




Scalable and Reliable : Un guide simple de l'informatique distribuée
Scalable and Reliable : Un guide simple de l'informatique distribuée
L'informatique distribuée consiste à exécuter des tâches ou des processus sur plusieurs ordinateurs connectés afin d'améliorer les performances, l'évolutivité et la fiabilité. Au lieu de s'appuyer sur une seule machine puissante, la charge de travail est répartie entre plusieurs nœuds, qui peuvent traiter des ensembles de données et des calculs plus importants de manière plus efficace. Cette approche constitue l'épine dorsale de nombreuses applications modernes axées sur les données, notamment les plateformes de commerce électronique, les pipelines d'apprentissage automatique, les analyses en temps réel, les réseaux de capteurs IoT et les simulations de recherche à haute performance.
 Informatique distribuée
Informatique distribuée
Figure: Informatique répartie
Du serveur unique aux systèmes distribués : L'évolution
Pendant longtemps, de nombreuses organisations se sont appuyées sur de grands serveurs centralisés - souvent appelés architectures monolithiques - pour faire fonctionner leurs applications. Toutefois, cette configuration présentait des inconvénients évidents :
Évolutivité limitée : Pour augmenter la capacité, il fallait acheter de plus gros serveurs, ce qui était coûteux et prenait du temps.
Un seul point de défaillance** : L'ensemble du système s'arrête si le serveur principal tombe en panne.
Mises à jour complexes** : Il était risqué d'apporter des modifications ou des mises à niveau, car tout était hébergé au même endroit.
Les grappes, qui regroupent des serveurs plus petits, ont apporté un certain soulagement, mais n'ont toujours pas résolu complètement les problèmes de [mise à l'échelle] (https://zilliz.com/learn/scaling-vector-databases-to-meet-enterprise-demands) et de fiabilité. C'est là que l'informatique distribuée est intervenue. En répartissant les tâches et les données sur plusieurs nœuds connectés, les systèmes distribués :
évoluent plus rapidement et de manière plus abordable : Vous pouvez ajouter des nœuds au lieu de remplacer un seul gros serveur.
Améliorent la tolérance aux pannes** : Si un nœud tombe en panne, les autres peuvent maintenir le système en ligne.
Gérer les charges de travail lourdes** : Plusieurs nœuds travaillant ensemble peuvent traiter de gros volumes de données plus efficacement.
Des solutions modernes telles que Milvus de Zilliz s'appuient sur ces principes pour gérer de grandes quantités de données à haute dimension. Milvus prend en charge les recherches de similarités à grande échelle en distribuant les données sur plusieurs nœuds et maintient des performances élevées, même dans des conditions exigeantes.
Comment fonctionne l'informatique distribuée ?
L'informatique distribuée est un modèle dans lequel plusieurs machines (ou nœuds) travaillent ensemble pour accomplir des tâches qu'il serait difficile ou inefficace de traiter sur une seule machine. Chaque nœud d'un système distribué peut exécuter des fonctions spécifiques, telles que le stockage de données ou le traitement de calculs, et le système coordonne ces tâches pour fonctionner comme un tout unifié. Cette approche permet donc d'obtenir de meilleures performances, une meilleure [tolérance aux pannes] (https://zilliz.com/ai-faq/how-do-distributed-databases-ensure-fault-tolerance) et des options de mise à l'échelle flexibles.
Principes fondamentaux
Distribution des tâches](https://zilliz.com/ai-faq/how-does-data-distribution-work-in-a-distributed-database): L'idée principale de l'informatique distribuée est de diviser les gros travaux en tâches plus petites et de les assigner à différents nœuds. En divisant les charges de travail, chaque nœud peut travailler sur sa partie en parallèle, ce qui accélère le traitement et évite qu'une machine ne soit surchargée.
Data Partitioning](https://zilliz.com/ai-faq/what-is-data-partitioning-and-why-is-it-important-in-distributed-databases): Les données sont divisées en segments (souvent appelés "shards"). Chaque nœud stocke un ou plusieurs de ces segments pour les lire et les écrire en parallèle. Cela accélère l'accès aux données et facilite la mise à l'échelle : lorsque les données augmentent, il suffit d'ajouter des nœuds et de les partitionner davantage.
Synchronisation et coordination: Les tâches et les données étant dispersées, il est essentiel que les nœuds restent synchronisés afin d'éviter les mises à jour conflictuelles. Les systèmes distribués utilisent des protocoles et des algorithmes, tels que des mécanismes de consensus, pour garantir que chaque nœud conserve une vue cohérente des données. Ces méthodes permettent à toutes les parties du système de se mettre d'accord sur les changements, même lorsqu'ils se produisent simultanément.
Composants des systèmes distribués
 Composants des systèmes distribués
Composants des systèmes distribués
Figure: Composants d'un système distribué
Nœuds (ou hôtes) : Chaque nœud exécute des tâches ou stocke des données. Dans de nombreux cas, les nœuds peuvent être des serveurs physiques, des machines virtuelles ou des conteneurs. Lors de l'utilisation d'un système comme Milvus, chaque nœud peut contenir un segment de l'index vectoriel, ce qui permet d'effectuer des recherches distribuées dans de grands ensembles de données sans surcharger une seule machine.
Réseau : Le réseau est le ciment qui relie tous les nœuds. Il transporte les données et les messages entre les machines pour partager les résultats et se mettre à jour les uns les autres. Des connexions réseau fiables et rapides sont essentielles pour une communication sans faille.
Équilibreurs de charge** : Lorsque plusieurs nœuds sont prêts à accepter des demandes entrantes, les [équilibreurs de charge] (https://zilliz.com/ai-faq/how-do-distributed-databases-perform-load-balancing) répartissent le trafic de manière uniforme. Cela permet d'éviter qu'un nœud ne traite trop de demandes à la fois. En répartissant la charge, le système peut gérer les pics de trafic et maintenir des performances stables.
Serveur de base de données** : Un serveur de base de données est responsable du stockage, de la gestion et de l'extraction de données structurées ou non structurées sur plusieurs nœuds. Dans une architecture distribuée, les bases de données peuvent être partagées (division des données en plus petits morceaux sur plusieurs nœuds) ou répliquées (conservation de copies des données sur plusieurs nœuds pour la tolérance aux pannes).
Files d'attente de messages et services de coordination** : Les systèmes distribués s'appuient souvent sur des outils de messagerie (comme Apache Kafka ou NATS) ou des services de coordination (comme ZooKeeper) pour gérer la communication entre les nœuds. Ces outils permettent de planifier les tâches, de suivre la progression et de s'assurer que deux nœuds n'effectuent pas le même travail simultanément. Ils gèrent également les annonces à l'échelle du système, par exemple lorsqu'un nœud est mis en ligne ou hors ligne, afin que le reste du système puisse s'adapter.
Types d'architectures informatiques distribuées
Le calcul distribué peut prendre de nombreuses formes, en fonction de la manière dont les nœuds interagissent et partagent les responsabilités. Vous trouverez ci-dessous quelques architectures courantes, ainsi que des exemples de leur fonctionnement dans différents scénarios, y compris la base de données Milvus. Le choix de la bonne architecture distribuée dépend de la taille de la charge de travail, des exigences de latence et des contraintes de coût.
