




Aufbau von RAG mit Milvus, vLLM und Llama 3.1
Die University of California - Berkeley hat vLLM, eine schnelle und benutzerfreundliche Bibliothek für LLM-Inferenz und -Dienstleistungen, der LF AI & Data Foundation als Projekt in der Inkubationsphase im Juli 2024 gespendet. Wir heißen vLLM als Mitgliedsprojekt in der LF AI & Data Familie herzlich willkommen! 🎉
Große Sprachmodelle (LLMs) und Vektordatenbanken werden in der Regel kombiniert, um Retrieval Augmented Generation (RAG) zu erstellen, eine beliebte KI-Anwendungsarchitektur, um KI-Halluzinationen anzugehen. Dieser Blog wird Ihnen zeigen, wie Sie eine RAG mit Milvus, vLLM und Llama 3.1 erstellen und ausführen können. Genauer gesagt zeige ich Ihnen, wie man Textinformationen als Vektoreinbettungen in Milvus einbettet und speichert und diesen Vektorspeicher als Wissensbasis verwendet, um Textabschnitte, die für Benutzerfragen relevant sind, effizient abzurufen. Schließlich werden wir vLLM nutzen, um Metas Llama 3.1-8B Modell zu verwenden, um Antworten zu generieren, die durch den abgerufenen Text ergänzt werden. Legen wir los!
Einführung in Milvus, vLLM und Metas Llama 3.1
Milvus Vektor-Datenbank
Milvus ist eine Open-Source, speziell entwickelte, verteilte Vektordatenbank zur Speicherung, Indizierung und Suche von Vektoren für Generative AI (GenAI) Workloads. Seine Fähigkeit, hybride Suche Metadatenfilterung und Reranking durchzuführen und Billionen von Vektoren effizient zu verarbeiten, macht Milvus zur ersten Wahl für KI und maschinelles Lernen. Milvus kann lokal, in einem Cluster oder in der vollständig verwalteten Zilliz Cloud betrieben werden.
vLLM
vLLM ist ein Open-Source-Projekt, das am UC Berkeley SkyLab gestartet wurde und sich auf die Optimierung der LLM-Serving-Leistung konzentriert. Es verwendet eine effiziente Speicherverwaltung mit PagedAttention, kontinuierliche Stapelverarbeitung und optimierte CUDA-Kernel. Im Vergleich zu herkömmlichen Methoden verbessert vLLM die Serving-Leistung um das bis zu 24-fache und halbiert gleichzeitig die GPU-Speichernutzung.
Laut dem Papier "Efficient Memory Management for Large Language Model Serving with PagedAttention" belegt der KV-Cache etwa 30 % des GPU-Speichers, was zu potenziellen Speicherproblemen führt. Der KV-Cache wird in einem zusammenhängenden Speicher gespeichert, aber eine Änderung der Größe kann zu einer Fragmentierung des Speichers führen, was für Berechnungen ineffizient ist.

Abbildung 1. KV-Cache-Speicherverwaltung in bestehenden Systemen (2023 Paged Attention paper)
Durch die Verwendung von virtuellem Speicher für den KV-Cache weist vLLM nur bei Bedarf physischen GPU-Speicher zu, wodurch eine Speicherfragmentierung vermieden und eine Vorabzuweisung vermieden wird. In Tests übertraf vLLM HuggingFace Transformers (HF) und Text Generation Inference (TGI) und erreichte einen bis zu 24-mal höheren Durchsatz als HF und 3,5-mal höher als TGI auf NVIDIA A10G und A100 Grafikprozessoren.
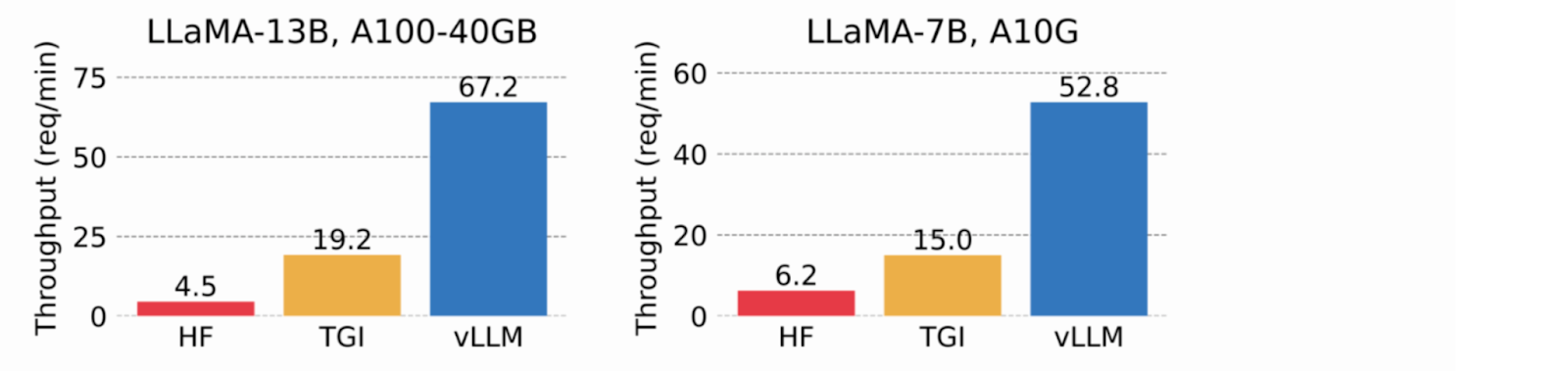
Abbildung 2. Serving-Durchsatz, wenn jede Anforderung drei parallele Ausgabeabschlüsse erfordert. vLLM erreicht einen 8,5- bis 15-mal höheren Durchsatz als HF und einen 3,3- bis 3,5-mal höheren Durchsatz als TGI (2023_ vLLM blog_).
Meta's Llama 3.1
Meta's Llama 3.1 wurde am 23. Juli 2024 angekündigt. Das 405B-Modell ist bei mehreren öffentlichen Benchmarks auf dem neuesten Stand der Technik und verfügt über ein Kontextfenster von 128.000 Eingabe-Token, für das verschiedene kommerzielle Anwendungen zulässig sind. Neben dem 405-Milliarden-Parameter-Modell hat Meta auch eine aktualisierte Version von Llama3 70B (70 Milliarden Parameter) und 8B (8 Milliarden Parameter) veröffentlicht. Die Modellgewichte können [auf der Website von Meta] heruntergeladen werden (https://info.deeplearning.ai/e3t/Ctc/LX+113/cJhC404/VWbMJv2vnLfjW3Rh6L96gqS5YW7MhRLh5j9tjNN8BHR5W3qgyTW6N1vHY6lZ3l8N8htfRfqP8DzW72mhHB6vwYd2W77hFt886l4_PV22X226RPmZbW67mSH08gVp9MW2jcZvf24w97BW207Jmf8gPH0yW20YPQv261xxjW8nc6VW3jj-nNW6XdRhg5HhZk_W1QS0yL9dJZb0W818zFK1w62kdW8y-_4m1gfjfNW2jswrd3xbv-yW5mrvdk3n-KqyW45sLMF21qDrwW5TR3vr2MYxZ9W2hWhq23q-nQdW4blHqh3JlZWfW937hlZ58-KJCW82Pgv9384MbYW7yp56M6pvzd6f77wnH004).
Eine wichtige Erkenntnis war, dass eine Feinabstimmung der generierten Daten die Leistung steigern kann, Beispiele von schlechter Qualität sie jedoch verschlechtern können. Das Llama-Team arbeitete intensiv daran, diese schlechten Beispiele mit Hilfe des Modells selbst, von Hilfsmodellen und anderen Tools zu identifizieren und zu entfernen.
Aufbau und Durchführung des RAG-Retrievals mit Milvus
Bereiten Sie Ihren Datensatz vor
Ich habe die offizielle [Milvus-Dokumentation] (https://milvus.io/docs/) als Datensatz für diese Demo verwendet, den ich heruntergeladen und lokal gespeichert habe.
from langchain.document_loaders import DirectoryLoader
# Lädt HTML-Dateien, die bereits in einem lokalen Verzeichnis gespeichert sind
path = "../../RAG/rtdocs_new/"
global_pattern = '*.html'
loader = DirectoryLoader(path=pfad, glob=global_pattern)
docs = loader.load()
# Druckt die Anzahl der Dokumente und eine Vorschau.
print(f "geladene {len(docs)} Dokumente")
print(docs[0].page_content)
pprint.pprint(dokumente[0].metadaten)
 loaded 22 docs
loaded 22 docs
Download eines Einbettungsmodells
Als nächstes laden Sie ein kostenloses, quelloffenes Einbettungsmodell von HuggingFace herunter.
torch importieren
from sentence_transformers import SentenceTransformer
# Torch-Einstellungen für geräteunabhängigen Code initialisieren.
N_GPU = torch.cuda.device_count()
DEVICE = torch.device('cuda:N_GPU' if torch.cuda.is_available() else 'cpu')
# Laden Sie das Modell vom Huggingface Model Hub herunter.
model_name = "BAAI/bge-large-de-v1.5"
encoder = SentenceTransformer(model_name, device=DEVICE)
# Holt die Modellparameter und speichert sie für später.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Überprüfen Sie die Modellparameter.
print(f "model_name: {model_name}")
print(f "EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH}")

Chunk und kodieren Sie Ihre eigenen Daten als Vektoren.
Ich werde eine feste Länge von 512 Zeichen mit 10% Überlappung verwenden.
from langchain.text_splitter import RecursiveCharacterTextSplitter
CHUNK_SIZE = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f "chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# Definieren Sie den Splitter.
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=chunk_overlap)
# Chunk die Dokumente.
chunks = child_splitter.split_documents(docs)
print(f"{len(docs)} docs split into {len(chunks)} child documents.")
# Encoder-Eingabe ist doc.page_content als Strings.
list_of_strings = [doc.page_content for doc in chunks if hasattr(doc, 'page_content')]
# Einbettungsinferenz unter Verwendung des HuggingFace-Encoders.
embeddings = torch.tensor(encoder.encode(list_of_strings))
# Normalisieren Sie die Einbettungen.
Einbettungen = np.array(Einbettungen / np.linalg.norm(Einbettungen))
# Milvus erwartet eine Liste von `numpy.ndarray` von `numpy.float32` Zahlen.
umgewandelte_Werte = list(map(np.float32, Einbettungen))
# dict_list für Milvus-Einfügung erstellen.
dict_list = []
for chunk, vector in zip(chunks, converted_values):
# Einbettungsvektor, ursprünglicher Textchunk, Metadaten zusammenfügen.
chunk_dict = {
'chunk': chunk.page_content,
'Quelle': chunk.metadata.get('Quelle', ""),
'vector': vector,
}
dict_list.append(chunk_dict)

Speichern Sie die Vektoren in Milvus
Aufnahme der kodierten Vektoreinbettung in die Milvus-Vektordatenbank.
# Verbinden Sie einen Client mit dem Milvus Lite Server.
von pymilvus import MilvusClient
mc = MilvusClient("milvus_demo.db")
# Erstellen Sie eine Sammlung mit flexiblem Schema und AUTOINDEX.
COLLECTION_NAME = "MilvusDocs"
mc.create_collection(COLLECTION_NAME,
EMBEDDING_DIM,
consistency_level="Eventually",
auto_id=True,
overwrite=True)
# Daten in die Milvus-Sammlung einfügen.
print("Start inserting entities")
start_time = time.time()
mc.insert(
COLLECTION_NAME,
data=dict_list,
progress_bar=True)
end_time = time.time()
print(f "Milvus Einfügezeit für {len(dict_list)} Vektoren: ", end="")
print(f"{rund(end_time - start_time, 2)} Sekunden")

Durchführen einer Vektorsuche
Stellen Sie eine Frage und suchen Sie nach den nächstgelegenen Chunks aus Ihrer Wissensbasis in Milvus.
SAMPLE_QUESTION = "Was bedeuten die Parameter für HNSW?"
# Einbetten der Frage unter Verwendung des gleichen Encoders.
query_embeddings = torch.tensor(encoder.encode(SAMPLE_QUESTION))
# Normalisieren der Einbettungen auf Einheitslänge.
abfrage_einbettungen = F.normalize(abfrage_einbettungen, p=2, dim=1)
# Konvertieren der Einbettungen in eine Liste von np.float32-Listen.
abfrage_einbettungen = list(map(np.float32, abfrage_einbettungen))
# Definieren Sie Metadatenfelder, nach denen Sie filtern können.
OUTPUT_FIELDS = list(dict_list[0].keys())
OUTPUT_FIELDS.remove('vector')
# Definieren Sie, wie viele Top-k-Ergebnisse Sie abrufen möchten.
TOP_K = 2
# Führen Sie die semantische Vektorsuche unter Verwendung Ihrer Abfrage und der Vektordatenbank durch.
results = mc.search(
COLLECTION_NAME,
data=query_embeddings,
output_fields=OUTPUT_FIELDS,
limit=TOP_K,
consistency_level="Eventuell")
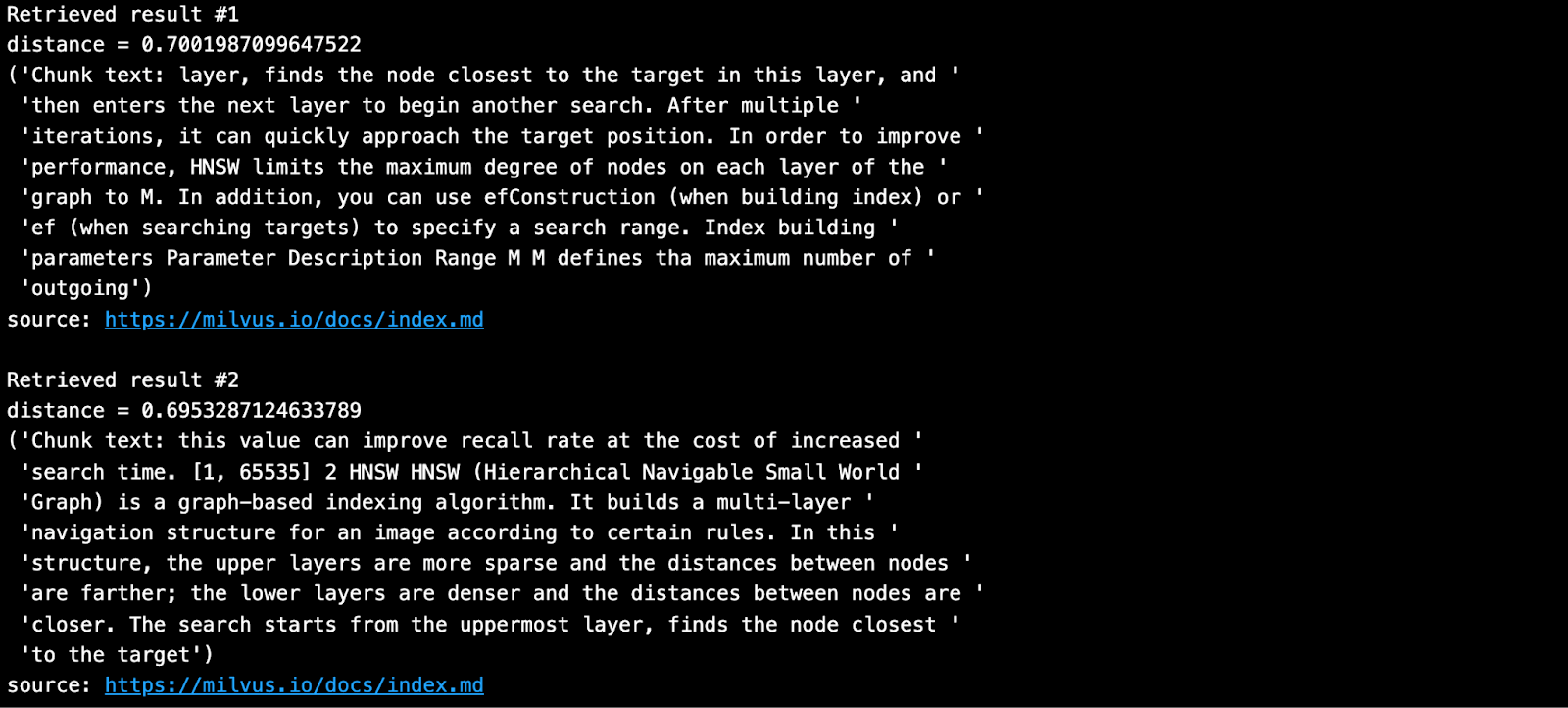
Das abgerufenen Ergebnis ist wie unten dargestellt.
Erstellen und Durchführen der RAG-Generierung mit vLLM und Llama 3.1-8B
Installieren Sie vLLM und die Modelle von HuggingFace
vLLM lädt standardmäßig große Sprachmodelle von HuggingFace herunter. Wenn Sie ein neues Modell von HuggingFace verwenden wollen, sollten Sie ein pip install--update oder -U durchführen. Außerdem benötigen Sie eine GPU, um die Inferenz von Metas Llama 3.1-Modellen mit vLLM durchzuführen.
Eine vollständige Liste aller vLLM-unterstützten Modelle finden Sie auf dieser [Dokumentationsseite] (https://docs.vllm.ai/en/latest/models/supported_models.html#supported-models).
# (Empfohlen) Erstellen Sie eine neue conda-Umgebung.
conda create -n myenv python=3.11 -y
conda activate myenv
# Installieren Sie vLLM mit CUDA 12.1.
pip install -U vllm transformers torch
importiere vllm, torch
von vllm importieren LLM, SamplingParams
# Leeren Sie den GPU-Speicher-Cache.
torch.cuda.empty_cache()
# Überprüfen Sie die GPU.
!nvidia-smi
Um mehr über die Installation von vLLM zu erfahren, lesen Sie die Seite installation.
Ein HuggingFace-Token erhalten
Einige Modelle auf HuggingFace, wie z.B. Meta Llama 3.1, erfordern, dass der Benutzer ihre Lizenz akzeptiert, bevor er die Gewichte herunterladen kann. Daher müssen Sie ein HuggingFace-Konto erstellen, die Lizenz des Modells akzeptieren und ein Token generieren.
Wenn du diese Llama3.1-Seite auf HuggingFace besuchst, wirst du aufgefordert, den Bedingungen zuzustimmen. Klicken Sie auf "Lizenz akzeptieren", um die Meta-Bedingungen zu akzeptieren, bevor Sie die Modellgewichte herunterladen. Die Genehmigung dauert in der Regel weniger als einen Tag.
Nachdem Sie die Genehmigung erhalten haben, müssen Sie ein neues HuggingFace-Token erstellen. Ihre alten Token werden mit den neuen Berechtigungen nicht mehr funktionieren.
Melden Sie sich vor der Installation von vLLM mit Ihrem neuen Token bei HuggingFace an. Im Folgenden habe ich Colab-Geheimnisse verwendet, um das Token zu speichern.
# Melde dich bei HuggingFace mit deinem neuen Token an.
from huggingface_hub import login
from google.colab import userdata
hf_token = userdata.get('HF_TOKEN')
login(token = hf_token, add_to_git_credential=True)
Die RAG-Generierung ausführen
In der Demo führen wir das Modell "Llama-3.1-8B" aus, das einen Grafikprozessor und einen großen Arbeitsspeicher zum Hochfahren benötigt. Das folgende Beispiel wurde auf Google Colab Pro ($10/Monat) mit einer A100 GPU ausgeführt. Weitere Informationen über die Ausführung von vLLM finden Sie in der [Quickstart-Dokumentation] (https://docs.vllm.ai/en/latest/getting_started/quickstart.html).
# 1. Wählen Sie ein Modell
MODELTORUN = "meta-llama/Meta-Llama-3.1-8B-Instruct"
# 2. Leeren Sie den GPU-Speicher-Cache, Sie werden ihn ganz brauchen!
torch.cuda.empty_cache()
# 3. Instanziieren Sie eine vLLM-Modellinstanz.
llm = LLM(model=MODELTORUN,
enforce_eager=True,
dtype=torch.bfloat16,
gpu_memory_utilization=0.5,
max_model_len=1000,
seed=415,
max_num_batched_tokens=3000)

Schreiben Sie einen Prompt unter Verwendung von Kontexten und Quellen, die Sie von Milvus erhalten haben.
# Trenne alle Kontexte durch ein Leerzeichen.
kontexte_kombiniert = ' '.join(kontexte)
# Lance Martin, LangChain, sagt, dass die besten Kontexte am Ende stehen sollen.
kontexte_zusammen = ' '.join(reversed(kontexte))
# Trennen Sie alle eindeutigen Quellen durch ein Komma.
source_combined = ' '.join(reversed(list(dict.fromkeys(sources))))
SYSTEM_PROMPT = f"""Prüfen Sie zunächst, ob der angegebene Kontext für die Frage des Benutzers relevant ist.
Frage des Benutzers relevant ist. Zweitens, nur wenn der angegebene Kontext sehr relevant ist, beantworte die Frage unter Verwendung des Kontextes. Andernfalls, wenn der Kontext nicht sehr relevant ist, beantworten Sie die Frage ohne Verwendung des Kontextes.
Seien Sie klar, prägnant und relevant. Antworten Sie klar und deutlich in weniger als 2 Sätzen.
Grundlegende Quellen: {Quelle_kombiniert}
Kontext: {Kontexte_kombiniert}
Frage des Benutzers: {BEISPIEL_FRAGE}
"""
prompts = [SYSTEM_PROMPT]
Erzeugen Sie nun eine Antwort unter Verwendung der abgerufenen Chunks und der ursprünglichen Frage, die in die Eingabeaufforderung eingefügt wurde.
# Stichprobenparameter
sampling_params = SamplingParams(Temperatur=0.2, top_p=0.95)
# Rufen Sie das vLLM-Modell auf.
outputs = llm.generate(Eingabeaufforderungen, sampling_params)
# Druckt die Ausgaben.
for output in outputs:
prompt = output.prompt
generierter_text = ausgabe.ausgaben[0].text
# !r ruft repr() auf, das eine Zeichenkette in Anführungszeichen ausgibt.
print()
print(f "Frage: {SAMPLE_QUESTION!r}")
pprint.pprint(f "Erstellter Text: {erstellter_text!r}")

Die obige Antwort sieht für mich perfekt aus!
Wenn Sie an dieser Demo interessiert sind, können Sie sie gerne selbst ausprobieren und uns Ihre Meinung mitteilen. Sie können auch gerne unserer Milvus-Community auf Discord beitreten, um sich direkt mit den GenAI-Entwicklern zu unterhalten.
Referenzen
vLLM offizielle Dokumentation und Modellseite.
2023 vLLM-Präsentation auf dem Ray Summit
vLLM-Blog: vLLM: Einfaches, schnelles und günstiges LLM Serving mit PagedAttention
Hilfreicher Blog über den Betrieb des vLLM-Servers: Bereitstellung von vLLM: eine schrittweise Anleitung
Die Llama 3 Herde von Modellen | Forschung - AI bei Meta](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/)

Weiterlesen

The AWS Outage Was a Wake-Up Call for Vector Database Cross-Region Disaster Recovery
Zilliz Cloud Had the Answer Before the Crisis. Zilliz Cloud is the world's first vector database with native cross-region disaster recovery.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.