueda vectorial.
¿Qué es CAGRA?
Construir CAGRA
CAGRA (CUDA Anns GRAph-based) introduce un nuevo enfoque para la construcción de grafos que difiere del método iterativo de inserción-actualización utilizado por los grafos de mundos pequeños navegables jerárquicos (HNSW) en las CPU. Este cambio aborda el reto de aprovechar al máximo las capacidades de construcción de grafos altamente paralelas de las GPU, que el proceso de construcción de HNSW basado en CPU no aprovecha. CAGRA comienza creando un grafo inicial utilizando IVFPQ o NN-DESCENT, en el que cada nodo está conectado a numerosos vecinos. Los siguientes pasos consisten en ordenar estas conexiones por importancia, podar las aristas menos críticas y fusionar los grafos dirigidos para finalizar la estructura y construir un grafo inicial. En el grafo inicial, cada nodo tiene un gran número de nodos vecinos. A continuación, CAGRA ordena todas las aristas adyacentes según su importancia basándose en el grafo inicial y poda las aristas sin importancia.
Proceso de construcción de CAGRA](https://assets.zilliz.com/The_build_process_of_CAGRA_45e00eb1c0.png)
Construcción inicial del gráfico
IVFPQ
En el modo IVFPQ, CAGRA aprovecha el conjunto de datos para construir un índice IVFPQ, utilizando la característica de cuantificación del índice Product Quantization (PQ) para minimizar el uso de memoria de vídeo. Tras la creación de este índice, CAGRA realiza una búsqueda para cada punto del conjunto de datos, utilizando los vecinos más cercanos aproximados identificados por el índice IVFPQ como búsqueda de vecinos más cercanos de puntos adyacentes. Este proceso constituye la base para construir el gráfico inicial, garantizando una configuración eficiente sin ocupar demasiada memoria de forma significativa.
NN-DESCENT
CAGRA emplea el algoritmo NN-DESCENT para otro enfoque de la construcción del grafo inicial, que implica los siguientes pasos detallados:
Inicialización: Seleccionar aleatoriamente k puntos del conjunto de datos v para crear la lista de adyacencia inicial B[v].
2. Reversión y fusión: Tomar la inversa de B[v] para generar la lista de adyacencia invertida R[v], y luego fusionar la B y R para formar H[v].
Para cualquier nodo v en el conjunto de datos, identificar todos los vecinos de los vecinos sobre la base de H[v], la selección de la más cercana topk** nodos como sus nuevos vecinos.
Iteración: Repetir el proceso de Reversión y Fusión y Ampliación de Vecinos hasta que B se estabilice y ya no cambie o hasta que se alcance un umbral de iteración preestablecido.
En comparación con HNSW, NN-Descent ofrece una paralelización más sencilla y una menor interacción de datos entre tareas, lo que aumenta significativamente el tiempo de construcción del grafo y la eficiencia del grafo de adyacencia CAGRA en GPU. Sin embargo, debe tenerse en cuenta que la calidad inicial del grafo en NN-DESCENT puede quedar ligeramente por detrás de la conseguida con el modo IVFPQ.
Optimización de CAGRA
La estrategia de optimización de grafos de CAGRA se basa en dos supuestos principales:
**Para determinar la importancia de las aristas, se da preferencia a la ordenación basada en la trayectoria frente a la ordenación tradicional basada en la distancia. Este método sostiene que la conectividad de los grafos no tiene por qué beneficiarse de la clasificación por importancia basada en la distancia.
2. Fusión de grafos inversos: La estrategia de fusión de grafos inversos se basa en el principio de que un nodo que se considera importante para uno también puede serlo para el otro.
El proceso de optimización incluye dos pasos principales:
- Inicialmente, se asigna a las aristas adyacentes de cada nodo distintos pesos ('w')** en función de la distancia. CAGRA emplea una estrategia de poda en la que las aristas se cortan si conectan nodos que son más "detectables", basándose en la condición "max(w_{x a z},w_{z a y}) < w_{x a y}". Esto se centra en eliminar las conexiones menos críticas para racionalizar el grafo.
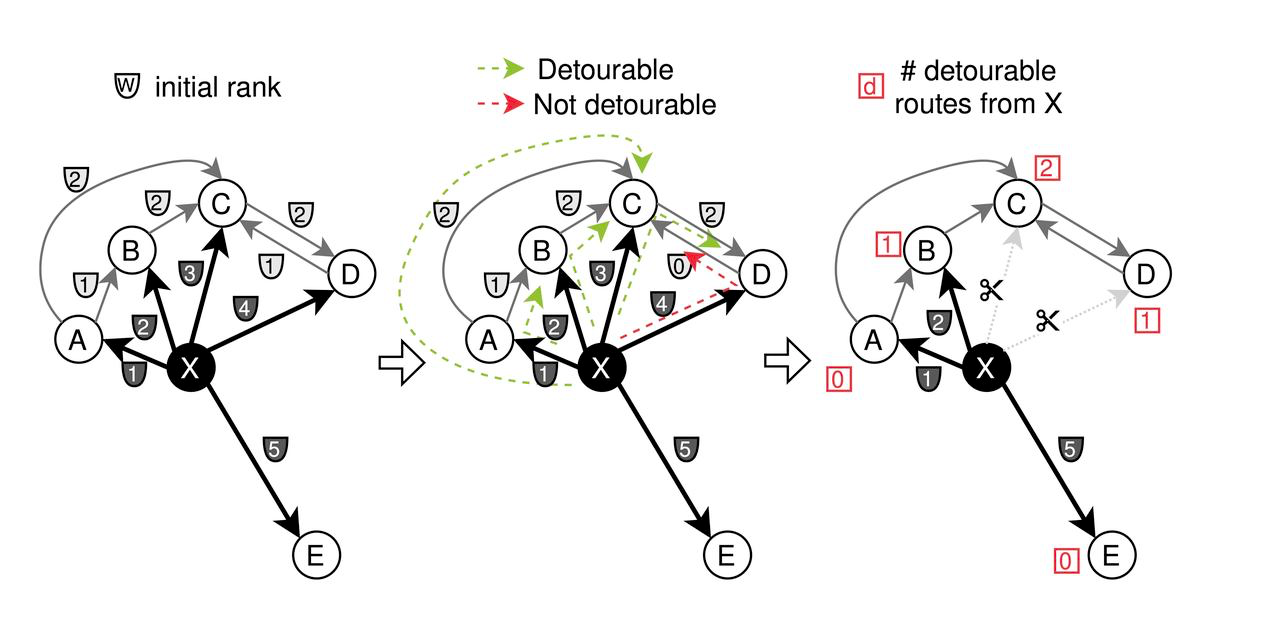 Proceso de poda para la optimización de CAGRA
Proceso de poda para la optimización de CAGRA
- Fusión: Después de podar el gráfico anterior basándose en la importancia de la ruta, las aristas se invierten y se fusionan. Específicamente, la mitad de las aristas son seleccionadas de ambos grafos para crear el grafo final optimizado CAGRA.
Este detallado método de construcción y optimización del grafo garantiza la eficiencia y eficacia de CAGRA en las operaciones de búsqueda vectorial, aprovechando las capacidades únicas de las GPU y resolviendo los problemas inherentes a los algoritmos de búsqueda basados en grafos.
Búsqueda con CAGRA
El mecanismo de búsqueda de CAGRA emplea un enfoque metódico que utiliza una cola de prioridad ordenada de tamaño fijo para lograr una navegación eficiente por el grafo. Este proceso detallado se describe mediante una serie de pasos dentro de un marco estructurado:
Marco de búsqueda CAGRA
CAGRA funciona con un búfer de memoria secuencial compuesto por una lista interna Top-M y una lista de candidatos. La lista top-M interna actúa como una cola de prioridad, con una longitud fijada en M (donde M ≥ k), lo que garantiza que pueda almacenar los resultados más relevantes hasta el número deseado de vecinos más cercanos, k. El tamaño de la lista de candidatos viene determinado por p × d, donde p representa el número de nodos fuente explorados en cada iteración y d indica el grado del grafo. Cada elemento de estas listas empareja un índice de nodo con la distancia a la consulta, lo que permite una gestión eficaz de la búsqueda.
Proceso de búsqueda CAGRA](https://assets.zilliz.com/CAGRA_Search_Process_bf88c0e30d.png)
Pasos del proceso de búsqueda
- Muestreo aleatorio (Inicialización)
- Utiliza un generador pseudoaleatorio para seleccionar p × d índices de nodos aleatorios, calculando la distancia entre cada nodo y la consulta.
- Los resultados pueblan la lista de candidatos, mientras que la lista top-M interna se inicializa con entradas virtuales (ajustadas a FLT_MAX) para evitar influir en los resultados iniciales de la ordenación.
- Actualización de la lista Top-M interna: Selecciona los nodos Top-M basados en las distancias más pequeñas de todo el buffer para incluirlos en la lista Top-M interna.
Actualización del índice de la lista de candidatos (Graph Traversal):
- Identifica todos los nodos vecinos de los p nodos superiores de la lista top-M interna, excluyendo los nodos utilizados previamente mediante un filtro de tabla hash.
- Añade estos vecinos a la lista de candidatos sin recalcular distancias en esta etapa.
- **Cálculo de distancias
- Realiza cálculos de distancia para los nodos que aparecen por primera vez en la lista de candidatos, evitando cálculos redundantes para los nodos evaluados en iteraciones anteriores.
- Garantiza que los nodos sólo se añadan a la lista top-M si sus distancias justifican su relevancia, basándose en si son lo suficientemente pequeños para pertenecer a ella o demasiado grandes para ser considerados.
El algoritmo procesa iterativamente estos pasos, recorriendo todos los nodos de la lista top-M interna hasta que todos han servido como puntos de partida para la búsqueda. La búsqueda concluye extrayendo las k entradas más importantes de la lista top-M interna, obteniendo los resultados de la búsqueda Approximate Nearest Neighbor Search (ANNS).
Rendimiento
La decisión de aprovechar los índices de la GPU estuvo motivada principalmente por consideraciones de rendimiento. Llevamos a cabo una evaluación exhaustiva del rendimiento de Milvus utilizando una herramienta de evaluación comparativa base de datos vectorial de código abierto, centrándonos en las comparaciones entre los índices HNSW, IVFFLAT basado en GPU y CAGRA.
Configuración de pruebas comparativas
Para realizar una evaluación realista, nuestras pruebas se llevaron a cabo en máquinas alojadas en AWS equipadas con GPU NVIDIA T4 y A10G, garantizando que los entornos de prueba reflejaran los recursos disponibles habitualmente. Las máquinas seleccionadas tenían precios comparables, lo que proporcionó igualdad de condiciones para la evaluación del rendimiento. El objetivo de todas las pruebas era alcanzar el 100 %@98 % de recuperación, utilizando una instancia de AWS m6i.4xlarge (16C64G) como cliente.
Información básica de la máquina seleccionada](https://assets.zilliz.com/Basic_Info_for_Selected_Machine_2fb7d5556e.png)
Información sobre el rendimiento
**Rendimiento de lotes pequeños
En situaciones con lotes de búsqueda pequeños (tamaño de lote de 1), en las que las GPU suelen estar infrautilizadas, CAGRA superó con creces a sus homólogos. Nuestras pruebas revelaron que CAGRA podía ofrecer casi 10 veces más rendimiento que los métodos tradicionales en estas condiciones.
Comparación del rendimiento del conjunto de datos de lotes pequeños](https://assets.zilliz.com/Performance_Comparison_for_Small_Batch_Data_Set_b9bcc9f26e.png)
**Rendimiento de lotes grandes
Al examinar lotes de búsqueda más grandes (tamaños de 10 y 100), la ventaja de CAGRA se hizo aún más pronunciada. Frente a HNSW, CAGRA mostró un aumento espectacular del rendimiento, mejorando la eficiencia de la búsqueda en decenas de veces.
Comparación del rendimiento de un conjunto de datos de gran tamaño](https://assets.zilliz.com/Performance_Comparison_for_Large_Batch_Data_Set_ef371476c6.png)
Eficacia de la construcción de índices:
Además de las funciones de búsqueda, CAGRA también es capaz de construir índices. Gracias a la aceleración en la GPU, CAGRA ha demostrado ser capaz de construir índices aproximadamente 10 veces más rápido que otros métodos alternativos.
Comparación del rendimiento en la creación de índices](https://assets.zilliz.com/Performance_Comparison_for_Index_Building_2368e7a64e.png)
Los resultados de las pruebas de rendimiento ponen de manifiesto las sustanciales ventajas de adoptar índices acelerados en la GPU como CAGRA en Milvus. No sólo acelera las tareas de búsqueda en todos los tamaños de lote, sino que también mejora significativamente la velocidad de construcción de índices, lo que confirma el valor de las GPU para optimizar el rendimiento de las bases de datos vectoriales.
¿Y ahora qué?
CAGRA supone un importante salto adelante en nuestro empeño por redefinir los límites de la búsqueda vectorial y demostrar el potencial de la búsqueda basada en la GPU para afrontar los retos de producción más exigentes. A medida que avanzamos, Milvus se propone profundizar en los aspectos de alta recuperación, baja latencia, eficiencia de costes y escalabilidad en la búsqueda vectorial. Nuestro compromiso va más allá de los logros actuales para abarcar una gestión de datos más flexible, capacidades de búsqueda enriquecidas y optimizaciones de rendimiento revolucionarias.
Esta visión nos impulsa a innovar continuamente, garantizando que Milvus lidere y sea pionera en el futuro de la búsqueda acelerada de datos no estructurados. Al superar los límites de lo que es posible hoy, nuestro objetivo es abrir nuevas posibilidades para el mañana, haciendo que la búsqueda vectorial sea más potente, eficiente y accesible.
Trucos y consejos prácticos para desarrolladores que utilizan bases de datos vectoriales.png](https://assets.zilliz.com/Practical_Tips_and_Tricks_for_Developers_Using_Vector_Databases_a923000a3c.png) ¿No está seguro de qué índice elegir para su solución? Tenemos un blog que le ayudará a tomar la decisión correcta.

Sigue leyendo

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.

Vector Databases vs. Hierarchical Databases
Use a vector database for AI-powered similarity search; use a hierarchical database for organizing data in parent-child relationships with efficient top-down access patterns.