




Che cos'è un database NoSQL? Guida all'archiviazione moderna dei dati

Che cos'è un database NoSQL? Guida all'archiviazione moderna dei dati
Che cos'è un database NoSQL?
Un database NoSQL (non solo SQL) offre un'archiviazione dei dati flessibile e priva di schemi, progettata per gestire dati non strutturati o semi-strutturati come JSON, documenti o grafici. A differenza dei database relazionali tradizionali (SQL), che utilizzano tabelle strutturate e schemi predefiniti, i database NoSQL sono costruiti per garantire scalabilità, prestazioni e agilità nelle applicazioni moderne. Supportano diversi modelli di dati, tra cui i formati chiave-valore, documento, colonna-famiglia e grafo. Comunemente utilizzati in scenari come l'analisi in tempo reale, la gestione dei contenuti e l'IoT, i database NoSQL possono gestire grandi volumi di dati su sistemi distribuiti. Esempi popolari sono MongoDB, Cassandra, Redis e DynamoDB.
L'ascesa dei database NoSQL
I database NoSQL sono diventati importanti perché hanno risolto problemi che i database SQL tradizionali non erano in grado di gestire. I database tradizionali utilizzano strutture fisse, come tabelle con righe e colonne, che funzionano bene per i dati organizzati. Ma oggi molte applicazioni hanno a che fare con dati [non strutturati] (https://zilliz.com/learn/introduction-to-unstructured-data) o semi-strutturati, come i post dei social media e i dati dei sensori dei dispositivi IoT. Questi dati non si adattano perfettamente alle tabelle, rendendo i database tradizionali meno efficaci.
Un problema importante dei database tradizionali è la scalabilità. Quando i dati crescono rapidamente, è più difficile e più costoso scalarli. I database NoSQL risolvono questo problema essendo progettati per la scalabilità orizzontale, il che significa che possono facilmente distribuire i dati su molti server. Questo li rende perfetti per le applicazioni che devono gestire enormi quantità di dati senza rallentamenti.
Tipi di database NoSQL
I database NoSQL sono disponibili in diversi tipi, ognuno dei quali è stato progettato per risolvere problemi specifici di gestione dei dati. Esploriamo i quattro tipi principali di database NoSQL e vediamo come funzionano con esempi reali.
1. Database basati su documenti
I database basati su documenti memorizzano i dati come documenti, tipicamente in formati come JSON, BSON o XML. Ogni documento è autonomo e può avere una struttura unica, il che rende questi database flessibili per la gestione di dati non strutturati o semi-strutturati.
Come funziona**: Ogni documento ha campi e valori, che possono includere testo, numeri, array o persino documenti annidati.
Esempio: MongoDB, Couchbase.
Casi d'uso:
Sistemi di e-commerce: Memorizzazione di cataloghi di prodotti, dove ogni documento rappresenta un prodotto con campi come nome, prezzo e descrizione.
Sistemi di gestione dei contenuti**: Gestione di articoli, blog o contenuti multimediali con attributi diversi.
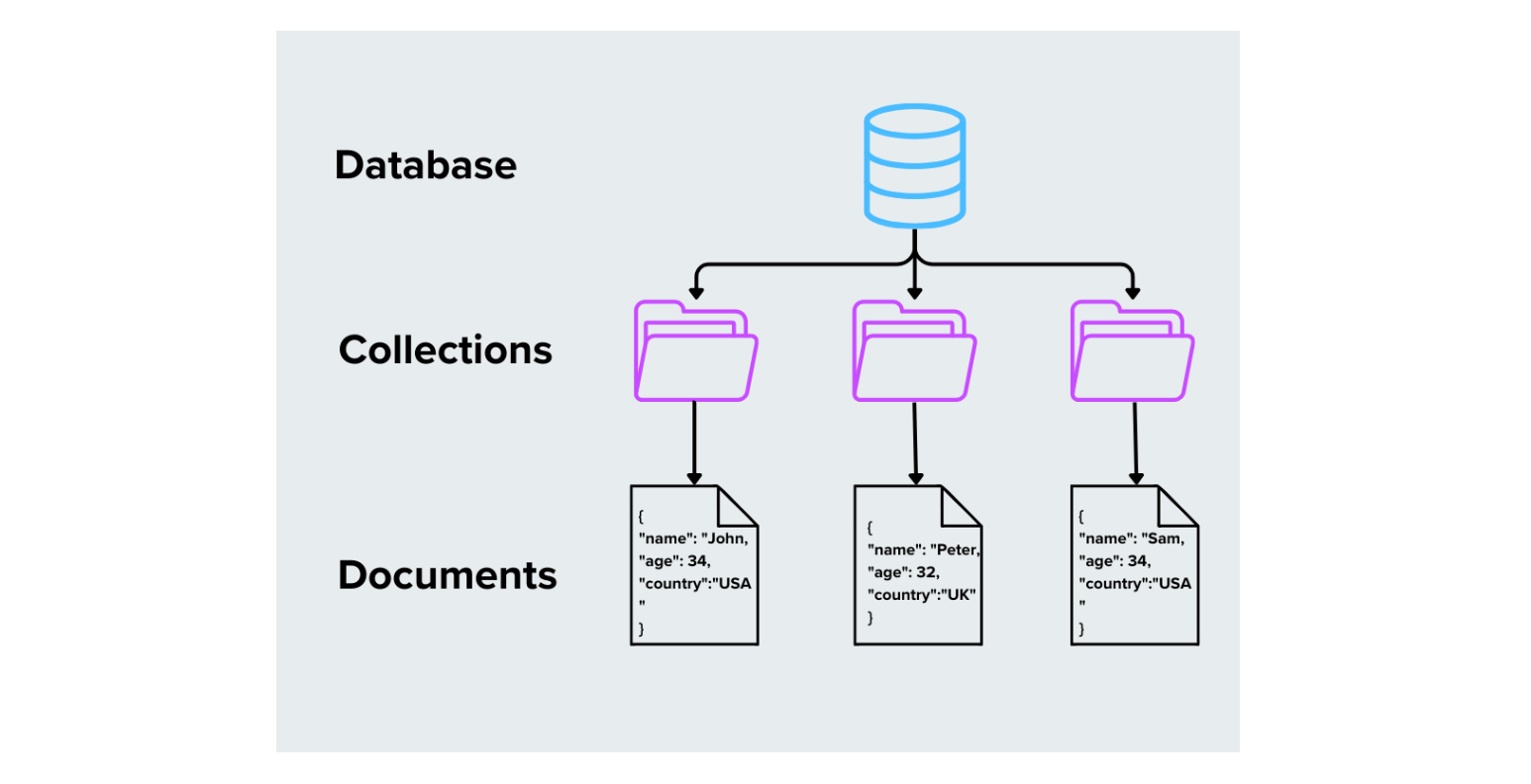 Figura- Basi di dati basate su documenti
Figura- Basi di dati basate su documenti
Figura: Basi di dati basate su documenti
2. Archivi chiave-valore
I database a valore-chiave utilizzano una chiave unica per recuperare i valori, che possono essere qualsiasi cosa, dal semplice testo a strutture di dati complesse. Questo design è molto efficiente per un accesso rapido ai dati.
Come funziona**: È come un dizionario: ogni chiave corrisponde direttamente a un valore.
Esempi** sono Redis, Amazon DynamoDB e Firebase.
Casi d'uso:
Caching: Memorizzazione di dati temporanei per un accesso rapido, come le sessioni degli utenti o i prodotti visti di recente.
Applicazioni in tempo reale**: Gestione delle classifiche di gioco o dei messaggi di chat, dove la velocità è fondamentale.
 Figura- Archivi di valori-chiave di database
Figura- Archivi di valori-chiave di database
Figura: Database con archivi di valori-chiave
3. Archivi per famiglie di colonne
Gli archivi a colonne organizzano i dati in righe e colonne, ma a differenza dei database tradizionali, le colonne possono essere raggruppate in famiglie. Questa struttura li rende ideali per la lettura e la scrittura di grandi insiemi di dati.
Come funziona**: Invece di avere uno schema fisso, le righe in un archivio a colonne possono avere diverse serie di colonne raggruppate in famiglie in base alla rilevanza.
Esempio: Apache Cassandra, HBase.
Casi d'uso:
Dati di serie temporali: Memorizzazione di log o metriche di server e applicazioni in cui vengono aggiunte continuamente nuove voci.
Applicazioni di Big Data**: Alimentazione di sistemi come motori di raccomandazione o piattaforme di analisi che elaborano enormi quantità di dati strutturati.
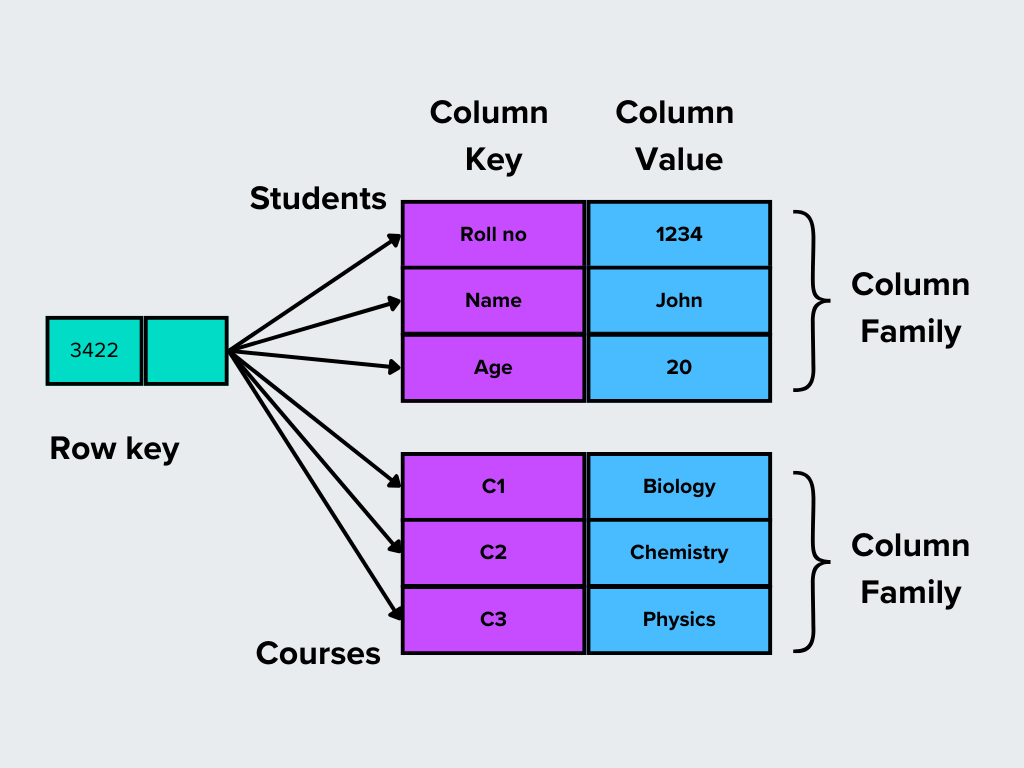 Figura- Basi di dati a colonne.png
Figura- Basi di dati a colonne.png
Figura: Basi di dati a colonna
4. Basi di dati grafiche
[I database grafici (https://zilliz.com/learn/vector-database-vs-graph-database) utilizzano i nodi per rappresentare le entità e i bordi per rappresentare le connessioni tra di esse. Questo li rende adatti alle applicazioni in cui la comprensione e l'analisi delle relazioni sono fondamentali.
Come funziona**: I dati sono memorizzati come nodi (entità), bordi (relazioni) e proprietà (dettagli su nodi e bordi).
Esempio: Neo4j, Amazon Neptune.
Casi d'uso:
Reti sociali: Rappresentare gli utenti come nodi e le loro connessioni (amici, follower) come bordi.
Sistemi di raccomandazione**: Identificazione di prodotti o contenuti correlati in base al comportamento e alle preferenze degli utenti.
Rilevamento delle frodi**: Analizzare gli schemi delle transazioni finanziarie per scoprire relazioni sospette.
 Figura- Grafico-database.png
Figura- Grafico-database.png
Figura: Basi di dati grafiche
La tabella che segue fornisce una rapida panoramica dei tipi di database NoSQL insieme al loro funzionamento, agli esempi e ai casi d'uso.
| Tipo | Come funziona | Esempi | Casi d'uso chiave |
|---|---|---|---|
| Document-Based | Memorizza i dati come documenti flessibili. | MongoDB, Firebase, Couchbase | E-commerce, gestione dei contenuti. |
| Key-Value Stores | Mappatura di chiavi e valori per un accesso rapido. | Redis, DynamoDB | Caching di dati in tempo reale come giochi o sessioni. |
| Column-Family | Raggruppa le colonne in famiglie. | Cassandra, HBase | Dati di serie temporali, analisi dei big data. |
| Graph Databases | Si concentra sulle relazioni tra i dati. | Neo4j, Neptune | Reti sociali, sistemi di raccomandazione, frodi. |
Tabella: Tipi di database NoSQL
Vantaggi dei database NoSQL
I database NoSQL offrono diversi vantaggi alle moderne applicazioni che trattano dati massicci, diversi e dinamici. Ad esempio:
1. Scalabilità
Uno dei maggiori punti di forza dei database NoSQL è la loro capacità di scalare orizzontalmente. Ciò significa che è possibile aggiungere altri server per distribuire i dati e il carico di lavoro, anziché affidarsi a un singolo server con maggiore potenza (scalabilità verticale). La scalabilità orizzontale è conveniente e garantisce che il sistema possa gestire quantità crescenti di dati e traffico. Applicazioni come i social media, l'e-commerce o l'IoT generano dati enormi che devono essere archiviati ed elaborati senza rallentamenti. I database NoSQL sono progettati per distribuire questo carico su più macchine senza problemi.
- Esempio**: Un rivenditore online può gestire i picchi di shopping aggiungendo altri server al proprio cluster di database NoSQL invece di aggiornare un singolo server.
2. Flessibilità nella modellazione dei dati
I database NoSQL memorizzano i dati in un modo che corrisponde alle esigenze dell'applicazione. A differenza dei database relazionali che utilizzano tabelle rigide e colonne predefinite, i database NoSQL consentono di lavorare con i dati in vari formati, come documenti, coppie chiave-valore, grafici o colonne.
Questa flessibilità è perfetta per le applicazioni in cui le strutture dei dati cambiano frequentemente o devono supportare diversi tipi di dati.
- Esempio: Un sistema di gestione dei contenuti può memorizzare articoli, video e profili utente nello stesso database senza costringerli in un formato fisso.
3. Progettazione senza schemi per applicazioni dinamiche
I database tradizionali richiedono uno schema predefinito, il che significa che bisogna decidere come saranno strutturati i dati prima di memorizzarli. I database NoSQL, invece, sono privi di schema, il che significa che è possibile memorizzare i dati senza definire in anticipo una struttura. Questo facilita l'adattamento ai cambiamenti dell'applicazione. Questo è utile per le startup o per le applicazioni in rapida evoluzione in cui i requisiti cambiano frequentemente.
- Esempio**: Un'applicazione mobile che aggiunge nuove funzionalità come l'integrazione dei pagamenti o la funzionalità di chat può facilmente memorizzare nuovi tipi di dati senza dover riprogettare il database.
4. Vantaggi in termini di prestazioni
I database NoSQL sono ottimizzati per specifici tipi di carichi di lavoro, come letture e scritture ad alta velocità, gestione di dati non strutturati ed elaborazione in tempo reale. A differenza dei database relazionali, che possono rallentare in presenza di carichi pesanti, i database NoSQL sono costruiti per garantire prestazioni costanti. Le applicazioni che richiedono tempi di risposta rapidi, come i giochi, il trading finanziario o l'analisi in tempo reale, possono contare sui database NoSQL per la loro velocità ed efficienza.
- Esempio: Una piattaforma di gioco può utilizzare un archivio di valori-chiave come Redis per gestire i dati di sessione di milioni di giocatori simultanei con una latenza minima.
5. Supporto per sistemi distribuiti su larga scala
I database NoSQL sono progettati per sistemi distribuiti, in cui i dati sono archiviati su più server in luoghi diversi. Questo li rende altamente affidabili e garantisce la disponibilità dei dati anche in caso di guasto di un server. I sistemi distribuiti migliorano anche le prestazioni riducendo la latenza grazie all'accesso localizzato ai dati.
Le applicazioni su larga scala, come le piattaforme globali di e-commerce o le reti di distribuzione dei contenuti, devono garantire che i dati siano sempre accessibili, indipendentemente dalla posizione dell'utente.
- Esempio**: Un servizio di streaming video internazionale può utilizzare un database NoSQL distribuito per garantire un accesso veloce e affidabile ai contenuti per gli utenti di diverse regioni.
Sfide e limiti dei database NoSQL
Sebbene i database NoSQL offrano molti vantaggi, non sono privi di sfide e limitazioni:
1. Mancanza di standardizzazione
I database NoSQL non seguono uno standard universale come l'SQL per i database relazionali. Ogni sistema NoSQL ha il proprio linguaggio di interrogazione, le proprie API e i propri principi di progettazione. La mancanza di standardizzazione può rendere più difficile passare da un sistema NoSQL all'altro o integrarlo con altri strumenti e piattaforme.
2. Problemi di coerenza dei dati nei sistemi distribuiti
Molti database NoSQL privilegiano la disponibilità e la tolleranza alle partizioni (in base al teorema CAP) rispetto alla coerenza. Ciò significa che possono consentire incoerenze temporanee nei dati tra i server distribuiti. Le applicazioni che richiedono una coerenza rigorosa, come i sistemi finanziari o le piattaforme transazionali critiche, possono incontrare difficoltà con i database NoSQL.
3. Curva di apprendimento
Gli sviluppatori abituati a lavorare con i database relazionali possono trovare il paradigma NoSQL poco familiare. Concetti come la progettazione senza schema, l'eventuale coerenza o modelli di dati specifici possono richiedere un cambiamento di mentalità. Questa curva di apprendimento può rallentare lo sviluppo e aumentare il rischio di errori di progettazione nei sistemi basati su NoSQL.
4. Limitazioni dei casi d'uso
I database NoSQL non sono sempre adatti ad applicazioni che richiedono transazioni complesse e in più fasi o una forte conformità ACID (Atomicità, Consistenza, Isolamento, Durabilità). I database relazionali sono più adatti a compiti come il mantenimento dei livelli di inventario o l'elaborazione di transazioni finanziarie, dove sono fondamentali forti garanzie sull'integrità dei dati.
Approcci ibridi e database multi-modello
Nel mondo in evoluzione della gestione dei dati, le organizzazioni hanno spesso bisogno dell'affidabilità e della struttura dei database SQL insieme alla flessibilità e alla scalabilità dei NoSQL. Gli approcci ibridi e i database multi-modello offrono una soluzione che combina le migliori caratteristiche, consentendo agli sviluppatori di lavorare con dati e carichi di lavoro diversi senza dover ricorrere a più sistemi di database.
Un database multi-modello è un singolo sistema di database che supporta diversi tipi di modelli di dati. Ad esempio, può memorizzare dati relazionali in tabelle e gestire documenti, coppie chiave-valore o grafi, il tutto all'interno dello stesso sistema. I database multi-modello eliminano la necessità di mantenere database separati per i diversi tipi di dati, riducendo la complessità e i costi operativi.
Esempi**:
ArangoDB: Supporta modelli di documenti, grafi e valori-chiave.
Couchbase: Combina l'archiviazione di documenti e valori-chiave con l'interrogazione di tipo SQL.
Oracle Database: Fornisce supporto per dati relazionali, JSON e spaziali.
Database vettoriale: La spina dorsale delle moderne applicazioni di intelligenza artificiale
Mentre i database NoSQL gestiscono dati non strutturati come documenti e grafici, i database vettoriali fanno un ulteriore passo avanti per gestire i dati attraverso vettori ad alta dimensionalità. Questi vettori sono rappresentazioni matematiche di dati non strutturati complessi, come testo, immagini o audio, utilizzati ampiamente nell'IA e nell'apprendimento automatico. I database vettoriali sono costruiti appositamente per memorizzare, indicizzare e interrogare queste incorporazioni, consentendo attività come ricerche di similarità, riconoscimento di immagini e elaborazione del linguaggio naturale (NLP). A differenza dei database tradizionali, che si basano su corrispondenze esatte, i database vettoriali si concentrano sulla ricerca di dati "simili", rendendoli fondamentali per le applicazioni basate sull'intelligenza artificiale, come i motori di raccomandazione, i chatbot e la retrieval augmented generation (RAG).
Milvus e Zilliz Cloud ****(gestito da Milvus) sono esempi principali di moderni database vettoriali. Milvus è un database vettoriale open-source in grado di gestire dati vettoriali su scala miliardaria e offre una serie di funzionalità pronte per l'impresa, come scalabilità, multi-tenancy, ricerca ibrida (ricerca full-text, ricerche vettoriali sparse e dense, ricerca vettoriale con filtraggio dei metadati, ecc) e perfetta integrazione con l'ecosistema AI. Zilliz Cloud fornisce un servizio completamente gestito di Milvus, in modo che gli sviluppatori possano eliminare la complessità della manutenzione e dell'implementazione e concentrarsi sullo sviluppo delle loro app e sul loro business. Zilliz Cloud offre inoltre prestazioni 10 volte più veloci in molte situazioni.
SQL vs NoSQL vs Database vettoriali
La tabella seguente evidenzia le principali distinzioni tra database SQL, NoSQL e vettoriali:
| Caratteristiche | Basi di dati SQL | Basi di dati NoSQL | Basi di dati vettoriali |
|---|---|---|---|
| Modello dei dati | Relazionale (tabelle con righe e colonne). | Non relazionali (documenti, chiavi-valori, grafi, ecc.). | Vettoriale (incorporazioni vettoriali ad alta dimensionalità). |
| Schema | Schema rigido e predefinito. | Schema flessibile e dinamico. | Senza schema si concentra sulle incorporazioni vettoriali. |
| Linguaggio di interrogazione | Linguaggio di interrogazione strutturato (SQL). | Varia a seconda del sistema (linguaggi di interrogazione NoSQL, API ecc.). | Metodi di ricerca vettoriale (ad esempio, RNA, similarità del coseno). |
| Focalizzazione sui tipi di dati | Dati strutturati. | Dati semi-strutturati e non strutturati. | I dati non strutturati sono rappresentati come vettori. |
| Scalabilità | Scalabilità verticale (scalabilità orizzontale limitata). | Scalabilità orizzontale (aggiunta di altri server). | Altamente scalabile con distribuzione sia verticale che orizzontale. (nota: non tutti i database vettoriali possono offrire entrambe le cose). |
| Esempi di utilizzo | Sistemi transazionali, analisi. | Big data, applicazioni web in tempo reale, sistemi distribuiti. | Applicazioni AI/ML, ricerche di similarità e RAG. |
| Performance | Ottimizzato per query e join complessi. | Ottimizzato per velocità e scalabilità. | Ottimizzato per la ricerca di similarità vettoriali ad alta dimensione. |
| Applicazioni tipiche | Sistemi bancari, ERP, CRM. | Reti sociali, IoT, gestione dei contenuti. | Recupero di immagini, motori di raccomandazione, NLP, RAG. |
| Formato di archiviazione | Righe e colonne. | Varia (JSON, BSON, ecc.). | Vettori ad alta dimensione. |
Tabella: SQL vs NoSQL vs Database vettoriale
Quando utilizzare database SQL, NoSQL o vettoriali?
La scelta tra database SQL, NoSQL e vettoriali dipende dalle esigenze specifiche dell'applicazione, tra cui la struttura dei dati, la scalabilità e la natura del carico di lavoro. I punti che seguono illustrano quando ciascun tipo di database è più adatto.
Quando usare SQL?
Applicazioni che richiedono dati coerenti e relazioni complesse.
Sistemi con uno schema fisso ed esigenze di dati prevedibili.
Esempi: Banche, sistemi ERP e applicazioni aziendali tradizionali.
Quando usare NoSQL?
Applicazioni che trattano dati su larga scala, dinamici o non strutturati.
Scenari che richiedono operazioni ad alta velocità e scalabilità.
Esempi: Social media, IoT, analisi in tempo reale ed elaborazione di big data.
Quando utilizzare un database vettoriale?
Applicazioni che richiedono la ricerca per similarità di dati ad alta dimensionalità come immagini, documenti o audio.
Flussi di lavoro AI/ML che coinvolgono incorporazioni vettoriali per attività come NLP, raccomandazioni o RAG.
Sistemi di ricerca avanzati, come il riconoscimento delle immagini o la ricerca semantica, per i dati non strutturati.
Conclusione
I database NoSQL hanno trasformato l'archiviazione e la gestione dei dati offrendo flessibilità, scalabilità e velocità per i dati non strutturati e semi-strutturati. Eccellono nella gestione di carichi di lavoro su larga scala per applicazioni come IoT, analisi in tempo reale e big data. D'altro canto, i database vettoriali, come Milvus, sono progettati per esigenze specifiche, come la gestione di dati vettoriali ad alta dimensionalità per attività di AI e machine learning. Le organizzazioni possono sfruttare le soluzioni giuste per costruire sistemi robusti e pronti per il futuro, adatti alle loro esigenze specifiche, comprendendo i ruoli distinti di SQL, NoSQL e database vettoriali.
Domande frequenti sui database NoSQL
**1. Che cos'è un database NoSQL?
Un database NoSQL è un database non relazionale che gestisce dati non strutturati, semi-strutturati o strutturati. A differenza dei database SQL, offre flessibilità nella modellazione dei dati e scalabilità per le applicazioni moderne.
**2. In che modo i database NoSQL si differenziano dai tradizionali database SQL?
I database NoSQL non si basano su schemi fissi o tabelle strutturate. Sono progettati per sistemi distribuiti e sono più adatti a gestire dati su larga scala, dinamici e diversi.
**3. Che cos'è Milvus e in che cosa si differenzia dai database NoSQL?
Milvus è un database vettoriale specializzato, progettato per gestire dati ad alta dimensionalità, come i vettori utilizzati nell'IA e nell'apprendimento automatico. A differenza dei database NoSQL generici, Milvus si concentra specificamente su compiti come la ricerca di similarità, la ricerca semantica e la gestione delle incorporazioni vettoriali per le applicazioni di AI.
**4. Quali sono i vantaggi dei database NoSQL?
I vantaggi principali includono la scalabilità, la flessibilità nella modellazione dei dati, un design privo di schemi, prestazioni elevate per carichi di lavoro specifici e il supporto per i sistemi distribuiti.
**5. Quando dovrei usare un database NoSQL?
Utilizzare NoSQL quando si ha a che fare con dati non strutturati e su larga scala o con applicazioni che richiedono scalabilità, come i sistemi di intelligenza artificiale, le piattaforme IoT, le analisi in tempo reale o l'elaborazione di big data.
Risorse correlate
Da righe e colonne a vettori: Il viaggio evolutivo delle tecnologie di database
Zilliz Cloud, il database vettoriale più performante, costruito su Milvus®
Benchmarking delle prestazioni dei database vettoriali: tecniche e approfondimenti
Usare il database vettoriale come archivio dati JSON (o relazionale)
Vettorizzazione di dati JSON con Milvus per la ricerca di similarità
- Che cos'è un database NoSQL?
- L'ascesa dei database NoSQL
- Tipi di database NoSQL
- Vantaggi dei database NoSQL
- Sfide e limiti dei database NoSQL
- Approcci ibridi e database multi-modello
- Database vettoriale: La spina dorsale delle moderne applicazioni di intelligenza artificiale
- SQL vs NoSQL vs Database vettoriali
- Quando utilizzare database SQL, NoSQL o vettoriali?
- Conclusione
- Domande frequenti sui database NoSQL
- Risorse correlate
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente