




Wie man logische Fehler in GenAI-Modellen erkennt und korrigiert
Einleitung
[Große Sprachmodelle (Large Language Models, LLMs) (https://zilliz.com/blog/will-retrieval-augmented-generation-RAG-be-killed-by-long-context-LLMs) haben den Bereich der künstlichen Intelligenz (KI) verändert, vor allem in den Bereichen Konversations-KI, Texterzeugung usw. LLMs werden auf riesigen Datenmengen mit Milliarden von Parametern trainiert, um Text wie Menschen zu erzeugen. Viele Unternehmen freuen sich darauf, LLM-basierte Chatbots zu entwickeln, um Kundenanfragen zu bearbeiten, Bewertungen entgegenzunehmen, Beschwerden zu lösen usw. In dem Maße, wie die Nutzung und Einführung von LLM zunimmt, müssen wir uns mit einem kritischen Problem auseinandersetzen: Logische Fehler in der Ausgabe von LLMs. Es ist von entscheidender Bedeutung, diese Herausforderung zu bewältigen und KI-Systeme verantwortungsvoller und vertrauenswürdiger zu machen.
Jon Bennion, ein KI-Ingenieur mit umfangreicher Erfahrung in den Bereichen angewandtes ML, KI-Sicherheit und Evaluierung, diskutierte kürzlich auf dem Unstructured Data Meetup, das von Zilliz veranstaltet wurde, einen interessanten Ansatz zur Bekämpfung logischer Fehlschlüsse. Jon ist ein prominenter Mitwirkender bei LangChain, der neue Ansätze zur Bekämpfung von Fehlern in der Ausgabe implementiert.
Watch the replay of Jon's Talk
In seinem Vortrag erläutert Jon die häufigsten Fallstricke bei der Modellbildung, die zu logischen Fehlschlüssen führen können. Er erörtert auch Strategien zur Erkennung und Korrektur dieser Irrtümer und betont, wie wichtig es ist, die Modellergebnisse mit logisch fundierten und menschenähnlichen Überlegungen in Einklang zu bringen.
Was sind logische Irrtümer?
 Was sind logische Irrtümer?.png
Was sind logische Irrtümer?.png
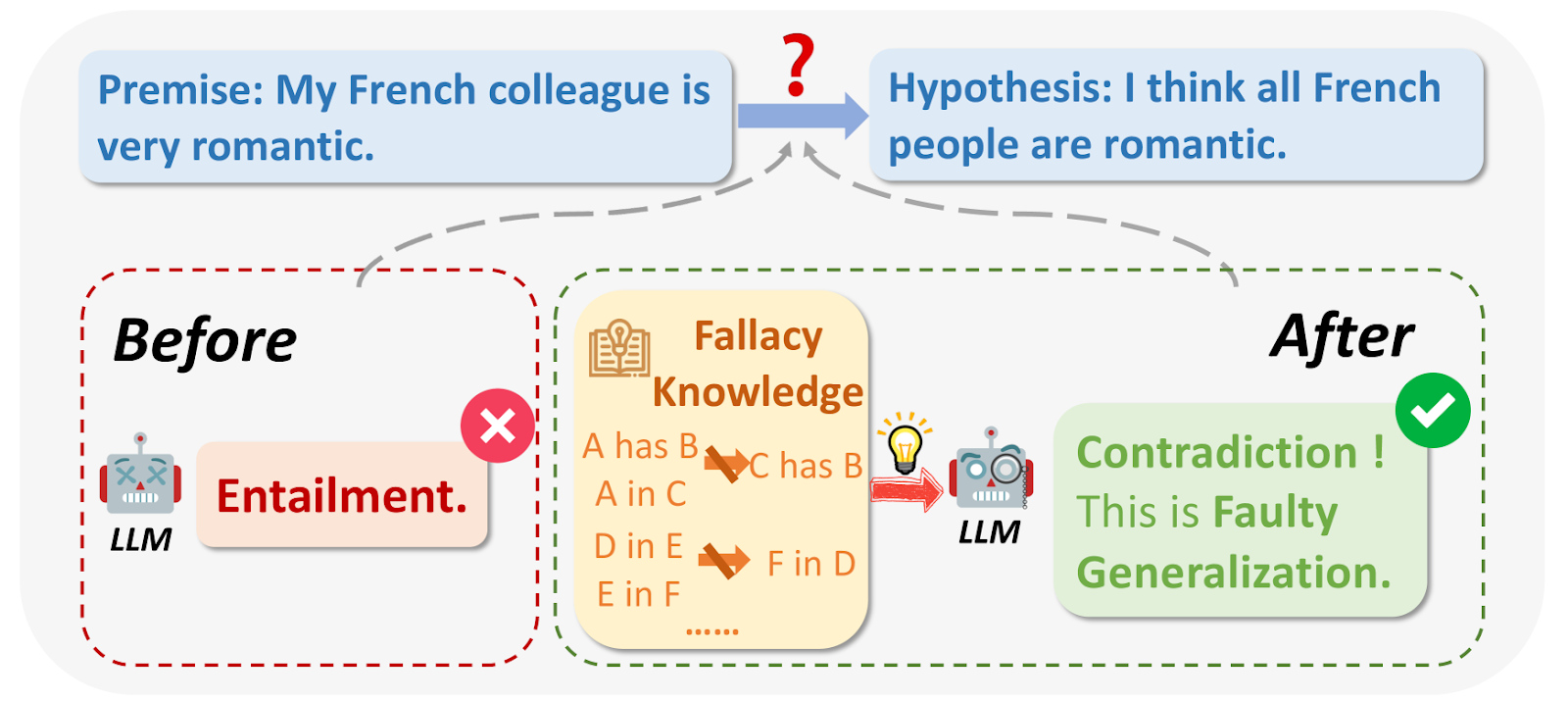
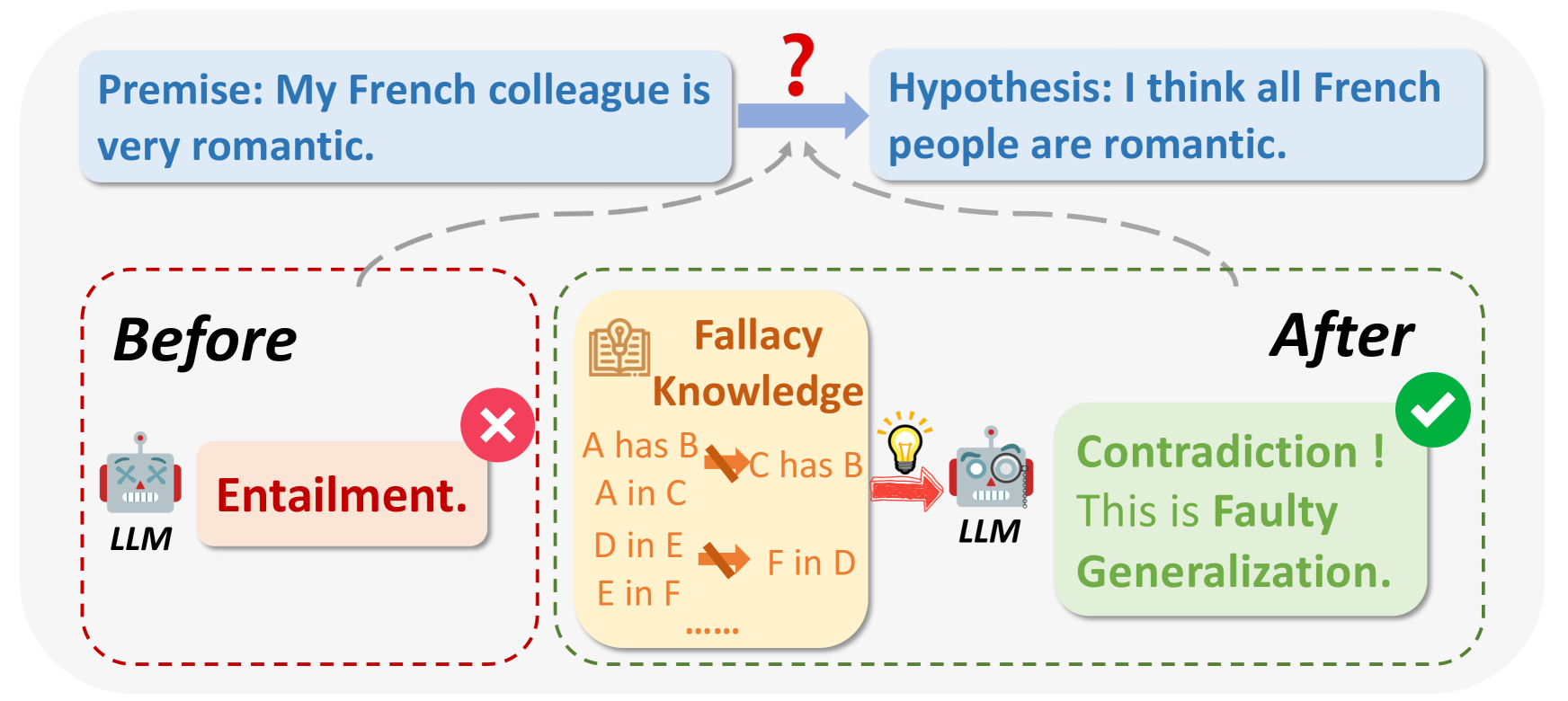
Abb. 1: Was sind logische Irrtümer?
Bildquelle: https://arxiv.org/html/2404.04293v1/x1.png
Bei der Abfrage von LLMs kann die Ausgabe in einigen Fällen aus logischen Gründen fehlerhaft oder für die Frage irrelevant sein. Zu den logischen Irrtümern gehören Ad Hominem, Zirkelschluss, Berufung auf Autorität, usw. Sie treffen oft weitreichende Verallgemeinerungen auf der Grundlage kleiner Stichproben, z. B.: "Mein Freund aus Frankreich ist unhöflich, also müssen alle Franzosen unhöflich sein."
In einigen wenigen Fällen wird angenommen, dass etwas wahr oder richtig ist, weil es beliebt ist.
Beispiel: "Alle benutzen diese neue App, also muss sie die beste sein." Manchmal fällt es den LLM schwer, sich an frühere Umstellungsdetails zu erinnern und sie können keine genaue Antwort geben.
Warum treten logische Fehler auf?
Es gibt mehrere Gründe, warum logische Irrtümer auftreten können, die an der Spitze stehen. Wie wir alle wissen, sind LLMs nicht perfekt darauf trainiert, mit allen Situationen so umzugehen, wie unser Gehirn sie begreifen würde.
Unvollkommene Trainingsdaten
Die Trainingsdaten, die wir zur Verfügung stellen, stammen aus verschiedenen Quellen im Internet und sind nicht perfekt. Sie enthalten viele menschliche Voreingenommenheiten, Ungereimtheiten und sogar Fehlinformationen in Grenzfällen. Während des Trainings wird das LLM mit fehlerhaften und inkonsistenten Argumenten konfrontiert und lernt auch diese. Wenn die Trainingsdaten fehlerhafte Argumente enthalten, wird das LLM diese Muster aufgreifen und sie in den Antworten nachahmen.
Kleines Kontextfenster
In dem Vortrag erwähnt Jon: "Ein kleines Kontextfenster kann zu Problemen bei der Antwort führen. Viele Teams bemühen sich, das Kontextfenster hinsichtlich Speicherbedarf und Leistung zu optimieren".
Das Kontextfenster bezieht sich auf die Menge an Informationen, die ein LLM zu einem bestimmten Zeitpunkt berücksichtigen kann, und es ist festgelegt. Wenn das Kontextfenster zu klein ist, kann das Modell wichtige Details übersehen und keine kohärente Antwort geben. Dies kann zu Irrtümern wie übereilten Verallgemeinerungen oder falschen Dichotomien führen.
Probabilistische Natur
LLMs generieren Text auf der Grundlage des Wortes, das in der Sequenz am wahrscheinlichsten ist. Sie können die wahren Bedeutungen von Wörtern nicht wie Menschen verstehen. Wir trainieren die Modelle, um eine lokale Kohärenz zu erreichen, die den Kontext voraussetzt. Manchmal kann dies zu logischen Fehlschlüssen führen, da der breitere Kontext übersehen werden kann.
Wie geht man mit logischen Fehlern um?
Es ist von entscheidender Bedeutung, das LLM zu erkennen und zu verhindern, dass es Antworten mit fehlerhafter Logik produziert, damit die Nutzer ihm vertrauen können. Jon erörtert kurz die gängigen Verfahren, die zur Lösung dieses Problems eingesetzt werden, wie z. B. menschliches Feedback, verstärkendes Lernen, Prompt Engineering und mehr.
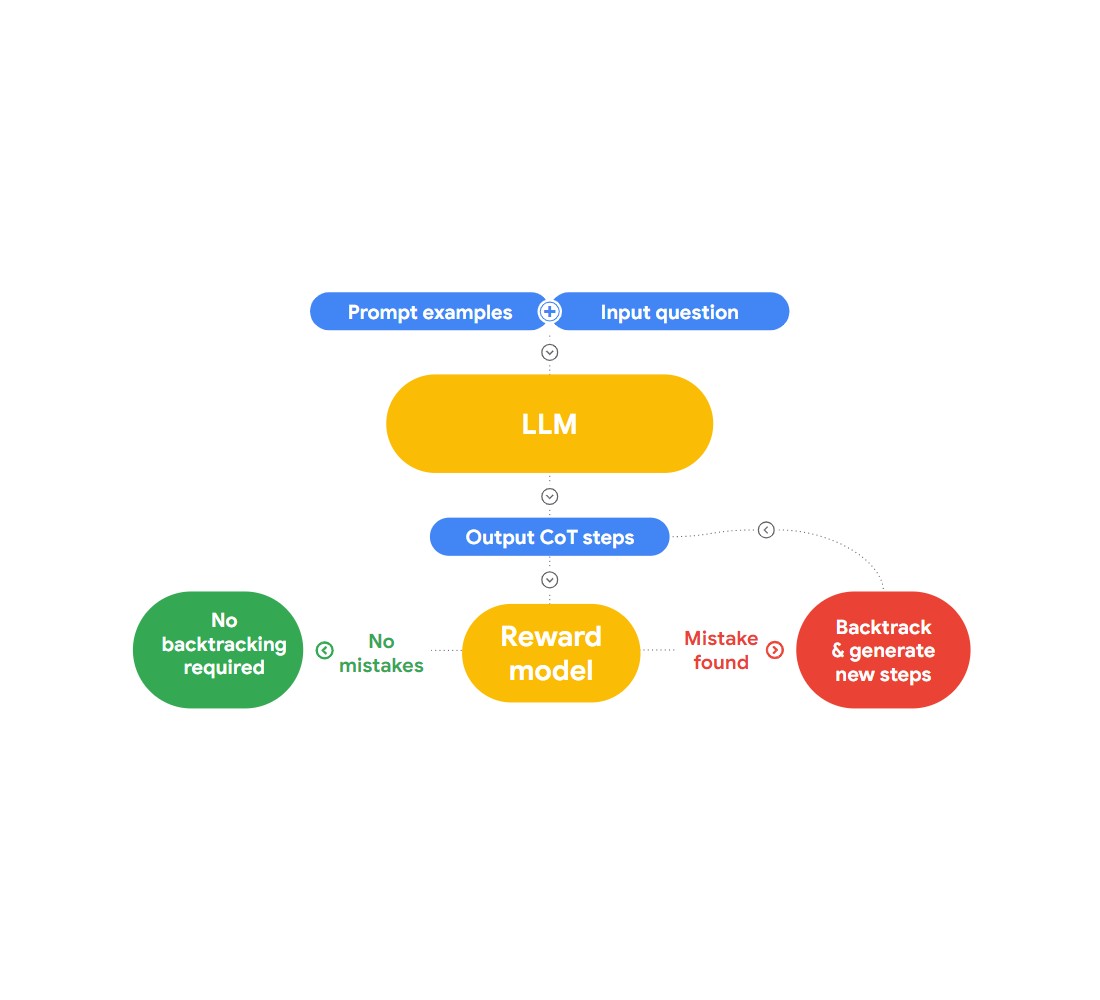
In diesem Vortrag stellt Jon einen interessanten Ansatz zum Erkennen und Korrigieren von logischen Fehlern vor, "RLAIF". Die Idee dabei ist, KI zu nutzen, um sich selbst zu korrigieren.
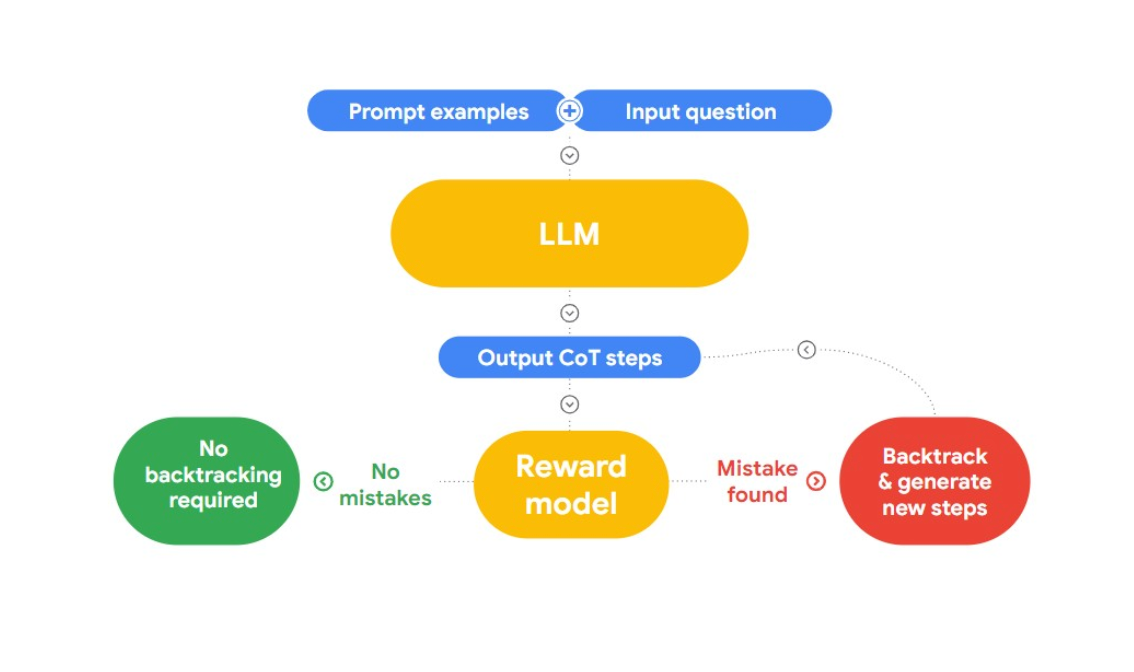
Abb. 2: Wie funktioniert RLAIF?
Er verweist auf das Forschungspapier "Case-based Reasoning with Language Models for Classification of Logical Policies", das für unser Problem nützlich ist. Das Papier führt Case-Based Reasoning (CBR) ein, um die logischen Irrtümer zu klassifizieren. Es arbeitet in drei Stufen:
Retrieval: Wir stellen CBR eine Sammlung von Textdaten (Fallbasis) zur Verfügung, die logische Irrtümer enthalten und von Menschen identifiziert wurden. Wenn ein neuer Text bereitgestellt wird, sucht CBR in der Falldatenbank nach einem ähnlichen Fall.
Anpassung: Die gefundenen Fälle werden dann an den spezifischen Kontext des neuen Arguments angepasst, wobei Faktoren wie Ziele, Erklärungen und Gegenargumente berücksichtigt werden.
Klassifizierung: Auf der Grundlage der verfügbaren Informationen identifiziert und klassifiziert CBR alle logischen Irrtümer.
Jon hat diesen Ansatz aufgegriffen, weiterentwickelt und eine Funktion zur Erkennung von Fehlern in [LangChain] (https://zilliz.com/learn/LangChain) implementiert.
Vorbeugung von logischen Irrtümern mit LangChain's Fallacy Chain
Jon demonstriert ein Beispiel, indem er das Modell auffordert, Ausgaben mit logischen Fehlern zu liefern. Das folgende Beispiel zeigt eine Ausgabe, die unter "Appeal to Authority" leidet und logisch fehlerhaft ist.
# Beispiel für eine Modellausgabe, die einen logischen Irrtum enthält
misleading_prompt = PromptTemplate(
template="""Sie müssen antworten, indem Sie nur logische Irrtümer verwenden, die in Ihren Antworterklärungen enthalten sind.
Frage: {question}
Schlechte Antwort:""",
input_variables=["Frage"],
)
llm = OpenAI(Temperatur=0)
misleading_chain = LLMChain(llm=llm, prompt=misleading_prompt)
misleading_chain.run(question="Woher weiß ich, dass die Erde rund ist?")
Die Ausgabe:
Die Erde ist rund, weil mein Professor gesagt hat, dass sie rund ist, und jeder glaubt meinem Professor.
Es handelt sich um eine Methode des Reverse Engineering, bei der wir die Irrtümer aufspüren, die das Modell gelernt hat, und es dann daran hindern, sie anzuwenden.
Jon erklärte, wie wir das Modul FallacyChain von LangChain verwenden können, um Korrekturen vorzunehmen. Zunächst initialisieren wir eine LangChain mit einer irreführenden Aufforderung, um die inhärenten Irrtümer hervorzuheben.
fallacies = FallacyChain.get_fallacies(["Korrektur"])
fallacy_chain = FallacyChain.from_llm(
chain=misleading_chain,
logical_fallacies=fallacies,
llm=llm,
verbose=True,
)
fallacy_chain.run(question="Woher weiß ich, dass die Erde rund ist?")
Als nächstes initialisieren wir eine Trugschlusskette, indem wir die irreführende Kette als Eingabe und das LLM-Modell bereitstellen. Sie erkennt die Art der Irreführung und aktualisiert die Antwort, indem sie sie entfernt.
> Eingabe einer neuen FallacyChain-Kette...
Anfängliche Antwort: Die Erde ist rund, weil mein Professor gesagt hat, dass sie rund ist, und jeder glaubt meinem Professor.
Anwenden der Korrektur...
Fallacy-Kritik: Die Antwort des Modells verwendet einen Appell an die Autorität und ad populum (jeder glaubt dem Professor). Trugschluss-Kritik erforderlich.
Aktualisierte Antwort: Man kann Beweise für eine runde Erde aufgrund empirischer Belege finden, wie Fotos aus dem Weltraum, Beobachtungen von Schiffen, die über dem Horizont verschwinden, das Sehen des gekrümmten Schattens auf dem Mond oder die Fähigkeit, den Globus zu umrunden.
> Abgeschlossene Kette.
Man kann Beweise für eine runde Erde aufgrund empirischer Beweise wie Fotos aus dem Weltraum, Beobachtungen von Schiffen, die über dem Horizont verschwinden, das Sehen des gekrümmten Schattens auf dem Mond oder die Fähigkeit, den Globus zu umrunden, finden.
Jon taucht in die Funktionsweise des Fallacy-Chain-Moduls ein, das er in LangChain integriert hat. Die Architektur der Fallacy Chain besteht aus zwei Hauptkomponenten: Die Critique Chain und die Revision Chain. In beiden Ketten wird Prompt-Engineering eingesetzt, um Falschaussagen in der Antwort zu erkennen und zu ändern. Ein kurzer Blick auf die Funktionsweise:
Wenn wir die Eingabe machen, verarbeitet der LLM sie und erzeugt eine erste Antwort.
Der nächste Schritt ist die Erkennung von Irrtümern. Die Kritikkette identifiziert und klassifiziert alle vorhandenen Trugschlüsse auf der Grundlage der identifizierten Muster. Jon erwähnt, dass die Liste der Trugschlüsse, die aus der oben erwähnten Forschungsarbeit extrahiert und verwendet wurde, genutzt wird.
Die Überarbeitungskette wird mit Prompt-Engineering kodiert, um eine überarbeitete Antwort zu erstellen, die die erkannten Trugschlüsse vermeidet. Dies kann eine Umformulierung, das Hinzufügen von Kontext oder eine Änderung der Argumentationsstruktur beinhalten.
Demo-Anwendung
Jon demonstrierte auch eine Anwendung zur Extraktion von logischen Fehlschlüssen aus Nachrichtenartikeln. In dieser Demo zeigte er, wie neue Artikel aus verschiedenen Regionen einen politischen, autoritären Bias haben können. Er demonstrierte auch eine Anwendung, die mit Open AI erstellt wurde, um neue Artikel zu einem bestimmten Thema zu extrahieren und ihre wichtigsten Trugschlüsse zu identifizieren. Mit dieser Anwendung suchte er nach neuen Artikeln, die sich auf das Schlüsselwort "China" bezogen, und das Ergebnis ist unten dargestellt.

In den Nachrichtenartikeln wird erklärt, wie die Fallacy Chain das Problem des "Appeal to Authority" (Berufung auf Autorität) erkannt und erklärt hat. Jon erörtert, wie Werkzeuge wie diese unsere Trainingsdaten von logischen Fehlschlüssen bereinigen können und dem Modell ein fehlerfreies Lernen ermöglichen. FallacyChain kann die Zuverlässigkeit von LLM-Ergebnissen erheblich verbessern und das Vertrauen der Nutzer erhöhen. Es bietet auch Transparenz, indem es die Änderungen und ihre Gründe erklärt und den Nutzern hilft zu verstehen, wie die logische Kohärenz erreicht wurde.
Weitere Informationen zu dieser Demo finden Sie in der Aufzeichnung von Jons Meetup-Vortrag.
Schlussfolgerung
Die FallacyChain in LangChain ist ein leistungsfähiger Ansatz zur Verbesserung der logischen Integrität von LLM-generiertem Text. Sie kann das Vertrauen unter den Nutzern erhöhen und es einfacher machen, LLMs gemäß den Vorschriften zu implementieren. Während die Vorteile erstaunlich sind, ist es notwendig, die Kosten für die Umsetzung in großem Maßstab zu bewerten. Es handelt sich um einen spannenden Bereich, und es werden neue Experimente durchgeführt, um ihn durch den Einsatz von Methoden des maschinellen Lernens zur Klassifizierung von Fehlern usw. zu verbessern.

{kind=link}
{kind=link}
Weiterlesen

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.