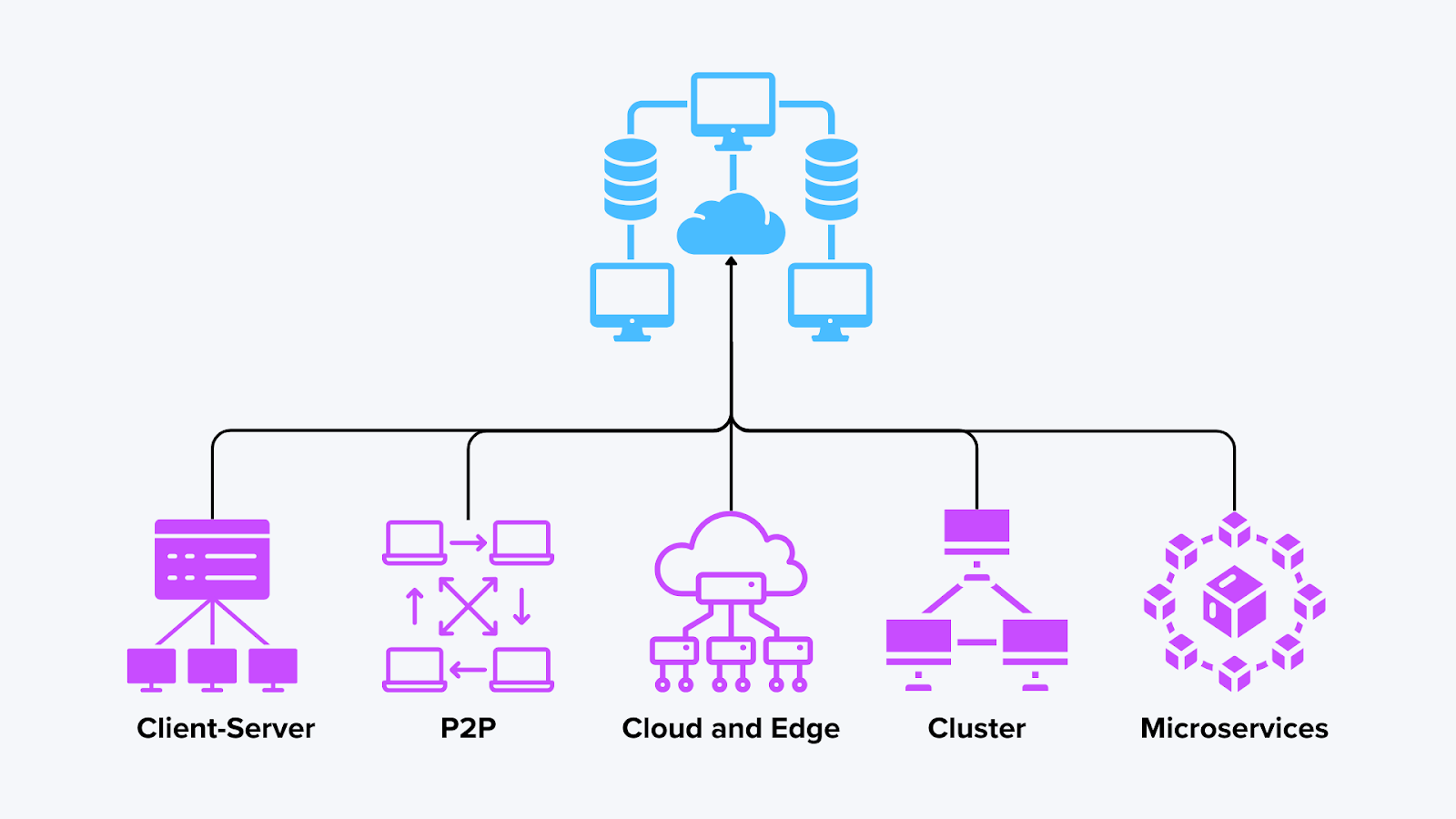 Types d'informatique distribuée
Types d'informatique distribuée
Figure: Types de calcul distribué
1. Modèle client-serveur
Dans le modèle client-serveur, un ou plusieurs serveurs centraux traitent les demandes émanant de plusieurs appareils clients. Chaque serveur est généralement plus puissant qu'un client individuel et héberge la logique commerciale principale ou le stockage des données. Les clients envoient des requêtes (telles que l'extraction de données ou l'exécution de calculs), et les serveurs répondent en fournissant les informations ou les résultats demandés.
Avantages : Séparation claire des rôles, contrôle centralisé et gestion simplifiée de la sécurité.
Inconvénients** : Les clients peuvent perdre l'accès au service si un serveur tombe en panne. La mise à l'échelle peut également s'avérer difficile si les demandes dépassent la capacité du serveur.
2. Réseaux pair-à-pair (P2P)
Les architectures pair-à-pair traitent tous les nœuds sur un pied d'égalité. Chaque nœud peut agir à la fois comme client et comme serveur, en partageant des ressources ou des fichiers sans dépendre d'un serveur central. Dans cette architecture, les nœuds se connectent directement les uns aux autres. Au lieu de demander des données à un serveur unique faisant autorité, les pairs échangent des données entre eux.
Avantages : Il n'y a pas de point de défaillance unique et il est plus facile d'augmenter le nombre de pairs.
Inconvénients** : La gestion de la cohérence des données et de la qualité de service peut s'avérer difficile dans les environnements entièrement décentralisés.
3. L'informatique en grappe
Un [cluster] (https://docs.zilliz.com/docs/cluster) est un groupe de serveurs qui travaillent ensemble si étroitement qu'ils apparaissent comme un système unique. Les tâches peuvent être réparties entre les nœuds pour un traitement parallèle, ce qui rend l'informatique en grappe populaire pour les charges de travail à haute performance. Les serveurs d'une grappe partagent souvent le stockage et les tâches sont réparties entre eux par un système de planification ou un équilibreur de charge. Si un serveur tombe en panne, les autres peuvent continuer à fonctionner.
Architecture Milvus: Milvus utilise des nœuds en grappe pour gérer de grands volumes de données vectorielles. La répartition des index vectoriels sur plusieurs machines permet de traiter efficacement des milliards de vecteurs à haute dimension. Cette approche de mise en grappe améliore les performances et la résilience, en particulier lorsqu'il s'agit de recherches massives ou de charges de travail de recommandation.
Avantages : Idéal pour le traitement parallèle et la tolérance aux pannes.
Inconvénients** : Il peut être complexe à gérer et nécessiter des investissements matériels plus importants.
4. Informatique en nuage et en périphérie
Le Cloud computing fournit des ressources à la demande (comme des machines virtuelles, du stockage et des services) sur Internet. L'[Edge computing] (https://zilliz.com/glossary/edge-computing) place le traitement et le stockage des données plus près de la source de données (par exemple, les appareils IoT) afin de réduire les temps de latence. Dans l'informatique en nuage, les organisations exécutent des applications sur des serveurs distants gérés par des fournisseurs d'informatique en nuage. La capacité est généralement extensible à court terme. Dans l'informatique périphérique, les données générées par les appareils sont traitées localement ou dans des centres de données périphériques proches, ce qui réduit la nécessité de tout envoyer à un nuage central.
Avantages** : Évolution élastique, flexibilité et coûts opérationnels potentiellement plus faibles. Les configurations en périphérie améliorent également la réactivité pour les tâches sensibles au temps.
Inconvénients** : Nécessite des connexions réseau stables (dans le cas de l'informatique en nuage), et les périphériques peuvent avoir des ressources limitées.
5. Microservices
Les [microservices] (https://zilliz.com/ai-faq/what-is-the-role-of-microservices-in-distributed-database-systems) divisent une application en services plus petits, faiblement couplés, qui communiquent sur un réseau. Chaque service gère une fonction spécifique, comme l'authentification des utilisateurs ou l'indexation des données. Les services peuvent être exécutés sur des machines distinctes ou dans des conteneurs. Ils exposent des API pour la communication et peuvent évoluer indépendamment pour s'adapter à leur charge de travail spécifique.
Avantages : Il simplifie les mises à jour, car chaque service peut être modifié sans affecter l'ensemble du système. Il permet également une mise à l'échelle spécialisée, où seuls les services les plus utilisés reçoivent des nœuds supplémentaires.
Les inconvénients** sont qu'elle rend plus complexe la gestion de nombreux services tout en garantissant un fonctionnement harmonieux. La surveillance, l'enregistrement et le déploiement des mises à jour nécessitent une planification minutieuse.
Cas d'utilisation de l'informatique distribuée
L'informatique distribuée offre un large éventail de solutions modernes. Voici quelques-uns des scénarios les plus courants dans lesquels les organisations tirent profit de la répartition des charges de travail et des données entre des nœuds interconnectés :
Analyse des Big Data et traitement en temps réel: Les organisations exécutent de grands ensembles de données en parallèle sur plusieurs nœuds afin d'accélérer l'analyse. Les données ne cessent d'affluer et les mises à jour sont quasi instantanées. Cet aspect est crucial dans les secteurs de la finance, de la santé et du commerce électronique, où les décisions sont guidées par des informations rapides.
Apprentissage machine et formation de modèles d'IA:** Les modèles complexes sont formés plus rapidement lorsque les calculs sont exécutés sur plusieurs machines simultanément. Cette configuration permet de traiter efficacement de grands ensembles de caractéristiques et de réduire le temps de formation global. Elle est courante dans les domaines de la reconnaissance d'images, du NLP et des recommandations personnalisées.
Applications Web à fort trafic et commerce électronique:** Les demandes sont réparties sur plusieurs serveurs, de sorte qu'aucune machine n'est submergée. Si un serveur tombe en panne, les autres continuent de fonctionner afin d'éviter les temps d'arrêt importants. Grâce à une mise à l'échelle flexible, les pics soudains, comme les ventes de vacances, sont plus faciles à gérer.
Internet des objets (IoT) et réseaux de capteurs:** De nombreux capteurs alimentent en données des nœuds distribués, qui les traitent à proximité de la source pour des réponses plus rapides. Cette approche localisée améliore la surveillance et facilite les alertes en temps réel. Elle est largement adoptée dans les villes intelligentes, la fabrication et les véhicules connectés.
Recherche scientifique et calcul à haute performance (HPC): Les tâches lourdes, comme les simulations climatiques, sont divisées en petits travaux qui s'exécutent en parallèle. Cela permet de réduire considérablement les temps de calcul et de soutenir les collaborations scientifiques mondiales. Les chercheurs peuvent affiner les modèles plus rapidement et faire avancer l'innovation.
Réseaux de diffusion de contenu (CDN):** Les fichiers et les médias sont stockés sur des serveurs dans le monde entier, ce qui permet aux utilisateurs d'accéder au contenu à partir du nœud le plus proche. Cette configuration réduit les temps de chargement et les retards du réseau, ce qui la rend vitale pour les services de diffusion en continu, les téléchargements de fichiers volumineux et les sites web à fort trafic.
Avantages des systèmes distribués
Les entreprises se tournent vers les systèmes distribués pour gérer des données et des tâches de calcul en constante augmentation. Voici quelques avantages clés qui aident les équipes à s'adapter, à rester résilientes et à travailler plus efficacement :
Les architectures distribuées permettent aux organisations d'ajouter des machines au fur et à mesure que les charges de travail augmentent, plutôt que de dépendre d'un seul gros serveur. Le système évite les goulets d'étranglement et améliore le débit en répartissant les données et les tâches sur plusieurs nœuds.
Tolérance aux pannes et redondance:** Lorsque les données et les tâches critiques sont répliquées sur plusieurs nœuds, le système peut continuer à fonctionner même si un nœud tombe en panne. Cette conception réduit les temps d'arrêt et préserve l'accès des utilisateurs.
Conception flexible et modulaire:** Les systèmes distribués divisent souvent les tâches en modules plus petits et indépendants. Chaque nœud prend en charge des tâches spécifiques, ce qui facilite la mise à jour ou le remplacement des composants sans perturber l'ensemble de l'environnement.
Équilibre entre cohérence et disponibilité (Théorème CAP): Il est difficile pour les systèmes distribués d'être à la fois totalement cohérents et toujours disponibles, en particulier lorsque des problèmes de réseau surviennent. Le compromis exact dépend de l'importance de la cohérence immédiate pour chaque cas d'utilisation.
Amélioration des performances et du débit:** En exécutant des tâches en parallèle, les systèmes distribués peuvent traiter plus d'opérations en moins de temps. C'est essentiel pour l'analyse des big data ou les recherches vectorielles en temps réel.
Défis et considérations
Si les systèmes distribués présentent de nombreux avantages, ils introduisent également des complexités uniques. Vous trouverez ci-dessous quelques obstacles et facteurs courants à prendre en compte lors de la création et de la maintenance d'infrastructures distribuées :
Latence du réseau et limites de la bande passante:** Les tâches qui s'étendent sur des serveurs distants peuvent ralentir si les connexions réseau sont faibles ou surchargées. Lorsque la bande passante est limitée, les transferts de données volumineux peuvent se heurter à des goulets d'étranglement. Le fait de placer les nœuds plus près des utilisateurs ou de mettre les données en cache peut contribuer à réduire la [latence] (https://zilliz.com/ai-faq/what-is-the-role-of-network-latency-in-distributed-databases).
Cohérence des données et tolérance aux partitions:** Il peut être difficile de tout synchroniser lorsque les données sont stockées sur plusieurs nœuds. Les défaillances du réseau ou les pannes de nœuds introduisent des conflits qui doivent être traités avec soin. Certains systèmes privilégient les mises à jour rapides, tandis que d'autres accordent la priorité à une précision rigoureuse.
Sécurité et confidentialité des données:** Les données circulent entre les machines, ce qui augmente le risque de fuites ou d'accès non autorisé. Le cryptage et des contrôles d'accès stricts permettent de protéger les informations sensibles. Des audits réguliers et des contrôles de conformité garantissent la protection des données des utilisateurs.
Gestion des transactions distribuées:** Une transaction unique peut impliquer plusieurs services ou nœuds, ce qui complique la coordination. Des protocoles tels que le commit en deux phases ou les [gestionnaires de transactions] (https://zilliz.com/ai-faq/what-is-the-role-of-a-distributed-transaction-manager) permettent de suivre ces étapes. Des stratégies de retour en arrière prudentes empêchent les défaillances partielles de corrompre les données.
Présentation de Milvus : une base de données vectorielle distribuée et native pour le cloud
Milvus est conçu dès le départ comme un système distribué cloud-native pour la gestion de données vectorielles à haute dimension. En répartissant les données et le traitement sur plusieurs nœuds, Milvus offre les principaux avantages de l'informatique distribuée (évolutivité, tolérance aux pannes et exécution parallèle), ce qui le rend bien adapté à l'apprentissage de modèles d'IA, aux systèmes de recommandation en temps réel et aux analyses complexes.
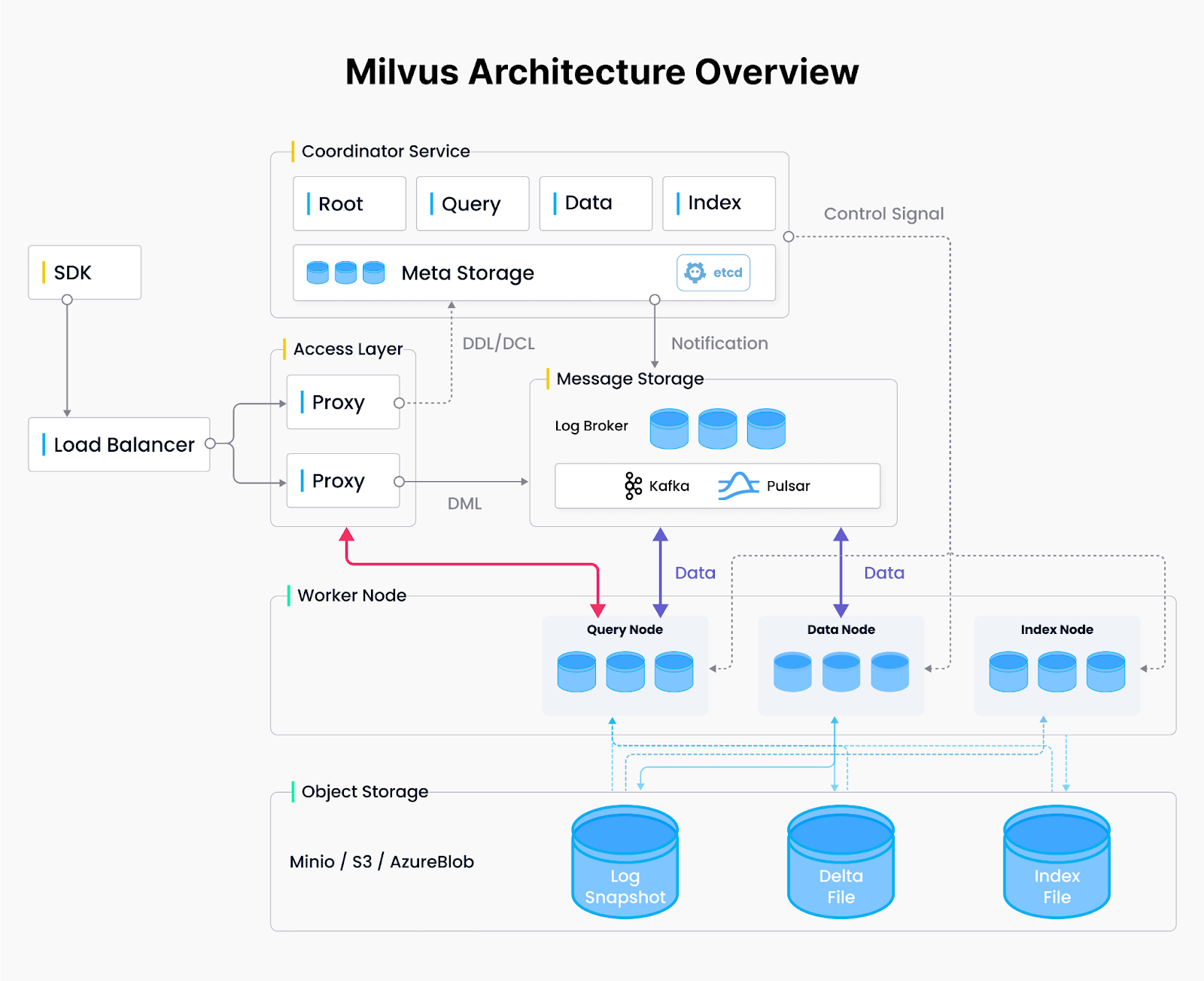 Milvus Architecture.png
Milvus Architecture.png
Figure: Architecture Milvus
Architecture distribuée Milvus : Conception à quatre couches
Milvus est une [base de données vectorielle] (https://zilliz.com/learn/what-is-vector-database) largement utilisée qui adopte une architecture de système distribuée comprenant quatre couches pour allouer dynamiquement les ressources là où elles sont le plus nécessaires, qu'il s'agisse d'une puissance de calcul accrue pour l'indexation à grande échelle ou d'une mémoire supplémentaire pour traiter des requêtes complexes en parallèle.
Couche d'accès:** Les nœuds d'accès sans état gèrent les demandes entrantes, agissant comme point d'entrée dans le système.
Couche de coordination : coordonne l'affectation des nœuds et la gestion des ressources, en augmentant ou en diminuant le nombre de travailleurs en fonction des besoins.
Couche travailleurs:** Effectue les tâches principales d'interrogation, d'ingestion de données et de construction d'index sur des nœuds évolutifs et sans état.
Couche de stockage:** Conserve les données vectorielles et les métadonnées du système pour assurer la tolérance aux pannes et la persistance des nœuds.
Évolutivité et cohérence dans l'architecture distribuée Milvus
Milvus applique les principes de l'informatique distribuée pour traiter des ensembles massifs de données vectorielles tout en maintenant la cohérence des données. Vous trouverez ci-dessous les principales caractéristiques de conception qui lui permettent de s'adapter horizontalement, de minimiser les goulets d'étranglement et d'offrir des niveaux de cohérence réglables :
Échelonnement horizontal: Milvus segmente les grands ensembles de données en morceaux gérables. Chaque segment est indexé indépendamment, de sorte qu'au fur et à mesure que vos données augmentent, vous pouvez ajouter des nœuds supplémentaires sans avoir à réviser l'infrastructure existante.
Nœuds indépendants pour les requêtes, les données et l'indexation:** Pour mettre à l'échelle des fonctions spécifiques, les requêtes, l'ingestion de données et l'indexation s'exécutent indépendamment sur des types de nœuds distincts. Cette séparation permet d'éviter les goulets d'étranglement et garantit que le système peut gérer des milliards de vecteurs.
Cohérence réglable et** Sharding: Les données sont réparties sur plusieurs nœuds pour les écritures simultanées, tandis que les niveaux de cohérence réglables de Milvus vous permettent d'équilibrer les performances et la précision en fonction des besoins de votre application.
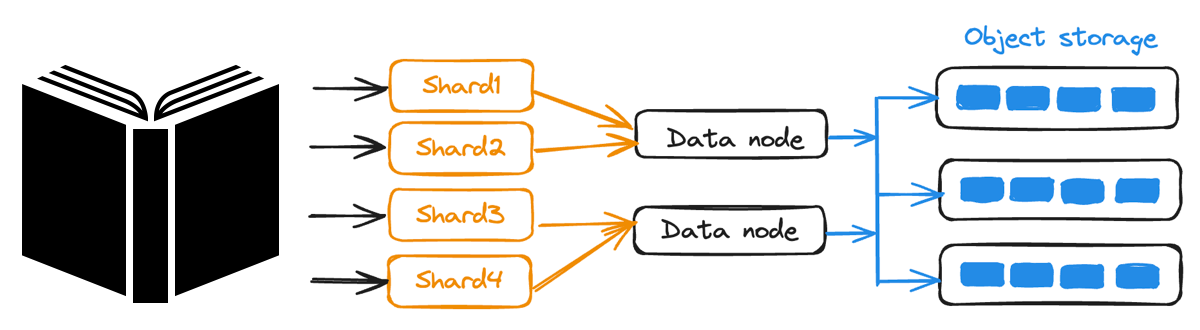 Le sharding de données dans Milvus
Le sharding de données dans Milvus
Figure: Partage des données dans Milvus
Plusieurs modes de déploiement pour différents besoins
Milvus propose plusieurs [options de déploiement] (https://milvus.io/docs/install-overview.md) pour s'adapter à différentes échelles de données et exigences de performance. Qu'il s'agisse de tester sur une seule machine ou d'exécuter un système de production à grande échelle, ces modes vous permettent d'adapter les ressources et la complexité aux besoins de votre projet. Vous trouverez ci-dessous une illustration du niveau de mise à l'échelle des données pour chaque base de données vectorielle. Vous pouvez constater que Milvus distribué est conçu pour gérer des échelles de données de plusieurs dizaines de millions et plus.
Modes de déploiement de Milvus](https://assets.zilliz.com/Milvus_Deployment_Modes_63d691a4d6.png)
Figure: Modes de déploiement de Milvus
Milvus Lite: Une bibliothèque Python légère qui fournit les fonctionnalités principales de Milvus sans nécessiter de processus de serveur séparé. Elle est idéale pour les expériences à petite échelle, le prototypage rapide ou les démonstrations rapides dans des environnements locaux. Milvus Lite vous permet de démarrer rapidement avec une configuration minimale si vous construisez une preuve de concept ou testez de nouvelles fonctionnalités dans un bloc-notes.
Milvus Distributed:** Une architecture entièrement multi-nœuds conçue pour répondre aux exigences des entreprises. En séparant les tâches entre les nœuds d'accès, les coordinateurs, les travailleurs et les couches de stockage, elle traite des milliards (voire des dizaines de milliards) de vecteurs avec une haute disponibilité et une tolérance aux pannes. Ce modèle est le choix idéal pour les entreprises qui s'attendent à une croissance rapide de leurs données, qui ont besoin de performances solides pour les requêtes simultanées et qui souhaitent avoir la possibilité d'ajouter ou de supprimer des nœuds en fonction de la charge de travail.
Milvus Standalone: Déploiement à nœud unique regroupant tous les composants Milvus dans un seul environnement, souvent distribué via une image Docker. Cela facilite l'installation et la maintenance tout en offrant une capacité suffisante pour des volumes de données modérés. Les équipes qui cherchent à exécuter des charges de travail de production ne nécessitant pas d'évolutivité massive ou de mécanismes de basculement complexes trouveront cette option à la fois rentable et fiable.
Pour en savoir plus sur le déploiement de Milvus, lisez notre guide : [Comment choisir le bon mode de déploiement Milvus pour vos applications d'IA] (https://zilliz.com/blog/choose-the-right-milvus-deployment-mode-ai-applications).
Conclusion
L'informatique distribuée a remodelé la manière dont les organisations traitent les données et dimensionnent leurs applications, en s'éloignant des serveurs monolithiques au profit de grappes flexibles et tolérantes aux pannes, composées de nœuds interconnectés. En répartissant les tâches et les données sur plusieurs machines, les équipes obtiennent un traitement plus rapide, une plus grande disponibilité et une utilisation plus efficace des ressources. Les solutions modernes, comme Zilliz, appliquent ces principes pour fournir une base de données vectorielle native qui peut traiter des milliards de vecteurs en parallèle. Alors que les volumes de données continuent d'augmenter et que les cas d'utilisation deviennent plus complexes, l'adoption d'une approche distribuée - que ce soit pour l'analyse, l'apprentissage automatique ou les recommandations en temps réel - reste une stratégie clé pour rester compétitif dans le monde actuel axé sur les données.
FAQ sur l'informatique distribuée
Pourquoi choisir un système distribué plutôt qu'un serveur unique et puissant ? Avec un système distribué, vous pouvez ajouter des machines au fur et à mesure que les charges de travail augmentent, au lieu de mettre à niveau un serveur unique. Cette flexibilité permet d'améliorer les performances, de réduire les coûts et de limiter l'impact d'un point de défaillance unique.
Les systèmes distribués utilisent des protocoles et des algorithmes (comme les mécanismes de consensus) pour assurer la synchronisation des données entre plusieurs nœuds. L'approche exacte varie d'un système à l'autre, mais l'objectif est de s'assurer que les mises à jour n'entrent pas en conflit et que chaque nœud dispose d'une vue correcte des données.
Alors que les systèmes distribués introduisent davantage de pièces mobiles, telles que la communication réseau, la coordination des nœuds et la réplication, des outils appropriés et des bonnes pratiques peuvent atténuer la complexité. Des outils tels que Kubernetes et les plateformes de surveillance simplifient l'orchestration et l'observabilité.
Milvus est une base de données vectorielles distribuée et native pour l'informatique en nuage, conçue pour les recherches de similarités à grande échelle. En divisant les données en segments et en exploitant l'indexation parallèle, Milvus peut traiter des milliards de vecteurs sur plusieurs nœuds sans sacrifier la vitesse ou la fiabilité.
Que se passe-t-il si mes données doivent être collectées ou si le trafic augmente soudainement ? Les systèmes distribués sont idéaux pour gérer les changements soudains de la demande. Vous pouvez rapidement mettre en service des nœuds ou des ressources supplémentaires, ce qui permet d'éviter toute surcharge sur une machine et de maintenir des performances constantes, même pendant les périodes d'utilisation maximale.
Ressources connexes
Modèles d'IA les plus performants pour vos applications GenAI | Zilliz](https://zilliz.com/ai-models)
Change Data Capture : Keeping Your Systems Synchronized in Real-Time
Optimisation de la communication des données : Milvus adopte la messagerie NATS
Introduction d'une surveillance et d'une observabilité complètes dans le nuage Zilliz
- Du serveur unique aux systèmes distribués : L'évolution
- Comment fonctionne l'informatique distribuée ?
- Types d'architectures informatiques distribuées
- Cas d'utilisation de l'informatique distribuée
- Avantages des systèmes distribués
- Défis et considérations
- Présentation de Milvus : une base de données vectorielle distribuée et native pour le cloud
- Conclusion
- FAQ sur l'informatique distribuée
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement