




De Palavras a Vectores: Compreender o Word2Vec no Processamento de Linguagem Natural (PNL)
De Palavras a Vectores: Compreender o Word2Vec no Processamento de Linguagem Natural (PNL)
O que é Word2Vec?
O Word2Vec é um modelo de aprendizagem automática que converte palavras em representações numéricas vectoriais para captar os seus significados com base no contexto em que aparecem. Desenvolvido por Tomas Mikolov e a sua equipa na Google, utiliza grandes conjuntos de dados de texto para compreender as relações entre palavras e representar semelhanças semânticas e sintácticas. Ao contrário das abordagens tradicionais, como a codificação de uma só vez, o Word2Vec cria incorporações densas e significativas em que as palavras semelhantes são posicionadas mais próximas num espaço vetorial contínuo. O Word2Vec é amplamente utilizado em aplicações de Processamento de Linguagem Natural, como análise de sentimentos e sistemas de recomendação.
Por que precisamos do Word2Vec?
Compreender as relações e os significados das palavras é um desafio central no Processamento de Linguagem Natural (PNL). Os métodos tradicionais, como a codificação one-hot, representam as palavras como vectores esparsos e de alta dimensão em que cada palavra é independente das outras. Esta abordagem não consegue captar as relações semânticas ou sintácticas entre as palavras. Por exemplo, na codificação de uma só vez, os vectores para "rei" e "rainha" pareceriam completamente não relacionados, apesar de os seus significados estarem intimamente ligados.
Para além disso, estas representações esparsas são computacionalmente ineficientes, especialmente para grandes vocabulários, e não se generalizam bem a palavras ou contextos não vistos. Esta limitação tem dificultado a verdadeira compreensão da linguagem por parte das máquinas, impedindo o progresso em tarefas como a tradução automática, a análise de sentimentos e a classificação de pesquisas.
O Word2Vec resolve estes desafios criando [word embeddings] (https://zilliz.com/ai-faq/what-is-word-embedding) compactos e densos que representam relações entre palavras com base na forma como aparecem no texto. Ao captar tanto o significado das palavras como o seu contexto, o Word2Vec transformou a forma como as máquinas interpretam e processam a linguagem humana, tornando-a mais eficiente e significativa.
Como funciona o Word2Vec?
No coração do Word2Vec estão os word embeddings, que são [vectores densos] de baixa dimensão (https://zilliz.com/learn/dense-vetor-in-ai-maximize-data-potential-in-machine-learning) que captam as propriedades semânticas e sintácticas das palavras. O Word2Vec funciona através da análise de grandes volumes de texto para aprender as relações entre as palavras. No seu núcleo, é uma [rede neural] superficial(https://zilliz.com/learn/Neural-Networks-and-Embeddings-for-Language-Models) que gera representações vectoriais para as palavras, capturando os seus significados semânticos e sintácticos. O modelo identifica padrões na forma como as palavras co-ocorrem nas frases e utiliza esta informação para posicionar as palavras relacionadas mais próximas umas das outras num espaço vetorial contínuo.
O conceito principal é que os vectores semelhantes representam palavras com significados ou contextos de utilização semelhantes. Por exemplo, as palavras "rei" e "rainha" terão vectores muito próximos, com diferenças que codificam distinções semânticas específicas, como o género.
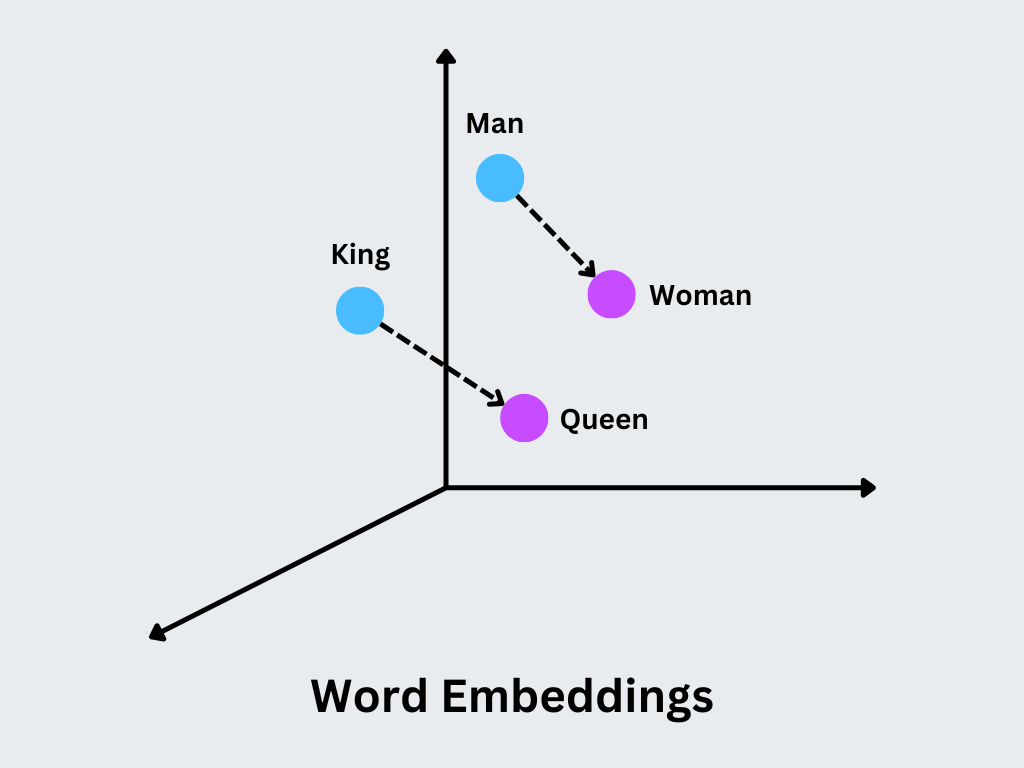 Figura- Word Embeddings.png
Figura- Word Embeddings.png
Figura: Incorporação de palavras
Word2Vec oferece duas abordagens para gerar embeddings, dependendo de como o contexto é tratado:
Saco de palavras contínuo (CBOW)
O [saco de palavras] contínuo (https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models#Bag-of-Words-Models) centra-se na previsão de uma palavra alvo com base nas palavras que a rodeiam. Por exemplo, na frase "As maçãs são doces e sumarentas", o CBOW utiliza as palavras de contexto ("Maçãs", "são", "e" e "sumarentas") para prever a palavra-alvo, como "doce".
O CBOW é computacionalmente eficiente porque calcula a média das palavras de contexto para prever o alvo. No entanto, tem um melhor desempenho com palavras frequentes e pode ter dificuldades com termos raros.
Caso de utilização: O CBOW é normalmente utilizado em aplicações como o preenchimento automático e a verificação ortográfica, em que é necessário prever a palavra em falta ou a palavra seguinte.
Modelo Skip-Gram
O Skip-Gram inverte o processo de predição. Em vez de prever uma palavra-alvo a partir do seu contexto, prevê as palavras do contexto com base numa palavra-alvo. Por exemplo, se a palavra-alvo for "doce", o Skip-Gram prevê as palavras de contexto "Maçãs", "são", "e" e "suculentas".
O Skip-Gram é melhor a lidar com palavras raras e é especialmente eficaz a captar relações mais matizadas quando se trabalha com grandes conjuntos de dados.
Caso de uso: O Skip-Gram é valioso em tarefas como a criação de sistemas de recomendação ou o agrupamento de termos semelhantes em campos especializados.
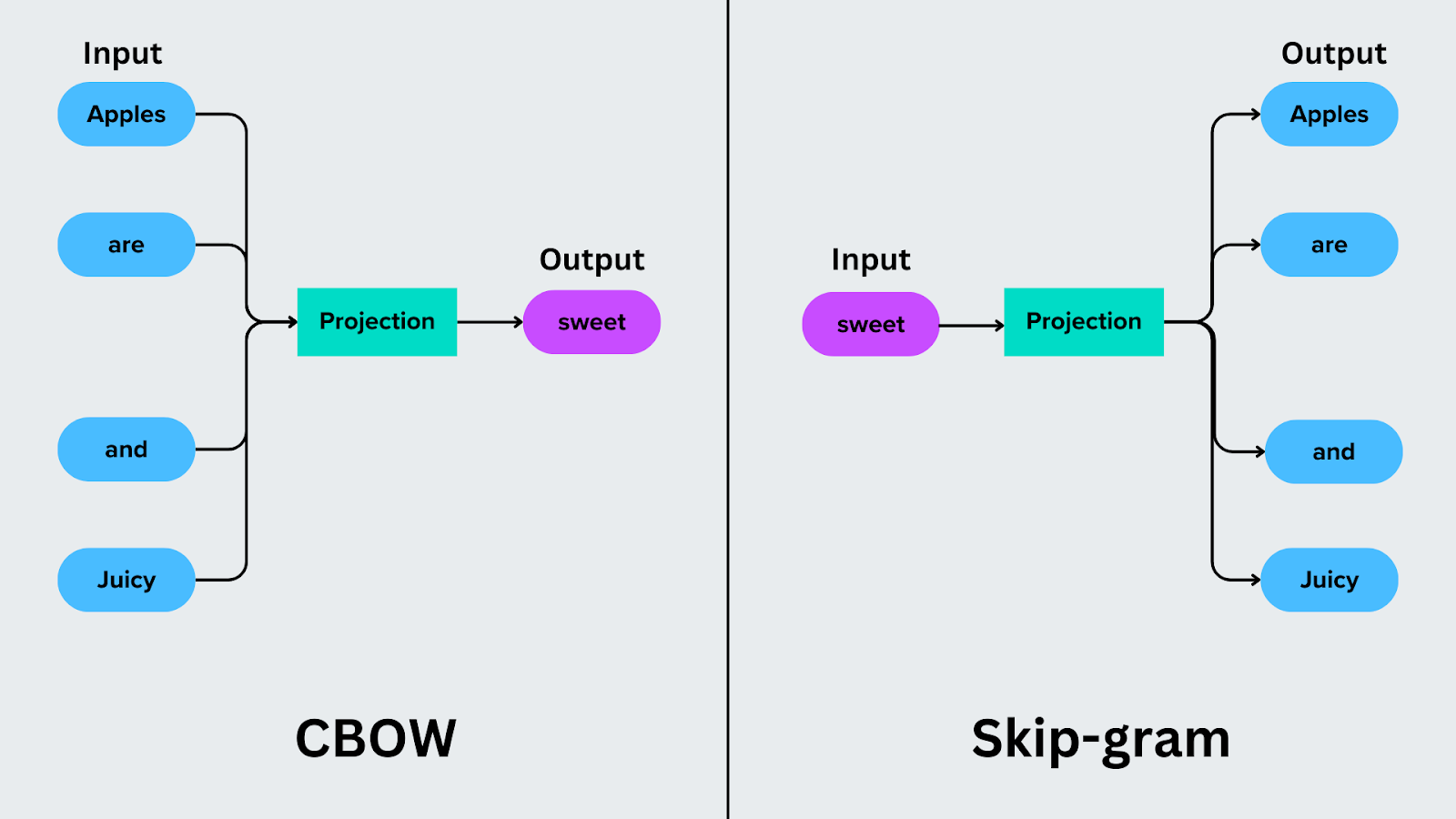 Figura- CBOW vs Skip-gram.png
Figura- CBOW vs Skip-gram.png
Figura: CBOW vs Skip-gram
Diferença entre o modelo CBOW e Skip-Gram
Embora tanto o CBOW como o Skip-Gram tenham como objetivo representar as palavras de uma forma significativa, diferem na forma como processam e prevêem as palavras com base no contexto. Abaixo está uma comparação para destacar as principais diferenças entre essas duas abordagens:
| Feature | Continuous Bag of Words (CBOW) | | Skip-Gram | | | ---------------------------- | --------------------------------------------------------- | -------------------------------------------------------- | | Determina a palavra-alvo usando o contexto circundante. | Prevê as palavras do contexto com base na palavra-alvo. | Eficiência | Mais rápido para treinar. | Mais lento para treinar. | | Foco** | Funciona bem com palavras frequentes. | Lida com palavras raras de forma eficaz. | | Complexidade** | Mais simples e computacionalmente eficiente. | Mais complexo e computacionalmente intensivo. | | Adequado para tarefas como previsão de palavras e autocorreção. | Ideal para tarefas especializadas, como sistemas de recomendação. | | Janela de contexto** | Considera a média de todas as palavras de contexto. | Avaliar palavras de contexto individuais separadamente. | | Requisito de tamanho do conjunto de dados** | Tem bom desempenho em conjuntos de dados menores. | Tem melhor desempenho com conjuntos de dados grandes. | | Exemplo | Prediz "latindo" a partir de "O cachorro está ___". | Prevê "O", "cachorro" e "é" a partir de "latindo". |
Tabela: CBOW vs Skip-Gram
Implementação do Word2Vec em Python
Abaixo está a implementação Python do Word2Vec usando os métodos CBOW e Skip-Gram. Este código é treinado num pequeno conjunto de dados personalizado para aprender a incorporação de palavras, demonstrando como ambos os métodos funcionam para capturar relações entre palavras com base no seu contexto. Ambas as secções do código foram concebidas para comparar a forma como o CBOW e o Skip-Gram aprendem relações entre palavras de forma diferente, mas partilham os mesmos parâmetros para uma comparação justa. Pode encontrar a implementação abaixo neste [Kaggle notebook] (https://www.kaggle.com/code/fariba999/word2vec-implementation).
Código
from gensim.models import Word2Vec
# Corpus pequeno e direcionado
corpus = [
["gato", "cão", "ladrou"],
["cão", "perseguido", "gato"],
["gato", "sentou-se", "tapete"],
["cão", "correu", "rápido"],
["gato", "correu", "rápido"],
["cão", "sentou-se", "tapete"]
]
# Treinar um modelo CBOW
cbow_model = Word2Vec(
frases=corpus,
vector_size=10, # Tamanho do vetor mais pequeno para simplificar
window=2, # Tamanho da janela de contexto
min_count=1, # Incluir todas as palavras
sg=0 # Definir sg=0 para CBOW
)
# Treinar um modelo de Skip-Gram
skipgram_model = Word2Vec(
frases=corpus,
vector_size=10, # Tamanho do vetor mais pequeno para simplificar
window=2, # Tamanho da janela de contexto
min_count=1, # Incluir todas as palavras
sg=1 # Definir sg=1 para Skip-Gram
)
# Função para apresentar vectores de palavras e palavras semelhantes
def display_model_results(model, model_name):
print(f"\n--- {nome_do_modelo} ---")
for word in ["cat", "dog"]:
print(f "Vetor de palavras para '{palavra}': {model.wv[palavra][:5]}...") # Mostra os primeiros 5 valores do vetor
palavras_similares = model.wv.most_similar(palavra, topn=3)
print(f "Mais semelhante a '{palavra}': {[(w, round(sim, 2)) for w, sim in similar_words]}")
# Mostrar os resultados do modelo CBOW
display_model_results(cbow_model, "CBOW Model")
# Mostrar os resultados do modelo Skip-Gram
exibir_resultados_do_modelo(skipgram_model, "Modelo Skip-Gram")
Saída:
--- Modelo CBOW ---
Vetor de palavras para 'cat': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Mais semelhantes a 'cat': [('cão', 0.54), ('rápido', 0.33), ('ladrou', 0.23)] Vetor de palavras para 'dog': [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Mais semelhantes a 'cão': [('gato', 0.54), ('rápido', 0.3), ('correu', 0.1)]
--- Modelo Skip-Gram ---
Vetor de palavras para 'gato': [ 0.07380505 -0.01533471 -0.04536613 0.06554051 -0.0486016 ]... Mais semelhantes a 'cat': [('cão', 0.54), ('rápido', 0.33), ('ladrou', 0.23)] Vetor de palavras para 'dog': [-0.00536227 0.00236431 0.0510335 0.09009273 -0.0930295 ]... Mais semelhantes a 'cão': [('gato', 0.54), ('rápido', 0.3), ('correu', 0.1)]
Na parte CBOW do código:
O modelo é treinado usando o parâmetro sg=0, que diz ao Word2Vec para usar o método Continuous Bag of Words.
O CBOW determina uma palavra utilizando o contexto das palavras que a rodeiam. Por exemplo, na frase ["cão", "perseguido", "gato"], o modelo pode utilizar "cão" e "gato" para prever "perseguido".
O vector_size=10 define o tamanho das palavras incorporadas (quantos números representam cada palavra).
A janela=2 especifica a [janela de contexto] (https://zilliz.com/glossary/context-window), o que significa que considera até 2 palavras antes e depois da palavra-alvo.
Na parte do código relativa ao Skip-Gram:
O modelo é treinado utilizando o parâmetro sg=1, que muda o Word2Vec para o método Skip-Gram.
O Skip-Gram identifica as palavras circundantes utilizando uma determinada palavra-alvo. Por exemplo, se a palavra-alvo for "perseguido", o modelo prevê "cão" e "gato" como vizinhos.
Semelhante ao CBOW:
vector_size=10 define o tamanho da palavra embeddings.
window=2 define o intervalo de palavras de contexto a considerar.
Benefícios do Word2Vec
Abaixo estão alguns dos principais benefícios que fazem do Word2Vec uma técnica fundamental na PNL:
Captura relações semânticas: O Word2Vec cria embeddings onde palavras semanticamente semelhantes (por exemplo, "rei" e "rainha") são posicionadas próximas umas das outras no espaço vetorial para analisar e utilizar estas relações em tarefas de PNL.
Compreensão contextual**: Ao analisar a coocorrência de palavras em grandes corpora, o Word2Vec capta relações dependentes do contexto, permitindo que os modelos compreendam melhor o significado das palavras em contextos específicos.
Representação eficiente**: Os word embeddings são densos e de baixa dimensão em comparação com representações esparsas como a codificação one-hot, o que os torna uma técnica eficiente em termos de memória e custos computacionais.
Lida com grandes vocabulários**: Ao contrário das técnicas mais antigas, o Word2Vec adapta-se eficazmente a grandes conjuntos de dados e vocabulários, tornando-o prático para aplicações do mundo real.
Apoia a aprendizagem por transferência**: Os embeddings pré-treinados do Word2Vec podem ser reutilizados em várias tarefas, economizando tempo e recursos computacionais e melhorando os resultados.
Aritmética em palavras: O Word2Vec suporta aritmética vetorial significativa para analogias como "rei - homem + mulher = rainha", que podem ser calculadas diretamente utilizando os embeddings.
Casos de uso do Word2Vec
O Word2Vec tem uma vasta gama de aplicações para tarefas de PNL. De seguida, apresentamos alguns dos seus casos de utilização práticos e com impacto:
Tradução automática: Melhora o mapeamento de palavras entre línguas, utilizando embeddings para alinhar palavras com significados semelhantes para aumentar a precisão da tradução.
Análise de sentimentos**: Identifica o tom do texto, analisando as relações entre palavras e o contexto para classificar sentimentos positivos, negativos ou neutros.
Classificação de pesquisa**: Melhora os motores de pesquisa ao compreender a semelhança entre as consultas de pesquisa e o conteúdo indexado, conduzindo a resultados mais relevantes.
Recomendações de produtos**: Faz corresponder as preferências do utilizador a produtos ou serviços, analisando descrições textuais e encontrando itens semelhantes.
Modelação de tópicos**: Organiza e analisa grandes conjuntos de dados de texto agrupando documentos em clusters com base na similaridade de palavras incorporadas.
Autocompletamento de texto**: Sugere palavras ou frases relevantes através da previsão de palavras contextualmente semelhantes, melhorando a experiência do utilizador em ferramentas de escrita ou de codificação.
Chatbots**: Permite uma melhor compreensão da entrada e do contexto do utilizador, ajudando os chatbots a gerar respostas precisas e relevantes.
Limitações do Word2Vec
Apesar dos seus benefícios, o Word2Vec apresenta as suas limitações:
Falta de consciência do contexto: O Word2Vec gera uma única incorporação para cada palavra, independentemente do seu contexto. Por exemplo, a palavra "banco" terá a mesma representação vetorial, quer se refira a uma margem de um rio ou a uma instituição financeira.
Dependência de dados**: Uma formação eficaz requer conjuntos de dados de texto grandes e de alta qualidade. Conjuntos de dados pequenos ou com curadoria deficiente podem levar a incorporações abaixo do ideal.
Lidar com palavras raras**: Luta com palavras pouco frequentes ou termos fora do vocabulário, uma vez que estes podem não aparecer o suficiente nos dados de treino para gerar embeddings significativos.
Sem representação ao nível da frase**: O Word2Vec foca-se em embeddings ao nível da palavra e não fornece representações para frases ou documentos inteiros, limitando o seu âmbito a tarefas específicas de PNL.
Ignora a ordem das palavras**: O modelo considera as palavras dentro de uma janela de contexto, mas não considera a sua sequência, o que pode afetar a compreensão da gramática ou da estrutura da frase.
Desatualizado em relação aos modelos modernos**: O Word2Vec foi substituído por modelos avançados como o BERT, o GLoVE e o GPT, que fornecem embeddings contextuais e mais robustos.
Colmatando a lacuna: Do Word2Vec ao GloVe, BERT e GPT
Os modelos preditivos, como o Word2Vec, criam embeddings de palavras focando-se no contexto local através de redes neuronais. No entanto, a sua dependência de pares de palavras próximas introduz uma limitação: Não conseguem captar relações mais amplas e globais em todo um corpus de texto. Por exemplo, embora o Word2Vec seja excelente na identificação de associações de palavras nas proximidades, muitas vezes não detecta ligações semânticas mais alargadas.
Para resolver este problema, o GloVe (Global Vectors for Word Representation) utiliza estatísticas de coocorrência globais para criar ligações de palavras. Analisa a frequência com que as palavras aparecem juntas em todo o corpus para capturar tanto o contexto local como as relações semânticas mais amplas para uma representação mais completa da linguagem.
Mais recentemente, modelos como o BERT (Bidirectional Encoder Representations from Transformers) e o GPT (Generative Pre-trained Transformer) foram além dos encaixes estáticos. O BERT introduziu as incorporações contextuais, representando as palavras de forma diferente com base na sua utilização numa frase, enquanto o GPT se concentrou na geração de texto coerente através da compreensão do contexto sequencial. Estes modelos transformaram ainda mais a PNL ao incorporarem representações dinâmicas e conscientes do contexto, resolvendo as limitações de métodos anteriores como o Word2Vec e o GloVe.
Word2Vec com Milvus: pesquisa vetorial eficiente para aplicações de PNL
O Word2Vec fornece uma maneira de criar embeddings de palavras que são essenciais para tarefas como [busca semântica] (https://zilliz.com/glossary/semantic-search), similaridade de documentos e sistemas de recomendação, onde a compreensão das relações entre palavras é crítica. No entanto, a gestão e a consulta de colecções extensas de embeddings de forma eficiente pode ser um desafio.
É aqui que entra o Milvus, a base de dados vetorial de código aberto desenvolvida por Zilliz. A Milvus fornece uma solução robusta para armazenar, indexar e consultar os embeddings Word2Vec ou qualquer outro tipo de embeddings em escala para uma integração perfeita nos fluxos de trabalho de PNL. Eis como o Word2Vec e o Milvus funcionam em conjunto:
Gestão eficiente de palavras incorporadas: O Word2Vec gera incorporações de alta dimensão para palavras do vocabulário, que podem crescer significativamente em tamanho com conjuntos de dados maiores. O Milvus lida eficientemente com esses embeddings ao:
Armazenamento escalável: Armazenamento de milhões de embeddings de palavras sem degradação do desempenho.
Recuperação rápida**: Algoritmos optimizados asseguram uma pesquisa rápida de embeddings semelhantes, que são cruciais para aplicações de PNL em tempo real, como sistemas de recomendação ou chatbots.
Pesquisa semântica melhorada: Os encaixes Word2Vec são excelentes na captura de relações entre palavras. Quando combinados com o Milvus, esses embeddings podem potencializar a pesquisa semântica avançada. Por exemplo:
Pesquisa de sinónimos ou termos relacionados (por exemplo, a pesquisa de "rei" permite obter embeddings como "rainha" ou "príncipe").
Implementação de sistemas de pesquisa robustos como [Retrieval Augmented Generation (RAG)] (https://zilliz.com/learn/Retrieval-Augmented-Generation) que se baseiam na semelhança de palavras para obter melhores resultados.
Fluxos de trabalho de PNL optimizados: Milvus simplifica os fluxos de trabalho de PNL que envolvem o Word2Vec através de:
Permite que os embeddings pré-treinados do Word2Vec sejam armazenados e consultados de forma eficiente.
Apoiando a integração com estruturas de aprendizagem automática para agrupamento, semelhança de documentos e pesquisa em tempo real.
Conclusão
O Word2Vec transformou a forma como trabalhamos com os dados linguísticos, introduzindo a incorporação de palavras que capturam os significados e as relações das palavras. Resolveu muitos desafios dos métodos tradicionais, como a incapacidade de captar semelhanças semânticas e sintácticas. É utilizado em aplicações como a análise de sentimentos, a tradução e os sistemas de recomendação. Apesar das suas limitações, o Word2Vec lançou as bases para muitos avanços neste domínio e influenciou o desenvolvimento de modelos mais sofisticados como o GLoVE, o BERT e o GPT.
FAQs sobre o Word2Vec
- **O que é o Word2Vec, e porque é que é importante?
O Word2Vec é um modelo de aprendizagem automática que cria representações vectoriais densas de palavras, denominadas word embeddings, com base no seu contexto. É importante porque capta as relações e os significados das palavras para tarefas de PNL como a análise de sentimentos, a tradução e a pesquisa.
- **Como é que o Word2Vec difere dos métodos tradicionais de representação de palavras?
Ao contrário dos métodos tradicionais, como a codificação de uma só vez, que representam as palavras como vectores esparsos sem relações inerentes, o Word2Vec cria embeddings densos que captam as semelhanças semânticas e sintácticas entre as palavras, tornando-o muito mais eficiente e significativo.
- **Quais são as principais arquitecturas utilizadas no Word2Vec?
O Word2Vec tem duas arquitecturas principais: Continuous Bag of Words (CBOW) e Skip-Gram. A CBOW determina uma palavra-alvo a partir do seu contexto circundante, enquanto a Skip-Gram identifica palavras de contexto utilizando uma determinada palavra-alvo. Cada uma tem os seus pontos fortes, dependendo do caso de utilização e do conjunto de dados.
- **Quais são os principais casos de utilização do Word2Vec?
O Word2Vec é utilizado em aplicações como a análise de sentimentos, a tradução automática, os sistemas de recomendação, a classificação de pesquisas, a modelação de tópicos e o desenvolvimento de chatbots. A sua capacidade de compreender as relações entre palavras torna-o versátil em várias tarefas de PNL.
- **Quais são as limitações do Word2Vec?
O Word2Vec tem várias limitações, incluindo a falta de conhecimento do contexto (por exemplo, não diferencia entre diferentes significados da mesma palavra), a dependência de grandes conjuntos de dados para treino e a incapacidade de captar a ordem das palavras ou o significado ao nível da frase. Estas desvantagens levaram ao desenvolvimento de modelos mais avançados como o GloVe, o BERT e o GPT.
Recursos relacionados
10 principais técnicas de PNL que todo cientista de dados deve conhecer
As 10 principais ferramentas e plataformas de processamento de linguagem natural](https://zilliz.com/learn/top-10-natural-language-processing-tools-and-platforms)
20 conjuntos de dados abertos populares para processamento de linguagem natural
Revelando o poder do processamento de linguagem natural: As 10 principais aplicações do mundo real
GloVe: um algoritmo de aprendizagem automática para descodificar ligações de palavras](https://zilliz.com/glossary/glove)
- O que é Word2Vec?
- Por que precisamos do Word2Vec?
- Como funciona o Word2Vec?
- Implementação do Word2Vec em Python
- Benefícios do Word2Vec
- Casos de uso do Word2Vec
- Limitações do Word2Vec
- Colmatando a lacuna: Do Word2Vec ao GloVe, BERT e GPT
- Word2Vec com Milvus: pesquisa vetorial eficiente para aplicações de PNL
- Conclusão
- FAQs sobre o Word2Vec
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis