




A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
After this year’s Databricks Data + AI Summit, I found myself thinking less about any single announcement and more about a question that has been sitting with me for a while:
When AI really moves into production, what does the data layer become?
My current answer is simple, though the implications are not: in this cycle, the data layer is the part of the AI stack that has been repriced the slowest. That is starting to change.
Data: the part of the AI stack the market has not priced yet
Algorithms have been repriced in public. Models improve quickly, and the industry can see the progress almost every week. Compute has been repriced by NVIDIA, the cloud providers, and the capital markets. Everyone understands that GPUs matter.
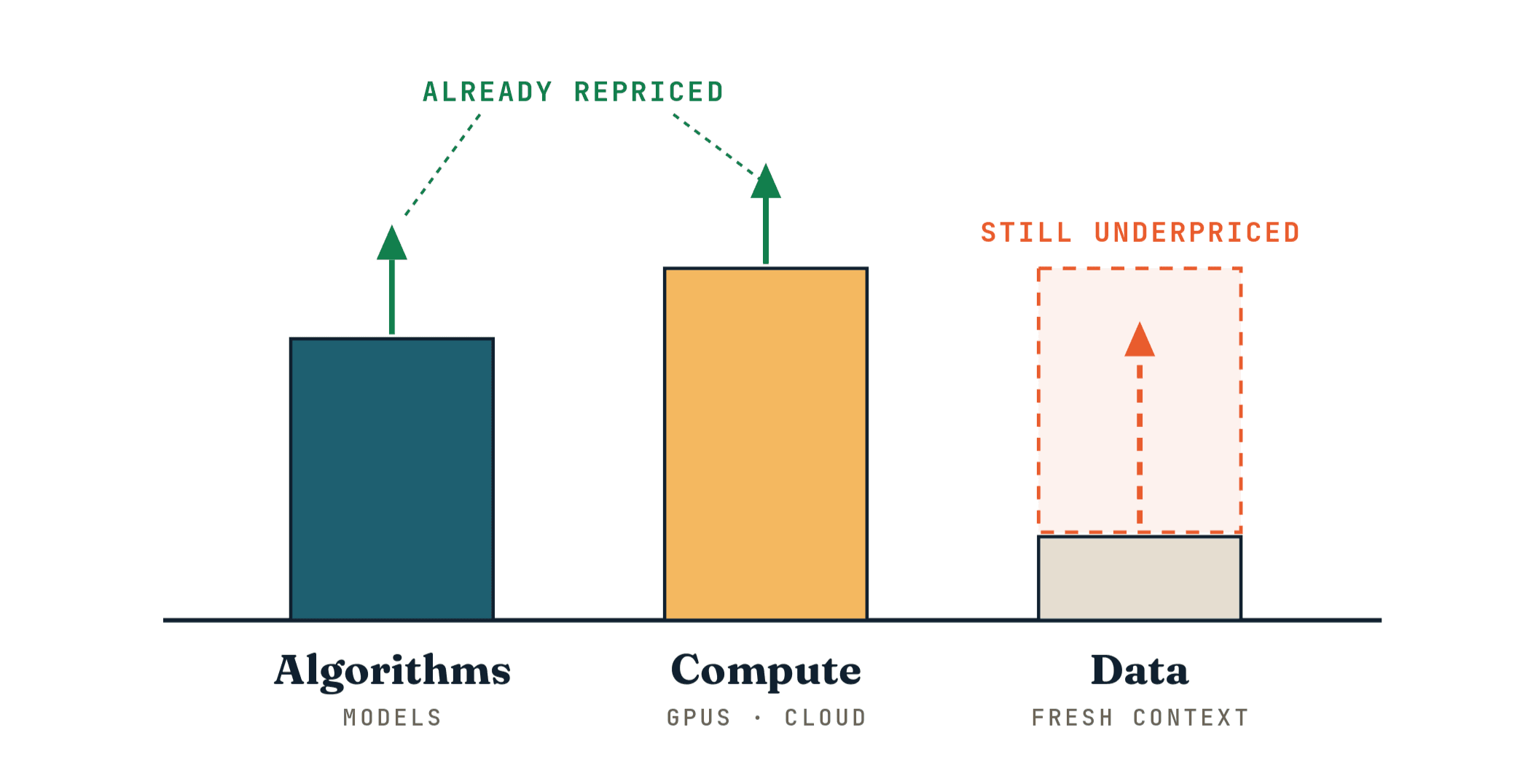
Data has moved more slowly. Not because it matters less. The opposite is true. Data is slow to reprice because it is hard to talk about and even harder to fix. Enterprise data is messy, scattered, duplicated, stale, and full of permissions that nobody fully understands. Business semantics do not line up cleanly across systems. The thing people call “real time” is often still a scheduled job that ran sometime last night.
That work is painful. It is also not very glamorous. But once AI moves from demos into production, the pain becomes impossible to hide.
In conversations with people building and training models, including those at OpenAI and Anthropic, the discussion often comes back to the same point. Models are converging. Compute can be bought, at least if you have enough money. The defensible layer is increasingly becoming the data: the quality of it, the freshness of it, the permissions around it, and the speed at which it can be turned into useful context.
This is not only an application-layer problem. Inside model companies, model quality still depends heavily on the data pipeline. A training run may require days of preparation before the first serious experiment begins. If an upstream field is dirty, a batch is mislabeled, or a filtering rule is wrong, days of compute and waiting can disappear before anyone notices the loss curve has drifted.
AI agents make the data problem impossible to hide
Agents expose the same problem in a more operational form.
When AI agents fail in production, the first cause is often not that the model is incapable. It is that the model is acting on the wrong context: a record it cannot access, a document that expired six hours ago, a data source that quietly changed overnight, or a retrieval path that is too expensive to use often enough. I recently saw a strong team lose nearly a week to a stale context pipeline. The agent was confidently answering yesterday’s question. The model was not dumb. The context was wrong, and the system had no clean way to prove where the error entered the loop.
That is the failure mode that matters. The next infrastructure bottleneck is not simply better reasoning. It is fresh, trusted, cheap, and auditable context at the moment a model or agent makes a decision.
That is why I think the data layer is the next part of the AI stack to be repriced.
Databricks is aiming at the right problem
I am skeptical of many products that call themselves “AI data platforms.” Too often the story arrives before the system.
Databricks is different enough that I think it deserves serious attention. Two things stood out to me at the Summit.
The first is still the engineering culture. At Databricks’ scale, it would be easy for the company to become purely sales-driven. Yet the founders are still on stage talking about execution engines, transactions, real-time analytics, and the pipes underneath the product. I respect that. You can feel when a company still has product and engineering intuition at its core. It shows up in small architectural decisions long before it shows up in a keynote.
The second is the customer base. The users I spoke with at the Summit were not talking about AI as a demo layer. They were trying to push AI into production systems, and the problems they described were much more concrete: agents need to read and write business state; real-time analytics cannot keep paying the tax of moving data; pipelines need to become more autonomous; agent behavior needs governance at runtime, not only after the fact.
That is why announcements such as Lakebase, Lakehouse//RT, data agents, and AI governance matter. The names are less important than the direction. Put transactions closer to the lake. Pull real-time analytics back toward the same data foundation. Automate more of the pipeline. Extend governance from “who can see this dataset” to “what is this agent allowed to do in this specific step?”
I do not see that as a wrong turn. I see it as evidence that many of us are looking at the same future from different angles.
The database is expanding. It is no longer only a place to store and query data. It is becoming the foundation for facts, state, semantics, governance, and action.
The map is good. But it is not finished.
Databricks is right in the direction. That does not mean the architecture has reached its final form.
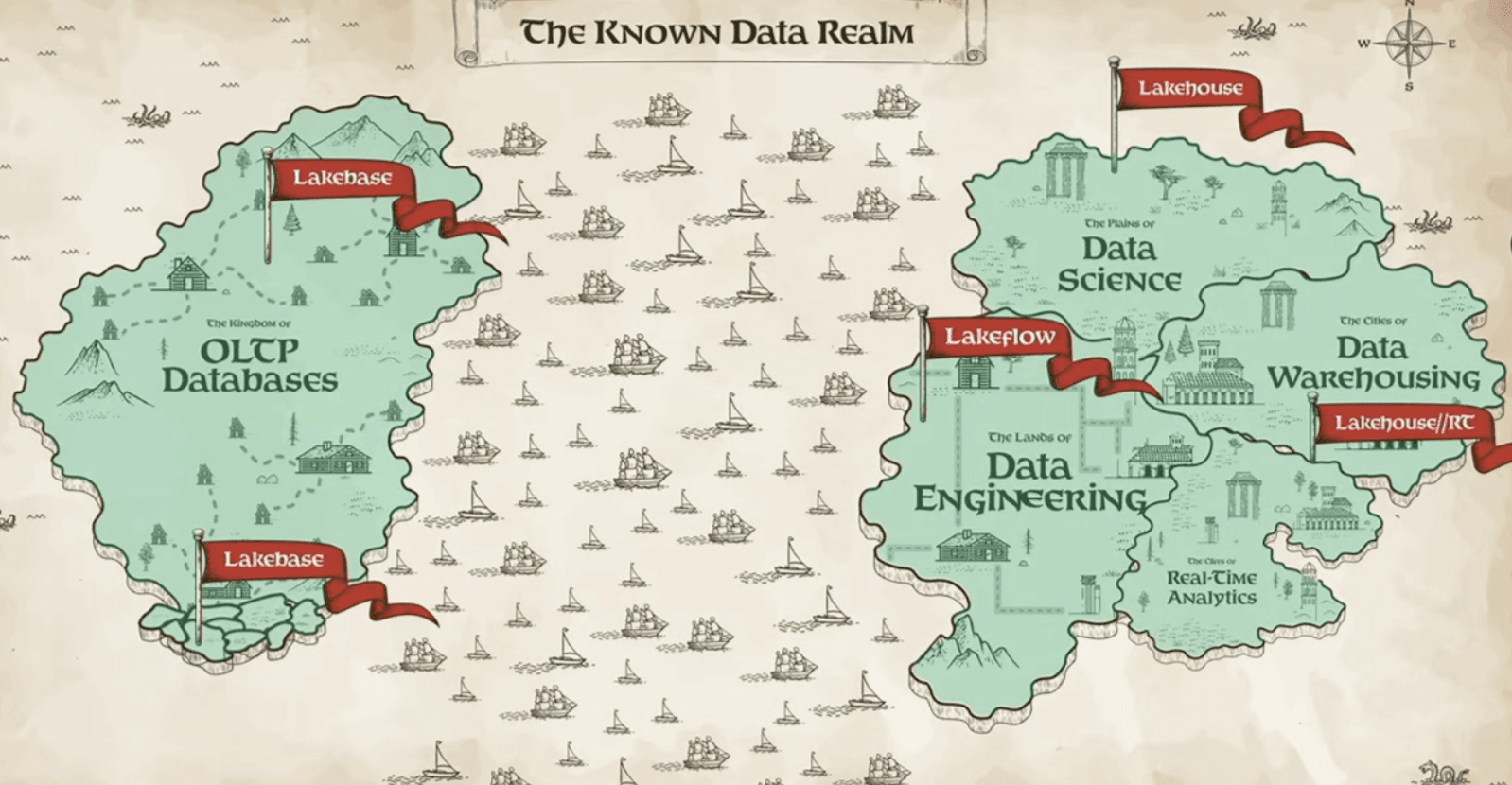
Photo: The Known Data Realm · Databricks Data + AI Summit 2026
I see three areas where the map is still incomplete.
The lakebase itself.
Starting with Postgres is a smart entry point. Developers know it. The ecosystem is huge. Compatibility lowers adoption friction. That matters.
But the architecture that gets people in the door is not always the architecture that wins the final workload.
AI-era operational systems need transactions, memory, vectors, multimodal data, trace, branching, rollback, and very fine-grained tenant isolation. A traditional relational core can expose some of these through extensions and surrounding services, but that does not make them native. Classic Postgres was not designed for cloud-native distributed scale, nor for agents that create short-lived databases, fork state, write to memory, generate traces, and disappear.
Moving Postgres closer to object storage does not erase those questions. Object storage is cheap and reliable, but it is not low-latency by default. To make it feel fast, you need a cache layer that is both aggressive and correct. A cache that stays stable under real transactional load is one of the hardest systems problems in databases. So my honest question about Lakebase is not whether the demo is impressive. It is whether the system can carry real OLTP workloads at production scale without turning that cache into the thing that wakes people up at 3 a.m.
The multimodal data.
Databricks has drawn a strong map across OLTP, warehousing, real-time analytics, data science, and governance. But AI applications increasingly consume text, images, audio, video, embeddings, behavior logs, and agent traces. Those are not just objects sitting next to tables. They are the data that agents retrieve, reason over, transform, and write back.
If multimodal data remains outside the core map, then the most important AI data assets still live in the margins.
The default user.
Much of the product surface still assumes a human user: dashboards, natural-language BI, Excel-style workflows, and analyst-facing experiences. Those are valuable. But agents use databases differently.
An agent does not open a dashboard once a day. It runs in a loop. It retrieves context, makes a decision, calls a tool, writes state, checks a policy, and repeats. Every step may need to be audited. Every retrieval may influence the next action. Every write may need rollback. Every permission check may need to happen at runtime.
That is a different database workload.
Photo: Unity AI Gateway · Governance —— Databricks Data + AI Summit 2026
When the database user is an agent
For decades, a database could mostly focus on one question: how to execute this query correctly and quickly.
In the agent era, the question becomes broader:
How does an agent get the freshest, most trusted, lowest-cost, and most auditable context at the moment it makes a decision?
That is not just a query optimization problem. It is a systems problem across storage, indexing, governance, lineage, replay, cost control, and runtime policy enforcement.
This is where the category starts to shift. A data system can no longer be only an intelligence system: you ask a question, it returns an answer. It has to become closer to an operating system for AI: the place where agents read context, make decisions, call tools, write state, and leave behind a trace that humans and other systems can inspect.
Auditability cannot be bolted on after the fact. If an agent gives the wrong answer, takes the wrong action, or spends too much money, the first question will be: what exactly did it see at that moment?
To answer that, the system needs to know which documents were retrieved, which vectors were matched, which metadata filters were applied, which reranker changed the order, which tool was called, what policy was enforced, and what state was written back. Debugging and governance become the same workflow.
That is the architecture I do not think anyone has fully solved yet.
What “AI-native” should actually mean
“AI-native” is becoming one of those phrases that can mean almost anything. I do not think there is a clean definition yet. But if we work backward from real agent workloads, an AI-native data system has to do at least a few things well.
Multimodal data has to be first-class
Text, images, audio, video, embeddings, logs, and traces should not be scattered across a relational table, a vector column, an object bucket, and several side indexes. They need to live in one logical system where retrieval, filtering, ranking, and governance can happen together.
The hard part is not storing these assets. The hard part is making them queryable together without turning the architecture into another pipeline problem.
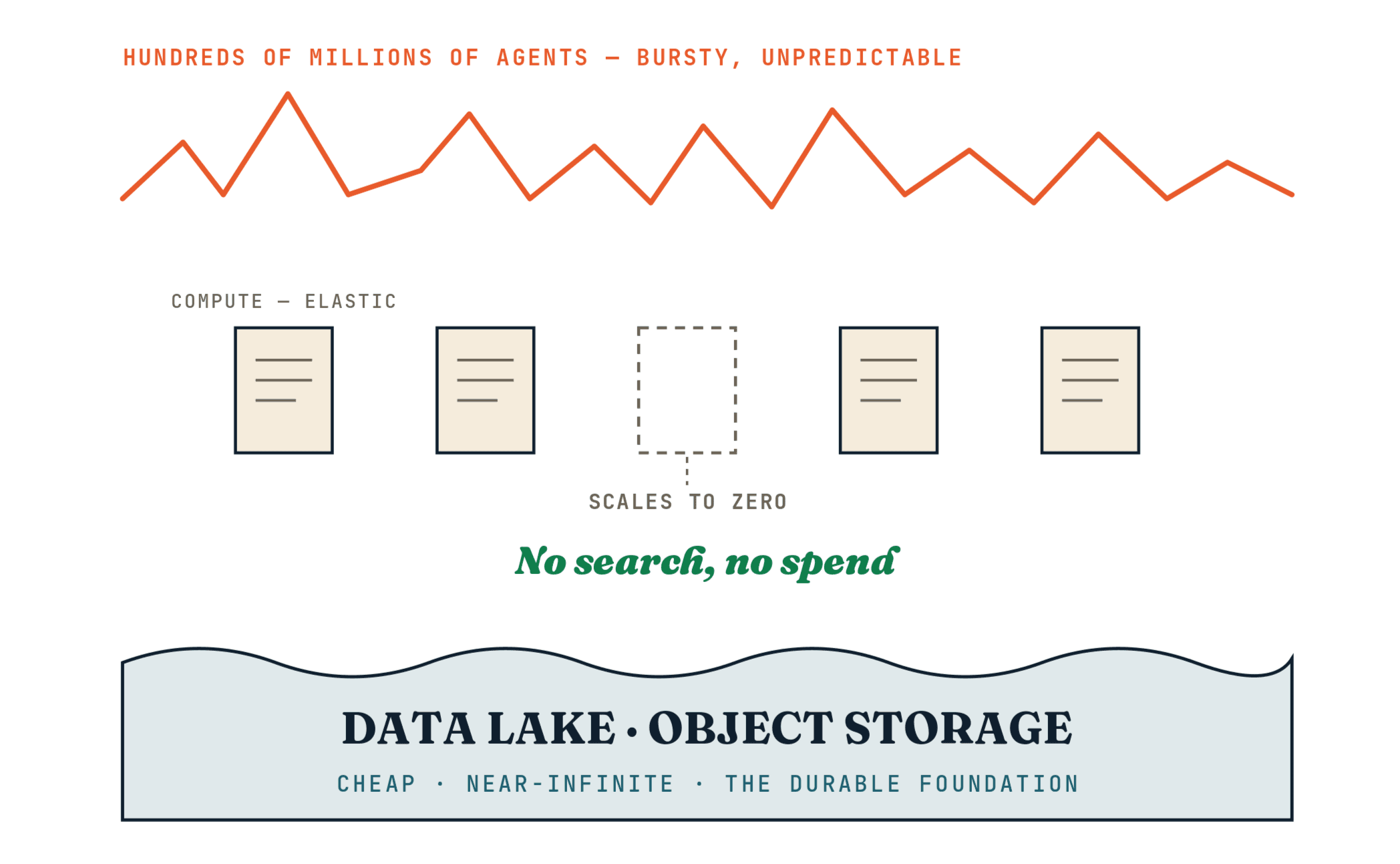
Elasticity has to start from the workload
Agent traffic is bursty. A system may be quiet for an hour and then receive a flood of retrieval, memory, and tool-use requests. The data lake or object store should become the durable foundation: cheap, reliable, and decoupled from compute.
But compute should not remain expensive just because the corpus exists. If nobody is searching, the system should spend very little. If a workload wakes up, compute should arrive quickly. In that world, the natural pricing unit is not always a permanent cluster. It may be the query, the session, or the minute of active compute.
Multi-tenancy has to move to the agent level
Traditional multi-tenant systems often assume a manageable number of large tenants. Agentic systems may create millions or billions of tiny, short-lived, isolated states. Each agent may carry its own memory, permissions, traces, temporary branches, and write paths.
A design built for thousands of large tenants will struggle when the tenant becomes the agent run itself.
Branching and rollback become core database features
Agents will write the wrong thing. That is not a corner case. It is part of the workload.
A useful AI data layer needs Git-like branching and fast rollback for data state. An agent run should be able to fork a working branch, test an action, write temporary state, and discard or promote it. If a bad update lands, the system should be able to return to a known good point quickly.
Versioning is not only an analytics convenience anymore. It becomes an operational safety mechanism.
Trace and deterministic replay are mandatory
When an agent fails, the question is not just “what was the final answer?” It is “what did the agent see, retrieve, rank, decide, call, and write?”
That requires a trace of every meaningful step. More importantly, it requires replay. The system should be able to reconstruct the decision context as it existed at the time, not as it looks after a document has changed or an index has been rebuilt.
For agents, auditability and debuggability collapse into the same requirement.
Permissions have to govern actions, not only rows
Traditional authorization asks who can read a table, a column, or a row. Agentic systems need a more dynamic question: what is this agent allowed to retrieve, call, modify, disclose, and spend in this specific step?
The hard part moves from the read path to the action path. Policy enforcement has to happen while the agent is running, not only when a human opens a dashboard.
Operations have to become self-driving
Agent-level scale breaks human-operated infrastructure. No team can manually manage indexes, compaction, cache warming, tenant placement, recovery, and resource scheduling across millions of small, fast-moving workloads.
The system has to operate itself. Otherwise, the architecture may work in a diagram but fail in the only place that matters: production.
SQL is not enough as the final interface
There is one more issue that I think about more and more: the interface itself.
SQL was the right interface for the analyst era. It is still essential. But for companies built around databases and analytics, SQL can also become a form of path dependence. The product surface, the user model, and even the organization often assume that the primary user is someone who knows how to write a query.
The final interface for AI-era data will not be a slightly better SQL editor. It also will not be a chatbot pasted in front of the database.
The more interesting endpoint is a headless, natural-language-native data system: one where a person or an agent can state the intent directly and the system can answer, act, or prepare the right execution plan without exposing every internal step as a query-writing exercise.
But this has to be native to the database, not a separate agent standing in front of it.
If natural language is only an application layer, the system reintroduces the very seams it is trying to remove: one more translation step, one more stale context window, one more governance gap. The database itself needs to understand the question, the data, the policies, and the execution path.
That is much harder than building a friendly interface. It means the database has to own semantics.
The moat that still matters
I do not have a perfectly clean conclusion. Maybe that is appropriate. The market is moving too quickly, and too many old assumptions are being drained faster than expected.
A proprietary query dialect is not the moat it used to be. Migration cost is weaker when agents can rewrite integration code. A familiar UI matters less when the next user may not be human. Even the quiet advantage of simply owning the data is weaker when open table formats, natural-language interfaces, and tool-using agents make movement easier.
The moat I still believe in is less glamorous: the ability to create real user value over a long period of time, patiently and repeatedly.
That is why I came away from the Summit taking Databricks seriously. I think Databricks has a real shot at becoming the next trillion-dollar company in data. Not because every product announcement is the final answer. Some of them will change. Some will probably be wrong. That is normal. What matters is that the company keeps walking back toward the right problem.
And the right problem is no longer just analytics, warehousing, or transactional storage. It is the data foundation for AI systems that act.
From the Zilliz side, we have been arriving at a similar conclusion from another direction. Vector databases are not disappearing. They are becoming the serving engine inside a broader architecture for unstructured and multimodal data. That is why we think in terms of Vector Lakebase: not a replacement for vector databases, but the next architecture built around them as AI workloads become more continuous, elastic, and agentic.
The map is not finished. That is the best part.
Cheap beats expensive. Reliable beats unreliable. Careful beats careless. Patient beats impatient.
The AI-native database is still being drawn. For everyone building in this space, that is very good news.
One more thing: Zilliz Vector Lakebase is available in public preview
We've launched the public preview of Zilliz Vector Lakebase — a major evolution of Zilliz Cloud from a pure vector database into a lake-native data foundation for AI, combining low-latency vector serving with the openness, scalability, and economics of a data lake.
Zilliz Vector Lakebase core capabilities:
- Tiered serving optimized for different real-time performance-cost trade-offs
- On-demand search for large-scale or exploratory workloads without always-on compute
- External data lake search — index and search directly over your existing lake data
- Full-spectrum search across vectors, text, JSON, and geospatial data with hybrid retrieval and reranking
- Unified lake-native storage built on Vortex, an open format with faster and cheaper random reads than Lance or Parquet
If your current stack splits serving and discovery into separate systems, Vector Lakebase might be worth a look. Try it on Zilliz Cloud — new work email signups get $100 free credits — or talk to us about your use case.

Keep Reading

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.

Zilliz Cloud Introduces Advanced BYOC-I Solution for Ultimate Enterprise Data Sovereignty
Explore Zilliz Cloud BYOC-I, the solution that balances AI innovation with data control, enabling secure deployments in finance, healthcare, and education sectors.