




VDBBench, 벡터 데이터베이스를 위한 비용 인식 벤치마킹 추가
작년에 저희는 벡터 데이터베이스 벤치마킹을 프로덕션 워크로드에 더 가깝게 만들기 위해 VectorDBBench 1.0을 출시했습니다. 고정된 벤치마크 데이터에서 피크 QPS만 테스트하는 대신, VectorDBBench(VDBBench라고도 함)를 사용하면 팀은 수집, 필터링, 리콜, 지연 시간, 동시성, 사용자 지정 데이터셋 등 자체 프로덕션 시스템을 더 가깝게 반영하는 워크로드 패턴을 사용해 벡터 데이터베이스를 평가할 수 있습니다.
VDBBench의 최신 릴리스에는 새로운 차원인 비용이 추가되었습니다.
프로덕션 팀은 성능만으로 벡터 데이터베이스를 선택하는 경우가 거의 없습니다. 목표 QPS에 도달하는 데 드는 비용, 해당 비용 모델에서 P99가 어떻게 동작하는지, 삽입된 데이터를 언제 검색할 수 있게 되는지, 언제 완전히 인덱싱되는지, 페이로드 크기가 검색에 어떤 영향을 미치는지, 시스템이 다수의 테넌트에서 어떻게 동작하는지, 유휴 상태 이후 첫 번째 쿼리에서 어떤 일이 발생하는지를 알아야 합니다. 이제 이러한 질문들이 VDBBench의 일부가 되었습니다.
이러한 새로운 비용 인식 벤치마크가 실제로 어떻게 작동하는지 보여주기 위해, 저희는 일반적으로 평가되는 세 가지 관리형 벡터 데이터베이스 제품인 Zilliz Cloud, Turbopuffer, and Pinecone.을 테스트했습니다. 결과는 삽입 준비 상태, 페이로드 검색, 멀티테넌트 검색, 콜드 지연 시간, 비용-성능 트레이드오프를 비교하는 차트와 표와 함께 새로운 VDBBench 비용 리더보드,에 게시되었습니다.
리더보드는 결과를 읽는 한 가지 방법일 뿐이며, 특정 시점의 세 제품에 대한 스냅샷입니다. VDBBench는 오픈 소스이므로 팀은 이러한 사례를 재현하거나, 리더보드에 없는 제품을 벤치마킹하거나, 워크로드를 자체 프로덕션 유사 데이터에 맞게 조정할 수도 있습니다.
목표는 보편적인 승자를 가리는 것이 아니라, 팀이 자신의 워크로드, 성능 목표, 예산에 가장 적합한 벡터 데이터베이스를 선택하도록 돕는 것입니다.
- 참고 자료: VectorDBBench GitHub | VDBBench 리더보드
VDBBench의 새로운 기능
이번 릴리스에는 피크 QPS 리더보드에서 종종 놓치는 프로덕션 동작을 측정하는 네 가지 클라우드 지향 벤치마크 사례가 추가되었습니다.
| 사례 | 측정 항목 | 중요한 이유 |
|---|---|---|
| CloudInsertCase | 삽입 완료, 검색 가능 상태, 완전 인덱싱 상태 및 쓰기 비용 | RAG, 카탈로그, 에이전트 메모리에서는 최신성과 백필 비용이 중요합니다 |
| CloudPayloadSearchCase | QPS, P99 지연 시간, 리콜 및 응답 페이로드 형태 | 벡터 또는 메타데이터를 반환하면 검색 비용 구조가 달라질 수 있습니다 |
| MultitenantSearchCase | 다수의 테넌트 또는 네임스페이스 전반의 처리량 | SaaS 워크로드는 단일 테넌트 검색과는 다르게 라우팅 및 파티션 동작에 부하를 줍니다 |
| CloudColdLatencyCase | 유휴 상태 이후 첫 번째 쿼리와 워밍된 쿼리 경로 비교 | 콜드 스타트 동작은 저빈도 테넌트와 에이전트 메모리에 중요합니다 |
이러한 사례에 더해, Cost Leaderboard는 각 제품의 측정된 서빙 한계에서 목표 QPS 수준별 운영 비용을 모델링하는 비용-파레토 뷰를 추가합니다. 구매 결정은 보통 성능과 비용이 만나는 지점에 달려 있기 때문입니다.
VDBBench 비용 리더보드는 이러한 사례를 사용해 관리형 제품을 공개적으로 비교합니다. 이 사례들은 오픈 소스 VDBBench에 포함되어 제공되므로, 팀은 리더보드에 표시되지 않은 제품과 워크로드를 포함해 자체 평가에 재사용할 수 있습니다.
테스트 대상: Zilliz Cloud vs. Turbopuffer vs. Pinecone
이번 첫 비용 인식 실행에서는 일반적으로 평가되는 세 가지 관리형 벡터 데이터베이스 제품을 테스트했습니다. 모든 제품은 2026년 5월 10일 AWS US West(us-west-2)에서 벤치마킹되었습니다. 이들의 운영 모델은 서로 다르므로, 결과는 단일 순위가 아니라 워크로드 적합성 측면에서 해석해야 합니다.
| 제품 | 이 벤치마크에서의 역할 |
|---|---|
| Zilliz Cloud | Milvus 제작자가 만든 관리형 클라우드 벡터 데이터베이스 및 벡터 레이크베이스로, Tiered 및 Capacity 구성 전반에서 테스트됨 |
| Turbopuffer | unpinned 및 pinned 모드 전반에서 테스트된 서버리스 벡터 데이터베이스 |
| Pinecone Serverless | 일반적인 프로덕션 기준점으로 사용되는 성숙한 저운영 서버리스 벡터 데이터베이스 |
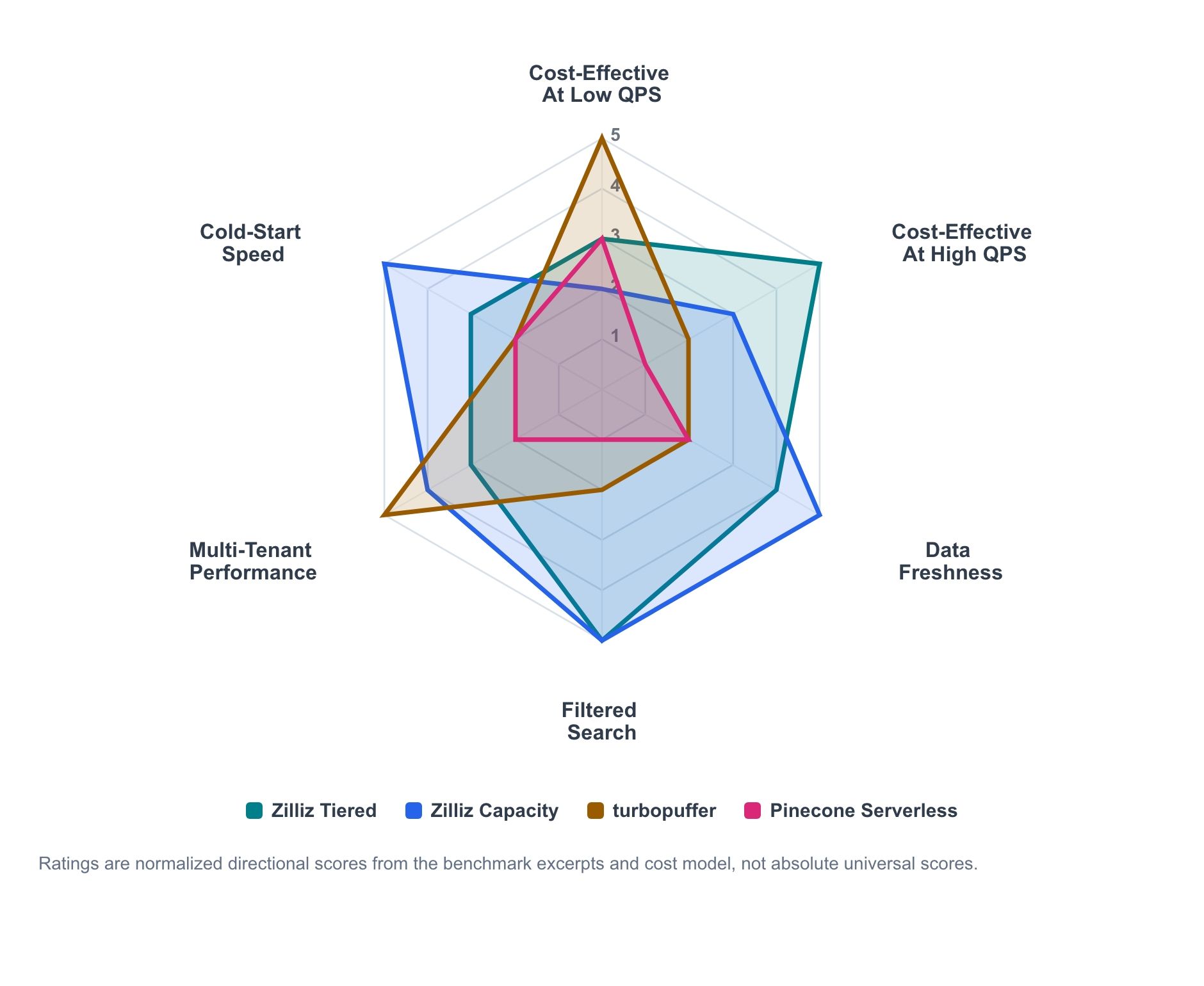
그림 1. 벤치마크 발췌와 비용 모델링을 기반으로 한 방향성 있는 워크로드 적합도 요약. 점수는 워크로드 차원 간 비교를 위해 정규화되었으며, 보편적인 절대 순위로 읽어서는 안 됩니다.
레이더 차트는 벤치마크 발췌와 비용 모델에서 나온 방향성 신호를 요약합니다. 이는 절대적인 성적표가 아니라, 각 제품이 어디에서 가장 강점을 보이는 경향이 있는지를 나타내는 지도입니다.
- Zilliz Cloud Tiered는 사용률이 증가함에 따라 확장되는 경제적인 활성 서빙 라인입니다.
- Zilliz Cloud Capacity는 예측 가능한 서빙, 최신성, 콜드 동작을 위한 더 높은 제어 프로파일입니다.
- Turbopuffer는 사용량 기반 과금 서버리스 경제성과 네임스페이스 지향 처리량이 워크로드와 일치하는 경우에 가장 강합니다.
- Pinecone은 특정 테스트에서 비용 대비 성능의 최전선이 아니더라도, 여전히 유용한 저운영 서버리스 기준선입니다.
주요 패턴은 명확합니다. 서버리스 경제성은 낮은 지속 QPS에서 매력적일 수 있습니다. 프로비저닝된 용량은 사용률이 증가함에 따라 더 경쟁력 있어집니다. 최신성, 필터링된 검색, 페이로드 크기, 테넌트 수, 콜드 동작은 모두 결정을 바꿀 수 있습니다.
데이터셋 및 워크로드
비용 인식 사례는 두 가지 워크로드 형태를 사용합니다.
- 단일 테넌트 LAION 100M: 1억 개의 768차원 밀집 벡터. 이는 페이로드 크기, 필터, 재현율, 지속 QPS가 중요한 대규모 프로덕션 컬렉션을 나타냅니다.
- 멀티테넌트 Cohere 10M: 1,000개의 테넌트에 무작위로 분할된 1,000만 개의 768차원 밀집 벡터 — 테넌트당 약 1만 개의 벡터. 이는 각 테넌트가 더 작은 데이터셋을 갖지만, 시스템이 많은 네임스페이스 또는 테넌트 파티션을 효율적으로 라우팅하고 서빙해야 하는 SaaS 스타일 워크로드를 나타냅니다.
아래 발췌는 결과의 형태를 보여줍니다. 전체 매트릭스, 클라이언트 정의 및 재현 세부 정보의 출처는 Cost Leaderboard와 VectorDBBench 저장소입니다.
CloudInsertCase: 삽입되었다고 항상 준비된 것은 아닙니다
삽입 성능은 하나의 숫자가 아닙니다. 관리형 벡터 데이터베이스는 해당 데이터가 의도한 인덱스 경로를 통해 안전하게 검색될 수 있기 전에 클라이언트로부터 데이터를 수락할 수 있습니다. 프로덕션 워크로드의 경우, 팀은 삽입 작업이 완료되는 시점, 데이터가 검색 가능해지는 시점, 백그라운드 인덱싱이 완전히 따라잡는 시점을 알아야 합니다.
CloudInsertCase는 쓰기-서빙 라이프사이클을 측정합니다. 이는 RAG 코퍼스 새로 고침, 제품 카탈로그 업데이트, 에이전트 메모리 쓰기, 데이터 백필에 중요합니다. 이러한 시스템에서는 "삽입 수락됨"만으로는 충분하지 않습니다. 운영상의 질문은 새로 쓰인 데이터를 프로덕션 성능으로 안정적으로 검색할 수 있는 시점입니다.
| 제품 / 모드 | 배치 크기 | 삽입 시간 | 검색 가능 대기 | 완전 인덱싱 대기 | 쓰기 비용 |
|---|---|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 10,000 | 3.2시간 | 0 ms | 1.9분 | $9.50 |
| Zilliz Cloud Tiered 4CU | 10,000 | 4.1시간 | 0 ms | 10.9분 | $6.34 |
| Turbopuffer (backpressure off) | 10,000 | 1.8시간 | 6.4시간 | 2.0분 | $302 |
| Pinecone Serverless | 10,000 | 72.4시간 | 0 ms | 127 ms | $1,180 |
표 1. LAION 100M 배치-10k 삽입 발췌. 비용과 타이밍은 현재 리더보드 실행 결과입니다. 프로비저닝된 Zilliz 구성의 경우 쓰기 비용은 로드 및 인덱싱 기간 동안 소비된 CU-시간 비용이며, Turbopuffer와 Pinecone의 경우 계량된 쓰기 요금입니다. 삽입됨, 검색 가능, 완전 인덱싱 상태에 대한 클라이언트 정의와 함께 타이밍을 읽으십시오(VDBBench 소스에서 클라이언트별로 정의됨).
배치 크기는 제품별 수치를 바꿉니다.
- Turbopuffer는 대용량 배치에서 강력한 원시 수집 성능을 보이며, 특히 백프레셔를 비활성화했을 때 — 가장 공격적인 수집 모드에서 — 그렇습니다. batch-10k 경로에서는 삽입을 빠르게 완료하지만, 검색 가능 대기가 전체 준비 완료 창의 대부분을 차지합니다.
- Zilliz Cloud는 배치 크기 전반에서 더 안정적입니다. 테스트한 Capacity 및 Tiered 구성에서는 삽입 완료 직후 데이터가 검색 가능해지며, 남은 완전 인덱싱 대기는 분 단위로 측정됩니다.
- Pinecone Serverless는 이 테스트에서 더 느린 대량 수집 기준선입니다. 데이터가 수락되면, 이 실행들에서는 추가 검색 가능 및 완전 인덱싱 대기가 사실상 0이지만, 삽입 단계 자체가 훨씬 더 오래 걸립니다.
제품에 대한 해석은 워크로드의 형태에 따라 달라집니다.
- Zilliz는 새로운 데이터가 예측 가능한 비용으로 빠르게 검색 가능하고 인덱싱되어야 하는 워크플로에 적합합니다.
- Turbopuffer는 워크로드가 더 긴 준비 완료 창을 감수할 수 있는 경우, 수락된 대규모 백필에 적합합니다.
- Pinecone은 대량 적재 속도나 비용보다 운영 단순성이 더 중요한 저용량 서버리스 수집 패턴에 적합합니다.
대량 로딩은 또한 비용 이벤트입니다. 이 LAION 100M 삽입 사례에서 Zilliz 구성은 테스트한 batch-10k 경로의 쓰기 측 비용을 한 자릿수 달러 범위로 유지합니다. Turbopuffer는 $302 수준으로 모델링됩니다. Pinecone Serverless는 $1,180 수준으로 모델링됩니다. 그렇다고 해서 한 가격 모델이 보편적으로 더 낫다는 뜻은 아닙니다. 이는 삽입 경제성이 워크로드가 해당 경로를 얼마나 자주 실행하는지에 달려 있음을 의미합니다.
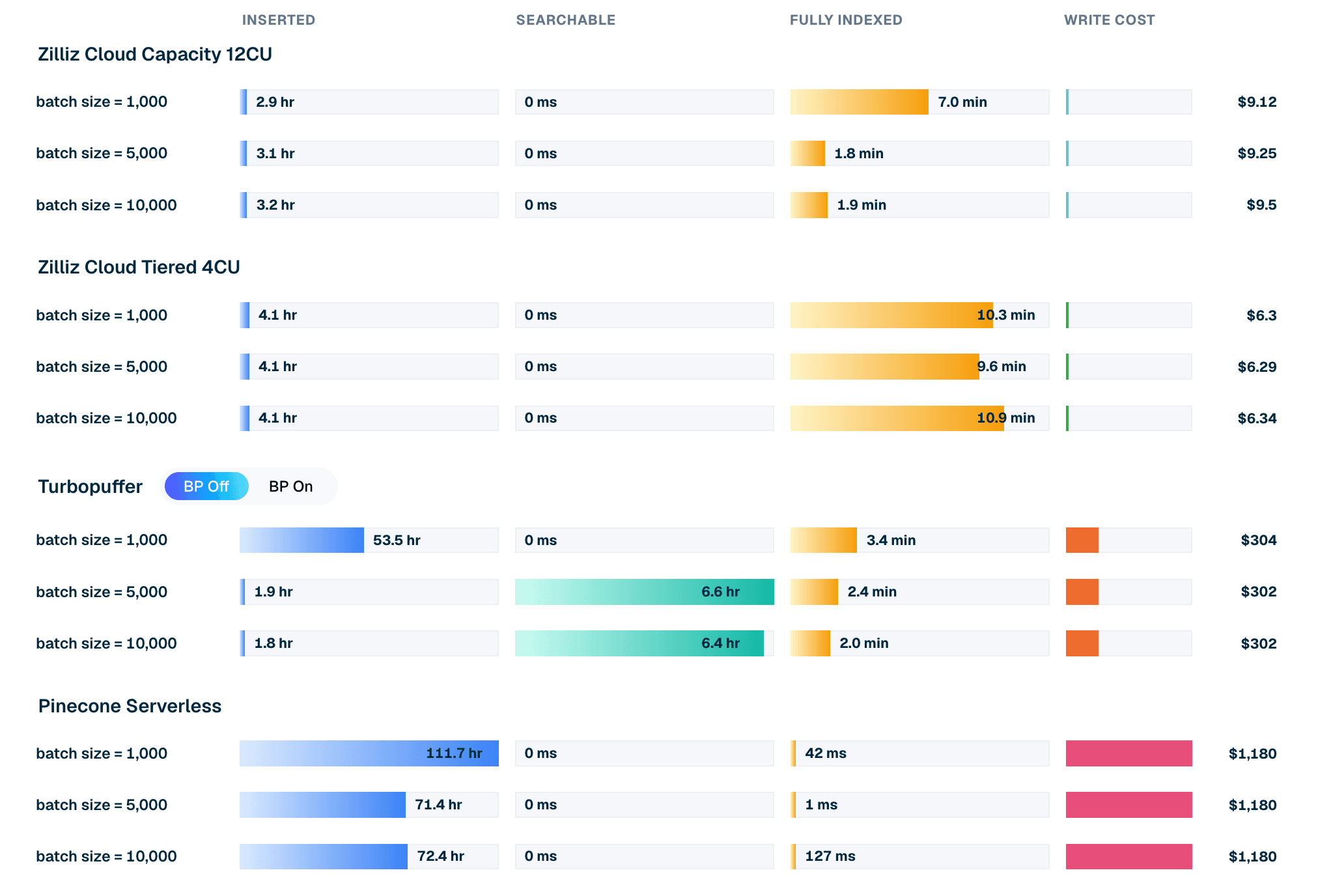
그림 2. batch 10k에서 LAION 100M의 삽입 라이프사이클: 제품별 삽입 시간, 검색 가능 대기, 완전 인덱싱 대기, 및 모델링된 쓰기 비용.
CloudPayloadSearchCase: 페이로드가 검색 표면을 바꿉니다
데이터가 검색 가능해지면, 다음 질문은 데이터베이스가 초당 몇 개의 쿼리를 처리할 수 있는지만이 아닙니다. 응답 형태가 중요합니다. ID만 반환하는 것은 메타데이터나 원시 벡터를 반환하는 것과 매우 다릅니다. 768차원 벡터는 각 결과에 수천 바이트를 추가할 수 있습니다. topK=100에서는 페이로드 크기가 쿼리 비용과 지연 시간의 주요 요인이 될 수 있습니다.
CloudPayloadSearchCase는 다양한 응답 페이로드와 필터 형태에서 단일 테넌트 LAION 100M을 테스트합니다. 판독값은 최대 동시 QPS, 해당 동시성에서의 P99 지연 시간, 페이로드 유형, 그리고 사용 가능한 경우 recall을 결합합니다.
표를 읽을 때 한 가지 참고 사항: 여기서 P99는 각 제품의 피크 QPS를 생성하는 포화 지점인 최대 동시성에서 측정됩니다 — 편안한 서비스 수준 운영 지점에서가 아닙니다. 이는 구성이 측정된 한계에서 어떻게 동작하는지를 보여줍니다.
| 제품 | 최대 동시성에서의 P99 지연 시간 | 최대 QPS | recall@10 |
|---|---|---|---|
| Zilliz Cloud Capacity 32CU | 158 ms | 786.1 | 0.9728 |
| turbopuffer | 2.34 s | 395.7 | 0.9321 |
| Zilliz Cloud Capacity 12CU | 299 ms | 376.0 | 0.9723 |
| Turbopuffer pinned | 3.30 s | 68.2 | 0.9321 |
| Zilliz Cloud Tiered 4CU | 5.57 s | 49.2 | 0.9510 |
| Pinecone Serverless | 4.85 s | 4.6 | 0.9609 |
표 2. 단일 테넌트 LAION 100M, 필터 없음, ID만, topK 100. Pinecone에 대한 참고: 이 단일 테넌트 사례에서 처리량은 서버 측 read-unit 스로틀링에 의해 제한되므로, 실행은 다른 제품의 80에 비해 동시성 4–5에서 최대치에 도달합니다. 해당 행은 포화 결과라기보다 페이싱된 서버리스 기준선으로 읽어야 합니다.
구성이 중요합니다. 12CU에서 Zilliz Capacity와 Turbopuffer는 이 광범위한 ID만 사용하는 사례에서 원시 QPS가 비슷한 반면, Zilliz는 recall과 P99 지연 시간에서 앞섭니다. 32CU에서 Zilliz Capacity는 이 단일 테넌트 워크로드에 대해 테스트된 Turbopuffer 결과를 초과합니다.
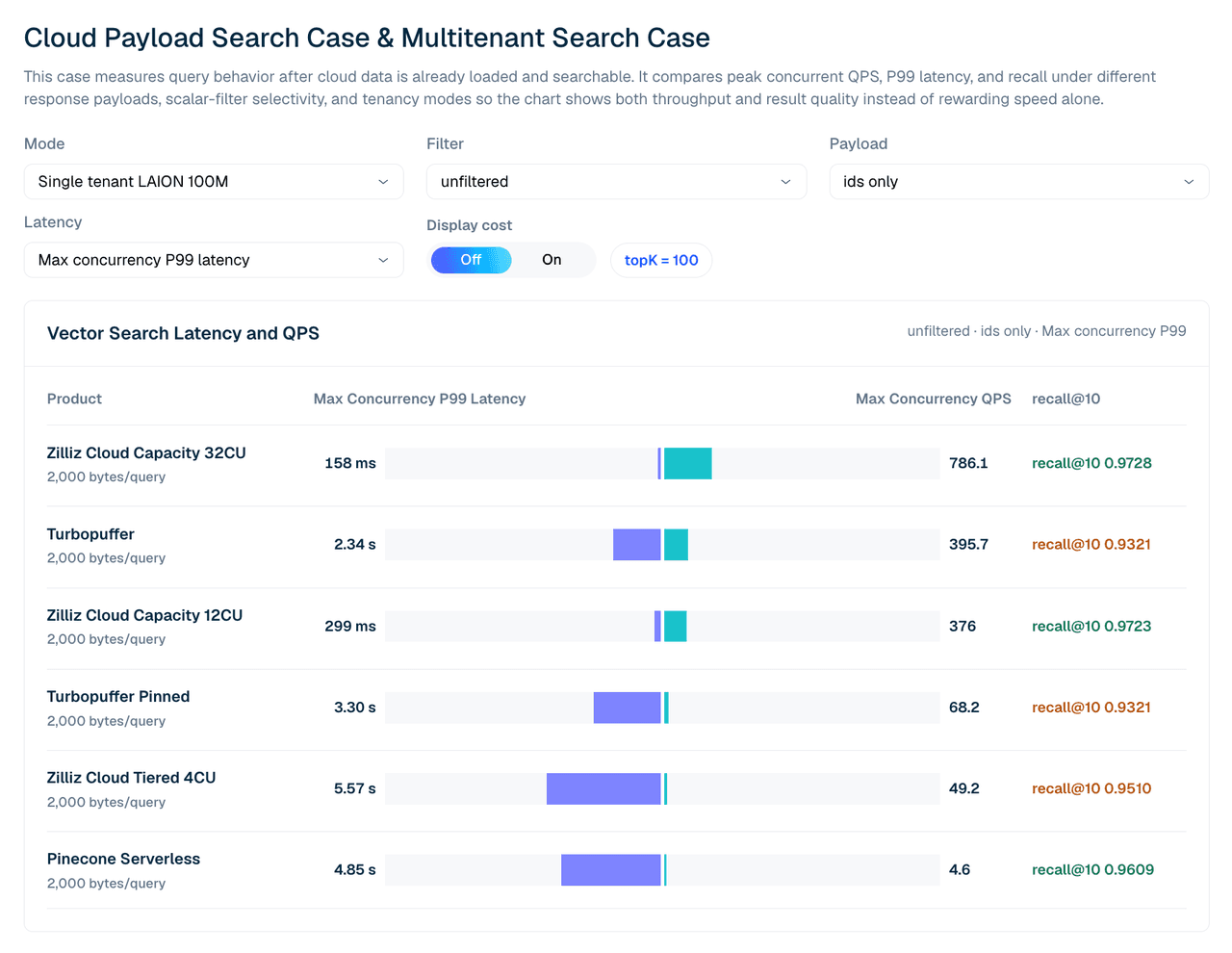
그림 3. ID만 반환하는 단일 테넌트 LAION 100M 검색. 이 뷰는 테스트한 관리형 구성 전반에서 최대 동시 QPS, P99 지연 시간, recall@10을 비교합니다.
문제는 단지 한 가지 구성에서 어떤 제품이 가장 빠른가만이 아닙니다. 팀이 더 많은 용량을 구매하거나, 페이로드 형태를 변경하거나, 리콜 목표가 필요할 때 성능이 어떻게 변하는가입니다. 쿼리가 원시 벡터 페이로드를 반환할 때 처리량은 의미 있게 달라질 수 있습니다.
| 제품 | ID만 반환 QPS | 벡터 페이로드 QPS | 리콜 |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 49.2 | 44.0 | 0.9510 |
| Zilliz Cloud Capacity 12CU | 376.0 | 229.4 | 0.9723 |
| Zilliz Cloud Capacity 32CU | 786.1 | 531.4 | 0.9728 |
| turbopuffer | 395.7 | 382.2 | 0.9321 |
| Pinecone Serverless | 4.6 | 4.5 | 0.9609 |
표 3. 광범위한 비필터링 검색에 대한 페이로드 발췌. 팀은 ID만 반환하는 검색뿐 아니라 애플리케이션이 실제로 반환하는 페이로드 형태를 벤치마크해야 합니다.
필터링 검색: 선택도가 중요한 지점
많은 프로덕션 벡터 검색 워크로드는 권한이 적용되거나 필터링됩니다. 지원 copilot은 사용자가 볼 수 있도록 허용된 문서만 검색할 수 있습니다. 추천 시스템은 지역, 카테고리, 판매자 또는 재고 여부로 필터링할 수 있습니다. 엔터프라이즈 검색 앱은 결과 순위를 매기기 전에 테넌트, 액세스 제어, 최신성, 문서 유형 제약을 적용할 수 있습니다.
이러한 필터는 단순한 장식이 아닙니다. 실행 경로를 바꿉니다. 99.9% 정수 필터와 벡터 페이로드 스트레스 지점에서는 제품 동작이 급격히 달라집니다.
| 제품 | 최대 QPS | 리콜 | P99 지연 시간 |
|---|---|---|---|
| Zilliz Cloud Tiered 4CU | 955.7 | 0.9423 | 0.16 s |
| Zilliz Cloud Capacity 12CU | 933.0 | 0.9781 | 0.12 s |
| turbopuffer | 45.1 | 0.9436 | 7.03 s |
| Pinecone Serverless | 4.8 | —* | 3.30 s |
표 4. 단일 테넌트 선택적 필터 스트레스 지점: 벡터 페이로드가 있는 99.9% 정수 필터. 이 스트레스 지점에서 Pinecone Serverless 실행의 리콜은 게시 시점에 아직 제공되지 않았으며, 해당 QPS와 지연 시간은 측정된 실행에서 나온 것입니다.
이것은 비용 인식 평가에 여러 워크로드 형태가 필요한 이유를 가장 명확하게 보여주는 사례 중 하나입니다. 광범위한 비필터링 검색에서 성능이 좋은 제품이 선택적 필터링 검색에 가장 적합한 것은 아닐 수 있습니다. 권한 기반 검색, 액세스 제어가 많은 RAG, 또는 필터 선택도가 높은 워크로드에서는 필터링된 행이 비필터링 행보다 더 중요할 수 있습니다.
MultitenantSearchCase: 많은 소규모 테넌트는 다르게 동작합니다
단일 테넌트 벤치마크가 모든 클라우드 워크로드를 포착하지는 않습니다.
많은 AI 애플리케이션은 SaaS 형태입니다. 하나의 제품이 수천 개의 테넌트를 서비스할 수 있으며, 각 테넌트는 더 작은 데이터셋을 가집니다. 운영상의 과제는 단일 대규모 컬렉션 내에서의 벡터 검색만이 아닙니다. 라우팅, 격리, 네임스페이스 관리, 그리고 많은 소규모 파티션 전반에서 처리량을 유지하는 것입니다.
멀티테넌트 사례는 1,000개 테넌트로 분할된 Cohere 10M 데이터셋을 사용합니다. 쿼리 형태는 topK 50을 사용하며 ID만 반환, 벡터 페이로드, 필터링된 행을 비교합니다.
이 표를 읽는 방식에는 두 가지 구성 관련 참고 사항이 영향을 줍니다.
첫째, 여기의 Zilliz 구성은 의도적으로 작게 설정되었습니다. Tiered 1CU와 Capacity 2CU로, Cohere 10M 데이터셋을 담기에 충분한 수준입니다. 위의 단일 테넌트 사례는 이미 Zilliz QPS가 CU 수에 따라 확장된다는 것을 보여줍니다. 이 사례가 묻는 질문은 최대 처리량이 아니라 데이터 규모에 맞춘 구성에서의 비용 효율성입니다.
둘째, Pinecone 열은 분리된 저동시성 실행(동시성 4)이며, 더 높은 동시성 행과 정규화되어 있지 않으므로 직접 비교보다는 참고 맥락으로 보아야 합니다.
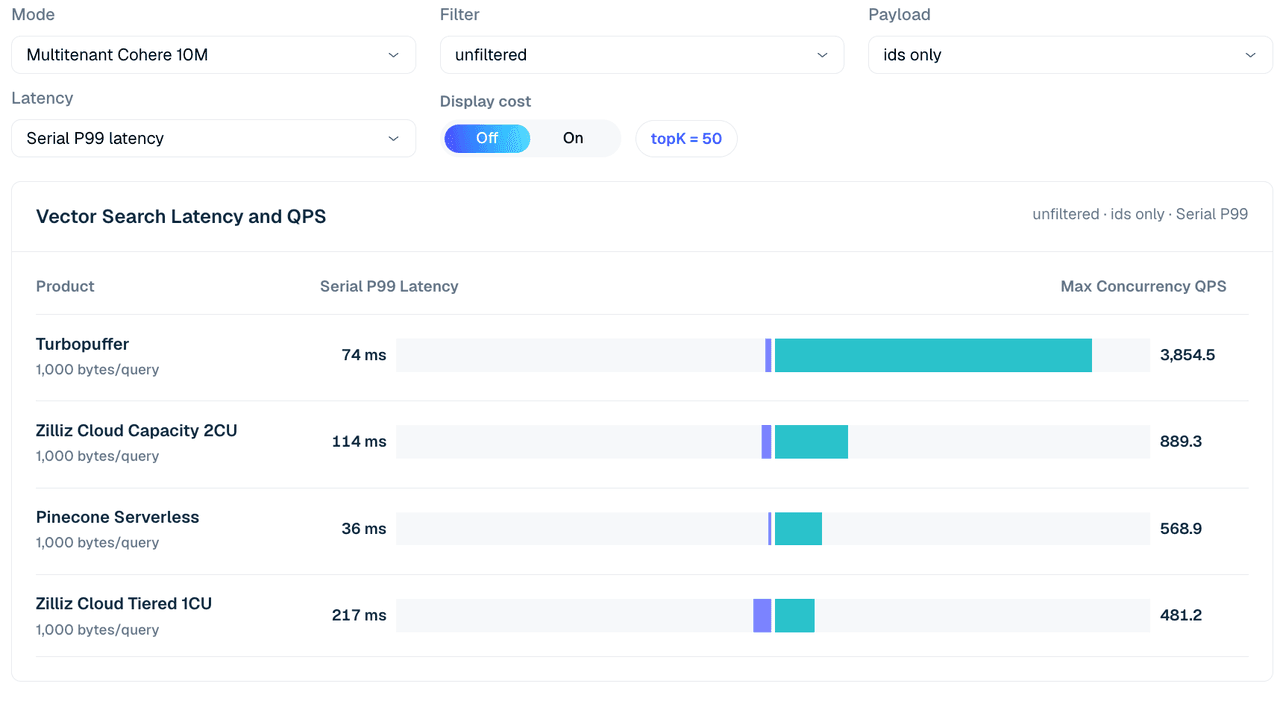
그림 4. 1,000개 테넌트에 걸친 Multitenant Cohere 10M 검색, 비필터링 ID만 반환, topK 50. 이 뷰는 테스트된 구성 전반의 직렬 P99 지연 시간과 최대 동시 QPS를 비교하며, 아래 표는 페이로드 및 필터 변형을 추가합니다.
| 사례 | Zilliz Tiered 1CU | Zilliz Capacity 2CU | turbopuffer | Pinecone (c4 run) |
|---|---|---|---|---|
| 필터 없음, ID만 | 481 | 889 | 3,855 | 569 |
| 필터 없음, 벡터 | 34 | 371 | 1,775 | 542 |
| 정수 필터 99.9%, 벡터 | 625 | 1,307 | 3,835 | 526 |
| 스칼라 레이블 1%, 벡터 | 152 | 588 | 1,767 | 600 |
| 스칼라 레이블 50%, 벡터 | 29 | 317 | 1,760 | 562 |
표 5. 1,000개 테넌트 전반의 멀티테넌트 검색 발췌, topK 50.
이 모드에서 Turbopuffer는 전반적으로 강력합니다. 필터 없는 ID 전용 검색에서 3,855 QPS, 선택적 정수 필터/벡터 행에서 3,835 QPS에 도달합니다. Zilliz Cloud Capacity 2CU는 이 발췌에서 여전히 더 강력한 Zilliz 프로필로, 필터 없는 ID 전용에서 889 QPS, 99.9% 정수 필터/벡터 행에서 1,307 QPS에 도달합니다.
제품 해석은 다시 워크로드의 형태에 따라 달라집니다. Turbopuffer는 많은 경량 테넌트와 네임스페이스 중심 처리량에 적합합니다. Zilliz는 워크로드가 필터링되거나, 권한이 적용되거나, 재현율에 민감하거나, 테넌트당 더 무거울 때 더 강력하며, 특히 팀이 서빙 목표에 맞는 Zilliz Capacity 구성을 선택할 수 있을 때 그렇습니다.
CloudColdLatencyCase: 유휴 상태 이후 첫 쿼리
웜 벤치마크 루프는 콜드 동작을 숨길 수 있습니다. 많은 프로덕션 AI 애플리케이션, 특히 에이전트 메모리, 롱테일 RAG, 저빈도 테넌트 워크로드의 경우, 유휴 상태 이후 첫 쿼리가 중요합니다. 시스템은 워밍업 후에는 빠르게 보일 수 있지만, 콜드 컬렉션, 네임스페이스 또는 캐시 경로에 다시 접근할 때 몇 초의 지연 시간을 추가합니다.
CloudColdLatencyCase는 이러한 동작을 분리합니다. 최소 24시간 동안 유휴 상태였던 컬렉션에 대한 첫 쿼리를 측정합니다. 이는 캐시와 서빙 경로가 현실적으로 가능한 한 콜드 상태가 되기에 충분한 시간이며, 같은 실행에서 워밍된 경로의 첫 쿼리와 비교합니다.
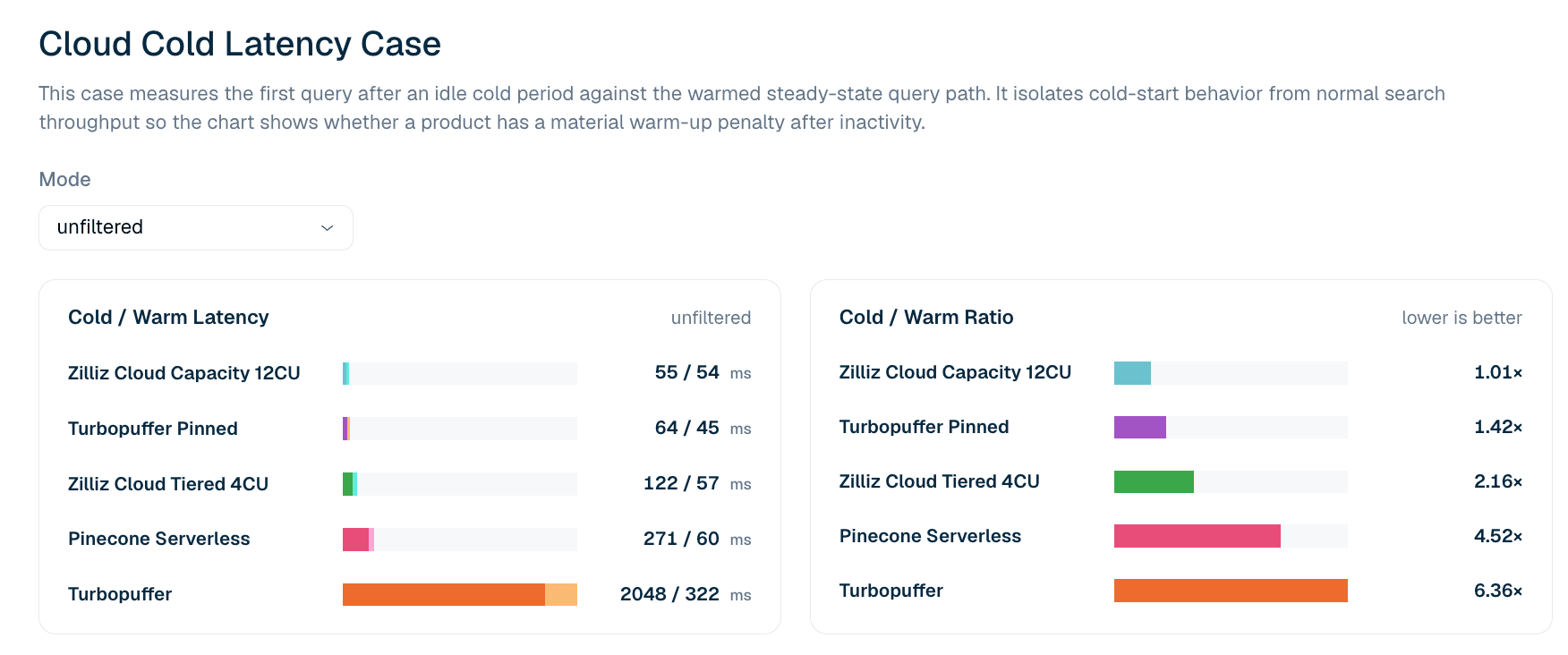
그림 5. 필터 없는 LAION 100M 검색에서 유휴 상태 이후 첫 쿼리 지연 시간 대 워밍된 쿼리 경로. 콜드/웜 비율은 제품에 유휴 상태 이후 유의미한 첫 쿼리 패널티가 있는지 강조합니다.
| 제품 | 유휴 상태 이후 첫 쿼리 | 첫 웜 쿼리 | 콜드/웜 비율 |
|---|---|---|---|
| Zilliz Cloud Capacity 12CU | 55 ms | 54 ms | 1.01x |
| Turbopuffer pinned | 64 ms | 45 ms | 1.42x |
| Zilliz Cloud Tiered 4CU | 122 ms | 57 ms | 2.16x |
| Pinecone Serverless | 271 ms | 60 ms | 4.52x |
| turbopuffer | 2,048 ms | 322 ms | 6.36x |
표 6. 필터 없는 LAION 100M에 대한 콜드 및 웜 첫 쿼리 지연 시간 발췌. 이 사례는 테일 백분위수가 아니라 첫 쿼리 지연 시간을 보고합니다. P99에서의 콜드/웜 비율은 이후 쿼리에서 안정적으로 재현되지 않는 네트워크 노이즈를 포착하는 경향이 있으므로, 리더보드는 더 엄격한 첫 쿼리 정의를 사용합니다.
현재 필터 없는 콜드 지연 시간 사례에서 Zilliz Cloud Capacity 12CU는 가장 타이트한 콜드-투-웜 프로필을 보여줍니다. 콜드 55 ms, 웜 54 ms, 즉 1.01x 비율입니다. Turbopuffer pinned도 콜드 64 ms, 웜 45 ms로 강력한 프로필을 보입니다. 고정되지 않은 Turbopuffer는 더 큰 콜드 패널티를 보입니다. 콜드 2,048 ms, 웜 322 ms, 즉 6.36x 비율입니다.
콜드 지연 시간은 항상 비용과 함께 해석해야 합니다. 고정 복제본과 프로비저닝된 용량은 첫 접근 패널티를 줄일 수 있지만, 경제 모델을 바꿉니다. 제품이 더 많은 열을 유지하기 때문에 뛰어난 콜드 동작을 보일 수 있습니다. 이는 인터랙티브 애플리케이션에는 올바른 트레이드오프일 수 있지만, 해당 경로를 유지하는 비용과 분리해서는 안 됩니다.
비용 파레토 선: 가격 모델이 교차하는 지점
가격표만으로는 충분하지 않습니다. 제품이 목표 QPS에 도달할 수 없다면 낮은 단가는 도움이 되지 않습니다. 높은 처리량 구성은 동일한 지연 시간, 재현율, 페이로드 요구 사항을 충족하는 다른 제품보다 비용이 더 많이 든다면 매력적이지 않습니다.
Cost Pareto 뷰는 측정된 벤치마크 경계와 가격 모델을 결합합니다. LAION 100M 쿼리 전용 설정의 경우, 각 제품 라인은 벤치마크에서 관측된 최대 QPS에서 멈춥니다. 그런 다음 차트는 목표 QPS 수준에서의 운영 비용을 추정하고, 이러한 측정된 제약 조건하에서 Pareto 최적 선택지를 표시합니다.
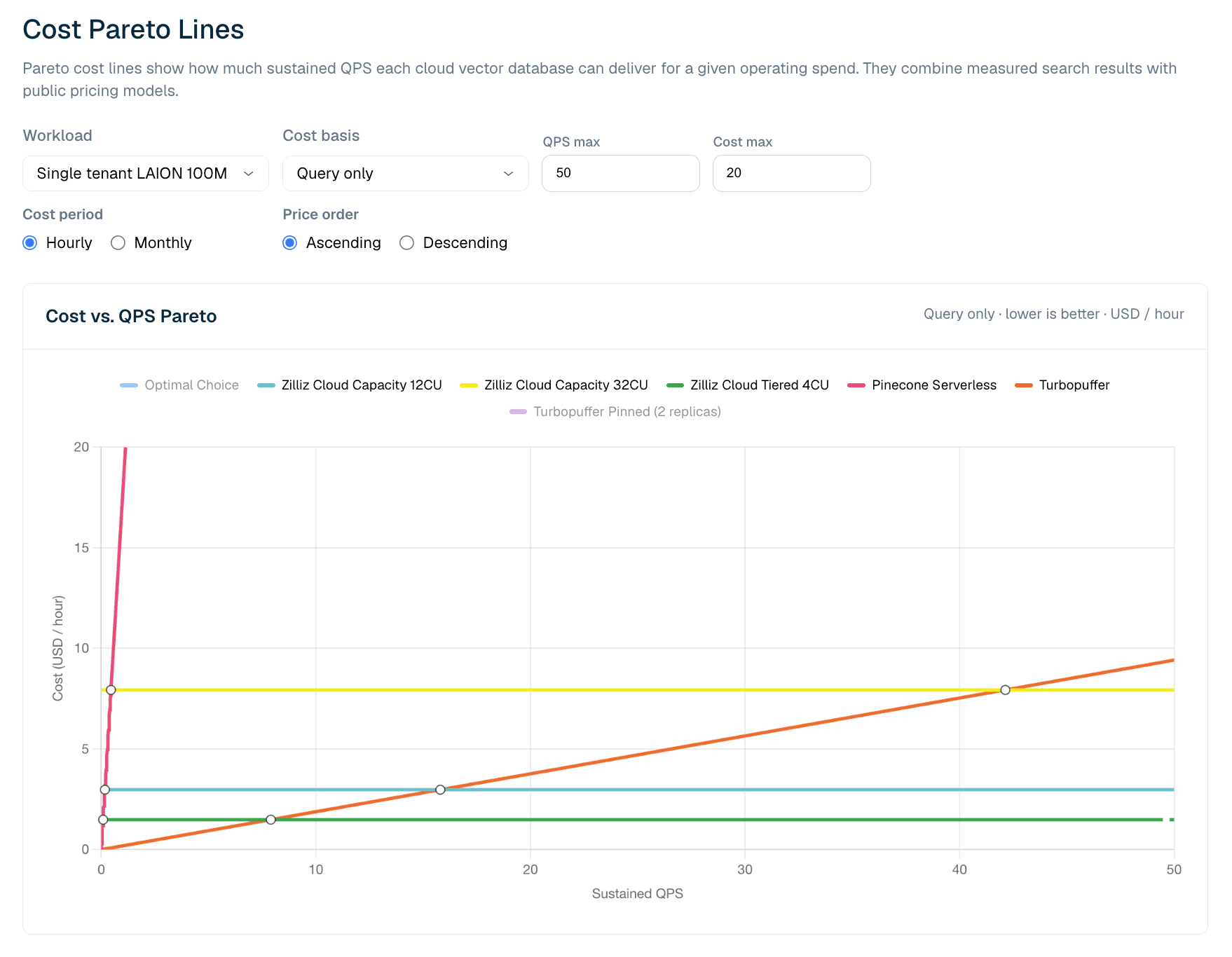
그림 6. LAION 100M 쿼리 전용 워크로드의 비용 대비 지속 QPS. Pareto 뷰는 낮은 QPS에서 serverless 가격이 더 효율적인 지점과, 사용률이 상승함에 따라 프로비저닝된 Zilliz 구성이 더 비용 효율적이 되는 지점을 보여줍니다.
현재 LAION 100M 쿼리 전용 모델에서 Turbopuffer는 매우 낮은 지속 QPS에서 이점을 갖습니다. 측정된 교차점은 대략 8 QPS입니다. 그보다 낮으면 turbopuffer의 사용량 기반 쿼리 가격 라인이 더 저렴하고, 그보다 높으면 Zilliz Cloud Tiered 4CU가 더 저렴해집니다. 이는 프로비저닝된 이후 CU-hour 서빙 비용이 대부분 고정적이기 때문입니다. QPS가 상승하면 사용률이 개선되고 프로비저닝된 용량이 더 비용 효율적이 됩니다.
그렇다고 serverless가 더 나쁘다는 의미는 아닙니다. serverless와 프로비저닝 경제성이 교차한다는 의미입니다. 낮거나, 급증하거나, 예측하기 어려운 워크로드의 경우 사용량 기반 serverless가 가장 적합할 수 있습니다. 지속적인 프로덕션 트래픽의 경우, 사용률이 교차점을 지나면 고정 CU-hour 모델이 더 저렴해질 수 있습니다. 더 강력한 서빙 범위, 콜드 동작 또는 운영 제어가 필요한 팀의 경우, Tiered가 더 낮은 비용 라인일 때에도 Zilliz Capacity가 적합한 프로파일일 수 있습니다.
Zilliz Cloud vs. Turbopuffer vs. Pinecone: 워크로드별 최적 적합성
| 워크로드 형태 | 가장 강한 신호 | 이유 |
|---|---|---|
| 매우 낮은 지속 QPS | turbopuffer | 낮은 QPS 교차점 이전에는 사용량 기반 serverless 경제성이 매력적입니다 |
| 교차점 이상의 지속 QPS(이 모델에서는 ~8 QPS) | Zilliz Cloud Tiered | 사용률이 상승함에 따라 고정 CU-hour 경제성이 개선됩니다 |
| 최신 데이터 또는 빈번한 갱신 | Zilliz Cloud Capacity / Tiered | LAION 100M 삽입 사례에서 insert-to-search 및 완전 인덱싱 준비 상태가 강합니다 |
| 대규모 전체 로드 비용 민감도 | Zilliz Cloud Capacity / Tiered | 테스트된 LAION 100M 벌크 로드 경로에서 쓰기 측 비용이 훨씬 낮습니다 |
| 광범위한 비필터링 payload 검색 | Turbopuffer and Zilliz Capacity 32CU | Turbopuffer는 광범위한 검색에 강하고, Zilliz는 더 많은 용량으로 확장됩니다 |
| 선택적 필터 또는 권한 기반 검색 | Zilliz Cloud Capacity / Tiered | Zilliz는 99.9% 필터 스트레스 지점에서 훨씬 더 높은 QPS와 더 낮은 P99 지연 시간을 보여줍니다 |
| 많은 경량 테넌트 | turbopuffer | 1,000개 테넌트 발췌에서 가장 강한 원시 QPS |
| 콜드 스타트에 민감한 인터랙티브 앱 | Zilliz Cloud Capacity; Turbopuffer pinned | 서로 다른 비용 모델로 둘 다 첫 쿼리 페널티를 줄입니다 |
| 낮은 운영 부담의 serverless 기준선 | Pinecone Serverless | 이 워크로드에서 선두는 아니더라도 성숙한 serverless 기준점 |
이러한 벤치마킹 결과를 활용하는 방법
VDBBench와 Cost Leaderboard는 벡터 데이터베이스 평가가 팀이 실제로 관리형 클라우드 제품을 구매하고 운영하는 방식을 더 잘 반영하도록 설계되었습니다. 피크 QPS는 여전히 중요하지만, 그것만으로는 더 이상 충분하지 않습니다. 더 유용한 질문은 제품이 지연 시간, recall, freshness, payload, tenancy, 비용에 대한 워크로드 요구 사항을 동시에 충족할 수 있는지입니다.
실용적인 평가 흐름은 다음과 같습니다.
- Performance Leaderboard를 사용하여 제어된 벤치마크 조건에서의 원시 서빙 기능을 이해합니다.
- Cost Leaderboard를 사용하여 관리형 클라우드 제품과 워크로드 형태 전반의 비용-성능 트레이드오프를 이해합니다.
- VDBBench 자체를 사용하여 사례를 재현하고, 다른 제품을 테스트하거나, 프로덕션과 유사한 데이터 및 쿼리 분포에 대해 벤치마크를 실행합니다.
현재 결과는 몇 가지 주의 사항과 함께 읽어야 합니다.
- 제품들은 2026년 5월 10일에 벤치마크되었으며, 비용 모델은 해당 날짜 기준 AWS us-west-2 가격을 사용합니다. 가격은 날짜와 리전에 따라 변경될 수 있습니다.
- 고정 모드, 프로비저닝된 용량, 스케일링 제어, 서버리스 스로틀링과 같은 구성 선택은 결과에 영향을 줄 수 있습니다.
- 준비 상태가 항상 같은 방식으로 노출되는 것은 아니므로, 삽입됨, 검색 가능함, 완전히 인덱싱됨의 정의는 각 클라이언트별로 확인해야 합니다.
- 마지막으로, 워크로드는 의도적으로 특정하게 설계되었습니다. 비용 파레토 결과는 항상 지연 시간, 재현율, 페이로드 형태, 측정된 서빙 한계와 함께 읽어야 합니다.
자체 워크로드 벤치마크
Cost Leaderboard는 현재 결과의 공개 스냅샷이지만, 더 중요한 변화는 VDBBench 자체에 있습니다. 이제 팀은 워크로드별 제약 조건, 즉 신선도, 페이로드 크기, 테넌트 형태, 콜드 동작, 운영 모델에 대해 성능과 비용을 함께 평가할 수 있습니다.
서버리스 제품은 낮은 지속 QPS에 적합할 수 있습니다. 프로비저닝된 용량은 사용률이 높아지면 더 비용 효율적이 될 수 있습니다. 한 시스템은 광범위한 검색에서 앞설 수 있는 반면, 다른 시스템은 선택적 필터, 빈번한 갱신 또는 콜드 스타트에 민감한 워크로드에서 더 나은 성능을 보일 수 있습니다.
목표는 가장 좋은 헤드라인 수치가 아닙니다. 목표는 워크로드에 가장 잘 맞는 것입니다.
- 현재 결과 보기: VDBBench Cost Leaderboard
- 이 사례들을 재현하거나 자체 후보를 벤치마크하기: GitHub의 VectorDBBench
- 질문이나 공유할 결과가 있나요? GitHub에 이슈를 열거나 Discord에서 대화에 참여하세요.

계속 읽기

3 Easiest Ways to Use Claude Code on Your Mobile Phone
Run Claude Code from your phone with Remote Control, Happy Coder, or SSH + Tailscale. Comparison table, setup steps, and tools for typing, memory, and parallel tasks.

Zilliz Cloud Update: Smarter Autoscaling for Cost Savings, Stronger Compliance with Audit Logs, and More
What's new in Zilliz Cloud? Smarter autoscaling with scale-down, audit logs GA, enhanced SSO, and Milvus 2.6 in Private Preview.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.