




RAG locale agenziale con LangGraph e Llama 3.2
Aggiornato il 25 settembre 2024 con Llama 3.2.
In questo post dimostreremo come costruire agenti in grado di chiamare in modo intelligente strumenti per eseguire compiti specifici utilizzando LangGraph e Llama 3, sfruttando anche Milvus Lite per una memorizzazione efficiente dei dati. Questi agenti riuniscono diverse capacità importanti, tra cui la pianificazione, la memoria e la chiamata di strumenti, per migliorare le prestazioni dei sistemi di retrieval-augmented generation (RAG).
Introduzione a LangGraph e Llama 3
LangGraph è un'estensione di LangChain, progettata per costruire applicazioni multi-attore robuste e statiche con modelli linguistici di grandi dimensioni (LLM). Mentre LangChain offre un quadro di riferimento per l'integrazione degli LLM in vari flussi di lavoro, LangGraph lo migliora modellando i compiti come nodi e bordi in una struttura a grafo. Ciò consente flussi di controllo più complessi, permettendo agli LLM di pianificare, imparare e adattarsi al compito da svolgere. LangGraph offre la flessibilità necessaria per implementare sistemi in cui gli agenti utilizzano ragionamenti in più fasi, selezionando dinamicamente gli strumenti giusti per ogni fase. Inoltre, LangGraph può essere utilizzato per costruire agenti RAG affidabili che seguono un flusso di controllo definito dall'utente ogni volta che vengono eseguiti, garantendo coerenza e prevedibilità nelle loro risposte.
LangGraph consente anche comportamenti più complessi, simili a quelli degli agenti, permettendo di incorporare cicli nei flussi di lavoro. Questi cicli permettono agli agenti di tornare indietro alle fasi precedenti, se necessario, consentendo aggiustamenti dinamici delle azioni intraprese sulla base di nuove informazioni o riflessioni. In questo modo si ottengono agenti più intelligenti, capaci di affinare il loro ragionamento nel tempo, creando sistemi RAG più robusti e adattivi.
Llama 3, un modello linguistico open-source di grandi dimensioni, funge da motore di ragionamento centrale della memoria dell'agente. In combinazione con LangGraph, Llama 3 è in grado di analizzare l'input, decidere quali azioni intraprendere e invocare gli strumenti necessari. Anziché limitarsi a generare testo, Llama 3, alimentato da LangGraph, consente agli agenti di pianificare, eseguire e riflettere sulle proprie azioni, rendendoli più intelligenti e capaci.
In questo post mostreremo come creare un sistema agentic rag utilizzando LangGraph con Llama 3 e Milvus Lite. Questa configurazione consente di eseguire tutto in locale senza bisogno di server esterni, rendendola ideale per gli utenti attenti alla privacy e per gli ambienti offline.
Costruzione di un agente di chiamata di strumenti con LangGraph
Il flusso di lavoro di LangGraph è costruito attorno al concetto di nodi, dove ogni nodo rappresenta un compito o uno strumento specifico. Questi compiti possono includere la chiamata di LLM, il recupero di informazioni o l'invocazione di strumenti personalizzati. In un agente che richiama uno strumento, sono in gioco due componenti chiave:
**Questo nodo decide quale strumento utilizzare in base all'input dell'utente. Analizza la richiesta e fornisce il nome dello strumento e i relativi argomenti.
**Questo nodo prende il nome dello strumento e gli argomenti dal nodo LLM, invoca lo strumento appropriato e restituisce il risultato all'LLM.
Strutturando i compiti (come la ricerca sul web) come nodi e spigoli, LangGraph consente di creare flussi di lavoro intelligenti e in più fasi, in cui i LLM possono ragionare sulle domande degli utenti riguardo alle azioni da intraprendere, agli strumenti da utilizzare, alle risposte da dare alle domande e a come affinare le risposte. Milvus Lite svolge un ruolo fondamentale in questo senso, fornendo una memorizzazione e un recupero efficienti di [dati vettoriali] (https://zilliz.com/learn/an-ultimate-guide-to-vectorizing-structured-data) a livello locale.
Come Milvus Lite migliora gli agenti locali di chiamata degli strumenti
Milvus Lite è una versione locale e leggera di Milvus che non richiede Docker o Kubernetes per funzionare. In questo modo è facile eseguire Milvus sul proprio computer portatile, su un notebook Jupyter o anche su Google Colab. La distribuzione locale di Milvus Lite consente di memorizzare vettori generati da diverse fonti web o documenti senza dover ricorrere a [database] esterni (https://zilliz.com/glossary/ai-database). Si integra perfettamente con LangGraph per gestire le ricerche vettoriali, rendendolo una soluzione ideale per i sistemi RAG locali.
Ad esempio, Milvus Lite può essere utilizzato per memorizzare documenti indicizzati che vengono recuperati dall'agente durante una ricerca sul Web. Quando l'agente chiede informazioni, il database vettoriale consente di recuperare in modo rapido e preciso i documenti pertinenti.
Creazione di un sistema RAG locale con LangGraph e Llama 3
Utilizziamo LangGraph per costruire un agente RAG locale personalizzato alimentato da Llama 3.2 che utilizza diversi approcci:
Implementiamo ogni approccio come flusso di controllo in LangGraph:
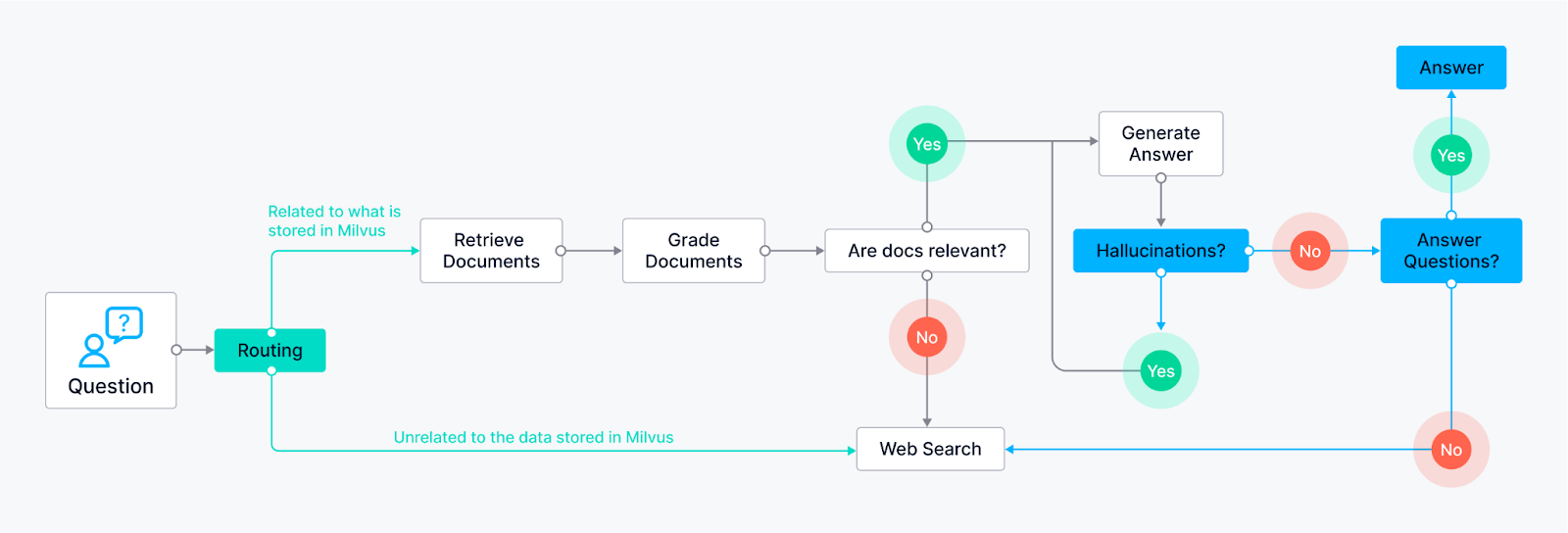
Instradamento (Adaptive RAG) - Consente all'agente di indirizzare in modo intelligente le richieste dell'utente verso il metodo di reperimento più adatto in base alla domanda stessa. Il nodo LLM analizza la domanda e, in base alle parole chiave o alla struttura della domanda, può indirizzarla a nodi di reperimento specifici.
Esempio 1: Le domande che richiedono risposte concrete potrebbero essere indirizzate a un nodo di reperimento di documenti che cerca in una base di conoscenza preindicizzata (alimentata da Milvus).
Esempio 2: Le domande aperte e creative potrebbero essere indirizzate al LLM per la generazione di compiti.
Fallback (Corrective RAG) - Assicura che l'agente abbia un piano di backup se i suoi metodi di reperimento iniziali non riescono a fornire risultati rilevanti. Supponiamo che i nodi di reperimento iniziali (ad esempio, il reperimento di documenti dalla base di conoscenza) non restituiscano risposte soddisfacenti (in base al punteggio di rilevanza o alle soglie di fiducia). In questo caso, l'agente ricorre a un nodo di ricerca sul web.
- Il nodo di ricerca web può utilizzare API di ricerca esterne.
Autocorrezione (Self-RAG) - Consente all'agente di identificare e correggere i propri errori o risultati fuorvianti. Il nodo LLM genera una risposta, che viene poi indirizzata a un altro nodo per la valutazione. Questo nodo di valutazione può utilizzare varie tecniche:
Riflessione: L'agente può verificare la sua risposta rispetto alla domanda originale per vedere se affronta tutti gli aspetti.
Analisi del punteggio di fiducia: Il LLM può assegnare un punteggio di fiducia alla sua risposta. Se il punteggio è inferiore a una certa soglia, la risposta viene rinviata al LLM per la revisione.
Idee generali per gli agenti
Il meccanismo di autocorrezione è una forma di riflessione in cui l'agente LangGraph riflette sul suo reperimento e sulle sue generazioni. Il meccanismo di autocorrezione è una forma di riflessione in cui l'agente LangGraph riflette sul suo reperimento e sulle sue generazioni.
Il flusso di controllo delineato nel grafo è una forma di pianificazione: l'agente non si limita a reagire alla domanda, ma stabilisce un processo passo dopo passo per recuperare o generare la risposta migliore.
Il flusso di controllo dell'agente LangGraph incorpora nodi specifici per vari strumenti. Questi possono includere nodi di recupero per la base di conoscenza (ad esempio, Milvus), dimostrando la sua capacità di attingere a un vasto bacino di informazioni, e nodi di ricerca sul web per informazioni esterne.
Esempi di agenti
Per mostrare le capacità dei nostri agenti LLM, analizziamo due componenti chiave: l'Hallucination Grader e l'Answer Grader. Il codice completo è disponibile in fondo a questo post, ma questi snippet ci faranno capire meglio come funzionano questi agenti all'interno del framework LangChain.
Classificatore di allucinazioni
L'Hallucination Grader cerca di risolvere una sfida comune con gli LLM: le allucinazioni, in cui il modello genera risposte che sembrano plausibili ma che mancano di fondamento fattuale. Questo agente agisce come un fact-checker, valutando se la risposta dell'LLM è in linea con un insieme di documenti recuperati da Milvus.
### Classificatore di allucinazioni
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template="""Sei un classificatore che valuta se
una risposta è fondata o supportata da un insieme di fatti. Fornisci un punteggio binario "sì" o "no" per indicare
se la risposta è fondata o supportata da un insieme di fatti. Fornire il punteggio binario come JSON con un'unica chiave "score" e nessun preconcetto.
singola chiave "score" e nessun preambolo o spiegazione.
Ecco i fatti:
{documenti}
Ecco la risposta:
{generazione}
""",
input_variables=["generation", "documents"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents": docs, "generation": generation})
Classificatore di risposte
Dopo l'Hallucination Grader, interviene un altro agente. Questo agente controlla un altro aspetto cruciale: assicurarsi che la risposta dell'LLM risponda direttamente alla domanda originale dell'utente. Utilizza lo stesso LLM ma con una richiesta diversa, specificamente progettata per valutare la pertinenza della risposta alla domanda.
def grade_generation_v_documents_and_question(state):
"""
Determina se la generazione è fondata sul documento e risponde alle domande.
Args:
stato (dict): Lo stato attuale del grafo
Restituisce:
str: Decisione per il prossimo nodo da chiamare
"""
print("---Controlla le allucinazioni---")
domanda = stato["domanda"]
documenti = stato["documenti"]
generazione = stato["generazione"]
punteggio = hallucination_grader.invoke({"documents": documenti, "generation": generazione})
voto = punteggio['punteggio']
# Controlla l'allucinazione
se voto == "sì":
print("---DECISIONE: GENERAZIONE È FONDATA SU DOCUMENTI---")
# Verifica la risposta alle domande
print("---Generazione del voto rispetto alla domanda---")
punteggio = answer_grader.invoke({"domanda": domanda, "generazione": generazione})
voto = punteggio['punteggio']
se voto == "sì":
print("---Decisione: la generazione affronta la domanda---")
restituire "utile"
altrimenti:
print("---DECISIONE: LA GENERAZIONE NON RISPONDE ALLA DOMANDA---")
restituire "non utile".
Altrimenti:
pprint("---DECISIONE: LA GENERAZIONE NON E' FONDATA SUI DOCUMENTI, RIPROVA---")
restituire "non supportato"
Nel codice precedente si può notare che stiamo verificando le previsioni del LLM che usiamo come classificatore.
Compilazione del grafico LangGraph
Questa operazione compila tutti gli agenti che abbiamo definito e rende possibile l'uso di diversi strumenti per il sistema RAG.
