




Sharding von Datenbanken verstehen

Sharding von Datenbanken verstehen
Moderne Websites und Anwendungen stützen sich in hohem Maße auf Datenbanktechnologien, um Lese- und Schreibanfragen von mehreren Benutzern zu verarbeiten. Mit zunehmender Popularität einer Anwendung steigt jedoch auch die Anzahl der Benutzer, und es wird schwierig, aufgrund häufiger Datenbankabstürze eine optimale Kundenerfahrung zu bieten.
Wie können Entwickler also ihre Datenbanken skalieren, um der steigenden Nachfrage gerecht zu werden? Während die Antwort je nach Anwendungsfall unterschiedlich ausfallen kann, ist das Sharding von Datenbanken eine unkomplizierte und kostengünstige Methode. Sie ist einfach zu implementieren und bietet erhebliche Leistungsverbesserungen.
Trotz seiner Einfachheit kann Datenbank-Sharding ein verwirrendes Konzept sein. In diesem Beitrag werden seine Bedeutung, Implementierungstechniken, Alternativen, Vorteile und Herausforderungen sowie Anwendungsfälle erläutert, damit Sie verstehen, wann und wie Sie die am besten geeignete Sharding-Methode anwenden.
Was ist Datenbank-Sharding?
Beim Datenbank-Sharding wird eine umfangreiche Datenbank in kleinere Teile, so genannte Shards, aufgeteilt und auf mehrere Rechner verteilt. Jeder Rechner verwendet die gleiche Technologie und arbeitet parallel, um große Datenmengen zu verarbeiten.
Dies ist eine von vielen Methoden, um die Datenverarbeitung zu beschleunigen und [Hochverfügbarkeit] zu gewährleisten (https://zilliz.com/learn/ensuring-high-availability-of-vector-databases). Wenn ein einzelner Rechner oder Datenbankserver aufgrund einer Überlastung ausfällt, können die anderen Server weiterhin Lese- und Schreibanfragen verarbeiten, so dass ein reibungsloser Ablauf für die Benutzer gewährleistet ist.
Sharding funktioniert jedoch nur so lange, wie die Daten verfügbar und zugänglich sind. Es ermöglicht den Entwicklern, die Arbeitslast organisch zu verteilen und die Latenzzeit zu verringern.
Replikation und Partitionierung sind weitere Techniken zur Vermeidung von Ausfallzeiten. Diese Methoden sind eher für kleinere Datenbanken geeignet. Bei der Replikation wird eine gesamte Datenbank auf mehrere Server kopiert, während bei der Partitionierung eine Datenbank aufgeteilt und auf einem einzigen Rechner gespeichert wird. In späteren Abschnitten werden diese Ansätze näher erläutert.
Wie funktioniert das Sharding von Datenbanken?
Sharding ist eine Form der horizontalen Skalierung, bei der Entwickler zusätzliche Knoten oder Server installieren, um mehrere Datenpartitionen zu speichern. Jede Partition wird zu einer unabhängigen Tabelle mit demselben Schema wie die ursprüngliche Datenbank. Die Informationen in jedem Shard sind jedoch eindeutig, und die Entwickler speichern die einzelnen Chunks auf mehreren Computern, den sogenannten Nodes.
Die folgende Tabelle veranschaulicht beispielsweise eine einzelne Datenbank, die Informationen über Kunden und die von ihnen gekauften Artikel enthält.
| Kunden-ID | Name | Gekaufter Artikel |
| 10001 | A | Hemd |
| 10002 | B | Mütze |
| 10003 | C | Hemd |
| 10004 | D | Schuhe |
Ein Entwickler kann Datenbank-Sharding verwenden, um die Datenbank in kleinere Partitionen, so genannte logische Shards, auf separaten Rechnern oder physischen Shards aufzuteilen.
Server 1
| Kunden-ID | Name | Gekaufter Artikel |
| 10001 | A | Hemd |
| 10002 | B | Mütze |
Server 2
| Kunden-ID | Name | Gekaufter Artikel |
| 10003 | C | Hemd |
| 10004 | D | Schuhe |
Sharding basiert auf einer Shared-Nothing-Architektur, bei der ein einzelner Knoten in einem Computer-Cluster Benutzeranfragen unabhängig bearbeitet. Wenn ein Benutzer versucht, auf die Datenbank zuzugreifen, wird nur der Shard, der die Informationen des Benutzers enthält, aktiv und verarbeitet die eingehende Anfrage.
Die Entwickler unterteilen die Daten mit Hilfe eines Shard-Schlüssels in logische Shards. Sie können den Schlüssel auf der Grundlage einer Spalte auswählen, die die Daten in Gruppen organisiert, oder einen neuen Schlüssel erstellen. In den folgenden Abschnitten wird erläutert, wie ein Shard-Schlüssel funktioniert und wie er bei der Entwicklung von Datengruppen für eine effiziente Aufteilung hilft.
Sharding-Methoden
Entwickler können je nach Anwendungsfall und Art der zu verarbeitenden Daten mehrere Sharding-Techniken implementieren. Zu den gängigen Methoden gehören bereichsbasiertes Sharding, Hash-Sharding, Verzeichnis-Sharding und Geo-Sharding.
Bereichsbasiertes Sharding
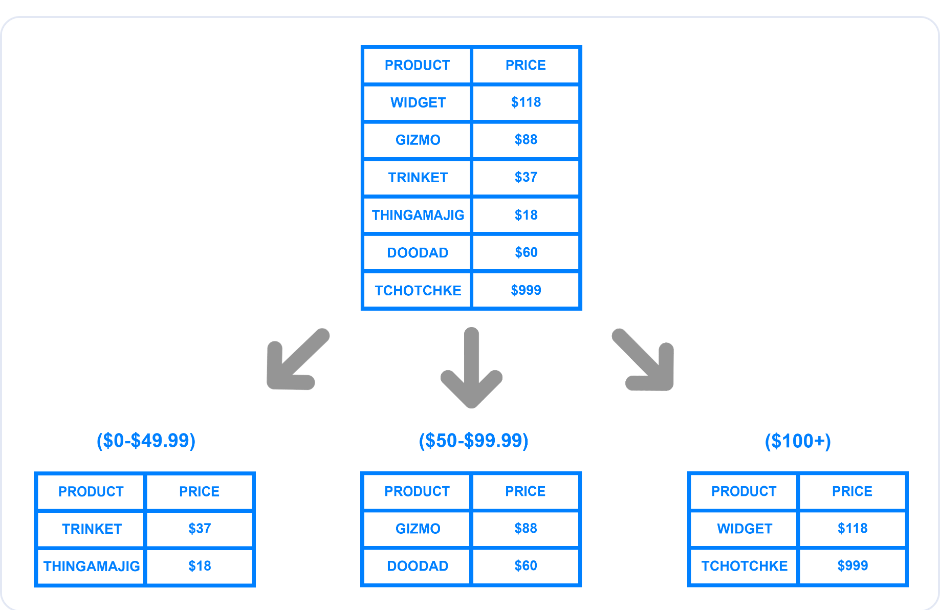
Beim bereichsbasierten oder dynamischen Sharding wird eine Datenbank auf der Grundlage eines bestimmten Wertebereichs in Shards aufgeteilt. Das folgende Diagramm zeigt, wie ein Entwickler eine Tabelle anhand einer Preisspanne in Shards aufteilen kann.
 Bereichsbasiertes Sharding basierend auf Preis.png
Bereichsbasiertes Sharding basierend auf Preis.png
Bereichsbasiertes Sharding auf Basis des Preises
Das Beispiel zeigt drei logische Shards, die anhand von Preisspannen erstellt wurden. Der Entwickler kann jedem Chunk einen eindeutigen Shard-Schlüssel zuweisen und sie auf separaten physischen Shards oder Rechnern speichern. Wenn ein Datensatz in die Datenbank geschrieben wird, ermittelt das System anhand der Preisspanne den entsprechenden Shard, zu dem die Daten gehören, und aktualisiert ihn entsprechend.
Obwohl die Implementierung von dynamischem Sharding einfach ist, kann ein bestimmter Shard überlastet werden, wenn er mehr Datensätze enthält als andere. Wenn im obigen Beispiel mehr Kunden Artikel mit einem Preis von über 100 $ kaufen, wird das Datenvolumen im dritten Shard größer sein als in den anderen.
Die ungleiche Verteilung kann den Zweck des Sharding zunichte machen, da nur ein einziger Shard den Großteil der Daten enthält und das System dadurch verlangsamt wird. Außerdem erfordert die Methode eine Nachschlagetabelle, die den eindeutigen Shard-Schlüssel und die entsprechenden Bereiche speichert.
Hashed Sharding
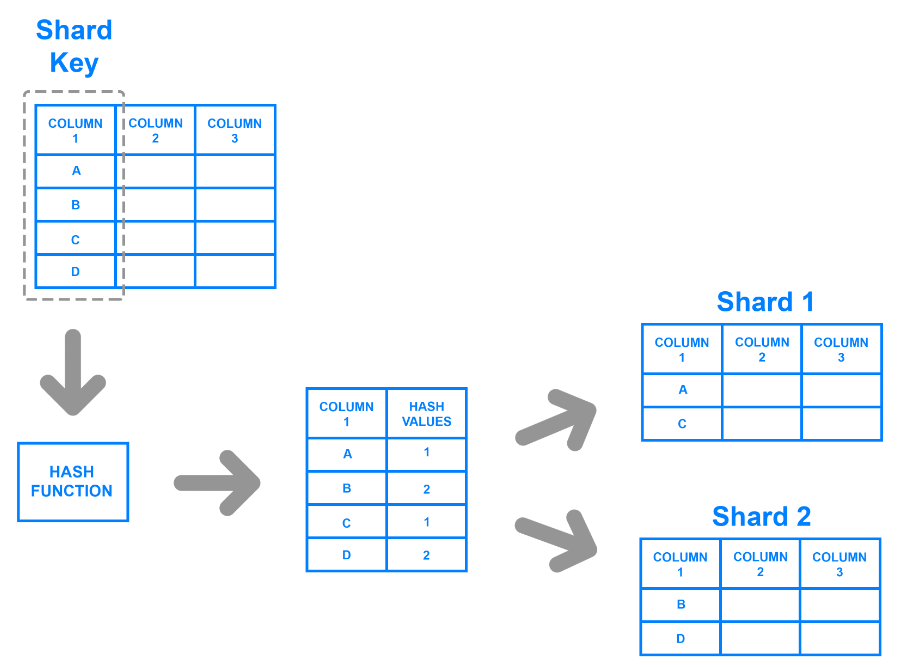
Beim Hashed Sharding wird jedem Datensatz ein Hash-Schlüssel zugewiesen, der auf einer bestimmten Spalte basiert. Entwickler erzeugen Hash-Schlüssel mit Hilfe einer Hash-Funktion, die die Werte in der Spalte als Eingabe nimmt. Sie können die Daten aufteilen, indem sie die Datensätze ermitteln, die zu einem entsprechenden Schlüssel oder Hash-Wert gehören.
Beispielsweise können Entwickler eine Spalte auswählen und deren Werte verwenden, um Hash-Werte zu erzeugen. Diese Werte können als Shard-Schlüssel für jeden Chunk dienen, und Entwickler können sie auf verschiedenen Rechnern speichern. Das folgende Diagramm veranschaulicht den Prozess.
 Hashed sharding.png
Hashed sharding.png
Hashed Sharding überwindet das Problem der ungleichmäßigen Verteilung, da die Hashing-Funktion oder der Algorithmus keinen benutzerdefinierten Shard-Schlüssel zur Partitionierung der Daten benötigt. Allerdings wird es schwierig, Daten aus einzelnen Shards abzufragen, da die Schlüssel die Daten nicht nach sinnvollen Kriterien gruppieren. Ein Algorithmus generiert die Hash-Werte nach dem Zufallsprinzip und teilt die Daten ad hoc auf.
Beim bereichsbasierten Sharding beispielsweise spiegeln die Schlüssel die Bereiche eines bestimmten Werts in der Tabelle wider und stehen in einem sinnvolleren Zusammenhang mit der Datenstruktur. [Die Abfrage von Shards (https://zilliz.com/learn/an-ultimate-guide-to-vectorizing-structured-data) auf der Grundlage von Wertebereichen ist schneller als die Abfrage von Daten auf der Grundlage von Hash-Schlüsseln.
Außerdem muss der Entwickler beim Hinzufügen weiterer Shards oder beim Upgrade des Systems den gesamten Hash-Algorithmus für alle Datensätze erneut ausführen. Dieser Prozess ist notwendig, um das Datenvolumen auf den verschiedenen Rechnern auszugleichen, kann aber erhebliche Ausfallzeiten und Rechenressourcen erfordern.
Verzeichnis-Sharding
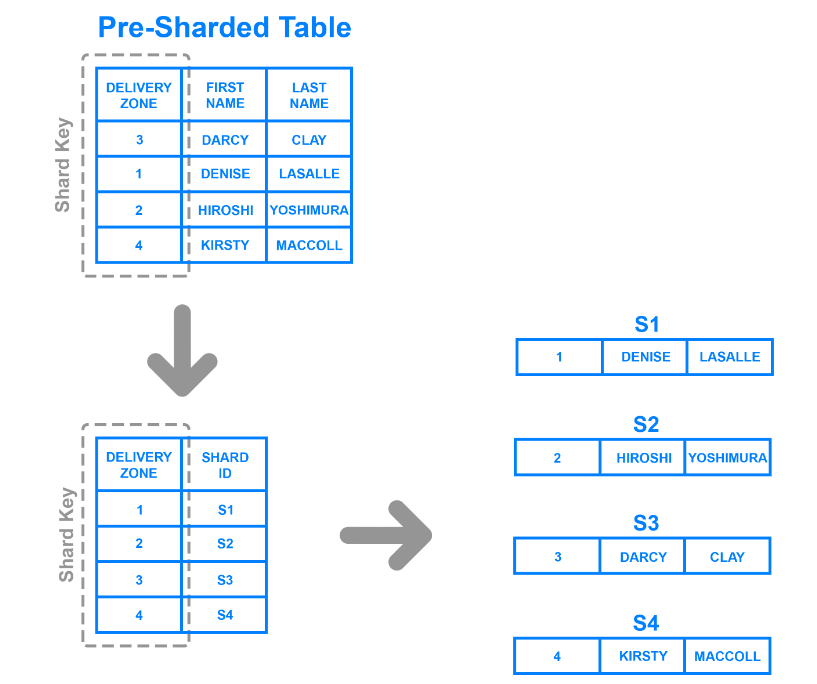
Das Directory Sharding ist flexibler als die oben beschriebenen Methoden. Es teilt die Daten auf der Grundlage der Werte einer bestimmten Spalte auf und verwendet eine Nachschlagetabelle, um festzustellen, zu welchem Shard ein Datensatz gehört.
 Verzeichnis-Sharding basierend auf der Lieferzone.png
Verzeichnis-Sharding basierend auf der Lieferzone.png
Directory sharding based on delivery zone
Die Abbildung zeigt beispielsweise, wie man die Spalte "Lieferzone" als Shard-Schlüssel verwendet und die Daten nach den Zonen aufteilt, zu denen ein Kunde gehört. Mit dieser Methode werden vier verschiedene Shards erstellt, da die Tabelle vier Zonen hat.
Im Gegensatz zum bereichsbasierten Sharding sind Datenpartitionen vielseitiger, da sie sich nicht an strenge Wertebereiche halten müssen. Außerdem können die Entwickler die Shards schneller aktualisieren, da sie die Schlüssel für alle Werte einer bestimmten Spalte nicht algorithmisch erzeugen müssen.
Allerdings erfordert diese Technik eine Nachschlagetabelle, um eingehende Anfragen zu bearbeiten, was die Verarbeitungsgeschwindigkeit verlangsamt. Außerdem kann die Auswahl einer Spalte, die zu einer großen Anzahl von Shards führt, die Größe der Nachschlagetabelle und die Latenzzeit erheblich erhöhen.
Auswählen eines Shard-Schlüssels
Für ein effizientes Sharding von Datenbanken müssen die Entwickler einen geeigneten Sharding-Schlüssel festlegen, um eine gleichmäßige Verteilung der Daten auf die Shards zu gewährleisten. Bei einer ungleichmäßigen Verteilung können bestimmte Shards zu Daten-Hotspots werden, die mehr Daten enthalten als andere.
Der Shard-Schlüssel muss außerdem den Abfrageprozess vereinfachen, um die Verarbeitungsgeschwindigkeit zu erhöhen und Ausfallzeiten zu vermeiden. Darüber hinaus hängt die Bestimmung eines geeigneten Shard-Schlüssels von der Auswahl der richtigen Spalte ab.
In der folgenden Liste sind drei wichtige Faktoren aufgeführt, die Entwickler bei der Auswahl der am besten geeigneten Spalte für die Generierung des Shard-Schlüssels berücksichtigen können.
- Kardinalität: Die Kardinalität gibt die maximale Anzahl von Shards an, die ein Entwickler auf der Grundlage unterschiedlicher Werte in einer Spalte erstellen kann. Wenn beispielsweise eine Spalte mit drei unterschiedlichen Werten ausgewählt wird, ergeben sich drei Shards. Verzeichnisbasiertes Sharding ist hilfreich, wenn die Kardinalität einer Spalte gering ist.
- Häufigkeit: Die Häufigkeit bezieht sich auf den Prozentsatz der Daten, die zu einem bestimmten Shard-Schlüssel gehören. Bei der bereichsbasierten Aufteilung auf der Grundlage von Preisen können beispielsweise bestimmte Preisbereiche etwa 80 % der gesamten Datensätze enthalten, was zu einem Daten-Hotspot führt.
- Dynamische Shards: Das Datenvolumen in dynamischen Shards ändert sich, wenn sich die Nachfrage nach einer Anwendung ändert. Wenn die Anwendung beispielsweise immer beliebter wird, kann sich die Benutzerdemografie ändern, und die Anmeldungen von Kunden im Alter von 20 bis 25 Jahren können zunehmen. Eine bereichsbasierte Aufteilung auf der Grundlage des Alters kann zu einem Daten-Hotspot führen, da mehr Daten in dem Shard vorhanden sind, der dem Altersbereich 20-25 Jahre entspricht.
Um ein effektives Datenbank-Sharding zu gewährleisten, müssen die Entwickler die Kardinalität und Häufigkeit eines Shard-Schlüssels berücksichtigen und bestimmen, ob er zu dynamischen Shards führt.
Vergleich mit Alternativen
Datenbank-Sharding ist eine Methode zur Skalierung von Datenbanken. Andere Methoden sind vertikale Skalierung, Replikation und Partitionierung. Wenn Sie verstehen, wie sich diese von Sharding unterscheiden, können Sie die richtige Skalierungsmethode für bestimmte Szenarien wählen.
Vertikale Skalierung
Bei der vertikalen Skalierung wird die Kapazität eines bestehenden Servers aufgerüstet. Entwickler können zusätzliche CPUs, Festplatten und andere Software installieren, um die Leistung zu verbessern.
Diese Methode ist hilfreich, wenn ein einzelner Rechner für die Bearbeitung von Benutzeranfragen ausreicht und nur schrittweise Verbesserungen zur Leistungssteigerung erforderlich sind.
Sie ist zwar weniger kostspielig als das Sharding, erhöht aber die Serverkapazität nur in begrenztem Maße, da nur ein einziger Rechner für die Bearbeitung von Benutzeranfragen zur Verfügung steht.
Replikation
Bei der Replikation erstellen die Entwickler Kopien derselben Datenbank und speichern sie auf mehreren Computern. Wie das Sharding gewährleistet diese Methode eine hohe Verfügbarkeit, da bei einem Ausfall eines Computers die anderen aktiv bleiben.
Sharding und Replikation sind ähnlich, da sie die Verarbeitung auf mehrere Rechner verteilen. Beim Sharding werden die Daten jedoch in verschiedene Brocken aufgeteilt, während bei der Replikation die gesamten Daten kopiert werden, ohne sie zu zerlegen.
Sharding ist eher für große Datenbanken geeignet, während die Replikation Server mit hoher Speicherkapazität erfordert. Die Pflege und Aktualisierung der einzelnen Replikate auf verschiedenen Rechnern ist kostspielig und zeitaufwändig.
Partitionierung
Bei der Partitionierung wird eine Datenbank in mehrere Gruppen aufgeteilt und auf einem einzigen Rechner gespeichert. Diese Methode eignet sich, wenn Sie die Abfrageleistung verbessern wollen und die Datenbank nicht groß genug ist, um die Speicherung von Partitionen auf verschiedenen Rechnern zu rechtfertigen.
Sie kann zur Optimierung der Datenarchivierung beitragen, da die Entwickler die Daten nach Datum und Uhrzeit partitionieren können. Sie können bestimmte Datensätze mit Zeitstempeln, die älter als ein bestimmter Schwellenwert sind, in eine Archivierungstabelle verschieben und eine andere Tabelle zur Speicherung der neuesten Datensätze verwenden.
Vorteile von Database Sharding
Das Sharding von Datenbanken ist eine wertvolle Strategie für eine effiziente Datenverwaltung. Unternehmen, die für den Betrieb ihrer Websites, Anwendungen und anderer datengesteuerter Software auf umfangreiche Daten angewiesen sind, müssen Sharding einsetzen, um den Nutzen ihrer Datenbanktechnologie zu maximieren.
In der folgenden Liste werden einige der Vorteile, die Sharding Unternehmen bietet, näher erläutert.
Skalierbarkeit: Durch die Aufteilung der Daten auf mehrere Rechner können Unternehmen ihre Datenbanksysteme effizienter skalieren, um steigende Arbeitslasten zu unterstützen.
Minimale Ausfallzeiten: Sharding gewährleistet eine hohe Verfügbarkeit, da es auf einer Shared-Nothing-Architektur basiert. Diese Strategie ermöglicht eine bessere Benutzererfahrung, da der Ausfall eines Rechners die Leistung der anderen nicht beeinträchtigt.
Einfaches Upgrade: Die Implementierung von Leistungsupgrades ist effizienter, da die Entwickler einzelne Maschinen separat aktualisieren können, ohne das gesamte System herunterfahren zu müssen.
Herausforderungen von Database Sharding
Obwohl Sharding erhebliche Vorteile bietet, können Entwickler mit einigen Herausforderungen konfrontiert werden, die die Komplexität der Implementierung erhöhen. In der folgenden Liste werden diese Probleme mit möglichen Abhilfestrategien aufgeführt.
Ungleichmäßige Verteilung: Die Ungewissheit über das Datenvolumen und die Datenvielfalt kann zum Auftreten von Hotspots führen. Trotz eines effektiven Scherbenschlüssels kann sich die Art der Daten ändern, so dass die Entwickler einen neuen Schlüssel auswählen oder erstellen müssen. Die Entwickler müssen die Eignung von Datenbank-Sharding in bestimmten Szenarien sorgfältig prüfen. Es ist möglich, dass eine Replikation oder vertikale Skalierung in verschiedenen Situationen praktischer ist als Sharding.
Komplexe Verwaltung: Die Verwaltung mehrerer Rechner ist komplex, da die Entwickler den Zustand jedes Knotens ständig überwachen müssen, um Probleme schnell zu erkennen und zu beheben. Robuste Überwachungssysteme mit Echtzeit-Warnmechanismen können dazu beitragen, diese Probleme zu entschärfen, indem sie die zuständigen Teams im Falle von Serverausfällen benachrichtigen.
Wartungskosten: Die Wartung mehrerer lokaler Server ist kostspielig und erfordert zusätzliches Personal mit einschlägigem Fachwissen, um Probleme während der Wartung zu beheben. Unternehmen können auf eine [Cloud-Infrastruktur] (https://zilliz.com/blog/zilliz-cloud-available-in-11-regions-across-3-major-cloud-providers) migrieren, um verschiedene Shards zu hosten, und den Cloud-Anbieter im Hintergrund regelmäßige Wartungsprüfungen durchführen lassen.
Datenbank-Sharding Anwendungsfälle
Obwohl in den obigen Abschnitten die Anwendungsfälle, in denen Sharding vorteilhaft ist, kurz beleuchtet wurden, werden diese Szenarien in der folgenden Liste kategorisiert und näher erläutert.
Große Webanwendungen: E-Commerce-Websites mit einer großen Nutzerbasis, Social-Media-Plattformen, Car-Hailing-Apps und Gaming-Websites sind ideale Kandidaten für Datenbank-Sharding. Sharding kann den Administratoren solcher Websites helfen, die Last effektiver auszugleichen und Ausfallzeiten während der Spitzenzeiten zu vermeiden.
Big-Data-Analytik: Für Benutzer, die große Datenmengen analysieren, kann Sharding die Verarbeitungsgeschwindigkeit verbessern, indem die Last auf mehrere Server verteilt wird.
Content Delivery Networks (CDNs): Ein CDN ist eine Gruppe von Servern, die über verschiedene Standorte verteilt sind, um Anfragen von Nutzern in nahe gelegenen geografischen Gebieten zu bearbeiten. Entwickler können Datenbanken nach den Standorten der Benutzer aufteilen und die Daten auf diese Server verteilen, um die Antwortzeiten zu verkürzen.
FAQs über Datenbank-Sharding
- Was ist der Unterschied zwischen Sharding und Partitionierung?
Während beim Sharding und bei der Partitionierung Daten in kleinere Chunks aufgeteilt werden, wird beim Sharding jeder Chunk auf verschiedene Rechner oder Knoten verteilt. Im Gegensatz dazu wird bei der Partitionierung jedes Chunk auf einem einzigen Rechner gespeichert.
- Was ist der Unterschied zwischen Sharding und Replikation?
Die Replikation kopiert die gesamte Datenbank und speichert sie auf verschiedenen Rechnern. Im Vergleich zum Sharding, bei dem die Datenbank in Zeilen aufgeteilt und jeder Teil auf mehreren Servern gespeichert wird, bietet die Replikation eine höhere Verfügbarkeit, erfordert aber mehr Rechenressourcen und Speicherkapazität.
- Wie wählt man den richtigen Shard-Schlüssel aus?
Bei der Auswahl eines geeigneten Shard-Schlüssels müssen die Entwickler die richtige Spalte für die Aufteilung der Daten bestimmen. Ein Shard-Schlüssel muss eine geringe Kardinalität und gleiche Häufigkeit aufweisen.
Die Kardinalität bezieht sich auf die maximale Anzahl von Shards, die je nach Spaltenwert möglich sind. Wird beispielsweise eine Spalte ausgewählt, die vier verschiedene Werte enthält, so ergeben sich vier Shards. Die Häufigkeit bezieht sich auf den Anteil der Daten, die jeder Shard enthält.
Wählen oder erstellen Sie außerdem Shards, die während des gesamten Lebenszyklus der Anwendung statisch bleiben. Shards, deren Datenvolumen sich wahrscheinlich ändern wird, können zu Hotspots führen, wobei einige Shards mehr Volumen erhalten als andere.
- Welches sind die größten Herausforderungen beim Sharding von Datenbanken?
Datenbank-Sharding erhöht den Abfrage-Overhead, da Entwickler Abfragen schreiben müssen, um auf Daten von mehreren Rechnern zuzugreifen und Analysen durchzuführen.
Es erhöht auch die Infrastrukturkosten, da Unternehmen mehrere Server warten und deren Zustand überwachen müssen, um Ausfälle zu vermeiden.
Auch die Aktualisierung und der Ausgleich von Shards ist komplex, wenn Datenvolumen und -vielfalt zunehmen. Eine Sharding-Technik, die in einer bestimmten Situation geeignet ist, kann in anderen Situationen nicht mehr praktikabel sein.
- Ist Datenbank-Sharding für kleine Anwendungen geeignet?
Obwohl Datenbank-Sharding eine wertvolle Technik zur Verbesserung der Verarbeitungsgeschwindigkeit und des Durchsatzes ist, ist sie für kleine Anwendungen ungeeignet. Es ist nur dann sinnvoll, wenn das Datenvolumen einen Punkt erreicht, an dem es nicht mehr tragbar ist, eine einzige Datenbank auf einem einzigen Server zu unterhalten.
Verwandte Ressourcen
Obwohl Entwickler Sharding normalerweise auf strukturierte Datensätze anwenden, helfen Ihnen die folgenden Ressourcen, das Konzept im Kontext von [unstrukturierten Daten] (https://zilliz.com/learn/introduction-to-unstructured-data) und [Vektordatenbanken] (https://zilliz.com/learn/what-is-vector-database) zu verstehen:
Sharding, Partitionierung und Segmente - Holen Sie das Beste aus Ihrer Datenbank
Bereitstellung von Vektordatenbanken in Multi-Cloud-Umgebungen
Anatomie eines Cloud-nativen Vektordatenbank-Managementsystems](https://zilliz.com/blog/anatomy-of-a-cloud-native-vector-database-management-system)
Was sind Vektordatenbanken und wie funktionieren sie? ](https://zilliz.com/learn/what-is-vector-database)
Generative KI Ressource Hub | Zilliz](https://zilliz.com/learn/generative-ai)
Was ist RAG? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
- Was ist Datenbank-Sharding?
- Wie funktioniert das Sharding von Datenbanken?
- Sharding-Methoden
- Auswählen eines Shard-Schlüssels
- Vergleich mit Alternativen
- Vorteile von Database Sharding
- Herausforderungen von Database Sharding
- Datenbank-Sharding Anwendungsfälle
- FAQs über Datenbank-Sharding
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren