




Warum wir Vector Lakebase entwickelt haben: Unstrukturierte Datenarchitektur für KI neu denken
Kürzlich haben wir Zilliz Vector Lakebase vorgestellt, die nächste Entwicklungsstufe von Zilliz Cloud: von einem reinen Vektordatenbanksystem hin zu einer einheitlichen, lake-nativen Datengrundlage für AI-Workloads. Die Ankündigung stieß auf großes Interesse. Sie warf aber auch fast sofort Fragen dazu auf, wohin sich Zilliz entwickelt.
Rückte Zilliz von Vektordatenbanken ab? Oder, direkter gefragt: Werden Vektordatenbanken bereits obsolet?
Ich verstehe, warum diese Fragen aufgekommen sind. Seit Jahren ist Zilliz dafür bekannt, produktionsreife Vektordatenbanksysteme zu entwickeln (Open-Source Milvus und vollständig verwaltete Zilliz Cloud). Als wir also begannen, über die Weiterentwicklung zu einer lake-nativen Datengrundlage für AI zu sprechen, fragten sich manche Menschen ganz natürlich, ob dies eine Richtungsänderung bedeute.
Die kurze Antwort lautet NEIN. Ganz und gar NICHT. Wenn überhaupt, ist Vector Lakebase unsere Antwort darauf, was passiert, nachdem Vektordatenbanken erfolgreich geworden sind.
In den vergangenen mehreren Jahren sind Vektordatenbanken zu einer der grundlegenden Infrastrukturschichten des AI-Stacks geworden. Die Akzeptanz ist schneller gewachsen, als wir es uns hätten vorstellen können, als wir vor fast einem Jahrzehnt mit Milvus begannen. Die Kategorie ist real, und der Bedarf an semantischer Suche wird nur noch wichtiger.
Aber uns ist auch noch etwas anderes klar geworden: Vektorsuche ist nicht mehr das gesamte Problem.
Während sich AI-Systeme von statischen Assistenten zu kontinuierlich laufenden Agenten entwickeln, verlangen Unternehmen von ihrer Infrastruktur für unstrukturierte Daten etwas Umfassenderes. Sie wollen nicht nur ein System, das Informationen abrufen kann. Sie wollen ein System, das die Daten verbessern, neu organisieren, analysieren, verfeinern und diese Verbesserungen wieder in die Produktion zurückführen kann. Das verändert die Architektur.
Dieser Wandel erinnert mich an einen früheren Zyklus in der Geschichte der Infrastruktur: die Entwicklung von Datenbanken während der Ära des mobilen Internets. Die Details sind anders, aber das Muster ist vertraut. Eine neue Art von Anwendung erzeugt eine neue Art von Datendruck. Die erste Generation der Infrastruktur löst das unmittelbare Serving-Problem. Dann, wenn die Datenmenge wächst, muss sich die Architektur erweitern.
Ich denke, Vektordatenbanken treten jetzt in diese nächste Phase ein.
Das mobile Internet hat diesen Zyklus bereits einmal durchlaufen
Um 2010, als mobile Anwendungen explodierten, wurde MongoDB zu einem der prägenden Infrastrukturprodukte dieser Zeit.
Der Grund war einfach. Mobile Anwendungen erzeugten enorme Mengen halbstrukturierter Daten: Nutzerereignisse, soziale Aktivität, Gerätetelemetrie, Verhaltenssignale, Produktlogs. Nichts davon passte sauber in die relationalen Datenbankmuster, die die meisten Teams damals verwendeten. Produktteams lieferten schnell aus, Schemata änderten sich ständig, und das erste Problem bestand schlicht darin, die Daten anzunehmen, ohne die Anwendung zu verlangsamen. MongoDB löste dieses unmittelbare Problem sehr gut: zuerst die Daten aufnehmen. Strukturierung und Analyse konnten später kommen.

Einige Jahre später begann die Branche, eine andere Frage zu stellen. Wenn all diese Daten nun existierten, wie konnten Unternehmen sie tatsächlich nutzen? Dieser Wandel trug zum Aufstieg moderner Data Warehouses wie Snowflake und Redshift bei. Der Fokus verlagerte sich von operativer Speicherung zu analytischer Erkenntnis. Unternehmen wollten BI-Berichte, Nutzerkohorten, Attribution, Prognosen und Wachstumsanalysen. Daten waren nicht mehr nur ein operatives Nebenprodukt, sondern wurden zu einem Geschäftswert.
Dann entstand ein weiterer Engpass.
Die Trennung zwischen transaktionalen Systemen und analytischen Systemen wurde zunehmend schmerzhaft. Datenpipelines zwischen OLTP- und OLAP-Umgebungen waren fragil, teuer und betrieblich erschöpfend. Dieselben Datensätze wurden wiederholt über Systeme hinweg kopiert, oft mit Synchronisationsverzögerungen und subtilen Inkonsistenzen.
Das war die Umgebung, aus der die Lakehouse-Architektur hervorging. Databricks, Iceberg, Hudi und verwandte Systeme konvergierten alle um dieselbe Grundidee: Eine einzige logische Kopie von Daten sollte mehrere Berechnungsmodelle unterstützen, ohne endlose Verschiebungen zwischen Systemen zu erfordern.
Rückblickend wirkt die Entwicklung beinahe unvermeidlich. Doch damals war nichts davon offensichtlich. Der Aufstieg von MongoDB sagte Snowflake nicht voraus. Snowflake sagte das Lakehouse nicht voraus. Jeder Übergang entstand, weil die vorherige Generation von Infrastruktur im großen Maßstab erfolgreich war und dann eine neue Klasse von Einschränkungen sichtbar machte.
Dieses Muster ist wichtig, weil sich KI-Infrastruktur zunehmend so anfühlt, als würde sie einem ähnlichen Pfad folgen.
Retrieval löste das erste Problem, nicht das letzte
Als große Sprachmodelle 2023 den Durchbruch in die breite Nutzung schafften, wurden Vektordatenbanken zu einer der ersten herausragenden Infrastrukturkategorien. Der Grund war praktischer Natur. RAG-Systeme benötigten eine native Möglichkeit, Embeddings zu speichern und semantisches Retrieval durchzuführen. Die meisten traditionellen Datenbanken waren nicht für hochdimensionale Vektorsuche, ANN-Indizes, hybrides Retrieval und latenzarme Filterung im großen Maßstab ausgelegt.
In vielerlei Hinsicht lösten Vektordatenbanken dieselbe Art von Problem, die MongoDB zuvor gelöst hatte. Ein neues Anwendungsmuster schuf eine neue Datenabstraktion, und Entwickler brauchten Infrastruktur, die sie unterstützen konnte. Diesmal war die Abstraktion die semantische Repräsentation: Embeddings, die von neuronalen Modellen aus unstrukturierten Daten erzeugt wurden.
Diese erste Phase der Einführung verlief sehr schnell. Doch nur wenige Jahre später sind die Fragen, die wir von Kunden hören, deutlich komplexer geworden. Sie fragen nicht mehr nur, wie man Vektoren effizient abruft. Sie fragen:
- Wie können wir Trainingsdaten kontinuierlich deduplizieren und verfeinern?
- Wie können wir Milliarden von Embeddings auf Clustering- und Qualitätsprobleme analysieren?
- Wie können wir Drift, Bias oder Redundanz in multimodalen Datensätzen identifizieren?
- Wie können wir Ausführungsverläufe von Agenten nachverfolgen und optimieren?
- Wie können wir Daten erneut verarbeiten und verbessern, während sich Modelle weiterentwickeln?
- Wie können wir kalte Daten durchsuchen, ohne die gesamte Compute-Kapazität ständig laufen zu lassen?
- Wie können wir Daten, die bereits in Iceberg, Lance, Parquet und Objektspeicher liegen, für mehrere KI-Workloads nutzen?
Das sind keine reinen Retrieval-Probleme mehr. Sie erfordern groß angelegte Offline-Verarbeitung, iterative Discovery-Workflows, Data Governance, analytische Exploration und kontinuierliche Feedbackschleifen zwischen Online-Systemen und Offline-Berechnung. Zunehmend bemerkten wir bei fortgeschrittenen KI-Teams etwas Wichtiges: Der Engpass war nicht mehr nur die Modellfähigkeit. Es war die Iterationsgeschwindigkeit.
Eine Erfahrung machte dies schmerzhaft deutlich. Wir sahen Teams, die versuchten, große Vektordatensätze erneut zu verarbeiten: Embeddings neu zu clustern, Duplikate zu entfernen, Indizes neu zu erzeugen, ganze Korpora erneut einzubetten. In manchen Fällen konnte allein das Verschieben von einer Milliarde Vektoren von einem System in ein anderes Tage dauern. Nicht Stunden. Tage.
Gleichzeitig bewegen sich die Iterationszyklen in führenden KI-Teams in die entgegengesetzte Richtung. Forschende wollen kontinuierlich experimentieren. Data Engineers stehen unter Druck, Datensätze schneller zu bereinigen, zu evaluieren und zu aktualisieren. Modelle verbessern sich. Embedding-Modelle ändern sich. Agenten erzeugen jeden Tag neue Traces. Doch der darunterliegende Infrastruktur-Stack war nicht für kontinuierliche Verfeinerungsschleifen auf unstrukturierten Daten ausgelegt.
Das war der Punkt, an dem wir anfingen zu denken, dass die Branche das Problem zu eng fasste.
Infrastruktur für unstrukturierte Daten ist nicht bloß eine Retrieval-Schicht. Sie wird zu einem kontinuierlich arbeitenden System.
Von Retrieval-Systemen zu kontinuierlichen Systemen: CS/CD
Intern begannen wir, diese Architektur als kontinuierliche Schleife zwischen Serving und Discovery zu beschreiben. Mit der Zeit begannen wir, sie CS/CD zu nennen: Continuous Serving und Continuous Discovery.
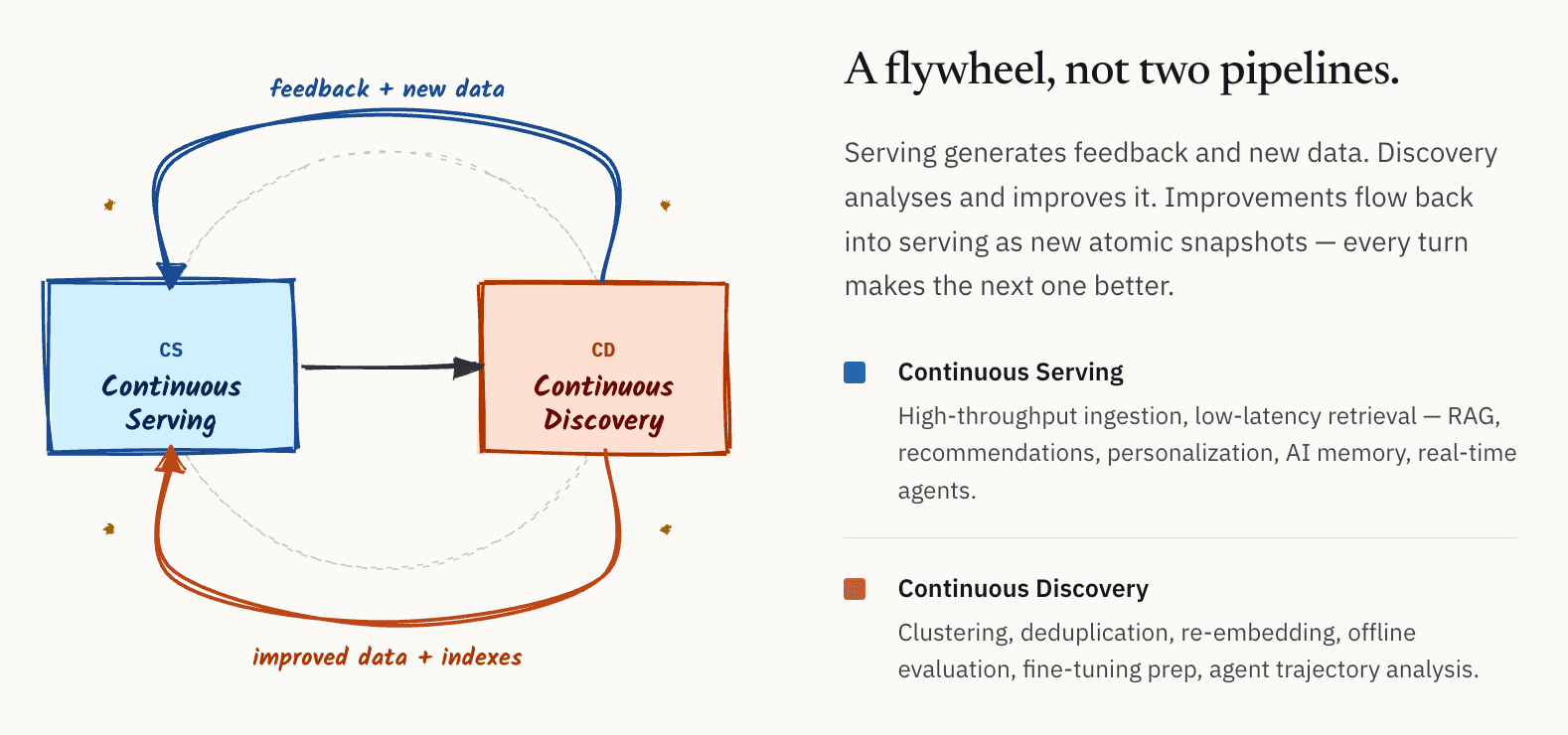
Die Idee ist konzeptionell einfach.
- Auf der einen Seite gibt es die Serving-Schicht: Hochdurchsatz-Ingestion, Retrieval mit niedriger Latenz für Online-RAG-Systeme, Empfehlungssysteme, Personalisierung, KI-Memory und Echtzeit-Agenten.
- Auf der anderen Seite gibt es die Discovery-Schicht: Clustering, Deduplizierung, Re-Embedding, Offline-Evaluierung, Qualitätsanalyse, Vorbereitung des Modell-Fine-Tunings und Analyse von Agenten-Trajektorien.
Der wichtige Punkt ist, dass dies keine unabhängigen Workflows sind. Sie bilden ein Schwungrad. Serving-Systeme erzeugen kontinuierlich Feedback und neue Daten. Discovery-Systeme analysieren und verbessern diese Daten. Die daraus resultierenden Verbesserungen, einschließlich besserer Embeddings, saubererer Datensätze, verbesserter Indizes und verfeinerter Metadaten, fließen dann zurück in die Serving-Schicht.
Jede Iteration sollte die nächste verbessern. Zumindest in der Theorie.
In der Praxis können die meisten Organisationen diesen Kreislauf immer noch nicht effizient betreiben, weil die zugrunde liegende Infrastruktur fragmentiert bleibt.
Wenn ein Team heute groß angelegte Offline-Verarbeitung auf Produktions-Vektordaten durchführen möchte, ist der typische Workflow immer noch schmerzhaft manuell. Daten müssen zunächst aus der Vektordatenbank in eine Lake- oder Batch-Umgebung exportiert werden. Indizes können in der Regel nicht wiederverwendet werden. Synchronisationspipelines werden fragil. Inkrementelle Aktualisierungen sind schwierig. Verarbeitete Ergebnisse müssen schließlich wieder in das Serving-System re-importiert werden, oft ohne atomare Konsistenzgarantie zwischen den neuen Daten und den neuen Indizes.
Das Ergebnis ist ein Workflow, der langsam, fragil und teuer ist. Und weil seine Wartung so teuer ist, vermeiden viele Organisationen kontinuierliche Discovery einfach. Die Daten liegen dort, abrufbar, aber weitgehend unerforscht.
Dies erinnerte uns zunehmend an die historische Kluft zwischen OLTP- und OLAP-Systemen, nur dass die Fragmentierung jetzt zwischen Online-Semantic-Retrieval und Offline-Verarbeitung unstrukturierter Daten liegt.
Warum bestehende Architekturen irgendwann an ihre Grenzen stoßen
Eine Sache, von der wir zunehmend überzeugt waren, ist, dass keine Seite des aktuellen Infrastruktur-Stacks falsch ist.
Vektordatenbanken und Lakehouse-Systeme lösen beide wichtige Probleme. Das Problem ist, dass jede Architektur nur um eine Hälfte der entstehenden Workload herum optimiert wurde.
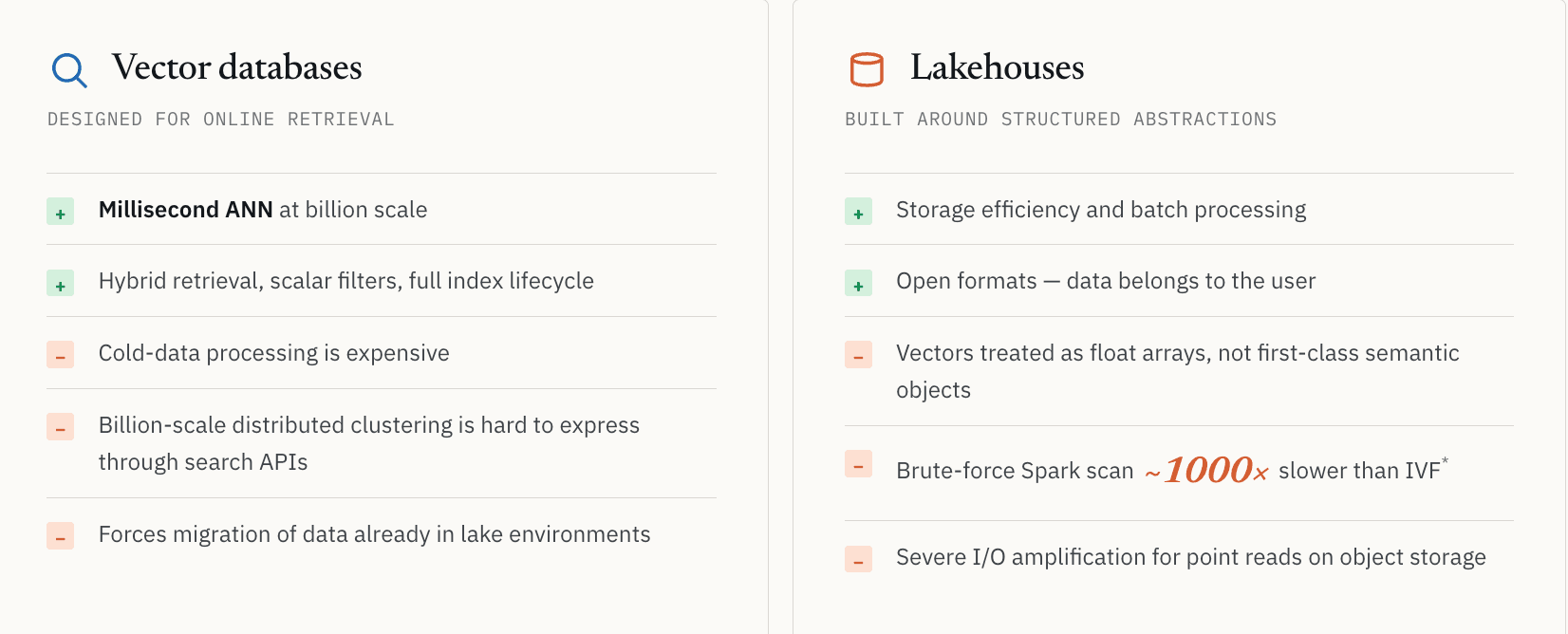
Vektordatenbanken wurden primär für Online-Retrieval entwickelt.
Nehmen wir das Open-Source-Projekt Milvus als Beispiel. Es löst Vektorsuche in großem Maßstab extrem gut. Doch wenn Workloads über Serving hinausgehen und in groß angelegte Discovery übergehen, treten natürliche architektonische Grenzen zutage.
Die Verarbeitung kalter Daten wird teuer. Verteiltes Clustering im Milliardenmaßstab lässt sich nur schwer über Online-Such-APIs ausdrücken. Viele Systeme gehen davon aus, dass Daten in der Online-Infrastruktur geladen bleiben müssen, um weiterhin abfragbar zu sein. Unternehmen, die bereits massive unstrukturierte Datensätze in Lake-Umgebungen speichern, sehen sich mit Migrationskosten und Governance-Fragmentierung konfrontiert, wenn sie aufgefordert werden, alles in ein dediziertes Retrieval-System zu verschieben.
Das sind keine Implementierungsfehler. Sie sind Folgen der Optimierung auf Online-Retrieval mit niedriger Latenz.
Lakehouses lösen Speichereffizienz und Batch-Verarbeitung, wurden jedoch um strukturierte Datenabstraktionen herum entwickelt
Der entgegengesetzte Ansatz, von der Lakehouse-Seite ausgehend, bringt andere Kompromisse mit sich.
Lakehouses lösen Speichereffizienz und Batch-Verarbeitung elegant. Aber sie wurden um strukturierte Datenabstraktionen herum entwickelt. In den meisten Lake-Architekturen werden Vektoren immer noch als lange Arrays von Floats behandelt, statt als erstklassige semantische Objekte. Dateiformate wie Parquet wurden nicht um ANN-Indizes, invertierte Indizes oder semantische Retrieval-Pfade mit niedriger Latenz herum entwickelt.
Wir haben das direkt bei einem Pharmakunden gesehen, der eine Suche nach molekularer Ähnlichkeit durchführte. Ein Brute-Force-Spark-Scan über Lake-Daten war ungefähr 1000x langsamer als eine indizierte Vektorabfrage mit IVF-basierter Suche. Die genaue Zahl hängt von Datenverteilung, Indexparametern und Hardware ab, aber die Lehre ist stabil: Ohne den richtigen Index sind viele semantische Workloads wirtschaftlich nicht praktikabel.
Es gibt auch ein grundlegenderes Speicherproblem. Objektspeicher kann bei abruforientierten Workloads eine erhebliche I/O-Verstärkung verursachen. Semantische Suche findet oft eine kleine Anzahl von IDs, aber die Anwendung benötigt weiterhin die vollständigen Datensätze hinter diesen IDs. Bei traditionellen spaltenorientierten Formaten kann das Abrufen einiger kleiner Datensätze das Lesen großer Speicherblöcke erfordern. Das ist für Scans in Ordnung. Für Serving mit niedriger Latenz ist es schlecht geeignet.
Mit der Zeit wurde unsere Schlussfolgerung schwer zu vermeiden: Die Branche sollte nicht zwischen Vektordatenbanken und Lake-Architekturen wählen müssen. Sie braucht eine Architektur, in der Retrieval und groß angelegte Discovery native Bestandteile desselben operativen Systems sind.
Was wir unter Vector Lakebase verstehen
Diese Erkenntnis führte uns zu dem, was wir heute Vector Lakebase nennen. Die Kernidee ist nicht „eine Vektordatenbank plus ein Data Lake“. Ich denke, diese Einordnung verfehlt den tieferen architektonischen Punkt.
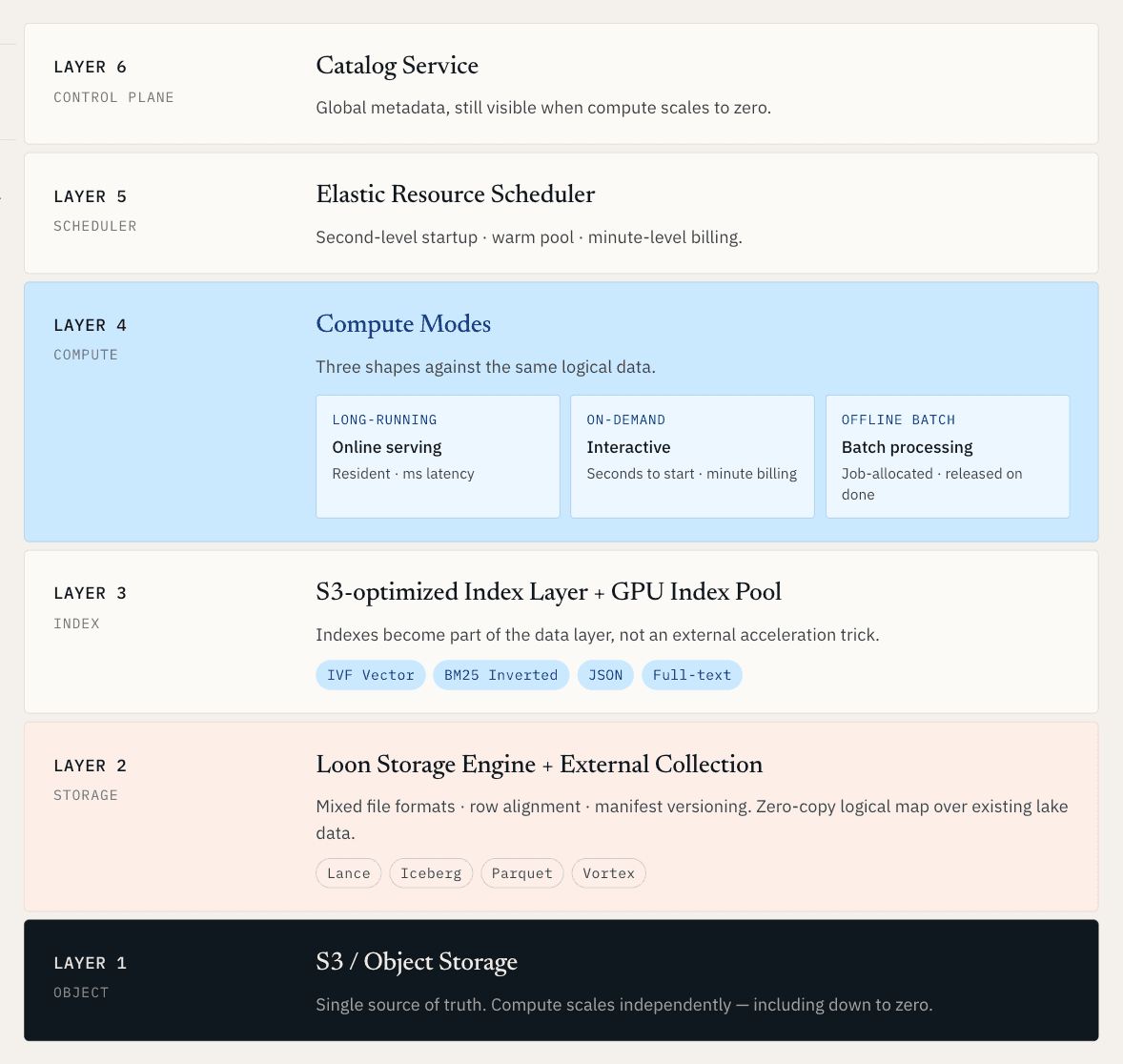
Das Ziel ist, eine einheitliche operative Schicht für unstrukturierte Daten zu schaffen, in der Online-Serving, Offline-Discovery und elastische Compute-Ressourcen alle auf derselben logischen Datengrundlage arbeiten.
Für Rohdaten bedeutet das, dass Vektoren, Dokumente, Metadaten, Logs und Indizes gemeinsam auf lake-nativem Speicher verwaltet werden. Für Daten, die bereits in Iceberg, Lance, Parquet oder Objektspeicher liegen, bedeutet es, dass das System diese Daten mappen und indizieren kann, ohne eine vollständige Migration zu erzwingen.
Wenn man von dieser Anforderung ausgeht, muss die Architektur mehrere schwierige Probleme gleichzeitig lösen. Compute muss unabhängig vom Speicher skalieren können. Indizes müssen Teil der Datenschicht werden, nicht ein externer Beschleunigungstrick. Neue Daten und neue Indizes müssen gemeinsam als konsistente Snapshots veröffentlicht werden. Und bestehende Lake-Daten müssen durchsuchbar werden, ohne eine weitere Kopie zu erstellen.
Diese Ideen klingen einfach. Sie so umzusetzen, dass die Performance erhalten bleibt, die Menschen von einer Vektordatenbank erwarten, ist der schwierige Teil. Genau hier beginnen die Engineering-Entscheidungen auf niedrigerer Ebene wichtig zu werden.
Die Kosten der Trennung von Speicher und Compute und wie wir sie angehen
Die Trennung von Speicher und Compute ist für den CS/CD-Loop notwendig, aber sie ist nicht kostenlos.
Langsamer Kaltstart
Wenn Compute auf null herunterskalieren kann, kann die erste Abfrage in einem On-Demand- oder Offline-Workflow auf vollständig kalte Daten treffen. Der Knoten hat keinen lokalen Index, keinen warmen Cache und keine residenten Daten. Alles muss aus dem Objektspeicher kommen.
Für kleine Datensätze ist das handhabbar. Bei großen Vektor-Workloads wird es schnell inakzeptabel. Betrachten wir eine Milliarde 768-dimensionale Vektoren. Ein konventioneller HNSW-Index kann etwa 340 GB groß sein. Das vollständige Laden dieses Index aus S3 kann mehr als vier Minuten dauern. Niemand möchte vier Minuten warten, bevor eine Suche beginnen kann.
Unsere Antwort ist, den Cold Path viel kleiner zu machen. Mit einer RaBitQ-ähnlichen 1+3-Bit-Quantisierung können wir diesen etwa 340 GB großen Index auf rund 13 GB komprimieren. Die Suche läuft in zwei Stufen. Die erste Stufe verwendet eine 1-Bit-Repräsentation für grobes Filtern, mit ungefähr 85 bis 90 Prozent Recall, während die Datengröße auf etwa ein Dreißigstel des Originals reduziert wird. Die zweite Stufe verwendet die 1+3-Bit-Repräsentation, um Ergebnisse neu zu ranken und auf etwa 95 Prozent Recall zu verfeinern. Dadurch sinkt der Kaltstart von Minuten auf ungefähr 5 bis 10 Sekunden.
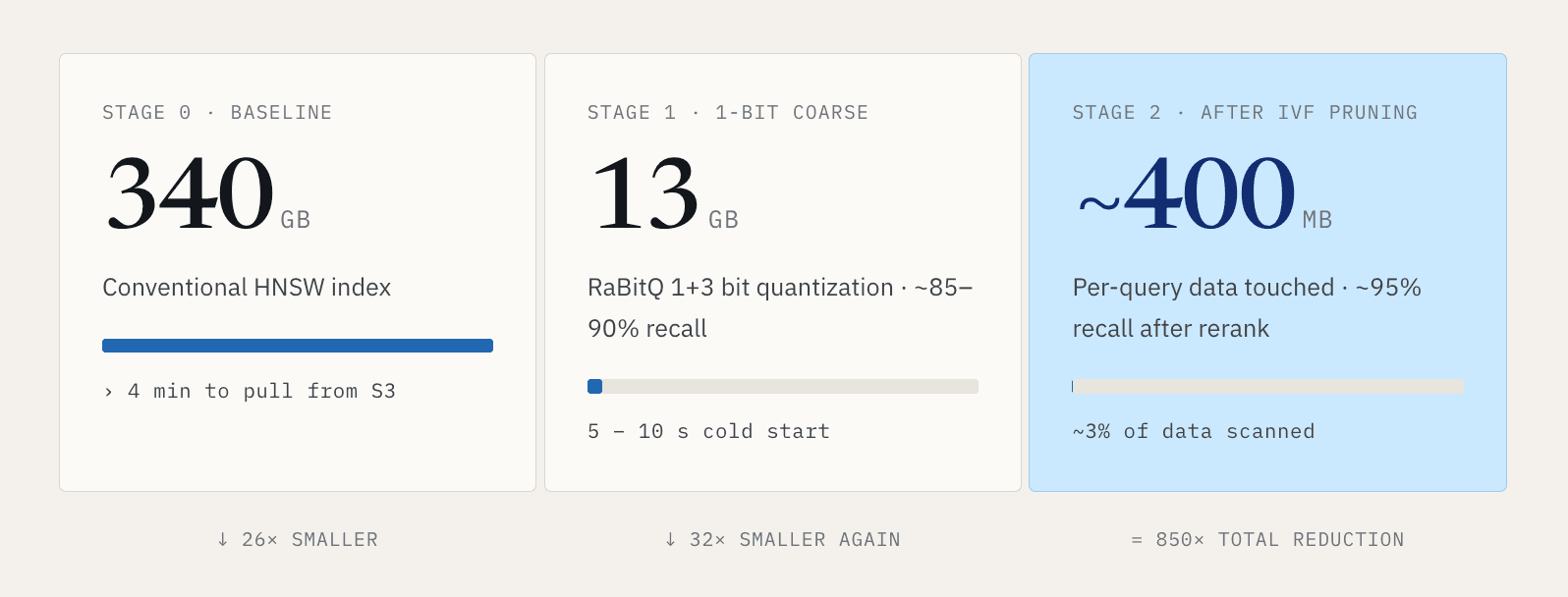
Anschließend verwenden wir IVF-Clustering, um die pro Abfrage berührte Datenmenge zu reduzieren. In einem repräsentativen Setup durchsucht jede Abfrage etwa 3 Prozent der Daten. Der Pfad wird zu: 340 GB konventioneller Index, komprimiert auf 13 GB, wobei eine einzelne Abfrage nach dem Pruning ungefähr 400 MB berührt.
Das ist der Unterschied zwischen elastischer Vektorsuche als Idee und elastischer Vektorsuche als nutzbares System.
I/O-Amplifikation
Cold Start ist nur eine Seite des Problems. Die andere Seite ist der Datensatz-Zugriff.
Vektorsuche gibt IDs zurück. Anwendungen benötigen jedoch vollständige Datensätze: Textabschnitte, Metadaten, Dokumentverweise, Berechtigungen, Zeitstempel, Bildattribute oder andere Felder. In einem Standard-Parquet-Layout kann ein kleiner Point Read das System dazu zwingen, eine große Row Group herunterzuladen. Eine Abfrage benötigt möglicherweise nur wenige Kilobyte an nützlichen Daten, zieht am Ende aber Dutzende Megabyte aus dem Object Storage. Kleinere Row Groups helfen bei Point Reads, beeinträchtigen jedoch Kompression und Scan-Effizienz.
Deshalb haben wir Loon entwickelt, die neu aufgebaute Storage Engine hinter Zilliz Vector Lakebase.
Loon verwendet gemischte Dateiformate, Zeilenausrichtung und manifestbasierte Versionierung. Skalare Felder können spaltenorientierte Layouts verwenden, die für Filterung und Scans effizient bleiben. Vektorfelder und Daten mit vielen Point Queries können Layouts verwenden, die besser für Retrieval mit niedriger Latenz geeignet sind. Column Groups richten Row IDs aus, sodass das System die benötigten Felder abrufen kann, ohne große, nicht verwandte Blöcke durch das Netzwerk zu ziehen.
Unter der Haube verwendet Loon Vortex, ein Open-Source-Dateiformat unter der Linux Foundation. Vortex unterstützt flexible Layouts und verschachtelte Encodings, einschließlich Point Queries ohne Dekomprimierung großer irrelevanter Blöcke.
In einem internen Test mit 3 Millionen Zeilen, 128-dimensionalen Vektoren, S3-Storage und 256 gleichzeitigen Lesern luden Parquet-Point-Reads etwa 9,4 MB pro Read herunter. Vortex lud etwa 0,07 MB herunter. Das ist eine 135-fache Reduzierung der heruntergeladenen Daten. Der Full-Scan-Durchsatz war in diesem Setup ebenfalls höher.
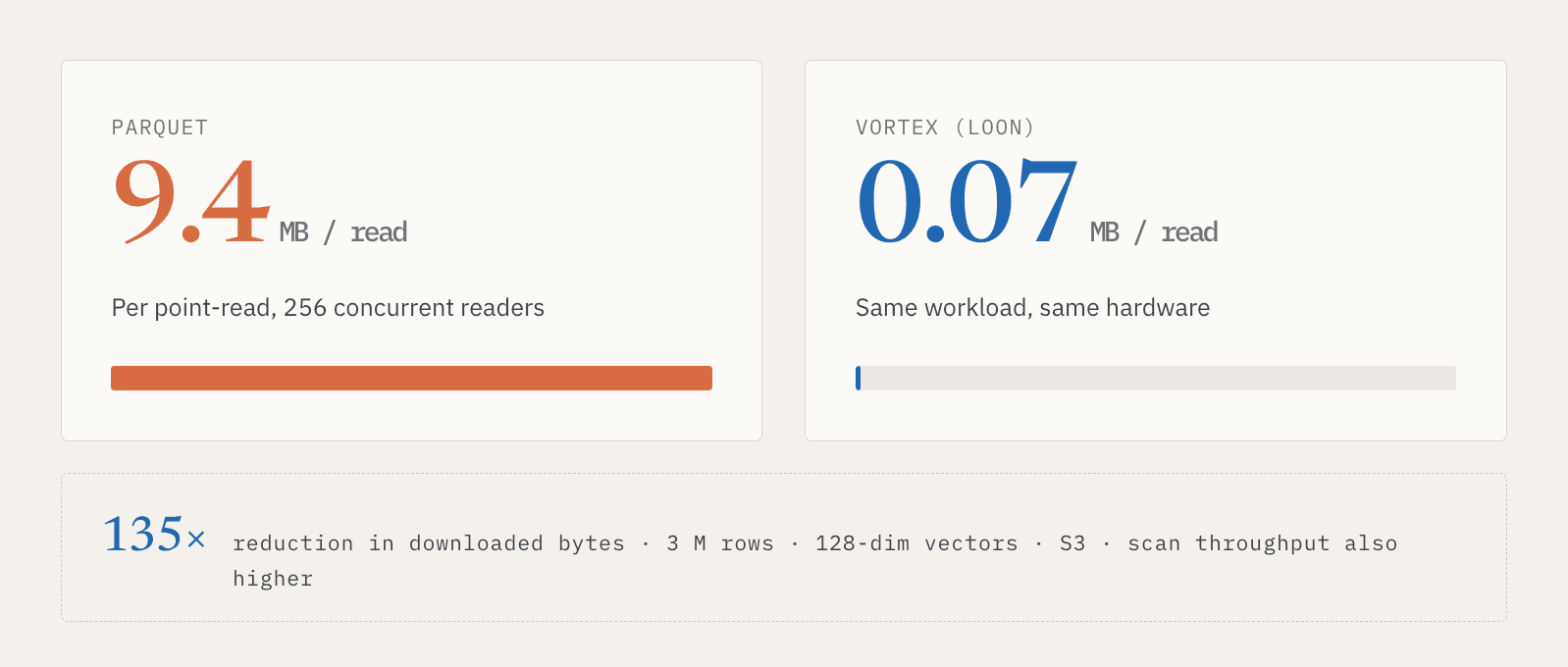
Der Punkt ist nicht nur, dass ein Format in einem Benchmark schneller ist. Der Punkt ist, dass Serving und Discovery unterschiedliche Zugriffsmuster auf dieselben logischen Daten benötigen. Online-Systeme benötigen schnelle Point Reads. Batch-Systeme benötigen effiziente Scans. Eine Vector Lakebase muss beides unterstützen, ohne Nutzer dazu zu zwingen, zwei Kopien der Daten zu verwalten.
Vector Lakebase: eine Datengrundlage, mehrere Compute-Modi
Sobald die Datenschicht gemeinsam genutzt wird, kann Compute kein One-size-fits-all sein.
Verschiedene KI-Workloads haben sehr unterschiedliche Formen. Manche benötigen den ganzen Tag über vorhersagbar niedrige Latenz. Manche benötigen eine interaktive Suchsitzung für zehn Minuten. Manche benötigen einen großen Batch-Job, der über Nacht läuft und dann wieder verschwindet.
Deshalb unterstützt Zilliz Vector Lakebase drei Compute-Modi.
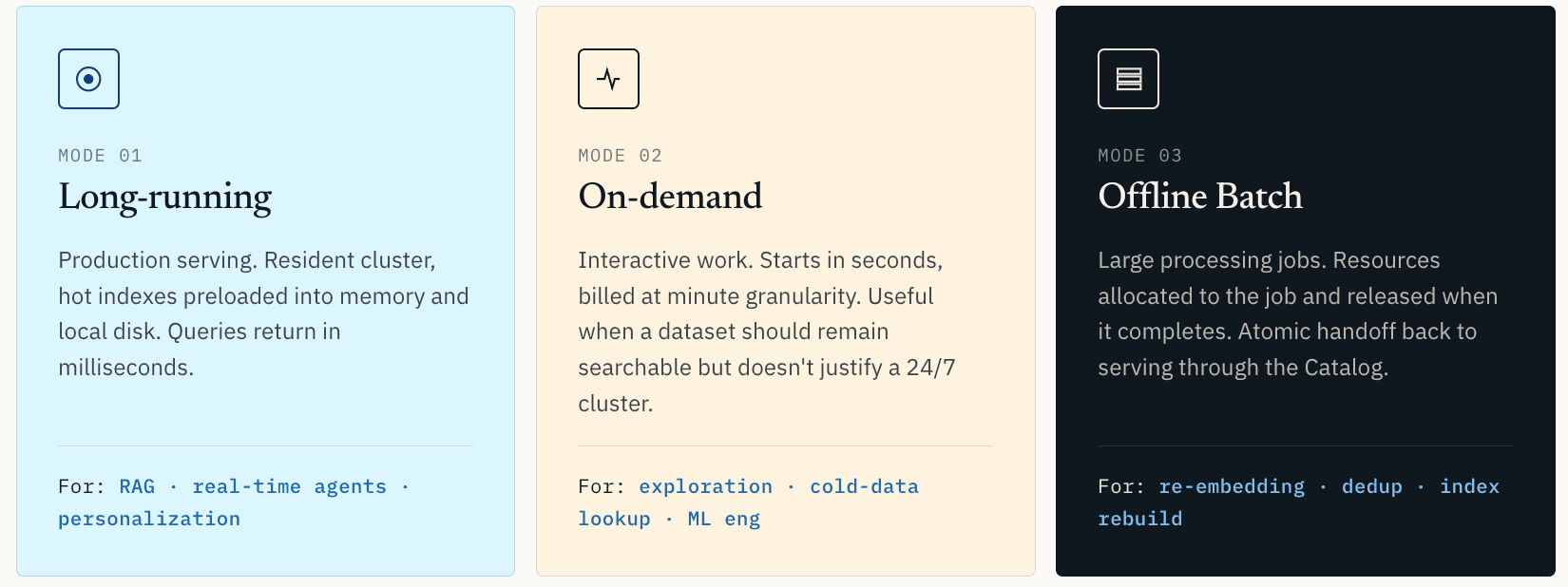
- Long-running Compute ist für Production Serving. Der Cluster bleibt resident. Hot Indexes und Daten werden in Arbeitsspeicher und lokalen Speicher vorgeladen. Abfragen werden in Millisekunden beantwortet. Dies ist der richtige Modus für Production RAG, Echtzeit-Empfehlungen, Personalisierung, Online Agents und jeden Workload, bei dem Latenz Teil der User Experience ist.
- On-demand Compute ist für interaktive Arbeit. Er startet in Sekunden und wird mit minutengenauer Granularität abgerechnet. Dies ist nützlich für Similarity Exploration, Anomalieprüfung, Cold-Data-Retrieval oder ML-Engineering-Workflows, bei denen der Datensatz durchsuchbar bleiben soll, aber keinen 24/7-Cluster rechtfertigt.
- Offline Batch Compute ist für große Verarbeitungsjobs: Vektor-Clustering, Deduplizierung von Trainingsdaten, vollständiges Re-Embedding, Index-Neuaufbau und Datenqualitätsscans. Ressourcen werden dem Job zugewiesen und freigegeben, wenn der Job abgeschlossen ist.
Die Übergabe zurück an Serving erfolgt über den Catalog als neuer Snapshot. Serving liest weiterhin den alten Snapshot, bis die neuen Daten und Indizes bereit sind. Dann wird die neue Version atomar sichtbar. Dieser atomare Wechsel ist wichtig. Discovery ist nur dann nützlich, wenn Verbesserungen zurück in die Produktion fließen können, ohne halbfertige Indizes oder inkonsistente Daten offenzulegen.
 architecture.png
architecture.png
Ein Kundenbeispiel zeigt, warum diese Unterscheidung wichtig ist. Ein Kunde aus dem Bereich autonomes Fahren hatte eine Milliarde 768-dimensionale Vektoren, benötigte aber nur etwa 20 Minuten Online-Abfragezeit pro Tag. Die Ausführung des Workloads als dauerhaft laufender Cluster kostete ungefähr $7,000 pro Monat. Durch die Umstellung auf den On-demand-Modus sanken die monatlichen Kosten auf etwa $500. Derselbe Kunde hatte einen Deduplizierungs-Workflow, der zuvor etwa 70 Stunden damit verbrachte, ANN-Suchen einzeln auszuführen. Die Umstellung auf einen Offline-Batch-Job reduzierte die Rechenzeit auf etwa 10 Stunden auf derselben Ressourcenklasse.

Die Lehre ist nicht, dass ein Compute-Modus besser ist als ein anderer. Die Lehre ist, dass KI-Daten-Workloads nicht nur eine Form haben und die Architektur sie nicht in eine einzige zwingen sollte.
Ressourcenplanung wird Teil der Vector Lakebase
Die drei Compute-Modi funktionieren nur, wenn die Ressourcenplanung genauso elastisch ist wie die Rechenleistung selbst.
Traditionelle Datenbank-Scheduler gehen normalerweise von einem festen Pool von Maschinen aus. Ausgehend von diesen Knoten entscheidet das System, wo Daten platziert und wie Lasten ausgeglichen werden. Dieses Modell funktioniert gut, wenn der Workload konstant ist. Es passt schlecht zu KI-Workloads, die in Bursts auftreten: eine On-demand-Suchsession, eine kurze Inspektion kalter Daten, ein nächtlicher Deduplizierungsjob, danach stundenlang nichts.
In dieser Welt ist die bessere Frage nicht nur, wo die Daten laufen sollen. Sie lautet, ob die Compute-Ressourcen überhaupt laufen sollten.
Deshalb muss Vector Lakebase Daten und Ressourcen gemeinsam planen. In der Praxis bedeutet das, einen Warm Pool vorbereiteter Knoten vorzuhalten, Daten schnell anzubinden, wenn Arbeit eintrifft, Ressourcen nach der Anfrage kurz warm zu halten und sie freizugeben, wenn sie nicht mehr nützlich sind.
Das verändert auch die Wirtschaftlichkeit. Das ist nicht dasselbe wie Serverless-Preise pro Anfrage, und es ist nicht dasselbe wie dedizierte monatliche Kapazität. Für viele KI-Daten-Workloads ist eine nutzungsbasierte Abrechnung auf Minutenebene die natürlichere Einheit: für Compute bezahlen, während der Loop läuft, und ihn danach verschwinden lassen.
Dahinter steht eine größere Architekturverschiebung: von einer Control Plane, die einen weitgehend statischen Kernel verwaltet, hin zu einem Kernel, der Ressourcen, Cache-Zustand, Snapshots und Kosten versteht. Das verdient einen eigenen Beitrag. Für diesen Artikel ist der wichtige Punkt einfacher: Ohne dieses Ressourcenmodell wären Long-running, On-demand und Offline Batch drei separate Bereitstellungsoptionen, nicht drei Teile desselben elastischen Datensystems.
External Collection: Daten dort abholen, wo sie bereits liegen
Es gibt noch eine weitere Realität, für die wir entwerfen mussten.
Die meisten Unternehmen verfügen bereits über große Mengen unstrukturierter Daten in Lake-Umgebungen: Lance-Tabellen, Iceberg-Tabellen, Parquet-Datasets und Objekt-Storage-Verzeichnisse. Sie zu bitten, alles in ein neues System zu verschieben, bevor sie es nutzen können, ist nicht realistisch.
Deshalb haben wir External Collection innerhalb von Zilliz Vector Lakebase entwickelt. External Collection ist nicht nur ein Zero-Copy-Mapping. Sie baut eine unabhängige Indexierungsschicht auf externen Daten auf. Die Originaldaten bleiben dort, wo sie sind, und unterliegen weiterhin der bestehenden Plattform des Kunden, während Zilliz die Vektorindizes, invertierten Indizes und JSON-Indizes erstellt und verwaltet, die benötigt werden, um diese Daten über denselben Retrieval-Pfad wie native Daten durchsuchbar zu machen.
Unser internes Prinzip wurde einfach: One Data. One Index. Kein duplizierter Speicher. Keine Dual-Write-Pipelines. Keine fragmentierten Discovery-Pfade.
Das bedeutet, dass die CS/CD-Schleife mehr abdecken kann als nur die bereits in eine Vektordatenbank importierten Daten. Sie kann die unstrukturierten Datenbestände einbeziehen, die Unternehmen bereits in ihren Lakes haben.
Was die erste Generation von Vector Lakebase definiert
Diese Ideen sind nicht nur Architektur auf dem Papier. Wir liefern sie bereits in Zilliz Vector Lakebase aus, und der Prozess ihrer Entwicklung hat unsere Sicht auf die Kategorie deutlich konkreter gemacht.
Eine Vector Lakebase der ersten Generation muss mehrere Dinge gleichzeitig richtig machen.

- Erstens: Trennung von Storage und Compute mit mehrschichtigem Caching. Daten liegen im Objektspeicher, und Compute kann unabhängig skalieren, auch bis auf null. Aber Trennung allein reicht nicht aus. Online-Vektorsuche benötigt weiterhin Arbeitsspeicher, lokalen Speicher, warme Knoten und cache-bewusste Ausführung, um heiße Abfragen im Millisekundenbereich schnell zu halten.
- Zweitens: einheitliches Management für multimodale unstrukturierte Daten. Das System sollte nicht nur Vektoren verwalten, sondern auch Quelldokumente, Bilder, Audio, Video, Embeddings, skalare Metadaten, Berechtigungen und Indizes. Ein System, das nur Vektoren speichert, ist ein Indexdienst, keine Datengrundlage.
- Drittens: native Vektordatenbank-Fähigkeiten. Millisekundenschnelle ANN-Suche, Index-Lifecycle-Management, hybride Suche, skalare Filterung, Volltextsuche, JSON-Filterung und mehrere Ähnlichkeitsmetriken müssen integriert sein. Ein Lakehouse mit einer externen Vektordatenbank zu verbinden, beseitigt keine Fragmentierung. Es schafft lediglich eine weitere Pipeline.
- Viertens: mehrere Compute-Modi. Online-Bereitstellung, On-Demand-Interaktion und Offline-Batch-Verarbeitung müssen über dieselben logischen Daten hinweg funktionieren. On-Demand-Compute ist besonders wichtig, weil er zur Brücke zwischen Produktionsbereitstellung und groß angelegter Offline-Verarbeitung wird.
- Fünftens: offene Formate und keine erzwungene Migration. Die Speicherschicht sollte von externen Engines wie Spark, Ray und Daft lesbar sein. Bestehende Iceberg-Tabellen, Lance-Datasets und Parquet-Dateien sollten ohne unnötiges Kopieren in das System eingebunden werden können. Daten gehören dem Nutzer, nicht der Engine.
- Sechstens: Ressourcen sollten den Daten folgen. Compute kann verschwinden, wenn er nicht benötigt wird, während Metadaten sichtbar und abfragbar bleiben. Eine Anfrage kann Ressourcen innerhalb von Sekunden wieder zurückbringen. Inaktive Tenants sollten nicht für dedizierte Compute-Ressourcen bezahlen, die sie nicht nutzen. Das ist nicht nur Autoscaling; es erfordert, dass die Engine Ressourcenentscheidungen gemeinsam mit Datenentscheidungen trifft.
Das sind unsere aktuellen Überzeugungen, nicht das letzte Wort. Wir werden sie weiter überarbeiten, während das System reift. Aber ein Druck scheint sich kaum zu ändern: Unstrukturierte Daten werden weiter wachsen, während Infrastrukturbudgets nicht im gleichen Tempo wachsen werden. Das bedeutet, dass KI-Systeme iterativer, effizienter und kontinuierlich anpassungsfähiger werden müssen.
Vektordatenbanken verschwinden nicht
Um also auf die ursprüngliche Frage zurückzukommen: Bedeutet das, dass Vektordatenbanken verschwinden werden? Ganz und gar nicht.
Wenn überhaupt, wird semantisches Retrieval in dieser Architektur wichtiger. Aber seine Rolle ändert sich.
Vektordatenbanken werden zur Serving-Engine innerhalb eines größeren Systems für unstrukturierte Daten, ähnlich wie transaktionale Datenbanken in der umfassenderen Lakehouse-Ära unverzichtbar blieben. OLTP-Systeme wurden nicht durch Lakehouses ersetzt. Sie wurden zu einer Schicht innerhalb eines größeren Architektur-Stacks. Ich glaube, dass Vektordatenbanken jetzt denselben Übergang durchlaufen.
Der breitere Wandel, der unter der KI-Infrastruktur stattfindet, dreht sich nicht einfach um Retrieval. Es geht darum, kontinuierliche operative Schleifen um unstrukturierte Daten selbst aufzubauen. Serving erzeugt Feedback. Discovery verbessert die Datenqualität. Diese Verbesserungen fließen zurück in die Produktion. Jede Runde der Schleife macht das System besser.
Alles andere, einschließlich Speicherformaten, Caching-Hierarchien, Indexierungssystemen, elastischen Compute-Modellen und Ressourcenplanung, existiert, um dieses Schwungrad im großen Maßstab wirtschaftlich tragfähig zu machen.
Wir wissen immer noch nicht genau, was aus Vector Lakebase in den nächsten fünf Jahren werden wird. Als wir vor fast einem Jahrzehnt mit Milvus begannen, hätten wir ebenfalls nicht vorhersagen können, wohin Vektordatenbanken selbst führen würden.
Aber eines scheint jetzt klar. Unstrukturierte Daten werden weiter wachsen. Modelle werden sich weiter verändern. Agenten werden mehr Traces, Feedback und State erzeugen. Teams werden ihre Daten schneller verbessern müssen, ohne die Infrastrukturkosten unbegrenzt wachsen zu lassen.
Die Systeme, die erfolgreich sein werden, werden diejenigen sein, die kontinuierliches Serving und kontinuierliche Discovery wie Teile derselben Maschine wirken lassen. Das ist die Richtung, in die wir bauen.
Zilliz Vector Lakebase ist als öffentliche Vorschau verfügbar
Wir haben die öffentliche Vorschau von Zilliz Vector Lakebase gestartet — eine bedeutende Weiterentwicklung von Zilliz Cloud von einer verwalteten Vektordatenbank zu einer einheitlichen semantischen Datenplattform, die latenzarmes Vector Serving mit der Offenheit, Skalierbarkeit und Wirtschaftlichkeit eines Data Lake kombiniert.
Kernfunktionen von Zilliz Vector Lakebase:
- Gestuftes Serving, optimiert für unterschiedliche Echtzeit-Performance-Kosten-Abwägungen
- On-Demand-Suche für großskalige oder explorative Workloads ohne Always-on-Compute
- Suche in externen Data Lakes — direktes Indexieren und Suchen über Ihre vorhandenen Lake-Daten
- Vollspektrum-Suche über Vektoren, Text, JSON und Geodaten mit hybrider Retrieval und Reranking
- Einheitlicher lake-nativer Speicher auf Basis von Vortex, einem offenen Format mit schnelleren und günstigeren zufälligen Lesezugriffen als Lance oder Parquet
Wenn Ihr aktueller Stack Serving und Discovery in separate Systeme aufteilt, könnte Vector Lakebase einen Blick wert sein. Probieren Sie es auf Zilliz Cloud aus — neue Registrierungen mit geschäftlicher E-Mail erhalten $100 kostenloses Guthaben — oder sprechen Sie mit uns über Ihren Anwendungsfall.
Hinweis: Die Leistungs- und Kostenzahlen in diesem Artikel stammen aus Open-Source-VectorDB-Benchmark-Ergebnissen, internen Tests und anonymisierten Kundenszenarien. Die tatsächlichen Ergebnisse variieren je nach Datengröße, Verteilung, Indexparametern, Workload-Form und Ressourcenkonfiguration.

Weiterlesen

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.