




Observabilidade: Seguimento para além da monitorização
Observabilidade: Seguimento para além da monitorização
O que é observabilidade?
Observabilidade significa entender o que está acontecendo dentro de um sistema com base nos dados que ele produz. Pense nisso como a capacidade de "olhar para dentro" de um sistema de software e entender seu estado e comportamento. Ajuda a responder a perguntas como: "Está tudo a funcionar como esperado?" ou "Porque é que algo está a correr mal?" Em vez de adivinhar o que está a causar os problemas, a observabilidade fornece informações claras através de dados como registos, métricas e rastreios.
Por que a observabilidade é importante?
Os sistemas de software modernos estão ficando mais complexos. Com o surgimento de tecnologias como microsserviços, computação em nuvem e conteinerização, os sistemas agora são compostos de muitas partes interconectadas que podem estar espalhadas por diferentes locais. Isto torna-os difíceis de monitorizar e resolver problemas.
As ferramentas de monitoramento tradicionais geralmente são insuficientes - elas podem dizer que algo está errado, mas não o porquê. A observabilidade preenche essa lacuna, fornecendo visibilidade do estado interno dos sistemas para identificar problemas rapidamente.
Pilares principais da observabilidade
O Observability tem três pilares que trabalham juntos para fornecer uma imagem clara do que está acontecendo dentro de um sistema. Vamos detalhá-los:
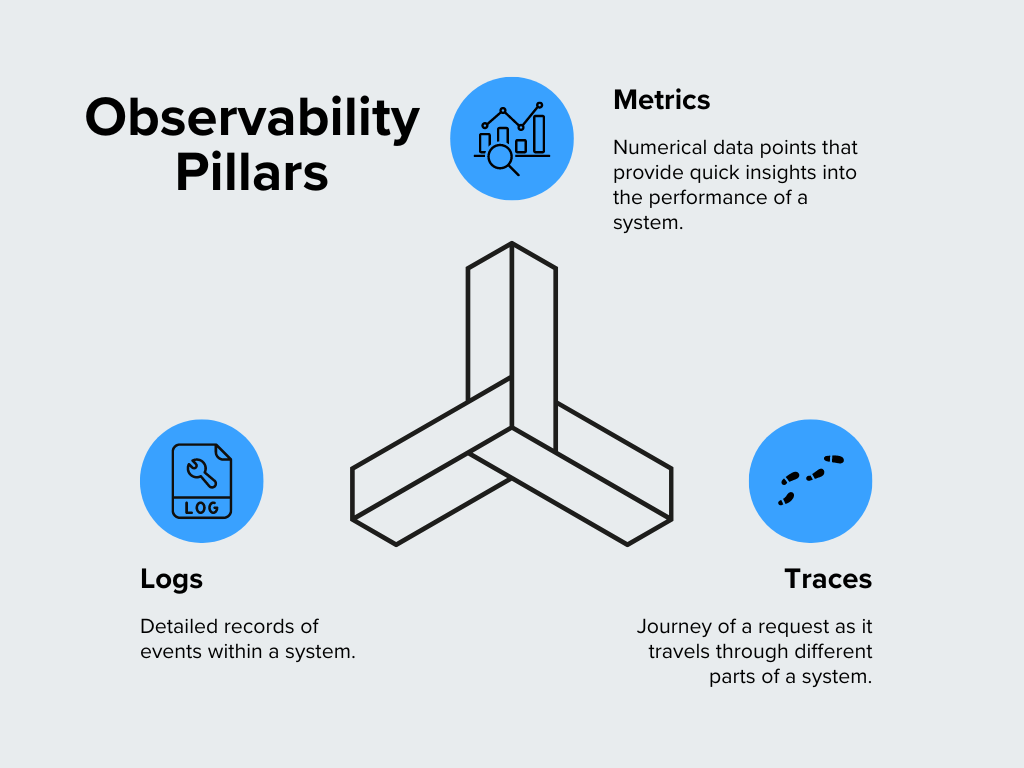 Figura - Pilares da Observabilidade.png
Figura - Pilares da Observabilidade.png
Figura: Pilares da observabilidade
Métricas
As métricas são pontos de dados numéricos que fornecem informações rápidas sobre o desempenho de um sistema. Elas são os sinais vitais do seu sistema que mostram como as coisas estão funcionando. As métricas comuns incluem o uso da CPU, o consumo de memória, as taxas de solicitação e os tempos de resposta. Por exemplo, se você notar um pico incomum no uso da CPU, isso pode indicar um problema que precisa de atenção. As métricas são óptimas para identificar tendências e ver como um sistema se comporta ao longo do tempo.
Logs
Os logs são registos detalhados de eventos dentro de um sistema. Pense neles como um diário que captura o que acontece dentro do seu software. Sempre que ocorre um erro, um utilizador inicia sessão ou é processada uma transação, esta é normalmente registada num registo. Os registos fornecem contexto para diagnosticar problemas e compreender o comportamento do sistema. Por exemplo, quando algo corre mal, os registos podem ajudar a identificar o que aconteceu imediatamente antes e depois da ocorrência do problema.
Traces
**Em uma configuração complexa com vários serviços trabalhando juntos, um rastreamento mostra o caminho percorrido por um único pedido e quanto tempo ele gasta em cada serviço. Os rastreamentos identificam gargalos ou atrasos no processo. Se um pedido demorar mais do que o esperado, os traços podem ajudá-lo a ver onde está a ocorrer o abrandamento.
Como funciona a observabilidade?
A observabilidade segue algumas etapas importantes. Veja como ela funciona:
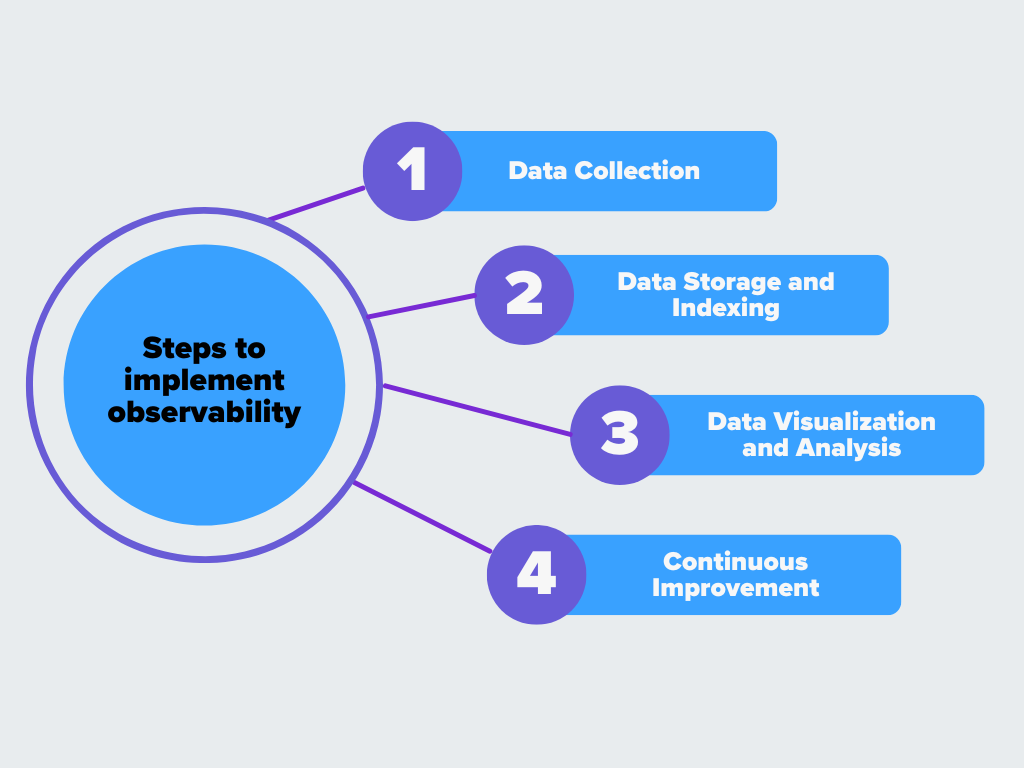 Figura - Passos para implementar a observabilidade.png
Figura - Passos para implementar a observabilidade.png
Figura: Passos para implementar a observabilidade
Recolha de dados
O primeiro passo é recolher dados de todas as partes do sistema. Isso inclui a coleta de métricas (como
uso da CPU), logs (registros detalhados de eventos) e traces (o caminho que as solicitações tomam através dos serviços). O objetivo é capturar tudo o que possa oferecer informações sobre o desempenho do sistema, problemas ou comportamento geral. Estes dados provêm de várias fontes, tais como servidores, aplicações, bases de dados e interações dos utilizadores.
Armazenamento e indexação de dados
Depois que os dados são coletados, eles devem ser armazenados de forma eficiente. O armazenamento adequado significa que pode encontrar e utilizar rapidamente os dados quando necessário. A indexação dos dados ajuda a procurar e recuperar partes específicas de informações mais rapidamente. Por exemplo, quando surge um problema, os engenheiros devem ser capazes de obter facilmente os registos ou métricas relacionados com esse incidente sem atrasos. As boas práticas de armazenamento são cruciais para manter os dados organizados e acessíveis.
Visualização e análise de dados
Recolher dados é uma coisa, mas dar-lhes sentido é outra. As ferramentas de visualização e os dashboards desempenham um papel vital aqui. Eles transformam dados brutos em gráficos, tabelas e alertas fáceis de entender. A visualização ajuda as equipas a ver rapidamente tendências, padrões ou qualquer comportamento invulgar no sistema. Os painéis de controlo facilitam a deteção de problemas de desempenho e o aprofundamento dos detalhes se algo parecer estranho. Os sistemas de alerta também podem notificar as equipas em tempo real quando as métricas ultrapassam determinados limites ou quando ocorrem erros.
Melhoria contínua
Os dados de observabilidade não servem apenas para corrigir problemas, mas também para melhorar o sistema. Ao analisar regularmente os dados recolhidos, as equipas podem identificar áreas que precisam de ser melhoradas ou optimizadas. O ciclo de feedback contínuo incorpora melhorias para que o sistema funcione de forma mais eficiente. Os dados de observabilidade podem orientar as decisões sobre o dimensionamento dos recursos, o que melhora a experiência do utilizador e evita problemas futuros.
Casos de uso da observabilidade
A observabilidade tem um forte impacto nas aplicações do mundo real. Aqui estão alguns casos práticos que mostram como a observabilidade faz a diferença:
Monitorização do desempenho em sistemas distribuídos
Os problemas de desempenho podem ser difíceis de identificar em um sistema distribuído com vários serviços trabalhando juntos. A observabilidade ajuda fornecendo métricas, logs e traços que dão uma imagem clara de como os diferentes serviços interagem. Por exemplo, se um único microsserviço torna a aplicação inteira mais lenta, as ferramentas de observabilidade podem destacar rapidamente qual serviço está causando o atraso.
Depuração e solução de problemas de falhas
Quando um sistema quebra, as equipes descobrem o que deu errado. A observabilidade torna este processo muito mais fácil, fornecendo registos detalhados e vestígios de eventos. Por exemplo, se um servidor falhar ou um pedido falhar, os registos podem mostrar exatamente o que aconteceu imediatamente antes da falha. Os traços ajudam as equipas a ver como o problema se propaga por diferentes serviços.
Confiabilidade e disponibilidade
A observabilidade desempenha um papel importante no cumprimento dos objetivos de nível de serviço (SLOs) e dos acordos de nível de serviço (SLAs). Estes são compromissos sobre o quão fiável e disponível um sistema deve ser. Ao acompanhar o estado do sistema através de métricas e alertas, as equipas podem cumprir estes objectivos. Por exemplo, se os tempos de resposta começarem a ficar mais lentos, a observabilidade ajuda as equipas a agir antes de os utilizadores serem afectados, mantendo um serviço fiável.
Planeamento e dimensionamento da capacidade
À medida que os sistemas crescem, eles precisam de mais recursos, como servidores ou memória. A observabilidade ajuda no planejamento de capacidade rastreando métricas que mostram como o sistema está sendo usado. Por exemplo, monitorar o uso da CPU ou a carga do banco de dados ao longo do tempo pode ajudar a prever quando mais capacidade é necessária. Com o planeamento e o escalonamento da capacidade, o sistema funciona bem sem surpresas.
Deteção proativa de problemas
Uma das melhores utilizações da observabilidade é a deteção de problemas antes de se tornarem grandes problemas. A monitorização e os alertas em tempo real permitem às equipas detetar padrões ou picos invulgares, como o aumento das taxas de erro ou dos tempos de resposta. A abordagem proactiva pode evitar tempos de inatividade e manter uma experiência de utilizador sem problemas. Por exemplo, se as ferramentas de observabilidade detectarem precocemente uma fuga de memória, as equipas podem corrigi-la antes que o sistema entre em colapso.
Monitorização da experiência do utilizador
A observabilidade não se refere apenas ao backend; também pode monitorizar as interações e o comportamento do utilizador. A monitorização das métricas da experiência do utilizador, como os tempos de carregamento da página, os tempos de resposta dos botões e as mensagens de erro, ajuda as equipas a identificar e a corrigir rapidamente os problemas que afectam o utilizador. Por exemplo, se uma nova funcionalidade fizer com que as páginas carreguem mais lentamente, os dados de observabilidade mostrarão isso imediatamente.
Otimização de custos em ambientes de nuvem
Os ambientes de nuvem geralmente envolvem preços de pagamento conforme o uso, o que significa que você é cobrado pelos recursos que usa. A observabilidade pode ajudar as equipes a otimizar os custos rastreando quais partes do sistema usam mais recursos. Por exemplo, se um determinado microsserviço consome uma grande quantidade de largura de banda, as ferramentas de observabilidade podem identificar isso, permitindo que a equipe otimize ou refatore o serviço para reduzir os custos.
Ferramentas e tecnologias para observabilidade
O Prometheus é uma ferramenta de monitoramento de código aberto que coleta e armazena métricas como dados de séries temporais. É amplamente utilizada para monitorizar o desempenho de sistemas e aplicações através das suas capacidades de consulta flexíveis.
Grafana](https://grafana.com/) é uma ferramenta de visualização frequentemente associada ao Prometheus. Ela cria painéis interativos que ajudam a visualizar métricas do Prometheus, interpretar dados facilmente, monitorar tendências e configurar alertas para o comportamento do sistema.
O Jaeger é uma ferramenta de rastreamento distribuída que ajuda a rastrear solicitações à medida que elas fluem pelos microsserviços. Ela também ajuda a rastrear latências e identificar gargalos em sistemas complexos e distribuídos.
AWS CloudWatch](https://aws.amazon.com/cloudwatch/) é a ferramenta de monitorização e observabilidade da Amazon que rastreia métricas, recolhe registos e fornece alertas para recursos de nuvem AWS. Integra-se bem com outros serviços AWS para monitorizar e gerir a sua infraestrutura.
O Google Cloud Monitoring oferece visibilidade de aplicações e serviços em execução no Google Cloud. Oferece métricas, painéis de controlo e alertas para monitorizar a saúde e o desempenho dos recursos da nuvem.
O Azure Monitor é uma ferramenta que oferece total observabilidade dos recursos e aplicativos da nuvem do Azure. Recolhe métricas, registos e rastreios para ajudar as equipas a analisar o desempenho e a resolver rapidamente os problemas.
As ferramentas de observabilidade modernas utilizam IA e aprendizagem automática para detetar anomalias e prever problemas futuros. Estas ferramentas avançadas podem identificar automaticamente padrões e alertar as equipas para comportamentos invulgares.
Desafios da observabilidade
Escalabilidade e volume de dados
Coletar, armazenar e processar grandes quantidades de métricas, logs e traces pode se tornar um desafio em um sistema em crescimento. O gerenciamento eficiente de dados e as soluções de armazenamento escalonáveis são fundamentais para lidar com esse crescimento.
