




Datenbeherrschung leicht gemacht: Die Magie von Vektordatenbanken in Jupyter Notebooks entdecken
Anthropic hat kürzlich eine 100k-Token-Version von Claude veröffentlicht. Google hat kürzlich PaLM 2 veröffentlicht. Und natürlich sind wir uns inzwischen alle GPT und ChatGPT von OpenAI sehr bewusst. Große Sprachmodelle (LLMs) haben die Geschwindigkeit der KI-Einführung vorangetrieben und damit auch die Nachfrage nach Vektordatenbanken erhöht.
Warum? Weil Vektordatenbanken dabei helfen können, eines der größten Probleme zu lösen, mit denen LLMs konfrontiert sind – ein Mangel an Domänenwissen und aktuellen Daten. Außerhalb von LLMs zeigen Vektordatenbanken auch ihren Nutzen beim Betrieb von Anwendungen für Ähnlichkeitssuche. Darüber hinaus sind sie notwendig für die Arbeit an Produktempfehlungen, umgekehrter Bildsuche und semantischer Textsuche.
Wie kannst du mit einer Vektordatenbank in deinem Jupyter Notebook beginnen? Dieses Tutorial behandelt:
- Was ist eine Vektordatenbank?
- Wie man eine Vektordatenbank in deinem Jupyter Notebook verwendet
- Was ist Milvus (Lite)?
- Zusammenfassung einer Vektordatenbank in deinem Jupyter Notebook
Dies gilt gleichermaßen für CoLab-Notebooks. Hier sind zwei für dich: ein CoLab-Notebook für umgekehrte Bildsuche, und ein CoLab-Notebook für semantische Textsuche.
Was ist eine Vektordatenbank?
Bevor wir in das Tutorial einsteigen, wollen wir ein grundlegendes Verständnis von Vektordatenbanken gewinnen. Eine Vektordatenbank ist dafür konzipiert, Vektordaten zu speichern, zu indexieren und abzufragen. Sie werden hauptsächlich für die Arbeit mit unstrukturierten Daten wie Bildern, Text oder Video verwendet. Zuerst lässt du deine Daten durch ein bestehendes neuronales Netzwerk laufen, um die Vektoreinbettungen zu erhalten, die normalerweise aus der vorletzten Schicht extrahiert werden.
Diese Vektoreinbettungen werden dann in einer Vektordatenbank gespeichert. Sobald deine Vektoreinbettungen gespeichert sind, kannst du die Vektordatenbank nach den top k ähnlichsten Dateneinträgen über Vektoreinbettungen abfragen, wie in den oben genannten CoLab-Notebooks gezeigt. Einige der Werkzeuge, die Vektordatenbanken für dich abstrahieren, umfassen:
- Vektorindizes, die du andernfalls einbinden müsstest.
- Vektorsuchalgorithmen wie HNSW.
- Eine Möglichkeit, mit einer persistenten Speicherschicht zu kommunizieren.
Was ist Milvus (Lite)?
Milvus ist eine Vektordatenbank mit einem verteilten, systemnativen Backend. Sie wurde speziell dafür entwickelt, das Indexieren, Speichern und Abfragen von Vektordaten im Milliardenmaßstab zu bewältigen. Milvus verwendet mehrere Schichten und Arten von Worker-Nodes für ein leicht skalierbares Design. Zusätzlich zur Verwendung mehrerer Single-Purpose-Nodes nutzt Milvus auch segmentierte Daten für eine effizientere Indexierung. Milvus verwendet 512MB-Datensegmente, die nach dem Befüllen nicht mehr verändert werden, und fragt sie parallel ab, um die niedrigste Latenz in der gesamten Branche zu bieten.
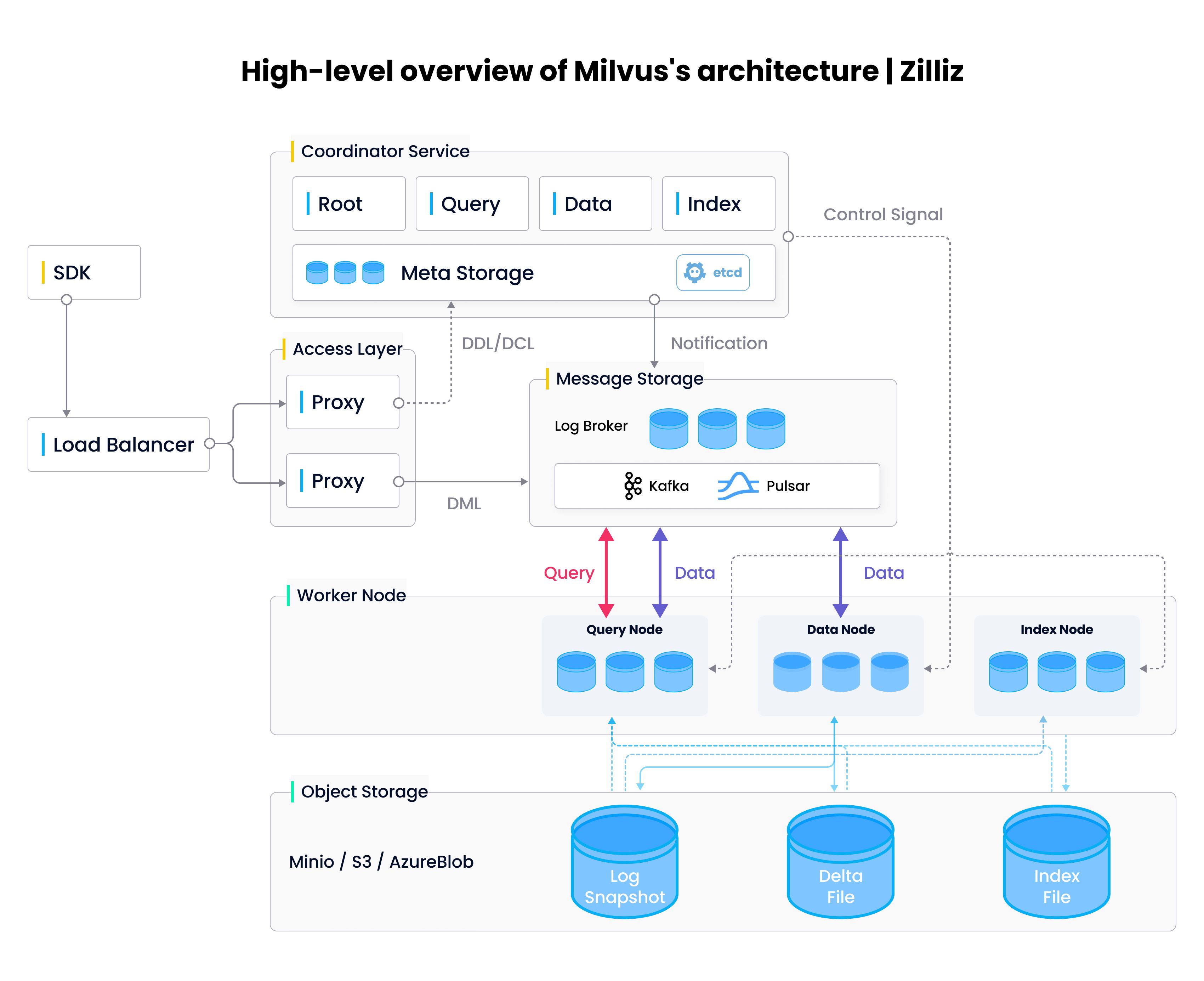 High-Level-Architektur der Milvus-Vektordatenbank
High-Level-Architektur der Milvus-Vektordatenbank
Typischerweise würdest du Docker Compose, Helm oder den Milvus Operator verwenden, um eine Milvus-Instanz zu starten. Milvus Lite ermöglicht es dir jedoch, eine Milvus-Instanz direkt aus deinem Jupyter Notebook oder Python-Skript zu starten. Es funktioniert auf die gleiche Weise wie Milvus und speichert alle deine Daten lokal.
Wie man eine Vektordatenbank in deinem Jupyter Notebook verwendet
Du kannst mit einer Vektordatenbank wie Milvus Lite direkt in deinem Notebook über eine pip-Installation beginnen. Führe in der ersten Zeile deines Jupyter Notebook ! pip install pymilvus milvus aus. Sobald du pymilvus und milvus installiert hast, kannst du die Vektordatenbank starten und dich innerhalb eines iPython-Notebooks mit ihr verbinden.
Das Modul milvus stellt Milvus Lite bereit, und das Modul pymilvus stellt eine Python-Schnittstelle zur Verbindung mit Milvus bereit. Zu Beginn importieren wir drei Module. Erstens default_server aus milvus. Zweitens,connections aus pymilvus, und drittens utility aus pymilvus. Wir verwenden die Funktion start() aus dem default_server, um den Server zu starten. Sobald der Server gestartet ist, verbinden wir uns mit connect aus connections und übergeben den Host, localhost oder 127.0.0.1, sowie den Port, der vom Standardserver abgerufen wird.
from milvus import default_server
from pymilvus import connections, utility
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
Sobald Sie mit Milvus verbunden sind, können Sie utility verwenden, um Ihre Datenbank zu überprüfen. Rufen Sie zum Beispiel get_server_version() auf, um sicherzustellen, dass Sie die neueste Version haben, nach der Sie im Milvus Blog suchen können. Sie können utility auch verwenden, um nach collections zu suchen, separaten Tabellen in Milvus. Wenn Sie neu beginnen möchten, können Sie prüfen, ob eine Collection mit dem Namen, den Sie verwenden möchten, bereits in Gebrauch ist, und sie entweder mit drop_collection löschen oder einen neuen Namen wählen.
utility.get_server_version()
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
Möchten Sie noch weiter gehen und eine Vektordatenbank in der Produktion oder für ein größeres Projekt verwenden? Ziehen Sie Zilliz Cloud oder Milvus Standalone in Betracht.
Zusammenfassung: So verwenden Sie eine Vektordatenbank in Ihrem Jupyter Notebook
In diesem Beitrag haben wir gelernt, dass Vektordatenbanken immer dann hilfreich sind, wenn Sie etwas tun müssen, das eine Ähnlichkeitssuche beinhaltet. Sie helfen dabei, Vektor-Embedding-Repräsentationen unstrukturierter Daten wie Bilder, Videos oder Text zu indizieren, zu speichern und abzufragen. Anschließend sehen wir uns ein Beispiel für die Verwendung einer Vektordatenbank in Ihrem Jupyter Notebook über Milvus Lite an.
Zum Schluss werfen wir einen Blick unter die Haube von Milvus, um das Backend des verteilten Systems zu sehen. Außerdem stellen wir Ressourcen bereit, um anhand von Beispielen in CoLab-Notebooks zu verstehen, wie man mit der Verwendung einer Vektordatenbank beginnt. Für diejenigen, die eine eigenständige Vektordatenbankinstanz verwenden möchten, stellen wir auch Beispiele dafür bereit, wie Milvus Standalone eingerichtet wird.

Weiterlesen

Zilliz Skills Breakdown: How AI Agents Master Vector Databases
Zilliz's Milvus Skill (pymilvus, 7 files) and Zilliz Cloud Skill (zilliz-cli, 14 modules) bring vector-DB dev and ops into one Claude Code session.

Build for the Boom: Why AI Agent Startups Should Build Scalable Infrastructure Early
Explore strategies for developing AI agents that can handle rapid growth. Don't let inadequate systems undermine your success during critical breakthrough moments.

AI Integration in Video Surveillance Tools: Transforming the Industry with Vector Databases
Discover how AI and vector databases are revolutionizing video surveillance with real-time analysis, faster threat detection, and intelligent search capabilities for enhanced security.