




Auto-GPT erklärt: Ein umfassender Auto-GPT-Leitfaden für Ihren individuellen Anwendungsfall
Dieser Artikel wurde ursprünglich in The Sequence veröffentlicht und wird hier mit Genehmigung erneut veröffentlicht.
Im Dezember 2022 brachte ChatGPT, die von GPT betriebene Chatbot-Oberfläche, große Sprachmodelle (LLMs) in die Mainstream-Medien. Seitdem sind zahlreiche GPT-Apps aufgetaucht. Eine der beliebtesten? Auto-GPT. Eine Open-Source-App auf GPT-Basis, die darauf abzielt, GPT vollständig autonom zu machen. Innerhalb weniger kurzer Wochen hat sie über 120.000 Sterne auf GitHub gesammelt und damit PyTorch, Scikit-Learn, HuggingFace Transformers und jede andere Open-Source-KI/ML-Bibliothek, die Ihnen einfällt, überholt.
Was macht Auto-GPT zu einem so beliebten Projekt? Erstens zeigt es vielversprechende Ansätze, die selbst beschriebene Vision eines autonomen GPT zu erfüllen. Auto-GPT hat „Agenten“ integriert, um das Web zu durchsuchen, zu sprechen, Gespräche nachzuverfolgen und mehr. Menschen haben es genutzt, um Pizza zu bestellen, Apps zu programmieren und Merch zu verkaufen. Jetzt sind Sie an der Reihe zu lernen, wie Sie Auto-GPT nutzen können, um Ihren Workflow zu beschleunigen und alltägliche Aufgaben zu automatisieren.
In diesem Auto-GPT-Tutorial lernen Sie:
- Was ist Auto-GPT?
- So richten Sie Auto-GPT in wenigen Minuten ein
.envfür Auto-GPT konfigurieren
- Ihre erste Aufgabe mit Auto-GPT ausführen
- Auto-GPT Speicher hinzufügen
- Milvus Standalone verwenden (Docker Compose)
- Milvus Lite verwenden (Pip Install)
- Zusammenfassung von „Auto-GPT erklärt“
Was ist Auto-GPT?
KI ist in letzter Zeit ein heißes Thema. Berichten zufolge ist ChatGPT die am schnellsten wachsende App aller Zeiten und erreichte im Februar 2023 monatlich über 1 Milliarde Besucher. LLMs wurden als das Aufkommen von Artificial General Intelligence (AGI), die Zukunft der Software und der technologische Durchbruch angepriesen, der die Menschheit zur Erleuchtung oder in die Zerstörung führen wird. LLMs haben jedoch einen eklatanten Fehler. Sie können nicht eigenständig handeln. Sie benötigen jemanden, der sie wiederholt von Aufgabe zu Aufgabe auffordert.
Auto-GPT will dieses Problem lösen. Auto-GPT ist eine Open-Source-Software, die darauf abzielt, GPT-4 autonom funktionieren zu lassen. Wie bietet sie diese Autonomie? Durch den Einsatz von Agenten. Auto-GPT ermöglicht es Nutzern, Agenten zu starten, um Aufgaben wie das Surfen im Internet, das Sprechen über Text-to-Speech-Tools, das Schreiben von Code, das Nachverfolgen seiner Ein- und Ausgaben und mehr auszuführen.
Diese erweiterte Funktionalität befeuert den Hype und das Untergangs- und Trübsal-Narrativ der Medien. Sie müssen jedoch keine Angst vor KI haben. Solange Sie verstehen, wie Sie KI zu Ihrem eigenen Vorteil nutzen können, kann Ihr KI-Narrativ positiv und produktiv sein. Schauen wir uns also an, wie Sie Auto-GPT in nur wenigen Minuten auf Ihrem lokalen Rechner zum Laufen bringen können.
So richten Sie Auto-GPT in wenigen Minuten ein
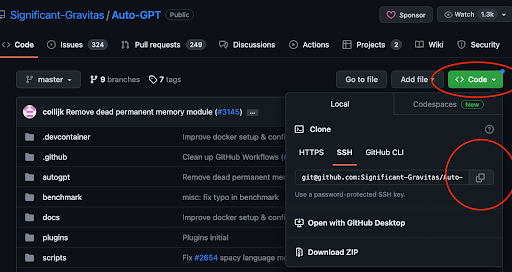 So konfigurieren Sie auto-GPT
So konfigurieren Sie auto-GPT
Auto-GPT ist überraschend einfach einzurichten. Gehen Sie zuerst zur Auto-GPT-GitHub-Seite und kopieren Sie den Clone-Link. Öffnen Sie dann Ihr Terminal oder Ihre VSCode-Instanz und navigieren Sie zu einem Arbeitsverzeichnis. Bei mir ist es ~/Documents/workspace. Verwenden Sie git clone [git@github.com](mailto:git@github.com):Significant-Gravitas/Auto-GPT.git, um das Repo lokal zu klonen. Navigieren Sie als Nächstes zum neu erstellten Ordner.
Erstellen Sie im neu erstellten Ordner eine neue virtuelle Python-Umgebung, damit Sie eine saubere Ausgangsbasis haben. Sobald Sie sich in Ihrer virtuellen Umgebung befinden, führen Sie pip install -r requirements.txt aus, um alle Abhängigkeiten zu installieren. Wir haben Auto-GPT nun installiert. Das Letzte, was wir tun müssen, um eine Instanz zum Laufen zu bringen, ist, unseren OpenAI-API-Schlüssel in die Umgebungsvariablen einzutragen.
.env für Auto-GPT konfigurieren
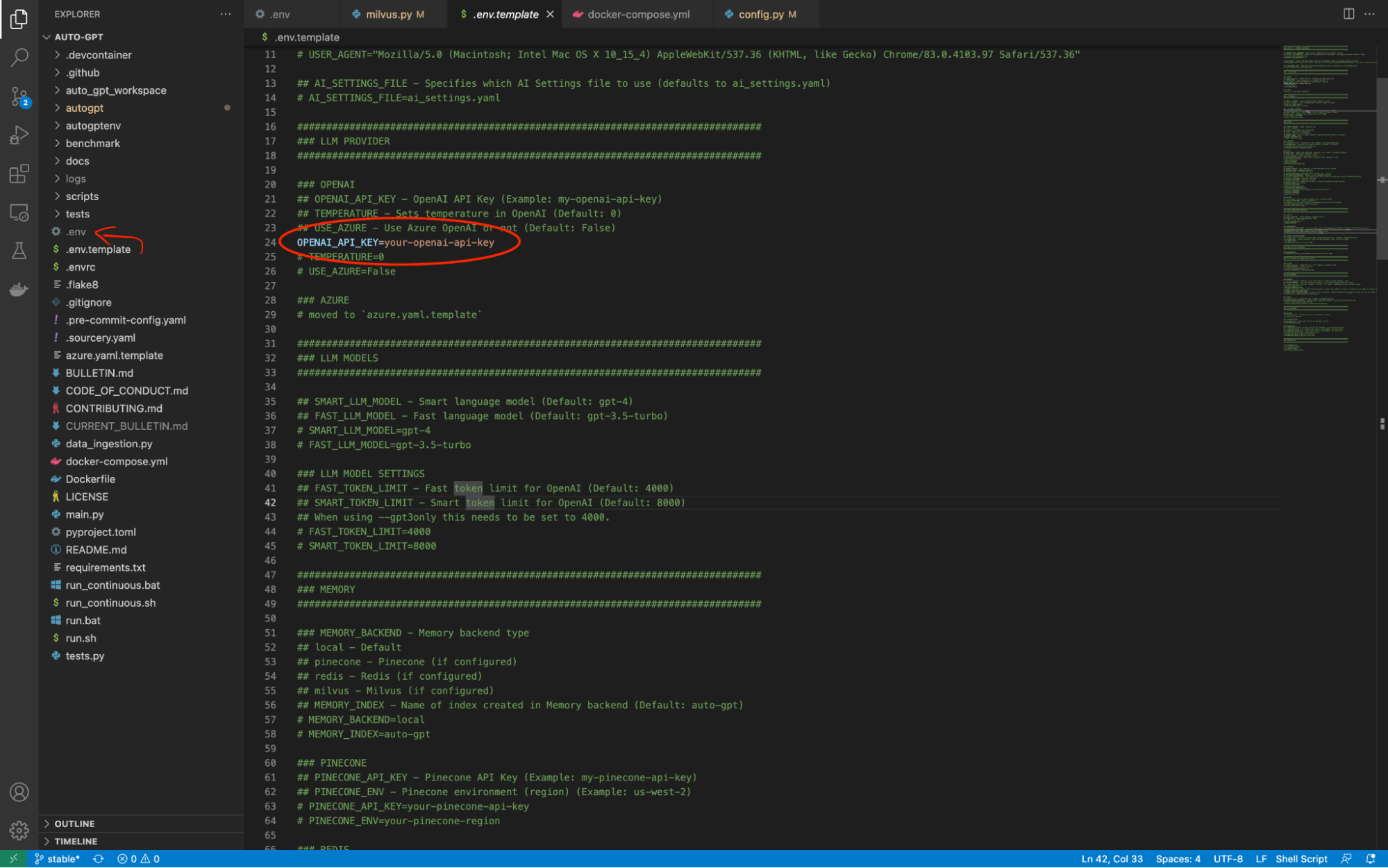 configure-env.png
configure-env.png
Auto-GPT hat in seinem Stammverzeichnis eine Datei mit dem Namen .env.template. Wir müssen diesen Dateinamen einfach in .env ändern. Dann können wir diese Datei verwenden, um alle Informationen zu speichern, die wir benötigen, um eine Verbindung zu den externen Tools herzustellen, die Auto-GPT seine autonomen Fähigkeiten verleihen. Es gibt eine Änderung, die wir vornehmen müssen, bevor wir Auto-GPT überhaupt starten können. Wir müssen den Wert von OPENAI_API_KEY in unseren OpenAI API-Schlüssel ändern.
Führe deine erste Aufgabe mit Auto-GPT aus
 run-task-auto-gpt.png
run-task-auto-gpt.png
Wenn dein OpenAI API-Schlüssel aktualisiert ist, kannst du Auto-GPT verwenden, um einige Arbeiten für dich zu automatisieren. In diesem Beispiel automatisieren wir die Erstellung eines Newsletters über die einflussreichsten Entwicklungen im Bereich KI des vergangenen Monats. Führe python -m autogpt in deinem Terminal aus, um es zu starten. Wenn wir Auto-GPT starten, fordert es uns auf, ihm einen Namen zu geben, eine Rolle dafür zu definieren und ihm einige Ziele zu geben.
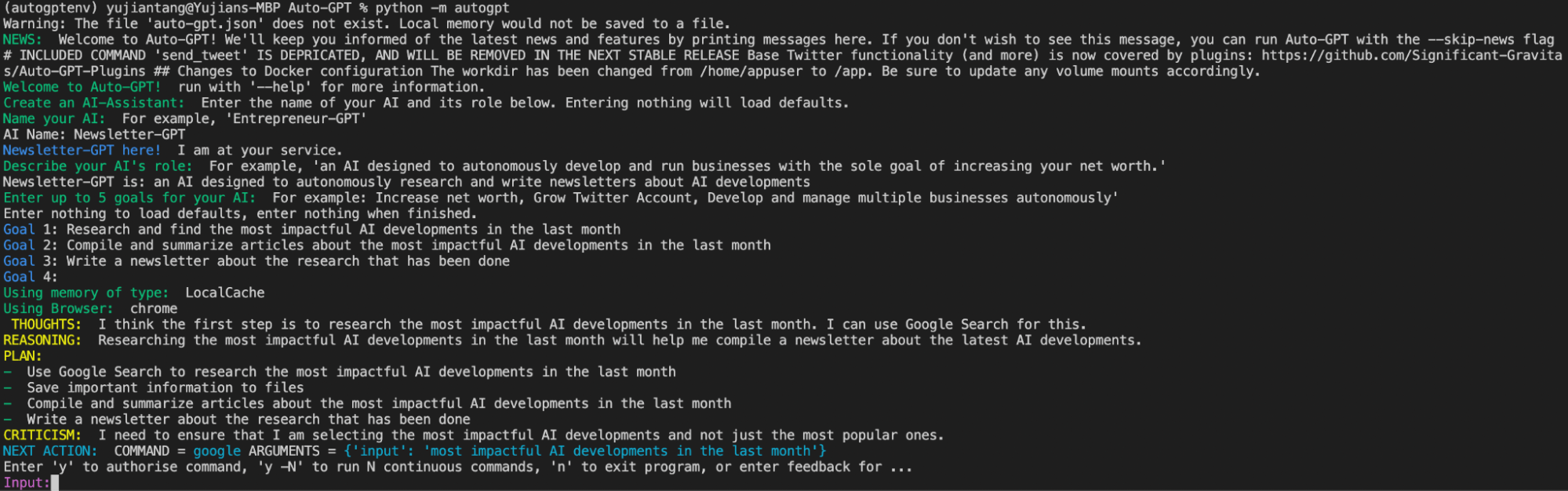 run-first-task-auto-gpt.png
run-first-task-auto-gpt.png
In diesem Beispiel nennen wir unsere KI „Newsletter-Generator“. Bei der nächsten Eingabeaufforderung teilen wir der KI mit, dass Newsletter-Generator eine KI ist, die darauf ausgelegt ist, autonom Newsletter über KI-Entwicklungen zu recherchieren und zu schreiben. Als Nächstes fordert Auto-GPT uns auf, unserer KI bis zu fünf Ziele zu geben.
Ich habe Newsletter-Generator drei Ziele gegeben. Erstens soll er die einflussreichsten KI-Entwicklungen des vergangenen Monats recherchieren und finden. Zweitens soll er Artikel über die einflussreichsten KI-Entwicklungen des vergangenen Monats zusammenstellen und zusammenfassen. Drittens soll er einen Newsletter über die durchgeführte Recherche schreiben. Sobald die Einrichtung abgeschlossen ist, erstellt Auto-GPT eine Datei namens ai_settings.yaml, um diese Konfiguration zu speichern, und beginnt mit seinen Aufgaben.
Für jede Aufgabe liefert es Gedanken, Begründungen, einen Plan, eine Kritik an seinem Plan und den nächsten Schritt. Bevor es eine Aufgabe ausführt, fordert es uns zur Genehmigung oder zu Feedback zu seinem Plan auf. Wenn wir möchten, können wir ihm erlauben, die nächsten N Aufgaben autonom auszuführen, ohne uns zur Genehmigung aufzufordern.
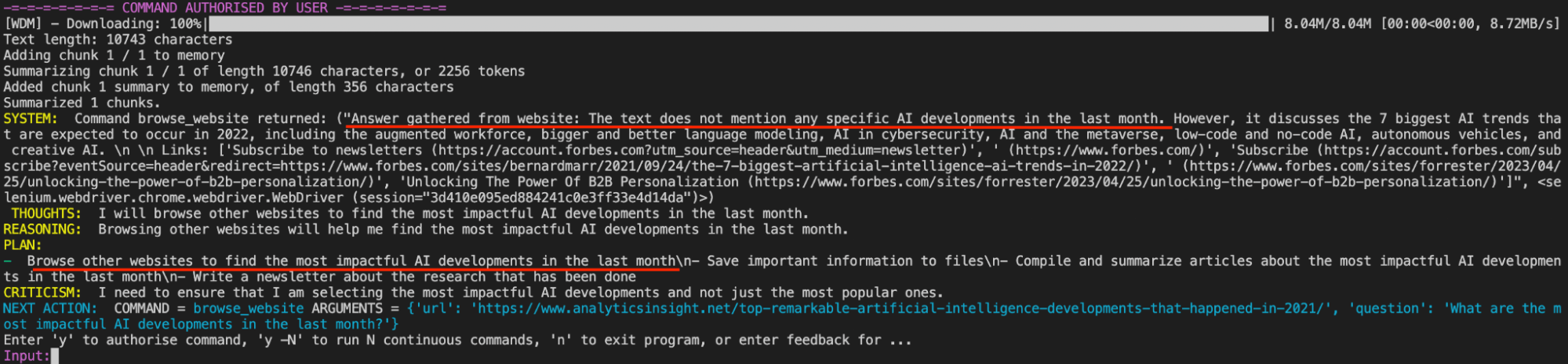 auto-gpt-ability.png
auto-gpt-ability.png
Im obigen Bild sehen wir die Fähigkeit von Auto-GPT zu erkennen, dass der erste Artikel, den es auf Google gefunden hat, tatsächlich nicht die notwendigen Informationen enthält, um seine Aufgabe zu erledigen. Es gibt uns dies zurück und erarbeitet dann den nächsten Schritt, um die einflussreichen KI-Entwicklungen des vergangenen Monats zu erhalten.
Speicher zu Auto-GPT hinzufügen
 adding-memory-auto-gpt.png
adding-memory-auto-gpt.png
Wenn die standardmäßige „lokale“ Speicheroption von Auto-GPT verwendet wird, erstellt Auto-GPT ein Dokument namens auto-gpt.json, das ungefähr wie das obige Bild aussieht. Es enthält einen Textblock, gefolgt von einer Reihe von Zahlen. Die Textblöcke verfolgen deine aktuelle Unterhaltung mit Auto-GPT, und die Zahlen sind die Vektor-Embeddings, die diese Unterhaltung darstellen.
Die Verwendung einer JSON-Datei als Speicher ist keine skalierbare Lösung. Je mehr du mit Auto-GPT arbeitest, desto mehr Daten erzeugt es. Nicht nur in Form eines Speichers deiner bisherigen Unterhaltung, sondern auch Dateien zum Schreiben und zusätzliche „Agenten“. Während JSON diese Informationen verfolgen kann, benötigst du ein dauerhaftes Speicher-Backend, wenn du jemals etwas suchen, abrufen oder bearbeiten möchtest, das du erstellt hast.
Glücklicherweise kann Auto-GPT viele verschiedene Memory-Backends verwenden. Da wir Vektordaten speichern, ist eine Vektordatenbank wie Milvus eine ideale Lösung. Milvus ist eine Open-Source-Vektordatenbank mit mehreren Lösungen, einschließlich verteilter Lösungen zur Ausführung auf Kubernetes oder Docker sowie einer Möglichkeit, eine lokale Instanz auszuführen. In diesem Beispiel behandeln wir zwei Möglichkeiten, Milvus als Backend zu verwenden.
Zunächst behandeln wir, wie man Milvus Standalone verwendet, eine verteilte Lösung mit Docker Compose, die Sie lokal ausführen können. Zweitens behandeln wir, wie man Milvus Lite verwendet, um eine Vektordatenbank in Ihrem Python-Code zu instanziieren und zu nutzen. Die erste Lösung erfordert nur ein paar Änderungen am Auto-GPT-Code, setzt jedoch voraus, dass Sie Milvus über Docker Compose herunterladen. Die zweite Lösung erfordert einige weitere Änderungen am bestehenden Paket, ermöglicht es Ihnen aber, Milvus nur mit einem pip install zu verwenden.
Verwendung von Milvus Standalone (Docker Compose)
Die Verwendung von Milvus Standalone als Memory-Lösung erfordert weniger Änderungen am Auto-GPT-Code, setzt aber Docker voraus. Befolgen Sie die Anweisungen zu Milvus Standalone und bringen Sie eine Instanz in einem lokalen Docker-Container zum Laufen.
Sobald wir eine Milvus-Instanz am Laufen haben, müssen wir nur wenige Änderungen vornehmen, damit Auto-GPT unsere Milvus-Instanz für die Langzeitspeicherung verwendet. Suchen Sie in der Datei .env nach MEMORY_BACKEND und ändern Sie den Wert von local zu milvus. Suchen Sie dann nach MILVUS. Unterhalb von MILVUS befinden sich zwei Umgebungsvariablen, MILVUS_ADDR und MILVUS_COLLECTION. Kommentieren Sie diese aus. Sie können die Standardwerte beibehalten.
Führen Sie pip install pymilvus aus, um das Milvus SDK zu erhalten. Starten Sie anschließend Auto-GPT erneut mit python -m autogpt. Diesmal sollten Sie eine Änderung bemerken. Das Terminal sollte eine Meldung Using memory of type: MilvusMemory anzeigen. Das ist alles, was nötig ist, um Milvus zu Auto-GPT hinzuzufügen.
 add-milvus-auto-gpt.png
add-milvus-auto-gpt.png
Verwendung von Milvus Lite (Pip Install)
Hinweis: Der Pull Request, um diese Änderungen in Auto-GPT zu übernehmen, ist offen.
Im Gegensatz zu Milvus Standalone hat Milvus Lite keine zusätzlichen Abhängigkeiten. Wir installieren Milvus Lite und das Milvus Python SDK mit pip, indem wir pip install milvus pymilvus ausführen. Da wir Milvus nicht extern starten werden, bevor wir Auto-GPT starten, muss es starten, während Auto-GPT eingerichtet wird.
Dies tun wir, indem wir Änderungen in drei Dateien vornehmen: .env, autogpt/memory/milvus.py und autogpt/config/config.py. Wir beginnen mit denselben Änderungen wie bei der Milvus-Standalone-Instanz. Ändern Sie die Variable MEMORY_BACKEND zu milvus und kommentieren Sie die Variablen MILVUS_ADDR und MILVUS_COLLECTION aus. Fügen Sie im Milvus-Abschnitt der Datei .env eine neue Umgebungsvariable namens MILVUS_TYPE hinzu und setzen Sie sie auf lite.