Sobrecarga de dados
O excesso de dados pode sobrecarregar as equipas e dificultar a obtenção de informações úteis. Para evitar o ruído, é importante filtrar e concentrar-se em dados acionáveis que ajudem diretamente a diagnosticar e a resolver problemas, em vez de seguir todos os pequenos detalhes.
Integração entre serviços
Os sistemas modernos utilizam frequentemente várias ferramentas e componentes. A integração adequada é necessária para manter a observabilidade contínua entre esses diferentes serviços. Sem ela, informações críticas podem ser perdidas, e o tempo pode ser desperdiçado pulando entre as ferramentas.
Práticas recomendadas de observabilidade
Para utilizar os benefícios da observabilidade da melhor forma possível, certifique-se de que segue as melhores práticas como:
Construir com a observabilidade em mente
Desde o início, projete sistemas para serem facilmente observáveis. Incorpore métricas, logs e traços em sua arquitetura para facilitar o rastreamento e a compreensão do comportamento do sistema. Essa abordagem proativa simplifica a solução de problemas futuros e o ajuste de desempenho.
Visão unificada de todos os sistemas
Consolide todos os dados de observabilidade em uma plataforma ou painel. Uma visão unificada ajuda as equipas a identificar rapidamente os problemas e a obter uma compreensão holística de como os diferentes serviços estão a interagir, reduzindo o tempo gasto a reunir informações de várias fontes.
Estratégias de alerta e notificação
Configure alertas que sejam claros, significativos e acionáveis. Evite a fadiga dos alertas, visando apenas eventos críticos ligados a acções específicas e necessárias. O objetivo é informar a equipa de forma eficaz e não sobrecarregá-la com ruído.
Observabilidade vs. Monitorização
Embora frequentemente mencionados em conjunto, a observabilidade e a monitorização não são a mesma coisa. A tabela abaixo destaca as principais diferenças entre os dois:
| Aspeto | Observabilidade | Monitoramento | | | ------------------ | ------------------------------------------------------------------------ | -------------------------------------------------------------------- | | Objetivo | Fornece uma compreensão mais profunda do estado interno do sistema. | Rastreia métricas específicas para detetar problemas ou anomalias. | | Dados coletados | Reúne métricas, logs e rastreamentos para análise detalhada. | Coleta métricas predefinidas, como uso da CPU, memória e erros. | | Abordagem Exploratória: ajuda a entender "por que" um problema aconteceu. | Reativa; notifica quando ocorre um problema conhecido. | | Escopo: concentra-se no comportamento geral do sistema e em informações sobre o desempenho. | Foca em métricas individuais para medir a saúde do sistema. | | Resolução de problemas Ajuda a identificar rapidamente problemas desconhecidos e causas principais. | Alerta para problemas conhecidos, mas pode não ter contexto para uma análise mais profunda. | | Análise em tempo real Oferece suporte à análise de dados em tempo real para acompanhar o comportamento do sistema em tempo real. | Depende de verificações e limites predefinidos, geralmente com contexto atrasado. | | Flexibilidade de dados Permite a exploração flexível e profunda dos dados além das métricas predefinidas. | Monitora métricas específicas e pré-selecionadas sem um contexto mais amplo. |
Diferenças de observabilidade e monitorização
Observabilidade em Milvus e Zilliz Cloud: Acompanhar o desempenho do banco de dados vetorial
O Milvus é uma base de dados vetorial de código aberto concebida para tratar dados não estruturados à escala de mil milhões de forma eficiente. É ideal para aplicações de pesquisa semântica, pesquisa por semelhança e GenAI. A observabilidade desempenha um papel crucial na gestão e otimização do desempenho do Milvus. Utilizando práticas de observabilidade, pode garantir que a sua base de dados de vectores está a funcionar sem problemas e de forma eficaz, quer se trate de recomendações em tempo real ou de tarefas retrieval-augmented generation (RAG) .
O Milvus de código aberto integra o Prometheus para monitorizar o seu desempenho e o Grafana para visualizar todas as métricas. O Milvus integra-se perfeitamente com o Prometheus através de:
Prometheus Endpoint: Reúne dados de vários exportadores.
Prometheus Operator: Simplifica o gerenciamento das configurações de monitoramento do Prometheus.
Kube-Prometheus: Simplifica o monitoramento completo do cluster Kubernetes para uma operação robusta.
Com o Prometheus, é possível rastrear métricas críticas de desempenho do Milvus, como tempos de resposta de consulta e uso de recursos (CPU, GPU e memória), permitindo a resolução proativa de problemas e a otimização do sistema. Além disso, a integração do Prometheus com Grafana aprimora ainda mais sua estrutura de monitoramento, fornecendo painéis detalhados para análise aprofundada e manutenção eficiente das implantações do Milvus adaptadas aos aplicativos GenAI e similarity search.
Para obter orientações abrangentes sobre a configuração do Prometheus para Milvus e a visualização de métricas com o Grafana, explore os recursos abaixo:
Monitorar o Milvus com o Prometheus | Documentação do Milvus
Visualize as métricas do Milvus com o Grafana | Documentação do Milvus
Zilliz Cloud é a versão gerenciada do Milvus com recursos mais avançados e desempenho 10x maior. Fornece funcionalidades de monitorização e observabilidade ainda mais claras e fáceis. O Zilliz Cloud introduziu recentemente [funcionalidades