




Tokenização: Compreender o texto separando-o
Tokenização: Compreender o texto separando-o
TL; DR
A tokenização é o processo de dividir o texto em unidades menores chamadas tokens, como palavras, frases ou subpalavras, para prepará-lo para modelos de aprendizado de máquina. Por exemplo, a frase "Tokenization in Milvus is powerful" pode ser dividida em tokens como ["Tokenization," "in," "Milvus," "is," "powerful"]. Estes tokens são transformados em embeddings numéricos que captam o seu significado para tarefas como a pesquisa semântica. Na base de dados vetorial Milvus, a tokenização está integrada com analisadores incorporados que processam o texto de forma eficiente para indexação e recuperação. Esta caraterística simplifica os fluxos de trabalho, permitindo aos programadores lidar diretamente com texto em bruto e alimentar aplicações de pesquisa avançada com elevada precisão e escalabilidade;
Introdução
No centro de muitos sistemas de inteligência artificial (IA) e processamento de linguagem natural (PNL) está um processo que transforma texto em bruto em "dados estruturados" - a tokenização. Mas o que é exatamente a tokenização e porque é tão importante para as máquinas dividir o texto em pedaços mais pequenos?
A tokenização é o processo de dividir o texto em unidades mais pequenas, permitindo às máquinas analisar e compreender a linguagem de forma mais eficaz. Este passo essencial permite que os computadores lidem e processem a linguagem humana para várias tarefas de PNL, tais como análise de sentimentos, tradução de linguagem e geração de texto.
 tokenização
tokenização
O que é Tokenization?
A tokenização divide textos, tais como palavras ou caracteres, em unidades mais pequenas chamadas tokens. É um passo fundamental na NLP, permitindo que as máquinas processem e compreendam a linguagem humana de forma mais eficaz.
Por que precisamos de tokenização?
A tokenização é como aprender uma nova língua: começa-se por dividir as frases em unidades mais pequenas para compreender o seu significado e estrutura. Da mesma forma, os computadores dividem um bloco de texto em unidades mais pequenas e manejáveis para o processar. A tokenização ensina o computador a identificar estes componentes fundamentais, como palavras ou subpalavras, permitindo-lhe compreender e analisar o texto.
Tecnicamente, a tokenização converte texto não estruturado num formato estruturado que um computador pode processar. Por exemplo, quando uma frase é introduzida num modelo de PNL, o tokenizador divide-a em tokens, aos quais são atribuídos valores numéricos. Estes valores permitem aos computadores efetuar operações matemáticas, identificar relações e extrair significado dos dados. Sem a tokenização, o texto continuaria a ser uma sequência de caracteres incompreensível para a máquina, impossibilitando uma análise mais aprofundada.
Conceitos-chave na tokenização
Aqui, exploraremos os principais conceitos que você precisa entender sobre tokenização.
Token
Um token é uma unidade básica de texto considerada significativa para análise. Os tokens podem ser caracteres, palavras ou subpalavras que servem como entrada principal para tarefas subsequentes de processamento de texto.
Tokenizador
Os tokenizadores são as ferramentas fundamentais que permitem aos computadores dissecar e interpretar a linguagem humana, dividindo o texto em tokens. Aplica regras específicas, como a divisão por espaços ou a utilização de técnicas de nível de subpalavra, para definir a granularidade da representação do texto.
Analisador
Um analisador vai além da simples tokenização para processar e compreender profundamente o texto. Após a tokenização, os filtros são aplicados aos tokens para refiná-los ainda mais, aplicando processamento adicional, como minúsculas, stemming, lematização ou remoção de stopwords.
Vocabulário
O vocabulário é o conjunto de tokens únicos (palavras, subpalavras ou caracteres) que um modelo pode processar. Ele é construído a partir dos tokens produzidos durante a tokenização. O vocabulário serve como referência do modelo para a compreensão do texto. A sua conceção e tamanho afectam a capacidade do modelo para lidar com a linguagem, especialmente com palavras raras ou não vistas.
Figura - Tokenizador e analisador em Milvus](https://assets.zilliz.com/Figure_Tokenizer_and_Analyzer_in_Milvus_2f283b3046.png)
Figura: Tokenizador e Analisador em Milvus
Este diagrama ilustra o fluxo de processamento de texto, em que o texto em bruto é tokenizado. Depois, um analisador aplica filtros para converter os tokens em minúsculas e remover palavras de paragem, resultando numa lista refinada de tokens com significado.
Tipos de tokenização
Os métodos de tokenização variam de acordo com a granularidade da decomposição do texto e os requisitos específicos da tarefa em questão. Aqui estão os tipos comuns de tokenização:
1. Tokenização de caracteres: Divide o texto em caracteres individuais. Isto pode ser útil para línguas com morfologia complexa e tarefas como correção ortográfica ou tratamento de texto com ruído.
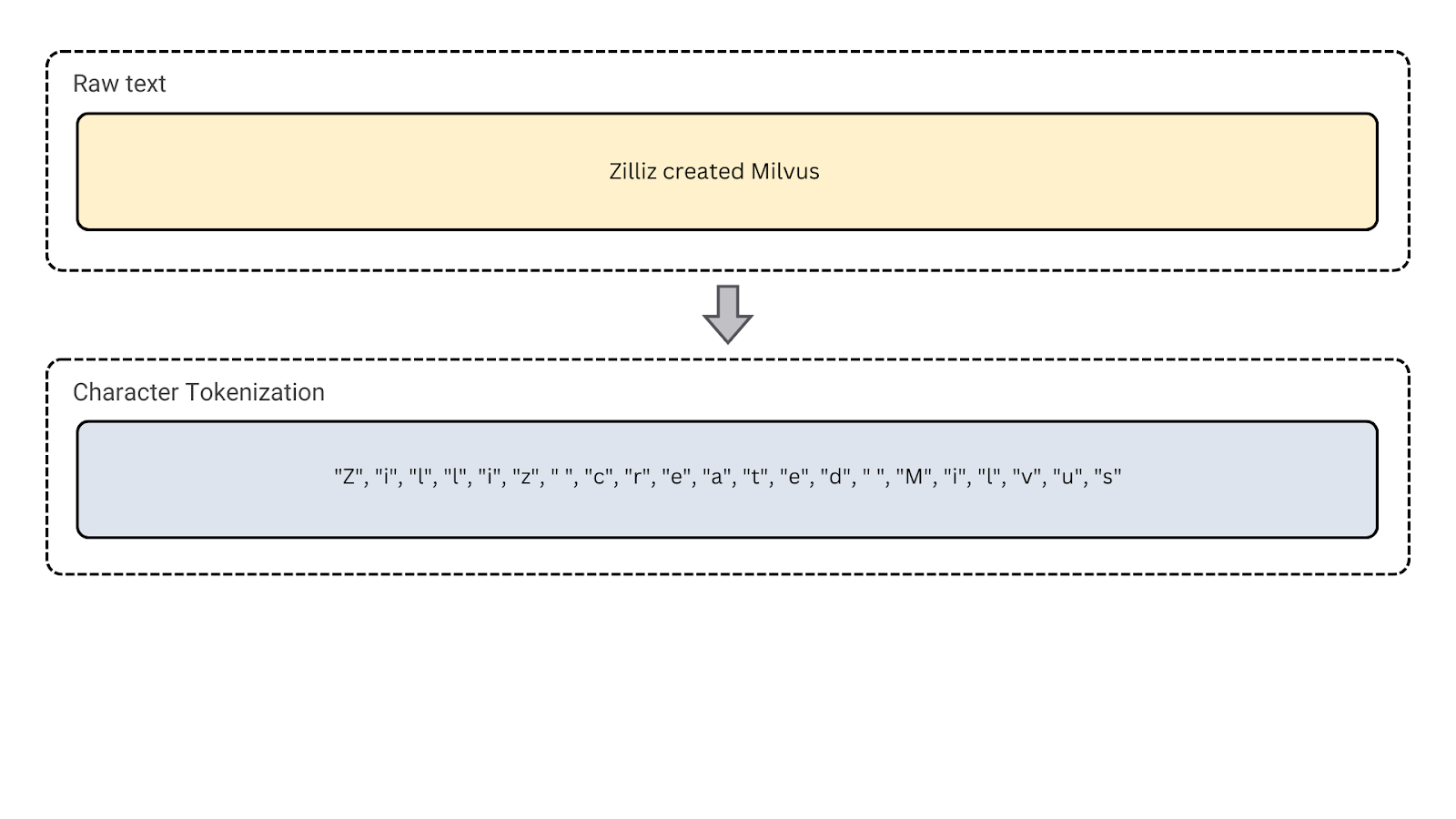 Figura - Tokenização de caracteres
Figura - Tokenização de caracteres
Figura: Tokenização de caracteres
2. Tokenização de palavras: Este é o tipo mais comum de tokenização, dividindo o texto em palavras individuais. É útil para modelagem de linguagem, marcação de parte da fala e reconhecimento de entidades nomeadas, que dependem da análise no nível da palavra.
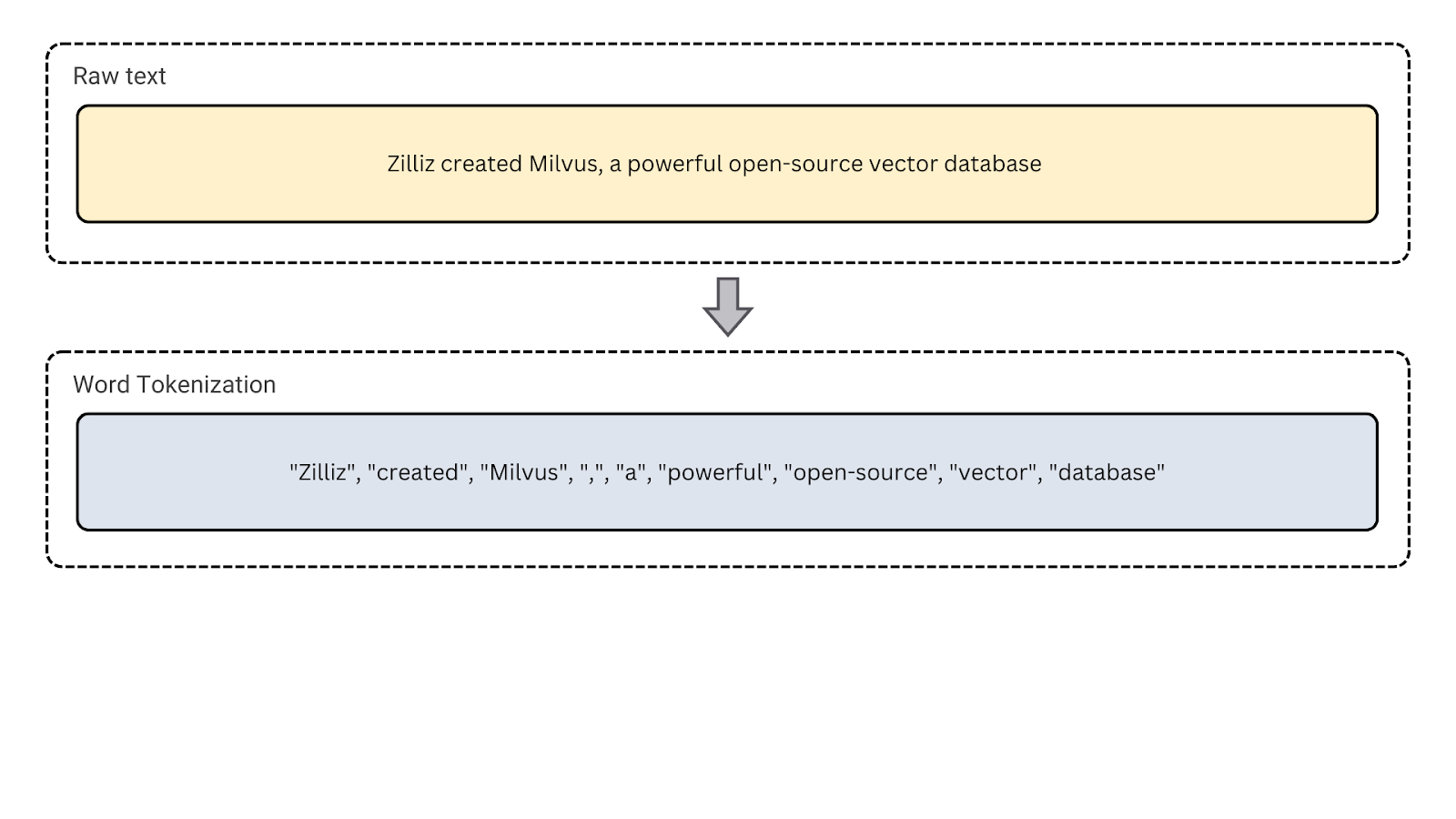 Figura- Tokenização de palavras
Figura- Tokenização de palavras
Figura: Tokenização de palavras.
3. Tokenização de frases: Este tipo segmenta o texto em frases. Ele separa parágrafos ou blocos longos de texto em frases distintas. Utilize este tipo para tarefas como a análise de sentimentos e o resumo de texto, em que é necessário analisar a estrutura ao nível da frase.
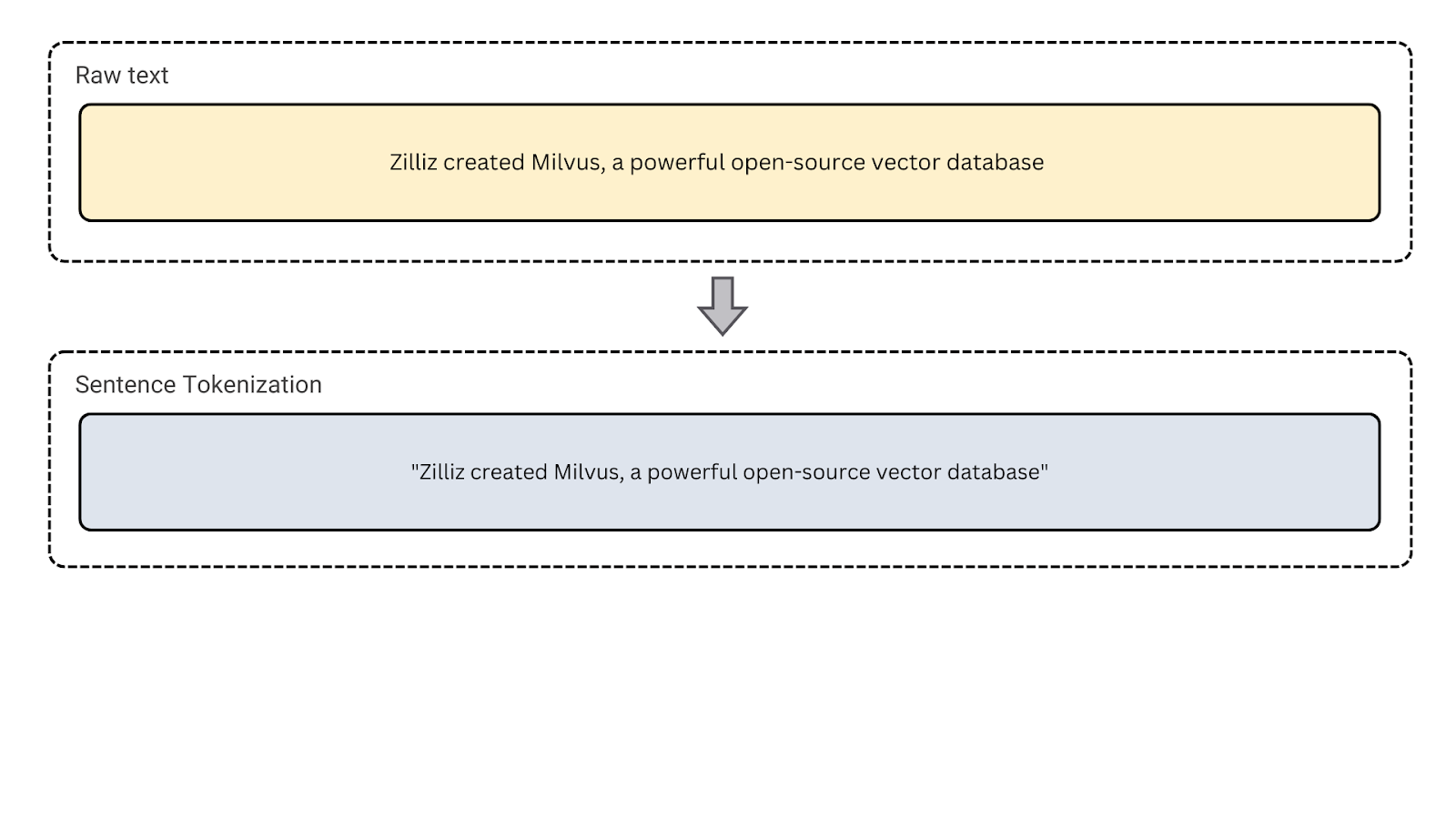 Figura - Tokenização de frases
Figura - Tokenização de frases
Figura: Tokenização de frases.
4. Tokenização de subpalavras: Este método divide as palavras em unidades mais pequenas e significativas (por exemplo, prefixos, sufixos ou hastes). Ajuda a reduzir o tamanho do vocabulário e é especialmente útil para tarefas como a geração de texto.
 Figura- Tokenização de subpalavras
Figura- Tokenização de subpalavras
Figura: Subword tokenization
A tokenização de subpalavras dividiu a frase em tokens de subpalavras. Palavras raras como "Zilliz" e "Milvus" são divididas em unidades mais pequenas. Além disso, "open-source" é dividido em ["open", "-", "source"], tratando o hífen como um token separado.
Exemplo de código
Aqui está um exemplo Python usando o [tokenizador BERT] da Hugging Face (https://huggingface.co/docs/transformers/v4.47.1/en/model_doc/bert#transformers.BertTokenizer). Ele demonstra como a sentença é tokenizada usando a tokenização de subpalavras com o algoritmo WordPiece:
from transformers import AutoTokenizer
# Carregar um tokenizador pré-treinado
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Tokenizar uma frase
frase = "Zilliz criou Milvus, uma poderosa base de dados vetorial de código aberto"
tokens = tokenizer.tokenize(sentence)
print(tokens)
Saída
['z', '##ill', '##iz', 'created', 'mil', '##vus', ',', 'a', 'powerful', 'open', '-', 'source', 'vetor', 'database']
Comparação entre Tokenização e Incorporação de Palavras
A tokenização e a incorporação de palavras são ambas técnicas fundamentais no processamento de linguagem natural (NLP), mas têm objectivos diferentes. A tokenização divide o texto em unidades menores, enquanto a incorporação converte essas unidades em forma numérica.
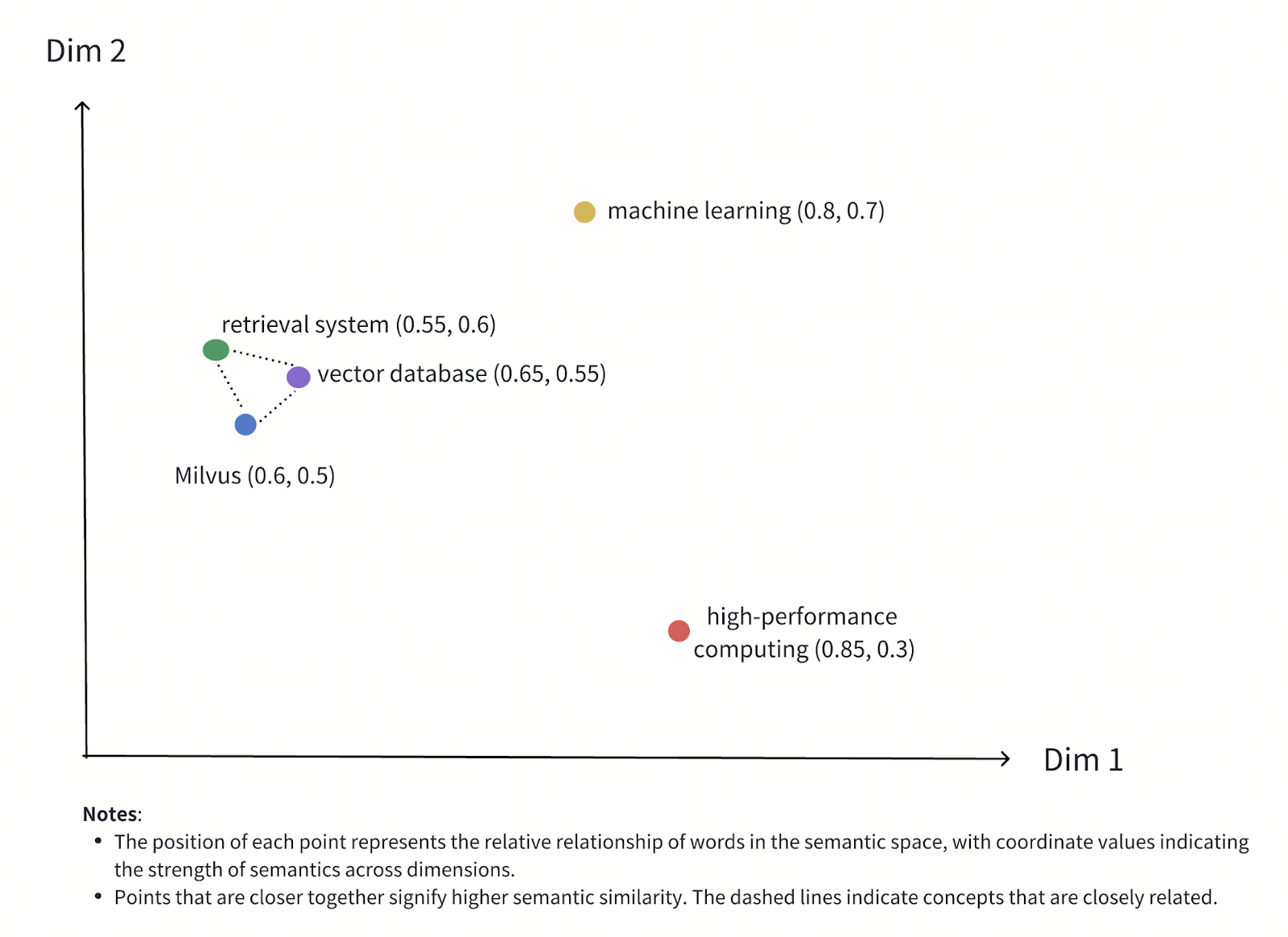 Figura - Relação semântica entre palavras no espaço vetorial
Figura - Relação semântica entre palavras no espaço vetorial
Figura: Relação Semântica entre Palavras no Espaço Vetorial
Aqui está uma comparação entre a Tokenização e a Incorporação de Palavras:
| Aspeto | Tokenização | Corporação de palavras | | | --------------- | ------------------------------------------------------------------------------- | -------------------------------------------------------------------------------- | | Definição** | O processo de dividir o texto em unidades menores (tokens) | Um método para representar tokens como vetores densos em um espaço vetorial de alta dimensão | | Separar o texto em unidades que podem ser processadas | Capturar o significado semântico e a relação entre as palavras na representação vetorial | | Exemplos** | Sentença: "A tokenização é crucial "Tokens: ["Tokenização", "é", "crucial"] | Palavra: "Milvus "Embedding: [0.23, 0.56, -0.12, ...] | | Converte texto não estruturado em um formato estruturado que pode ser processado por um computador. Captura a semântica, as relações e o contexto das palavras. | Limitações** | Não captura a semântica dos tokens | Requer grande poder computacional para gerar embeddings |
Benefícios e desafios da tokenização
A tokenização é crucial no processamento de texto. Oferece várias vantagens para a modelação e análise da linguagem, mas também tem os seus próprios desafios. Vamos examinar ambos os aspectos.
Benefícios
Processamento de texto eficaz:** A tokenização é fundamental na preparação de dados de texto para tarefas de PNL. Ela torna o texto mais adequado para modelos de aprendizado de máquina.
Controlo de granularidade:** A tokenização fornece controlo sobre o nível de granularidade, permitindo que o modelo trabalhe com palavras, subpalavras ou mesmo caracteres com base na tarefa em questão. Tarefas diferentes têm requisitos diferentes, e uma granularidade específica pode melhorar o desempenho.
Independência de idioma:** As técnicas de tokenização podem adaptar-se a diferentes idiomas e scripts para se adequarem a diferentes idiomas.
Facilita a modelagem de linguagem:** A tokenização é crucial para a modelagem de linguagem. Ela define as unidades básicas (tokens) que o modelo processa, permitindo uma melhor compreensão e geração de texto.
Desafios
Ambiguidade: A tokenização enfrenta desafios devido à ambiguidade da linguagem. Por exemplo, a palavra "banco" pode referir-se a uma instituição financeira ou à margem de um rio, dependendo do contexto. Da mesma forma, frases como "high school" podem ser tokenizadas como duas palavras separadas ou uma única unidade, afectando a interpretação.
Perda de tokens:** Alguns métodos de tokenização podem perder informação ao dividir as palavras em tokens mais pequenos, tornando mais difícil para os modelos compreenderem o contexto ou o significado completo do texto original
Tratamento de pontuação:** A segmentação de tokens que incluem pontuação, como apóstrofos ou traços, pode por vezes ser complicada para os algoritmos de PNL.
Línguas sem limites claros:** A tokenização pode ser particularmente difícil em línguas sem limites claros de palavras, como o chinês ou o japonês, onde os espaços nem sempre separam as palavras. Estas línguas requerem métodos de tokenização mais sofisticados para dividir o texto com precisão.
Casos de uso da tokenização
A tokenização é amplamente utilizada em várias tarefas de PNL, ajudando os sistemas a processar e analisar dados textuais. Abaixo estão alguns dos principais casos de uso da tokenização:
Motores de pesquisa:** A tokenização permite que os motores de pesquisa indexem e recuperem conteúdo relevante rapidamente, dividindo termos de consulta e documentos em tokens, garantindo resultados precisos para as consultas dos utilizadores.
Tradução automática:** A tokenização é fundamental na tradução automática, ajudando a decompor os idiomas de origem e de destino em tokens que um modelo pode mapear e traduzir eficazmente entre idiomas.
Reconhecimento de fala:** A tokenização ajuda a converter a linguagem falada em texto, segmentando a entrada de áudio em tokens para processamento, permitindo que os sistemas compreendam as palavras faladas de forma estruturada.
Análise de sentimentos:** A tokenização é essencial para a análise de sentimentos, onde decompõe o texto em tokens para processamento posterior, a fim de determinar se o sentimento expresso é positivo, negativo ou neutro.
Chatbots e assistentes virtuais:** A tokenização permite que os chatbots e os assistentes virtuais compreendam e processem as consultas dos utilizadores, dividindo o texto em unidades geríveis. Isto permite-lhes responder de forma inteligente com base na entrada.
Ferramentas para Tokenização
Várias ferramentas são normalmente usadas para tokenização em NLP:
NLTK: É uma poderosa biblioteca Python para processamento de linguagem natural, fornecendo ferramentas para tokenização, stemming, lematização, marcação POS e muito mais.
SpaCy: Uma biblioteca rápida de PNL com um poderoso tokenizador para palavras e frases e tokenização personalizável, o que a torna uma ferramenta de referência para aplicações industriais.
Hugging Face Tokenizer: Tokeniza modelos baseados em transformadores como BERT e GPT com tratamento de subpalavras.
Gensim: Popular para modelagem de tópicos, inclui funções de pré-processamento e tokenização de texto.
Tokenização na Base de Dados Vetorial Milvus
Uma base de dados vetorial foi concebida para armazenar, indexar e pesquisar dados não estruturados - tais como texto, imagens e vídeos - utilizando vetor embeddings de elevada dimensão. Estas incorporações permitem uma rápida recuperação de informação semântica e pesquisas baseadas em semelhanças, tornando as bases de dados vectoriais essenciais para aplicações como sistemas de recomendação, motores de pesquisa e fluxos de trabalho de IA.
**A "tokenização" é o primeiro passo neste processo. Divide o texto em bruto em unidades mais pequenas, tais como palavras, frases ou subpalavras, que são depois convertidas em representações numéricas (vetor embeddings) por [modelos de aprendizagem automática] (https://zilliz.com/ai-models). A Milvus, uma base de dados de vectores de código aberto desenvolvida por Zilliz, armazena estas incorporações num espaço de elevada dimensão, onde podem ser consultadas de forma eficiente para verificar a sua semelhança.
Tokenização incorporada no Milvus
Milvus simplifica a tokenização com seus built-in analyzers, que são adaptados para diferentes idiomas e casos de uso. Esses analisadores integram tokenizadores e filtros para processar dados de texto para indexação e recuperação eficientes:
Analisador padrão: O analisador padrão para processamento de texto de uso geral. Ele executa a tokenização baseada em gramática, converte tokens em minúsculas e suporta pesquisas sem distinção entre maiúsculas e minúsculas.
Analisador de inglês**: Projetado especificamente para texto em inglês. Inclui stemming (redução de palavras às suas formas de raiz) e remoção de palavras de paragem comuns, concentrando-se em termos significativos.
Analisador chinês**: Optimizado para processar texto chinês, com tokenização concebida para lidar com estruturas linguísticas únicas.
Estes analisadores integrados permitem aos programadores introduzir texto em bruto diretamente no Milvus sem necessidade de pré-processamento externo, simplificando os fluxos de trabalho e reduzindo a complexidade.
Como Milvus lida com a Tokenização
A partir do Milvus 2.5, a base de dados inclui capacidades pesquisa de texto completo integradas, permitindo-lhe processar internamente entradas de texto em bruto. Quando insere dados de texto, o Milvus utiliza o analisador especificado para tokenizar o texto em termos individuais e pesquisáveis. Estes termos são depois convertidos em representações vectoriais esparsas utilizando algoritmos como BM25 e armazenados para uma recuperação eficiente.
Esta abordagem híbrida permite ao Milvus tratar tanto os vectores densos (embeddings semânticos) como os vectores esparsos (representações baseadas em palavras-chave). Como resultado, o Milvus suporta cenários avançados de pesquisa híbrida que combinam a compreensão semântica com a precisão das palavras-chave, ao mesmo tempo que gere a tokenização e a vectorização de forma integrada na base de dados.
Benefícios da Tokenização Integrada no Milvus
Fluxo de trabalho simplificado**: Os analisadores integrados do Milvus eliminam a necessidade de ferramentas externas de tokenização, facilitando a ingestão direta de dados de texto bruto.
Capacidades de pesquisa melhoradas**: Ao combinar a pesquisa de texto completo com a [pesquisa de semelhança vetorial] (https://zilliz.com/learn/vetor-similarity-search), o Milvus fornece resultados altamente precisos e relevantes para diversas aplicações.
Escalabilidade**: O tratamento interno da tokenização e vectorização garante que o Milvus pode processar eficientemente dados de texto em grande escala numa variedade de casos de utilização.
Com estas caraterísticas, o Milvus permite que os programadores criem mais facilmente aplicações de pesquisa e análise inteligentes, concentrando-se na inovação e não nas complexidades do pré-processamento de texto. Quer esteja a trabalhar em pesquisa de linguagem natural, recomendações orientadas por IA ou sistemas de recuperação híbridos, o Milvus fornece uma plataforma robusta e de fácil desenvolvimento para alimentar as suas aplicações.
FAQs sobre Tokenização
**01. Por que a tokenização é importante na PNL?
A tokenização converte texto não estruturado em unidades gerenciáveis, permitindo que os computadores processem a linguagem. Ajuda os modelos de PNL a atribuir representações numéricas aos tokens, permitindo operações matemáticas e a extração de padrões significativos.
**02. Qual é a diferença entre tokenização de palavras e caracteres?
A tokenização de palavras divide o texto em palavras individuais, tratando cada palavra como um token separado. Por outro lado, a tokenização de caracteres divide o texto em caracteres individuais.
**03. O que é lematização e tokenização?
A tokenização divide o texto em unidades mais pequenas, como palavras ou frases, facilitando o processamento por parte dos computadores. A lematização reduz as palavras à sua forma básica, como a conversão de "running" para "run", garantindo a consistência na compreensão da língua.
**04. Como é que a tokenização afecta o desempenho do modelo?
A tokenização afecta a forma como o texto é dividido e compreendido por um modelo. A tokenização adequada pode melhorar o desempenho do modelo, capturando relações precisas entre palavras, enquanto uma tokenização deficiente pode levar a interpretações erradas ou perda de significado.
**05. Que papel desempenha a tokenização na análise de sentimentos ou na classificação de textos?
Na análise de sentimentos e na classificação de textos, a tokenização divide o texto em unidades mais pequenas, como palavras ou frases, que podem ser analisadas em busca de padrões ou sentimentos. Este processo permite que os algoritmos processem tokens individuais e classifiquem ou atribuam sentimentos ao texto com precisão.
Recursos relacionados
- TL; DR
- Introdução
- O que é Tokenization?
- Por que precisamos de tokenização?
- Conceitos-chave na tokenização
- Tipos de tokenização
- Comparação entre Tokenização e Incorporação de Palavras
- Benefícios e desafios da tokenização
- Casos de uso da tokenização
- Ferramentas para Tokenização
- Tokenização na Base de Dados Vetorial Milvus
- FAQs sobre Tokenização
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis