




ColPali: Recupero di documenti migliorato con modelli linguistici di visione e strategia di incorporazione ColBERT
La Retrieval Augmented Generation (RAG) è una tecnica che combina le capacità dei modelli linguistici di grandi dimensioni (LLMs con fonti di conoscenza esterne per migliorare l'accuratezza e la rilevanza delle risposte. Un'applicazione comune della RAG è l'estrazione di contenuti da fonti come i PDF, poiché questi file spesso contengono dati preziosi ma sono difficili da cercare e indicizzare. La difficoltà risiede nel fatto che le informazioni importanti possono essere trascurate a seconda dello strumento utilizzato per l'estrazione. Ad esempio, il testo incorporato nelle immagini potrebbe non essere rilevato durante l'estrazione, rendendo impossibile il successivo recupero.
ColPali, un modello di recupero di documenti, affronta questo problema con la sua nuova architettura basata su modelli linguistici di visione (VLM). Indicizza i documenti attraverso le loro caratteristiche visive, catturando gli elementi testuali e visivi. Generando rappresentazioni multivettoriali di testo e immagini in stile ColBERT, ColPali codifica le immagini dei documenti direttamente in uno spazio di incorporamento unificato, eliminando la necessità di estrarre e segmentare il testo in modo tradizionale.
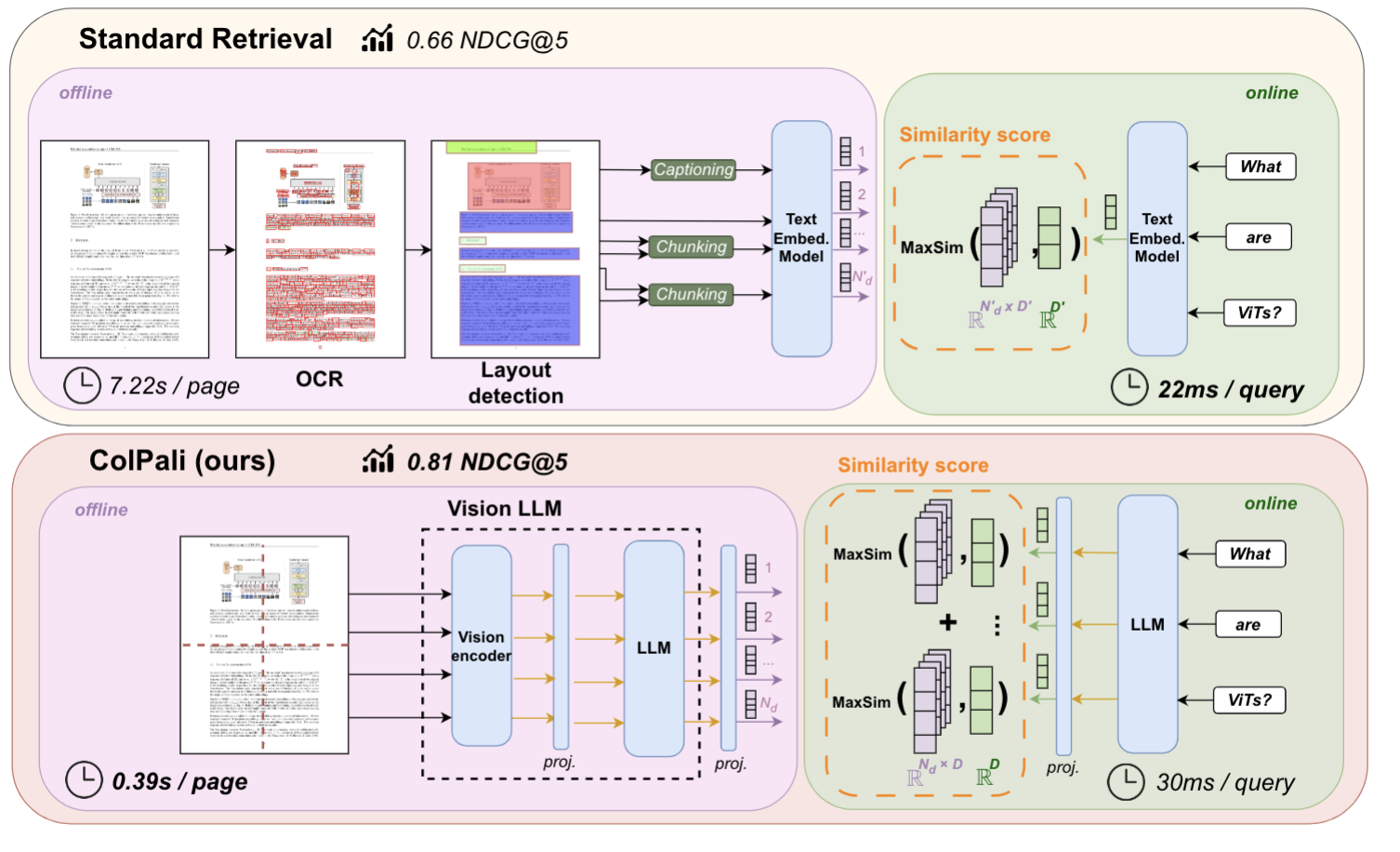 Figura: Pipeline di recupero standard vs. Pipeline ColPali per il recupero di PDF
Figura: Pipeline di recupero standard vs. Pipeline ColPali per il recupero di PDF
L'immagine qui sopra è tratta dall'articolo di ColPali, in cui gli autori sostengono che una normale pipeline di recupero di PDF di solito include più fasi: estrazione del testo tramite OCR, rilevamento del layout, chunking e generazione di embedding. ColPali semplifica questo processo utilizzando un unico Vision Language Model (VLM) che prende in input una schermata della pagina.