robustas de monitorização e observabilidade] (https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud) para ajudar os utilizadores a acompanhar o desempenho da base de dados vetorial. O painel Metrics fornece uma visão geral da saúde do cluster, incluindo a utilização de recursos (CPU, memória, armazenamento), o desempenho (QPS, VPS, latências) e as métricas de dados (contagens de colecções e entidades), tudo personalizável para uma análise mais profunda. O painel de controlo apresenta as métricas de uma forma muito intuitiva para obter informações rápidas.
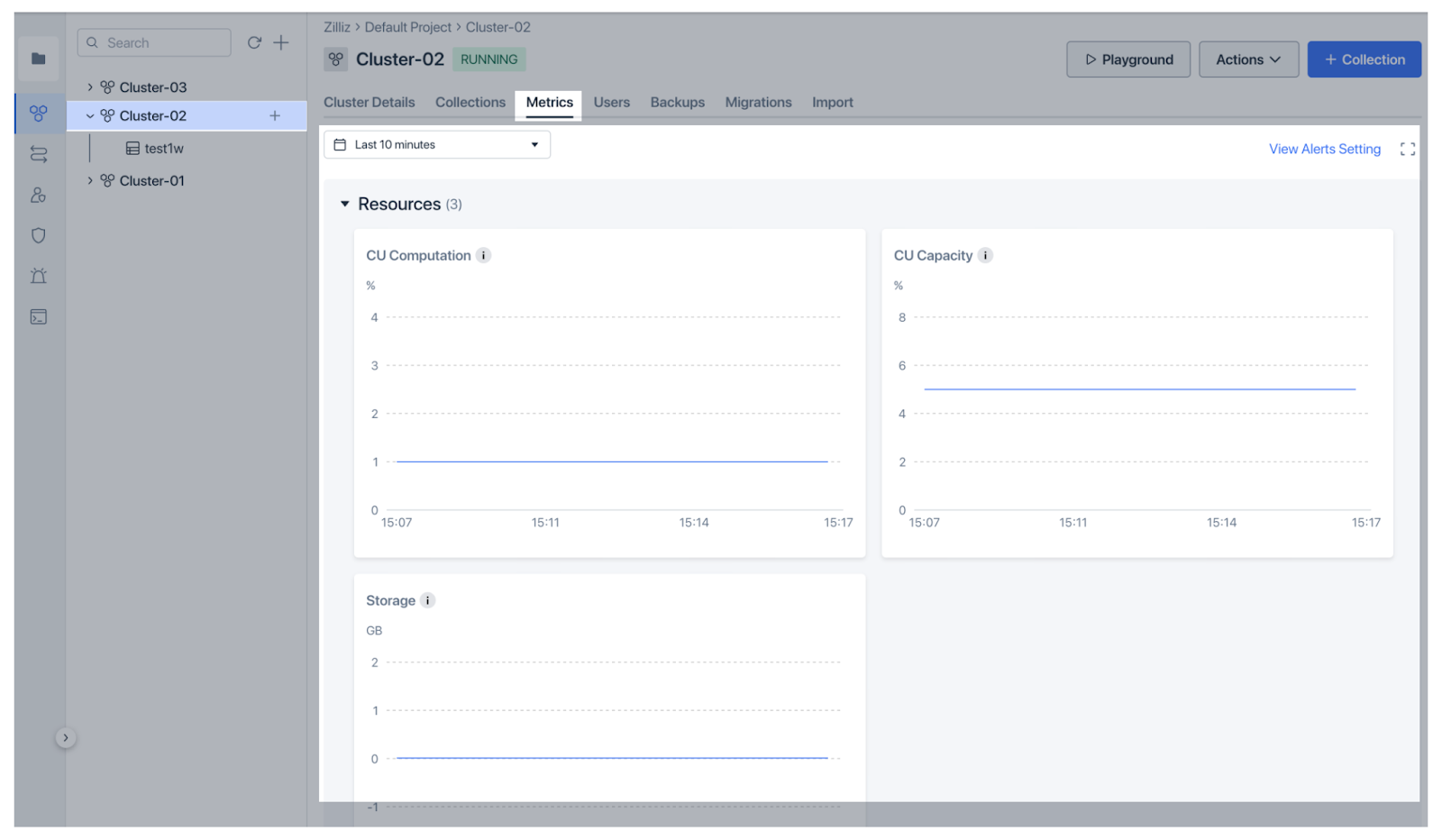 Figura: Métricas de monitorização da nuvem do Zilliz
Figura: Métricas de monitorização da nuvem do Zilliz
Figura: Métricas de monitorização da nuvem do Zilliz
Para detetar problemas precocemente, o Zilliz Cloud oferece Organization Alerts para questões de faturação e Project Alerts para factores operacionais como a utilização de CU e latência, com limites flexíveis e definições de gravidade.
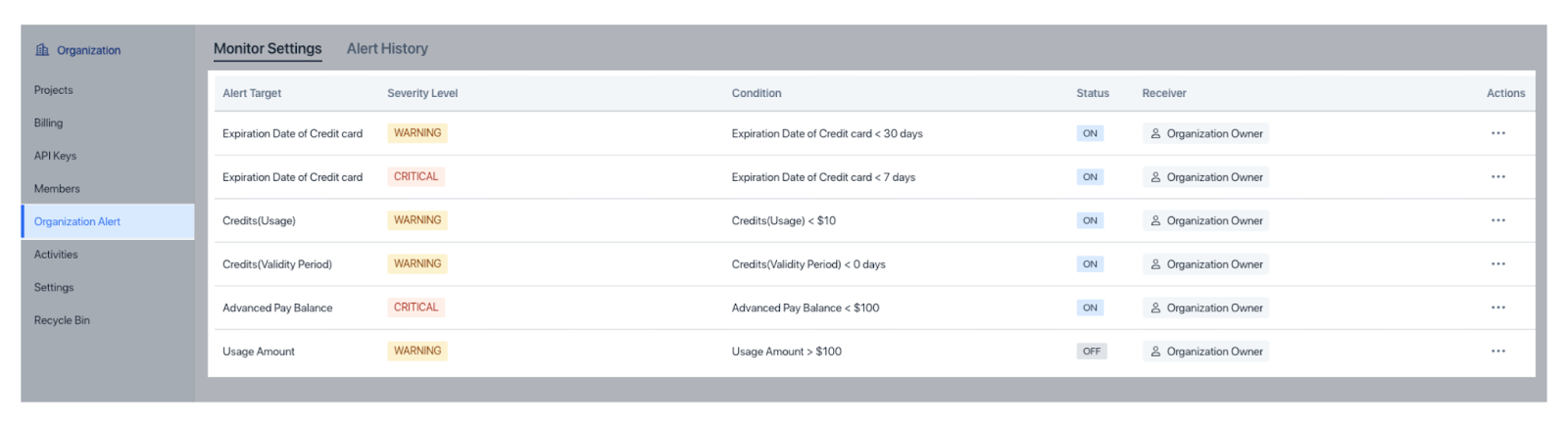 Figura: Alertas de organização no Zilliz Cloud
Figura: Alertas de organização no Zilliz Cloud
Figura: Alertas da organização no Zilliz Cloud
Figura: Alertas de projeto no Zilliz Cloud](https://assets.zilliz.com/Figure_3_Screenshot_of_Project_Alerts_1d2299185f.png)
Figura: Alertas de projeto no Zilliz Cloud
Principais caraterísticas
Monitorização em tempo real** para feedback instantâneo sobre o desempenho do cluster.
Dashboards personalizáveis** adaptados às suas principais métricas.
Alertas flexíveis** para deteção precoce de possíveis problemas.
Múltiplos canais de notificação** (e-mail, Slack, PagerDuty).
Dados históricos** para analisar tendências de desempenho para planeamento a longo prazo.
Conclusão
A observabilidade é uma abordagem para entender e manter a integridade de sistemas modernos e complexos. Utilizando métricas, registos e rastreios, as equipas podem garantir um desempenho fiável, resolver rapidamente problemas e melhorar as experiências dos utilizadores. À medida que os sistemas crescem e evoluem, a adoção de práticas recomendadas de observabilidade é importante para se manter à frente dos problemas e escalar com eficiência. Seja executando microsserviços distribuídos ou criando aplicativos orientados por IA com ferramentas como Milvus, a observabilidade fornece a visibilidade necessária para manter tudo funcionando sem problemas e de forma confiável.
FAQs sobre observabilidade
O que é observabilidade e por que ela é importante? A observabilidade é a prática de entender o estado interno de um sistema coletando e analisando dados como métricas, logs e rastreamentos. Ela é importante para diagnosticar problemas, monitorar o desempenho e manter a confiabilidade do sistema, especialmente em configurações modernas complexas, como microsserviços e aplicativos nativos da nuvem.
Como a observabilidade difere do monitoramento?** Enquanto o monitoramento rastreia métricas específicas para detetar problemas, a observabilidade vai mais fundo, fornecendo insights sobre o "porquê" por trás desses problemas. O monitoramento é como uma lista de verificação, enquanto a observabilidade é como uma investigação completa sobre o comportamento e o estado do sistema.
Quais são os principais componentes da observabilidade? Os três pilares da observabilidade são métricas (dados numéricos sobre o desempenho do sistema), logs (registos detalhados de eventos) e traces (caminhos percorridos pelos pedidos nos serviços). Estes combinados oferecem uma visão abrangente da saúde e do desempenho de um sistema.
Por que a observabilidade é essencial para sistemas distribuídos? Os sistemas distribuídos, como os criados em microsserviços ou plataformas de nuvem, têm vários componentes que interagem. A observabilidade ajuda a monitorar e depurar problemas entre esses componentes, facilitando o rastreamento de problemas de desempenho, a identificação de gargalos e a manutenção da integridade do sistema.
Recursos adicionais
- [Introduzindo o monitoramento abrangente e a observabilidade no Zilliz Cloud] (https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)
- O que é observabilidade?
- Por que a observabilidade é importante?
- Pilares principais da observabilidade
- Como funciona a observabilidade?
- Casos de uso da observabilidade
- Ferramentas e tecnologias para observabilidade
- Desafios da observabilidade
- Práticas recomendadas de observabilidade
- Observabilidade vs. Monitorização
- Observabilidade em Milvus e Zilliz Cloud: Acompanhar o desempenho do banco de dados vetorial
- Conclusão
- FAQs sobre observabilidade
- Recursos adicionais
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis