




Chat Towards Data Science: Einen Chatbot mit Zilliz Cloud erstellen
Dieser Artikel ist der erste Teil der Blogserie Chat Towards Data Science.
Im Zeitalter der Generativen KI nutzen Entwickler große Sprachmodelle (LLMs) für intelligentere Anwendungen. LLMs neigen jedoch aufgrund ihres begrenzten Wissens zu Halluzinationen. Retrieval Augmented Generation (RAG) adressiert dieses Problem effektiv, indem LLMs mit externem Wissen ergänzt werden. In meiner Blogserie Chat Towards Data Science führe ich Sie durch den Aufbau eines RAG-basierten Chatbots, der Ihren Datensatz als Wissensgrundlage nutzt.
Im ersten Teil meiner Blogserie führen wir Sie durch die Erstellung eines Chatbots für die Website Towards Data Science und nutzen dabei Web Scraping, um eine Wissensbasis zu erstellen, die in Zilliz Cloud gespeichert wird, einem vollständig verwalteten Vektordatenbankdienst, der auf Milvus basiert.
Webdaten mit BeautifulSoup4 scrapen
Der erste Schritt in jedem Machine-Learning-(ML-)Projekt besteht darin, die erforderlichen Daten zu sammeln. Für dieses Projekt verwenden wir Web-Scraping-Techniken, um Daten für unsere Wissensbasis zu sammeln. Wir nutzen die Bibliothek requests, um Webseiten abzurufen, und verwenden anschließend BeautifulSoup4 (eine Bibliothek, die Informationen aus Webseiten extrahiert), um die HTML-Informationen zu parsen und die Absätze zu extrahieren.
BeautifulSoup4 und Requests für Web Scraping vorbereiten
Installieren Sie zunächst BeautifulSoup, indem Sie pip install beautifulsoup4 sentence-transformers ausführen. Für diesen Abschnitt benötigen wir nur zwei Imports: requests und BeautifulSoup. Als Nächstes erstellen wir ein Dictionary mit URLs, die wir scrapen möchten. In diesem Beispiel scrapen wir nur Inhalte von Towards Data Science, aber Sie können auch andere Websites scrapen. Wir rufen Daten von jeder Archivseite mit dem im folgenden Code gezeigten Format ab.
import requests
from bs4 import BeautifulSoup
urls = {
'Towards Data Science': 'https://towardsdatascience.com/archive/{0}/{1:02d}/{2:02d}',
}
Wir benötigen außerdem zwei Hilfsfunktionen für unser Web Scraping. Die erste Funktion konvertiert die Anzahl der Tage des Jahres in ein Monats- und Tagesformat. Die zweite ruft die Anzahl der Claps (Claps zeigen Unterstützung für einen Medium-Artikel) aus einem Artikel ab.
Die Funktion zur Tageskonvertierung ist relativ einfach. Wir codieren die Anzahl der Tage jedes Monats fest und verwenden diese Liste, um die Konvertierung durchzuführen. Da dieses Web-Scraping-Projekt ausdrücklich auf das Jahr 2023 abzielt, müssen wir Schaltjahre nicht berücksichtigen. Sie können die Funktion gern für andere Jahre anpassen, wenn Sie möchten.
Die Clap-Zählfunktion stellt die Claps für einen Medium-Artikel dar. Einige Artikel können Tausende von Claps erhalten, was Medium mit dem Buchstaben "K" kennzeichnet. Daher müssen wir diese Darstellung in unserer Funktion berücksichtigen.
# takes the number day of the year and returns month, day
def convert_day(day):
month_days = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
m = 0
d = 0
while day > 0:
d = day
day -= month_days[m]
m += 1
return (m, d)
# converts the claps string
def get_claps(claps_str):
if (claps_str is None) or (claps_str == '') or (claps_str.split is None):
return 0
split = claps_str.split('K')
claps = float(split[0])
claps = int(claps*1000) if len(split) == 2 else int(claps)
return claps
Die Web-Scraping-Antwort von BeautifulSoup4 parsen
Nachdem wir nun die notwendigen Komponenten eingerichtet haben, können wir mit dem Web Scraping fortfahren. In diesem Abschnitt importieren wir eine zusätzliche Bibliothek namens "time.” Ich habe diese Bibliothek hinzugefügt, weil während des Prozesses 429-Fehler (zu viele Anfragen) auftraten. Mit der time-Bibliothek können wir eine Verzögerung zwischen dem Senden von Anfragen einführen. Zusätzlich nutzen wir die Bibliothek sentence transformers, um unser Embedding-Modell, konkret ein MiniLM-Modell, von Hugging Face zu erhalten.
Wie bereits erwähnt, scrapen wir nur Daten für 2023, daher setzen wir das Jahr auf 2023. Außerdem benötigen wir nur Daten von Tag 1 (1. Januar) bis Tag 243 (30. August). Zum Zeitpunkt des Scrapings war es Anfang September. Rückblickend wäre es besser gewesen, bis Tag 244 zu scrapen, aber wir fahren vorerst mit dem fort, was ich bereits gemacht habe. Im ersten Teil unserer Funktion, bis zum ersten time.sleep()-Aufruf, richten wir die notwendigen Komponenten ein. Wir konvertieren den Iterator in einen Monat und einen Tag, wandeln dies in einen Datumsstring um und rufen anschließend die HTML-Antwort von der Archiv-URL ab.
Nachdem wir das HTML erhalten haben, parsen wir es mit BeautifulSoup und suchen nach div-Elementen mit einem bestimmten Klassennamen (im Code angegeben), der darauf hinweist, dass es sich um einen Artikel handelt. Von dort aus parsen wir den Titel, Untertitel, die Artikel-URL, die Anzahl der Claps, die Lesezeit und die Anzahl der Antworten. Anschließend verwenden wir erneut requests, um den Artikel über die Artikel-URL abzurufen.
Wir rufen time.sleep() ein zweites Mal auf, um den zweiten Abschnitt dieser for-Schleife abzuschließen. Zu diesem Zeitpunkt haben wir den Großteil der für jeden Artikel erforderlichen Metadaten erhalten. Wir extrahieren jeden Absatz und das zugehörige Embedding mithilfe unseres Hugging-Face-Modells. Anschließend erstellen wir ein Dictionary, das alle Metadaten für diesen spezifischen Absatz und Artikel enthält.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2")
import time
# data_batch = []
year = 2023
for i in range(1, 243):
month, day = convert_day(i)
date = '{0}-{1:02d}-{2:02d}'.format(year, month, day)
for publication, url in urls.items():
response = requests.get(url.format(year, month, day), allow_redirects=True)
if not response.url.startswith(url.format(year, month, day)):
continue
time.sleep(8)
page = response.content
soup = BeautifulSoup(page, 'html.parser')
articles = soup.find_all(
"div",
class_="postArticle postArticle--short js-postArticle js-trackPostPresentation js-trackPostScrolls")
for article in articles:
title = article.find("h3", class_="graf--title")
# print(title.contents)
if title is None:
continue
title = str(title.contents[0]).replace(u'\xA0', u' ').replace(u'\u200a', u' ')
# title = title.contents[0]
subtitle = article.find("h4", class_="graf--subtitle")
subtitle = str(subtitle.contents[0]).replace(u'\xA0', u' ').replace(u'\u200a', u' ') if subtitle is not None else ''
article_url = article.find_all("a")[3]['href'].split('?')[0]
try:
claps = get_claps(article.find_all("button")[1].contents[0])
except:
claps = 0
reading_time = article.find("span", class_="readingTime")
reading_time = 0 if reading_time is None else int(reading_time['title'].split(' ')[0])
responses = article.find_all("a")
if len(responses) == 7:
responses = responses[6].contents[0].split(' ')
if len(responses) == 0:
responses = 0
else:
responses = responses[0]
else:
responses = 0
article_res = requests.get(article_url)
time.sleep(8)
soup = bs4.BeautifulSoup(article_res.text)
paragraphs = soup.select('[class*="pw-post-body-paragraph"]')
for i, paragraph in enumerate(paragraphs):
embedding = model.encode(paragraph.text)
data_batch.append({
"_id": f"{article_url}+{i}",
"article_url": article_url,
"title": title,
"subtitle": subtitle,
"claps": claps,
"responses": responses,
"reading_time": reading_time,
"publication": publication,
"date": date,
"paragraph": paragraph.text,
"embedding": embedding
})
Der letzte Schritt besteht darin, unsere Datei zu picklen.
import pickle
filename="TDS_8_30_2023"
with open(f'{filename}.pkl', 'wb') as f:
pickle.dump(data_batch, f)
Wie sehen unsere Daten aus?
Es ist immer hilfreich, die Daten zu visualisieren. Unten sehen Sie, wie die Daten in Zilliz Cloud aussehen. Achten Sie auf die Embeddings, die den Vektor darstellen. Wir erzeugen diese Vektor-Embeddings aus dem Text im folgenden Abschnitt.
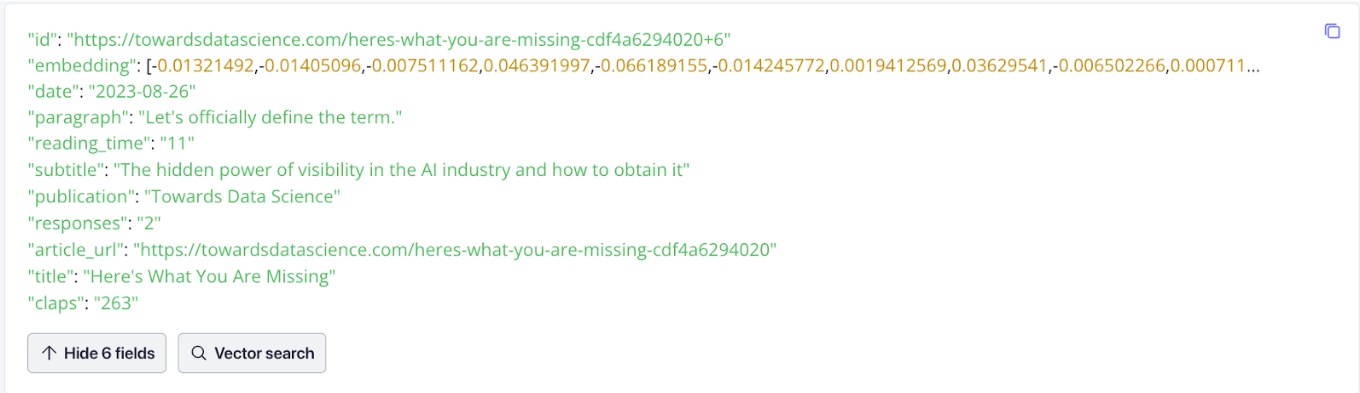
Daten aus TDS in Ihre Vektordatenbank aufnehmen
Sobald wir die Daten haben, besteht der nächste Schritt darin, sie an eine Vektordatenbank weiterzuleiten. In diesem Projekt habe ich ein separates Notebook verwendet, um die Daten in Zilliz Cloud, einen vollständig verwalteten Vektordatenbankdienst auf Basis von Milvus, aufzunehmen, anstatt sie von Towards Data Science zu scrapen.
Um unsere Daten in Zilliz Cloud einzufügen, befolgen wir diese Schritte:
Verbindung zu Zilliz Cloud herstellen.
Die Parameter für unsere Collection definieren.
Die Daten in Zilliz Cloud einfügen.
Einrichten des Jupyter Notebooks
Führen Sie den Befehl pip install pymilvus python-dotenv aus, um unser Jupyter Notebook einzurichten und den Datenaufnahmeprozess zu starten. Ich verwende wie üblich die Bibliothek dotenv, um meine Umgebungsvariablen zu verwalten. Für das Paket pymilvus müssen wir die folgenden Module importieren:
utility- zum Prüfen des Status Ihrer Collectionsconnections- um eine Verbindung zu Ihrer Milvus-Instanz herzustellenFieldSchema- um das Schema eines Felds zu definierenCollectionSchema- um das Schema einer Collection zu definierenDataType- Datentypen, die in einem Feld gespeichert sindCollection- die Art und Weise, wie wir auf eine Collection zugreifen
Dann öffnen wir die Daten, die wir zuvor gepickelt haben, rufen unsere Umgebungsvariablen ab und stellen eine Verbindung zu Zilliz Cloud her.
import pickle
import os
from dotenv import load_dotenv
from pymilvus import utility, connections, FieldSchema, CollectionSchema, DataType, Collection
filename="TDS_8_30_2023"
with open(f'{filename}.pkl', 'rb') as f:
data_batch = pickle.load(f)
load_dotenv()
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
connections.connect(
uri= zilliz_uri,
token= zilliz_token
)
Einrichten Ihrer Zilliz-Vektordatenbank und Datenaufnahme
Jetzt müssen wir Zilliz Cloud einrichten. Wir müssen eine Collection erstellen, um die Daten zu speichern und zu organisieren, die wir von der TDS-Website scrapen. Zwei Konstanten sind erforderlich: Dimension und Collection-Name. Die Dimension bezieht sich auf die Anzahl der Dimensionen, die unser Vektor hat. In diesem Fall verwenden wir das MiniLM-Modell mit 384 Dimensionen. Der Collection-Name ist selbsterklärend.
Mit Milvus' neuer Funktion dynamisches Schema können wir einfach das ID- und Embedding-Feld für eine Collection definieren, ohne uns um die Anzahl der anderen gespeicherten Felder oder deren erforderlichen Datentyp kümmern zu müssen. Es ist jedoch wichtig, sich die spezifischen Namen der Felder zu merken, die wir verwendet haben, um sie korrekt abzurufen.
Für dieses Projektbeispiel verwenden wir die Funktion für dynamische Schemas, um nur die ID- und Embedding-Felder zu definieren. Anschließend weisen wir diese Felder einem Schema und das Schema einer Collection zu. Als Nächstes geben wir die Parameter für den Index an. In diesem Fall verwenden wir einen invertierten Dateiindex (IVF) ohne Quantisierung (FLAT), eine euklidische Distanz (L2) und 128 Zentroide für den Index.
IVF ohne Quantisierung ist die intuitivste Indexierungsmethode. Im Wesentlichen clustern wir die Vektoren in 128 Abschnitte für die Abfrage. 128 ist in diesem Fall eine willkürliche Zahl. Es ist ein Hyperparameter, den wir je nachdem, wie unsere Ergebnisse aussehen, abstimmen können. Heuristisch gesehen ist es ein guter Ausgangspunkt, da er sowohl eine gute Vielfalt an Clustern bieten als auch die anfängliche Komplexität der Abfrage reduzieren kann. Sobald wir diese Parameter definiert haben, erstellen wir den Index auf dem Embedding-Feld und laden die Collection in den Arbeitsspeicher.
DIMENSION=384
COLLECTION_NAME="tds_articles"
fields = [
FieldSchema(name='id', dtype=DataType.VARCHAR, max_length=200, is_primary=True),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields, enable_dynamic_field=True)
collection = Collection(name=COLLECTION_NAME, schema=schema)
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()
Sobald wir die Collection definiert und in den Arbeitsspeicher geladen haben, haben wir zwei Optionen zum Einfügen der Daten:
Die Datenbatch durchlaufen und jedes Element einzeln einfügen
Die Daten in Batches einfügen
Nachdem wir alle Daten eingefügt haben, ist es wichtig, die Collection zu flushen, um sie zu indexieren und Konsistenz sicherzustellen. Das Ingestieren großer Datenmengen kann einige Zeit dauern.
for data in data_batch:
collection.insert([data])
collection.flush()
TDS-Artikelsegmente abfragen
Jetzt ist alles eingerichtet und bereit für Abfragen. In diesem Beitrag halten wir diesen Teil einfach, indem wir unsere Abfrage vektorisieren und in Zilliz Cloud nach der nächstliegenden Übereinstimmung suchen. In meinen folgenden Beiträgen werden wir auch LlamaIndex und LangChain verwenden.
Dein HuggingFace-Modell erhalten und für Abfragen an Zilliz einrichten
Du musst das Embedding-Modell beschaffen und die Vektordatenbank einrichten, um unsere Towards Data Science-Wissensbasis abzufragen. Dieser Schritt erfordert das Ausführen eines separaten Notebooks. Ich werde die dotenv-Bibliothek verwenden, um Umgebungsvariablen zu verwalten. Zusätzlich müssen wir das MiniLM-Modell von Sentence Transformers verwenden. Für diesen Schritt kannst du den im Abschnitt Web Scraping bereitgestellten Code wiederverwenden.
import os
from dotenv import load_dotenv
from pymilvus import connections, Collection
load_dotenv()
zilliz_uri = os.getenv("ZILLIZ_URI")
zilliz_token = os.getenv("ZILLIZ_TOKEN")
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-MiniLM-L12-v2")
Eine Vektorsuchabfrage ausführen
Jetzt musst du eine Verbindung zu deiner Vektordatenbank herstellen und eine Suche durchführen. In diesem Projekt verbinden wir uns mit einer Zilliz Cloud-Instanz und rufen die Collection ab, die wir zuvor erstellt haben, tds_articles. Um unsere Abfrage zu erhalten, fordern wir den Benutzer auf, seine Frage zu TDS bis einschließlich September 2023 einzugeben.
Als Nächstes verwenden wir das Embedding-Modell von Hugging Face, um die Abfrage zu kodieren. Dieser Prozess wandelt die Frage des Benutzers in eine 384-dimensionale Vektordarstellung um. Anschließend verwenden wir diese kodierte Abfrage, um die Vektordatenbank zu durchsuchen. Während der Suche müssen wir das Feld für approximative nächste Nachbarn (anns_field), Indexparameter, das gewünschte Limit für die Anzahl der Suchergebnisse und die gewünschten Ausgabefelder angeben.
Zuvor haben wir Milvus' Dynamic-Schema-Funktion genutzt, um die Definition des Feldschemas zu vereinfachen. Jetzt, da wir die Vektordatenbank durchsuchen, ist es wichtig, die gewünschten dynamischen Felder in die Suchergebnisse aufzunehmen. Dieses spezifische Szenario umfasst die Anforderung des Felds paragraph, das den Text aus jedem Absatz der Artikel enthält.
connections.connect(uri=zilliz_uri, token=zilliz_token)
collection = Collection(name="tds_articles")
query = input("What would you like to ask Towards Data Science's 2023 publications up to September? ")
embedding = model.encode(query)
closest = collection.search([embedding],
anns_field='embedding',
param={"metric_type": "L2",
"params": {"nprobe": 16}},
limit=2,
output_fields=["paragraph"])
print(closest[0][0])
print(closest[0][1])
Ich bat die App, Informationen über große Sprachmodelle bereitzustellen, und sie gab die folgenden zwei Antworten zurück. Obwohl diese Antworten „Sprachmodelle“ erwähnen und einige verwandte Informationen enthalten, liefern sie keine detaillierte Erklärung großer Sprachmodelle. Die zweite Antwort ist semantisch ähnlich, muss aber ausreichend nah an dem sein, was wir angefragt haben.

Erweiterung einer Wissensbasis in einer Vektordatenbank
Bisher haben wir mit Zilliz als unserer Vektordatenbank eine Wissensbasis zu TDS-Artikeln erstellt. Obwohl wir problemlos semantisch ähnliche Suchergebnisse abrufen konnten, sind sie nur manchmal das, was wir brauchen. Der nächste Schritt besteht darin, unsere Ergebnisse durch die Einbindung neuer Frameworks und Technologien zu verbessern.
Im kommenden Abschnitt werden wir die Ergänzung von LlamaIndex untersuchen, um unsere Ergebnisse zu routen, ähnlich dem Routing, das wir in meinem vorherigen Blog über Abfragen mehrerer Dokumente mit LlamaIndex, LangChain und Milvus durchgeführt haben.
Zusammenfassung
Dieses Tutorial behandelt den Aufbau eines Chatbots für die Publikation Towards Data Science. Wir veranschaulichen den Web-Scraping-Prozess, um eine Wissensbasis in einer Vektordatenbank (genauer gesagt Zilliz Cloud) zu erstellen und zu speichern. Anschließend zeigen wir, wie man den Benutzer zu einer Abfrage auffordert, die Abfrage vektorisiert und die Vektordatenbank abfragt.
Wir haben jedoch festgestellt, dass die Ergebnisse zwar semantisch ähnlich sind, aber nicht genau dem entsprechen, was wir uns wünschen. Im nächsten Teil dieser Blogserie werden wir untersuchen, wie LlamaIndex zum Routen von Abfragen verwendet werden kann, und sehen, ob wir bessere Ergebnisse erzielen können. Neben den hier besprochenen Schritten können Sie auch mit Zilliz Cloud experimentieren, indem Sie das Modell ersetzen, Texte kombinieren oder einen anderen Datensatz verwenden!
Um die gesamte Chat-Towards-Data-Science-Reihe erneut zu lesen, finden Sie hier die Links:

Weiterlesen

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.

Vector Databases vs. Key-Value Databases
Use a vector database for AI-powered similarity search; use a key-value database for high-throughput, low-latency simple data lookups.