ColPali integra strumenti che vanno oltre i tradizionali sistemi RAG, quindi è importante capire prima alcuni di questi concetti. Prima di discutere i dettagli di ColPali, impariamo a conoscere i modelli linguistici di visione e i modelli di interazione tardiva.
Cosa sono i modelli linguistici di visione (VLM)?
I Modelli linguistici di visione (VLM) sono modelli multimodali che apprendono contemporaneamente da immagini e testo. Prendono in input immagini e testo e generano output testuali e fanno parte della più ampia categoria dei modelli generativi.
Esempio di VLM](https://assets.zilliz.com/vision_language_model_3_36f9866f43.png)
ColPali sfrutta i VLM per allineare gli embedding dei token di testo e immagine acquisiti durante la messa a punto multimodale. In particolare, utilizza una versione estesa del modello PaliGemma-3B per produrre rappresentazioni multivettoriali ColBERT-style. Gli autori hanno scelto questo modello perché dispone di una serie di punti di controllo ottimizzati per diverse risoluzioni e compiti delle immagini, tra cui l'OCR per la lettura del testo dalle immagini.
ColPali è costruito sul modello PaliGemma-3B di Google, che è stato rilasciato con pesi aperti. Questo modello è stato addestrato utilizzando un set di dati eterogeneo, per il 63% accademico e per il 37% sintetico, proveniente da pagine PDF scartabellate dal web e arricchito da pseudo-domande generate da VLM.
Cosa sono i modelli di interazione tardiva?
I modelli Late Interaction sono progettati per compiti di recupero. Si concentrano sulla somiglianza a livello di token tra i documenti, anziché utilizzare una singola rappresentazione vettoriale. Rappresentando il testo come una serie di embeddings di token, questi modelli offrono il dettaglio e l'accuratezza dei cross-encoder, beneficiando al contempo dell'efficienza dell'archiviazione offline dei documenti.
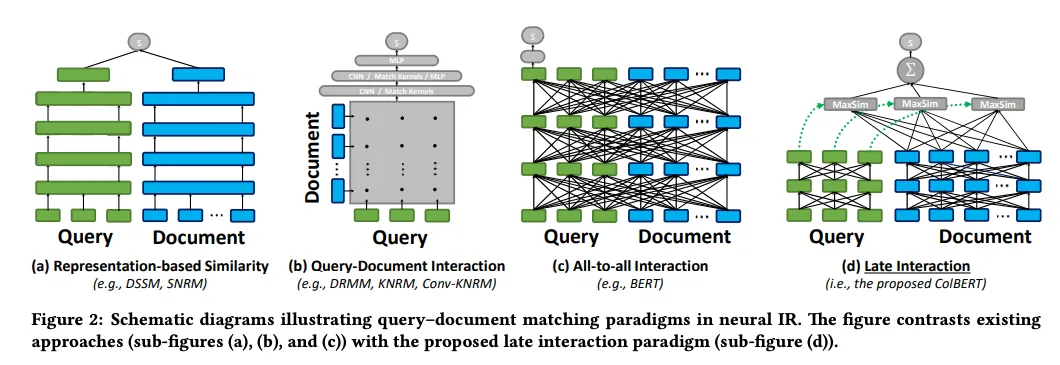 Figura 2: Diagrammi schematici che illustrano i paradigmi di corrispondenza query-documento nell'IR neurale
Figura 2: Diagrammi schematici che illustrano i paradigmi di corrispondenza query-documento nell'IR neurale
Figura 2: Schemi che illustrano i paradigmi di query-document matching nell'IR neurale. | Fonte](https://arxiv.org/pdf/2004.12832)_
Con questa comprensione dei Modelli di interazione e dei modelli linguistici di visione, possiamo ora esplorare il modo in cui ColPali combina questi elementi per migliorare il reperimento dei documenti.