# Compilazione
app = workflow.compile()
# Test
da pprint import pprint
input = {"domanda": "Cos'è il prompt engineering?"}
per output in app.stream(inputs):
per chiave, valore in output.items():
pprint(f "Esecuzione terminata: {chiave}:")
pprint(valore["generazione"])
'Esecuzione terminata: generazione:'
('L'ingegneria dei prompt è il processo di comunicazione con i grandi modelli linguistici '
'modelli di grandi dimensioni (LLM) per orientare il loro comportamento verso i risultati desiderati senza '
'aggiornare i pesi del modello. Si concentra sull'allineamento e sulla guidabilità del modello, ' 'richiedendo sperimentazione e euristica.
'che richiede sperimentazione ed euristica a causa degli effetti variabili tra i '
'modelli. L'obiettivo è migliorare la generazione di testo controllabile ottimizzando i ' 'suggerimenti per applicazioni specifiche.
' 'suggerimenti per applicazioni specifiche.')
Conclusione
In questo post abbiamo mostrato come costruire un sistema RAG utilizzando agenti con LangChain/ LangGraph, Llama 3.2 e Milvus. Questi agenti permettono ai LLM di avere capacità di pianificazione, di memoria e di utilizzo di strumenti diversi, che possono portare a risposte più robuste e informative.
Prossimi passi per il miglioramento
Sebbene l'attuale implementazione del sistema agentic RAG sia efficace per i flussi di lavoro locali a singolo agente, ci sono diverse direzioni interessanti per ulteriori miglioramenti e innovazioni.
**Attualmente LangGraph viene utilizzato per progettare sistemi a singolo agente che operano all'interno di un flusso di controllo predefinito, come una ricerca sul web. Tuttavia, un'evoluzione naturale sarebbe quella di estendere questo sistema per supportare più agenti che lavorano in parallelo o in coordinamento. In scenari in cui un compito richiede conoscenze specialistiche o fonti di reperimento multiple, gli agenti possono elaborare in modo collaborativo diverse parti del compito. Ad esempio, un agente potrebbe concentrarsi sul reperimento di informazioni fattuali, mentre un altro gestisce compiti creativi o l'interazione con l'utente e un terzo valuta la qualità complessiva dell'output. Questi sistemi multi-agente consentirebbero operazioni più complesse, che porterebbero a una maggiore efficienza e accuratezza nella gestione di query diverse.
Aggiornamenti Dati in tempo reale** Un altro potenziale miglioramento potrebbe essere quello di consentire agli agenti di aggiornare le loro fonti di dati in tempo reale. Attualmente, Milvus Lite funge da base di conoscenza statica; tuttavia, in domini dinamici, le informazioni possono diventare rapidamente obsolete. Gli agenti potrebbero essere progettati per monitorare e aggiornare continuamente il loro archivio vettoriale locale con dati freschi provenienti dal web o da altre API, garantendo che i risultati del sistema rimangano pertinenti e aggiornati. Ad esempio, se a un agente vengono chieste le ultime quotazioni azionarie o le ultime notizie, potrebbe recuperare automaticamente i dati più recenti, rendendo il sistema molto più adattabile e utile in ambienti con ritmi frenetici.
**Sebbene l'attuale meccanismo di riflessione sia utile, c'è spazio per un miglioramento in termini di autocorrezione. Le versioni future dell'agente potrebbero incorporare tecniche più avanzate, come l'apprendimento per rinforzo o i meccanismi di apprendimento continuo, consentendo all'agente di imparare dalle esperienze passate e dagli errori commessi nel corso del tempo. Consentendo all'agente di lavorare sulla memoria per migliorare la qualità delle sue risposte in modo iterativo, potremmo ottenere un sistema che non solo recupera e genera risposte di alta qualità, ma affina anche i suoi processi in base al feedback.
Incorporando queste fasi successive, possiamo migliorare in modo significativo le capacità dei sistemi agenziali RAG, rendendoli più flessibili, adattivi ed efficaci nella risoluzione di compiti complessi in una varietà di settori.
Non esitate a consultare il codice disponibile nel [repository Milvus Bootcamp] (https://github.com/milvus-io/bootcamp/tree/master/bootcamp/RAG/advanced_rag).
Se vi è piaciuto questo post che mostra come costruire langgraph agentic rag, dateci una stella su , e condividete le vostre esperienze con la comunità iscrivendovi al nostro sito
Questo è ispirato al Repository Github di Meta con le ricette per l'uso di Llama 3.

Continua a leggere

How Zilliz Saw the Future of Vector Databases—and Built for Production
An inside look at how Zilliz built vector databases for real-world use, focusing on scalability, stability, and running them reliably at scale.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.