




딥서처를 소개합니다: 로컬 오픈 소스 심층 연구
 deep researcher.gif
deep researcher.gif
이전 글 [오픈소스로 딥 리서치를 만들었습니다. 당신도 할 수 있습니다!"(https://milvus.io/blog/i-built-a-deep-research-with-open-source-so-can-you.md)에서는 리서치 에이전트의 기본 원리를 설명하고 주어진 주제나 질문에 대한 상세한 보고서를 생성하는 간단한 프로토타입을 만들었습니다. 이 글과 해당 노트북은 도구 사용, 질문 분해, 추론, 반성의 기본 개념을 설명했습니다. 이전 포스팅의 예제는 OpenAI의 딥 리서치와는 달리 Milvus 및 LangChain과 같은 오픈 소스 모델과 도구만을 사용해 로컬에서 실행되었습니다. (계속하기 전에 위 글을 읽어보시기 바랍니다.)
그 후 몇 주 동안 OpenAI의 딥 리서치를 이해하고 재현하는 데 대한 관심이 폭발적으로 증가했습니다. 예를 들어, 퍼플렉시티 딥 리서치 및 허깅 페이스의 오픈 딥리서치를 참조하세요. 이러한 도구는 웹이나 내부 문서를 서핑하여 주제나 질문을 반복적으로 조사하고 상세하고 정보에 입각한 체계적인 보고서를 출력한다는 목표는 공유하지만 아키텍처와 방법론은 다릅니다. 중요한 점은 기본 에이전트가 각 중간 단계에서 어떤 조치를 취해야 하는지에 대한 추론을 자동화한다는 점입니다.
이번 포스팅에서는 이전 포스팅을 기반으로 질리즈의 딥서처 오픈소스 프로젝트를 소개합니다. 에이전트가 추가 개념을 시연합니다: 쿼리 라우팅, 조건부 실행 흐름, 그리고 도구로서의 웹 크롤링이라는 추가 개념을 소개합니다. Jupyter 노트북이 아닌 Python 라이브러리와 명령줄 도구로 제공되며 이전 게시물보다 더 완전한 기능을 갖추고 있습니다. 예를 들어, 여러 소스 문서를 입력할 수 있고 구성 파일을 통해 임베딩 모델과 벡터 데이터베이스를 설정할 수 있습니다. 아직은 비교적 단순하지만, DeepSearcher는 에이전트 RAG의 훌륭한 쇼케이스이며 최첨단 AI 애플리케이션을 향한 한 걸음 더 나아간 것입니다.
또한 더 빠르고 효율적인 추론 서비스의 필요성에 대해서도 살펴봅니다. 추론 모델은 "추론 확장", 즉 추가 계산을 사용하여 결과를 개선하는데, 단일 보고서에 수백 또는 수천 개의 LLM 호출이 필요할 수 있다는 사실과 결합하여 추론 대역폭이 주요 병목 현상이 됩니다. 저희는 가장 가까운 경쟁사보다 초당 출력 토큰 수가 두 배 빠른 삼바노바의 맞춤형 하드웨어에 탑재된 DeepSeek-R1 추론 모델을 사용합니다(아래 그림 참조).
삼바노바 클라우드는 또한 Llama 3.x, Qwen2.5, QwQ 등 다른 오픈 소스 모델에 대한 서비스형 추론도 제공합니다. 추론 서비스는 재구성 가능한 데이터 흐름 장치(RDU)라는 SambaNova의 맞춤형 칩에서 실행되며, 이는 생성형 AI 모델에서 효율적인 추론을 위해 특별히 설계되어 비용을 낮추고 추론 속도를 높입니다. [자세한 내용은 웹사이트(https://sambanova.ai/technology/sn40l-rdu-ai-chip)에서 확인할 수 있습니다.)
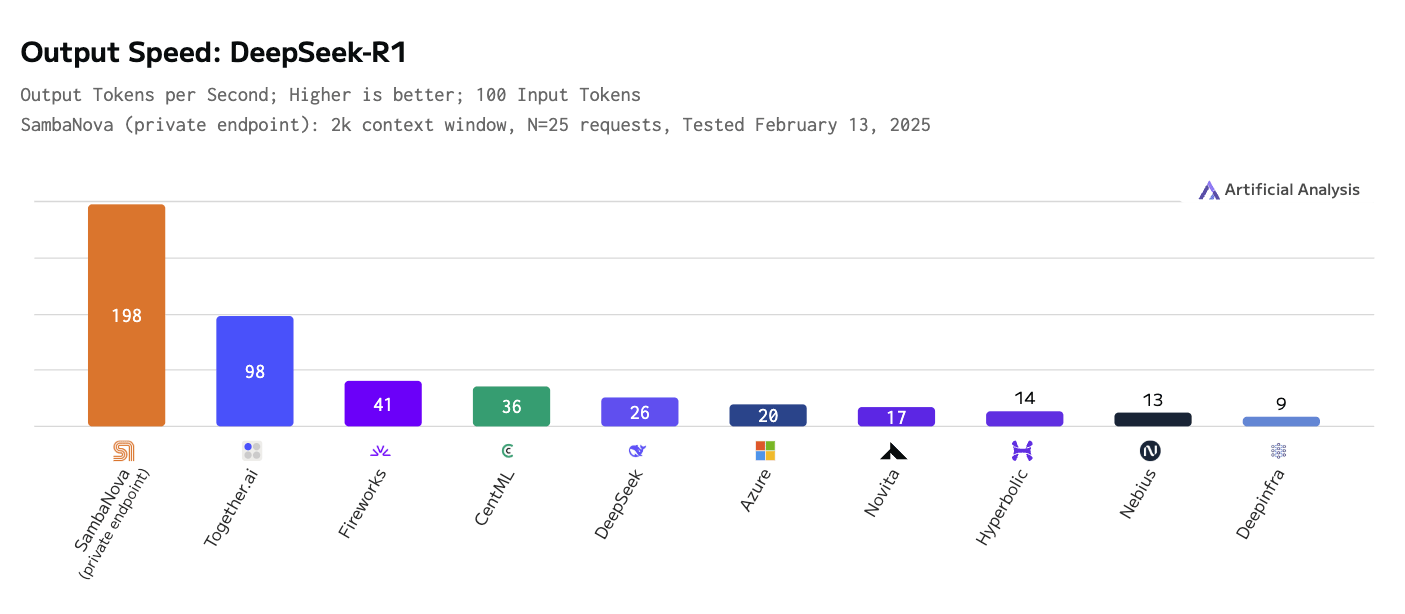 출력 속도-딥시크 r1.png
출력 속도-딥시크 r1.png
딥서처 아키텍처
딥서처](https://github.com/zilliztech/deep-searcher)의 아키텍처는 이전 포스팅과 마찬가지로 문제를 질문 정의/세분화, 조사, 분석, 종합의 네 단계로 나누고 있는데, 이번에도 일부 중복되는 부분이 있습니다. 각 단계를 살펴보면서 DeepSearcher의 개선 사항을 중점적으로 살펴봅니다.
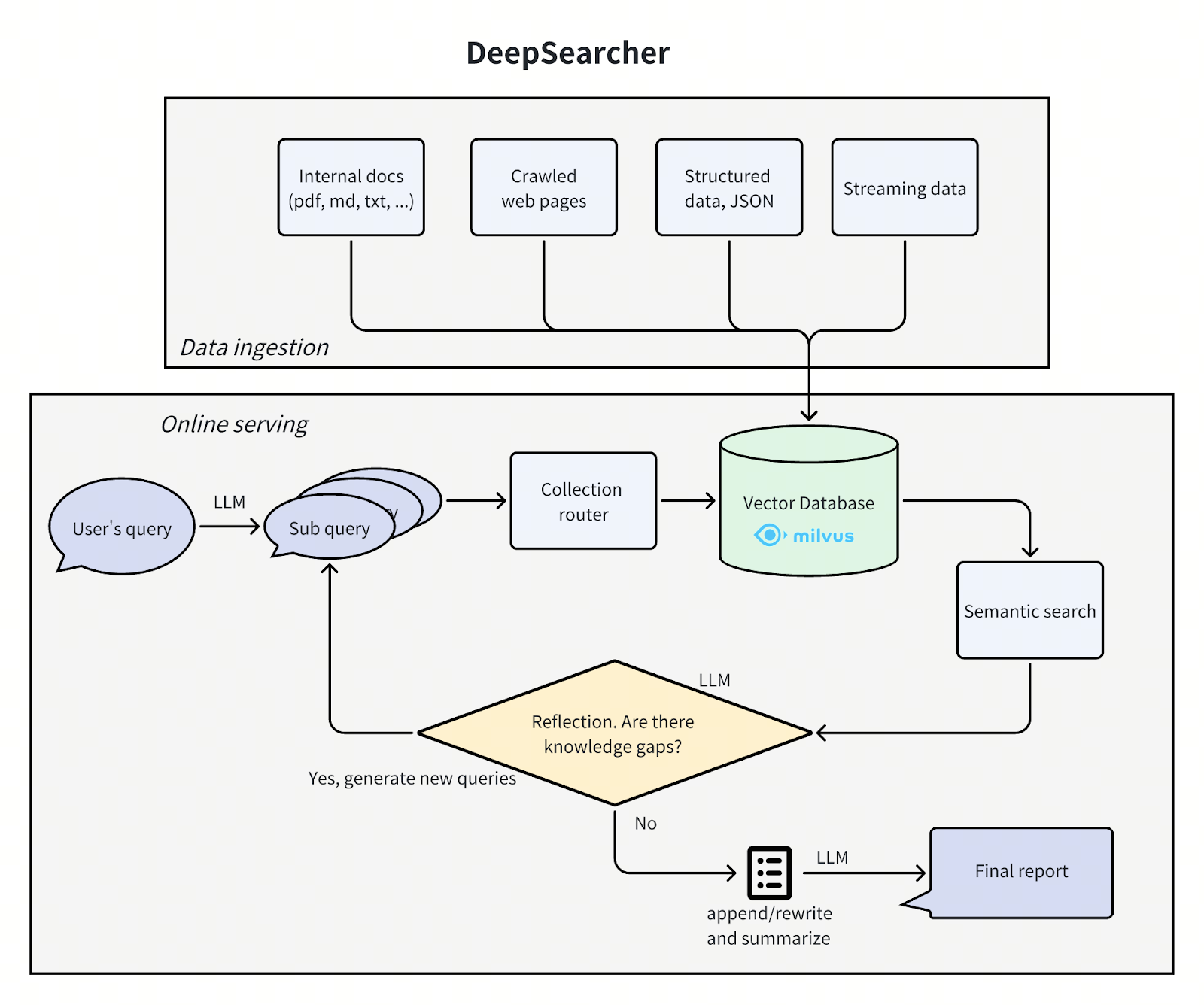 딥서치어 아키텍처.png
딥서치어 아키텍처.png
질문 정의 및 구체화하기
원래 쿼리를 새로운 하위 쿼리로 세분화합니다: [
'심슨 가족의 문화적 영향력과 사회적 관련성은 데뷔 이후부터 현재까지 어떻게 발전해 왔나요?',
'심슨 가족의 여러 시즌에 걸쳐 캐릭터 개발, 유머 및 스토리텔링 스타일에 어떤 변화가 있었나요?
'심슨 가족의 애니메이션 스타일과 제작 기술은 시간이 지남에 따라 어떻게 변화해 왔나요?
'심슨 가족의 시청자 인구 통계, 반응, 시청률은 방영 기간 동안 어떻게 변화했나요?']
딥서처의 설계에서는 질문을 조사하는 것과 구체화하는 것 사이의 경계가 모호합니다. 초기 사용자 쿼리는 이전 게시물과 마찬가지로 하위 쿼리로 분해됩니다. "심슨 가족은 시간이 지남에 따라 어떻게 변했나요?"라는 쿼리에서 생성된 초기 하위 쿼리는 위를 참조하세요. 그러나 다음 연구 단계에서는 필요에 따라 질문을 계속 구체화할 것입니다.
조사 및 분석
쿼리를 하위 쿼리로 세분화하면 에이전트의 리서치 부분이 시작됩니다. 대략 네 단계로 구성되어 있습니다: 라우팅_, 검색, 반영 및 조건부 반복의 네 단계로 구성됩니다.
라우팅
데이터베이스에는 여러 소스의 여러 테이블이나 컬렉션이 포함되어 있습니다. 시맨틱 검색을 현재 쿼리와 관련된 소스로만 제한할 수 있다면 더 효율적일 것입니다. 쿼리 라우터는 어떤 컬렉션 정보를 검색할지 결정하도록 LLM에 메시지를 표시합니다.
다음은 쿼리 라우팅 프롬프트를 구성하는 방법입니다:
def get_vector_db_search_prompt(
질문: str,
collection_names: List[str],
collection_descriptions: List[str],
context: List[str] = None,
):
섹션 = []
# 공통 프롬프트
common_prompt = f"""귀하는 고급 AI 문제 분석가입니다. 기존의 모든 데이터 세트에 기반한 추론 능력과 과거 대화 정보를 사용하여 다음 질문에 대한 정확한 답을 얻고, 질문과 관련이 있을 수 있는 데이터 세트 설명에 따라 각 데이터 세트에 적합한 질문을 생성하세요.
질문: {질문}
"""
섹션.추가(공통_프롬프트)
# 데이터 집합 프롬프트
data_set = []
for i, collection_name in enumerate(collection_names):
data_set.append(f"{collection_name}: {collection_descriptions[i]}")
data_set_prompt = f"""다음은 모든 데이터 세트 정보입니다. 데이터 집합 정보의 형식은 데이터 집합 이름: 데이터 집합 설명입니다.
데이터 집합 및 설명:
"""
sections.append(data_set_prompt + "\n".join(data_set))
# 컨텍스트 프롬프트
컨텍스트
context_prompt = f"""다음은 과거 대화의 압축된 버전입니다. 이 분석에서 이 정보를 결합하여 답변에 더 가까운 질문을 생성해야 합니다. 동일한 데이터 집합에 대해 동일하거나 유사한 질문을 생성해서는 안 되며, 관련성이 없는 것으로 확인된 데이터 집합에 대한 질문을 다시 생성해서는 안 됩니다.
과거 대화:
"""
sections.append(context_prompt + "\n".join(context))
# 응답 프롬프트
response_prompt = f"""위의 문제를 해결하기 위해 다음 데이터 세트 목록에서 몇 개의 데이터 세트만 선택하면 선택한 데이터 세트에 대한 적절한 관련 질문을 생성할 수 있습니다. 출력 형식은 json이며, 여기서 키는 데이터 세트의 이름이고 값은 해당 생성된 질문입니다.
데이터 집합:
"""
sections.append(response_prompt + "\n".join(collection_names))
footer = """정확한 JSON 스키마와 일치하는 유효한 JSON 형식으로만 응답하세요.
중요 요구 사항:
- 하나의 액션 유형만 포함
- 지원되지 않는 키를 추가하지 마세요.
- JSON이 아닌 모든 텍스트, 마크다운 또는 설명 제외
- 엄격한 JSON 구문 유지"""
sections.append(footer)
반환 "\n\n".join(sections)
LLM 반환 구조화된 출력은 다음에 수행할 작업에 대한 결정으로 쉽게 변환할 수 있도록 JSON으로 만듭니다.
검색
이전 단계를 통해 다양한 데이터베이스 컬렉션을 선택했다면, 검색 단계에서는 Milvus로 유사도 검색을 수행합니다. 이전 게시물과 마찬가지로 소스 데이터를 미리 지정하고 청크화하여 벡터 데이터베이스에 임베드하고 저장했습니다. 딥서처의 경우 로컬 및 온라인 데이터 소스를 모두 수동으로 지정해야 합니다. 온라인 검색은 추후 작업을 위해 남겨둡니다.
반영
이전 게시물과 달리, 딥서처는 지금까지 질문한 질문과 검색된 관련 청크에 정보 격차가 있는지 여부를 '반영'하는 프롬프트에 이전 출력을 컨텍스트로 입력하는 진정한 형태의 에이전트 반영을 보여줍니다. 이는 분석 단계로 볼 수 있습니다.
프롬프트를 만드는 방법은 다음과 같습니다:
def get_reflect_prompt(
question: str,
mini_questions: List[str],
mini_chuncks: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
반영_프롬프트 = f"""원본 쿼리, 이전 하위 쿼리 및 검색된 모든 문서 청크를 기반으로 추가 검색 쿼리가 필요한지 여부를 결정합니다. 추가 조사가 필요한 경우 최대 3개의 검색 쿼리 파이썬 목록을 제공합니다. 추가 조사가 필요하지 않은 경우 빈 목록을 반환합니다.
원래 쿼리가 보고서를 작성하는 것이라면 빈 목록을 반환하는 대신 몇 가지 추가 쿼리를 생성하는 것이 좋습니다.
원래 쿼리: {질문}
이전 하위 쿼리: {mini_questions}
관련 청크:
{mini_chunk_str}
"""
footer = """다른 텍스트 없이 유효한 목록 문자열 형식으로만 응답합니다."""
반환 반영_프롬프트 + 푸터
다시 한 번 LLM이 이번에는 파이썬으로 해석 가능한 데이터로 구조화된 출력을 반환하도록 합니다.
다음은 위의 초기 하위 쿼리에 대한 답변 후 리플렉션을 통해 '발견된' 새로운 하위 쿼리의 예입니다:
다음 반복을 위한 새로운 검색 쿼리: [
"심슨 가족의 성우진과 제작진의 변화가 여러 시즌에 걸쳐 쇼의 발전에 어떤 영향을 미쳤나요?",
"심슨 가족의 풍자와 사회적 논평은 수십 년에 걸쳐 현대적 이슈에 적응하는 데 어떤 역할을 했나요?",
'심슨 가족은 스트리밍 서비스와 같은 미디어 소비의 변화를 어떻게 다루고 배포 및 콘텐츠 전략에 통합했나요?']
조건부 반복
이전 게시물과 달리 딥서처는 조건부 실행 흐름을 보여줍니다. 지금까지의 질문과 답변이 완전한지 검토한 후 추가 질문이 있는 경우 에이전트는 위의 단계를 반복합니다. 중요한 점은 실행 흐름(동안 루프)이 하드 코딩된 것이 아니라 LLM 출력의 함수라는 점입니다. 이 경우에는 이진 선택만 가능합니다: 리서치 반복_ 또는 보고서 생성. 더 복잡한 에이전트에서는 다음과 같은 여러 가지가 있을 수 있습니다: 하이퍼링크 따라가기, 청크 검색, 메모리에 저장, 반영 등 여러 가지가 있을 수 있습니다. 이러한 방식으로 에이전트가 루프를 종료하고 보고서를 생성하기로 결정할 때까지 질문은 계속 개선됩니다. 심슨 가족 예제에서 DeepSearcher는 추가 하위 쿼리로 빈틈을 메우는 작업을 두 번 더 수행합니다.
Synthesize
마지막으로, 완전히 분해된 질문과 검색된 청크가 하나의 프롬프트가 포함된 보고서로 합성됩니다. 다음은 프롬프트를 생성하는 코드입니다:
def get_final_answer_prompt(
question: str,
mini_questions: List[str],
mini_chuncks: List[str],
):
mini_chunk_str = ""
for i, chunk in enumerate(mini_chuncks):
mini_chunk_str += f"""<chunk_{i}>\n{chunk}\n</chunk_{i}>\n"""
summary_prompt = f"""귀하는 콘텐츠 요약에 능숙한 AI 콘텐츠 분석 전문가입니다. 이전 쿼리와 검색된 문서 청크를 기반으로 구체적이고 상세한 답변 또는 보고서를 요약해 주세요.
원본 쿼리: {질문}
이전 하위 쿼리: {미니 질문}
관련 청크:
{mini_chunk_str}
"""
반환 요약_프롬프트
이 접근 방식은 각 질문을 개별적으로 분석하고 단순히 결과물을 연결한 프로토타입에 비해 모든 섹션이 서로 일관된, 즉 반복되거나 모순되는 정보를 포함하지 않는 보고서를 생성할 수 있다는 장점이 있습니다. 보다 복잡한 시스템은 조건부 실행 흐름을 사용하여 보고서 구조화, 요약, 재작성, 반영 및 피벗 등 두 가지 측면을 결합하여 향후 작업을 위해 남겨둘 수 있습니다.
결과
다음은 "심슨 가족은 시간이 지남에 따라 어떻게 변했나요?"라는 쿼리에 의해 생성된 보고서의 샘플로, DeepSeek-R1이 심슨 가족에 대한 Wikipedia 페이지를 소스 자료로 전달합니다:
Report: 심슨 가족의 진화(1989년~현재)'
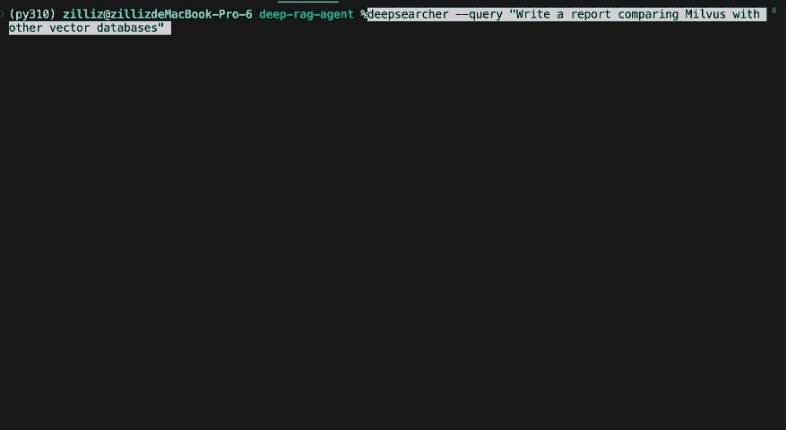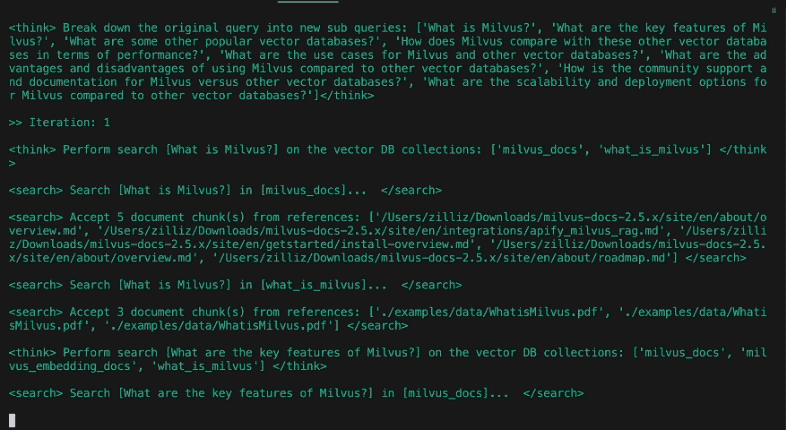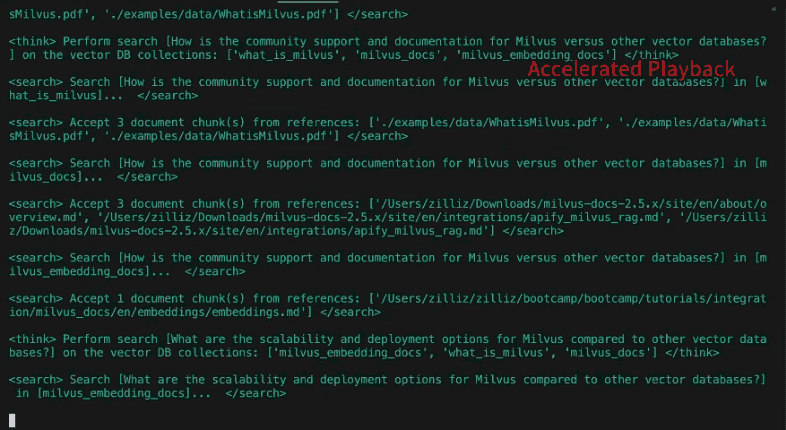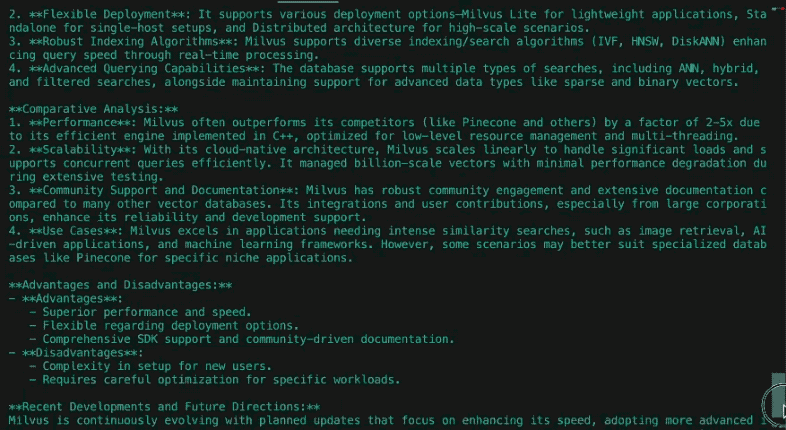
1. 문화적 영향과 사회적 연관성
심슨 가족은 미국 중산층 생활에 대한 전복적인 비판으로 데뷔하여 1990년대에 대담한 풍자로 명성을 얻었습니다. 처음에는 반문화적인 현상이었지만 종교, 정치, 소비주의를 다룬 에피소드를 통해 규범에 도전했습니다. 시간이 지남에 따라 사우스 파크와 패밀리 가이 같은 경쟁자들이 경계를 허물면서 문화적 지배력은 약해졌습니다. 2010년대 들어, 이 프로그램은 유행을 선도하는 프로그램에서 향수를 불러일으키는 프로그램으로 전환하면서 사회적 반향은 적었지만 기후 변화 및 성소수자 인권과 같은 현대적 이슈를 다루려는 시도와 전통적 매력의 균형을 맞췄습니다.
...
결론
심슨 가족은 기술, 정치, 시청자의 기대에 부응하며 급진적인 풍자극에서 텔레비전 기관으로 진화했습니다. 황금기 시절의 명성은 여전하지만, 스트리밍, 업데이트된 유머, 글로벌 홍보를 통한 적응력은 문화적 시금석으로서 그 자리를 굳건히 지키고 있습니다. 이 프로그램의 장수에는 향수와 실용적인 변화 수용이 모두 반영되어 있으며, 파편화된 미디어 환경 속에서 관련성 문제를 해결하기 위해 고군분투하고 있습니다.
보고서 전문](https://drive.google.com/file/d/1GE3rvxFFTKqro67ctTkknryUf-ojhduN/view?usp=sharing)과 딥서처가 GPT-4o 미니로 제작한 보고서를 비교하실 수 있습니다.
토론 ## 토론
리서치 수행 및 보고서 작성을 위한 에이전트인 DeepSearcher를 소개했습니다. 이 시스템은 이전 글에서 소개한 아이디어를 기반으로 조건부 실행 흐름, 쿼리 라우팅, 개선된 인터페이스 등의 기능을 추가했습니다. 소규모 4비트 정량화된 추론 모델을 사용한 로컬 추론에서 대규모 DeepSeek-R1 모델을 위한 온라인 추론 서비스로 전환하여 출력 보고서를 질적으로 개선했습니다. DeepSearcher는 OpenAI, Gemini, DeepSeek, Grok 3(곧 출시 예정!) 등 대부분의 추론 서비스와 함께 작동합니다.
특히 리서치 에이전트에서 사용되는 추론 모델은 추론이 많은데, 운 좋게도 맞춤형 하드웨어에서 실행되는 삼바노바의 가장 빠른 DeepSeek-R1 제품을 사용할 수 있었습니다. 데모 쿼리의 경우, 약 2만 5천 개의 토큰을 입력하고 2만 2천 개의 토큰을 출력하며 0.30달러의 비용으로 삼바노바의 DeepSeek-R1 추론 서비스를 65회 호출했습니다. 모델에 6,710억 개의 매개변수가 포함되어 있고 크기가 3/4 테라바이트에 달한다는 점을 감안할 때 추론 속도에 깊은 인상을 받았습니다. [자세한 내용은 여기에서 확인하세요.(https://sambanova.ai/press/fastest-deepseek-r1-671b-with-highest-efficiency)
향후 포스팅에서 이 작업을 계속 반복하여 추가적인 에이전트 개념과 연구 에이전트의 설계 공간을 검토할 예정입니다. 그동안 여러분 모두 DeepSearcher를 사용해 보시고, GitHub에 별표 표시를 해 주시고 피드백을 공유해 주시기 바랍니다!
리소스
딥서처: 심슨 가족에 대한 딥시크-R1 보고서
밀버스 오픈 소스 벡터 데이터베이스](https://milvus.io/docs)

계속 읽기

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

Vector Databases vs. Document Databases
Use a vector database for similarity search and AI-powered applications; use a document database for flexible schema and JSON-like data storage.

DeepRAG: Thinking to Retrieval Step by Step for Large Language Models
Discover DeepRAG, an advanced retrieval-augmented generation (RAG) model that improves LLM accuracy by retrieving only essential data through step-by-step reasoning.