




2026년 RAG를 위한 최고의 임베딩 모델을 선택하는 방법: 10개 모델 벤치마크
TL;DR: 공개 벤치마크가 놓치는 네 가지 프로덕션 시나리오(크로스모달 검색, 크로스링구얼 검색, 핵심 정보 검색, 차원 압축)에서 10개의 임베딩 모델을 테스트했습니다. 모든 것을 이기는 단일 모델은 없습니다. Gemini Embedding 2가 최고의 올라운더입니다. 오픈소스 Qwen3-VL-2B는 크로스모달 작업에서 클로즈드소스 API를 능가합니다. 스토리지를 절약하기 위해 차원을 압축해야 한다면 Voyage Multimodal 3.5 또는 Jina Embeddings v4를 선택하세요.
임베딩 모델 선택에 MTEB만으로는 충분하지 않은 이유
대부분의 RAG 프로토타입은 OpenAI의 text-embedding-3-small로 시작합니다. 저렴하고, 통합하기 쉽고, 영어 텍스트 검색에는 충분히 잘 작동합니다. 하지만 프로덕션 RAG는 빠르게 이를 넘어섭니다. 파이프라인에 이미지, PDF, 다국어 문서가 들어오기 시작하면 텍스트 전용 임베딩 모델만으로는 충분하지 않게 됩니다.
MTEB 리더보드는 더 나은 옵션이 있다는 것을 보여줍니다. 문제는 무엇일까요? MTEB는 단일 언어 텍스트 검색만 테스트합니다. 크로스모달 검색(이미지 컬렉션에 대한 텍스트 쿼리), 크로스링구얼 검색(중국어 쿼리로 영어 문서 찾기), 긴 문서 정확도, 또는 벡터 데이터베이스에서 스토리지를 절약하기 위해 임베딩 차원을 자를 때 품질이 얼마나 손실되는지는 다루지 않습니다.
그렇다면 어떤 임베딩 모델을 사용해야 할까요? 데이터 유형, 언어, 문서 길이, 그리고 차원 압축이 필요한지 여부에 따라 달라집니다. 우리는 CCKM이라는 벤치마크를 구축하고, 바로 이러한 차원 전반에서 2025년부터 2026년 사이에 출시된 10개 모델을 테스트했습니다.
CCKM 벤치마크란 무엇인가요?
CCKM(Cross-modal, Cross-lingual, Key information, MRL)은 표준 벤치마크가 놓치는 네 가지 기능을 테스트합니다:
| 차원 | 테스트 내용 | 중요한 이유 |
|---|---|---|
| 크로스모달 검색 | 거의 동일한 방해 요소가 있을 때 텍스트 설명을 올바른 이미지와 매칭 | 멀티모달 RAG 파이프라인은 텍스트와 이미지 임베딩이 동일한 벡터 공간에 있어야 함 |
| 크로스링구얼 검색 | 중국어 쿼리에서 올바른 영어 문서를 찾고, 그 반대도 수행 | 프로덕션 지식 베이스는 종종 다국어로 구성됨 |
| 핵심 정보 검색 | 4K–32K자 문서에 묻혀 있는 특정 사실 찾기(바늘 찾기 문제) | RAG 시스템은 계약서와 연구 논문 같은 긴 문서를 자주 처리함 |
| MRL 차원 압축 | 임베딩을 256차원으로 자를 때 모델이 얼마나 많은 품질을 잃는지 측정 | 차원이 적을수록 벡터 데이터베이스의 스토리지 비용은 낮아지지만, 품질 비용은 어느 정도일까? |
MTEB는 이 중 어느 것도 다루지 않습니다. MMEB는 멀티모달을 추가하지만 어려운 네거티브를 건너뛰므로, 모델이 미묘한 차이를 처리한다는 것을 입증하지 않고도 높은 점수를 얻습니다. CCKM은 이들이 놓치는 부분을 다루도록 설계되었습니다.
어떤 임베딩 모델을 테스트했나요? Gemini Embedding 2, Jina Embeddings v4 등
우리는 API 서비스와 오픈소스 옵션을 모두 포함한 10개 모델을 테스트했으며, 2021년 기준선으로 CLIP ViT-L-14도 포함했습니다.
| 모델 | 출처 | 매개변수 | 차원 | 모달리티 | 핵심 특징 |
|---|---|---|---|---|---|
| Gemini Embedding 2 | 미공개 | 3072 | 텍스트 / 이미지 / 비디오 / 오디오 / PDF | 모든 모달리티, 가장 넓은 범위 | |
| Jina Embeddings v4 | Jina AI | 3.8B | 2048 | 텍스트 / 이미지 / PDF | MRL + LoRA 어댑터 |
| Voyage Multimodal 3.5 | Voyage AI (MongoDB) | 미공개 | 1024 | 텍스트 / 이미지 / 비디오 | 작업 전반의 균형 |
| Qwen3-VL-Embedding-2B | Alibaba Qwen | 2B | 2048 | 텍스트 / 이미지 / 비디오 | 오픈 소스, 경량 멀티모달 |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | 텍스트 / 이미지 | 현대화된 CLIP 아키텍처 |
| Cohere Embed v4 | Cohere | 미공개 | 고정 | 텍스트 | 엔터프라이즈 검색 |
| OpenAI text-embedding-3-large | OpenAI | 미공개 | 3072 | 텍스트 | 가장 널리 사용됨 |
| BGE-M3 | BAAI | 568M | 1024 | 텍스트 | 오픈 소스, 100개 이상 언어 |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | 텍스트 | 경량, 영어 중심 |
| nomic-embed-text | Nomic AI | 137M | 768 | 텍스트 | 초경량 |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | 텍스트 / 이미지 | 기준선 |
크로스 모달 검색: 어떤 모델이 텍스트-이미지 검색을 처리할 수 있을까?
RAG 파이프라인이 텍스트와 함께 이미지를 처리한다면, 임베딩 모델은 두 모달리티를 동일한 벡터 공간에 배치해야 합니다. 전자상거래 이미지 검색, 이미지-텍스트가 혼합된 지식 베이스, 또는 텍스트 쿼리로 적절한 이미지를 찾아야 하는 모든 시스템을 떠올려 보세요.
방법
COCO val2017에서 200개의 이미지-텍스트 쌍을 가져왔습니다. 각 이미지에 대해 GPT-4o-mini가 상세한 설명을 생성했습니다. 그런 다음 이미지당 3개의 어려운 부정 예시를 작성했습니다. 이는 정답과 한두 가지 세부 사항만 다른 설명입니다. 모델은 200개의 이미지와 600개의 방해 항목 풀에서 올바른 매치를 찾아야 합니다.
데이터셋의 예시는 다음과 같습니다:
 California와 Cuba를 포함한 여행 스티커가 붙은 빈티지 갈색 가죽 여행가방들이 파란 하늘을 배경으로 금속 수하물 선반 위에 놓여 있음 — 크로스 모달 검색 벤치마크의 테스트 이미지로 사용됨
California와 Cuba를 포함한 여행 스티커가 붙은 빈티지 갈색 가죽 여행가방들이 파란 하늘을 배경으로 금속 수하물 선반 위에 놓여 있음 — 크로스 모달 검색 벤치마크의 테스트 이미지로 사용됨
정답 설명: "이미지에는 'California', 'Cuba', 'New York'을 포함한 다양한 여행 스티커가 붙은 빈티지 갈색 가죽 여행가방들이 맑고 파란 하늘을 배경으로 금속 수하물 선반 위에 놓여 있습니다."
어려운 부정 예시: 같은 문장이지만 "California"가 "Florida"로, "blue sky"가 "overcast sky"로 바뀝니다. 모델은 이를 구별하기 위해 이미지의 세부 사항을 실제로 이해해야 합니다.
채점:
- 모든 이미지와 모든 텍스트(200개의 정답 설명 + 600개의 어려운 부정 예시)에 대해 임베딩을 생성합니다.
- 텍스트-이미지(t2i): 각 설명이 200개의 이미지 중 가장 가까운 매치를 검색합니다. 최상위 결과가 정답이면 1점을 부여합니다.
- 이미지-텍스트(i2t): 각 이미지가 800개의 모든 텍스트 중 가장 가까운 매치를 검색합니다. 최상위 결과가 어려운 부정 예시가 아니라 정답 설명일 때만 1점을 부여합니다.
- 최종 점수: hard_avg_R@1 = (t2i 정확도 + i2t 정확도) / 2
결과
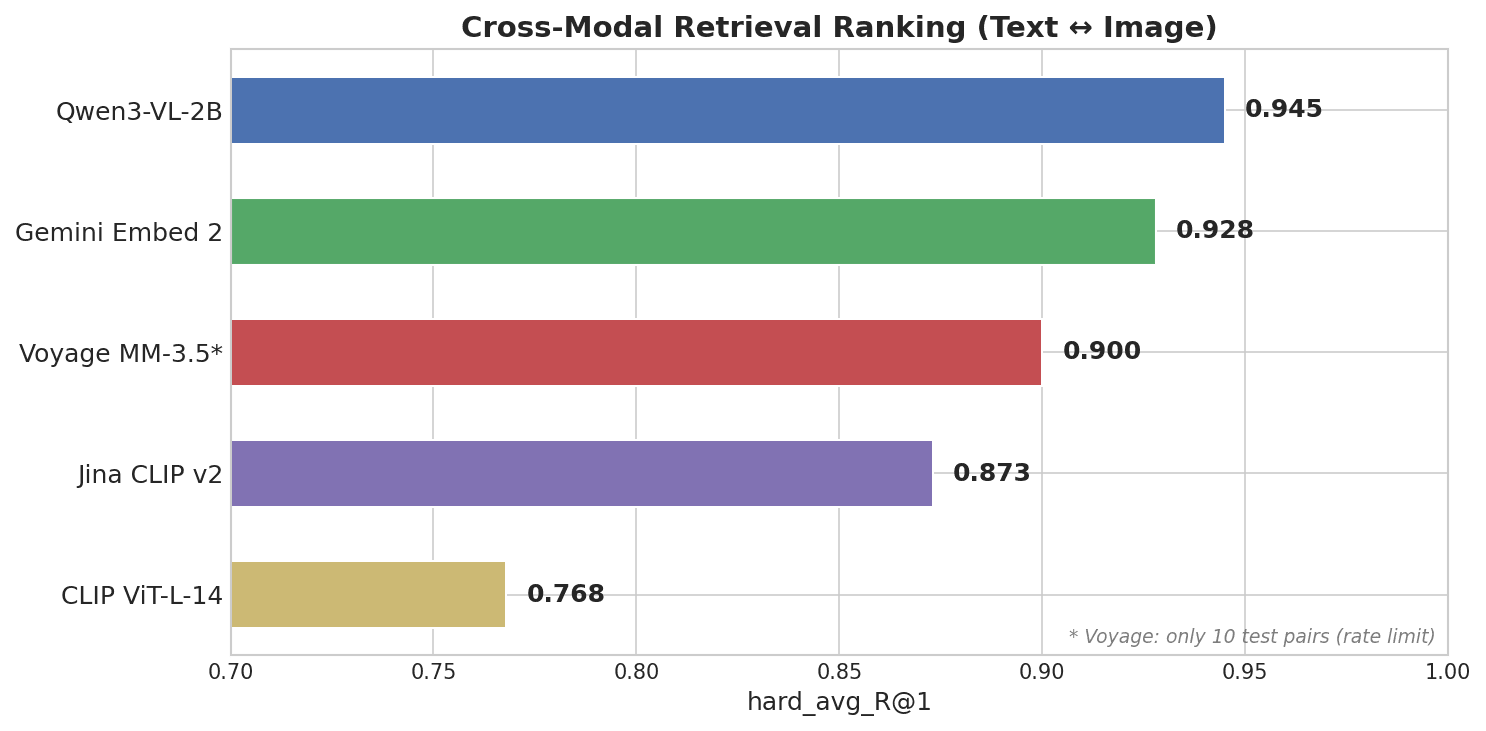 크로스 모달 검색 순위를 보여주는 가로 막대 차트: Qwen3-VL-2B가 0.945로 선두, 그 뒤를 Gemini Embed 2 0.928, Voyage MM-3.5 0.900, Jina CLIP v2 0.873, CLIP ViT-L-14 0.768이 따름
크로스 모달 검색 순위를 보여주는 가로 막대 차트: Qwen3-VL-2B가 0.945로 선두, 그 뒤를 Gemini Embed 2 0.928, Voyage MM-3.5 0.900, Jina CLIP v2 0.873, CLIP ViT-L-14 0.768이 따름
Alibaba의 Qwen 팀이 만든 오픈 소스 2B 매개변수 모델인 Qwen3-VL-2B가 모든 폐쇄형 소스 API를 앞서며 1위를 차지했습니다.
모달리티 갭이 차이의 대부분을 설명합니다. 임베딩 모델은 텍스트와 이미지를 동일한 벡터 공간에 매핑하지만, 실제로는 두 모달리티가 서로 다른 영역에 군집되는 경향이 있습니다. 모달리티 갭은 이 두 군집 사이의 L2 거리를 측정합니다. 갭이 작을수록 크로스 모달 검색이 더 쉬워집니다.
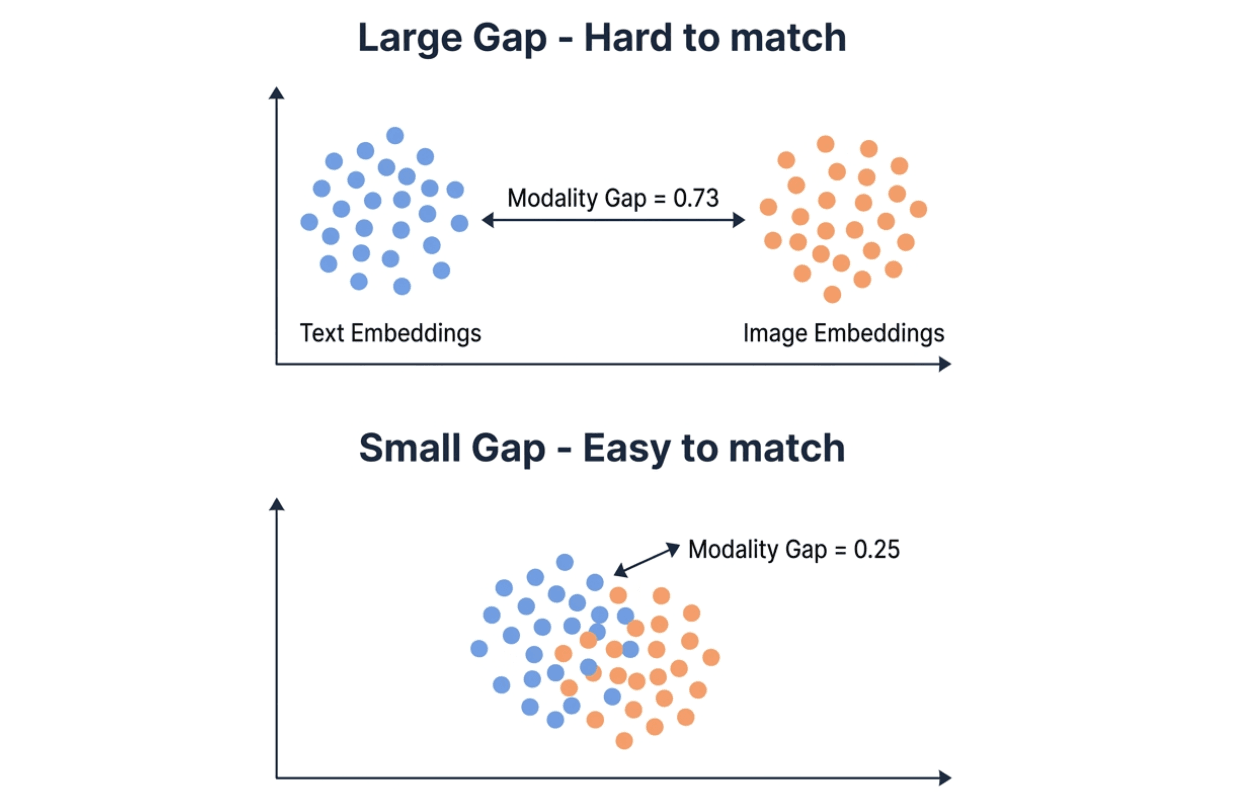 큰 모달리티 격차(0.73, 텍스트 및 이미지 임베딩 클러스터가 멀리 떨어져 있음)와 작은 모달리티 격차(0.25, 클러스터가 겹침)를 비교한 시각화 — 격차가 작을수록 크로스 모달 매칭이 더 쉬워짐
큰 모달리티 격차(0.73, 텍스트 및 이미지 임베딩 클러스터가 멀리 떨어져 있음)와 작은 모달리티 격차(0.25, 클러스터가 겹침)를 비교한 시각화 — 격차가 작을수록 크로스 모달 매칭이 더 쉬워짐
| 모델 | 점수 (R@1) | 모달리티 격차 | Params |
|---|---|---|---|
| Qwen3-VL-2B | 0.945 | 0.25 | 2B (오픈 소스) |
| Gemini Embedding 2 | 0.928 | 0.73 | 알 수 없음 (폐쇄형) |
| Voyage Multimodal 3.5 | 0.900 | 0.59 | 알 수 없음 (폐쇄형) |
| Jina CLIP v2 | 0.873 | 0.87 | ~1B |
| CLIP ViT-L-14 | 0.768 | 0.83 | 428M |
Qwen의 모달리티 격차는 0.25로, Gemini의 0.73의 대략 3분의 1 수준입니다. Milvus 같은 벡터 데이터베이스에서는 모달리티 격차가 작다는 것은 텍스트와 이미지 임베딩을 동일한 collection에 저장하고 둘 모두에 대해 직접 search할 수 있음을 의미합니다. 격차가 크면 크로스 모달 유사도 검색의 신뢰성이 낮아질 수 있으며, 이를 보완하기 위해 재랭킹 단계가 필요할 수 있습니다.
교차 언어 검색: 어떤 모델이 여러 언어 간 의미를 정렬할 수 있을까?
다국어 지식 베이스는 프로덕션에서 흔합니다. 사용자가 중국어로 질문하지만 답은 영어 문서에 있거나, 그 반대일 수도 있습니다. 임베딩 모델은 한 언어 내부에서만이 아니라 언어 간 의미를 정렬해야 합니다.
방법
우리는 세 가지 난이도 수준에 걸쳐 중국어와 영어 병렬 문장 쌍 166개를 구축했습니다:
 교차 언어 난이도 단계: 쉬움 단계는 我爱你를 I love you처럼 문자 그대로의 번역에 매핑하고, 중간 단계는 这道菜太咸了를 This dish is too salty처럼 하드 네거티브가 있는 의역 문장에 매핑하며, 어려움 단계는 画蛇添足 같은 중국어 관용구를 의미적으로 다른 하드 네거티브와 함께 gilding the lily에 매핑함
교차 언어 난이도 단계: 쉬움 단계는 我爱你를 I love you처럼 문자 그대로의 번역에 매핑하고, 중간 단계는 这道菜太咸了를 This dish is too salty처럼 하드 네거티브가 있는 의역 문장에 매핑하며, 어려움 단계는 画蛇添足 같은 중국어 관용구를 의미적으로 다른 하드 네거티브와 함께 gilding the lily에 매핑함
각 언어에는 또한 152개의 하드 네거티브 방해 항목이 있습니다.
채점:
- 모든 중국어 텍스트(정답 166개 + 방해 항목 152개)와 모든 영어 텍스트(정답 166개 + 방해 항목 152개)에 대해 임베딩을 생성합니다.
- 중국어 → 영어: 각 중국어 문장은 318개의 영어 텍스트에서 올바른 번역을 검색합니다.
- 영어 → 중국어: 반대 방향도 동일합니다.
- 최종 점수: hard_avg_R@1 = (zh→en 정확도 + en→zh 정확도) / 2
결과
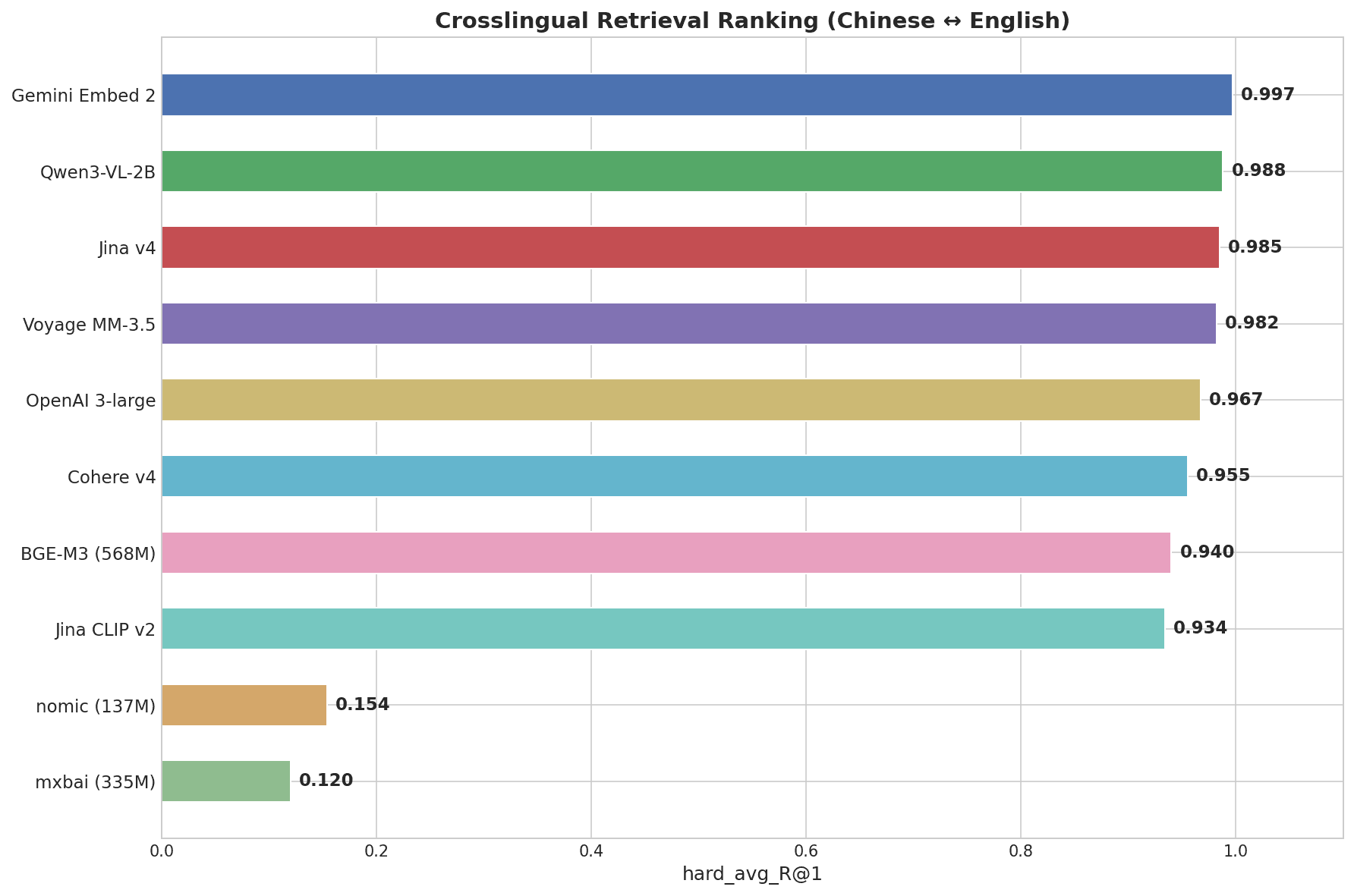 교차 언어 검색 순위를 보여주는 가로 막대 차트: Gemini Embed 2가 0.997로 선두, 이어 Qwen3-VL-2B가 0.988, Jina v4가 0.985, Voyage MM-3.5가 0.982, mxbai가 0.120까지 이어짐
교차 언어 검색 순위를 보여주는 가로 막대 차트: Gemini Embed 2가 0.997로 선두, 이어 Qwen3-VL-2B가 0.988, Jina v4가 0.985, Voyage MM-3.5가 0.982, mxbai가 0.120까지 이어짐
Gemini Embedding 2는 0.997을 기록해 테스트한 모든 모델 중 가장 높은 점수를 받았습니다. "画蛇添足" → "gilding the lily"와 같은 쌍이 패턴 매칭이 아니라 언어 간 진정한 의미론적 이해를 요구하는 Hard 단계에서 완벽한 1.000을 기록한 유일한 모델이었습니다.
| 모델 | 점수 (R@1) | 쉬움 | 중간 | 어려움 (관용구) |
|---|---|---|---|---|
| Gemini Embedding 2 | 0.997 | 1.000 | 1.000 | 1.000 |
| Qwen3-VL-2B | 0.988 | 1.000 | 1.000 | 0.969 |
| Jina Embeddings v4 | 0.985 | 1.000 | 1.000 | 0.969 |
| Voyage Multimodal 3.5 | 0.982 | 1.000 | 1.000 | 0.938 |
| OpenAI 3-large | 0.967 | 1.000 | 1.000 | 0.906 |
| Cohere Embed v4 | 0.955 | 1.000 | 0.980 | 0.875 |
| BGE-M3 (568M) | 0.940 | 1.000 | 0.960 | 0.844 |
| nomic-embed-text (137M) | 0.154 | 0.300 | 0.120 | 0.031 |
| mxbai-embed-large (335M) | 0.120 | 0.220 | 0.080 | 0.031 |
상위 7개 모델은 모두 전체 점수에서 0.93을 넘습니다. 실제 차이는 Hard 단계(중국어 관용구)에서 나타납니다. nomic-embed-text와 mxbai-embed-large는 모두 영어 중심의 경량 모델로, 교차 언어 작업에서 거의 0에 가까운 점수를 기록합니다.
핵심 정보 검색: 모델은 32K 토큰 문서에서 바늘을 찾을 수 있을까?
RAG 시스템은 종종 긴 문서 — 법률 계약서, 연구 논문, 비정형 데이터가 포함된 내부 보고서 — 를 처리합니다. 문제는 임베딩 모델이 수천 자의 주변 텍스트 속에 묻힌 특정 사실 하나를 여전히 찾아낼 수 있는지입니다.
방법
우리는 다양한 길이(4K~32K 문자)의 Wikipedia 문서를 건초더미로 삼고, 하나의 조작된 사실 — 바늘 — 을 시작, 25%, 50%, 75%, 끝 등 서로 다른 위치에 삽입했습니다. 모델은 쿼리 임베딩을 기반으로 어떤 버전의 문서에 바늘이 포함되어 있는지 판단해야 합니다.
예시:
- 바늘: "The Meridian Corporation reported quarterly revenue of $847.3 million in Q3 2025."
- 쿼리: "Meridian Corporation의 분기 매출은 얼마였나요?"
- 건초더미: 광합성에 관한 32,000자짜리 Wikipedia 문서로, 그 안 어딘가에 바늘이 숨겨져 있습니다.
채점:
- 쿼리, 바늘이 포함된 문서, 포함되지 않은 문서에 대한 임베딩을 생성합니다.
- 쿼리가 바늘이 포함된 문서와 더 유사하면 적중으로 계산합니다.
- 모든 문서 길이와 바늘 위치에 걸쳐 평균 정확도를 계산합니다.
- 최종 지표: overall_accuracy 및 degradation_rate(가장 짧은 문서에서 가장 긴 문서로 갈 때 정확도가 얼마나 떨어지는지).
결과
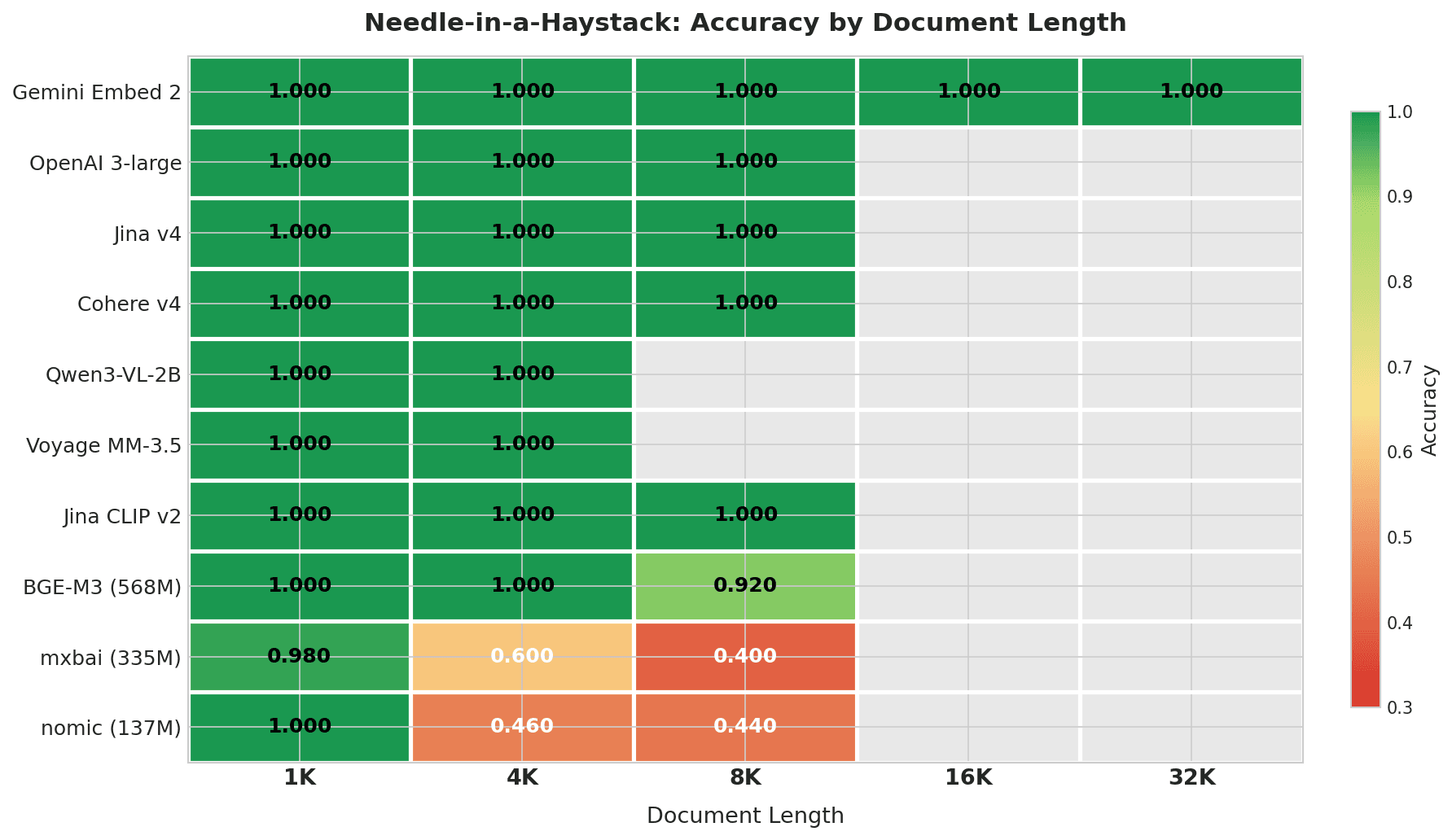 문서 길이별 Needle-in-a-Haystack 정확도를 보여주는 히트맵: Gemini Embed 2는 32K까지 모든 길이에서 1.000을 기록; 상위 7개 모델은 각자의 컨텍스트 창 내에서 완벽한 점수; mxbai와 nomic은 4K+에서 급격히 저하
문서 길이별 Needle-in-a-Haystack 정확도를 보여주는 히트맵: Gemini Embed 2는 32K까지 모든 길이에서 1.000을 기록; 상위 7개 모델은 각자의 컨텍스트 창 내에서 완벽한 점수; mxbai와 nomic은 4K+에서 급격히 저하
Gemini Embedding 2는 전체 4K–32K 범위에서 테스트된 유일한 모델이며, 모든 길이에서 완벽한 점수를 기록했습니다. 이 테스트의 다른 어떤 모델도 32K에 도달하는 컨텍스트 창을 가지고 있지 않습니다.
| 모델 | 1K | 4K | 8K | 16K | 32K | 전체 | 저하 |
|---|---|---|---|---|---|---|---|
| Gemini Embedding 2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0% |
| OpenAI 3-large | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Jina Embeddings v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Cohere Embed v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Qwen3-VL-2B | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Voyage Multimodal 3.5 | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Jina CLIP v2 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| BGE-M3 (568M) | 1.000 | 1.000 | 0.920 | — | — | 0.973 | 8% |
| mxbai-embed-large (335M) | 0.980 | 0.600 | 0.400 | — | — | 0.660 | 58% |
| nomic-embed-text (137M) | 1.000 | 0.460 | 0.440 | — | — | 0.633 | 56% |
"—"는 문서 길이가 모델의 컨텍스트 창을 초과한다는 뜻입니다.
상위 7개 모델은 각자의 컨텍스트 창 내에서 완벽한 점수를 기록했습니다. BGE-M3는 8K(0.920)에서 흔들리기 시작합니다. 경량 모델(mxbai와 nomic)은 불과 4K 문자 — 대략 1,000토큰 — 에서 0.4–0.6까지 떨어집니다. mxbai의 경우, 이 하락은 부분적으로 512토큰 컨텍스트 창이 문서의 대부분을 잘라내기 때문입니다.
MRL 차원 압축: 256차원에서 얼마나 많은 품질을 잃나요?
Matryoshka Representation Learning (MRL)은 벡터의 처음 N개 차원이 그 자체로 의미를 갖도록 만드는 훈련 기법입니다. 3072차원 벡터를 256으로 잘라도 여전히 의미적 품질의 대부분을 유지합니다. 차원이 적을수록 벡터 데이터베이스의 저장 공간 및 메모리 비용이 낮아집니다 — 3072에서 256차원으로 줄이면 저장 공간이 12배 감소합니다.
 MRL 차원 절단을 보여주는 그림: 전체 품질의 3072차원, 95%의 1024, 90%의 512, 85%의 256 — 256차원에서 12배 저장 공간 절감
MRL 차원 절단을 보여주는 그림: 전체 품질의 3072차원, 95%의 1024, 90%의 512, 85%의 256 — 256차원에서 12배 저장 공간 절감
방법
우리는 STS-B 벤치마크에서 사람의 주석이 달린 유사도 점수(0–5)가 있는 150개의 문장 쌍을 사용했습니다. 각 모델에 대해 전체 차원에서 임베딩을 생성한 다음, 1024, 512, 256으로 잘랐습니다.
 사람 유사도 점수가 포함된 문장 쌍을 보여주는 STS-B 데이터 예시: A girl is styling her hair vs A girl is brushing her hair 점수 2.5; A group of men play soccer on the beach vs A group of boys are playing soccer on the beach 점수 3.6
사람 유사도 점수가 포함된 문장 쌍을 보여주는 STS-B 데이터 예시: A girl is styling her hair vs A girl is brushing her hair 점수 2.5; A group of men play soccer on the beach vs A group of boys are playing soccer on the beach 점수 3.6
채점:
- 각 차원 수준에서, 각 문장 쌍의 임베딩 간 코사인 유사도를 계산합니다.
- Spearman's ρ(순위 상관)를 사용해 모델의 유사도 순위를 사람의 순위와 비교합니다.
Spearman's ρ란 무엇인가요? 두 순위가 얼마나 잘 일치하는지 측정합니다. 사람이 쌍 A를 가장 유사한 것으로, B를 두 번째로, C를 가장 덜 유사한 것으로 순위를 매겼고 — 모델의 코사인 유사도가 동일한 순서 A > B > C를 생성한다면 — ρ는 1.0에 가까워집니다. ρ가 1.0이면 완벽한 일치를 의미합니다. ρ가 0이면 상관관계가 없음을 의미합니다.
최종 지표: spearman_rho(높을수록 좋음) 및 min_viable_dim(품질이 전체 차원 성능의 5% 이내로 유지되는 가장 작은 차원).
결과
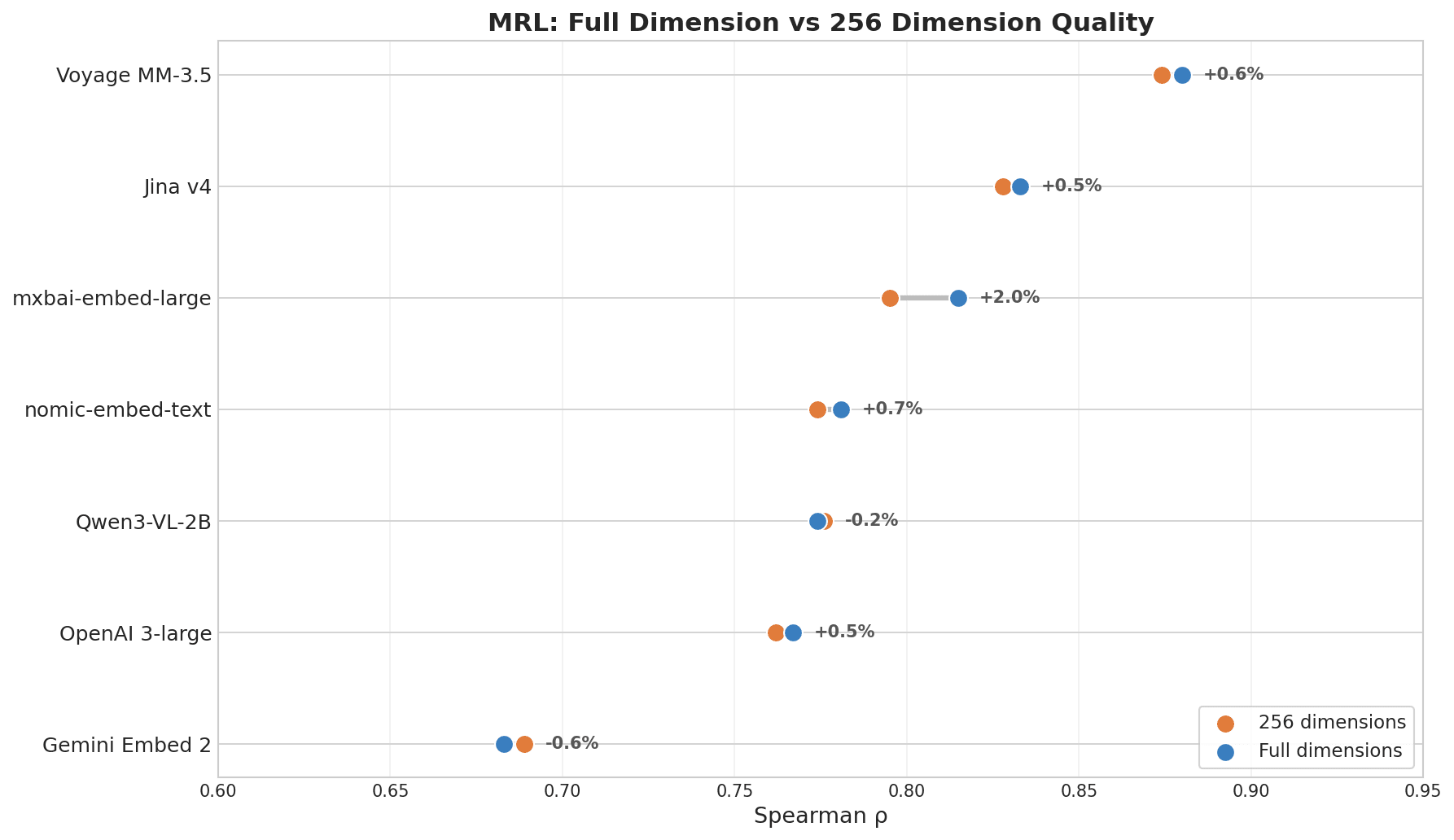 MRL 전체 차원 vs 256 차원 품질을 보여주는 점 도표: Voyage MM-3.5가 +0.6% 변화로 선두, Jina v4 +0.5%, Gemini Embed 2는 -0.6%로 최하위
MRL 전체 차원 vs 256 차원 품질을 보여주는 점 도표: Voyage MM-3.5가 +0.6% 변화로 선두, Jina v4 +0.5%, Gemini Embed 2는 -0.6%로 최하위
Milvus 또는 다른 벡터 데이터베이스에서 차원을 잘라내 저장 비용을 줄일 계획이라면, 이 결과는 중요합니다.
| Model | ρ (full dim) | ρ (256 dim) | Decay |
|---|---|---|---|
| Voyage Multimodal 3.5 | 0.880 | 0.874 | 0.7% |
| Jina Embeddings v4 | 0.833 | 0.828 | 0.6% |
| mxbai-embed-large (335M) | 0.815 | 0.795 | 2.5% |
| nomic-embed-text (137M) | 0.781 | 0.774 | 0.8% |
| OpenAI 3-large | 0.767 | 0.762 | 0.6% |
| Gemini Embedding 2 | 0.683 | 0.689 | -0.8% |
Voyage와 Jina v4가 앞서는 이유는 둘 다 MRL을 목표로 명시적으로 학습되었기 때문입니다. 차원 압축은 모델 크기와는 거의 관련이 없으며 — 모델이 이를 위해 학습되었는지가 중요합니다.
Gemini 점수에 대한 참고 사항: MRL 순위는 모델이 절단 후 품질을 얼마나 잘 보존하는지를 반영하는 것이지, 전체 차원 검색 성능이 얼마나 좋은지를 나타내는 것은 아닙니다. Gemini의 전체 차원 검색 성능은 강력합니다 — 교차 언어 및 핵심 정보 결과가 이미 이를 입증했습니다. 다만 축소에 최적화되지 않았을 뿐입니다. 차원 압축이 필요하지 않다면, 이 지표는 적용되지 않습니다.
어떤 임베딩 모델을 사용해야 할까요?
모든 항목에서 이기는 단일 모델은 없습니다. 전체 점수표는 다음과 같습니다:
| Model | Params | Cross-Modal | Cross-Lingual | Key Info | MRL ρ |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Undisclosed | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage Multimodal 3.5 | Undisclosed | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina Embeddings v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| OpenAI 3-large | Undisclosed | — | 0.967 | 1.000 | 0.760 |
| Cohere Embed v4 | Undisclosed | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
"—"는 모델이 해당 모달리티나 기능을 지원하지 않는다는 의미입니다. CLIP은 참고용 2021년 기준선입니다.
두드러지는 점은 다음과 같습니다:
- 크로스모달: Qwen3-VL-2B(0.945)가 1위, Gemini(0.928)가 2위, Voyage(0.900)가 3위. 오픈소스 2B 모델이 모든 폐쇄형 소스 API를 이겼습니다. 결정적 요인은 파라미터 수가 아니라 모달리티 격차였습니다.
- 크로스링구얼: Gemini(0.997)가 선두 — 관용구 수준 정렬에서 완벽한 점수를 받은 유일한 모델입니다. 상위 8개 모델은 모두 0.93을 넘습니다. 영어 전용 경량 모델은 거의 0점에 가깝습니다.
- 핵심 정보: API와 대형 오픈소스 모델은 8K까지 완벽한 점수를 기록합니다. 335M 미만 모델은 4K에서 성능 저하가 시작됩니다. Gemini는 32K를 완벽한 점수로 처리하는 유일한 모델입니다.
- MRL 차원 압축: Voyage(0.880)와 Jina v4(0.833)가 선두이며, 256차원에서 1% 미만의 손실을 보입니다. Gemini(0.668)는 최하위입니다 — 전체 차원에서는 강하지만, 절단에는 최적화되어 있지 않습니다.
선택 방법: 의사결정 플로차트
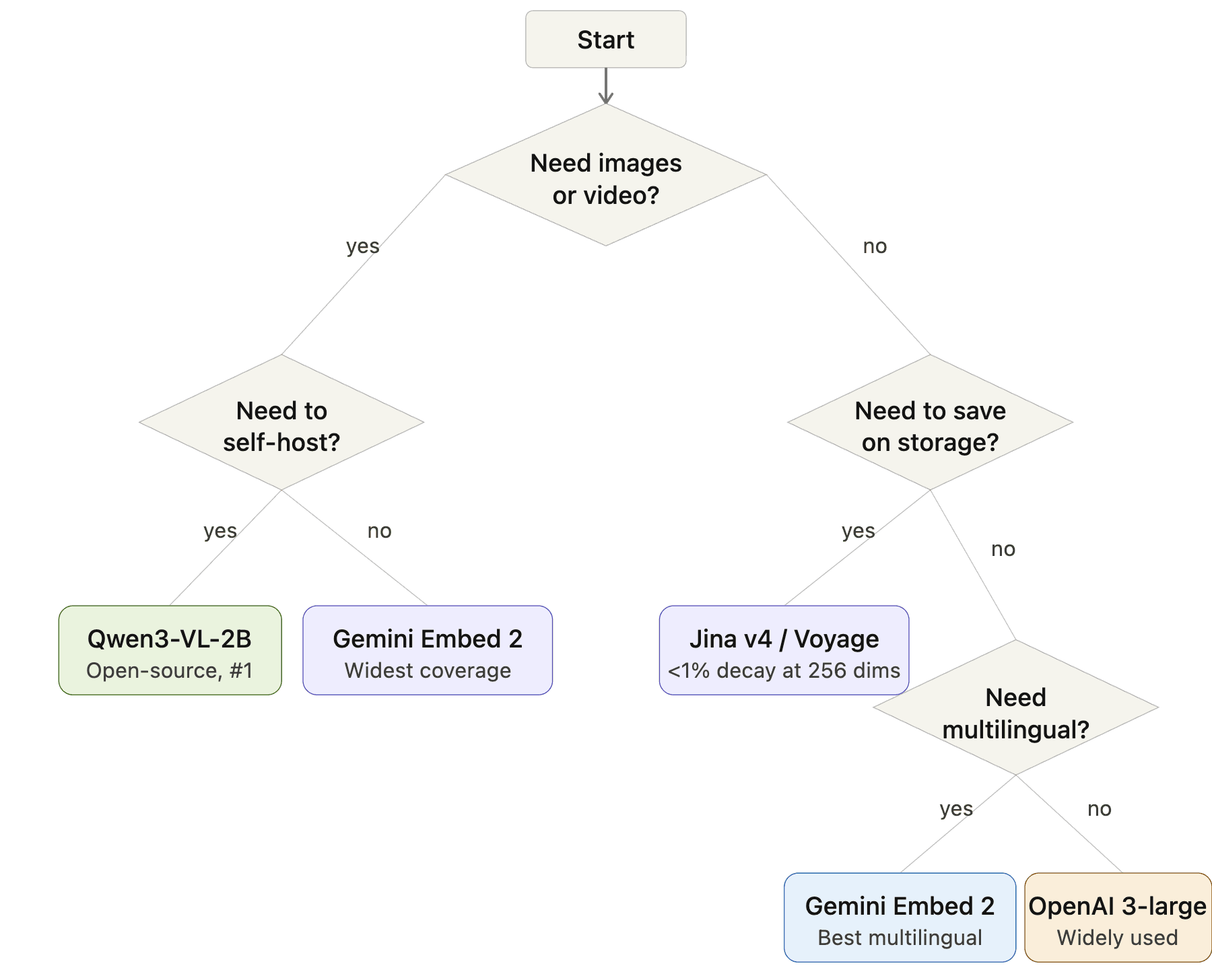 임베딩 모델 선택 플로차트: 시작 → 이미지나 비디오가 필요한가? → 예: 자체 호스팅이 필요한가? → 예: Qwen3-VL-2B, 아니요: Gemini Embedding 2. 이미지 없음 → 스토리지를 절약해야 하는가? → 예: Jina v4 또는 Voyage, 아니요: 다국어가 필요한가? → 예: Gemini Embedding 2, 아니요: OpenAI 3-large
임베딩 모델 선택 플로차트: 시작 → 이미지나 비디오가 필요한가? → 예: 자체 호스팅이 필요한가? → 예: Qwen3-VL-2B, 아니요: Gemini Embedding 2. 이미지 없음 → 스토리지를 절약해야 하는가? → 예: Jina v4 또는 Voyage, 아니요: 다국어가 필요한가? → 예: Gemini Embedding 2, 아니요: OpenAI 3-large
최고의 올라운더: Gemini Embedding 2
종합적으로 볼 때, Gemini Embedding 2는 이 벤치마크에서 가장 강력한 전체 모델입니다.
강점: 크로스링구얼(0.997)과 핵심 정보 검색(32K까지 모든 길이에서 1.000)에서 1위. 크로스모달(0.928)에서 2위. 가장 넓은 모달리티 범위 — 대부분의 모델이 최대 세 가지에 그치는 반면, 다섯 가지 모달리티(텍스트, 이미지, 비디오, 오디오, PDF)를 지원합니다.
약점: MRL 압축(ρ = 0.668)에서 최하위. 크로스모달에서는 오픈소스 Qwen3-VL-2B에 밀렸습니다.
차원 압축이 필요 없다면, Gemini는 크로스링구얼 + 긴 문서 검색의 조합에서 실질적인 경쟁자가 없습니다. 하지만 크로스모달 정밀도나 스토리지 최적화가 필요하다면, 특화 모델이 더 나은 성능을 냅니다.
한계
- 고려할 만한 모든 모델을 포함하지는 않았습니다 — NVIDIA의 NV-Embed-v2와 Jina의 v5-text도 목록에 있었지만 이번 라운드에는 포함되지 않았습니다.
- 텍스트와 이미지 모달리티에 집중했습니다. 비디오, 오디오, PDF 임베딩(일부 모델이 지원을 주장하더라도)은 다루지 않았습니다.
- 코드 검색 및 기타 도메인 특화 시나리오는 범위 밖이었습니다.
- 샘플 크기가 비교적 작았기 때문에, 모델 간의 근소한 순위 차이는 통계적 노이즈 범위에 들어갈 수 있습니다.
이 글의 결과는 1년 안에 구식이 될 것입니다. 새로운 모델은 끊임없이 출시되고, 리더보드는 릴리스마다 재편됩니다. 더 오래가는 투자는 자체 평가 파이프라인을 구축하는 것입니다 — 데이터 유형, 쿼리 패턴, 문서 길이를 정의하고, 새 모델이 출시될 때 자체 테스트에 통과시켜 보세요. MTEB, MMTEB, MMEB 같은 공개 벤치마크는 모니터링할 가치가 있지만, 최종 판단은 항상 자신의 데이터에서 나와야 합니다.
저희 벤치마크 코드는 GitHub에 오픈소스로 공개되어 있습니다 — 포크해서 사용 사례에 맞게 조정해 보세요.
임베딩 모델을 선택했다면, 이제 그 벡터를 대규모로 저장하고 검색할 장소가 필요합니다. Milvus는 바로 이를 위해 구축된, 43K+ GitHub stars를 보유한 세계에서 가장 널리 채택된 오픈소스 벡터 데이터베이스입니다 — MRL로 절단된 차원, 혼합 멀티모달 컬렉션, dense 및 sparse 벡터를 결합한 하이브리드 검색을 지원하며, 노트북에서 수십억 개의 벡터까지 확장됩니다.
- Milvus Quickstart guide로 시작하거나
pip install pymilvus로 설치하세요. - 임베딩 모델 통합, 벡터 인덱싱 전략 또는 프로덕션 확장에 대해 질문하려면 Milvus Slack 또는 Milvus Discord에 참여하세요.
- RAG 아키텍처를 함께 살펴보려면 무료 Milvus Office Hours 세션 예약을 하세요 — 모델 선택, 컬렉션 스키마 설계, 성능 튜닝을 도와드릴 수 있습니다.
- 인프라 작업을 건너뛰고 싶다면 Zilliz Cloud(관리형 Milvus)에서 시작할 수 있는 무료 티어를 제공합니다.
엔지니어가 프로덕션 RAG용 임베딩 모델을 선택할 때 자주 나오는 몇 가지 질문:
Q: 지금은 텍스트 데이터만 있어도 멀티모달 임베딩 모델을 사용해야 하나요?
로드맵에 따라 다릅니다. 파이프라인에 향후 6~12개월 내 이미지, PDF 또는 다른 모달리티가 추가될 가능성이 높다면 Gemini Embedding 2나 Voyage Multimodal 3.5 같은 멀티모달 모델로 시작하면 나중에 고통스러운 마이그레이션을 피할 수 있습니다 — 전체 데이터셋을 다시 임베딩할 필요가 없습니다. 가까운 미래에도 텍스트 전용이라고 확신한다면 OpenAI 3-large나 Cohere Embed v4 같은 텍스트 중심 모델이 더 나은 가격 대비 성능을 제공합니다.
Q: MRL 차원 압축은 벡터 데이터베이스에서 실제로 얼마나 많은 스토리지를 절약하나요?
3072차원에서 256차원으로 줄이면 벡터당 스토리지가 12배 감소합니다. float32에서 1억 개의 벡터를 가진 Milvus 컬렉션의 경우, 대략 1.14 TB → 95 GB입니다. 핵심은 모든 모델이 잘림을 잘 처리하는 것은 아니라는 점입니다 — Voyage Multimodal 3.5와 Jina Embeddings v4는 256차원에서 품질 손실이 1% 미만인 반면, 다른 모델들은 크게 저하됩니다.
Q: Qwen3-VL-2B가 교차 모달 검색에서 정말 Gemini Embedding 2보다 나은가요?
저희 벤치마크에서는 그렇습니다 — 거의 동일한 방해 요소가 있는 어려운 교차 모달 검색에서 Qwen3-VL-2B는 0.945점을 기록한 반면 Gemini는 0.928점을 기록했습니다. 주된 이유는 Qwen의 모달리티 간격이 훨씬 작기 때문입니다(0.25 대 0.73). 이는 텍스트와 이미지 embeddings가 벡터 공간에서 더 가깝게 군집된다는 의미입니다. 다만 Gemini는 다섯 가지 모달리티를 지원하는 반면 Qwen은 세 가지를 지원하므로, 오디오나 PDF 임베딩이 필요하다면 Gemini가 유일한 옵션입니다.
Q: 이러한 임베딩 모델을 Milvus와 직접 사용할 수 있나요?
예. 이 모든 모델은 표준 float 벡터를 출력하며, 이를 Milvus에 삽입하고 cosine similarity, L2 거리 또는 내적으로 검색할 수 있습니다. PyMilvus는 모든 임베딩 모델과 함께 작동합니다 — 모델의 SDK로 벡터를 생성한 다음 Milvus에 저장하고 검색하세요. MRL로 잘린 벡터의 경우, 컬렉션 생성 시 컬렉션의 차원을 목표값(예: 256)으로 설정하기만 하면 됩니다.

계속 읽기

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.