




Cómo Zilliz terminó en el centro de la historia de datos no estructurados de NVIDIA en GTC 2026
En NVIDIA GTC este año, en medio de la avalancha habitual de afirmaciones sobre chips, sistemas e infraestructura, Jensen Huang mostró una diapositiva que importaba por una razón diferente.
No trataba sobre la próxima GPU. No trataba sobre el tamaño de los modelos. Ni siquiera trataba realmente sobre la inferencia.
Trataba sobre los datos.
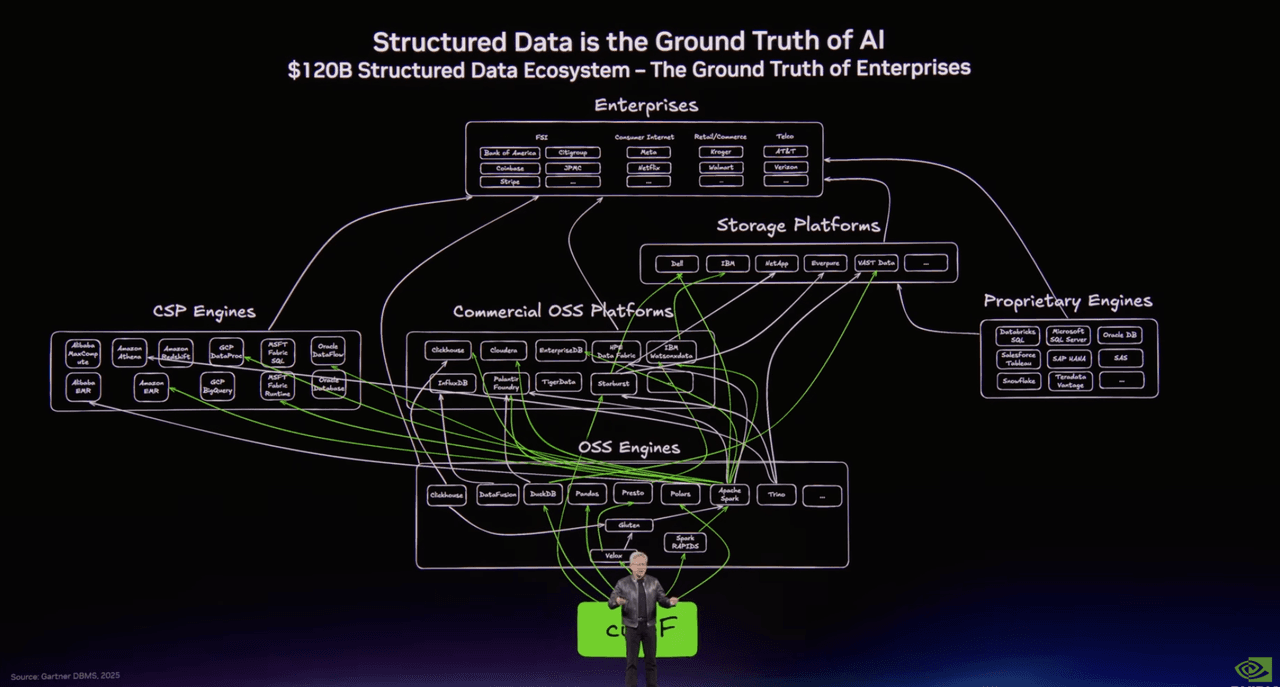
Una diapositiva trazaba el mundo de los datos estructurados: Spark, Presto, DuckDB, Polars, Snowflake, Databricks, BigQuery, la maquinaria familiar que ha impulsado la analítica y la ingeniería de datos durante décadas.
Otra trazaba la pila emergente para datos no estructurados. Y allí, en medio de esa segunda imagen, aparecían Milvus en código abierto y Zilliz Cloud en la capa de base de datos empresarial.

El título de la diapositiva lo decía todo: Los datos no estructurados son el contexto de la IA.
Es fácil asentir ante esa frase. Por supuesto, la IA necesita contexto. Por supuesto, la mayoría de los datos empresariales son no estructurados. Por supuesto, el texto, las imágenes, el video, el audio, los registros, los PDF y todo lo demás importan ahora más que nunca. Pero una vez que se supera el eslogan, aparece una pregunta más difícil: si los datos no estructurados se están convirtiendo en el sustrato real de los sistemas de IA, ¿cómo es realmente la infraestructura para ese mundo?
Esa es la historia más interesante. Y es la razón por la que Milvus ha pasado de ser una base de datos vectorial especializada a ocupar una posición mucho más estratégica en la pila de IA.
Por qué Zilliz (Milvus) sigue apareciendo
Esta no fue la primera vez que Zilliz apareció en GTC, y probablemente no será la última.
Mucho antes de que las bases de datos vectoriales se convirtieran en un bloque de construcción predeterminado en los sistemas modernos de IA, Milvus se construyó en torno a la idea de que la búsqueda por similitud tendría que operar a una escala muy diferente a la de las bases de datos tradicionales. La aceleración por GPU no fue una idea añadida posteriormente. Formó parte de la lógica de diseño desde el principio.
Eso importó cuando la IA dejó de ser una historia de investigación y se convirtió en una historia de infraestructura.
En GTC 2023, Jensen Huang ya destacaba la integración más profunda entre las bibliotecas de aceleración de NVIDIA y sistemas como FAISS, Redis y Milvus. Un año después, en GTC 2024, esa relación se volvió más concreta con Milvus 2.4, que incorporó aceleración completa por GPU al indexado y la búsqueda vectorial al combinar GPUs de NVIDIA con CAGRA de RAPIDS cuVS. El resultado no fue una mejora de velocidad cosmética. En algunos escenarios de referencia, el rendimiento de búsqueda mejoró hasta 50 veces respecto a HNSW.
Para cuando llegó Milvus 2.6, la conversación había vuelto a evolucionar. La pregunta ya no era si la aceleración por GPU importaba. Era cómo utilizarla de forma rentable. Milvus 2.6 introdujo patrones de implementación más flexibles para CAGRA, incluidas arquitecturas híbridas GPU-CPU que usan la GPU para la construcción del grafo y la CPU para la recuperación. Eso importa porque la mayoría de las empresas no quieren el sistema más rápido posible a cualquier precio. Quieren un sistema que siga siendo lo suficientemente rápido sin dejar de ser económicamente sensato.
Vale la pena detenerse en ese detalle, porque dice algo más amplio sobre por qué Milvus se ha vuelto importante. Esta no es solo una historia sobre el rendimiento de la búsqueda vectorial. Es una historia sobre lo que ocurre cuando la recuperación vectorial deja de ser una función experimental y pasa a formar parte de la infraestructura de producción.
Qué se necesita para que la búsqueda vectorial funcione en producción
La velocidad por sí sola deja de ser la historia.
Pero una vez que la recuperación vectorial sale de las demos y entra en sistemas reales, la velocidad por sí sola deja de ser la historia.
La pregunta más difícil es qué se necesita para que la recuperación sea práctica a escala empresarial, sin convertir la pila circundante en un caos de pipelines frágiles, alta presión de memoria y costes de infraestructura crecientes.
Parte de ese desafío empieza aguas arriba. En el modelo anterior, convertir un PDF, una imagen o un documento en algo buscable normalmente implicaba unir una capa de análisis separada, lógica de fragmentación, servicios de embedding y escrituras en la base de datos. El sistema de recuperación solo empezaba a funcionar después de que una larga cadena de preprocesamiento ya hubiera completado su trabajo. Milvus 2.6 empezó a difuminar esa frontera con un enfoque Data-in, Data-out, permitiendo que el contenido sin procesar se escribiera directamente en el sistema y se incrustara dentro de la propia base de datos.
Parte de ello se encuentra dentro de la capa de recuperación. Diferentes cargas de trabajo requieren diferentes compensaciones, así que admite múltiples tipos de índices en lugar de imponer una única estrategia de recuperación a cada caso de uso. La compresión también pasa a formar parte de la ecuación. Funciones como Int8 y RaBitQ no son añadidos llamativos, pero abordan un objetivo más importante: reducir la presión de memoria y los costes sin sacrificar la calidad de la recuperación.
Y parte de ello es simplemente operacional. Milvus introdujo una arquitectura rediseñada de registro de escritura anticipada que eliminó la necesidad de Kafka y Pulsar de la pila, reduciendo tanto la complejidad como la sobrecarga. Ese tipo de ingeniería rara vez acapara titulares, pero es exactamente la que determina si la infraestructura sigue siendo interesante en teoría o se vuelve utilizable en la práctica.
El almacenamiento resulta ser otra línea de falla.
A medida que los sistemas de IA crecen, también lo hace el coste de fingir que todos los datos deben tratarse de la misma manera, todo el tiempo. En una gran plataforma multiinquilino, solo una pequeña parte de los datos puede estar realmente activa en un día determinado. La mayor parte permanece fría. Pero las arquitecturas tradicionales de carga completa siguen tratando todo como si mereciera la misma residencia local, la misma postura de rendimiento y la misma huella de coste.
A pequeña escala, eso parece ineficiente. A escala empresarial, se vuelve difícil de justificar.
Milvus 2.6 abordó eso con almacenamiento por niveles. Los datos calientes permanecen locales, donde la latencia importa. Los datos fríos se cargan bajo demanda desde almacenamiento de objetos de menor coste. Y la frontera entre ambos cambia dinámicamente a medida que el sistema se usa realmente. Eso suena como una modesta optimización de sistemas. En la práctica, cambia la economía de la recuperación. Cuando los datos adecuados viven en el nivel adecuado, los costes de almacenamiento pueden caer más de un 70 por ciento.
Nada de esto es especialmente glamuroso. Pero así es normalmente como madura la infraestructura: no mediante un único avance espectacular, sino a través de una serie de decisiones de diseño que hacen que el sistema sea más rápido, más barato y más fácil de convivir con él.
Y todas estas funciones han estado disponibles en Zilliz Cloud, el servicio totalmente gestionado de Milvus.
El verdadero problema con los datos no estructurados
Sin embargo, el cambio más grande no tiene que ver realmente solo con Milvus. Tiene que ver con el tipo de datos del que ahora dependen los sistemas de IA.
Los datos estructurados evolucionaron de forma larga y ordenada. Filas, columnas, esquemas, índices, almacenes de datos, motores de consulta. Las herramientas maduraron durante décadas porque los datos en sí encajaban con los supuestos sobre los que se construyeron esos sistemas. Sabías cómo era un registro. Sabías qué campos consultar. Sabías cómo indexarlos.
Los datos no estructurados rompen ese modelo.
Un contrato no es una fila. Tampoco lo es una imagen médica, una transcripción de soporte, un repositorio de código o una transmisión de vigilancia. Estos objetos pueden almacenarse, pero almacenarlos es la parte fácil. La parte difícil es hacerlos buscables de una manera que entienda el significado en lugar de coincidencias exactas de campos.
Por eso los embeddings lo cambiaron todo. Una vez que el texto, las imágenes, el audio y otras formas de contenido pudieron mapearse en un espacio vectorial de alta dimensión, la recuperación ya no tuvo que depender de la coincidencia simbólica exacta. Los sistemas podían recuperar por similitud, intención y contexto.
Ese fue el avance.
También fue el comienzo de un nuevo problema de infraestructura.
Una vez que los datos no estructurados se vuelven consultables, las empresas se enfrentan de inmediato a la economía de escala. Millones de documentos se convierten en cientos de millones de embeddings. Una actualización del modelo significa volver a generar embeddings para el corpus histórico. La calidad de la recuperación depende de la calidad del índice. La latencia importa en producción. También el costo de almacenamiento. También la carga operativa de mantener todo esto sincronizado.
En otras palabras, la recuperación semántica resolvió el problema de acceso, pero expuso el problema de sistemas.
Ese es el contexto en el que Milvus tiene sentido.
Por qué una base de datos vectorial no fue suficiente
Para la primera ola de empresas nativas de IA, la respuesta era sencilla: usar una base de datos vectorial como capa de recuperación, conectarla a un modelo y construir la aplicación a partir de ahí. Ese modelo funcionó, y todavía funciona, especialmente cuando la búsqueda semántica es el núcleo del producto.
Pero las grandes empresas tienden a chocar con un muro diferente.
El problema no es si pueden hacer funcionar la búsqueda vectorial. El problema es lo que ocurre después.
Los archivos sin procesar viven en almacenamiento de objetos o lagos de datos. Los embeddings viven en una base de datos vectorial. Los metadatos viven en un sistema relacional. El procesamiento offline ocurre en otro lugar. Los registros de búsqueda se acumulan en otra canalización. Luego cambia el modelo de embeddings, o cambia la lógica de clasificación, o la base de conocimiento necesita curación, o alguien quiere rastrear por qué un sistema de recuperación sigue fallando en casos límite. De repente, el sistema ya no es un solo sistema. Es un mosaico.
Ese mosaico crea tres problemas conocidos.
- El primero son los silos de datos. Los datos necesarios para ejecutar una funcionalidad de IA están distribuidos en múltiples sistemas, cada uno con su propio formato, ciclo de vida y modelo operativo.
- El segundo es el costo de iteración. Cuando cambia un modelo de embeddings, la reescritura no es incremental por defecto. Puede convertirse en un esfuerzo de reindexación y migración de meses.
- El tercero es el bucle roto entre el servicio online y la mejora offline. El sistema sirve consultas en producción, pero las señales que podrían mejorarlo, salidas de deduplicación, etiquetas de clustering, puntuaciones de calidad y análisis de fallos, a menudo viven en entornos separados y nunca fluyen limpiamente de vuelta a la capa de recuperación.
Ese es el punto en el que comprar una base de datos vectorial deja de sentirse como la respuesta y empieza a sentirse como el comienzo de una cuestión arquitectónica más amplia.
Si el verdadero problema es la mejora continua a escala, entonces la arquitectura tiene que cambiar.
De base de datos vectorial a AI Lakebase
Antes del auge de la IA, Databricks ayudó a popularizar el modelo Lakehouse al colapsar la incómoda división entre lagos de datos y almacenes de datos. En lugar de mantener sistemas separados para almacenamiento, analítica y procesamiento a gran escala, las empresas podían trabajar desde una base más unificada.
La era de la IA está obligando a un replanteamiento similar, pero en torno a los datos no estructurados.
Si observas de cerca los diagramas de infraestructura que Jensen Huang ha estado usando, el centro de gravedad se está moviendo. En la era de los datos estructurados, frameworks como Spark estaban en el corazón de la canalización. En la era de los datos no estructurados, la infraestructura vectorial como Milvus está empezando a ocupar ese papel. No porque la búsqueda vectorial sea lo único que importa, sino porque cada vez más se sitúa en la intersección entre datos sin procesar, embeddings, índices y recuperación de aplicaciones.
Eso abre una posibilidad mayor: ¿y si la recuperación vectorial no se tratara como una capa de servicio separada añadida al costado de la pila? ¿Y si se integrara directamente con el lago de datos empresarial y los flujos de trabajo de datos circundantes?
Arquitectura de AI Lakebase
Esa es la idea detrás de AI Lakebase.
El objetivo de AI Lakebase no es añadir otra categoría de producto más a un mercado ya saturado. El objetivo es reemplazar un patrón fragmentado por uno más coherente.
- En la base se encuentra una capa de almacenamiento unificada. Parte de esos datos vive en colecciones nativas de Zilliz optimizadas para recuperación vectorial de alto rendimiento. Parte permanece en formatos abiertos que la empresa ya utiliza, Iceberg, Lance, Paimon, y archivos sin procesar en almacenamiento de objetos. Lo importante es que los datos no necesitan copiarse en cinco sistemas diferentes solo para volverse utilizables.
- Encima de eso se encuentra la capa de servicio de producción, creada para la recuperación en tiempo real. En Zilliz Cloud, eso significa clústeres de servicio impulsados por Cardinal optimizados para latencia a nivel de milisegundos, con diferentes modos para rendimiento, capacidad y ubicación escalonada de datos calientes-fríos. En la práctica, eso significa que los datos a los que se accede con frecuencia permanecen locales mientras que los datos fríos se cargan bajo demanda desde almacenamiento más barato. El resultado no es solo un mejor diseño del sistema. Es control de costos.
- Luego está la capa de cómputo elástico: clústeres bajo demanda para ETL, deduplicación, clustering, análisis de calidad de datos, re-embedding, evaluación e investigación interactiva. Estos no son sistemas laterales pegados después. Son parte de la misma base.
Las tres capas comparten los mismos datos en lugar de mantener múltiples copias desconectadas.
Eso suena como una historia de limpieza arquitectónica, y lo es. Pero es más que eso.
Pero el punto más importante es lo que esa arquitectura hace posible.
AI Lakebase es más que una limpieza arquitectónica
La mayoría de los sistemas de IA de hoy pueden servir. Muchos menos pueden mejorar sistemáticamente.
Eso no suele deberse a que el modelo esté equivocado. Se debe a que la infraestructura a su alrededor hace que la retroalimentación sea costosa.
Un sistema de producción genera señales constantemente. Cada consulta te dice algo. Cada recuperación fallida te dice algo. Cada respuesta de baja calidad, cada resultado repetido, cada interacción sin salida, cada clúster de documentos similares, cada fragmento ruidoso en el corpus, todo eso es información que podría usarse para mejorar el sistema.
Pero en la mayoría de las pilas, esas señales están dispersas entre registros de servicio, pipelines offline, notebooks, dashboards y scripts puntuales. El sistema funciona, pero realmente no aprende de su propia experiencia.
El marco de AI Lakebase para resolver eso es Continuous Serving/Continuous Discovery (AI CS/CD).
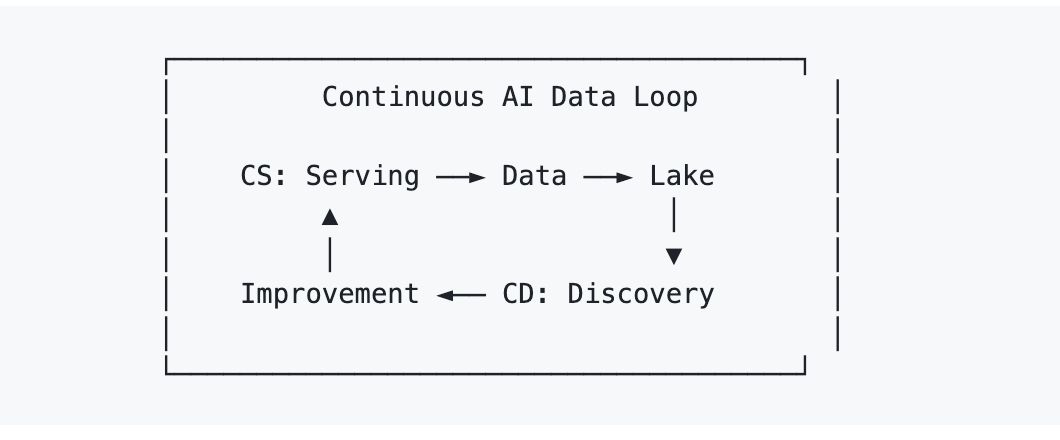
- Continuous Serving es la parte obvia: el sistema en vivo gestiona la recuperación y la generación en producción.
- Continuous Discovery es la parte menos obvia: el sistema analiza continuamente lo que ha acumulado, brechas de cobertura, modos de fallo, estructura de clústeres, problemas de calidad de datos, y escribe las mejoras resultantes de vuelta en el mismo entorno operativo.
Eso importa porque, una vez que el servicio y el descubrimiento comparten la misma base de datos, las mejoras dejan de parecer migraciones y empiezan a parecer iteraciones. Los resultados de deduplicación pueden fluir de vuelta a la recuperación en vivo. Las puntuaciones de calidad pueden influir en el ranking de producción. Las etiquetas de clúster pueden convertirse en señales de recuperación. El re-embedding puede ocurrir de forma incremental mediante cómputo elástico en lugar de como un evento gigante de una sola vez.
La arquitectura empieza a comportarse menos como una base de datos estática y más como un ciclo vivo de mejora.
Ese es un cambio mucho más trascendente que “base de datos vectorial, pero más rápida.”
Escala rápido e itera rápido con AI Lakebase
Muchas empresas de infraestructura pueden afirmar que escalan. Muchas pueden afirmar que tienen velocidad. Menos pueden afirmar de manera plausible que ofrecen tanto escala como iteración continua en el mismo sistema.
Zilliz sostiene que la próxima fase de la infraestructura de IA empresarial requiere ambas cosas.
- Escalar rápido significa una infraestructura multirregional y multinube que pueda soportar cargas de trabajo de producción a muy gran escala, no solo ejecuciones de benchmark o entornos de demostración.
- Iterar rápido significa que el sistema está diseñado para que el descubrimiento offline y el servicio online formen parte del mismo ciclo operativo. La mejora está incorporada, no añadida posteriormente.
Esa distinción importa porque la IA en producción falla de dos maneras opuestas. Algunos sistemas escalan pero se estancan. Se vuelven grandes, caros y cada vez más difíciles de mejorar. Otros iteran rápidamente en entornos pequeños pero nunca se convierten en sistemas de producción duraderos. El verdadero objetivo no es ninguno de los dos. Es un sistema que pueda crecer y aprender simultáneamente.
Esa es la promesa detrás del paso de base de datos vectorial a AI Lakebase.
La base de datos vectorial no desaparece en esa transición. Sigue siendo importante. Sigue siendo el motor de servicio para la recuperación en tiempo real. Pero deja de ser el punto final de la arquitectura. Se convierte en una capa dentro de un sistema más amplio, igual que las bases de datos relacionales siguen existiendo en un mundo Lakehouse sin definir por sí mismas toda la arquitectura.
Y esa puede ser la forma más útil de interpretar la frase de Jensen Huang en GTC.
Si los datos no estructurados son el contexto de la IA, entonces el techo de las aplicaciones de IA estará determinado no solo por los modelos, sino por la madurez que alcance la infraestructura para datos no estructurados.
Esa infraestructura aún está inacabada. El mercado todavía está en una fase temprana. Pero el contorno empieza a vislumbrarse.
Y, cada vez más, Milvus está justo en el centro de ello.
¡Mantente atento!
AI Lakebase será la actualización arquitectónica detrás de Milvus 3.0 y una evolución importante de Zilliz Cloud. Si quieres echar un vistazo temprano a hacia dónde se dirige esto, contáctanos para acceso anticipado.
Sigue leyendo

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.