Cos'è ColPali e come funziona?
ColPali è un modello avanzato di recupero dei documenti progettato per indicizzare e recuperare informazioni direttamente dalle caratteristiche visive dei documenti, in particolare dei PDF. A differenza dei metodi tradizionali che si basano sull'OCR (Optical Character Recognition) e sulla segmentazione del testo, ColPali acquisisce schermate di ogni pagina e incorpora le intere pagine del documento in uno spazio vettoriale unificato utilizzando i VLM. Questo approccio consente a ColPali di bypassare i complessi processi di estrazione, migliorando l'accuratezza e l'efficienza del recupero.
Di seguito sono riportati i passaggi chiave del flusso di lavoro:
Elaborazione dei documenti
- Invece di estrarre il testo, creare pezzi e poi incorporarli, ColPali incorpora direttamente lo screenshot di una pagina PDF in una rappresentazione vettoriale. Questo passaggio equivale a scattare una foto di ogni pagina, anziché cercare di estrarne il contenuto.
- Suddivisione delle immagini in griglie: Ogni pagina viene quindi divisa in una griglia di pezzi uniformi chiamati patch. Per impostazione predefinita, viene suddivisa in una griglia di 32x32, con il risultato di 1024 patch per immagine. Ogni patch è rappresentata come un vettore a 128 dimensioni. Si può pensare a un'immagine con 1024 "parole" che descrivono le patch.
Generazione di incorporazioni
- Elaborazione di patch di immagini: ColPali trasforma queste patch visive in embeddings attraverso un Vision Transformer (ViT), che elabora ogni patch per creare una rappresentazione vettoriale dettagliata.
- Allineamento delle incorporazioni visive e testuali: Per abbinare le informazioni visive alla query di ricerca, ColPali converte il testo della query in embeddings nello stesso spazio vettoriale delle patch dell'immagine. Questo allineamento consente al modello di confrontare e abbinare direttamente i contenuti visivi e testuali.
- Elaborazione della domanda: Il modello tokenizza la query, assegnando a ogni token un vettore di 128 dimensioni. Utilizza richieste come "Descrivi questa immagine
" per garantire che il modello si concentri sugli elementi visivi, consentendo una perfetta integrazione dei dati testuali e visivi.
Meccanismo di recupero
ColPali utilizza un meccanismo di similarità dell'interazione tardiva per confrontare le incorporazioni della query e del documento al momento dell'interrogazione. Questo approccio consente un'interazione dettagliata tra tutti i vettori delle celle della griglia dell'immagine e i vettori dei token del testo della query, garantendo un confronto completo.
La somiglianza viene calcolata utilizzando un approccio di "somma delle somiglianze massime":
- Calcolo dei punteggi di somiglianza tra ogni token della query e ogni token della patch nell'immagine.
- Aggregare questi punteggi per generare un punteggio di rilevanza per ogni documento.
- Ordinare i documenti in base al punteggio in ordine decrescente, utilizzando il punteggio come misura di rilevanza.
Questo metodo consente a ColPali di abbinare efficacemente le query dell'utente ai documenti pertinenti, concentrandosi sulle patch dell'immagine che meglio si allineano con il testo della query. In questo modo si evidenziano le porzioni più rilevanti del documento, combinando il contenuto testuale e visivo per un reperimento preciso.
Processo di formazione del modello
ColPali si basa sul modello PaliGemma-3B, un modello di linguaggio di visione sviluppato da Google. Nella sua implementazione, ColPali mantiene i pesi del modello congelati durante l'addestramento per conservare la conoscenza pre-addestrata del VLM, concentrandosi al contempo sulla ottimizzazione dei compiti di recupero dei documenti.
La chiave per adattare questo VLM generico al reperimento di documenti risiede in un componente piccolo ma cruciale: **Questo adattatore si sovrappone al modello PaliGemma-3B e viene addestrato per apprendere rappresentazioni adatte ai compiti di recupero.
Il processo di addestramento di questo adattatore utilizza un approccio di apprendimento a triplette:
- Un'interrogazione di testo
- Un'immagine di una pagina pertinente alla query
- Un'immagine di una pagina irrilevante per la query
Questo metodo consente al modello di apprendere distinzioni a grana fine tra contenuti rilevanti e irrilevanti, migliorando l'accuratezza del reperimento.
Vantaggi di ColPali
- Eliminazione della complessa pre-elaborazione: ColPali sostituisce la tradizionale pipeline di estrazione del testo, OCR, rilevamento del layout e chunking con un unico VLM che prende in input uno screenshot della pagina.
- Cattura di informazioni visive e testuali**: Lavorando direttamente con le immagini delle pagine, ColPali può incorporare sia il contenuto testuale che il layout visivo nella comprensione dei documenti.
- Recupero efficiente di documenti visivamente ricchi: Il meccanismo di interazione tardiva permette una corrispondenza a grana fine tra le query e il contenuto del documento, consentendo di recuperare in modo efficiente le informazioni rilevanti da documenti complessi e visivamente ricchi.
- Preservazione del contesto: Operando su immagini di pagine intere, ColPali mantiene il contesto completo del documento, che può andare perso negli approcci tradizionali di text-chunking.
Le sfide di ColPali
Come ogni sistema di reperimento su larga scala, ColPali deve affrontare sfide significative in termini di complessità computazionale e requisiti di archiviazione.
Complessità computazionale: I requisiti di calcolo di ColPali crescono quadraticamente con il numero di token della query e di vettori patch. Ciò significa che all'aumentare della complessità delle interrogazioni o della risoluzione delle immagini dei documenti, la richiesta computazionale cresce rapidamente.
Requisiti di memorizzazione: Il costo di memorizzazione degli approcci simili a ColBERT è da 10 a 100 volte superiore a quello dell'incorporazione vettoriale densa, poiché richiede un vettore per ogni token. Le esigenze di archiviazione del sistema scalano linearmente con tre fattori:
Numero di documenti
Numero di patch per documento
Dimensionalità delle rappresentazioni vettoriali.
Questa scalatura può comportare notevoli requisiti di memorizzazione per le raccolte di documenti di grandi dimensioni.
Strategia di ottimizzazione - Riduzione della precisione
Per affrontare queste sfide di scalabilità, suggeriamo di utilizzare la strategia di riduzione della precisione.
- Riduzione della precisione: Passare da rappresentazioni ad alta precisione (ad esempio, i float a 32 bit) a formati a bassa precisione (ad esempio, gli interi a 8 bit) può ridurre drasticamente i requisiti di memorizzazione con un impatto spesso minimo sulla qualità del recupero.
Sintesi
ColPali ha un potenziale significativo per trasformare il modo in cui recuperiamo contenuti visivamente ricchi con un contesto testuale nei sistemi RAG. Sfruttando i modelli linguistici di visione, consente di recuperare documenti basati non solo sul testo, ma anche sugli elementi visivi.
Tuttavia, nonostante i risultati impressionanti, ColPali deve affrontare delle sfide dovute all'elevata richiesta di spazio di archiviazione e alla complessità computazionale, che potrebbero ostacolarne l'adozione su larga scala. Le future ottimizzazioni potrebbero risolvere questi limiti, rendendolo più pratico. Con il continuo sviluppo dei metodi RAG, i metodi di reperimento come ColPali, che integrano la comprensione visiva e testuale, probabilmente svolgeranno un ruolo sempre più importante nel information retrieval per diversi tipi di documenti.
Ci piacerebbe sapere cosa ne pensate!
Se questo post vi è piaciuto, vi saremmo grati se ci deste una stella su GitHub! Siete anche invitati a unirvi alla nostra comunità Milvus su Discord per condividere le vostre esperienze. Se sei interessato a saperne di più, dai un'occhiata al nostro repository Bootcamp su GitHub o ai nostri notebook. Ci piacerebbe anche sapere se avete intenzione di provare ColPali in futuro!
Ulteriori letture
- Carta ColPali: [2407.01449] ColPali: Efficient Document Retrieval with Vision Language Models
- ColPali GitHub: https://github.com/illuin-tech/colpali
- ColBERT: A Token-Level Embedding and Ranking Model
- ColPali: Recupero di documenti con modelli linguistici di visione
- Cos'è il RAG?
- Cosa sono i database vettoriali e come funzionano?

Continua a leggere

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.