




Datenbank-Denormalisierung: Ein umfassender Leitfaden

Datenbank-Denormalisierung: Ein umfassender Leitfaden
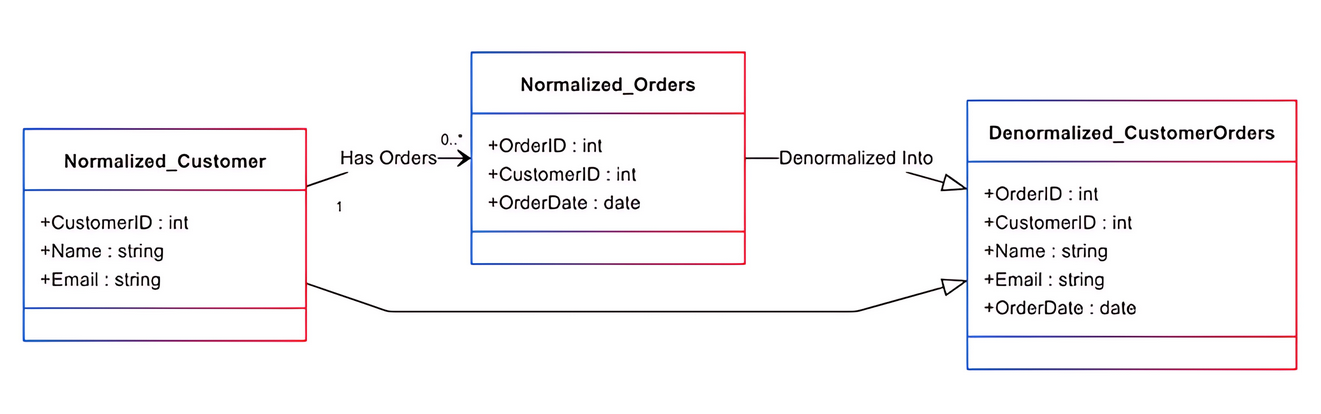
Abbildung 1: Illustration der Datenbank-Denormalisierung
Warum verarbeiten manche Datenbanken Abfragen schneller als andere, selbst wenn sie große Informationsmengen bewältigen müssen? Die Antwort liegt in der Indizierung, der Abfrageoptimierung und der Speicherarchitektur der Datenbank. Schneller Datenabruf ist entscheidend, da er die Leistung, die Benutzererfahrung und die Gesamteffektivität verbessert.
Traditionelle Datenbanknormalisierung erhält die Datenintegrität, indem sie Daten in Tabellen mit klar definierten Beziehungen organisiert. Während Normalisierung die Datengenauigkeit verbessert, führt sie in Systemen, die viele Joins verwenden, tendenziell zu einem Leistungsengpass. Bei so vielen Tabellen und Joins wird es schwieriger, die Daten abzurufen, wodurch die Reaktionsfähigkeit der Anwendung verlangsamt wird.
Eine Technik zur Optimierung der Datenbankleistung ist die Denormalisierung. Denormalisierung führt redundante Daten in die Datenbank ein, um leseintensive Lasten zu optimieren. Dadurch wird die Notwendigkeit komplexer Joins reduziert und somit die Abfrageleistung verbessert.
Dieser Leitfaden erklärt das Konzept der Datenbank-Denormalisierung, vergleicht es mit der Normalisierung und erörtert ihre Vorteile. Außerdem zeigen wir die Anwendungsfälle auf, in denen Datenbank-Denormalisierung vorteilhaft ist, sowie die Herausforderungen, denen Unternehmen bei ihrer Implementierung begegnen könnten.
Was ist Datenbank-Denormalisierung?
Datenbank-Denormalisierung ist eine Optimierungstechnik, die einem zuvor normalisierten Schema doppelte Daten hinzufügt. Diese Technik verbessert die Leseleistung, indem sie Abfragen vereinfacht und die Anzahl der Joins reduziert.
Normalisierte Datenbanken leiden unter mehreren Joins, um Daten zwischen verschiedenen Tabellen abzurufen, wodurch sie bei der Arbeit mit großen Datensätzen langsam werden. Die Denormalisierungstechnik ist in Systemen nützlich, die eher Leseoperationen als Schreiboperationen ausführen.
Nehmen wir zum Beispiel an, eine normalisierte Datenbank enthält drei separate Tabellen für Kunden, Bestellungen und Produkte. Das Abrufen der Bestellhistorie eines Kunden mit Produktdetails erfordert, dass die Datenbank mehrere Tabellen verknüpft und Daten aus Kunden, Bestellungen und Produkten kombiniert. Ein denormalisiertes Schema kombiniert zusammengehörige Daten, wie Produktdetails, in einer Tabelle, um Joins zu minimieren und die Leseleistung zu verbessern.
Ein Leistungsschub für Leseoperationen geht jedoch zulasten der Schreiboperationen. Konsistente Datenaktualisierungen werden komplexer, da die Datenbank redundante Informationen verwalten muss.
Wie es funktioniert
Der Denormalisierungsprozess transformiert normalisierte Datenbanken durch Umstrukturierung, um die Geschwindigkeit und Leistung von Abfragen und Datenabrufen zu verbessern. Während der Normalisierungsprozess Duplikate eliminiert und gleichzeitig die Datenkonsistenz aufrechterhält, fügt die Denormalisierung gezielt doppelte Daten hinzu, um Leseoperationen in Anwendungen zu beschleunigen.
Datenbanken, die Echtzeit-Reporting, Hochgeschwindigkeitsabfragen und Analysen benötigen, setzen diese Technik weitverbreitet ein. Im Folgenden besprechen wir Denormalisierungsansätze und ihre Auswirkungen auf die Effektivität von Datenbanken.
 Ansätze der Datenbank-Denormalisierung
Ansätze der Datenbank-Denormalisierung
Abbildung 2: Ansätze der Datenbank-Denormalisierung
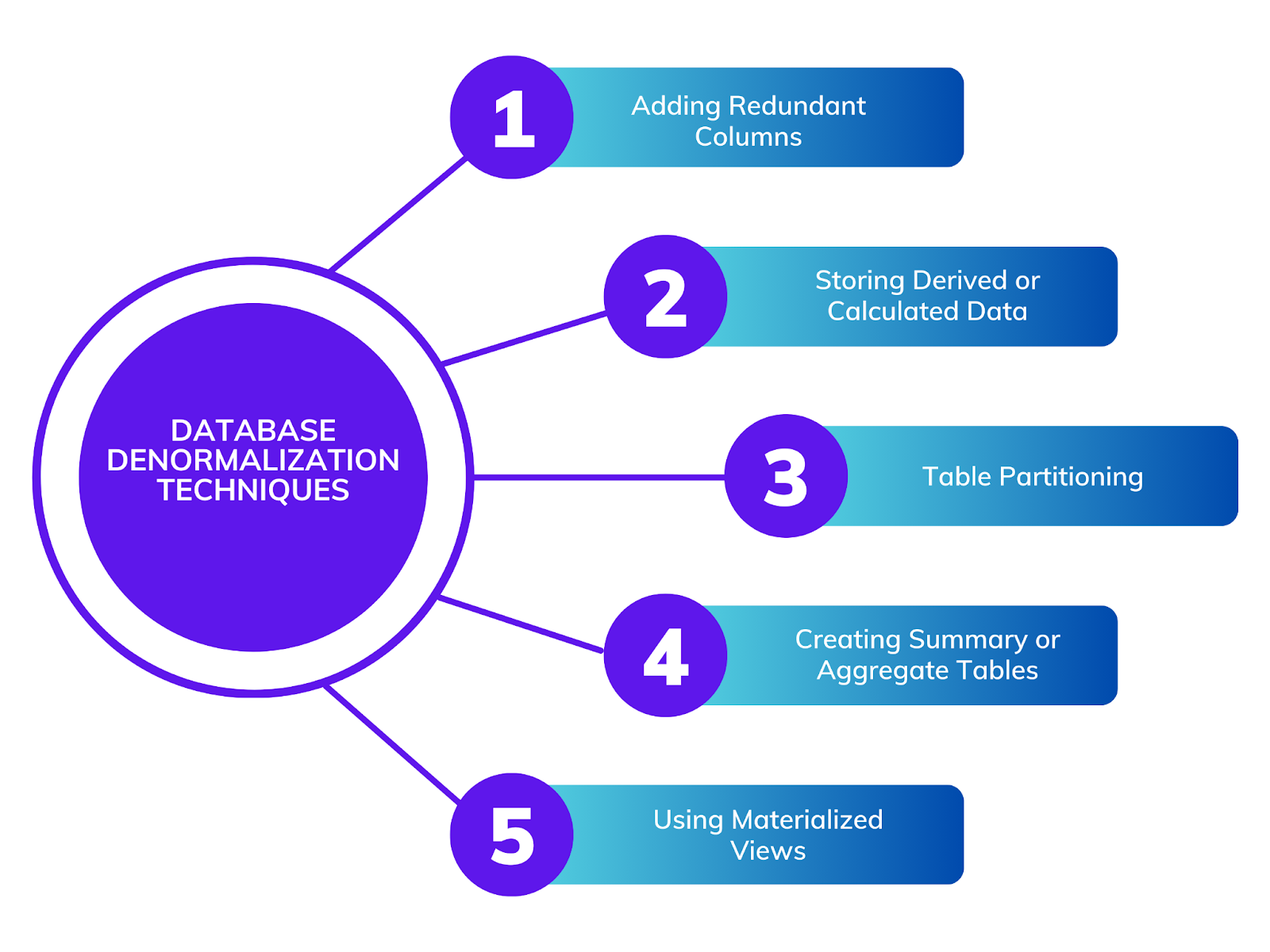
Hinzufügen redundanter Spalten
Das Hinzufügen redundanter Spalten ist eine einfache und gängige Methode der Denormalisierung. Dabei werden Daten an mehreren Stellen hinzugefügt, um Join-Operationen zu reduzieren. Zum Beispiel hat die Bestelltabelle einer Datenbank einen Fremdschlüssel namens ID, der sie mit der Kundentabelle verbindet. Die Kundentabelle enthält wesentliche Details zu jedem Kunden, wie Name, ID und Kontaktinformationen.
Wenn Kundenauftragsdetails analysiert werden, ist eine Join-Operation erforderlich, um Kundendaten zu extrahieren. Das Verknüpfen von Tabellen kann besonders kostspielig sein und die Gesamtleistung verlangsamen. Wenn die Kundeninformationen in der Auftragstabelle gespeichert sind, entfällt die Notwendigkeit eines Joins, und dies führt zu einer effizienten Datenabfrage.
Obwohl diese Methode die Geschwindigkeit von Abfragen erheblich verbessert, erhöht sie die Kosten durch Datenredundanz. Wenn sich Kundendaten ändern, müssen alle redundanten Kopien aus Konsistenzgründen aktualisiert werden. Dies erfordert die Optimierung der Leistung und die Verwaltung der Datenintegrität durch Aktualisierungen oder Trigger. Das Ausbalancieren dieses Problems kann mithilfe klar definierter Aktualisierungsprozesse umgesetzt werden.
Speichern abgeleiteter oder berechneter Daten
Eine weitere Methode der Denormalisierung ist das Speichern und Vorberechnen häufiger Berechnungen. In einem normalisierten Datenbanksystem werden Berechnungen dynamisch zur Abfragezeit durchgeführt. Während dies garantiert, dass die Werte aktuell sind, wirkt es sich auch negativ auf die Rechenlast aus.
Die Systemleistung leidet beim Umgang mit großen Datensätzen oder zahlreichen Abfrageanforderungen. Die Leistung kann jedoch verbessert werden, indem diese Werte als zusätzliche Spalten innerhalb bestehender Tabellenzeilen hinzugefügt werden.
Zum Beispiel kann die Datenbank Gesamtbestellbeträge in der Auftragstabelle vorab speichern, sodass Benutzer diese Informationen nicht neu berechnen müssen, wenn sie ihre Bestellhistorie anfordern. Das Datenbanksystem kann den Wert ohne zusätzliche Verarbeitung liefern, da diese Werte bereits gespeichert sind.
Diese Technik ist im Finanzsektor, im E-Commerce und in BI-Systemen von Vorteil, die ein hohes Datenvolumen aufweisen, das aggregierte und komplexe Berechnungen erfordert. Die Integrität vorab berechneter Werte zu wahren, ist jedoch entscheidend. Dies macht anschließend regelmäßige Aktualisierungen oder Trigger-Aktivierungen basierend auf Änderungen in den Daten erforderlich.
Tabellenpartitionierung
Tabellenpartitionierung ist ein zentraler Denormalisierungsansatz, der große Tabellen in Partitionen aufteilt, um die Abfrageverarbeitung und die Geschwindigkeit des Datenabrufs zu verbessern. Sie liefert außergewöhnliche Ergebnisse bei der Verarbeitung umfangreicher Datenbanken, die Transaktionsprotokolle, Audit-Aufzeichnungen und historische Datensätze enthalten. Sie wird weiter in zwei Teile unterteilt:
Horizontale Partitionierung: Die Partitionierungstechnik unterteilt eine Tabelle anhand von Kriterien wie Datumsparametern, geografischen Gebieten und Benutzergruppen in kleinere Partitionen. Zum Beispiel kann ein Online-Händler mit Millionen von Verkaufstransaktionen seine Auftragstabelle nach jährlichen Partitionen aufteilen. Die Leistung verbessert sich, wenn Abfragen aktuelle Transaktionen benötigen, da sie einen reduzierten Datenteilbestand statt der vollständigen Tabelle durchsuchen müssen.
Vertikale Partitionierung: Die vertikale Partitionierung funktioniert anders als die horizontale Partitionierung, da sie Tabellen in unterschiedliche spaltenbasierte Abschnitte trennt. Sie teilt Tabellen in zwei Teile, indem häufig abgerufene Spalten neben weniger häufig abgerufenen platziert werden, sodass Abfragen nur die notwendigen Daten abrufen müssen. Der Ansatz erweist sich als vorteilhaft für breite Tabellen mit zahlreichen Attributen, da er Abfragen ermöglicht, nur auf wesentliche Felder zuzugreifen.
Beide Partitionierungsmethoden verbessern die Speicheroptimierung und reduzieren die Abfrageausführungszeit, wodurch sie einen erheblichen Mehrwert für Hochleistungsdatenbanken bieten. Die Methoden erhöhen jedoch die Komplexität der Indizierung und Partitionierung und können zu Ineffizienzen bei Abfragen führen, wenn keine geeigneten Strategien durchgesetzt werden.
Erstellen von Zusammenfassungs- oder Aggregattabellen
Anwendungen zur Berichterstellung und Datenanalyseverarbeitung extrahieren häufig Echtzeit-Zusammenfassungsstatistiken aus Rohdaten. Dies erfordert typischerweise erhebliche Rechenleistung. Daher besteht ein Ansatz darin, Tabellen zu aggregieren. Anstatt neu zu berechnen, kann eine Zusammenfassungstabelle als Speicherpunkt verwendet werden, wodurch sofortiger Zugriff auf voraggregierte Daten ermöglicht wird.
Stellen Sie sich ein Einzelhandelsunternehmen vor, das die Verkaufsleistung über mehrere Regionen hinweg analysiert. Die Erstellung einer Übersichtstabelle mit den pro Monat aggregierten Gesamtverkäufen für jede Region würde es erleichtern, übergeordnete Erkenntnisse zu gewinnen.
Diese Tabelle könnte in Echtzeit, über Trigger oder mit geplanten Batch-Updates aktualisiert werden. Die Übersichtstabelle ermöglicht eine schnellere Abfrageausführung, da sie weniger Zeilen enthält als die ursprüngliche Transaktionstabelle, was die Reaktionsfähigkeit von Dashboards und Berichten verbessert.
Während diese Methode übergeordnete Erkenntnisse verbessert, erfordert sie auch einen starken Mechanismus zur Datenaktualisierung. Batch-Verarbeitung oder ETL-Pipelines können die Speicherung aktueller Übersichtsdaten sicherstellen.
Verwendung von Materialized Views
Materialized Views sind eine fortschrittliche Optimierungsfunktion, die physische Datenbankobjekte erstellt, welche die Ergebnisse der Abfrageausführung enthalten. Standard-Views erfordern bei jedem Zugriff eine dynamische Abfrageausführung. Materialized Views speichern ihre Daten jedoch auf der Festplatte, sodass Benutzer Informationen sofort ohne weitere Verarbeitung abrufen können.
Nehmen wir das Beispiel einer E-Commerce-Website, die Kundenkäufe überwacht. Die Betreiber der Website können eine Materialized View erstellen, die die Gesamtausgaben pro Kunde innerhalb mehrerer Produktkategorien verfolgt. Die Datenbank ruft vorberechnete Ergebnisse ab, anstatt Echtzeitberechnungen durchzuführen, da dieser Ansatz schnellere Abfrageantworten liefert.
Materialized Views können je nach Systemanforderungen periodisch aktualisiert oder inkrementell auf den neuesten Stand gebracht werden. Die Technik bietet außergewöhnliche Vorteile für Datenbanken, die Joins, Aggregationen und mehrstufige Transformationen erfordern.
Vergleich: Denormalisierung vs. Normalisierung
Die Wahl zwischen Normalisierung und Denormalisierung für das Datenbankdesign hängt von Anforderungen an Performance-Geschwindigkeit, Speichereffizienz und Datenkonsistenz ab. Diese Tabelle zeigt die Unterschiede zwischen Denormalisierung und Normalisierung.
| Aspekt | Normalisierung | Denormalisierung |
| Zweck | Redundanz reduzieren | Leseleistung verbessern |
| Datenstruktur | Mehrere verknüpfte Tabellen | Weniger Tabellen, redundante Daten |
| Abfragekomplexität | Komplexe Joins | Vereinfachte Abfragen |
| Am besten geeignet für | Schreibintensive Anwendungen | Leseintensive Anwendungen |
| Datenintegrität | Hoch | Potenziell beeinträchtigt |
| Speichernutzung | Effizient | Erhöht |
| Wartung | Vereinfacht | Komplexer |
| Update-Anomalien | Minimiert | Erhöhtes Risiko |
Der Auswahlprozess für die Datenbank erfordert eine Analyse der Datenabrufmuster, der Anforderungen an die Aktualisierungsgeschwindigkeit und der Systemleistungsspezifikationen. Eine richtig ausbalancierte Datenbank erhält die betriebliche Effizienz und Skalierbarkeit aufrecht.
Vorteile und Herausforderungen
Denormalisierung ist eine Optimierungsmethode, die redundante Daten hinzufügt, um Leseoperationen und die Geschwindigkeit der Abfrageausführung zu verbessern. Leistungssteigerungen können jedoch Probleme mit Speicher und Anomalien verursachen. Die Vorteile der Denormalisierung erfordern eine ausgewogene Implementierung, die das Entstehen potenzieller Risiken verhindert. Hier sind einige der Vorteile und Herausforderungen:
Vorteile der Denormalisierung
Reduzierte Anwendungskomplexität: Denormalisierung vereinfacht die Anwendungslogik, indem sie die Notwendigkeit komplexer Joins und Abfragen über mehrere Tabellen hinweg eliminiert. Dies verbessert die Lesbarkeit und Einfachheit von Abfragen und führt zu einer höheren Produktivität der Entwickler.
Verbesserte Leistung in verteilten Systemen: Das Abrufen von Daten aus mehreren Knoten in verteilten Datenbanken führt zu verzögerter Leistung. Denormalisierung platziert duplizierte Daten in der Nähe ihrer wichtigsten Zugriffspunkte. Dies verringert den Bedarf an Datenabrufen von Knoten zu Knoten. Die Technik erweist sich sowohl für cloudbasierte Systeme als auch für horizontal skalierte Architekturen als wertvoll.
Erhöhte Effizienz im Data Warehousing: Data Warehouses erfordern eine effiziente Verarbeitung analytischer Aufgaben, die komplexe Berechnungen und Aggregationsverfahren ausführen. Denormalisierung verbessert die Leseleistung, indem vorab verknüpfte oder vorab aggregierte Daten gespeichert werden, wodurch Echtzeit-Datentransformationen entfallen.
Ermöglicht Echtzeitanalysen: Anwendungen, die Analysen durchführen, benötigen unmittelbaren Zugriff auf Daten für schnelle Erkenntnisse. Denormalisierung reduziert die Notwendigkeit komplexer Echtzeitberechnungen, indem vorberechnete Werte zusammen mit redundanten Daten gespeichert werden.
Optimiertes Reporting: Denormalisierte Datenbanken halten vorverarbeitete Daten für die sofortige Berichtserstellung vor und minimieren den Bedarf an Datentransformationsvorgängen. Dieser Ansatz bietet erhebliche Vorteile für Business-Intelligence-Anwendungen und Executive-Dashboards.
Herausforderungen
Datenanomalien: Datenduplikation schafft ein höheres Risiko für Dateninkonsistenzen, da Aktualisierungen möglicherweise nicht ordnungsgemäß auf alle Systeminstanzen verteilt werden. Datenvalidierung und Konsistenzprüfungen sind in denormalisierten Systemen wichtig, um das Risiko von Anomalien zu verringern.
Erhöhte Speicherkosten: Redundante Daten erfordern zusätzlichen Speicherplatz, wodurch die Gesamtgröße der Datenbank steigt. Cloudbasierte Datenbanken, die nutzungsbasierte Preismodelle verwenden, könnten aufgrund der Speicheranforderungen höhere Kosten verursachen.
Komplexität bei der Datensynchronisierung: Die Datensynchronisierung erfordert, dass jeder Aktualisierungsvorgang alle Datenkopien gleichzeitig ändert, was zu Leistungseinschränkungen führt. Eine mangelhafte Ausführung der Datensynchronisierung erzeugt Datensätze, die Ungenauigkeiten oder veraltete Informationen enthalten.
Potenzielles Risiko von Datenintegritätsproblemen: Die unsachgemäße Ausführung von Aktualisierungen über mehrere Instanzen hinweg erzeugt inkonsistente Daten. Dies beeinträchtigt die operative Qualität und die Genauigkeit von Berichten. Systeme mit hohem Transaktionsvolumen benötigen zusätzliche Ressourcen und strenge Validierungssysteme, um die Datenintegrität aufrechtzuerhalten.
Reduzierte Flexibilität: Umgebungen mit mehreren Tabellen erschweren Schemaänderungen. Dies führt zu langsameren Entwicklungszyklen und erschwert es Organisationen, sich an neue Geschäftsanforderungen anzupassen.
Ein ordnungsgemäßes Management ist erforderlich, um Denormalisierung zu implementieren und Datenanomalien, Integritätsprobleme sowie Speicherkosten zu vermeiden. Organisationen sollten Denormalisierung auf Grundlage identifizierter Leistungsanforderungen implementieren, die den Anforderungen ihres Systems entsprechen.
Anwendungsfälle
Die Vorteile der Denormalisierung werden in bestimmten Anwendungsfällen deutlich, doch Organisationen sollten ihre Auswirkungen in unterschiedlichen Situationen verstehen. Hier sind einige der wichtigsten Anwendungsfälle:
Data Warehousing & OLAP-Systeme: Data Warehousing und OLAP-Systeme verwenden Denormalisierungsmethoden, um komplexe Abfragen und Aggregationen effizienter zu machen. Die Verwendung denormalisierter Schemata führt zu schnellerem Datenabruf, da die Notwendigkeit mehrerer Tabellen-Joins entfällt. Dies ist entscheidend für Business-Intelligence-Anwendungen und analytische Workloads.
Anwendungen mit niedriger Latenz: Denormalisierung kommt Low-Latency-Anwendungen zugute, indem sie die Zeit verkürzt, die zum Abrufen und Verarbeiten von Daten in kritischen Umgebungen wie Finanzhandelsplattformen benötigt wird.
Leseintensive Anwendungen: Anwendungen, die mehr Lese- als Schreibvorgänge durchführen, können durch den Einsatz von Denormalisierung eine bessere Leistung erzielen. Systeme wie Content-Management- und Reporting-Tools können durch das Hinzufügen duplizierter Daten eine bessere Leistung bei Leseanforderungen erzielen.
Echtzeit-Analysen: Anwendungen, die sofortige Erkenntnisse benötigen, können von Denormalisierung profitieren, indem sie auf voraggregierte Daten zugreifen. Dies reduziert die Abfrageverarbeitungszeit und ermöglicht schnelle Entscheidungen auf Basis aktueller Informationen.
FAQs
Ist Datenbank-Denormalisierung immer besser für die Leistung?
Denormalisierung in schreibintensiven Systemen führt zu Problemen mit Dateninkonsistenzen, da die Pflege redundanter Daten erhebliche Herausforderungen mit sich bringt. Sie müssen die Lese- und Schreibmuster Ihrer Anwendung bewerten, bevor Sie sich für Datenbank-Denormalisierung entscheiden.
Ersetzt Denormalisierung die Normalisierung?
Denormalisierung fungiert als zusätzlicher Schritt nach der Normalisierung, um Leistungsprobleme zu verbessern. Der Normalisierungsprozess strukturiert Daten, um Duplikation zu beseitigen und die Datenintegrität zu wahren, aber Denormalisierung führt Datenduplikate wieder ein, um die Lesegeschwindigkeit zu verbessern.
Welche Risiken birgt Denormalisierung?
Die Implementierung von Denormalisierung schafft drei Hauptrisiken: Datenredundanz, höhere Speicheranforderungen und Inkonsistenzen. Erhöhte Datenredundanz schafft potenzielle Anomalien, wenn sie unsachgemäß verwaltet wird, während eine größere Datenmenge höhere Speicherkosten erfordert.
Kann ich nur einen Teil meiner Datenbank denormalisieren?
Ja, Datenbank-Denormalisierung funktioniert, indem bestimmte Datenbankbereiche gezielt optimiert werden, um die Leistung zu verbessern. Die gezielte Implementierung ermöglicht eine bessere Leseeffizienz in bestimmten Bereichen, ohne die Verwaltbarkeit oder Integrität der Datenbank zu beeinträchtigen.
Wie halte ich die Datenkonsistenz in einer denormalisierten Datenbank aufrecht?
Eine denormalisierte Datenbank erfordert Datenbank-Trigger, Constraints und Anwendungslogik, um redundante Daten bei Aktualisierungen konsistent zu halten. Die Implementierung dieser Mechanismen erhält die Datensynchronisierung über alle Datenkopien hinweg aufrecht.
Verwandte Ressourcen
- Was ist Datenbank-Denormalisierung?
- Wie es funktioniert
- Vergleich: Denormalisierung vs. Normalisierung
- Vorteile und Herausforderungen
- Anwendungsfälle
- FAQs
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren