




Milvus sulle GPU con NVIDIA RAPIDS cuVS
Introduzione
**Le prestazioni in produzione sono un fattore critico per il successo della nostra applicazione AI. Più velocemente riusciamo a restituire i risultati all'utente, meglio è **Questa urgenza spinge alla necessità di ottimizzazione.
Consideriamo un esempio del mondo reale: un'applicazione Retrieval Augmented Generation (RAG). In un sistema RAG, la ricerca vettoriale è il motore che alimenta l'esperienza dell'utente, fornendo risultati pertinenti in base alle sue richieste. Tuttavia, sappiamo bene che la ricerca vettoriale è un'attività che richiede molte risorse. Più dati vengono memorizzati, più il calcolo diventa costoso e richiede tempo.
È necessario trovare una soluzione per ottimizzare le prestazioni delle nostre applicazioni di intelligenza artificiale in questi casi. In un recente intervento all'Unstructured Data Meetup ospitato da Zilliz, Corey Nolet, Principal Engineer di NVIDIA, ha discusso gli ultimi progressi di NVIDIA per risolvere questo problema, che analizzeremo in questo articolo. È inoltre possibile consultare il discorso di Corey su YouTube.
In particolare, ci concentreremo su cuVS, una libreria sviluppata da NVIDIA che contiene diversi algoritmi relativi alla ricerca vettoriale e sfrutta la potenza di accelerazione delle GPU. Vedremo come questa libreria può migliorare le prestazioni delle operazioni di ricerca vettoriale e ottimizzare i costi operativi complessivi. Quindi, senza ulteriori indugi, iniziamo!
La ricerca vettoriale e il ruolo del database vettoriale in essa
La ricerca vettoriale è un metodo di information retrieval in cui sia l'interrogazione dell'utente sia i documenti da cercare sono rappresentati come vettori. Per eseguire una ricerca vettoriale, dobbiamo trasformare la nostra query e i documenti (che possono essere immagini, testi, ecc.) in vettori.
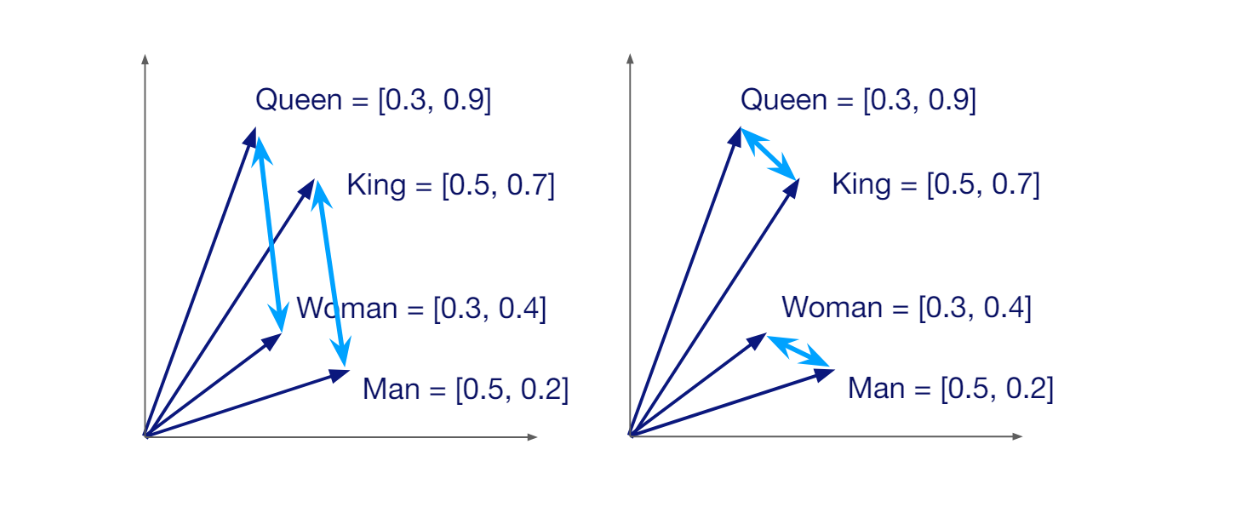
Un vettore ha una dimensione specifica, che dipende dal metodo utilizzato per generarlo. Per esempio, se utilizziamo un modello HuggingFace chiamato all-MiniLM-L6-v2 per trasformare la nostra query in un vettore, otterremo un vettore con una dimensione di 384. I vettori portano con sé il significato semantico dei dati o dei documenti che rappresentano. Pertanto, se due dati sono simili tra loro, i loro vettori corrispondenti sono posizionati l'uno vicino all'altro nello spazio vettoriale.
 Somiglianza semantica tra vettori in uno spazio vettoriale..png
Somiglianza semantica tra vettori in uno spazio vettoriale..png
Somiglianza semantica tra vettori in uno spazio vettoriale.
Il fatto che ogni vettore porti con sé il significato semantico dei dati che rappresenta ci permette di calcolare la similarità tra qualsiasi coppia casuale di vettori. Se sono simili, il punteggio di similarità sarà alto, e viceversa. Lo scopo principale della ricerca vettoriale è trovare i vettori più simili al vettore della nostra query.
L'implementazione della ricerca vettoriale è relativamente semplice quando si tratta di pochi documenti. Tuttavia, la complessità aumenta con l'aumentare dei documenti e la necessità di memorizzare più vettori. Più vettori abbiamo, più tempo ci vuole per eseguire una ricerca vettoriale. Inoltre, il costo operativo aumenta significativamente quando si memorizzano più vettori nella memoria locale. Occorre quindi una soluzione scalabile, ed è qui che entrano in gioco i [database vettoriali] (https://zilliz.com/learn/what-is-vector-database).
I database vettoriali offrono una soluzione efficiente, veloce e scalabile per memorizzare un'enorme collezione di vettori. Offrono metodi di indicizzazione avanzati per un recupero più rapido durante le operazioni di ricerca sui vettori, nonché una facile integrazione con i framework di IA più diffusi per semplificare il processo di sviluppo delle nostre applicazioni di IA. Nei database vettoriali come Milvus e Zilliz Cloud (il Milvus gestito), possiamo anche memorizzare i metadati dei vettori ed eseguire processi di filtraggio avanzati durante le operazioni di ricerca.
 Flusso di lavoro completo di un'operazione di ricerca vettoriale..png
Flusso di lavoro completo di un'operazione di ricerca vettoriale..png
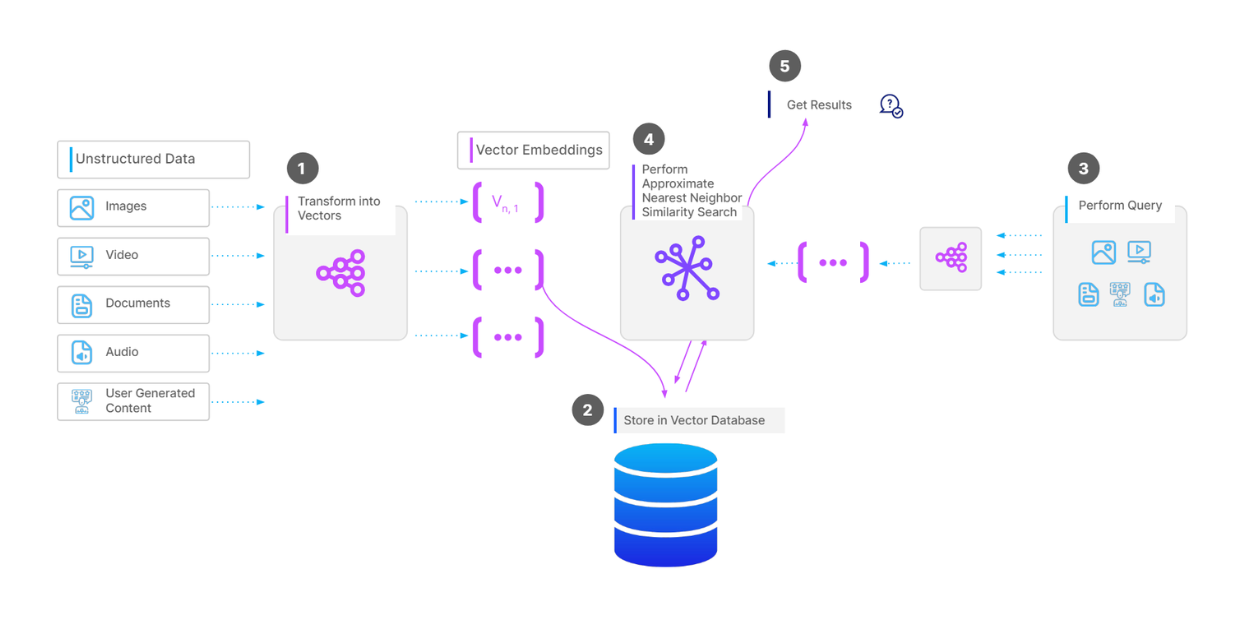
Flusso di lavoro completo di un'operazione di ricerca vettoriale.
Per memorizzare una collezione di vettori in un database vettoriale come Milvus, il primo passo è quello di eseguire una pre-elaborazione dei dati, a seconda del tipo di dati. Ad esempio, se i nostri dati sono una raccolta di documenti, possiamo dividere il testo di ogni documento in pezzi. Quindi, trasformiamo ogni pezzo in un vettore utilizzando un modello di incorporazione di nostra scelta. Quindi, inseriamo tutti i vettori nel nostro database vettoriale e costruiamo un indice su di essi per velocizzare il recupero durante le operazioni di ricerca vettoriale.
Quando abbiamo una query e vogliamo eseguire un'operazione di ricerca vettoriale, trasformiamo la query in un vettore usando lo stesso modello di incorporamento usato in precedenza, e poi calcoliamo la sua somiglianza con i vettori nel database. Infine, ci vengono restituiti i vettori più simili.
Operazione di ricerca vettoriale su CPU
Le operazioni di ricerca vettoriale richiedono un calcolo intensivo e il costo di calcolo aumenta con l'aumentare del numero di vettori memorizzati in un database vettoriale. Diversi fattori influenzano direttamente il costo di calcolo, come la costruzione dell'indice, il numero totale di vettori, la dimensionalità dei vettori e la qualità dei risultati di ricerca desiderati.
Le CPU sono le unità di elaborazione più comuni per le operazioni di ricerca vettoriale, grazie alla loro economicità e alla facile integrazione con altri componenti nelle applicazioni di intelligenza artificiale. Molti algoritmi di ricerca vettoriale sono completamente ottimizzati per le CPU e Hierarchical Navigable Small World (HNSW) è il più popolare.
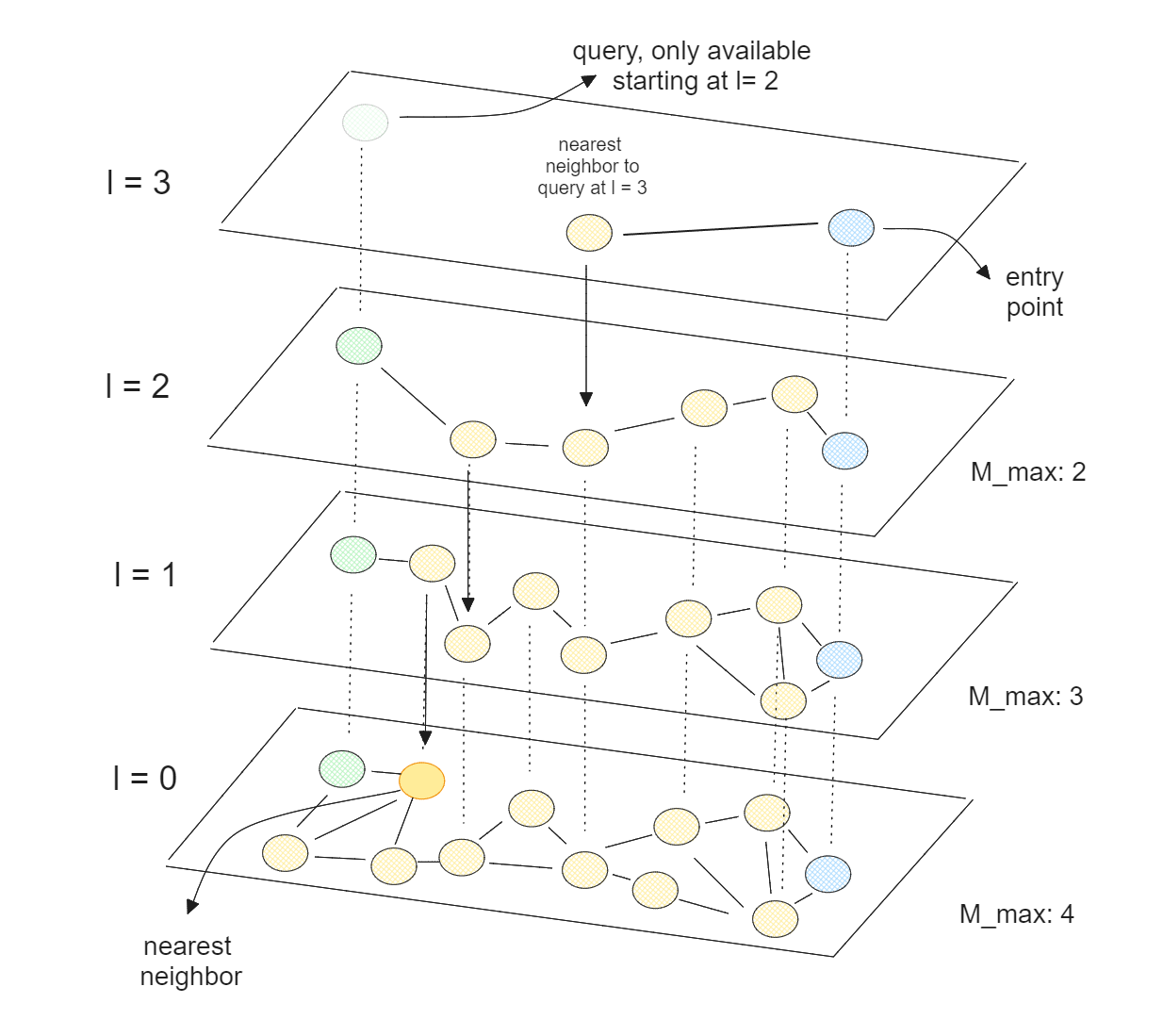
Nel suo nucleo, HNSW combina i concetti di skip list e Navigable Small World (NSW). In un algoritmo NSW, il grafo viene costruito mescolando in modo casuale i punti dati. Successivamente, i punti dati vengono inseriti uno per uno, e ogni punto è collegato ai suoi vicini attraverso un numero predefinito di bordi.
 Ricerca vettoriale con HNSW..png
Ricerca vettoriale con HNSW..png
Ricerca vettoriale con HNSW.png
HNSW è una NSW a più livelli, in cui il livello più basso contiene tutti i punti dati e il livello più alto contiene solo un piccolo sottoinsieme dei punti dati. Ciò significa che più alto è il livello, più punti di dati vengono saltati, il che corrisponde alla teoria delle liste di salto.
Con HNSW, abbiamo un grafo in cui la maggior parte dei nodi può essere raggiunta da qualsiasi altro nodo attraverso un numero ridotto di iterazioni. Questa proprietà consente a HNSW di navigare in modo efficiente e rapido attraverso il grafo per trovare i vicini approssimativi. Poiché HNSW è ottimizzato per le CPU, possiamo anche parallelizzare la sua esecuzione su più core della CPU per accelerare ulteriormente il processo di ricerca vettoriale.
Tuttavia, il tempo di calcolo di HNSW soffre ancora quando si memorizzano più dati all'interno del database vettoriale. La situazione può peggiorare se la dimensionalità dei vettori è molto elevata. Pertanto, abbiamo bisogno di un'altra soluzione per i casi in cui abbiamo un numero enorme di vettori ad alta dimensionalità.
Operazione di ricerca vettoriale su GPU
Una soluzione per migliorare le prestazioni della ricerca vettoriale quando si ha a che fare con un numero enorme di vettori ad alta dimensionalità è quella di operare su una GPU. Per facilitare questa operazione, è possibile utilizzare RAPIDS cuVS di NVIDIA, una libreria che contiene diverse implementazioni di ricerca vettoriale ottimizzate per le GPU. Semplifica l'uso delle GPU sia per le operazioni di ricerca vettoriale che per la creazione di indici.
cuVS offre diversi algoritmi di nearest neighbor tra cui scegliere, tra cui:
Brute-force: Una ricerca esaustiva dei vicini in cui la query viene confrontata con ogni vettore del database.
IVF-Flat: Un algoritmo di nearest neighbor approssimativo (ANN) che divide i vettori del database in diverse partizioni non intersecanti. L'interrogazione viene quindi confrontata solo con i vettori della stessa partizione (e facoltativamente di partizioni vicine).
IVF-PQ: Una versione quantizzata di IVF-Flat che riduce l'ingombro in memoria dei vettori memorizzati nel database.
CAGRA: Un algoritmo nativo per GPU simile a HNSW.
 Costruzione del grafo CAGRA. .png
Costruzione del grafo CAGRA. .png
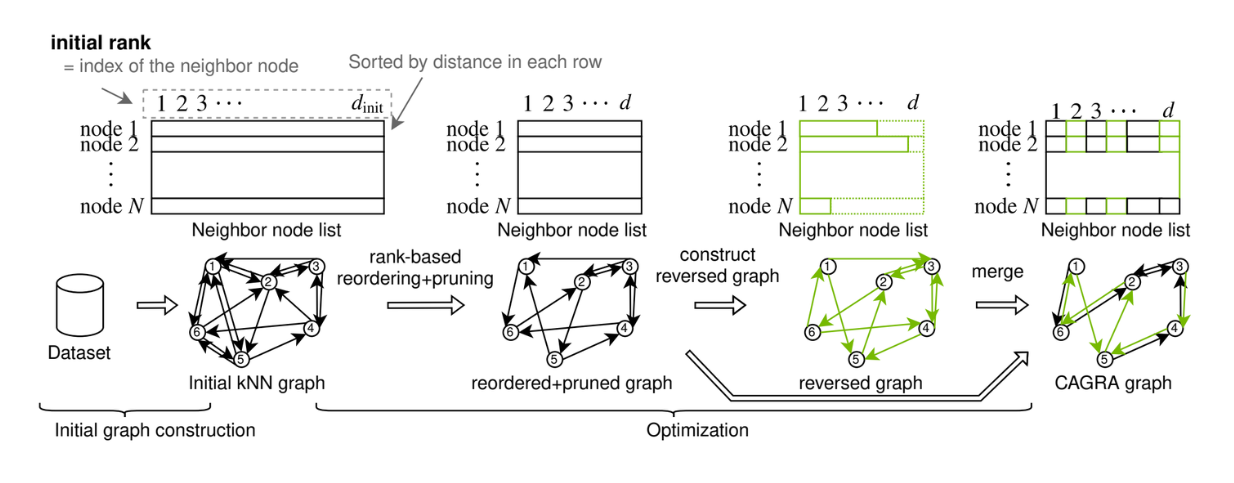
Costruzione del grafo CAGRA. Source._
Tra questi algoritmi di nearest neighbor, ci concentreremo su CAGRA.
CAGRA è un algoritmo basato su grafi introdotto da NVIDIA per una ricerca approssimativa dei vicini veloce ed efficiente, sfruttando la potenza di elaborazione in parallelo delle GPU.
Il grafo di CAGRA può essere costruito utilizzando il metodo IVF-PQ o il metodo NN-DESCENT:
Metodo IVF-PQ: Utilizza un indice per creare un grafo iniziale efficiente dal punto di vista della memoria, collegando ogni punto a molti vicini.
Metodo NN-DESCENT**: Utilizza un processo iterativo per costruire un grafo espandendo e raffinando le connessioni tra i punti.
Rispetto a HNSW, i metodi di costruzione del grafo di CAGRA sono più facili da parallelizzare e contengono meno interazioni di dati tra i task, il che migliora significativamente il tempo di costruzione del grafo o dell'indice. Se volete saperne di più su CAGRA, consultate il suo documento ufficiale o l'articolo su CAGRA.
CAGRA ha raggiunto lo stato dell'arte nelle operazioni di ricerca vettoriale. Per dimostrarlo, nella prossima sezione confronteremo le sue prestazioni con quelle di HNSW.
Confronto delle prestazioni di CAGRA e HNSW
Nella ricerca vettoriale ci sono due operazioni critiche per le quali le prestazioni sono fondamentali: la costruzione dell'indice e la ricerca stessa. Confronteremo le prestazioni di CAGRA e HNSW in queste due operazioni.
Cominciamo con la creazione dell'indice.
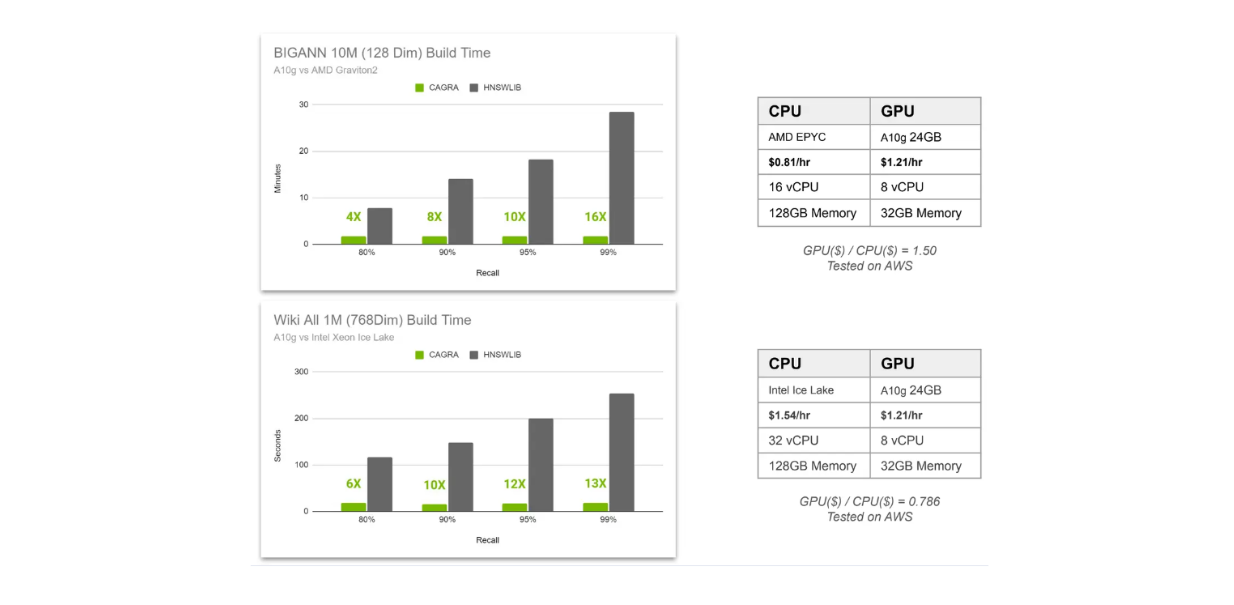 Confronto dei tempi di costruzione dell'indice CAGRA vs HNSW..png
Confronto dei tempi di costruzione dell'indice CAGRA vs HNSW..png
Confronto dei tempi di costruzione dell'indice CAGRA vs HNSW._
Nella visualizzazione qui sopra, confrontiamo il tempo di costruzione dell'indice di CAGRA e HNSW in due diversi scenari. In primo luogo, abbiamo 10 milioni di vettori a 128 dimensioni memorizzati in un database vettoriale e in secondo luogo abbiamo 1 milione di vettori a 768 dimensioni. Il primo scenario utilizza AMD Graviton2 come CPU per HNSW e GPU A10G per CAGRA, mentre il secondo scenario utilizza Intel Xeon Ice Lake come CPU per HNSW e GPU A10G per CAGRA.
Confrontiamo il tempo di costruzione dell'indice con quattro diversi valori di richiamo, che vanno dall'80% al 99%. Come forse già sapete, più alto è il richiamo, più intensivo è il calcolo necessario.
Questo perché in una ricerca vettoriale basata su grafi, possiamo regolare con precisione due fattori: il numero di vicini considerati per trovare il vicino più vicino a ogni livello e il numero di vicini più vicini da considerare come punto di ingresso in ogni livello. Più alto è il richiamo, più vicini saranno considerati, con una conseguente maggiore accuratezza di recupero ma anche un maggiore costo computazionale.
Dalla visualizzazione precedente, si nota che l'uso della GPU è più utile quando si vogliono ottenere risultati con un richiamo elevato. Inoltre, la velocità di utilizzo delle GPU aumenta con l'aumentare del numero di vettori ad alta dimensionalità memorizzati nel database vettoriale.
Confrontiamo quindi le prestazioni di HNSW e CAGRA utilizzando due metriche comuni nella ricerca vettoriale:
Throughput: il numero di query che possono essere completate in uno specifico intervallo di tempo.
Latenza: il tempo necessario all'algoritmo per completare una query.
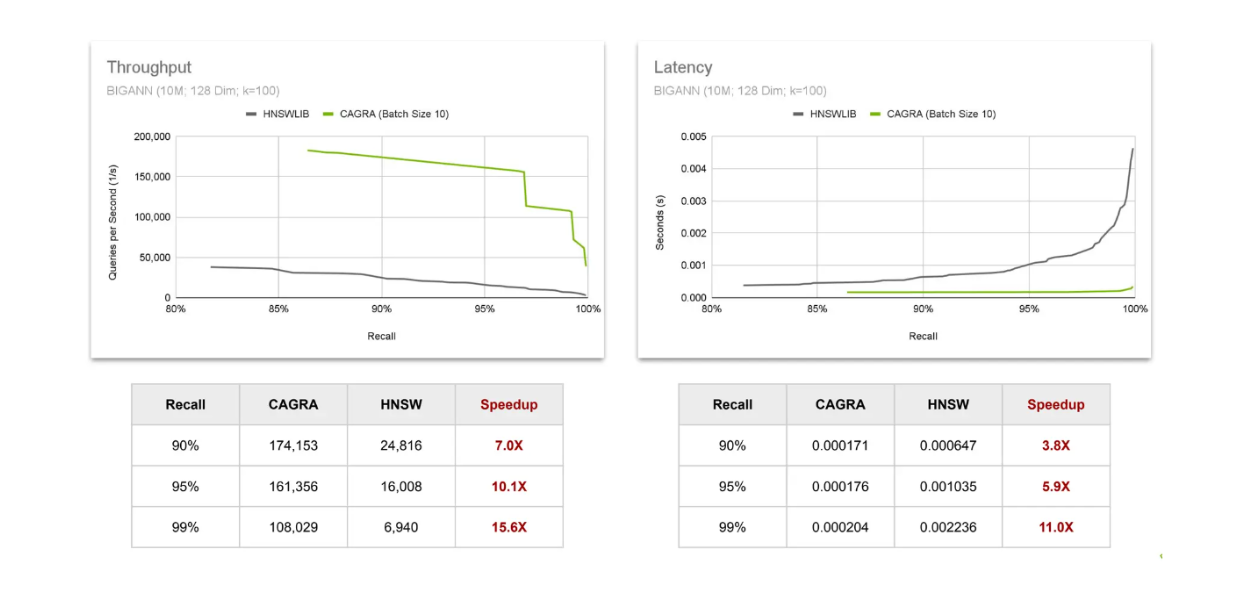 Confronto tra throughput e latenza CAGRA vs HNSW..png
Confronto tra throughput e latenza CAGRA vs HNSW..png
Confronto tra throughput e latenza CAGRA e HNSW.
Per valutare il throughput, osserviamo il numero di query che possono essere completate in un secondo. I risultati mostrano che la velocità derivante dall'uso di CAGRA su GPU aumenta man mano che si richiedono risultati con valori di richiamo più elevati. La stessa tendenza si osserva per la latenza, dove la velocità aumenta all'aumentare del valore di richiamo. Ciò conferma che il valore dell'uso della GPU aumenta quando si cercano risultati più precisi dalla ricerca vettoriale.
Tuttavia, a volte si desidera utilizzare la CPU durante la ricerca vettoriale per via della sua semplicità e della facile integrazione con altri componenti della nostra applicazione di intelligenza artificiale. In questo caso, l'implementazione degli algoritmi di nearest neighbors con CAGRA è ancora utile perché possiamo eseguire la ricerca vettoriale sia su GPU che su CPU.
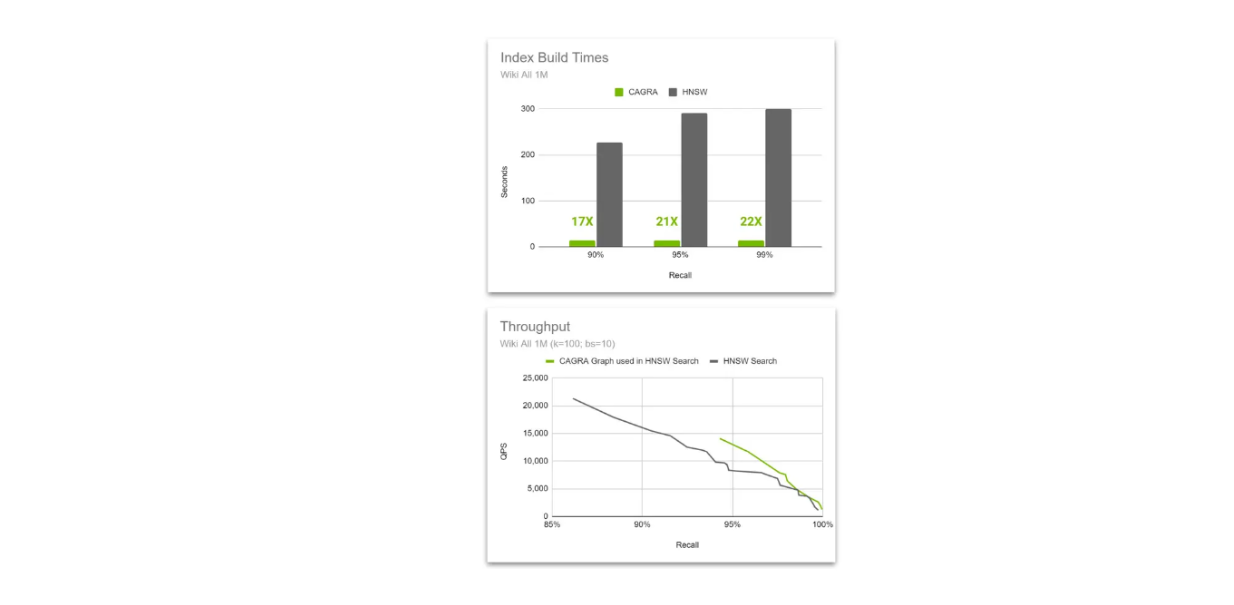 Confronto del throughput tra il grafico HNSW nativo e quello CAGRA utilizzato nella ricerca HNSW..png
Confronto del throughput tra il grafico HNSW nativo e quello CAGRA utilizzato nella ricerca HNSW..png
Confronto del throughput tra il grafico HNSW nativo e quello CAGRA utilizzato nella ricerca HNSW.
L'idea è di utilizzare la potenza di accelerazione di CAGRA e della GPU durante la costruzione dell'indice, per poi passare a HNSW durante la ricerca vettoriale. Questo metodo è possibile perché l'algoritmo HNSW è in grado di eseguire una ricerca utilizzando un grafo costruito da CAGRA e le sue prestazioni sono ancora migliori rispetto al grafo costruito con HNSW all'aumentare della dimensione del vettore.
CAGRA offre anche un metodo di quantizzazione chiamato CAGRA-Q per comprimere ulteriormente la memoria dei vettori memorizzati. Questo metodo è particolarmente utile per rendere più efficiente l'allocazione della memoria e ci permette di memorizzare i vettori quantizzati su dispositivi di memoria più piccoli per un recupero più rapido.
Supponiamo di avere una memoria del dispositivo di dimensioni inferiori rispetto alla memoria host. I benchmark iniziali delle prestazioni di NVIDIA hanno dimostrato che i vettori quantizzati memorizzati nella memoria del dispositivo con il grafico memorizzato nella memoria host avranno prestazioni simili rispetto ai vettori originali non quantizzati e al grafico memorizzato nella memoria del dispositivo a velocità di richiamo più elevate.
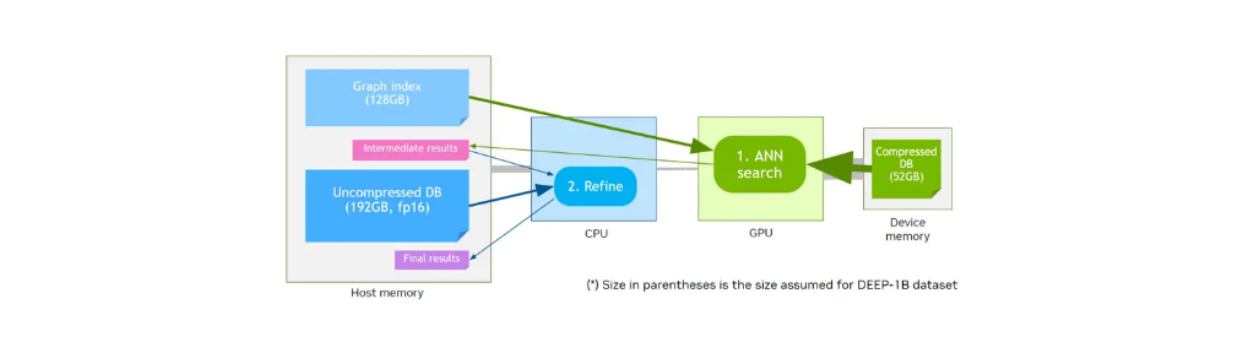 Flusso di lavoro della ricerca vettoriale mediante l'utilizzo della memoria del dispositivo e di CAGRA-Q..png
Flusso di lavoro della ricerca vettoriale mediante l'utilizzo della memoria del dispositivo e di CAGRA-Q..png
Flusso di lavoro della ricerca vettoriale con l'utilizzo della memoria del dispositivo e di CAGRA-Q._
Milvus su GPU con CuVS
Milvus supporta l'integrazione con la libreria cuVS, permettendoci di combinare Milvus con CAGRA per costruire applicazioni di intelligenza artificiale. L'architettura di Milvus consiste in diversi nodi, come i nodi indice, i nodi query e i nodi dati. cuVS ottimizza le prestazioni di Milvus accelerando i processi all'interno dei nodi query e dei nodi indice.
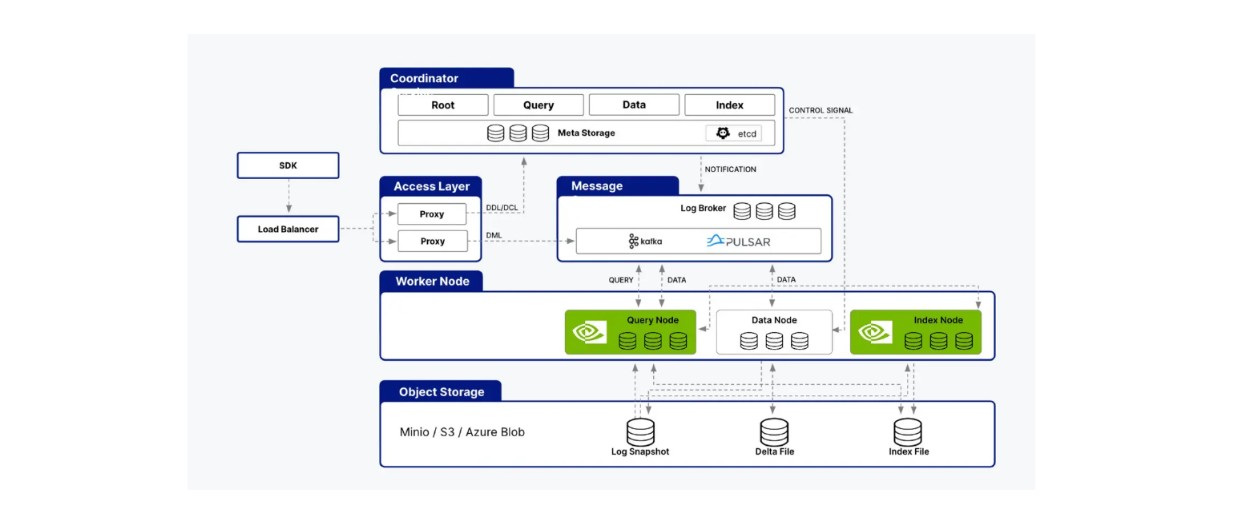 cuVS supporta sia i nodi di interrogazione che quelli di indice dell'architettura Milvus..png
cuVS supporta sia i nodi di interrogazione che quelli di indice dell'architettura Milvus..png
cuVS supporta sia i nodi di query che quelli di indice dell'architettura Milvus.
Come forse già sapete, i nodi indice sono responsabili della creazione degli indici, mentre i nodi query elaborano le query degli utenti, eseguono ricerche vettoriali e restituiscono i risultati all'utente. Nella sezione precedente abbiamo visto come CAGRA migliori tutti questi aspetti rispetto agli algoritmi nativi della CPU, come HNSW.
Ora esaminiamo le prestazioni della creazione di indici con cuVS e Milvus on-premise. In particolare, analizzeremo il tempo di costruzione dell'indice utilizzando CAGRA e IVF-PQ su un numero diverso di vettori: 10, 20, 40 e 80 milioni.
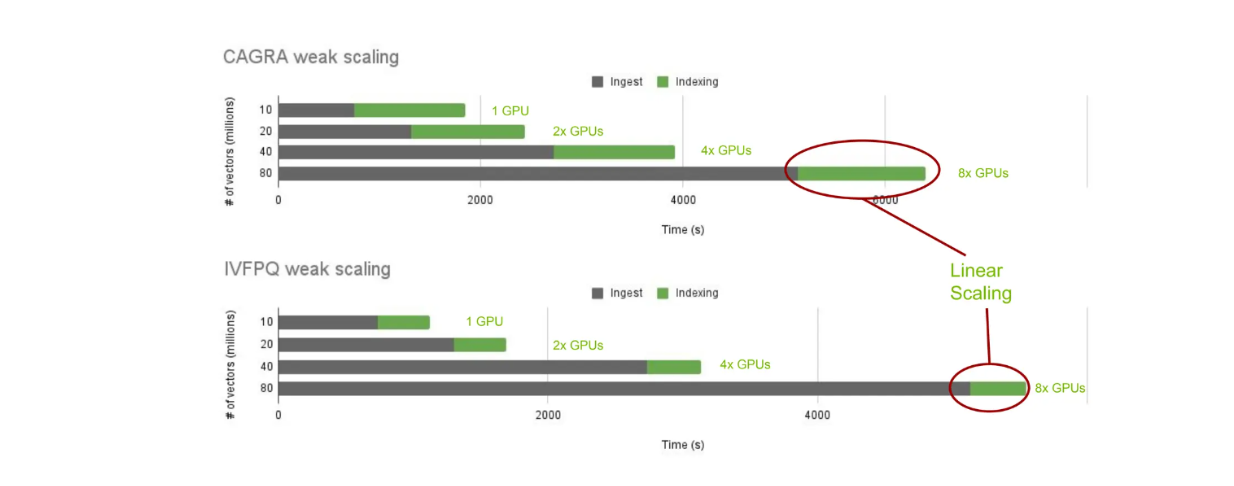 scalatura cuVS del tempo di costruzione dell'indice tra diversi algoritmi di nearest neighbor..png
scalatura cuVS del tempo di costruzione dell'indice tra diversi algoritmi di nearest neighbor..png
Scala del tempo di costruzione dell'indice tra i diversi algoritmi di prossimità.
Come previsto, il tempo di ingest aumenta all'aumentare del numero di vettori memorizzati. Tuttavia, il tempo di costruzione dell'indice rimane costante con l'aggiunta lineare di altre GPU in base al numero di vettori memorizzati. Questo ci permette di scalare e confrontare il tempo di costruzione dell'indice tra diversi algoritmi di nearest neighbor con cuVS.
Sappiamo che le GPU offrono operazioni di calcolo più veloci rispetto alle CPU. Tuttavia, il costo operativo dell'uso delle GPU è più elevato. Pertanto, è necessario confrontare il rapporto costo-prestazioni dell'uso delle GPU e delle CPU con Milvus, come visualizzato di seguito.
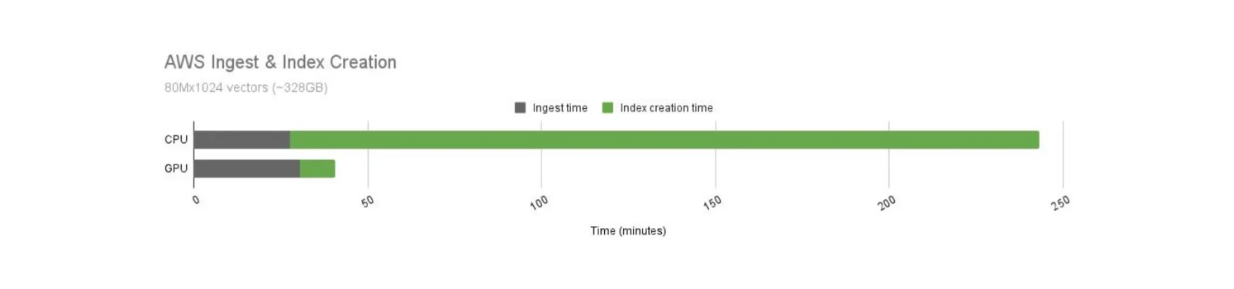 Confronto dei tempi di costruzione degli indici di Milvus tra GPU e CPU..png
Confronto dei tempi di costruzione degli indici di Milvus tra GPU e CPU..png
Confronto dei tempi di costruzione degli indici di Milvus tra GPU e CPU.
Il tempo di costruzione dell'indice utilizzando le GPU è significativamente più veloce rispetto alle CPU. In questo caso d'uso, Milvus accelerato dalle GPU offre una velocità di 21 volte superiore rispetto alla sua controparte CPU. Tuttavia, il costo operativo delle GPU è anche più costoso di quello delle CPU. La GPU costa 16,29 dollari all'ora, mentre la CPU costa 9,68 dollari all'ora.
Normalizzando il rapporto costo-prestazioni di GPU e CPU, l'uso delle GPU per la creazione di indici produce comunque risultati migliori. A parità di costo, il tempo di creazione dell'indice è 12,5 volte più veloce utilizzando le GPU.
In un altro test di benchmark, abbiamo costruito un indice per 635M vettori a 1024 dimensioni. Utilizzando 8 GPU DGX H100, il tempo di costruzione dell'indice con il metodo IVF-PQ richiede circa 56 minuti. Al contrario, l'utilizzo di una CPU per eseguire lo stesso compito richiederebbe circa 6,22 giorni.
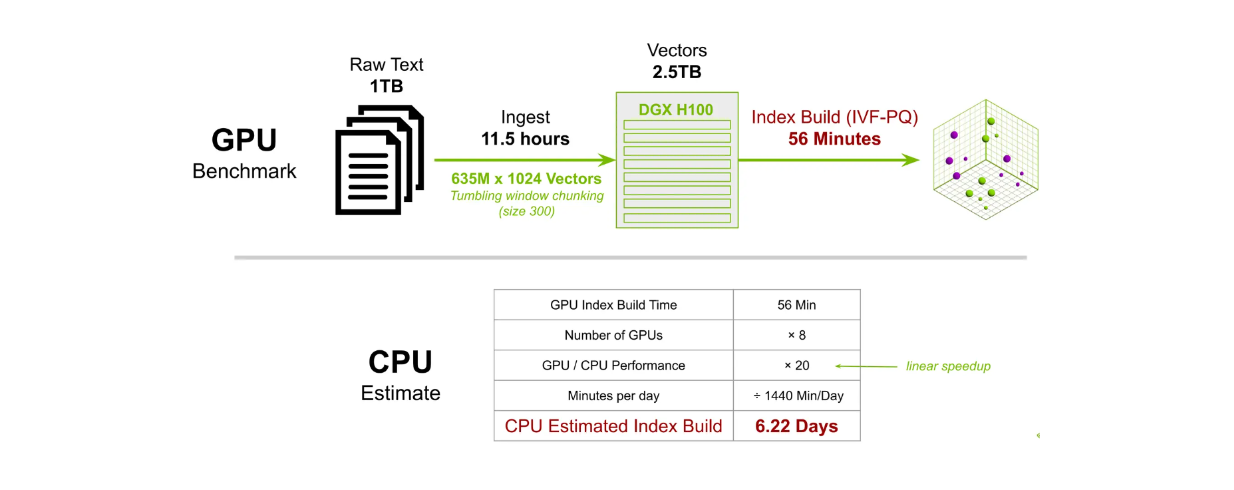 Confronto dei tempi di costruzione dell'indice di Milvus su larga scala tra GPU e CPU..png
Confronto dei tempi di costruzione dell'indice di Milvus su larga scala tra GPU e CPU..png
Confronto dei tempi di costruzione dell'indice di Milvus su larga scala tra GPU e CPU.
Conclusione
I progressi nella ricerca vettoriale accelerata dalle GPU grazie alla libreria NVIDIA cuVS e all'algoritmo CAGRA sono estremamente vantaggiosi per ottimizzare le prestazioni delle applicazioni di intelligenza artificiale in produzione. In particolare, le GPU offrono miglioramenti significativi rispetto alle CPU nei casi che prevedono valori di richiamo elevati, alta dimensionalità dei vettori e un numero elevato di vettori.
Grazie alle capacità di integrazione di Milvus, ora possiamo facilmente incorporare cuVS nel nostro database vettoriale Milvus. Sebbene le GPU abbiano costi operativi più elevati rispetto alle CPU, il rapporto prestazioni-costi spesso favorisce ancora le GPU nelle applicazioni su larga scala, come dimostrato dai benchmark sopra riportati. Se volete saperne di più su cuVS, potete consultare la documentazione completa fornita dal team NVIDIA.
Ulteriori risorse
Cos'è il RAG? ](https://zilliz.com/learn/Retrieval-Augmented-Generation)
Ricerca vettoriale efficiente in RecSys con Milvus e NVIDIA Merlin
Continua a leggere

How Zilliz Ended Up at the Center of NVIDIA’s Unstructured Data Story at GTC 2026
If unstructured data is the context of AI, then the ceiling of AI applications will be set not just by models, but by how mature the infrastructure for unstructured data becomes.

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.