




Scegliere il giusto modello di incorporazione per i propri dati
Cosa sono i modelli di incorporamento?
I modelli di embedding sono modelli di apprendimento automatico che trasformano dati non strutturati (testo, immagini, audio, ecc.) in vettori di dimensioni fisse, noti anche come embedding vettoriali (sparse, dense, embedding binario, ecc.). Questi vettori catturano il significato semantico dei dati non strutturati, facilitando l'esecuzione di varie attività come la ricerca per similarità, l'elaborazione del linguaggio naturale (NLP), la computer vision, il clustering, la classificazione e altro ancora.
Esistono vari tipi di modelli di embedding, tra cui embedding di parole, embedding di frasi, embedding di immagini, embedding multimodali e molti altri.
Incorporazioni di parole: Rappresenta le parole come [vettori densi] (https://zilliz.com/learn/sparse-and-dense-embeddings). Gli esempi includono Word2Vec, GloVe e FastText.
Sentence Embeddings: Rappresentano intere frasi o paragrafi. Esempi sono Universal Sentence Encoder (USE) e Sentence-BERT.
Image Embeddings: Rappresentano le immagini come vettori. Esempi sono modelli come ResNet e CLIP.
Integrazioni multimodali: Combinano diversi tipi di dati (ad esempio, testo e immagini) in un unico spazio di incorporamento. CLIP di OpenAI ne è un esempio significativo.
Modelli di incorporamento e generazione aumentata di recupero (RAG)
La Retrieval Augmented Generation (RAG) è un modello di IA generativa in cui è possibile utilizzare i dati per aumentare la conoscenza del modello generatore LLM (come ChatGPT). Questo approccio è una soluzione perfetta per risolvere i fastidiosi problemi di allucinazione degli LLM. Può anche aiutare a sfruttare i dati privati o specifici del dominio per costruire applicazioni di IAgen senza preoccuparsi dei problemi di sicurezza dei dati.
RAG è costituito da due diversi modelli, i [embedding models] (https://zilliz.com/ai-models) e i [large language models] (https://zilliz.com/glossary/large-language-models-(llms)) (LLM), entrambi utilizzati in modalità di inferenza. Questo blog illustra come scegliere il modello di incorporamento migliore e dove trovarlo in base al tipo di dati ed eventualmente alla lingua o al dominio di specializzazione, come ad esempio il diritto.
Come scegliere il miglior modello di incorporamento per i vostri dati
La scelta del modello di incorporamento più adatto ai dati richiede la comprensione del caso d'uso specifico, del tipo di dati e dei requisiti di prestazione dell'applicazione.
Dati di testo: MTEB Classifica
La classifica di HuggingFace MTEB è uno sportello unico per trovare modelli di incorporamento del testo! Per ogni modello di incorporamento, è possibile vedere la sua prestazione media nei compiti complessivi.
Un buon modo per iniziare è quello di **ordinare in senso decrescente in base alla colonna "Retrieval Average" (media di recupero), poiché è l'attività più correlata alla ricerca vettoriale. Quindi, cercate il modello più piccolo (GB di memoria) con la migliore valutazione.
La dimensione di incorporazione è la lunghezza del vettore, cioè la parte y di f(x)=y, che il modello produrrà.
Max tokens è la lunghezza del pezzo di testo in ingresso, cioè la parte x in f(x)=y, che è possibile inserire nel modello.
Oltre all'attività di recupero, è possibile filtrare anche in base a:
Lingua: francese, inglese, cinese o polacco. Ad esempio, compito=recupero e Lingua=cinese.
Ad esempio, task=retrieval and Language=law, per modelli ottimizzati su testi giuridici.
Sfortunatamente, poiché i dati di addestramento sono stati resi pubblici solo di recente, alcune voci di MTEB sono modelli sovradimensionati, che si posizionano ingannevolmente più in alto rispetto alle prestazioni realistiche che otterranno sui vostri dati. Questo blog di HuggingFace contiene suggerimenti per decidere se fidarsi di un modello di classificazione. Fate clic sul link del modello (chiamato "scheda modello").
Cercate blog e documenti** che spieghino come il modello è stato addestrato e valutato. Osservate attentamente le lingue, i dati e i compiti su cui il modello è stato addestrato. Inoltre, cercate modelli creati da aziende affidabili. Ad esempio, nella scheda del modello voyage-lite-02-instruct sono elencati altri modelli VoyageAI di produzione, ma non questo. Questo è un indizio! Questo modello è un modello di vanity overfit. **Non usatelo!
Nella schermata qui sotto, proverei la nuova voce di Snowflake, "snowflake-arctic-embed-1", perché è di alto livello, abbastanza piccola da poter essere eseguita sul mio portatile e la scheda del modello ha collegamenti a un blog e a un documento.
