




Vector Lakebase를 만든 이유: AI를 위한 비정형 데이터 아키텍처의 재고찰
최근 우리는 순수 벡터 데이터베이스 시스템에서 AI 워크로드를 위한 통합형 레이크 네이티브 데이터 기반으로 진화한 Zilliz Cloud의 다음 단계인 Zilliz Vector Lakebase를 출시했습니다. 이 발표는 많은 관심을 받았습니다. 동시에 Zilliz가 어디로 향하고 있는지에 대한 질문도 거의 즉시 제기되었습니다.
Zilliz가 벡터 데이터베이스에서 멀어지고 있는 것인가? 또는 더 직접적으로 말하자면: 벡터 데이터베이스는 이미 구식이 되어가고 있는 것인가?
왜 이런 질문들이 나왔는지 이해합니다. 수년 동안 Zilliz는 프로덕션에 바로 사용할 수 있는 벡터 데이터베이스 시스템(오픈소스 Milvus와 완전 관리형 Zilliz Cloud)을 구축하는 회사로 알려져 왔습니다. 그래서 우리가 AI를 위한 레이크 네이티브 데이터 기반으로의 진화를 이야기하기 시작했을 때, 일부 사람들은 이것이 방향 전환을 의미하는지 자연스럽게 궁금해했습니다.
짧은 답은 NO입니다. 절대 아닙니다. 오히려 Vector Lakebase는 벡터 데이터베이스가 성공한 이후에 어떤 일이 일어나는지에 대한 우리의 답입니다.
지난 몇 년 동안 벡터 데이터베이스는 AI 스택의 기반 인프라 계층 중 하나가 되었습니다. 도입 속도는 거의 10년 전 Milvus를 시작했을 때 우리가 상상했던 것보다 훨씬 빨랐습니다. 이 범주는 실재하며, 의미 기반 검색에 대한 필요성은 더욱 중요해지고 있습니다.
하지만 우리에게 또 하나 분명해진 사실이 있습니다: 벡터 검색은 더 이상 문제의 전부가 아닙니다.
AI 시스템이 정적인 어시스턴트에서 지속적으로 실행되는 에이전트로 이동하면서, 기업들은 비정형 데이터 인프라에서 더 넓은 범위를 요구하고 있습니다. 그들은 단지 정보를 검색할 수 있는 시스템만을 원하는 것이 아닙니다. 데이터를 개선하고, 재구성하고, 분석하고, 정제하며, 그 개선 사항을 다시 프로덕션에 반영할 수 있는 시스템을 원합니다. 이것은 아키텍처를 바꿉니다.
이러한 변화는 인프라 역사에서 이전에 있었던 한 주기를 떠올리게 합니다: 모바일 인터넷 시대의 데이터베이스 진화입니다. 세부 사항은 다르지만 패턴은 익숙합니다. 새로운 종류의 애플리케이션이 새로운 종류의 데이터 압력을 만들어냅니다. 1세대 인프라는 즉각적인 서빙 문제를 해결합니다. 그런 다음 데이터가 증가하면서 아키텍처는 확장되어야 합니다.
저는 벡터 데이터베이스가 이제 그 다음 단계에 들어서고 있다고 생각합니다.
모바일 인터넷은 이미 이 주기를 한 번 겪었습니다
2010년경, 모바일 애플리케이션이 폭발적으로 증가하면서 MongoDB는 그 시기를 대표하는 인프라 제품 중 하나가 되었습니다.
이유는 간단했습니다. 모바일 애플리케이션은 사용자 이벤트, 소셜 활동, 디바이스 텔레메트리, 행동 신호, 제품 로그와 같은 막대한 양의 반정형 데이터를 생성했습니다. 이들 중 어느 것도 당시 대부분의 팀이 사용하던 관계형 데이터베이스 패턴에 깔끔하게 들어맞지 않았습니다. 제품 팀은 빠르게 출시하고 있었고, 스키마는 끊임없이 바뀌었으며, 첫 번째 문제는 단순히 애플리케이션 속도를 늦추지 않고 데이터를 받아들이는 것이었습니다. MongoDB는 그 즉각적인 문제를 매우 잘 해결했습니다: 먼저 데이터를 수집하는 것. 구조화와 분석은 나중에 할 수 있었습니다.

몇 년 후, 업계는 다른 질문을 하기 시작했습니다. 이 모든 데이터가 존재하게 된 이후, 기업은 그것을 실제로 어떻게 활용할 수 있을까? 그 변화는 Snowflake와 Redshift 같은 현대적 데이터 웨어하우스의 부상을 촉진했습니다. 초점은 운영 스토리지에서 분석적 인사이트로 이동했습니다. 기업들은 BI 보고서, 사용자 코호트, 어트리뷰션, 예측, 성장 분석을 원했습니다. 데이터는 더 이상 단순한 운영 부산물이 아니라 비즈니스 자산이 되었습니다.
그러자 또 다른 병목이 나타났습니다.
트랜잭션 시스템과 분석 시스템 간의 분리는 점점 더 고통스러워졌습니다. OLTP와 OLAP 환경 사이의 데이터 파이프라인은 취약하고, 비용이 많이 들며, 운영적으로 소모적이었습니다. 동일한 데이터셋이 여러 시스템에 반복적으로 복사되었고, 종종 동기화 지연과 미묘한 불일치가 발생했습니다.
그것이 Lakehouse 아키텍처가 등장하게 된 환경이었습니다. Databricks, Iceberg, Hudi 및 관련 시스템들은 모두 동일한 기본 아이디어로 수렴했습니다. 데이터의 단일 논리적 사본이 시스템 간 끝없는 이동을 요구하지 않고도 여러 계산 모델을 지원해야 한다는 것입니다.
돌이켜보면, 그 진전은 거의 필연적으로 느껴집니다. 하지만 당시에는 그 어느 것도 명백하지 않았습니다. MongoDB의 부상이 Snowflake를 예측하지는 않았습니다. Snowflake가 Lakehouse를 예측하지도 않았습니다. 각각의 전환은 이전 세대의 인프라가 대규모로 성공한 뒤 새로운 종류의 제약을 드러냈기 때문에 나타났습니다.
그 패턴이 중요한 이유는 AI 인프라가 점점 비슷한 경로를 따르고 있는 것처럼 느껴지기 때문입니다.
검색은 첫 번째 문제를 해결했지, 최종 문제를 해결한 것은 아니었습니다
2023년에 대규모 언어 모델이 주류로 채택되기 시작했을 때, 벡터 데이터베이스는 가장 이른 시기에 두각을 나타낸 인프라 범주 중 하나가 되었습니다. 그 이유는 실용적이었습니다. RAG 시스템에는 임베딩을 저장하고 의미 기반 검색을 수행할 수 있는 네이티브한 방법이 필요했습니다. 대부분의 전통적인 데이터베이스는 고차원 벡터 검색, ANN 인덱스, 하이브리드 검색, 그리고 대규모 저지연 필터링을 위해 설계되지 않았습니다.
여러 면에서, 벡터 데이터베이스는 MongoDB가 앞서 해결했던 것과 같은 종류의 문제를 해결했습니다. 새로운 애플리케이션 패턴이 새로운 데이터 추상화를 만들어냈고, 개발자들은 이를 지원할 수 있는 인프라를 필요로 했습니다. 이번에 그 추상화는 의미 표현이었습니다. 즉, 신경망 모델이 비정형 데이터로부터 생성한 임베딩이었습니다.
