




DiDi Food가 Milvus로 라틴 아메리카 전역의 식료품 검색을 혁신한 방법

19% 감소
Milvus 의미 벡터 검색을 통해 달성한 결과 없음 쿼리에서
4% 증가
Milvus 기반 시맨틱 제품 매칭을 통한 장바구니 전환
쿼리의 15%
이제 기존 텍스트 검색을 보완하는 벡터 검색의 이점을 누리세요
1초 미만 벡터 검색
Milvus IVF_FLAT 인덱싱 및 내적 유사도 사용
DiDi Food 소개
전 세계 8억 명 이상의 사용자를 보유한 차량 호출 분야의 글로벌 리더 DiDi는 멕시코, 콜롬비아, 코스타리카를 포함한 라틴 아메리카 12개 주요 도시에서 식료품 배달 서비스인 DiDi Food를 출시했습니다. 기존 물류 네트워크와 실시간 최적화 역량을 활용해, 단 6개월 만에 월간 활성 사용자 200만 명, 일일 주문 50만 건, 2025년 1분기 GMV 1억 2천만 달러 이상이라는 놀라운 성장을 달성했습니다.
이 플랫폼은 30~45분 안에 신선 농산물과 생활 필수품을 배달하며, 제휴 매장은 각각 최대 3천만 개의 SKU를 제공합니다. 다국어 상호작용, 동적 가격 책정, 실시간 재고 관리를 갖춘 다양한 시장에서 운영되며, DiDi Food는 인상적인 비즈니스 기반을 구축했습니다. 하지만 규모가 커질수록 방대한 제품 카탈로그 전반에서 수백만 명의 고객이 정확히 필요한 것을 찾도록 돕는 일의 복잡성도 커졌습니다. 바로 이 지점에서 Milvus 벡터 데이터베이스가 이들의 검색 역량을 혁신하여, 여러 언어에서 작동하고 사람들이 실제로 검색하는 방식의 현실적인 혼란을 처리하는 의미론적 이해를 가능하게 했습니다.
검색 과제: 키워드 기반 Elasticsearch가 한계에 부딪힐 때
DiDi의 엔지니어링 팀은 키워드 기반 Elasticsearch 데이터베이스를 괴롭히는 한계에 직면했습니다. 단순한 철자 오류, 코드 스위칭, 또는 일반적이지 않은 설명은 종종 결과가 없는 페이지로 이어져 쇼핑 경험에 마찰을 만들었습니다.
높은 "결과 없음" 비율: 숨겨진 매출 손실
DiDi Food는 중요한 문제에 직면했습니다. 너무 많은 고객 검색이 결과를 전혀 반환하지 않아 쇼핑 세션 포기와 매출 손실로 이어졌습니다. DiDi의 검색 데이터에서 확인된 실제 사례는 이러한 실패를 유발하는 세 가지 주요 원인을 보여주었습니다.
오타와 철자 오류가 가장 흔한 원인이었습니다. 사용자는 "Jengibre"(생강)를 찾으면서 "Genjibr"라고 입력하거나, "HELADO"(아이스크림) 대신 "hedaho"를 입력하거나, "Kelloggs" 대신 "Kellongs"를 입력했습니다. Elasticsearch로 구동되는 기존 키워드 검색 시스템은 작지만 중요한 이러한 철자 차이를 메우지 못했습니다.
입력 방식 아티팩트는 또 다른 장벽을 만들었습니다. 모바일 키보드와 다양한 입력 시스템은 "wine" 대신 "𝑤𝑖𝑛𝑒", "banana" 대신 "𝑏𝑎𝑛𝑎𝑛𝑎", "chocolates" 대신 "𝑐ℎ𝑜𝑐𝑜𝑙𝑎𝑡𝑒𝑠"와 같은 특이한 Unicode 변형을 생성했습니다. 이러한 기술적 인코딩 문제 때문에 고객들은 분명히 재고가 있는 제품을 찾을 수 없었습니다.
혼합 언어 쿼리는 라틴 아메리카 시장에서 가장 큰 과제였습니다. 고객들은 자연스럽게 "apple juice orgánico" 또는 "leche sin lactosa"처럼 영어와 스페인어 용어를 결합해 검색했습니다. 지역별 차이는 이를 더 악화시켰습니다. 동일한 제품이 멕시코, 콜롬비아, 코스타리카 전역에서 서로 다른 이름으로 불릴 수 있었습니다.
각각의 실패한 검색은 좌절한 고객과 직접적인 매출 손실을 의미했습니다. 일일 주문 50만 건을 처리하는 플랫폼에서는 결과 없음 쿼리의 비율이 작더라도 상당한 비즈니스 영향으로 이어질 수 있습니다.
확장성과 다국어 복잡성
개별 검색 실패를 넘어, DiDi는 확장 능력을 위협하는 시스템적 과제에 직면했습니다. 수천만 개의 서로 다른 SKU 이름을 텍스트로 인덱싱하는 것은 여러 국가로 제품 카탈로그가 확장됨에 따라 스토리지 비용을 부풀리고 쿼리 성능을 저하시켰습니다.
다국어 복잡성은 혼합 언어 쿼리보다 더 깊었습니다. 멕시코, 콜롬비아, 코스타리카 및 기타 라틴 아메리카 시장에서 운영한다는 것은 동일한 제품이 각 지역에서 완전히 다른 이름을 가질 수 있음을 의미했습니다. 어떤 국가에서는 "Palta", 다른 국가에서는 "aguacate"—둘 다 아보카도를 가리킵니다. Elasticsearch로 구동되는 전통적인 키워드 시스템은 각 지역별 변형에 대해 별도의 인덱스를 유지해야 했고, 이는 스토리지 요구 사항을 몇 배로 늘리고 유지 관리를 복잡하게 만들었습니다.
문화적·언어적 미묘함은 추가적인 장벽을 만들었습니다. 지역 속어, 브랜드명 변형, 심지어 서로 다른 측정 체계(미터법 vs. 야드파운드법)까지 모두 검색 실패의 원인이 되었습니다. 키워드 기반 접근 방식은 수천 가지 지역별 변형을 수동으로 매핑해야 했는데, 이는 DiDi의 규모에서는 불가능한 일이었습니다.
DiDi의 엔지니어링 팀은 언어, 지역, 또는 고객이 자신의 니즈를 표현하는 방식과 관계없이 이러한 과제를 극복하고 사용자 쿼리 뒤의 의도를 이해할 수 있는 솔루션이 시급히 필요했습니다.
솔루션: Milvus로 시맨틱 검색 엔진 구축
Elasticsearch 기반 시스템은 단어를 의미 있는 개념이 아니라 개별 토큰으로 처리하기 때문에 언어 다양성과 사용자 입력 변동성에 어려움을 겪습니다. 그러나 벡터 데이터베이스는 벡터 임베딩을 통해 사용자 쿼리의 의미론적 의미와 의도를 이해하고, 언어나 오타와 관계없이 더 정확하고 관련성 높은 결과를 반환할 수 있습니다.
DiDi의 엔지니어링 팀은 다국어 임베딩 모델과 벡터 데이터베이스를 활용하여 시맨틱 검색 엔진을 구축하기로 결정했습니다. 임베딩 모델은 제품명과 설명, 그리고 사용자 쿼리를 고차원 공간에서 그 의미론적 의미를 나타내는 벡터 임베딩으로 변환하는 반면, 벡터 데이터베이스는 이러한 임베딩을 저장하고 쿼리 벡터와 제품 벡터 간의 거리를 계산하여 시맨틱 검색을 수행합니다.
신중한 평가 끝에, 그들은 서로 다른 언어의 텍스트를 동일한 고차원 수학적 공간에 매핑하기 때문에 jina-embeddings-v3를 주 임베딩 모델로 선택했습니다. 이는 "苹果"(중국어), "apple"(영어), 또는 "manzana"(스페인어)에 대한 쿼리가 거의 동일한 벡터를 생성하여, 복잡한 번역 시스템 없이도 정확한 교차 언어 매칭을 가능하게 한다는 뜻입니다. 오타가 있거나 음성적으로 유사한 입력조차 올바른 용어에 가까운 벡터를 생성합니다.
DiDi는 오픈소스 성숙도, 수십억 개 벡터까지 수평 확장할 수 있는 능력, 밀리초 단위 지연 시간, 검증된 고처리량 아키텍처, 풍부한 기능 세트 때문에 Milvus를 벡터 데이터베이스로 선택했습니다.
데이터 아키텍처 및 최적화 전략
DiDi의 엔지니어들은 매장 수준의 연관성을 유지하면서 3천만 개 SKU에 대해 저지연 벡터 검색을 지원하기 위해 몇 가지 핵심 최적화를 구현했습니다.
각 SKU-매장 조합에 대해 개별 벡터를 저장하는 대신, 동일한 품목명을 단일 벡터 항목으로 병합하고 해당 매장 ID를 배열에 저장했습니다. 이 접근 방식은 벡터 라이브러리를 3천만 개 항목에서 20만 개 고유 벡터로 줄여, 완전한 제품 커버리지를 유지하면서 메모리 사용량을 크게 절감했습니다.
팀은 Milvus에서
IVF_FLAT인덱스 구성을 선택하여 압축 복잡성보다 검색 정확도를 우선시했습니다. 사용자가 시스템에 쿼리하면 Milvus는 집계된 인덱스에서 가장 유사한 top-k 벡터를 반환하고, 이어서 빠른 매장 ID 필터를 적용해 쇼핑객의 현재 위치에서 구매 가능한 품목을 분리합니다.데이터 최신성을 위해 DiDi는 T+1 야간 업데이트 주기를 도입했습니다. 신규 및 업데이트된 SKU는 매일 배치 처리되고, GPU 클러스터를 사용해 다시 임베딩되며, Milvus 컬렉션을 갱신하도록 푸시됩니다. 이 전략은 방대한 제품 카탈로그 전반에서 데이터 최신성과 계산 효율성의 균형을 맞춥니다.
Milvus 스키마 설계
컬렉션 스키마는 식료품 검색에 대한 DiDi의 특정 요구 사항을 반영하며, 유연성과 성능의 균형을 맞춥니다:
item_name = FieldSchema(
name="item_name",
dtype=DataType.VARCHAR,
is_primary=True,
max_length=1000
)
vector = FieldSchema(
name="vector",
dtype=DataType.FLOAT_VECTOR,
dim=1024
)
shop_info = FieldSchema(
name='shop_info',
dtype=DataType.ARRAY,
element_type=DataType.INT64,
max_capacity=4096)
schema = CollectionSchema(
fields=[item_name, vector, shop_info],
description="jina-embeddings-v3를 사용한 임베딩",
enable_dynamic_field=True
)
prop = {"shards_num": 1}
try:
collection = Collection(name=collection_name, schema=schema, using='default', properties=prop,
dimension=1024)
except CollectionNotExistException:
return False
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024},
}
collection.create_index(field_name="vector", index_params=index_params)
utility.index_building_progress(collection_name)
return collection
GPU 가속 임베딩 생성
jina-embeddings-v3 모델을 사용한 초기 CPU 기반 임베딩 생성은 레코드당 5초라는 허용할 수 없는 지연 시간을 초래했습니다. 실시간 성능을 달성하기 위해 DiDi는 Luban 플랫폼에 GPU 인스턴스를 배포하여 쿼리당 임베딩 시간을 약 50밀리초로 단축했습니다:
from transformers import AutoModel
jina_model = AutoModel.from_pretrained("jinaai/jina-embeddings-v3", trust_remote_code=True)
jina_model.to("cuda")
def get_jina_embedding(item_name):
vec = []
try:
vec = jina_model.encode(item_name, task="text-matching")
except Exception as e:
print(e)
return vec
하이브리드 검색 파이프라인 아키텍처
기존 인프라를 완전히 대체하는 대신, DiDi는 확립된 Elasticsearch 시스템을 지능적으로 보완하는 방식으로 Milvus를 구현했습니다. 이중 파이프라인 설계는 Elasticsearch가 표준 키워드 쿼리를 처리하도록 하면서, Milvus가 복잡한 사례에 대한 의미론적 이해를 제공합니다.
검색 흐름은 다음 단계로 작동합니다:
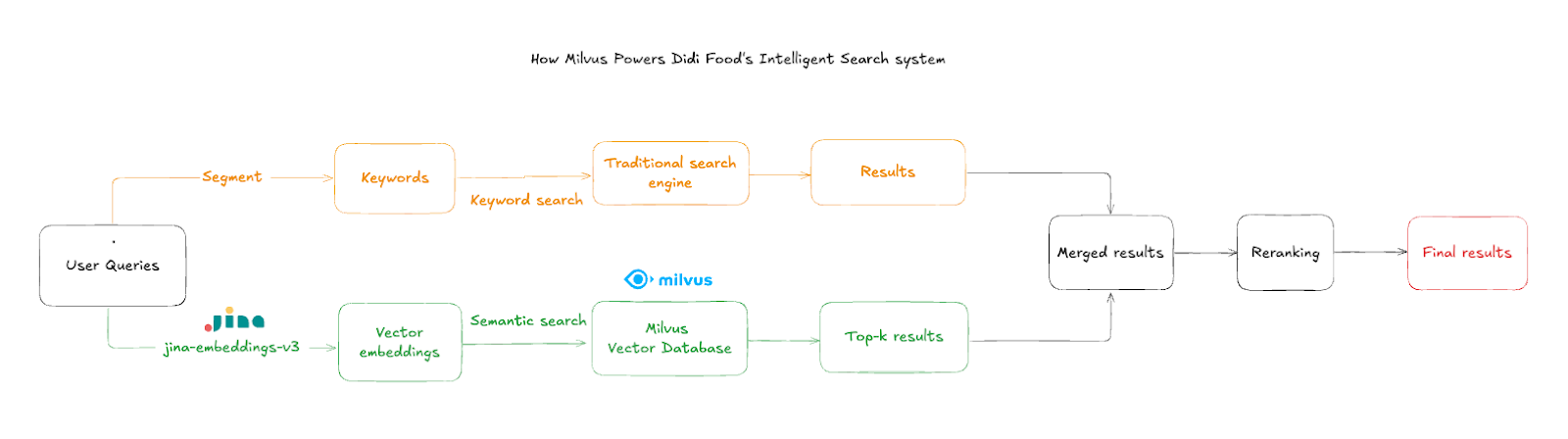
사용자 쿼리 입력: 고객은 제품명이나 설명을 입력하며, 오타나 혼합 언어가 포함되는 경우가 많습니다
텍스트 임베딩: 시스템은
jina-embeddings-v3를 사용해 입력을 약 50ms 내에 고차원 의미 벡터로 변환합니다유사도 검색: Milvus는 집계된 제품 벡터를 쿼리하여 가장 가까운 의미적 일치 항목을 찾습니다
매장 필터링: 결과는 현재 매장에서 재고가 있는 항목만 표시되도록 매장 ID별로 필터링됩니다
결과 병합: 기존 검색이 만족스럽지 못한 결과를 생성할 때 벡터 결과가 Elasticsearch 결과와 결합되어 더 풍부하고 완전한 검색 경험을 제공합니다
사용자 경험에 중요한 것은 매장 수준 필터링으로, 결과가 쇼핑객의 현재 위치 맥락에 속하도록 보장합니다. 시스템은 지능적인 결과 집계를 사용합니다—Elasticsearch가 만족스럽지 못한 결과를 생성할 때 Milvus의 의미적으로 관련 있는 항목이 응답을 보완합니다.
성능 결과와 실제 영향
DiDi의 Milvus 구현은 핵심 비즈니스 지표 전반에서 구체적인 개선을 제공했습니다.
이 시스템은 결과 없음 쿼리를 19% 감소시켰으며, 이는 이전에 실패했던 검색 다섯 건 중 거의 한 건이 이제 관련 제품을 반환한다는 의미로, 손실된 매출 기회를 직접 회복합니다. 하루 500,000건의 주문을 처리하는 플랫폼의 경우, 이 회복률은 상당한 비즈니스 가치를 나타냅니다.
벡터 검색은 전체 쿼리의 15%에서 트리거되며, 의미론적 이해가 핵심 쿼리 파이프라인에 부담을 주지 않으면서 가치를 더하는 정확한 순간에 기존 텍스트 검색을 보완합니다. 가장 중요한 점은 벡터로 재호출된 항목에 노출된 사용자들이 장바구니 추가 전환율에서 4% 증가를 보인다는 것으로, 검색 관련성 개선이 측정 가능한 구매 행동으로 이어진다는 점을 입증합니다.
이 시스템은 이제 영어, 스페인어, 중국어, 한국어, 일본어를 포함한 여러 언어의 쿼리를 처리하며, 특히 DiDi의 라틴아메리카 시장 입지에 중요한 스페인어에서 두드러진 정확도 향상을 보였습니다. 다국어 성능 테스트는 의미론적 이해의 힘을 보여주었습니다. 사용자가 영어 용어 "Liquid Foundation," 중국어 "液体妆前乳," 또는 스페인어 "Base de maquillaje líquida"를 입력하든 "Liquid Foundation" 검색은 동일하게 잘 작동합니다. 이 시스템은 기존 키워드 방식이라면 완전히 막혔을 언어 간 격차를 이어줍니다.
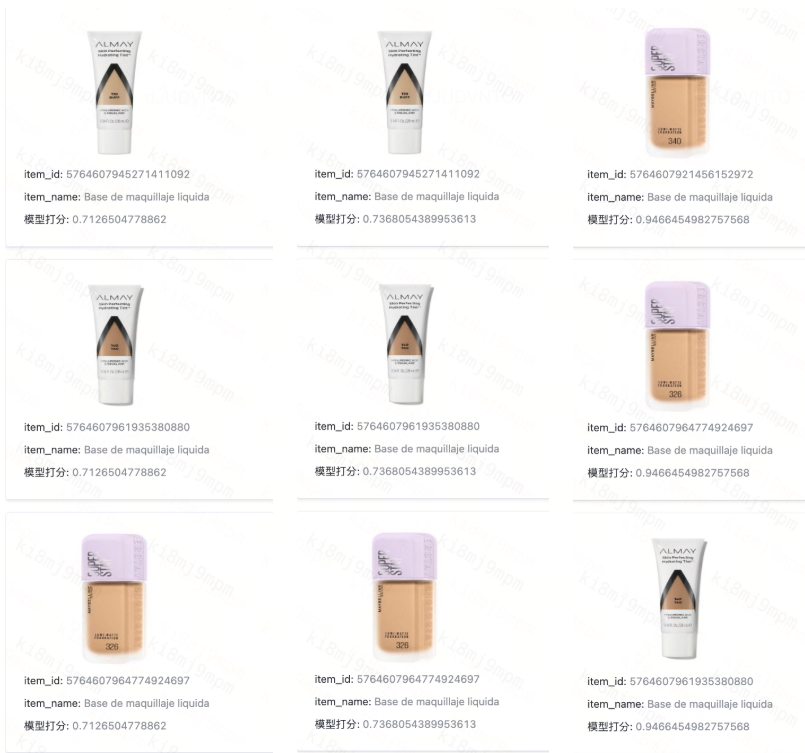
그림: 사용자가 영어 용어 "Liquid Foundation," 중국어 "液体妆前乳," 또는 스페인어 "Base de maquillaje líquida"를 입력하든 "Liquid Foundation" 검색은 동일하게 잘 작동합니다.
복잡한 제품 쿼리는 벡터 검색의 맥락 이해 능력을 보여줍니다. 사용자가 "Redac PalancaPara WC Blanca"(흰색 변기 물내림 레버)를 검색할 때, 벡터 시스템은 복합적인 기술 용어에도 불구하고 쿼리를 정확하게 매칭하는 반면, 기존 검색은 여러 단어로 된 제품 설명을 파싱하는 데 실패합니다.
이러한 성과는 더 매끄러운 쇼핑 경험, 더 높은 고객 만족도, 그리고 신선식품 이커머스 시장에서의 확실한 경쟁 우위로 이어집니다.
향후 로드맵: 차세대 검색 기능
이 탄탄한 기반을 바탕으로 DiDi와 Milvus는 다음 개발 단계에서 여러 고급 기능을 협업하고 있습니다.
실시간 카탈로그 동기화는 스트리밍 업데이트를 통해 재고 변경과 검색 가능한 데이터 간의 지연 시간을 줄여, 사용자가 실제로 구매할 수 없는 제품을 보지 않도록 보장합니다. 행동 신호 통합은 벡터 유사도를 사용자 이력, 선호도, 맥락 신호와 결합하여 시간이 지날수록 개선되는 초개인화 추천을 제공합니다.
고급 하이브리드 검색과 리랭킹은 아마도 가장 흥미로운 발전일 것입니다. 이 시스템은 가격, 평점, 프로모션, 재고 수준을 포함한 비즈니스 지표를 의미론적 관련성과 결합하여 각 개별 쇼퍼에게 진정으로 최적의 추천을 제공합니다.
향상된 다국어 지원은 DiDi가 새로운 시장에 진출함에 따라 언어 범위를 확장하고 지역 방언 처리를 개선할 것입니다. 동적 임베딩 최적화는 실제 사용자 상호작용 패턴을 기반으로 임베딩 품질을 향상시키는 지속 학습 메커니즘을 구현하여, 사용할수록 점점 더 똑똑해지는 검색 시스템을 만들어낼 것입니다.
지속적인 혁신을 통해 DiDi는 식료품 검색 경험을 재정의하며, 모든 쇼퍼가 매번 정확히 필요한 것을 찾을 수 있도록 보장하고 있습니다.
결론
DiDi Food가 Milvus와 함께한 여정은 의미론적 검색이 단순한 기술적 업그레이드 이상임을 보여줍니다. 이는 사용자가 대규모 제품 카탈로그와 상호작용하는 방식을 근본적으로 재구상하는 것입니다. 세심한 데이터 아키텍처, 적절한 기술 선택, 사용자 경험에 대한 흔들림 없는 집중을 결합함으로써, 이들은 언어와 문화를 넘어 의도를 진정으로 이해하는 검색 시스템을 만들어냈습니다.
그 결과는 이러한 접근 방식을 입증합니다. 불만을 느끼는 사용자는 줄고, 성공적인 구매는 늘며, 고객이 자신의 필요를 어떤 방식으로 표현하든 작동하는 쇼핑 경험이 제공됩니다. DiDi의 월간 사용자 200만 명에게 이는 자신에게 가장 자연스럽게 느껴지는 언어로, 필요할 때마다 필요한 것을 꾸준히 찾을 수 있음을 의미합니다.
이 성공 사례는 혁신적인 기업들이 대규모로 시맨틱 이해를 도입할 때 무엇이 가능해지는지를 보여줍니다. DiDi가 라틴 아메리카 전역으로 계속 확장함에 따라, Milvus 기반 검색 아키텍처는 지속적인 혁신과 사용자 만족을 위한 견고한 기반을 제공합니다. 기술은 제대로 작동하고, 비즈니스 성과는 명확하며, 사용자 경험 개선은 실질적입니다—훌륭한 엔지니어링이 제공해야 할 바로 그 가치입니다.