




Fuzz Testing Explained: Versteckte Schwachstellen in Software aufdecken

TL; DR: Fuzz-Testing (oder Fuzzing) ist eine Software-Testtechnik, bei der große Mengen an zufälligen oder unerwarteten Daten ("Fuzz") in ein Programm eingegeben werden, um Fehler, Abstürze oder Schwachstellen zu erkennen. Indem Fuzz-Tests aufzeigen, wie sich das System unter unerwarteten Bedingungen verhält, helfen sie bei der Aufdeckung von Grenzfällen, Sicherheitsmängeln und Schwachstellen, die bei herkömmlichen Tests möglicherweise übersehen werden. Fuzz-Tests werden häufig zur Verbesserung der Zuverlässigkeit und Sicherheit von Software eingesetzt, insbesondere bei Systemen, die komplexe Eingaben verarbeiten, wie Webdienste, Dateiparser und APIs.
Fuzz Testing Explained: Versteckte Schwachstellen in Software aufdecken
Was ist Fuzz-Testing?
Fuzz-Testing ist eine Softwaretestmethode, die versteckte Fehler findet, indem unerwartete oder zufällige Daten in ein Programm eingespeist werden, um zu sehen, wie es reagiert. Durch das absichtliche Herbeiführen ungewöhnlicher oder "unscharfer" Situationen deckt diese Testtechnik Schwachstellen auf, die regulären Tests möglicherweise entgehen, insbesondere bei komplexer oder sicherheitsempfindlicher Software.
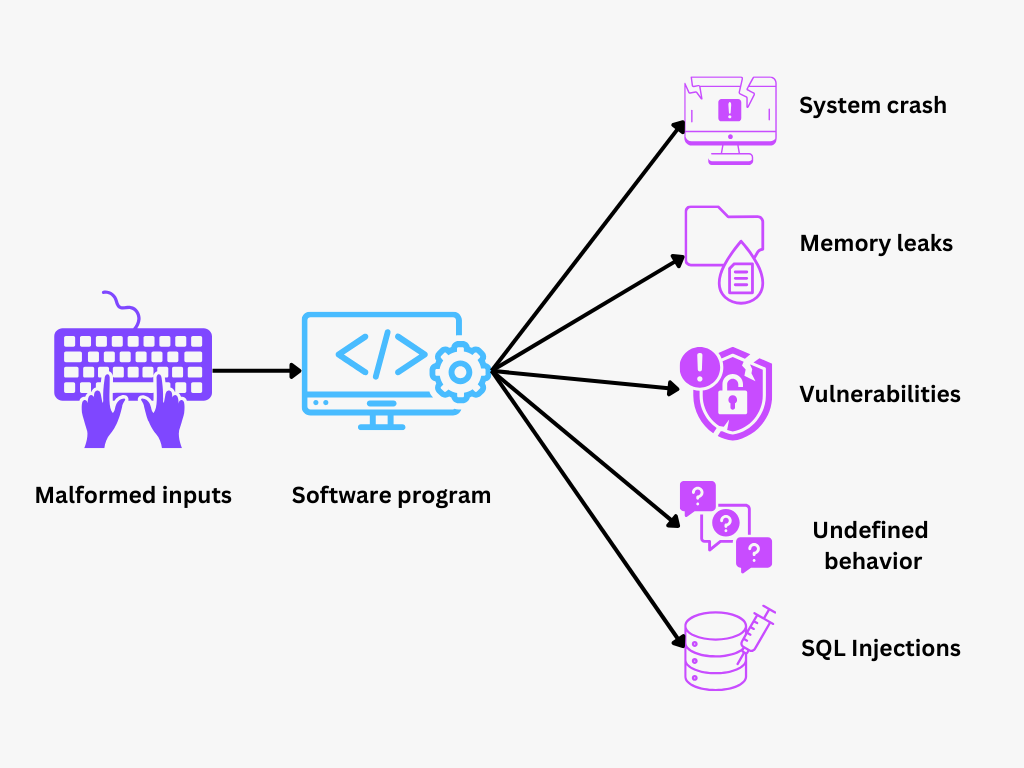 Abbildung- Fuzz Testing.png
Abbildung- Fuzz Testing.png
Abbildung: Fuzz-Testing
Geschichte des Fuzz-Testens
Fuzz-Testing begann als zufällige Entdeckung in den späten 1980er Jahren. Professor Barton Miller von der University of Wisconsin experimentierte mit vernetzten Computerprogrammen, als er unerwartete Abstürze bemerkte, die durch zufälliges Eingangsrauschen verursacht wurden. Dies veranlasste ihn zu weiteren Untersuchungen, indem er absichtlich Zufallsdaten in verschiedene Programme einspeiste, um deren Reaktionen zu beobachten. Er stellte fest, dass viele Anwendungen durch diese zufälligen Eingaben verwundbar waren, was Sicherheits- und Stabilitätsprobleme aufdeckte. Millers Arbeit legte den Grundstein für das Fuzz-Testing und etablierte es als effektive Methode zur Aufdeckung von Softwarefehlern und -schwachstellen.
Wie funktioniert Fuzz-Testing?
Beim Fuzz-Testing werden zufällige, unerwartete oder ungültige Daten ("Fuzz"-Eingaben) in ein Programm eingespeist, um dessen Verhalten zu bewerten und potenzielle Fehler aufzudecken. Durch diesen Ansatz wird das Programm in unvorhersehbare Zustände gezwungen, wodurch häufig Fehler oder Schwachstellen aufgedeckt werden, die bei herkömmlichen Tests möglicherweise übersehen werden. Die Idee ist, zu sehen, wie gut die Software unter dem Stress von unerwarteten Eingaben standhält, ohne abzustürzen oder sich unerwartet zu verhalten.
Phasen des Fuzz-Tests
Der Fuzz-Testing-Prozess besteht aus mehreren Schritten, die zur Identifizierung, zum Testen und zur Analyse von Problemen innerhalb eines Zielsystems führen.
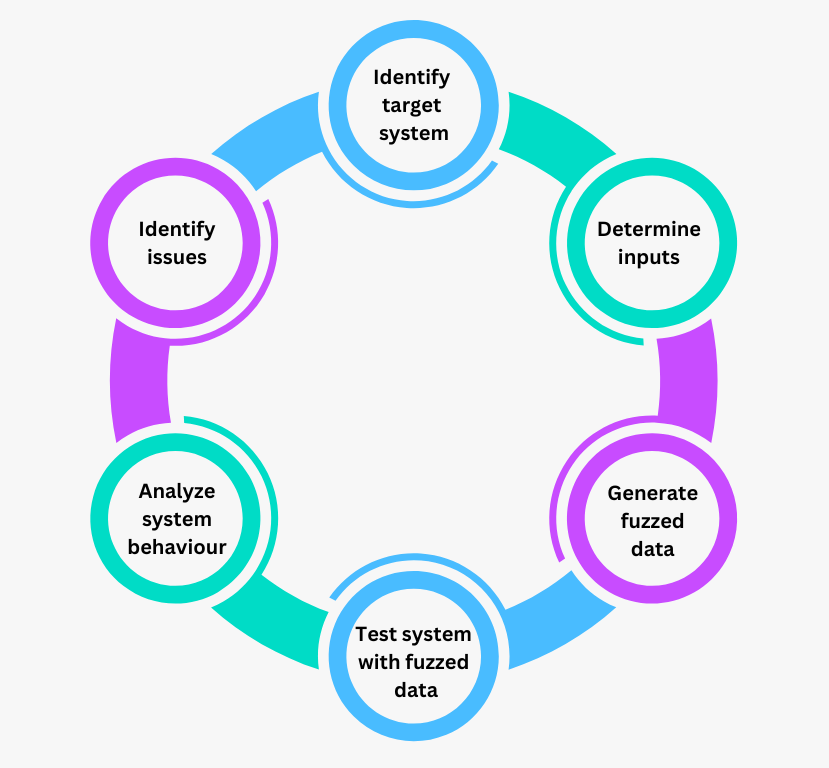 Abbildung- Phasen des Fuzz-Testens.png
Abbildung- Phasen des Fuzz-Testens.png
Abbildung: Phasen des Fuzz-Testens
Zielsystem identifizieren
Der erste Schritt beim Fuzz-Testing besteht darin, das Programm oder die Komponente auszuwählen, die Sie testen wollen. Dabei kann es sich um eine Anwendung, eine Funktion innerhalb eines umfassenderen Systems oder sogar um ein bestimmtes Eingabefeld handeln.
Eingaben bestimmen
Sobald das Zielsystem identifiziert ist, muss im nächsten Schritt entschieden werden, welche Art von Eingaben getestet werden soll. Dazu müssen die Datenformate oder Eingabetypen, die das System typischerweise verarbeitet, verstanden werden. Wenn das Zielsystem zum Beispiel Netzwerkpakete verarbeitet, können die Eingaben aus verschiedenen Paketstrukturen bestehen. Die Tester schaffen eine Grundlage für die Erstellung relevanter Fuzzedaten, indem sie relevante Eingaben definieren.
Erzeugen von Fuzzedaten
In dieser Phase erzeugt die Fuzzing-Engine eine Vielzahl von unerwarteten oder ungültigen Eingaben. Bei diesen Eingaben kann es sich um zufällig generierte, mutierte Formen gültiger Daten oder um selbst erstellte Sequenzen handeln, die Grenzfälle simulieren. Ziel ist es, Eingaben zu erzeugen, mit denen die Grenzen des Zielsystems auf Schwachstellen im Umgang mit unerwarteten Daten überprüft werden können.
Testsystem mit Fuzzed-Daten
Nun werden die generierten Fuzzedaten in das Zielsystem eingespeist. In dieser Phase interagiert das System mit jeder Eingabe und reagiert auf ungewöhnliche oder ungültige Daten. Da das System wiederholt mit verschiedenen Eingaben konfrontiert wird, zeigt das Fuzz-Testing Punkte auf, an denen das System nicht korrekt antwortet oder abstürzt.
Analysieren des Systemverhaltens
Während das System jede Eingabe verarbeitet, wird sein Verhalten genau beobachtet. Die Tester suchen nach Anzeichen für abnormale Aktivitäten, wie z. B. Abstürze, nicht reagierendes Verhalten oder unerwartete Fehlermeldungen. Diese Phase hilft bei der Ermittlung von Schwachstellen oder potenziellen Schwachstellen, die in einem realen Szenario ausgenutzt werden könnten.
Identifizieren Sie Probleme
Schließlich werden alle während der Tests festgestellten Anomalien überprüft, um festzustellen, ob sie auf echte Probleme hindeuten. Die Tester analysieren das beobachtete Verhalten mit Hilfe von Debugging-Tools, um die Grundursache für jeden Fehler zu ermitteln.
Arten von Fuzz-Tests
Fuzz-Tests gibt es in verschiedenen Formen, jede mit unterschiedlichen Strategien und Anwendungen. Im Folgenden finden Sie eine Übersicht über die wichtigsten Arten und Kategorien von Fuzz-Tests:
1. Eingabebasiertes Fuzzing
Diese Art von Fuzzing konzentriert sich auf die Erzeugung verschiedener Eingaben, um zu testen, wie ein Programm mit verschiedenen Daten umgeht. Sie umfasst zwei primäre Ansätze:
Mutationsbasiertes Fuzzing: Bei dieser Methode werden vorhandene Datenproben durch zufällige Änderungen verändert. Beim mutationsbasierten Fuzzing werden z. B. unerwartete Zeichen hinzugefügt, Abschnitte vertauscht oder Werte geändert, wenn es sich bei der Eingabe um eine Textdatei handelt. Die Idee ist, bekannte, gültige Eingaben zu nehmen und neue, leicht "mutierte" Versionen zu erstellen, die Schwachstellen aufdecken können, während sie gleichzeitig eine gewisse Ähnlichkeit mit realistischen Daten aufweisen.
Generationsbasiertes Fuzzing: Im Gegensatz zum mutationsbasierten Fuzzing werden beim generationsbasierten Fuzzing die Eingaben von Grund auf neu erstellt. Es verwendet vordefinierte Regeln und Strukturen, um neue Daten zu erstellen, die bestimmte Formate oder Protokolle imitieren. Beim generationsbasierten Fuzzing können beispielsweise XML-Dateien mit verschiedenen Strukturen, Tags und Attributwerten erstellt werden, wenn ein XML-Parser getestet wird.
2. Struktur-basiertes Fuzzing
Strukturbewusstes Fuzzing versteht die zugrunde liegende Struktur der zu testenden Daten. Anstatt zufällige oder veränderte Daten einzugeben, wird das korrekte Format oder die Protokollstruktur beibehalten, während der Inhalt variiert wird.
- Protokoll-Fuzzing: Eine typische Anwendung von strukturbewusstem Fuzzing ist das Protokoll-Fuzzing, das zum Testen von Netzwerkprotokollen verwendet wird, indem Eingaben erzeugt werden, die bestimmten Kommunikationsstandards entsprechen (wie HTTP oder TCP/IP).
3. Abdeckungsgesteuertes Fuzzing
Abdeckungsgesteuertes Fuzzing verwendet Rückmeldungen aus der Programmausführung, um neue Eingaben zu erzeugen. Es verfolgt Codeabdeckungsmetriken, um festzustellen, welche Teile des Codes mit jeder Eingabe ausgeführt wurden, und erstellt dann Eingaben, die darauf abzielen, ungetestete Codepfade abzudecken. Dieser Ansatz ist sehr effektiv, um gründliche Tests durchzuführen, da er die Codeabdeckung maximiert, was die Wahrscheinlichkeit erhöht, versteckte Fehler und Schwachstellen zu entdecken.
4. Black-Box-, White-Box- und Gray-Box-Fuzzing
Diese Kategorien unterscheiden sich je nachdem, wie viele Informationen der Tester über die Zielsoftware hat:
Black-Box-Fuzzing: Beim Black-Box-Fuzzing hat der Tester keine internen Programmkenntnisse. Die Eingaben werden nach dem Zufallsprinzip generiert und in die Software eingespeist, ohne die Struktur oder den Code des Programms zu berücksichtigen. Black-Box-Fuzzing ist einfach einzurichten und erfordert keinen Quellcode. Es hilft beim Testen von Closed-Source-Anwendungen, deckt aber möglicherweise nicht so viele Probleme auf wie andere Methoden.
White-Box-Fuzzing: Beim White-Box-Fuzzing hat der Tester vollen Zugriff auf den Quellcode des Programms. Dadurch kann der Fuzzing-Prozess auf bestimmte Teile des Codes abzielen und Techniken wie statische Analyse und Kontrollflussverfolgung einsetzen, um die Eingabeerzeugung zu steuern. White-Box-Fuzzing ist präziser und kann komplexe Fehler aufdecken, erfordert aber detaillierte Code-Kenntnisse und ist daher ressourcenintensiver.
Gray-Box-Fuzzing: Gray-Box-Fuzzing stellt ein Gleichgewicht zwischen Black-Box- und White-Box-Ansätzen dar. Die Tester haben teilweisen Zugang zu den internen Abläufen des Programms, typischerweise durch Instrumentierung, die Rückmeldung über die Codeabdeckung gibt. Dieser Ansatz profitiert von der Effizienz des Black-Box-Fuzzing mit der zusätzlichen Anleitung durch die Codeabdeckung.
5. Hybrides Fuzzing
Hybrid Fuzzing kombiniert mehrere Fuzzing-Strategien, um die Testtiefe und -effizienz zu verbessern. So kann beispielsweise mutationsbasiertes Fuzzing mit abdeckungsgesteuerten Techniken kombiniert werden, um die Codeabdeckung zu maximieren und gleichzeitig eine breitere Palette von Eingabevariationen zu untersuchen. Auf diese Weise können Tester komplexe Software mit größerer Genauigkeit auf Schwachstellen untersuchen, die mit einer einzelnen Fuzzing-Methode allein möglicherweise nicht gefunden werden.
Anwendungsfälle von Fuzz-Testing
Fuzz-Testing findet branchenübergreifend vielfältige Anwendung, insbesondere dort, wo Sicherheit, Stabilität und Ausfallsicherheit von entscheidender Bedeutung sind. Hier sind einige der wichtigsten Anwendungsfälle für Fuzz-Tests:
1. Sicherheitstests
Eine der häufigsten Anwendungen von Fuzz-Tests sind Sicherheitstests. Indem zufällige oder fehlerhafte Eingaben in ein Programm eingespeist werden, können Fuzz-Tests Schwachstellen aufdecken, die Hacker ausnutzen könnten, z. B. Pufferüberläufe, Fehler bei der Eingabevalidierung und Injektionsschwachstellen.
2. Software-Robustheit
Fuzz-Tests verbessern auch die Robustheit von Software, indem sie sicherstellen, dass Anwendungen unerwartete oder fehlerhafte Daten verarbeiten können, ohne abzustürzen. Viele Programme werden mit bestimmten Eingabeerwartungen entwickelt, aber die Daten der realen Welt sind nicht immer vorhersehbar. Durch das Testen mit verschiedenen unerwarteten Eingaben können Fuzz-Tests Bereiche aufdecken, in denen Software unter Stress versagen könnte, insbesondere bei Anwendungen, die in unvorhersehbaren Umgebungen laufen oder unterschiedliche Daten verarbeiten.
3. Protokoll-Tests
Protokoll-Fuzzing wird häufig eingesetzt, um die Belastbarkeit von Netzwerkprotokollen zu testen. Netzwerkprotokolle legen die Regeln für den Datenaustausch zwischen Geräten fest, und jede Schwachstelle in diesen Protokollen kann zu Sicherheitsverletzungen oder Unterbrechungen führen. Durch Fuzz-Testing von Netzwerkprotokollen können Tester beurteilen, wie gut diese Protokolle mit unerwarteten oder fehlerhaften Paketen umgehen, um Schwachstellen zu erkennen, die die Datenintegrität, Sicherheit oder Zuverlässigkeit der Kommunikation beeinträchtigen könnten.
4. Automobil- und IoT-Tests
Bei Automobilsystemen können Fuzz-Tests Schwachstellen in der Kommunikation zwischen den Teilsystemen des Fahrzeugs aufdecken, um sicherzustellen, dass diese funktionsfähig und sicher bleiben. Auch für IoT-Geräte sind Fuzz-Tests unerlässlich, um zu bestätigen, dass diese Geräte eine Reihe von Netzwerkbedingungen und Dateneingaben verarbeiten können, ohne dass die Funktionalität oder Sicherheit beeinträchtigt wird.
Vorteile von Fuzz-Tests
Frühzeitige Entdeckung von versteckten Fehlern und Schwachstellen: Fuzz-Testing deckt Fehler auf, die bei herkömmlichen Testmethoden möglicherweise übersehen werden, insbesondere solche, die durch seltene oder unerwartete Eingabeszenarien ausgelöst werden.
Verbesserung der Robustheit und Zuverlässigkeit von Software: Indem die Software verschiedenen Eingaben ausgesetzt wird, einschließlich fehlerhafter oder unerwarteter Daten, hilft Fuzz-Testing den Entwicklern, Schwachstellen zu erkennen und die Software gegen reale Bedingungen zu härten.
Verbesserte Sicherheitsmaßnahmen: Fuzz-Testing findet Schwachstellen, die für Angriffe ausgenutzt werden könnten, wie z. B. Pufferüberläufe, Speicherlecks und Injektionsfehler. Daher können Sicherheitsteams diese Schwachstellen proaktiv beheben, um die Software vor potenziellen Cyberangriffen und unbefugtem Zugriff zu schützen.
Erhöht die Codeabdeckung: Abdeckungsgesteuertes Fuzzing stellt sicher, dass auch weniger häufig genutzte Teile des Codes getestet werden, und deckt Fehler in selten ausgeführten Pfaden auf. Dieser breit angelegte Testansatz verbessert die Gesamtqualität und Stabilität der Software, indem Codepfade erforscht werden, die andernfalls vernachlässigt werden könnten.
Herausforderungen und Grenzen von Fuzz-Tests
Komplexität bei der Handhabung komplizierter Daten: Fuzz-Tests haben mit komplexen, zustandsabhängigen Programmen zu kämpfen, die auf komplizierten Datenformaten beruhen, die es schwierig machen, angemessene Eingaben zu erzeugen, ohne die Datenstruktur zu zerstören. Beim Testen von Protokollen oder Dateiformaten z.B. erfordert Fuzzing die Kenntnis der Struktur, was die Komplexität erhöht und fortgeschrittene Fuzzing-Techniken erfordert.
Ressourcen- und Zeitbeschränkungen: Fuzzing in großem Maßstab kann viel Rechenleistung und Speicherplatz beanspruchen, was es ressourcenintensiv macht. Um aussagekräftige Ergebnisse zu erzielen, sind oft lange Laufzeiten erforderlich, insbesondere bei komplexen Anwendungen, was den Test- und Entwicklungsprozess verzögern kann.
Grenzen der Erzeugung zufälliger Eingaben: Fuzz-Tests beruhen auf zufälligen oder halbzufälligen Eingaben, die nicht immer tiefere Teile des Codes erreichen, insbesondere bei komplexen Programmen mit komplizierter Logik oder Abhängigkeiten. Außerdem fehlt beim reinen Zufalls-Fuzzing die nötige Konzentration auf bestimmte Schwachstellen, so dass Fehler in bestimmten Codepfaden möglicherweise unentdeckt bleiben.
Schwierigkeit bei der Reproduktion von Problemen: Fuzz-Tests können obskure Fehler aufdecken, aber die Reproduktion der genauen Bedingungen, die diese Fehler ausgelöst haben, kann eine Herausforderung sein. Die Fehlersuche wird komplizierter, wenn die spezifische Eingabe oder die Abfolge von Ereignissen, die das Problem verursacht haben, nicht einfach reproduziert werden kann.
Falsch-Positive und Rauschen in den Ergebnissen: Fuzz-Tests können eine große Menge an Daten produzieren, wobei einige Ergebnisse auf Probleme hinweisen, bei denen es sich nicht um tatsächliche Sicherheitslücken handelt, was als falsch-positive Ergebnisse bezeichnet wird. Falschmeldungen herauszufiltern und sich auf echte Schwachstellen zu konzentrieren, kann zeitaufwändig sein und erfordert Fachwissen.
Laufende Überwachung und Analyse: Fuzz-Testing ist kein einmaliger Prozess; es erfordert eine kontinuierliche Überwachung. Darüber hinaus erfordert effektives Fuzzing die Interpretation umfangreicher Protokolle und Ergebnisse, was qualifiziertes Personal für die Analyse und Behebung erkannter Probleme voraussetzt.
Fuzz-Testing-Tools und Frameworks
AFL (American Fuzzy Lop): Bekannt für seine Effizienz beim mutationsbasierten Fuzzing, verwendet AFL eine Kombination aus intelligenter Eingabemutation und Codeabdeckungs-Feedback, um Schwachstellen zu entdecken.
libFuzzer: Ein abdeckungsgesteuerter Fuzzer, der für Bibliotheken und Anwendungen entwickelt wurde. libFuzzer generiert Eingaben, die auf Codeabdeckung abzielen, um versteckte Fehler in komplexer Software aufzudecken.
OSS-Fuzz: Eine groß angelegte Fuzzing-Plattform, die auf Open-Source-Projekte zugeschnitten ist. OSS-Fuzz bietet kontinuierliche, automatisierte Fuzz-Tests, um die Sicherheit und Stabilität von weit verbreiteter Open-Source-Software zu verbessern.
Peach: Ein umfassendes Fuzzing-Framework, das eine Reihe von Protokollen und Datenformaten zum Testen von komplexer Software und Kommunikationsprotokollen unterstützt, einschließlich generations- und mutationsbasierter Tests.
Sulley: Hauptsächlich für das Fuzzing von Netzwerkprotokollen verwendet, wird Sulley für seine Fähigkeit geschätzt, eine Vielzahl von Netzwerkeingaben zu simulieren und wird oft in der Sicherheitsforschung eingesetzt.
Radamsa: Ein leichtgewichtiger, mutationsbasierter Fuzzer, der einfach zu benutzen und effektiv ist, um unerwartete Eingaben zu erzeugen, um die Widerstandsfähigkeit und Robustheit von Software zu testen.
Fuzz-Testing für Vektordatenbanken und KI-Anwendungen
Fuzz-Tests sind für Vektordatenbanken wie Milvus (erstellt von Zilliz) und GenAI-Anwendungen von großer Bedeutung, da diese Technologien große Mengen an unterschiedlichen und komplexen Daten verarbeiten. Bei KI-gesteuerten Lösungen wie Retrieval-Augmented Generation (RAG) und anderen maschinellen Lernmodellen sind Fuzz-Tests von entscheidender Bedeutung für die Aufrechterhaltung der Datenintegrität, der Systemstabilität und der Sicherheit, insbesondere beim Umgang mit unstrukturierten Daten. Hier ist der Nutzen von Fuzz-Tests:
Sicherstellung einer robusten Datenverarbeitung in Vektordatenbanken: Da Vektordatenbanken häufig komplexe Abfragen und Filterungen unterstützen, können Fuzz-Tests aufzeigen, wie gut sie Randfälle in Abfrageeingaben verarbeiten. Dadurch werden potenzielle Fehler oder Ineffizienzen bei der Indizierung und Abfrage aufgedeckt.
Testen der Ausfallsicherheit in KI-gestützten Anwendungen wie RAG: RAG und ähnliche KI-Modelle sind darauf angewiesen, relevante Informationen aus externen Datenbanken abzurufen, um Antworten zu generieren oder bestimmte Aufgaben auszuführen. Diese Modelle sind empfindlich gegenüber der Qualität und Struktur der abgerufenen Daten. Mit Fuzz-Tests können beschädigte oder unerwartete Dateneingaben simuliert werden, um zu sehen, wie das Modell auf ungewöhnliche Abrufe reagiert.
Sicherung von Vektordatenbanken und KI-Pipelines gegen potenzielle Angriffe: Mit Fuzz-Tests können feindliche Dateneingaben simuliert werden, z. B. gegnerische Beispiele, die das Verhalten des KI-Modells manipulieren sollen. Dadurch werden Schwachstellen aufgedeckt, die Angreifer ausnutzen könnten, so dass die Entwickler die Sicherheit verstärken können.
Verbesserung der Zuverlässigkeit in verteilten KI-Architekturen: Viele KI-Anwendungen, insbesondere solche, die auf Large Language Models (LLMs) oder Bilderkennungssystemen basieren, sind über mehrere Knoten und Systeme verteilt. Fuzz-Tests können Probleme bei der Datensynchronisierung über Knoten in einer verteilten Vektordatenbank aufdecken, um zu prüfen, ob alle Instanzen der Datenbank reibungslos mit inkonsistenten oder unerwarteten Eingaben umgehen können.
Best Practices für Fuzz-Tests
Die effektive Durchführung von Fuzz-Tests erfordert eine sorgfältige Planung und die Einhaltung von Best Practices. Hier sind einige wichtige Tipps zur Optimierung von Fuzz-Tests:
Optimieren Sie die Eingabegenerierung
Verwenden Sie mutations- und generationsbasiertes Fuzzing, um eine breite Palette von Eingaben zu gewährleisten, die häufige und seltene Randfälle abdecken.
Passen Sie die Eingabegenerierung an die erwarteten Datenformate oder Protokolle der Zielsoftware an, um irrelevante Fehler zu vermeiden und sich auf sinnvolle Probleme zu konzentrieren.
Verwenden Sie strukturbewusstes oder abdeckungsgesteuertes Fuzzing für komplexe Datentypen, um die Codeabdeckung zu maximieren und tiefere Fehler zu finden.
Umfassende Überwachung und Feedback einrichten
Implementieren Sie eine detaillierte Protokollierung, um das Programmverhalten während des Testens zu erfassen, einschließlich Abstürzen, Speicherlecks und abnormalen Ausgaben.
Überwachungstools wie Prometheus können verwendet werden, um die Speichernutzung, die CPU-Last und die Ausführungspfade zu verfolgen, um Einblicke in die Softwareleistung unter Fuzzing-Eingaben zu erhalten.
Aktivieren Sie Tools für die Meldung von Abstürzen und die Fehlersuche, um die Ursache von erkannten Problemen aufzuspüren und die Reproduktion und Behebung der Fehler zu erleichtern.
Wählen Sie die richtigen Tools
Wählen Sie Fuzzing-Tools entsprechend den spezifischen Anforderungen des Projekts aus. Beispielsweise kann AFL für mutationsbasiertes Fuzzing, libFuzzer für Bibliotheken und OSS-Fuzz für Open-Source-Projekte verwendet werden.
Stellen Sie sicher, dass sich das Tool gut in Ihre Entwicklungs- und Testumgebung integrieren lässt und eine nahtlose Einbindung in CI/CD-Pipelines ermöglicht.
Experimentieren Sie mit mehreren Tools und kombinieren Sie verschiedene Fuzzing-Strategien, um eine bessere Abdeckung und bessere Ergebnisse zu erzielen.
Entwerfen einer effektiven Testumgebung
Erstellen Sie eine kontrollierte Testumgebung, die die gefuzzte Software von kritischen Systemen isoliert, um versehentliche Schäden oder Datenverluste zu vermeiden.
Stellen Sie ausreichend Rechenressourcen zur Verfügung, da Fuzz-Tests sehr ressourcenintensiv sein können. Ziehen Sie in Erwägung, die Tests in einer virtuellen Maschine oder einem Container durchzuführen, um die Ressourcenzuweisung effektiv zu verwalten.
Aktualisieren Sie Ihre Testumgebung regelmäßig, um die neuesten Abhängigkeiten und Patches einzubeziehen, da veraltete Komponenten unbeabsichtigte Probleme verursachen können.
Vermeiden Sie häufige Fallstricke
Fallstrick: Verlassen Sie sich ausschließlich auf zufällige Eingaben, ohne auf bestimmte Bereiche abzuzielen. Lösung: Verwenden Sie abdeckungsgesteuertes oder strukturbewusstes Fuzzing, um den Test auf die wichtigsten Codepfade zu richten.
Fallstrick: Ignorieren von Fehlalarmen, die die Ergebnisse überlagern können. Lösung: Überprüfen und filtern Sie die Ergebnisse regelmäßig, um sich auf echte Probleme zu konzentrieren, und verwenden Sie Tools oder Skripte, um die Ergebnisse zu sortieren.
Fall: Probleme, die bei Fuzz-Tests gefunden wurden, werden nicht reproduziert. Lösung: Protokollieren Sie alle Fuzz-Eingaben und Ausführungspfade, damit erkannte Probleme genau reproduziert und behoben werden können.
Fuzz-Testing kontinuierlich machen
Integrieren Sie Fuzz-Tests in Ihre CI/CD-Pipeline, um sicherzustellen, dass neue Code-Änderungen konsequent auf potenzielle Schwachstellen getestet werden.
Planen Sie regelmäßige Fuzz-Tests, insbesondere für kritische Softwarekomponenten, als Teil des laufenden Entwicklungsprozesses ein. Kontinuierliches Fuzzing erhöht die Wahrscheinlichkeit, dass Probleme frühzeitig erkannt werden.
Schlussfolgerung
Zusammenfassend lässt sich sagen, dass Fuzz-Testing eine leistungsstarke Methode ist, um versteckte Fehler und Schwachstellen in verschiedenen Softwareanwendungen, einschließlich Vektordatenbanken und KI-Systemen, aufzudecken. Fuzz-Tests helfen dabei, die Robustheit, Sicherheit und Zuverlässigkeit zu verbessern, indem zufällige oder missgestaltete Eingaben in ein Programm eingespeist werden. Obwohl es mit Herausforderungen verbunden ist, kann die Anwendung von Best Practices und der Einsatz der richtigen Tools die Effektivität maximieren.
FAQs zu Fuzz-Tests
- Was ist Fuzz-Testing, und warum ist es wichtig?**
Fuzz-Testing ist eine Softwaretestmethode, bei der zufällige oder unerwartete Daten in ein Programm eingegeben werden, um Fehler und Schwachstellen zu finden. Es verbessert die Sicherheit, Robustheit und Zuverlässigkeit von Software, indem es Probleme aufdeckt, die bei herkömmlichen Testmethoden möglicherweise übersehen werden.
- Wie funktioniert Fuzz-Testing in der Praxis?
Fuzz-Testing umfasst mehrere Phasen: Identifizierung des Zielsystems, Bestimmung der zu testenden Eingabetypen, Generierung von Fuzz-Daten, Ausführung des Programms mit diesen Daten, Analyse des Programmverhaltens und Identifizierung etwaiger Probleme. Dieser Prozess zeigt, wie gut die Software mit unerwarteten oder fehlerhaften Eingaben umgehen kann.
- Welche Arten von Fuzz-Tests sind üblich?
Zu den gängigen Arten gehören mutationsbasiertes Fuzzing (Veränderung vorhandener Daten), generationsbasiertes Fuzzing (Erstellung von Eingaben von Grund auf), abdeckungsgesteuertes Fuzzing (Maximierung der Codeabdeckung) und Protokoll-Fuzzing (Testen bestimmter Datenformate oder Kommunikationsstandards).
- Können Fuzz-Tests auf KI-Anwendungen und Vektordatenbanken angewendet werden?
Ja, Fuzz-Testing ist für KI und Vektordatenbanken von großer Bedeutung. Es hilft diesen Systemen, mit unvorhersehbaren Eingaben umzugehen, die Datenintegrität zu verbessern und die Sicherheit aufrechtzuerhalten, insbesondere bei Anwendungen wie [Retrieval-Augmented Generation (RAG)] (https://zilliz.com/vector-database-use-cases/llm-retrieval-augmented-generation) und komplexer Datenverarbeitung in KI-Pipelines.
- Welches sind die größten Herausforderungen beim Fuzz-Testing?
Zu den wichtigsten Herausforderungen gehören die Handhabung komplexer Datenstrukturen, die ressourcenintensive Natur von Fuzzing in großem Maßstab, die Grenzen der Generierung zufälliger Eingaben und die Schwierigkeit, Probleme zu reproduzieren. Die Einhaltung von Best Practices und die Auswahl der richtigen Tools können helfen, diese Herausforderungen zu bewältigen.
Verwandte Ressourcen
Bewertung von RAG-Anwendungen](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)
Optimierung von RAG-Anwendungen: Ein Leitfaden für Methoden, Metriken und Bewertungswerkzeuge zur Verbesserung der Zuverlässigkeit](https://zilliz.com/blog/how-to-evaluate-retrieval-augmented-generation-rag-applications)
Umfassende Überwachung und Beobachtbarkeit in der Zilliz Cloud](https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)
Prometheus Metrics: Überwachen Sie die Leistung Ihrer Anwendung
Observierbarkeit: Tracking über die Überwachung hinaus](https://zilliz.com/glossary/observability)
Überwachung von Milvus mit Grafana und Loki](https://zilliz.com/blog/monitoring-in-milvus-with-grafana-and-loki)
Wie man Engpässe bei der Suchleistung in Vektordatenbanken erkennt](https://zilliz.com/learn/how-to-spot-search-performance-bottleneck-in-vector-databases)
- Was ist Fuzz-Testing?
- Geschichte des Fuzz-Testens
- Wie funktioniert Fuzz-Testing?
- Arten von Fuzz-Tests
- Anwendungsfälle von Fuzz-Testing
- Vorteile von Fuzz-Tests
- Herausforderungen und Grenzen von Fuzz-Tests
- Fuzz-Testing-Tools und Frameworks
- Fuzz-Testing für Vektordatenbanken und KI-Anwendungen
- Best Practices für Fuzz-Tests
- Schlussfolgerung
- FAQs zu Fuzz-Tests
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren