




Zilliz Cloud: Entfacht Vektorsuche mit raketenartiger Geschwindigkeit
Wir haben kürzlich die neueste Version von Zilliz Cloud veröffentlicht und dabei eine Reihe spannender Funktionen eingeführt, darunter ein neues kostenloses Kontingent, dynamische Schemas und Partitionsschlüssel sowie erschwinglichere Preispläne, um unterschiedlichen Geschäftsanforderungen gerecht zu werden. Außerdem haben wir die Leistung deutlich verbessert, wodurch Zilliz Cloud doppelt so schnell ist wie die vorherige Version und drei- bis zehnmal schneller als Milvus und andere Vektordatenbanken.
Als Softwareentwickler bin ich besonders begeistert von der raketenartigen Geschwindigkeit, mit der Zilliz Cloud Abfragen verarbeitet. In diesem Beitrag werde ich zeigen, wie schnell Zilliz Cloud ist und was Zilliz blitzschnell macht.
Wie schnell ist Zilliz Cloud?
Bevor wir die Geschwindigkeit von Zilliz Cloud demonstrieren, müssen wir den Kontext unseres Vergleichs und die spezifischen Bedingungen festlegen, die wir bewerten.
VectorDBBench ist ein Open-Source-Benchmarking-Tool, das die Leistung verschiedener Vektordatenbanken anhand mehrerer Metriken wie QPS, Kapazität, Durchsatz und Latenz über eine intuitive und benutzerfreundliche Oberfläche bewertet.
Ich werde VectorDBBench verwenden, um Zilliz Cloud mit Milvus, einer von Zilliz entwickelten Open-Source-Datenbank, und anderen Vektordatenbanken auf dem Markt zu vergleichen, darunter Quadrant Cloud, Pinecone, WeaviateCloud und ElasticCloud.
Zilliz Cloud übertrifft Milvus problemlos um das 6-Fache
Die folgende Abbildung vergleicht die Leistung von Zilliz Cloud und Milvus hinsichtlich QPS bei der Verarbeitung von einer Million 768-dimensionalen Daten mit unterschiedlichen Konfigurationen von Rechen- und Speicherressourcen. Den Ergebnissen zufolge ist Zilliz Cloud mindestens dreimal schneller als Milvus.
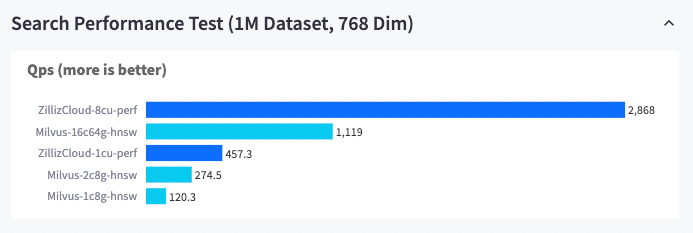 Zilliz Cloud vs. Milvus (1M-Datensatz, 768 Dim)
Zilliz Cloud vs. Milvus (1M-Datensatz, 768 Dim)
Beim Abrufen von 10 Millionen 768-dimensionalen Daten übertrifft Zilliz Cloud Milvus um das Sechsfache.
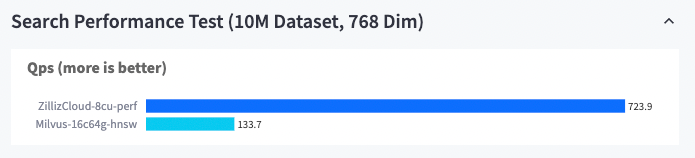 Zilliz Cloud vs. Milvus (10M-Datensatz, 768 Dim)
Zilliz Cloud vs. Milvus (10M-Datensatz, 768 Dim)
Zilliz Cloud ist mindestens 4x schneller als andere Vektordatenbanken
Zilliz Cloud ist auch schneller als andere Vektordatenbanken. Den Benchmarking-Ergebnissen zufolge erreicht Zilliz Cloud beim Abrufen von einer Million 768-dimensionalen Daten eine 4- bis 191-mal höhere QPS als Wettbewerber und bietet deutlich erschwinglichere Preispläne.