그 첫 번째 채택 단계는 매우 빠르게 일어났습니다. 하지만 불과 몇 년 후, 고객들로부터 듣는 질문은 훨씬 더 복잡해졌습니다. 그들은 더 이상 벡터를 효율적으로 검색하는 방법만 묻지 않습니다. 그들은 이렇게 묻습니다:
- 학습 데이터를 어떻게 지속적으로 중복 제거하고 정제할 수 있을까?
- 클러스터링 및 품질 문제를 위해 수십억 개의 임베딩을 어떻게 분석할 수 있을까?
- 멀티모달 데이터셋에서 드리프트, 편향 또는 중복성을 어떻게 식별할 수 있을까?
- 에이전트 실행 이력을 어떻게 추적하고 최적화할 수 있을까?
- 모델이 진화함에 따라 데이터를 어떻게 재처리하고 개선할 수 있을까?
- 모든 컴퓨트를 항상 실행 상태로 유지하지 않고도 콜드 데이터를 어떻게 검색할 수 있을까?
- Iceberg, Lance, Parquet 및 객체 스토리지에 이미 존재하는 데이터를 여러 AI 워크로드에 어떻게 사용할 수 있을까?
이것들은 더 이상 순수한 검색 문제가 아닙니다. 여기에는 대규모 오프라인 처리, 반복적인 발견 워크플로, 데이터 거버넌스, 분석적 탐색, 그리고 온라인 시스템과 오프라인 계산 사이의 지속적인 피드백 루프가 필요합니다. 점점 더, 우리는 고도화된 AI 팀들 사이에서 중요한 사실을 발견했습니다: 병목은 더 이상 모델 성능만이 아니었습니다. 그것은 반복 속도였습니다.
한 가지 경험은 이를 고통스러울 정도로 분명하게 보여주었습니다. 우리는 팀들이 대규모 벡터 데이터셋을 재처리하려고 애쓰는 모습을 보았습니다. 임베딩 재클러스터링, 중복 제거, 인덱스 재생성, 전체 코퍼스 재임베딩 등이었습니다. 어떤 경우에는 10억 개의 벡터를 한 시스템에서 다른 시스템으로 옮기는 것만으로도 며칠이 걸릴 수 있었습니다. 몇 시간이 아니라. 며칠이었습니다.
한편, 선도적인 AI 팀 내부의 반복 주기는 정반대 방향으로 움직이고 있습니다. 연구자들은 지속적으로 실험하고 싶어 합니다. 데이터 엔지니어들은 데이터셋을 더 빠르게 정리, 평가, 갱신해야 한다는 압박을 받고 있습니다. 모델은 개선됩니다. 임베딩 모델은 바뀝니다. 에이전트는 매일 새로운 트레이스를 생성합니다. 하지만 그 아래의 인프라 스택은 비정형 데이터에 대한 지속적인 정제 루프를 위해 설계되지 않았습니다.
그 지점에서 우리는 업계가 문제를 너무 좁게 규정하고 있다고 생각하기 시작했습니다.
비정형 데이터 인프라는 단순한 검색 계층이 아닙니다. 그것은 지속적으로 작동하는 시스템이 되어가고 있습니다.
검색 시스템에서 지속적 시스템으로: CS/CD
내부적으로 우리는 이 아키텍처를 서빙과 발견 사이의 지속적인 루프로 설명하기 시작했습니다. 시간이 지나면서, 우리는 이를 CS/CD: Continuous Serving and Continuous Discovery라고 부르기 시작했습니다.
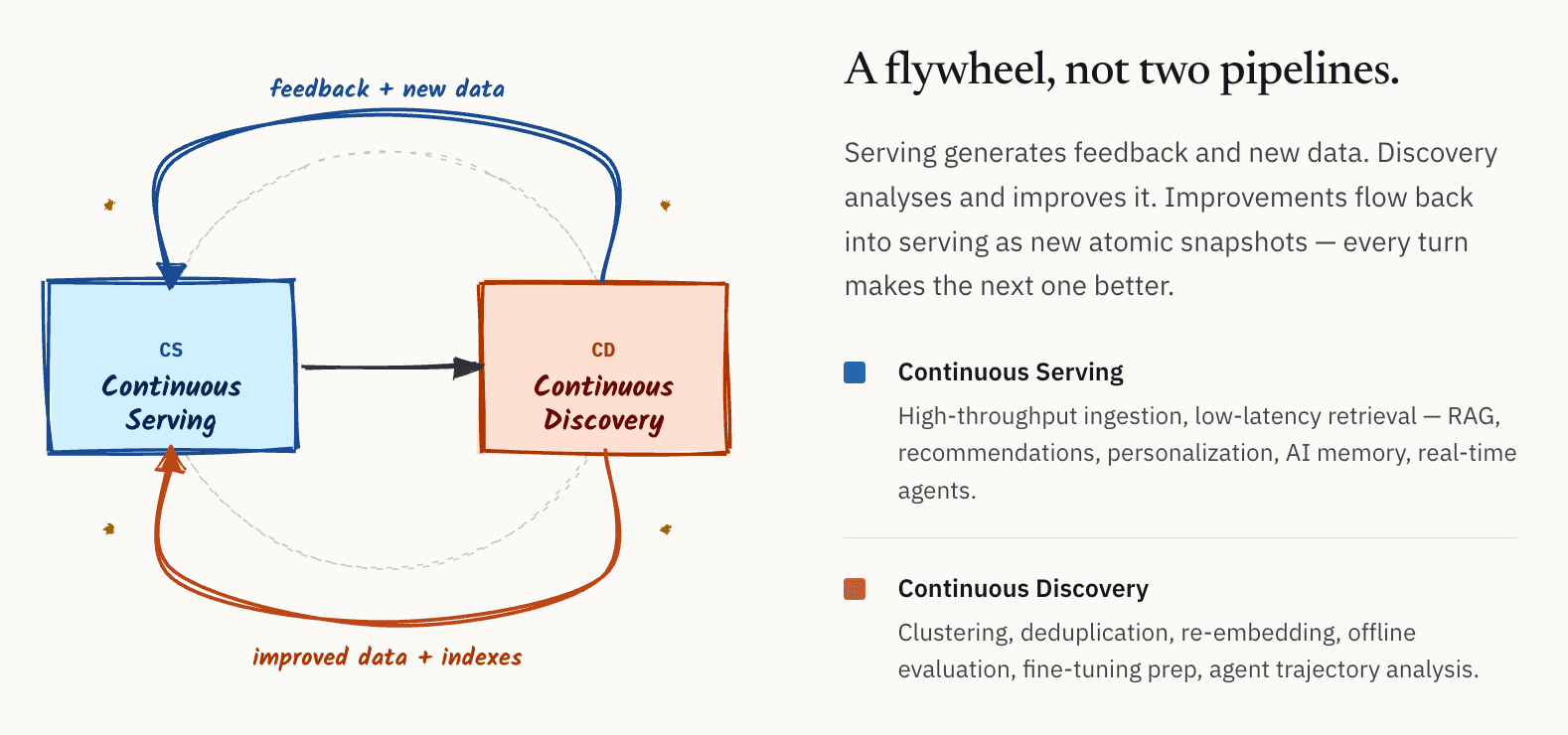
개념적으로 아이디어는 단순합니다.
- 한쪽에는 서빙 계층이 있습니다: 온라인 RAG 시스템, 추천 시스템, 개인화, AI 메모리, 실시간 에이전트를 위한 고처리량 수집과 저지연 검색.
- 다른 한쪽에는 발견 계층이 있습니다: 클러스터링, 중복 제거, 재임베딩, 오프라인 평가, 품질 분석, 모델 파인튜닝 준비, 에이전트 궤적 분석.
중요한 점은 이것들이 독립적인 워크플로가 아니라는 것입니다. 이들은 플라이휠을 형성합니다. 서빙 시스템은 지속적으로 피드백과 새로운 데이터를 생성합니다. 발견 시스템은 그 데이터를 분석하고 개선합니다. 더 나은 임베딩, 더 깨끗한 데이터셋, 개선된 인덱스, 정제된 메타데이터를 포함한 결과적 개선 사항은 다시 서빙 계층으로 흘러 들어갑니다.
모든 반복은 다음 반복을 개선해야 합니다. 적어도 이론상으로는 그렇습니다.
실제로는 대부분의 조직이 여전히 이 루프를 효율적으로 운영하지 못합니다. 기본 인프라가 여전히 파편화되어 있기 때문입니다.
오늘날 어떤 팀이 프로덕션 벡터 데이터에 대해 대규모 오프라인 처리를 수행하려 한다면, 일반적인 워크플로는 여전히 고통스러울 만큼 수작업에 의존합니다. 먼저 벡터 데이터베이스에서 레이크 또는 배치 환경으로 데이터를 내보내야 합니다. 인덱스는 대개 재사용할 수 없습니다. 동기화 파이프라인은 취약해집니다. 증분 업데이트는 어렵습니다. 처리된 결과는 결국 서빙 시스템으로 다시 가져와야 하며, 새 데이터와 새 인덱스 간에 원자적 일관성 보장이 없는 경우가 많습니다.
그 결과 워크플로는 느리고, 취약하며, 비용이 많이 듭니다. 그리고 유지 비용이 너무 크기 때문에 많은 조직은 단순히 지속적인 발견을 하지 않습니다. 데이터는 그곳에 남아 검색은 가능하지만, 대체로 탐색되지 않은 상태로 머뭅니다.
이는 점점 더 OLTP와 OLAP 시스템 사이의 역사적 격차를 떠올리게 했습니다. 다만 이제 파편화는 온라인 시맨틱 검색과 오프라인 비정형 데이터 처리 사이에 존재합니다.
기존 아키텍처가 결국 한계에 부딪히는 이유
우리가 점점 더 확신하게 된 한 가지는 현재 인프라 스택의 어느 한쪽도 틀리지 않았다는 것입니다.
벡터 데이터베이스와 Lakehouse 시스템은 모두 중요한 문제를 해결합니다. 문제는 각 아키텍처가 새롭게 부상하는 워크로드의 절반에만 최적화되어 있었다는 점입니다.
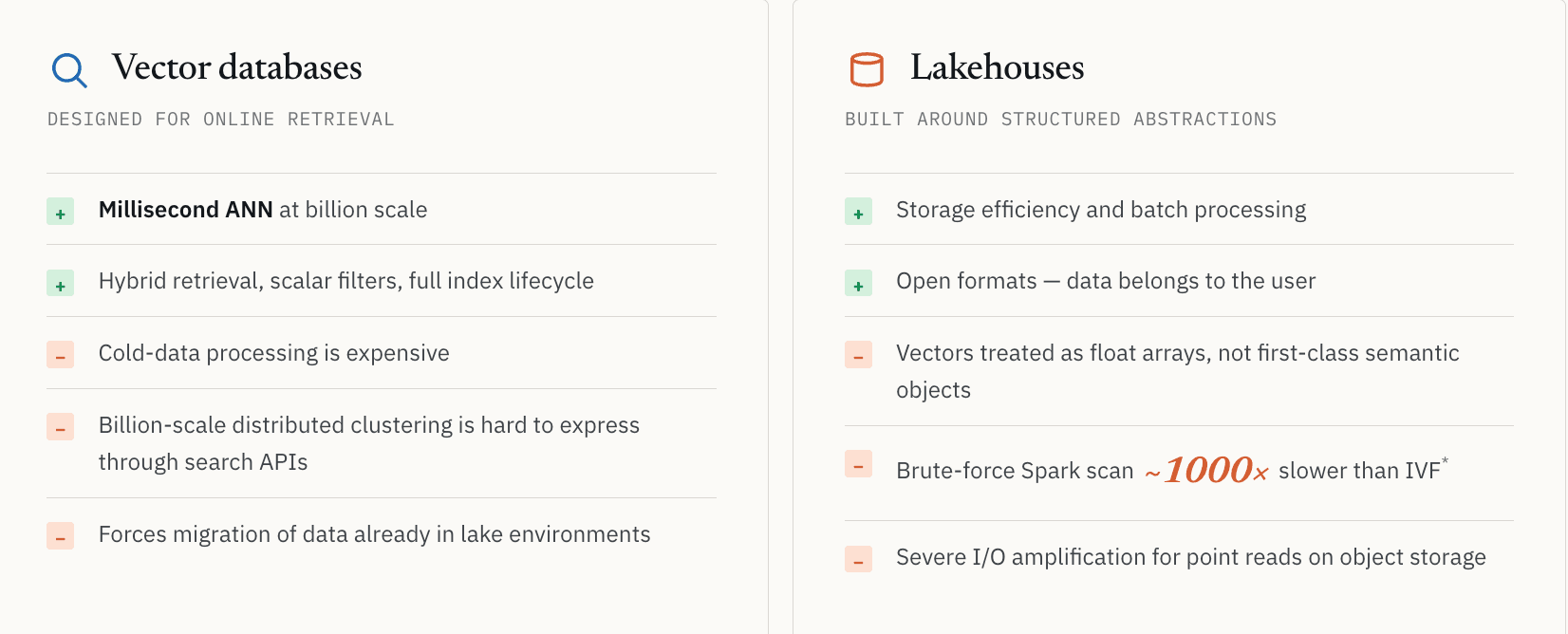
벡터 데이터베이스는 주로 온라인 검색을 위해 설계되었습니다.
오픈소스 Milvus를 예로 들어보겠습니다. Milvus는 대규모 벡터 검색을 매우 잘 해결합니다. 하지만 워크로드가 서빙을 넘어 대규모 발견으로 이동하면 자연스러운 아키텍처적 경계가 나타납니다.
콜드 데이터 처리는 비용이 많이 듭니다. 십억 규모의 분산 클러스터링은 온라인 검색 API를 통해 표현하기 어렵습니다. 많은 시스템은 데이터를 쿼리 가능하게 유지하려면 온라인 인프라에 계속 로드되어 있어야 한다고 가정합니다. 이미 방대한 비정형 데이터셋을 레이크 환경에 저장하고 있는 기업들은 모든 것을 전용 검색 시스템으로 옮기라는 요구를 받을 때 마이그레이션 비용과 거버넌스 파편화를 겪게 됩니다.
이것들은 구현상의 버그가 아닙니다. 저지연 온라인 검색에 최적화한 결과입니다.
Lakehouse는 스토리지 효율성과 배치 처리를 해결하지만, 구조화된 데이터 추상화를 중심으로 설계되었습니다
반대 접근법, 즉 Lakehouse 측에서 출발하는 방식은 또 다른 트레이드오프를 가져옵니다.
Lakehouse는 스토리지 효율성과 배치 처리를 우아하게 해결합니다. 하지만 구조화된 데이터 추상화를 중심으로 설계되었습니다. 대부분의 레이크 아키텍처에서 벡터는 여전히 일급 시맨틱 객체가 아니라 긴 부동소수점 배열로 취급됩니다. Parquet 같은 파일 형식은 ANN 인덱스, 역인덱스 또는 저지연 시맨틱 검색 경로를 중심으로 설계된 것이 아닙니다.
우리는 분자 유사도 검색을 수행하던 한 제약 고객 사례에서 이를 직접 확인했습니다. 레이크 데이터 전체를 brute-force Spark 스캔으로 처리하는 방식은 IVF 기반 검색을 사용하는 인덱싱된 벡터 검색보다 대략 1000배 느렸습니다. 정확한 수치는 데이터 분포, 인덱스 파라미터, 하드웨어에 따라 달라지지만, 교훈은 변하지 않습니다. 적절한 인덱스가 없으면 많은 시맨틱 워크로드는 경제적으로 실용적이지 않습니다.
또한 더 기본적인 스토리지 문제도 있습니다. 객체 스토리지는 검색 지향 워크로드에서 심각한 I/O 증폭을 일으킬 수 있습니다. 시맨틱 검색은 종종 소수의 ID를 찾아내지만, 애플리케이션은 여전히 그 ID 뒤에 있는 전체 레코드를 필요로 합니다. 전통적인 컬럼형 포맷에서는 몇 개의 작은 레코드를 검색하기 위해 큰 스토리지 블록을 읽어야 할 수 있습니다. 이는 스캔에는 괜찮습니다. 하지만 저지연 서빙에는 맞지 않습니다.
시간이 지나면서 우리의 결론은 피하기 어려워졌습니다. 업계는 벡터 데이터베이스와 레이크 아키텍처 중 하나를 선택해야 해서는 안 됩니다. 검색과 대규모 발견이 동일한 운영 시스템의 네이티브 구성요소가 되는 아키텍처가 필요합니다.
Vector Lakebase가 의미하는 것
그 깨달음은 우리가 이제 Vector Lakebase라고 부르는 방향으로 우리를 이끌었습니다. 핵심 아이디어는 “벡터 데이터베이스에 데이터 레이크를 더한 것”이 아닙니다. 저는 그런 프레이밍이 더 깊은 아키텍처적 핵심을 놓친다고 생각합니다.
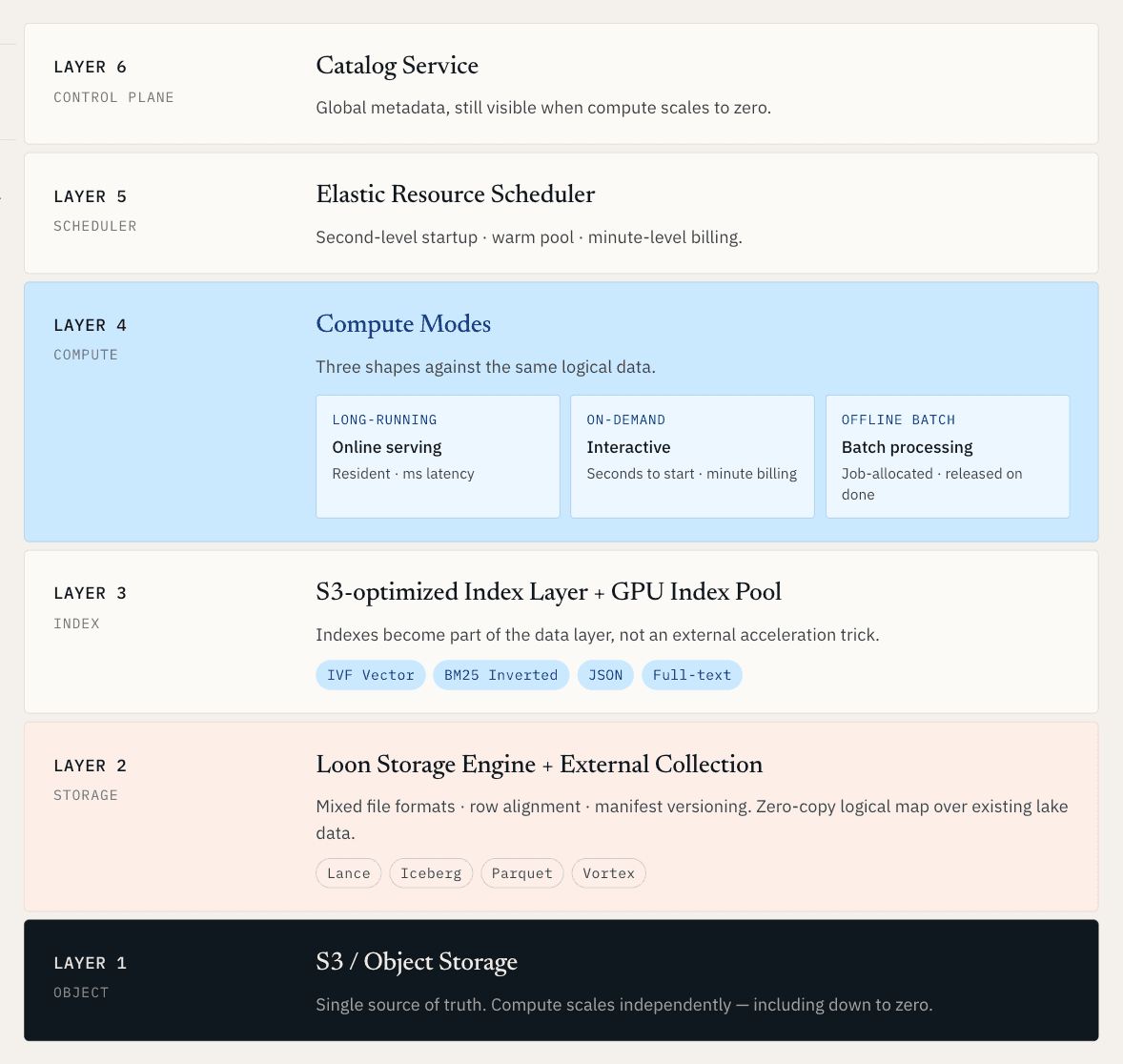
목표는 비정형 데이터를 위한 통합 운영 계층을 만드는 것입니다. 이 계층에서는 온라인 서빙, 오프라인 발견, 탄력적 컴퓨트가 모두 동일한 논리적 데이터 기반을 대상으로 동작합니다.
원시 데이터의 경우, 이는 벡터, 문서, 메타데이터, 로그, 인덱스가 레이크 네이티브 스토리지에서 함께 관리된다는 뜻입니다. 이미 Iceberg, Lance, Parquet 또는 객체 스토리지에 존재하는 데이터의 경우, 전체 마이그레이션을 강제하지 않고도 시스템이 해당 데이터를 매핑하고 인덱싱할 수 있다는 뜻입니다.
이 요구사항에서 출발하면, 아키텍처는 여러 어려운 문제를 동시에 해결해야 합니다. 컴퓨트는 스토리지와 독립적으로 확장되어야 합니다. 인덱스는 외부 가속 트릭이 아니라 데이터 계층의 일부가 되어야 합니다. 새로운 데이터와 새로운 인덱스는 일관된 스냅샷으로 함께 게시되어야 합니다. 그리고 기존 레이크 데이터는 또 다른 복사본을 만들지 않고도 검색 가능해져야 합니다.
이 아이디어들은 단순하게 들립니다. 사람들이 벡터 데이터베이스에서 기대하는 성능을 유지하면서 이를 작동하게 만드는 것이 어려운 부분입니다. 바로 여기에서 저수준 엔지니어링 결정들이 중요해지기 시작합니다.