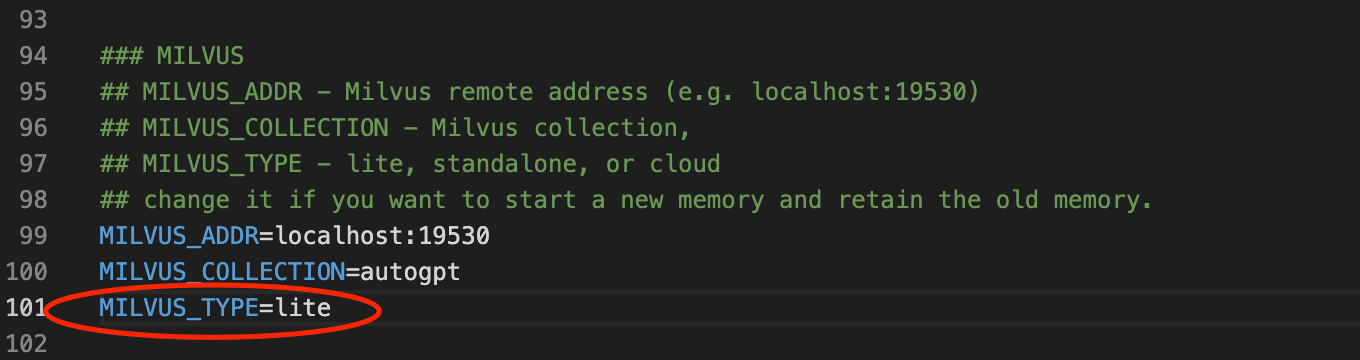 milvus-type.png
milvus-type.png
Es gibt zwei Dateien unter dem Ordner autogpt, an denen wir Änderungen vornehmen. Setzen Sie in der Datei config.py im Ordner config den Wert milvus_type so, dass MILVUS_TYPE aus den Umgebungsvariablen gelesen wird.
# milvus type can be standalone, lite, or cloud
self.milvus_type = os.getenv("MILVUS_TYPE")
In der Datei milvus.py im Ordner memory fügen wir eine if-Anweisung hinzu, die den Wert von milvus_type in der Konfiguration prüft. Wenn der Wert lite ist, importieren wir Milvus, starten einen Server und stellen eine Verbindung zum standardmäßigen Milvus-Lite-Server her. Wir verschieben die ursprüngliche Codezeile in die else-Anweisung.
if cfg.milvus_type == "lite":
from milvus import default_server
print("Starting Milvus Lite")
default_server.start()
connections.connect(host='127.0.0.1', port=default_server.listen_port)
else:
connections.connect(address=cfg.milvus_addr)
Sobald diese Änderungen vorgenommen wurden, können wir Auto-GPT wie gewohnt ausführen. Das Ausführen von python -m autogpt startet eine Instanz von Auto-GPT mit einer leicht anderen Startausgabe. Das Terminal sollte eine Zeile anzeigen, in der „Starting Milvus Lite“ steht, sowie den Ausgabetext von Milvus Lite. Es sollte weiterhin „Using memory of type: MilvusMemory“ anzeigen.
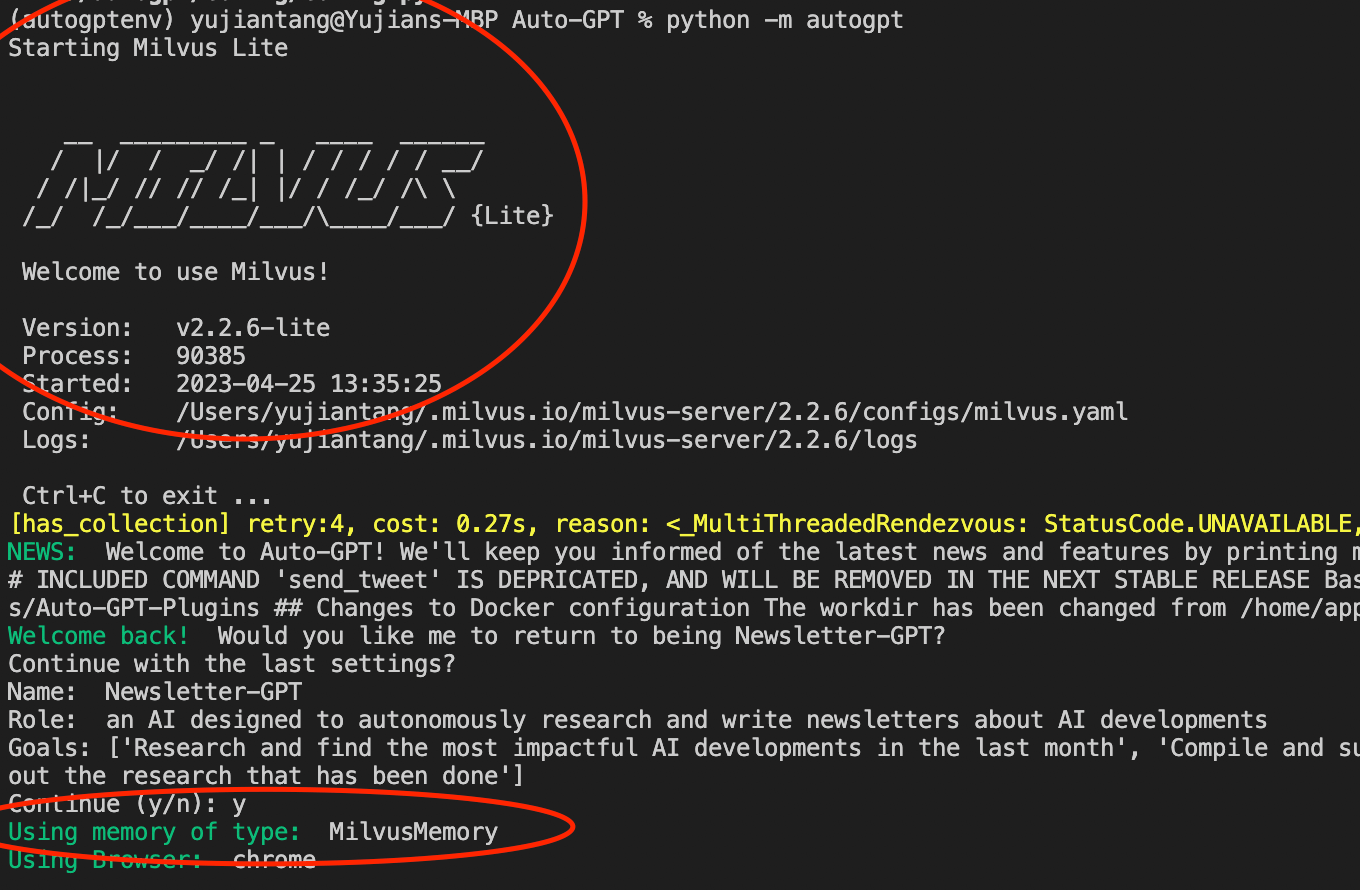 milvus-memory.png
milvus-memory.png
Zusammenfassung von „Auto GPT erklärt“
In diesem Artikel haben wir uns die Grundlagen von Auto-GPT angesehen. Zuerst haben wir Auto-GPT von GitHub heruntergeladen und eine Instanz zum Laufen gebracht. Nachdem es lief, haben wir uns die von Auto-GPT erzeugten Dateien angesehen. Beim Betrachten der Dateien von Auto-GPT haben wir festgestellt, dass es lokal eine JSON-Datei voller Vektoren verwendet, um seinen Speicher zu verwalten.
JSON-Dateien sind nicht skalierbar. Für ein robusteres Speicher-Backend verwenden wir die Milvus-Vektordatenbank, eine der anderen in Auto-GPT integrierten Speicheroptionen. Wir zeigen, wie man ein Milvus-Backend auf zwei Arten hinzufügt: als Satz eigenständiger Docker-Container oder als von Auto-GPT gestartete Instanz. Bleiben Sie dran für weitere Beiträge über Vektordatenbanken mit LLMs.

Weiterlesen

Why We Built Vector Lakebase: Rethinking Unstructured Data Architecture for AI
Vector Lakebase: a unified, lake-native data foundation for AI workloads — and an answer to what happens after vector databases succeed.

DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Discover how DeepSeek-OCR uses visual tokens and Contexts Optical Compression to boost long-context LLM efficiency and reshape RAG performance.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.