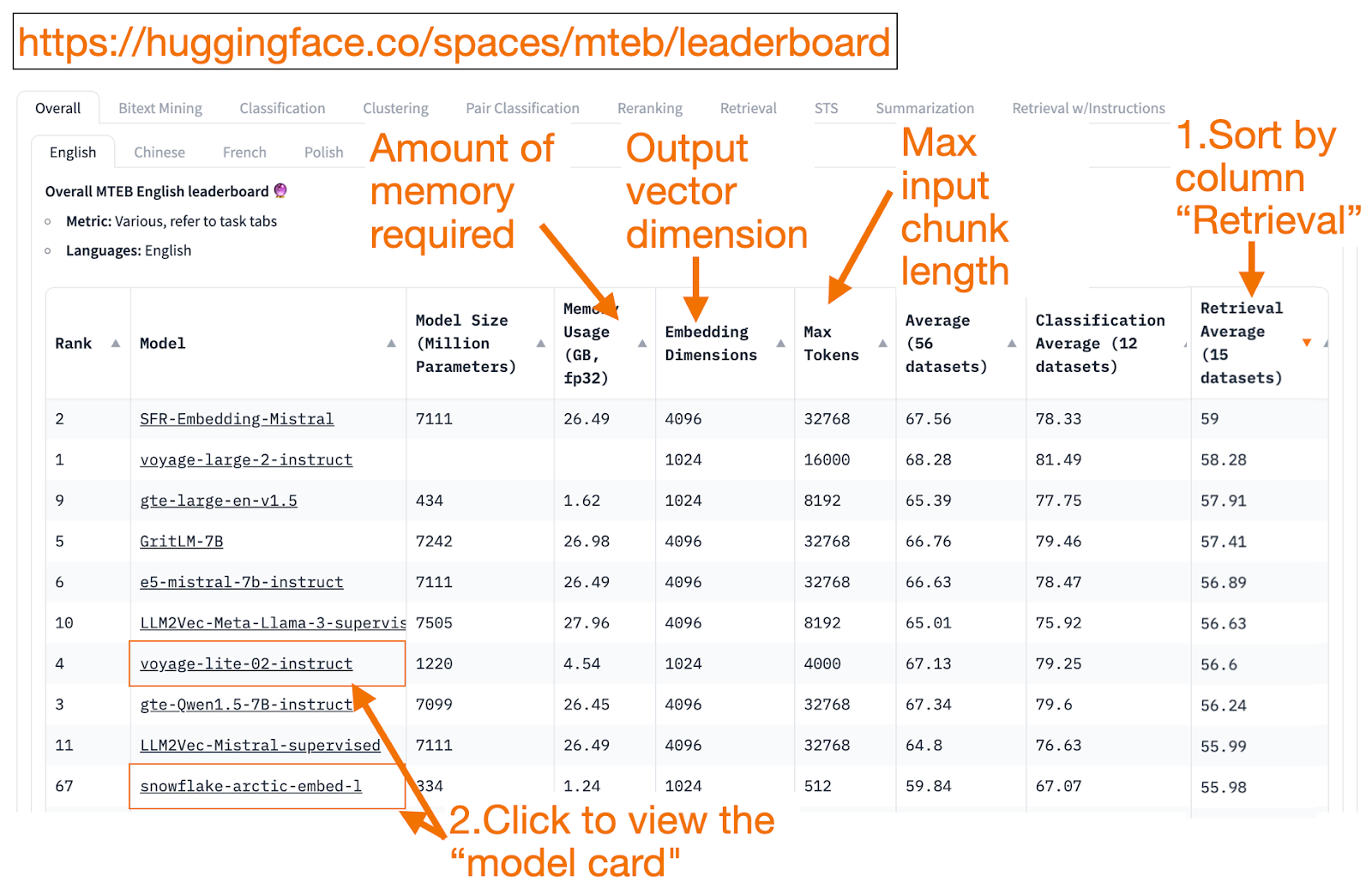 Immagine di Snowflake sulla classifica MTEB
Immagine di Snowflake sulla classifica MTEB
Una volta scelto il modello di incorporamento, la cosa bella di usare i modelli HuggingFace è che si può cambiare il modello cambiando **nome_modello** nel codice!
importare torch
da sentence_transformers import SentenceTransformer
# Inizializza le impostazioni di torch
torch.backends.cudnn.deterministic = True
DEVICE = torch.device('cuda:3' if torch.cuda.is_available() else 'cpu')
# Carica il modello da huggingface.
model_name = "WhereIsAI/UAE-Large-V1" # Basta cambiare model_name per usare un modello diverso!
encoder = SentenceTransformer(model_name, device=DEVICE)
# Ottenere i parametri del modello e salvarli in seguito.
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# Stampa i parametri del modello.
print(f "nome_modello: {nome_modello}")
print(f "EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH_IN_TOKENS}")

Dati immagine: ResNet50
A volte si desidera cercare immagini simili a un'immagine di input. Forse si stanno cercando altre immagini di gatti Scottish Fold? In questo caso, si dovrebbe caricare la propria immagine preferita di un gatto Scottish Fold e chiedere al motore di ricerca di trovare immagini simili!
ResNet50 è un popolare modello di Rete neurale convoluzionale (CNN) originariamente addestrato nel 2015 da Microsoft sui dati di ImageNet.
Analogamente, per la ricerca inversa di video, ResNet50 può ancora incorporare video. Quindi, viene eseguita una ricerca di somiglianza delle immagini inversa sul database dei fotogrammi video. Il video più vicino (escluso l'input) viene restituito all'utente come video più simile.
Dati sonori: PANN
Analogamente a quanto avviene per la ricerca inversa di un'immagine utilizzando un'immagine in ingresso, è possibile anche effettuare una ricerca inversa di clip audio sulla base di un suono in ingresso.
Le PANN (Pretrained Audio Neural Networks) sono modelli di incorporamento popolari per questo compito, perché sono pre-addestrati su insiemi di dati audio su larga scala e sono bravi in compiti come la classificazione e il tagging audio.
Dati di immagini e testi multimodali: SigLIP o Unum
Negli ultimi anni sono emersi modelli di embedding addestrati su un mix di Unstructured Data: Testo, Immagine, Audio o Video. Tali modelli di embedding catturano la semantica di più tipi di dati non strutturati contemporaneamente nello stesso spazio vettoriale.
I modelli di embedding multimodale consentono di utilizzare il testo per cercare immagini, generare descrizioni testuali di immagini o effettuare una ricerca inversa di immagini a partire da un'immagine di input.
CLIP (Contrastive Language-Image Pretraining) di OpenAI nel 2021 era il modello di embedding standard. Tuttavia, i professionisti lo trovavano difficile da usare perché doveva essere messo a punto. Nel 2024, SigLIP, o sigmoidal-CLIP da Google, sembra essere un CLIP migliorato, con segnalazioni di buoni risultati utilizzando i prompt zero-shot.
Le varianti a modello ridotto di LLM stanno diventando popolari. Invece di richiedere un grande cluster di cloud computing, possono essere eseguiti su computer portatili (come il mio M2 Apple con solo 16 GB di RAM). I modelli piccoli utilizzano meno memoria, il che significa che hanno una latenza inferiore e possono potenzialmente funzionare più velocemente dei modelli grandi. Unum offre modelli di incorporazione multimodali di piccole dimensioni.
Dati multimodali di testo e/o suono e/o video
La maggior parte dei sistemi RAG multimodali da testo a suono utilizza un LLM generativo multimodale per convertire prima il suono in testo. Una volta create le coppie suono-testo, il testo viene incorporato in vettori e si può utilizzare il RAG per recuperare il testo nel modo consueto. Nell'ultima fase, il testo viene mappato nuovamente in suono per terminare il ciclo Text-to-Sound o viceversa.
Whisper di OpenAI può trascrivere il parlato in testo.
Anche Text-to-speech (TTS) di OpenAI può convertire il testo in audio parlato.
I sistemi Multimodal Text-to-Video RAG utilizzano un approccio simile per mappare prima i video in testo, incorporare il testo, cercare il testo e restituire i video come risultati della ricerca.
Sora di OpenAI può convertire il testo in video. Come Dall-e, l'utente fornisce il testo richiesto e il LLM genera un video. Sora può anche generare video da immagini fisse o altri video.
Sintesi
Questo blog ha toccato alcuni modelli di embedding popolari utilizzati nelle applicazioni RAG.
Ulteriori risorse
Riferimenti
MTEB leaderboard, paper, Github: https://huggingface.co/spaces/mteb/leaderboard
Migliori pratiche MTEB per evitare di scegliere un modello overfit: https://huggingface.co/blog/lyon-nlp-group/mteb-leaderboard-best-practices
Ricerca di immagini simili: https://milvus.io/docs/image_similarity_search.md
Ricerca da immagine a video: https://milvus.io/docs/video_similarity_search.md
Ricerca di suoni simili: https://milvus.io/docs/audio_similarity_search.md
Ricerca da testo a immagine: https://milvus.io/docs/text_image_search.md
2024 Documento SigLIP (sigmoid loss CLIP): https://arxiv.org/pdf/2401.06167v1
Modelli di incorporazione multimodale tascabili di Unum: https://github.com/unum-cloud/uform

Continua a leggere

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Our Journey to 35K+ GitHub Stars: The Real Story of Building Milvus from Scratch
Join us in celebrating Milvus, the vector database that hit 35.5K stars on GitHub. Discover our story and how we’re making AI solutions easier for developers.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.