스토리지와 컴퓨트를 분리하는 비용과 우리가 이를 해결하는 방식
스토리지-컴퓨트 분리는 CS/CD 루프에 필요하지만, 공짜는 아닙니다.
느린 콜드 스타트
컴퓨트가 0까지 축소될 수 있다면, 온디맨드 또는 오프라인 워크플로의 첫 번째 쿼리는 순수한 콜드 데이터를 마주할 수 있습니다. 노드에는 로컬 인덱스도, 워밍된 캐시도, 상주 데이터도 없습니다. 모든 것이 객체 스토리지에서 와야 합니다.
작은 데이터셋의 경우 이는 관리 가능합니다. 하지만 대규모 벡터 워크로드에서는 빠르게 받아들일 수 없는 수준이 됩니다. 10억 개의 768차원 벡터를 생각해 보십시오. 전통적인 HNSW 인덱스는 약 340 GB가 될 수 있습니다. S3에서 그 전체 인덱스를 가져오는 데 4분 이상 걸릴 수 있습니다. 검색을 시작하기 전에 4분을 기다리고 싶어 하는 사람은 없습니다.
우리의 해법은 콜드 경로를 훨씬 더 작게 만드는 것입니다. RaBitQ 스타일의 1+3 bit 양자화를 사용하면, 대략 340 GB인 인덱스를 약 13 GB로 압축할 수 있습니다. 검색은 두 단계로 실행됩니다. 첫 번째 단계는 대략 85~90%의 재현율을 유지하면서 데이터 크기를 원본의 약 30분의 1로 줄이기 위해 1-bit 표현을 사용해 대략적인 필터링을 수행합니다. 두 번째 단계는 1+3 bit 표현을 사용해 결과를 재정렬하고 정교화하여 약 95%의 재현율에 도달합니다. 이를 통해 콜드 스타트는 몇 분에서 대략 5~10초로 줄어듭니다.
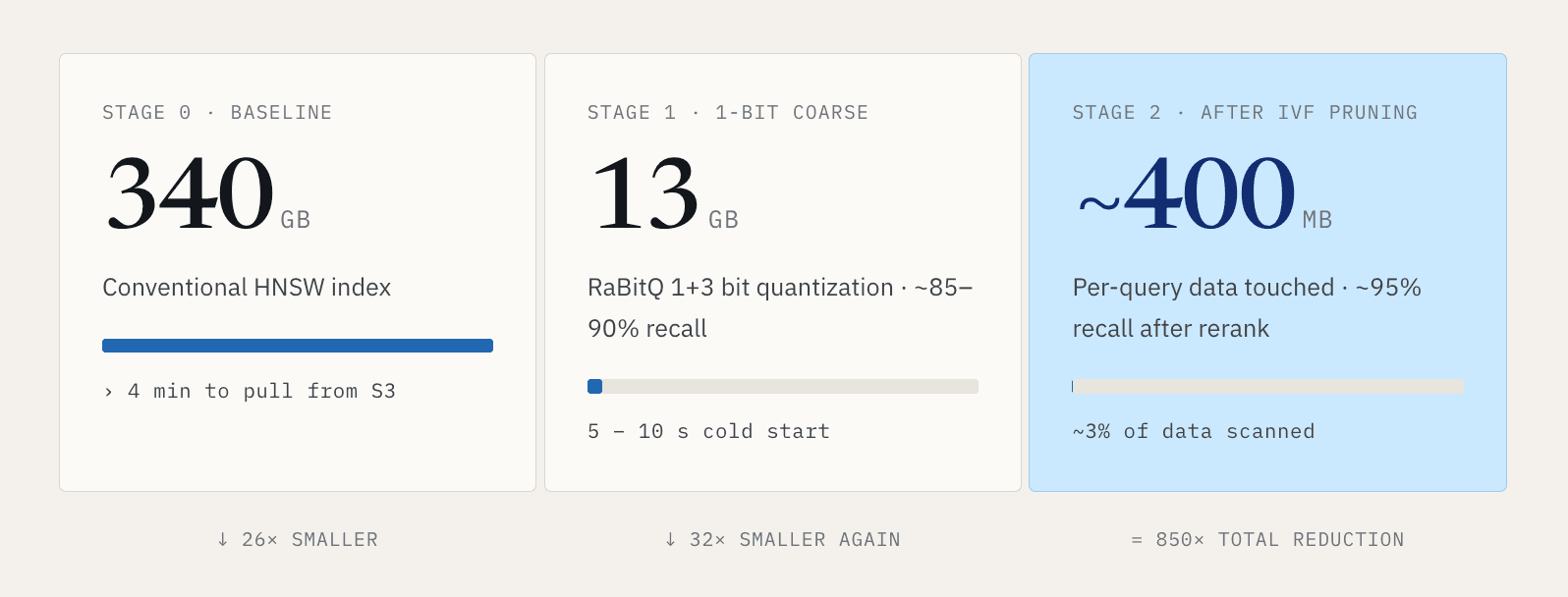
그런 다음 쿼리당 접근되는 데이터 양을 줄이기 위해 IVF 클러스터링을 사용합니다. 대표적인 설정에서 각 쿼리는 데이터의 약 3퍼센트를 스캔합니다. 경로는 다음과 같습니다: 340GB의 일반 인덱스가 13GB로 압축되고, 단일 쿼리는 프루닝 후 대략 400MB에 접근합니다.
이것이 아이디어로서의 탄력적 벡터 검색과 사용 가능한 시스템으로서의 탄력적 벡터 검색의 차이입니다.
I/O 증폭
콜드 스타트는 문제의 한쪽 면일 뿐입니다. 다른 한쪽은 레코드 접근입니다.
벡터 검색은 ID를 반환합니다. 하지만 애플리케이션에는 전체 레코드가 필요합니다: 텍스트 청크, 메타데이터, 문서 포인터, 권한, 타임스탬프, 이미지 속성 또는 기타 필드. 표준 Parquet 레이아웃에서는 작은 포인트 읽기 하나가 시스템으로 하여금 큰 row group을 다운로드하게 만들 수 있습니다. 쿼리는 유용한 데이터 몇 킬로바이트만 필요할 수 있지만, 결국 객체 스토리지에서 수십 메가바이트를 가져오게 됩니다. row group을 줄이면 포인트 읽기에는 도움이 되지만, 압축과 스캔 효율에는 해가 됩니다.
이것이 우리가 Zilliz Vector Lakebase의 기반이 되는 재구축된 스토리지 엔진인 Loon을 만든 이유입니다.
Loon은 혼합 파일 형식, 행 정렬, manifest 기반 버전 관리를 사용합니다. 스칼라 필드는 필터링과 스캔에 효율적인 컬럼형 레이아웃을 사용할 수 있습니다. 벡터 필드와 포인트 쿼리가 많은 데이터는 저지연 검색에 더 적합한 레이아웃을 사용할 수 있습니다. Column group은 row ID를 정렬하여 시스템이 네트워크를 통해 크고 관련 없는 블록을 끌고 오지 않고도 필요한 필드를 가져올 수 있게 합니다.
내부적으로 Loon은 Linux Foundation 산하의 오픈 소스 파일 형식인 Vortex를 사용합니다. Vortex는 크고 관련 없는 블록을 압축 해제하지 않는 포인트 쿼리를 포함해 유연한 레이아웃과 중첩 인코딩을 지원합니다.