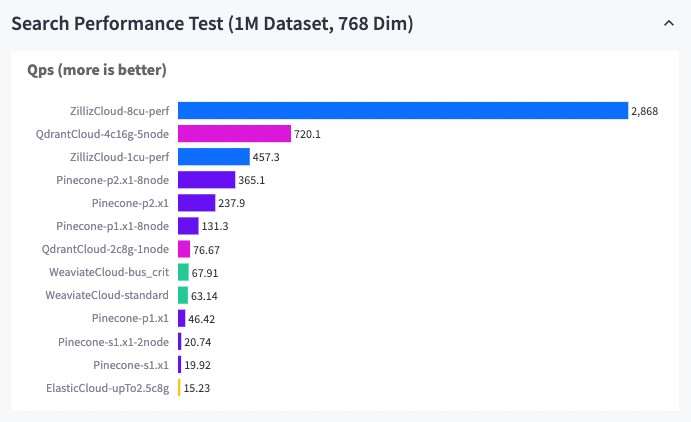 Zilliz Cloud vs. andere Vektordatenbanken (1M-Datensatz, 768 Dim)
Zilliz Cloud vs. andere Vektordatenbanken (1M-Datensatz, 768 Dim)
Bei der Durchführung von Ähnlichkeitssuchen auf größeren Datensätzen übertrifft Zilliz Cloud Vektordatenbankdienste wie Pinecone und Quadrant Cloud hinsichtlich QPS um das 3-Fache.
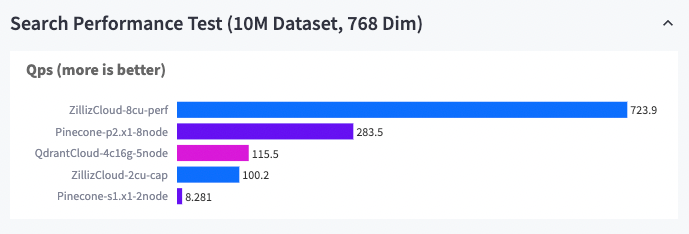 Zilliz Cloud vs. andere Vektordatenbanken (10M-Datensatz, 768 Dim)
Zilliz Cloud vs. andere Vektordatenbanken (10M-Datensatz, 768 Dim)
Weitere Ergebnisse finden Sie auf unserer Benchmarking-Seite.
Warum Zilliz Cloud so schnell ist
Jetzt haben Sie von der Geschwindigkeit von Zilliz Cloud gelesen; nun ist es an der Zeit aufzudecken, was es so schnell macht.
Zilliz Cloud verfügt über eine robuste Vektorindexierungs-Engine
Vektordatenbanken sind stark auf Rechenleistung angewiesen, wobei ihre Vektorindexierungsalgorithmen die meisten Ressourcen verbrauchen und die Leistung hauptsächlich bestimmen.
Zilliz Cloud verfügt über eine robuste Indexierungs-Engine mit leistungsstarken Vektor-Computing-Fähigkeiten. Glass ist die Open-Source-Version und belegte in den jüngsten Testergebnissen des ANN-Benchmark Spitzenplätze. Dieses bekannte Benchmarking-Tool vergleicht die Leistung verschiedener Algorithmen auf unterschiedlichen realen Datensätzen.
Werfen wir einen Blick auf zwei Beispiele. Die folgenden Diagramme zeigen die neuesten Benchmarking-Ergebnisse von ANN-Benchmark auf Basis von zwei verschiedenen Datensätzen:
gist-960-euclidean: eine Million 960-dimensionale Vektoren unter Verwendung der euklidischen Distanzfunktion.fashion-mnist-784-euclidean: 60.000 784-dimensionale Vektoren unter Verwendung der euklidischen Distanzfunktion.
Je höher die Kurve reicht, desto mehr Abfragen können die Algorithmen pro Sekunde verarbeiten. Ebenso gilt: Je weiter sich die Kurve nach rechts erstreckt, desto höhere Recall-Werte können die Algorithmen erzielen.
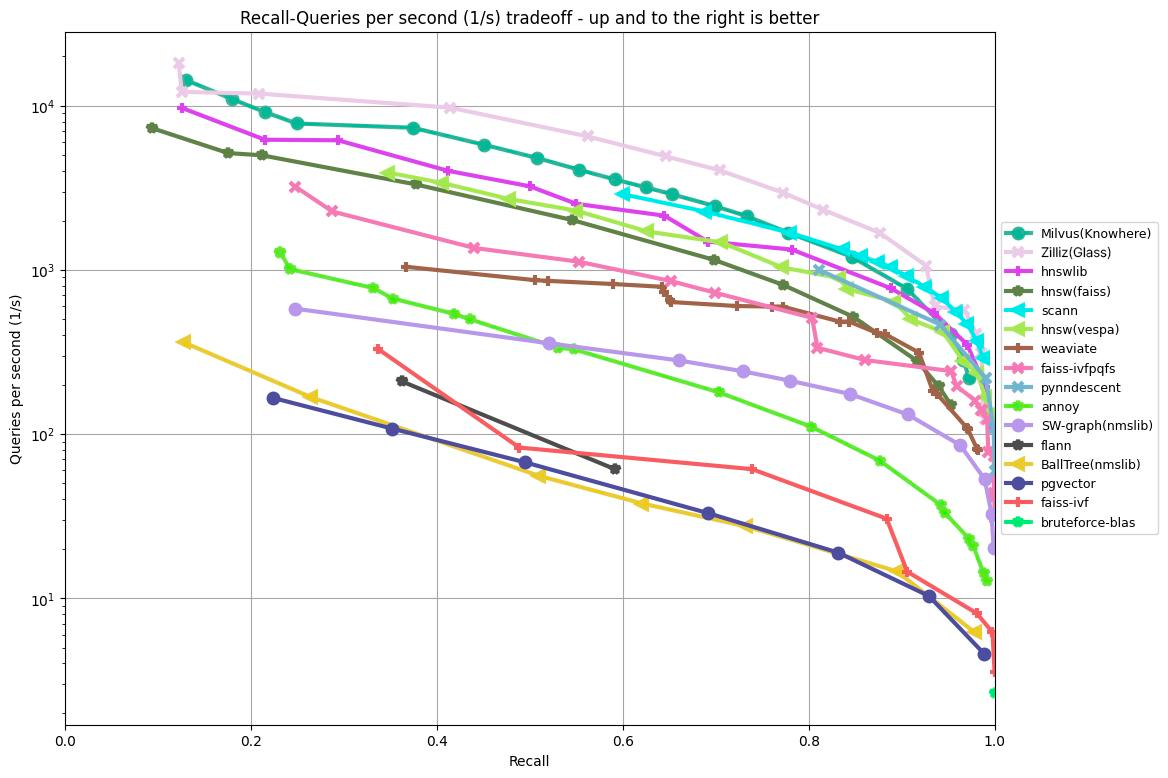 ANN Benchmark-Ergebnisse (Datensatz: gist-960-euclidean, k=10)
ANN Benchmark-Ergebnisse (Datensatz: gist-960-euclidean, k=10)
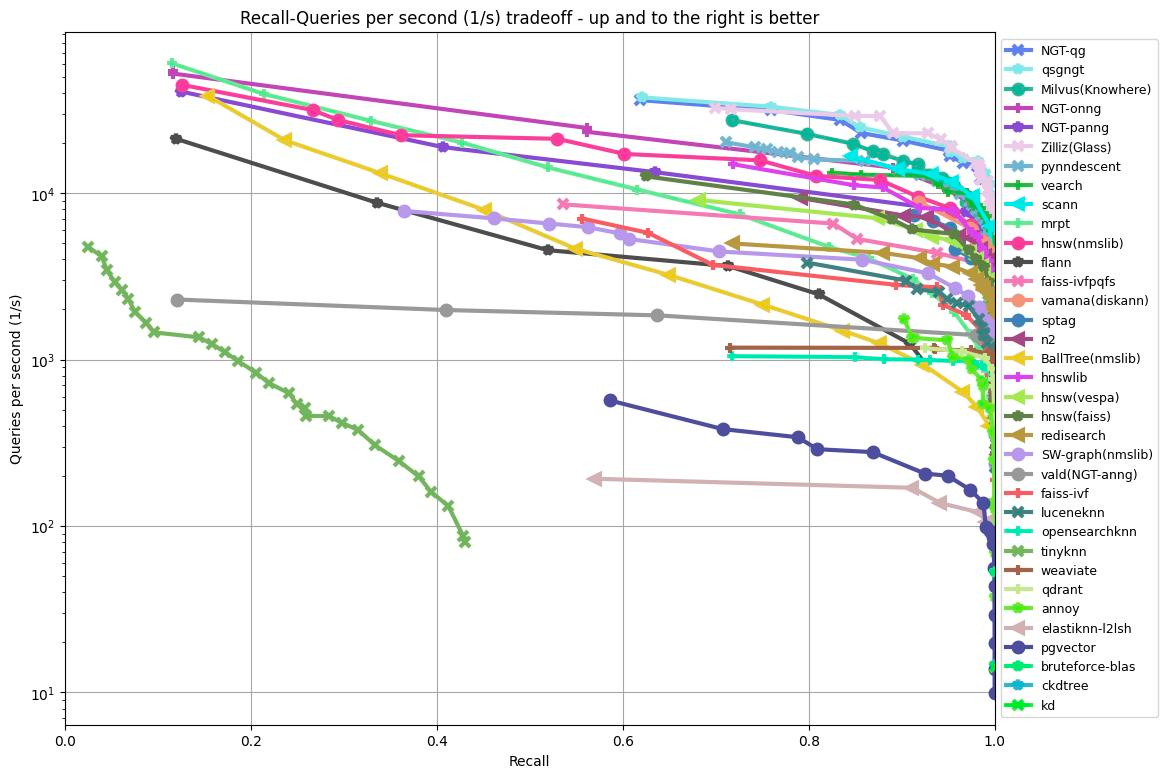 ANN Benchmark-Ergebnisse (Datensatz: gist-960-euclidean, k=10)
ANN Benchmark-Ergebnisse (Datensatz: gist-960-euclidean, k=10)
Basierend auf den in den Diagrammen gezeigten Ergebnissen rangierte Glass (die pinke Kurve) sowohl bei den Abfragen pro Sekunde als auch beim Recall als Spitzenreiter. Die außergewöhnliche Leistung von Glass hat erheblich dazu beigetragen, dass Zilliz Cloud blitzschnelle Geschwindigkeiten erreichen kann.
Optimierte Codestruktur
Zusätzlich zu Glasss robuster Indexierungsfähigkeit haben wir die Codestruktur von Zilliz Cloud optimiert. Diese Optimierung umfasst das Bereinigen redundanter Abfragepfade, die Verbesserung der Planung von Abfragezusammenführungen und Regeln für gleichzeitige Abfragen, die Optimierung der Load-Balancing-Struktur sowie das Ersetzen/Aktualisieren vieler ineffizienter und veralteter Drittanbieterbibliotheken. All diese Maßnahmen helfen Zilliz Cloud, die Fähigkeiten seiner Indexalgorithmen zu maximieren und Overhead zu reduzieren.
Wir haben außerdem mehrere Probleme behoben, die zuvor die Abfrageleistung von Zilliz Cloud beeinträchtigt haben. Infolgedessen sind skalar-gefilterte und vektor-gefilterte Suchen mit groß angelegten Datensätzen jetzt deutlich schneller.
AutoIndex von Zilliz Cloud für stabile Recall-Raten
Die Recall-Rate ist ein entscheidender Faktor für die Systemleistung. Eine unzureichende Recall-Rate führt zu Abrufresultaten, die die Anforderungen unserer Kunden nicht erfüllen. Eine übermäßig hohe Recall-Rate kann jedoch die Leistung erheblich beeinträchtigen. Daher benötigen wir eine stabile Recall-Rate, die Leistung und Genauigkeit ausbalanciert, vorhersagbare Ergebnisse sicherstellt und verschiedene Produktionsszenarien besser unterstützt.
Die Kontrolle der Recall-Rate ist essenziell, aber auch kompliziert, da die Recall-Rate von verschiedenen Faktoren beeinflusst werden kann, darunter Datengröße, Indexierungs- und Abfrageparameter, Datenverteilung und sogar die Größe der topk-Ergebnisse. Die meisten Datenbanksysteme verwenden eine der folgenden zwei Lösungen, um dieses Problem zu lösen:
- Benutzern erlauben, Parameter bereitzustellen: flexibel, aber schwierig einzuführen.
- Empirische Parameter bereitstellen: einfach zu verwenden, aber weniger flexibel und nicht in der Lage, Situationen mit unterschiedlichen Datensätzen und topk-Anforderungen präzise zu steuern.
Zilliz Cloud bietet eine einfachere und flexiblere Lösung namens AutoIndex. Sie analysiert praktische Anwendungsfälle auf Basis von Modellen und passt Parameter für jede Indexierungsanfrage an. Dieser Ansatz gewährleistet eine stabile Recall-Rate und liefert gleichzeitig hervorragende Leistung, um die Anforderungen der Benutzer in praktischen Anwendungen zu erfüllen.
Zusammenfassung
Das neueste Update von Zilliz Cloud hat Meilenstein-Verbesserungen bei Funktionalität und Leistung gebracht. Es bietet nun raketenartige Geschwindigkeit bei der Verarbeitung massiver Vektorsuchen und übertrifft andere Vektordatenbanken deutlich.
Erste Schritte mit Zilliz Cloud
- Kostenlos starten mit dem neuen Starter Plan! Ein großartiger Plan für den Einstieg ohne Installationsaufwand und ohne Kreditkarte!
- Oder starten Sie Ihre 30-tägige kostenlose Testversion des Standard-Plans mit Guthaben im Wert von $100 bei der Registrierung und der Möglichkeit, insgesamt Guthaben im Wert von bis zu $200 zu verdienen.
- Tauchen Sie tiefer in die Dokumentation von Zilliz Cloud ein.
- Sehen Sie sich den Leitfaden zur Migration von Milvus zu Zilliz Cloud an.

Weiterlesen

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.