




AWS 장애는 벡터 데이터베이스 교차 리전 재해 복구에 대한 경각심을 일깨웠다
클라우드 리전은 장애를 겪습니다. 문제는 발생 여부가 아니라 — 언제, 얼마나 심각하게 발생하느냐입니다.
지난주, 중동의 두 AWS 리전이 데이터 센터 인프라의 물리적 손상으로 인해 오프라인 상태가 되었습니다. AWS UAE 리전(ME-CENTRAL-1)의 세 가용 영역 중 두 곳이 중단되었고, Bahrain(ME-SOUTH-1)의 한 시설도 손상되었습니다. Lambda, EKS, VPC, S3, CloudWatch를 포함해 60개 이상의 AWS 서비스가 영향을 받았습니다. 이 지역 최대 차량 호출 플랫폼인 Careem은 서비스를 상실했습니다. 선도적인 결제 제공업체인 Alaan은 먹통이 되었습니다. AWS는 고객에게 워크로드를 다른 리전으로 이전하라고 권고했지만—이는 재부팅 후 복구되는 사고가 아니었습니다. 하드웨어 교체와 시설 수리를 고려하면 복구에는 몇 주가 걸릴 수 있습니다.
그리고 물리적 손상은 단지 하나의 장애 유형일 뿐입니다. 지난 12개월 동안, 잘못된 구성 변경으로 Azure의 Central US 리전이 14.5시간 동안 중단되었습니다. Google Cloud의 버그로 Cloud Run, GKE, Firebase가 동시에 8시간 동안 중단되었습니다. 클라우드 제공업체 문제조차 아니었던 결함 있는 CrowdStrike 소프트웨어 업데이트는 Azure 호스팅 인프라 전반으로 연쇄 확산되어 Fortune 500 기업들에 추정 54억 달러의 비용을 초래했습니다.
Uptime Institute의 2025년 보고서는 고영향 장애의 중간 비용을 시간당 200만 달러로 제시하며, 이는 3년 전 수치의 대략 두 배입니다. 그런데 Veeam의 2024 Data Protection Trends Report에 따르면 실제 재해 상황에서 복구를 실제로 오케스트레이션할 수 있는 조직은 13%에 불과합니다.
이 수치들은 이미 우려스러웠습니다. 그리고 AI가 판을 더 키웠습니다.
AI가 다운되면, 팀은 느려지는 것이 아니라 — 멈춥니다
5년 전에는 리전 단위 클라우드 장애가 주로 고객 대면 앱에 타격을 주었습니다. 고통스럽긴 했지만, 대부분의 팀은 내부적으로는 여전히 기능할 수 있었습니다. 오늘날 AI는 코드 리뷰, 문서화, 지원 분류, 심지어 일상적인 분석까지 부서 전체에 걸친 업무를 흡수했습니다. 직원의 거의 60%가 일상 워크플로에서 AI를 사용하는 상황에서, 장애는 점진적인 둔화를 일으키지 않습니다. 생산성은 절벽처럼 떨어집니다.
우리는 이미 이것이 실제로 벌어지는 것을 보았습니다 — ChatGPT와 Claude는 모두 2026년 초에 상당한 장애를 겪었고, 수백만 명의 사용자와 엔터프라이즈 팀이 자신들의 워크플로를 구축해 둔 AI 도구 없이 남겨졌습니다.
하지만 대부분의 팀이 간과하는 것이 있습니다. 모델 장애는 지장을 주지만, 모델은 대체로 상태 비저장입니다. 제공업체는 종종 추론 트래픽을 정상 리전으로 비교적 빠르게 우회시킬 수 있습니다. 더 어려운 문제는 그 아래의 데이터 계층입니다—메모리와 컨텍스트를 공급하는 데이터베이스, 객체 저장소, 벡터 인덱스입니다. 그 계층은 상태 저장이며, 리전에 묶여 있고, 복구가 훨씬 더 어렵습니다. 이 계층이 다운되면 LLM은 여전히 텍스트를 생성할 수는 있지만—올바른 컨텍스트 없이는 일반적이고 환각에 취약한 출력으로 기본 설정됩니다. AI는 단순히 오프라인이 되는 것이 아닙니다. 신뢰할 수 없게 됩니다.
벡터 데이터베이스는 AI의 장기 기억입니다 — 그리고 아마 단일 리전에 있을 것입니다
벡터 데이터베이스는 엔터프라이즈 AI의 중추가 되었습니다. RAG 파이프라인과 AI 에이전트는 여기에서 컨텍스트를 검색합니다. 추천 엔진은 이를 쿼리합니다. 시맨틱 검색은 이를 대상으로 실행됩니다. 이 계층을 사용할 수 없게 되면, 그 위에 구축된 모든 애플리케이션이 중단됩니다 — 부분적으로가 아니라 완전히.
그리고 상태 비저장 서비스와 달리, 복구는 간단하지 않습니다:
- 인덱스 재구축은 느립니다. 벡터 검색은 HNSW 그래프 같은 인덱스 구조에 의존하며, 재구축 시간은 데이터셋 크기에 따라 비선형적으로 증가합니다. 1억 개 이상의 벡터에 대한 인덱스를 표준 컴퓨트에서 재구축하는 데는 18시간 이상이 걸릴 수 있습니다.
- 연결 문자열은 곳곳에 있습니다. 기존 클러스터에 연결되었던 모든 애플리케이션은 엔드포인트를 업데이트해야 합니다 — 구성, 환경 변수, CI/CD 파이프라인 전반에 걸쳐, 종종 서로 다른 팀이 관리하는 영역에서 말입니다.
- 임베딩 모델 드리프트. 현재 벡터를 생성한 정확한 임베딩 모델 버전을 찾을 수 없다면, 전체 데이터셋을 다시 임베딩해야 할 수도 있습니다.
소프트웨어 장애의 경우, 재시작을 기다립니다. 하지만 데이터 센터가 물리적으로 손상되면 복구에는 몇 주가 걸립니다. 유일하게 실행 가능한 전략은 이미 다른 리전에서 서비스 중인 라이브, 인덱싱 완료, 쿼리 준비 완료 복제본을 보유하는 것입니다 — 코드 변경이 전혀 필요 없는 트래픽 재라우팅과 함께 말입니다.
Zilliz Cloud: 네이티브 크로스 리전 재해 복구를 갖춘 세계 최초의 벡터 데이터베이스
Zilliz Cloud는 자동 장애 조치, 실시간 복제, 그리고 리전 전환 중 애플리케이션 변경이 전혀 필요 없는 글로벌 엔드포인트를 통해 네이티브 크로스 리전 재해 복구를 제공하는 세계 최초의 벡터 데이터베이스입니다.
우리는 두 가지 상호 보완적인 기능을 제공합니다: 실시간 장애 조치를 위한 Global Cluster와 비용 효율적인 재해 복구를 위한 Cross-Region Backup입니다.
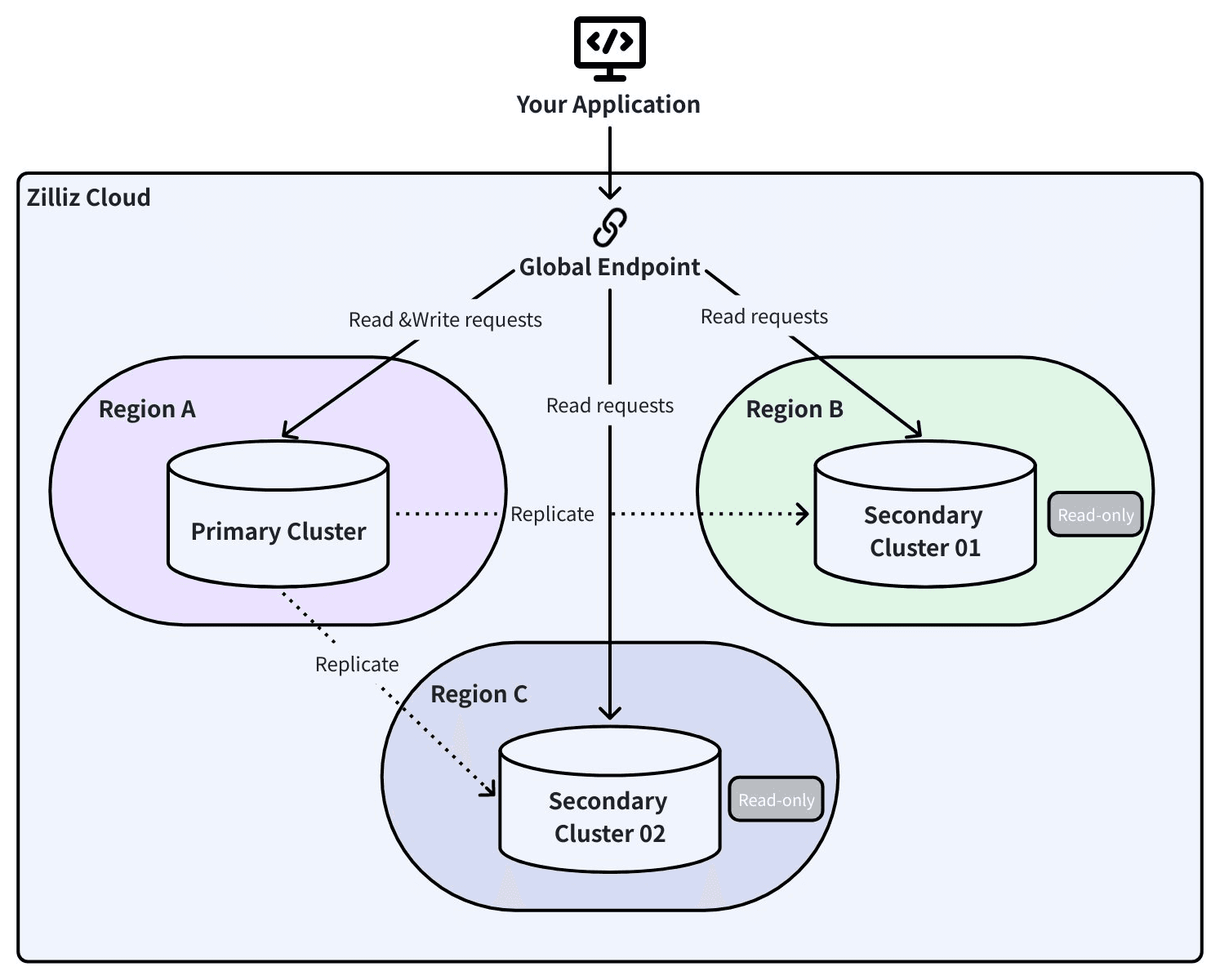
Global Cluster: 자동 장애 조치를 갖춘 라이브 복제
Global Cluster는 Change Data Capture(CDC)를 사용하여 기본 클러스터와 다른 리전에 있는 보조 클러스터 간에 데이터를 지속적으로 복제합니다. 주기적인 스냅샷이 아닙니다 — 모든 삽입, 업데이트, 삭제가 실시간으로 전파됩니다.
- 계획된 전환(유지보수, 마이그레이션, 컴플라이언스): 시스템은 진행 중인 CDC 메시지를 비우고, 전체 동기화를 확인한 다음, 역할을 교체합니다. RPO는 0입니다. RTO는 30초 미만입니다.
- 자동 장애 조치(예상치 못한 리전 장애): 보조 클러스터가 자동으로 자신을 승격합니다. RPO는 장애 순간의 CDC 지연 시간과 동일하며, 일반적으로 몇 초입니다. RTO는 60초 미만입니다.
한 가지 고유한 기능은 장애 조치 후에도 이전 기본 클러스터가 그냥 사라지지 않는다는 점입니다. 7일 보존 기간이 있는 휴지통으로 이동하며, DumpMessages라는 스트리밍 API를 통해 이전 기본 클러스터에 기록되었지만 아직 복제되지 않은 모든 쓰기를 가져올 수 있습니다. 데이터 손실을 받아들이는 대신, 이를 복구할 수 있는 시간을 확보하게 됩니다.
Global Endpoint: 하나의 연결, 모든 리전
바로 여기서 물리적 재해 시나리오에서 아키텍처의 진가가 드러납니다.
애플리케이션은 단일 글로벌 엔드포인트에 연결됩니다. 그 뒤에서는 SRV DNS 레코드가 어떤 클러스터가 기본이고 어떤 클러스터가 보조인지 추적합니다. 장애 조치가 발생하면 SDK가 토폴로지 변경을 감지하고 트래픽을 자동으로 재라우팅합니다. 연결 문자열 업데이트도 없습니다. 애플리케이션 재시작도 없습니다. 코드 변경도 없습니다.
장기간의 리전 장애 중 이것이 무엇을 의미하는지 생각해 보십시오. 글로벌 엔드포인트가 없다면 복구에는 누군가가 런북을 찾고, 클라이언트를 수동으로 재구성하고, 연결 문자열을 업데이트하고, 팀 간 조율을 해야 합니다 — 새벽 3시에, 압박 속에서 말입니다. RTO는 초 단위로 측정되지 않습니다. 적절한 엔지니어를 호출하는 데 걸리는 시간으로 측정됩니다.
Global Endpoint를 사용하면 RAG 파이프라인이 코드 한 줄도 변경하지 않고 60초 이내에 다른 리전의 복제본을 쿼리합니다.
Cross-Region Backup: 라이브 복제본 비용 없이 확보하는 복원력
모든 워크로드가 보조 클러스터 실행을 정당화하는 것은 아닙니다. Cross-Region Backup은 백업 데이터를 하나 이상의 대상 리전에 복제하며, 각 리전은 자체 보존 정책을 가집니다. 리전 수준의 장애가 발생하면 대상 리전의 어떤 백업 지점에서든 새 클러스터를 시작할 수 있습니다 — 데이터가 이미 그곳에 있기 때문에 위기 상황에서 크로스 리전 데이터 전송이 필요 없습니다.
트레이드오프:
- Global Cluster → RPO는 초 단위, RTO는 60초 미만. 다운타임을 전혀 허용할 수 없는 워크로드용입니다.
- Cross-Region Backup → RPO와 RTO는 시간 단위. 즉각적인 복구보다 데이터 생존이 더 중요한 워크로드용입니다.
많은 팀은 중요한 보장 — 리전 장애가 발생해도 데이터가 살아남는다는 점 — 을 위해 Cross-Region Backup으로 시작하고, AI 워크로드가 미션 크리티컬해짐에 따라 Global Cluster로 업그레이드합니다.
다른 벡터 데이터베이스는 크로스 리전 DR을 어떻게 처리하는가
대부분의 벡터 데이터베이스는 replica sets와 노드 중복성을 통해 단일 리전 내에서 고가용성을 제공합니다. 이는 노드 장애를 처리하지만, 리전 장애는 처리하지 못합니다. Zilliz Cloud는 글로벌 클러스터와 글로벌 엔드포인트를 통해 네이티브 자동화된 크로스 리전 장애 조치를 제공하는 유일한 벡터 데이터베이스입니다 — 다운타임 없이, 코드 변경 없이 리전 전환이 가능합니다.
| 기능 | Zilliz Cloud | Pinecone | Weaviate | Qdrant | turbopuffer |
|---|---|---|---|---|---|
| 크로스 리전 복제 | ✅ CDC 기반, 실시간 | ❌ | ❌ | ❌ | ❌ |
| 예기치 않은 장애 조치 | ✅ RPO ≈ 초 단위, RTO<= 30초 | ❌ | ❌ | ❌ | ❌ |
| 계획된 전환 | ✅ RPO=0, RTO=0 | ❌ | ❌ | ❌ | ❌ |
| 장애 조치 후 데이터 복구 | ✅ 동기화되지 않은 데이터를 자동 복구. | ❌ | ❌ | ❌ | ❌ |
| 글로벌 엔드포인트 | ✅ 하나의 글로벌 엔드포인트, 코드 변경 없이 자동 재라우팅 | ❌ | ❌ | ❌ | ❌ |
| 리전 장애 RPO/RTO | ✅ RPO ≈ 초 단위, RTO < 30초 | ❌ | ❌ | ❌ | ❌ |
| 자동 크로스 리전 백업 | ✅ 리전별 보존 기간으로 모든 리전 지원 | ❌ | ❌ | ❌ | ❌ |
재해 복구를 넘어
팀들은 또한 장애와는 무관한 운영 시나리오에서도 Global Cluster를 사용합니다:
- 지연 시간 최적화: 사용자에게 더 가까운 보조 리전을 추가하여 100ms 미만의 쿼리 응답 시간을 제공합니다.
- 리전 마이그레이션: 인프라 통합 중 다운타임 없이 리전 간 워크로드를 이동합니다.
- 데이터 레지던시 준수: 규제 요구사항을 충족하기 위해 데이터를 특정 지리적 경계 내에 유지합니다.
장애로부터 보호하는 동일한 CDC 파이프라인은 사용자에게 더 가까운 읽기 가능 복제본도 제공합니다 — 성능 최적화의 부수 효과로서 DR 기능을 얻는 것입니다.
시작하기
Global Cluster와 Cross-Region Backup은 전용 클러스터용 Zilliz Cloud에서 사용할 수 있습니다.
- 이미 Zilliz Cloud 계정이 있다면, 간단히 로그인하고 새로운 기능을 바로 사용해 보세요—업그레이드나 마이그레이션이 필요하지 않습니다.
- Zilliz Cloud를 처음 사용하시나요? 무료로 가입하고 \$100 크레딧으로 세계 최고의 관리형 벡터 데이터베이스를 경험해 보세요.
- 업데이트에 대해 궁금한 점이 있으신가요? 최신 문서를 확인하거나 Zilliz Support에 문의하세요—저희가 도와드리겠습니다.
한계 없이 구축하기: Zilliz Cloud의 엔터프라이즈급 기능 자세히 보기
Global Cluster는 프로덕션 규모 AI를 위해 구축된 더 넓은 플랫폼의 한 부분입니다. Zilliz Cloud는 또한 다음을 제공합니다:
- 탄력적 확장 및 비용 효율성 – 원클릭 배포, 서버리스 자동 확장, 사용량 기반 요금제.
- 고급 AI 검색 – 메타데이터 필터링, 동적 스키마, 멀티 테넌시를 지원하는 벡터, 전문, 하이브리드(sparse + dense) 검색.
- 엔터프라이즈급 보안 – 99.95% SLA, SOC 2 Type II 및 ISO 27001 인증, GDPR 준수, HIPAA 준비 상태, RBAC, BYOC, 감사 로그. 자세한 내용은 trust center를 참조하세요.
- 글로벌 가용성 – 전 세계 100ms 미만 지연 시간으로 AWS, GCP, Azure 전반에 배포.
- 원활한 마이그레이션 – Pinecone, Qdrant, Elasticsearch, PostgreSQL, OpenSearch, Weaviate 또는 온프레미스 Milvus에서 이동하기 위한 내장 도구.
- 자연어 쿼리 – 복잡한 API 없이 직관적인 쿼리를 위한 MCP server 지원.
- 그 외 다양한 기능!

계속 읽기

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Building RAG Pipelines for Real-Time Data with Cloudera and Milvus
explore how Cloudera can be integrated with Milvus to effectively implement some of the key functionalities of RAG pipelines.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.