300만 행, 128차원 벡터, S3 스토리지, 256명의 동시 리더를 사용한 한 내부 테스트에서 Parquet 포인트 읽기는 읽기당 약 9.4MB를 다운로드했습니다. Vortex는 약 0.07MB를 다운로드했습니다. 이는 다운로드된 데이터가 135배 감소한 것입니다. 이 설정에서는 전체 스캔 처리량도 더 높았습니다.
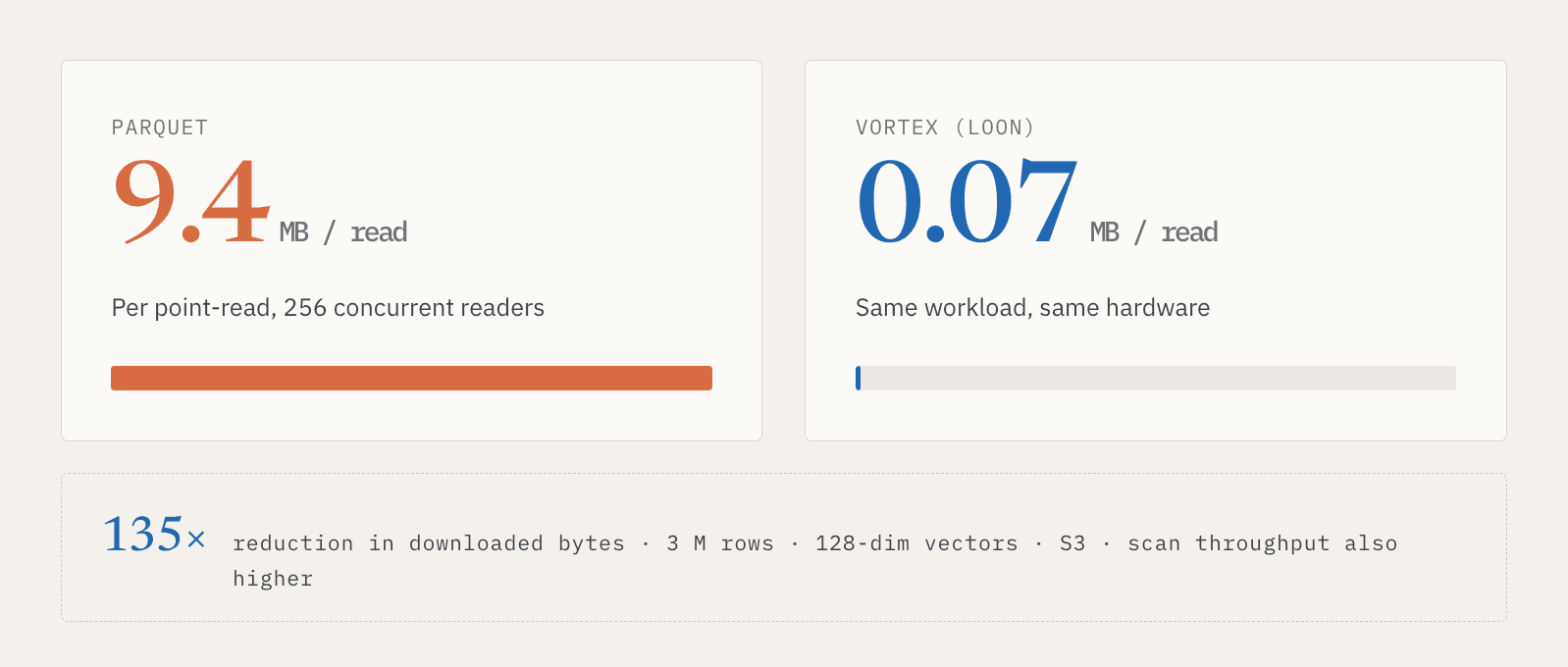
핵심은 한 형식이 하나의 벤치마크에서 더 빠르다는 것만이 아닙니다. 핵심은 serving과 discovery가 동일한 논리적 데이터에 대해 서로 다른 접근 패턴을 필요로 한다는 것입니다. 온라인 시스템에는 빠른 포인트 읽기가 필요합니다. 배치 시스템에는 효율적인 스캔이 필요합니다. Vector Lakebase는 사용자가 데이터 사본 두 개를 유지하도록 강요하지 않으면서 두 가지를 모두 지원해야 합니다.
Vector Lakebase: 하나의 데이터 기반, 여러 컴퓨트 모드
데이터 계층이 공유되면, 컴퓨트는 하나의 방식으로 모든 것에 맞출 수 없습니다.
서로 다른 AI 워크로드는 매우 다른 형태를 가집니다. 어떤 것은 하루 종일 예측 가능한 저지연이 필요합니다. 어떤 것은 10분 동안의 인터랙티브 검색 세션이 필요합니다. 어떤 것은 밤새 실행된 뒤 사라지는 대규모 배치 작업이 필요합니다.
이것이 Zilliz Vector Lakebase가 세 가지 컴퓨트 모드를 지원하는 이유입니다.
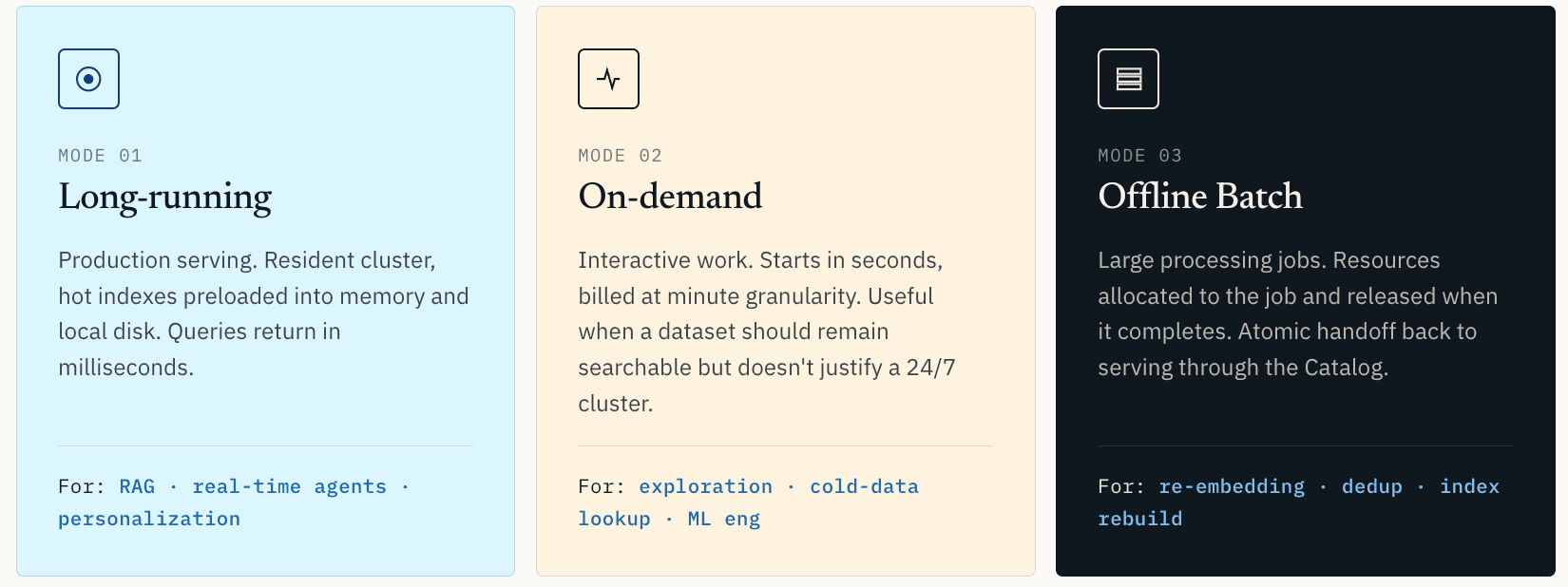
- Long-running compute는 프로덕션 serving을 위한 것입니다. 클러스터는 상주 상태를 유지합니다. hot index와 데이터는 메모리와 로컬 디스크에 미리 로드됩니다. 쿼리는 밀리초 단위로 반환됩니다. 이는 프로덕션 RAG, 실시간 추천, 개인화, 온라인 에이전트, 그리고 지연 시간이 사용자 경험의 일부인 모든 워크로드에 적합한 모드입니다.
- On-demand compute는 인터랙티브 작업을 위한 것입니다. 몇 초 안에 시작되며 분 단위의 세분화된 과금이 적용됩니다. 이는 유사도 탐색, 이상 징후 검사, 콜드 데이터 검색 또는 데이터셋은 검색 가능한 상태로 유지해야 하지만 24/7 클러스터를 정당화하지는 않는 ML 엔지니어링 워크플로에 유용합니다.
- Offline Batch compute는 대규모 처리 작업을 위한 것입니다: 벡터 클러스터링, 학습 데이터 중복 제거, 전체 재임베딩, 인덱스 재구축, 데이터 품질 스캔. 리소스는 작업에 할당되고 작업이 완료되면 해제됩니다.
서빙으로의 핸드오프는 새로운 스냅샷으로서 Catalog를 통해 이루어진다. 서빙은 새 데이터와 인덱스가 준비될 때까지 기존 스냅샷을 계속 읽는다. 그런 다음 새 버전이 원자적으로 표시된다. 이 원자적 전환이 중요하다. 검색은 개선 사항이 반쯤 만들어진 인덱스나 일관되지 않은 데이터를 노출하지 않고 프로덕션으로 다시 흘러 들어갈 수 있을 때에만 유용하다.
 architecture.png
architecture.png
한 고객 사례는 왜 이 구분이 중요한지 보여준다. 한 자율주행 고객은 10억 개의 768차원 벡터를 보유하고 있었지만, 하루에 약 20분의 온라인 쿼리 시간만 필요했다. 워크로드를 장기 실행 클러스터로 운영하는 데는 월 약 $7,000가 들었다. 이를 온디맨드 모드로 옮기자 월 비용은 약 $500로 줄었다. 같은 고객은 이전에 ANN 검색을 하나씩 수행하느라 약 70시간을 소비하던 중복 제거 워크플로도 가지고 있었다. 이를 오프라인 배치 작업으로 재구성하자 동일한 리소스 클래스에서 컴퓨팅 시간이 약 10시간으로 줄었다.

교훈은 어떤 컴퓨팅 모드가 다른 모드보다 낫다는 것이 아니다. 교훈은 AI 데이터 워크로드가 하나의 형태가 아니며, 아키텍처가 이를 하나로 강제해서는 안 된다는 것이다.
리소스 스케줄링은 Vector Lakebase의 일부가 된다
세 가지 컴퓨팅 모드는 리소스 스케줄링이 컴퓨팅 자체만큼 탄력적일 때에만 작동한다.
전통적인 데이터베이스 스케줄러는 보통 고정된 머신 풀을 가정한다. 이러한 노드가 주어지면, 시스템은 데이터를 어디에 배치하고 부하를 어떻게 균형 잡을지 결정한다. 이 모델은 워크로드가 안정적일 때 잘 작동한다. 그러나 온디맨드 검색 세션, 콜드 데이터에 대한 짧은 검사, 야간 중복 제거 작업, 그리고 그 뒤의 몇 시간 동안 아무 일도 없는 식으로 버스트 형태로 나타나는 AI 워크로드에는 잘 맞지 않는다.
그런 세계에서 더 나은 질문은 데이터가 어디에서 실행되어야 하는지만이 아니다. 컴퓨팅이 애초에 실행되고 있어야 하는지이다.
이것이 Vector Lakebase가 데이터와 리소스를 함께 스케줄링해야 하는 이유다. 실제로 이는 준비된 노드의 Warm Pool을 유지하고, 작업이 도착하면 데이터를 빠르게 연결하며, 요청 이후 잠시 리소스를 따뜻하게 유지하고, 더 이상 유용하지 않을 때 이를 해제하는 것을 의미한다.
이는 경제성도 바꾼다. 이는 요청별 서버리스 가격 책정과도 다르고, 전용 월간 용량과도 다르다. 많은 AI 데이터 워크로드에서는 분 단위 사용량이 더 자연스러운 단위다. 루프가 실행되는 동안 컴퓨팅 비용을 지불하고, 그런 다음 사라지게 두는 것이다.
그 뒤에는 대부분 정적인 커널을 관리하는 컨트롤 플레인에서 리소스, 캐시 상태, 스냅샷, 비용을 이해하는 커널로의 더 큰 아키텍처 전환이 있다. 이는 별도의 글에서 다룰 만하다. 이 글에서 중요한 점은 더 단순하다. 이 리소스 모델이 없다면 Long-running, On-demand, Offline Batch는 동일한 탄력적 데이터 시스템의 세 부분이 아니라 세 가지 별도의 배포 선택지가 되었을 것이다.
External Collection: 데이터가 이미 있는 곳에서 데이터를 만나다
우리가 설계에서 고려해야 했던 현실이 하나 더 있다.
대부분의 엔터프라이즈는 이미 레이크 환경에 대량의 비정형 데이터를 보유하고 있다. Lance 테이블, Iceberg 테이블, Parquet 데이터셋, 객체 스토리지 디렉터리 등이 그렇다. 이들에게 이를 사용하기 전에 모든 것을 새 시스템으로 옮기라고 요구하는 것은 현실적이지 않다.
이것이 우리가 Zilliz Vector Lakebase 안에 External Collection을 구축한 이유다. External Collection은 단순한 제로 카피 매핑만이 아니다. 외부 데이터 위에 독립적인 인덱싱 계층을 구축한다. 원본 데이터는 있던 곳에 그대로 남아 고객의 기존 플랫폼에 의해 계속 거버넌스되는 동시에, Zilliz는 해당 데이터를 네이티브 데이터와 동일한 검색 경로를 통해 검색 가능하게 만드는 데 필요한 벡터 인덱스, 역인덱스, JSON 인덱스를 구축하고 관리한다.
우리의 내부 원칙은 단순해졌다. 하나의 데이터. 하나의 인덱스. 중복 스토리지 없음. 이중 쓰기 파이프라인 없음. 파편화된 검색 경로 없음.
이는 CS/CD 루프가 벡터 데이터베이스에 이미 가져온 데이터보다 더 넓은 범위를 포괄할 수 있음을 의미합니다. 기업이 이미 데이터 레이크에 보유하고 있는 비정형 데이터 자산까지 포함할 수 있습니다.
Vector Lakebase의 1세대를 정의하는 요소
이러한 아이디어는 단지 문서상의 아키텍처가 아닙니다. 우리는 이미 Zilliz Vector Lakebase에서 이를 제공하고 있으며, 이를 구축하는 과정에서 이 카테고리에 대한 우리의 관점은 훨씬 더 구체화되었습니다.
1세대 Vector Lakebase는 몇 가지를 동시에 제대로 해내야 합니다.

- 첫째, 다계층 캐싱을 갖춘 스토리지-컴퓨트 분리. 데이터는 객체 스토리지에 존재하고, 컴퓨트는 0까지 축소되는 것을 포함해 독립적으로 확장할 수 있습니다. 하지만 분리만으로는 충분하지 않습니다. 온라인 벡터 검색은 여전히 핫 쿼리를 ms 수준으로 빠르게 유지하기 위해 메모리, 로컬 디스크, 웜 노드, 캐시 인식 실행이 필요합니다.
- 둘째, 멀티모달 비정형 데이터를 위한 통합 관리. 시스템은 벡터뿐 아니라 원본 문서, 이미지, 오디오, 비디오, 임베딩, 스칼라 메타데이터, 권한, 인덱스도 관리해야 합니다. 벡터만 저장하는 시스템은 데이터 기반이 아니라 인덱스 서비스입니다.
- 셋째, 네이티브 벡터 데이터베이스 기능. 밀리초 단위 ANN 검색, 인덱스 수명 주기 관리, 하이브리드 검색, 스칼라 필터링, 전문 검색, JSON 필터링, 여러 유사도 지표가 내장되어야 합니다. Lakehouse를 외부 벡터 데이터베이스에 연결한다고 해서 파편화가 사라지는 것은 아닙니다. 그저 또 다른 파이프라인을 만드는 것일 뿐입니다.
- 넷째, 여러 컴퓨트 모드. 온라인 서빙, 온디맨드 상호작용, 오프라인 배치 처리는 동일한 논리적 데이터 위에서 작동해야 합니다. 온디맨드 컴퓨트는 프로덕션 서빙과 대규모 오프라인 처리 사이의 가교가 되기 때문에 특히 중요합니다.
- 다섯째, 개방형 포맷과 강제 마이그레이션 없음. 스토리지 계층은 Spark, Ray, Daft 같은 외부 엔진에서 읽을 수 있어야 합니다. 기존 Iceberg 테이블, Lance 데이터셋, Parquet 파일은 불필요한 복사 없이 시스템에 합류할 수 있어야 합니다. 데이터는 엔진이 아니라 사용자에게 속합니다.
- 여섯째, 리소스는 데이터를 따라가야 합니다. 컴퓨트는 필요하지 않을 때 사라질 수 있지만, 메타데이터는 계속 표시되고 쿼리 가능해야 합니다. 요청이 들어오면 몇 초 안에 리소스를 다시 가져올 수 있어야 합니다. 유휴 테넌트는 사용하지 않는 전용 컴퓨트 비용을 지불해서는 안 됩니다. 이는 단순한 오토스케일링이 아닙니다. 엔진이 데이터 결정과 함께 리소스 결정을 내려야 합니다.
이는 우리의 현재 믿음이지 최종 결론은 아닙니다. 시스템이 성숙해짐에 따라 계속 수정해 나갈 것입니다. 하지만 한 가지 압력은 변하지 않을 가능성이 높아 보입니다: 비정형 데이터는 계속 증가하는 반면, 인프라 예산은 같은 속도로 증가하지 않을 것입니다. 이는 AI 시스템이 더 반복적이고, 더 효율적이며, 더 지속적으로 적응 가능해져야 함을 의미합니다.
벡터 데이터베이스는 사라지지 않습니다
그렇다면 원래 질문으로 돌아가 보겠습니다. 이것이 벡터 데이터베이스가 사라진다는 뜻일까요? 전혀 그렇지 않습니다.
오히려 이 아키텍처에서 시맨틱 검색은 더 중요해집니다. 하지만 그 역할은 달라집니다.
벡터 데이터베이스는 더 큰 비정형 데이터 시스템 안의 서빙 엔진이 됩니다. 이는 트랜잭션 데이터베이스가 더 넓은 Lakehouse 시대에도 여전히 필수적이었던 것과 비슷합니다. OLTP 시스템은 Lakehouse로 대체되지 않았습니다. 더 큰 아키텍처 스택 안의 한 계층이 되었습니다. 저는 벡터 데이터베이스가 지금 같은 전환을 겪고 있다고 믿습니다.
AI 인프라 아래에서 일어나고 있는 더 큰 변화는 단순히 검색에 관한 것이 아닙니다. 비정형 데이터 자체를 둘러싼 지속적인 운영 루프를 구축하는 것입니다. 서빙은 피드백을 생성합니다. 디스커버리는 데이터 품질을 개선합니다. 이러한 개선은 다시 프로덕션으로 흘러갑니다. 루프가 한 번 돌 때마다 시스템은 더 나아집니다.
스토리지 형식, 캐싱 계층, 인덱싱 시스템, 탄력적 컴퓨팅 모델, 리소스 스케줄링을 포함한 그 밖의 모든 것은 그 플라이휠을 대규모로 경제적으로 실행 가능하게 만들기 위해 존재합니다.
우리는 여전히 Vector Lakebase가 앞으로 5년 동안 정확히 무엇이 될지 알지 못합니다. 거의 10년 전 Milvus를 시작했을 때에도 벡터 데이터베이스 자체가 어디로 이어질지 예측할 수 없었습니다.
하지만 이제 한 가지는 분명해 보입니다. 비정형 데이터는 계속 증가할 것입니다. 모델은 계속 변화할 것입니다. 에이전트는 더 많은 트레이스, 피드백, 상태를 생성할 것입니다. 팀은 인프라 비용이 무제한으로 증가하도록 두지 않으면서 데이터를 더 빠르게 개선해야 할 것입니다.
성공하는 시스템은 지속적인 서빙과 지속적인 발견이 같은 기계의 일부처럼 느껴지게 만드는 시스템일 것입니다. 그것이 우리가 구축해 나가고 있는 방향입니다.
Zilliz Vector Lakebase 공개 프리뷰 제공 시작
Zilliz Vector Lakebase의 공개 프리뷰를 출시했습니다. 이는 Zilliz Cloud가 관리형 벡터 데이터베이스에서 통합 시맨틱 데이터 플랫폼으로 진화하는 중요한 단계로, 저지연 벡터 서빙과 데이터 레이크의 개방성, 확장성, 경제성을 결합합니다.
Zilliz Vector Lakebase 핵심 기능:
- 다양한 실시간 성능-비용 트레이드오프에 최적화된 계층형 서빙
- 상시 가동 컴퓨팅 없이 대규모 또는 탐색형 워크로드를 위한 온디맨드 검색
- 외부 데이터 레이크 검색 — 기존 레이크 데이터에서 직접 인덱싱 및 검색
- 하이브리드 검색 및 리랭킹을 통해 벡터, 텍스트, JSON, 지리공간 데이터 전반을 포괄하는 풀스펙트럼 검색
- Vortex 기반의 통합 레이크 네이티브 스토리지. Lance 또는 Parquet보다 더 빠르고 저렴한 랜덤 읽기를 제공하는 개방형 형식
현재 스택이 서빙과 발견을 별도 시스템으로 분리하고 있다면 Vector Lakebase를 살펴볼 가치가 있을 수 있습니다. Zilliz Cloud에서 사용해 보세요 — 새 업무용 이메일 가입자는 $100 무료 크레딧을 받을 수 있습니다 — 또는 사용 사례에 대해 문의해 주세요.
참고: 이 문서의 성능 및 비용 수치는 오픈 소스 VectorDB Benchmark 결과, 내부 테스트, 익명화된 고객 시나리오를 기반으로 합니다. 실제 결과는 데이터 규모, 분포, 인덱스 매개변수, 워크로드 형태, 리소스 구성에 따라 달라질 수 있습니다.

계속 읽기

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.