




Verbesserung der Effizienz des Datenflusses: Zilliz führt Upsert, Kafka Connector und Airbyte-Integration ein
In der heutigen datengesteuerten Landschaft bilden effiziente Datenaufnahme und robuste Datenpipelines das Rückgrat jedes leistungsstarken Datenbanksystems. Bei Zilliz unterstreichen unsere jüngsten Verbesserungen in diesen Bereichen – insbesondere die Einführung von Upsert, Kafka Connector und der Airbyte-Integration – unser Engagement, Entwicklern eine Vektordatenbank bereitzustellen, die durch Leistung, Vielseitigkeit und einfache Integration überzeugt. Wir haben diese neuen Ergänzungen entwickelt, um die Datenverarbeitung zu optimieren, eine nahtlose Integration und eine verbesserte Kontrolle über den Datenfluss zu bieten und Entwicklern dadurch zu ermöglichen, sich auf die Erstellung innovativer Anwendungen zu konzentrieren, ohne den Aufwand für die Verwaltung komplexer Datenaufnahmeprozesse.
Optimierung von Datenaktualisierungen mit Upsert
In früheren Milvus-Versionen umfasste das Aktualisieren von Daten in vielen Anwenderszenarien einen zweistufigen Prozess: löschen, dann einfügen. Diese Methode war zwar funktional, hatte jedoch bemerkenswerte Nachteile, vor allem die Unfähigkeit, Datenatomizität und betriebliche Zweckmäßigkeit sicherzustellen. In Anerkennung dieser Herausforderungen haben wir Upsert in Milvus 2.3 eingeführt und damit grundlegend verändert, wie Datenaktualisierungen gehandhabt werden. Wir freuen uns, dass Upsert nun in Zilliz Cloud als Public Preview verfügbar ist.
Upsert vereinfacht den Aktualisierungsprozess: Wenn Daten im System nicht vorhanden sind, werden sie eingefügt; wenn sie vorhanden sind, werden sie aktualisiert. Dieser Ansatz basiert auf dem entscheidenden Konzept der Atomizität und stellt sicher, dass Upsert-Operationen nach außen als eine einzige Aktion wahrgenommen werden, unabhängig davon, ob sie eine Einfügung oder Löschung umfassen.
Intern ist diese Methode unkonventionell, aber äußerst effektiv – wir fügen zuerst ein und löschen anschließend. Diese Abfolge ist entscheidend, um die Datensichtbarkeit während des Vorgangs aufrechtzuerhalten, insbesondere in einem System wie Milvus, in dem Einfügungen und Löschungen in verschiedenen Segmenten verarbeitet werden.
Darüber hinaus ist Upsert speziell darauf ausgelegt, Änderungen am Primärschlüssel mit sorgfältiger Berücksichtigung zu handhaben. Die Primärschlüsselspalte kann während einer Aktualisierung nicht geändert werden, was damit übereinstimmt, wie Milvus Daten über Shards hinweg basierend auf dem Primärschlüssel-Hash verwaltet. Diese Einschränkung vermeidet die Komplexitäten und potenziellen Inkonsistenzen von shardübergreifenden Operationen.
Die Verwendung von Upsert ist unkompliziert und ähnelt in vielerlei Hinsicht der Insert-Operation. Entwickler können Upsert mit minimalen Anpassungen problemlos in ihre bestehenden Workflows integrieren. Zum Beispiel kann in SDKs wie Pymilvus der Upsert-Befehl ähnlich wie Insert aufgerufen werden, was denjenigen, die mit der Plattform vertraut sind, eine nahtlose Erfahrung bietet.
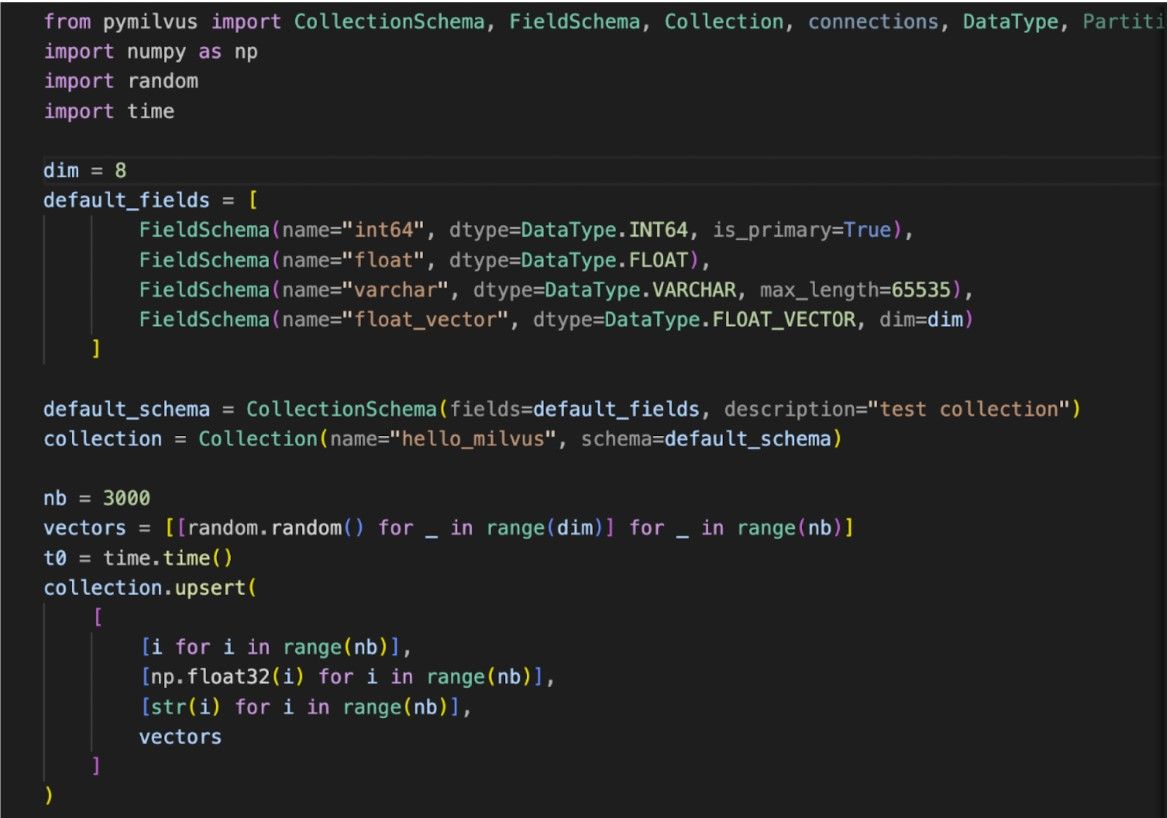
Bei der Ausführung liefert Upsert Rückmeldungen über den Erfolg der Operation und die Anzahl der betroffenen Zeilen, was die Benutzerfreundlichkeit für Entwickler weiter erhöht. Diese einfache Nutzung, gekoppelt mit der Robustheit der Operation, macht Upsert zu einem wertvollen Werkzeug im Arsenal des Datenmanagements. Weitere Details finden Sie in der Upsert-Dokumentation.
Es ist jedoch wichtig, bestimmte Überlegungen zu Upsert anzuerkennen.
AutoID-Einschränkung: Upsert erfordert, dass AutoID auf false gesetzt ist. Upsert-Operationen können nicht ausgeführt werden, wenn das Schema einer Collection AutoID auf true gesetzt hat. Diese Einschränkung besteht, weil Upsert als Aktualisierungsoperation die Übermittlung eines Primärschlüssels erfordert, um den entsprechenden Datenbatch zu aktualisieren. Es besteht ein potenzieller Konflikt, wenn ein vom Benutzer bereitgestellter Primärschlüssel mit einem von AutoID zugewiesenen Primärschlüssel kollidiert, was zum Überschreiben von Daten führen kann. Daher können Collections mit aktiviertem AutoID derzeit Upser nicht unterstützen. Zukünftige Iterationen könnten diese Einschränkung jedoch aufheben.
Performance-Overhead: Upsert kann Performance-Kosten verursachen. Milvus verwendet eine Write-Ahead-Logging-(WAL-)Architektur, und übermäßige Löschvorgänge können zu Performance-Einbußen führen. Dies liegt daran, dass Löschoperationen in Milvus Daten nicht sofort löschen. Stattdessen markieren sie die Daten mit einem Löschdatensatz. Dieser Datensatz wird erst später während eines Kompaktierungsprozesses verarbeitet, und die Daten werden entfernt. Daher können häufige Löschvorgänge zu Datenaufblähung führen und die Performance beeinträchtigen. Es wird empfohlen, Upsert nicht übermäßig oder missbräuchlich zu verwenden, um eine optimale Performance zu gewährleisten.
Während wir weiter voranschreiten, werden im Rahmen unserer kontinuierlichen Bemühungen, unsere Datenverwaltungsfunktionen zu verfeinern und weiterzuentwickeln, weitere neue Funktionen wie Upsert veröffentlicht, um sicherzustellen, dass Entwickler mit den Tools ausgestattet sind, die für eine effiziente und effektive Datenverarbeitung erforderlich sind.
Echtzeit-Datenlösungen mit Kafka Connector ermöglichen
Wir haben kürzlich den Kafka Sink Connector mit Open-Source-Milvus und Zilliz Cloud angekündigt. Diese Entwicklung ermöglicht nahtloses Echtzeit-Streaming von Vektordaten aus Confluent/ Kafka in Milvus- oder Zilliz-Vektordatenbanken. Diese Integration ist entscheidend, um die Leistungsfähigkeit unstrukturierter Daten zu nutzen und die Fähigkeiten von Echtzeit-Generativer KI zu verbessern, insbesondere mit fortschrittlichen Modellen wie OpenAI’s GPT-4.
Die Zusammenarbeit zwischen Zilliz und Confluent stellt einen bedeutenden Fortschritt bei der Verwaltung und Nutzung des ständig wachsenden Volumens unstrukturierter Daten dar, die inzwischen über 80 % der neu erstellten Informationen ausmachen. Durch die Ermöglichung von Echtzeit-Vektordaten-Streaming bieten wir eine robuste Lösung, um diese Daten effizient zu speichern, zu verarbeiten und leicht durchsuchbar zu machen.
Beispielhafte Anwendungsfälle mit diesem Connector umfassen:
Verbesserung Generativer KI: Die Bereitstellung aktueller Vektordaten für GenAI-Anwendungen ermöglicht genauere und zeitnahe Erkenntnisse. Dies ist besonders vorteilhaft in Branchen wie Finanzen und Medien, in denen das Streaming von Vektoreinbettungen aus verschiedenen Datenquellen entscheidend ist.
Optimierung von E-Commerce-Empfehlungen: Mit Echtzeit-Updates zu Bestand und Kundenverhalten können E-Commerce-Plattformen ihre Empfehlungen dynamisch anpassen und so die Benutzererfahrung verbessern.
Der Einstieg in diese Integration ist unkompliziert:
Laden Sie den Kafka Sink Connector von GitHub oder Confluent Hub herunter.
Konfigurieren Sie Ihre Confluent- und Zilliz-Konten und stellen Sie sicher, dass die Feldnamen auf beiden Plattformen übereinstimmen.
Laden und konfigurieren Sie den Connector gemäß den detaillierten Anweisungen in unserem GitHub-Repository.
Starten Sie den Connector und erleben Sie Echtzeit-Datenstreaming von Kafka zu Zilliz.
Für eine ausführliche Anleitung zur Einrichtung, zu Anwendungsfällen und Schritt-für-Schritt-Anweisungen empfehlen wir Ihnen, unser GitHub-Repository zu besuchen und unsere Confluent-Integrationsseite zu erkunden.
Effiziente Datenintegration mit Airbyte Integration erleichtern
Wir haben kürzlich mit dem Airbyte-Team zusammengearbeitet, um Airbyte in Milvus zu integrieren, wodurch die Datenaufnahme und -nutzung in Large Language Models (LLMs) und Vektordatenbanken transformiert werden. Diese Integration verbessert die Speicherung, Indexierung und Suche von hochdimensionalen Vektordaten, was für Anwendungen wie generative Chat-Antworten und Produktempfehlungen entscheidend ist.
Wichtige Highlights der Integration:
Effiziente Datenübertragung: Airbyte überträgt Daten nahtlos aus verschiedenen Quellen in Milvus/ Zilliz, ermöglicht die spontane Berechnung von Vektoreinbettungen und optimiert die Datenverarbeitung.
Erweiterte Suchfunktionalität: Diese Integration verbessert die Fähigkeiten der semantischen Suche innerhalb von Vektordatenbanken. Durch die Nutzung von Einbettungen kann das System automatisch eng verwandte Inhalte auf der Grundlage semantischer Ähnlichkeit identifizieren und präsentieren, was für Anwendungen, die eine effiziente Abfrage aus unstrukturierten Daten benötigen, von unschätzbarem Wert ist.
Einfacher Einrichtungsprozess: Das Einrichten eines Milvus-Clusters und die Konfiguration von Airbyte für die Datensynchronisierung sind unkompliziert, ebenso wie das Erstellen von Anwendungen mit Streamlit und der OpenAI Embedding API, falls gewünscht.
Diese Integration optimiert die Datenübertragung und -verarbeitung und eröffnet neue Möglichkeiten für KI-gesteuerte Echtzeitanwendungen. Beispielsweise kann die Integration dieser Technologie in Kundensupportsystemen intelligente Supportformulare mithilfe semantischer Suche erstellen. Dadurch kann das System den Nutzern sofort relevante Informationen bereitstellen, den Bedarf an direktem Eingreifen durch Supportmitarbeiter reduzieren und das gesamte Nutzererlebnis verbessern.
In unserem Release-Blog finden Sie ein detailliertes praktisches Anwendungsbeispiel, etwa die Verwendung von Zendesk als Datenquelle. Dieses Beispiel zeigt, wie die Integration in realen Szenarien angewendet werden kann, um das Support-Ticket-Management und die Zugänglichkeit der Wissensdatenbank zu verbessern.
Die Integration von Airbyte und Milvus stellt einen bedeutenden Fortschritt im Bereich KI und Datenmanagement dar und bietet eine effiziente Lösung für die Verwaltung von Vektordaten. Sie schafft neue Chancen für Entwickler und Unternehmen, die das volle Potenzial von KI in ihren Abläufen ausschöpfen möchten.
Fazit
Die fortlaufende Entwicklung und Integration von Tools wie Upsert, Kafka Connector und Airbyte mit der Vektordatenbank von Zilliz unterstreicht unser Engagement, Technologien für das Management unstrukturierter Daten voranzutreiben. Diese Verbesserungen sind darauf ausgelegt, die Suchleistung zu steigern und die gesamte Datenpipeline zu optimieren, wodurch sie effizienter und entwicklerfreundlicher wird.
Mit Blick auf die Zukunft planen wir, unsere Suite von Funktionen für Datenaufnahme und Pipelines weiter auszubauen. Bleiben Sie dran für diese Updates, während wir weiterhin innovativ sind und Tools bereitstellen, die den sich wandelnden Anforderungen des Umgangs mit unstrukturierten Daten und KI-gesteuerten Anwendungen gerecht werden.
Wir schätzen das Feedback und die Erkenntnisse aus der Entwicklercommunity sehr und setzen uns für kontinuierliche Verbesserung ein. Ihre Erfahrungen und Vorschläge sind entscheidend auf unserem Weg, diese Technologien voranzubringen. Wir würden gerne von Ihnen hören. Treten Sie gerne unserer GitHub-Community bei oder übermitteln Sie Ihr Feedback direkt, indem Sie hier ein Ticket einreichen.

Weiterlesen

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.