




Data Mining : Des données brutes aux informations précieuses

Data Mining : Des données brutes aux informations précieuses
Qu'est-ce que le Data Mining ?
L'exploration de données est une technique qui permet de découvrir des modèles, des tendances et des informations précieuses à partir de grandes quantités de données. Il aide les entreprises et les chercheurs à prendre de meilleures décisions en découvrant des liens cachés qui ne sont pas évidents à première vue. En utilisant des techniques telles que la classification, le regroupement et l'exploration de règles d'association, l'exploration de données transforme les données brutes en informations précieuses. Qu'il s'agisse de prédire le comportement des clients, de détecter les fraudes ou d'améliorer les résultats de recherche, l'exploration de données joue un rôle clé dans l'évolution de la technologie moderne.
Comment fonctionne le data mining ?
L'exploration de données analyse de vastes ensembles de données afin de trouver des modèles, des relations et des tendances cachés qui peuvent être utilisés pour la prise de décision. Il utilise des méthodes statistiques, des algorithmes d'apprentissage automatique et des techniques de gestion de base de données pour transformer des données brutes en informations exploitables. Le processus suit une série d'étapes pour nettoyer, organiser et extraire des informations utiles des données. Pour mieux comprendre, prenons l'exemple d'une plateforme de commerce électronique qui souhaite prédire quels clients sont susceptibles d'acheter en fonction de leur comportement de navigation.
Étapes du processus d'exploration des données
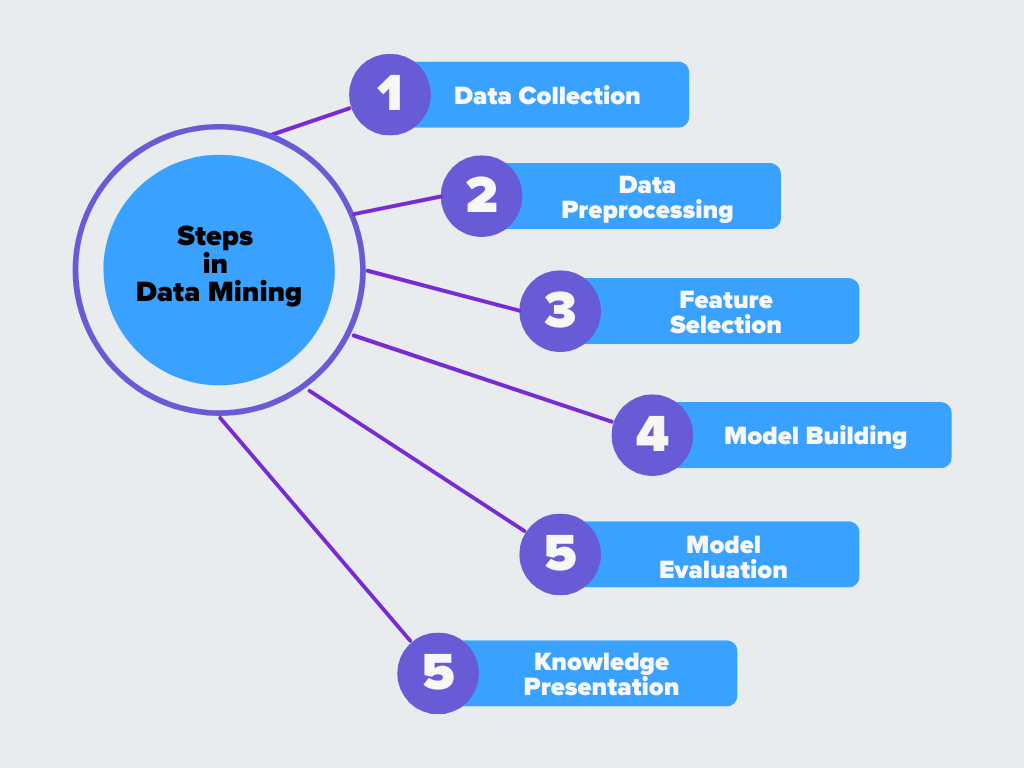 Figure- Étapes du Data Mining
Figure- Étapes du Data Mining
Figure: Les étapes du Data Mining
1. Collecte des données
La première étape consiste à collecter des données à partir de différentes sources, telles que des bases de données, des feuilles de calcul, des appareils IoT ou un stockage dans le nuage. Étant donné que les données se présentent souvent sous différents formats et structures, elles doivent être intégrées dans un système unique. Cette étape permet également de gérer les enregistrements en double et de fusionner les ensembles de données pour créer une vue unifiée. Par exemple, Une plateforme de commerce électronique recueille des données à partir des journaux du site web, des comptes d'utilisateurs et de l'historique des achats pour construire une vue complète du comportement des clients.
2. Prétraitement des données
Les données brutes sont rarement parfaites. Elles peuvent contenir des valeurs manquantes, des incohérences ou des erreurs qui peuvent avoir un impact sur la précision des résultats. Le prétraitement des données consiste à nettoyer les données en supprimant les doublons, en complétant les valeurs manquantes et en corrigeant les erreurs. Les techniques de prétraitement telles que la normalisation et la transformation permettent de structurer les données afin qu'elles soient prêtes pour l'analyse. **Par exemple, certains clients peuvent avoir des profils incomplets, un historique d'achat manquant ou des enregistrements en double qui doivent être nettoyés avant d'être analysés.
3. Sélection des caractéristiques
Tous les points de données ne sont pas utiles pour l'exploitation minière. Dans la [sélection des caractéristiques] (https://zilliz.com/ai-faq/what-is-feature-extraction), les données sont transformées dans un format plus approprié et les caractéristiques essentielles sont sélectionnées tandis que les caractéristiques non pertinentes sont supprimées. L'ingénierie des caractéristiques crée de nouvelles variables basées sur les données existantes, ce qui fait également partie de cette étape pour améliorer les performances du modèle. **Par exemple, des caractéristiques telles que le temps passé sur les pages produits, les achats passés et le taux d'abandon du panier peuvent être sélectionnées, tandis que des données moins utiles telles que les adresses IP peuvent être supprimées.
4. Construction du modèle
Une fois les données nettoyées et préparées, des algorithmes sont appliqués pour trouver des modèles et des relations. Des techniques telles que le regroupement, la classification et l'extraction de règles d'association permettent d'identifier des informations significatives. Les modèles d'apprentissage automatique peuvent être formés à ce stade pour reconnaître les tendances, classer les données ou faire des prédictions basées sur des modèles historiques. **Par exemple, la plateforme peut utiliser un modèle de classification pour prédire si un utilisateur est susceptible d'effectuer un achat en fonction de son comportement de navigation et de ses achats antérieurs.
5. Évaluation du modèle
Les modèles découverts lors de l'exploration ne sont pas tous utiles. Cette étape permet de valider les résultats afin de s'assurer qu'ils sont exacts et significatifs. Les analystes comparent les résultats avec des données connues, utilisent des [mesures de performance] (https://zilliz.com/learn/information-retrieval-metrics) telles que la précision et le rappel, et affinent les modèles si nécessaire. L'objectif est de confirmer que les modèles trouvés sont fiables et applicables à des scénarios réels. **La plateforme teste le modèle de prédiction en comparant ses résultats avec les achats réels afin de vérifier sa précision.
6. Présentation des connaissances
La dernière étape consiste à présenter les connaissances de manière claire et compréhensible. Il peut s'agir de rapports visuels, de tableaux de bord ou de résumés que les décideurs peuvent utiliser. Les connaissances extraites sont ensuite appliquées pour améliorer les processus, prendre des décisions commerciales ou améliorer les systèmes pilotés par l'IA.
**Par exemple, la plateforme de commerce électronique utilise ces connaissances pour créer des recommandations de produits personnalisées, des publicités ciblées et des offres promotionnelles afin d'augmenter les ventes.
Techniques et algorithmes d'exploration de données
Les techniques d'exploration de données sont divisées en catégories en fonction de la manière dont elles analysent les données et extraient des modèles significatifs. Ces techniques comprennent l'apprentissage supervisé, l'apprentissage non supervisé, l'apprentissage semi-supervisé et [la détection d'anomalies] (https://zilliz.com/ai-faq/how-does-machine-learning-improve-anomaly-detection). Chaque approche est adaptée à différents types de problèmes, allant de la classification et de la prédiction à la découverte de structures cachées dans les données.
Figure- Techniques d'exploration de données](https://assets.zilliz.com/Figure_Techniques_in_Data_Mining_1996f576bf.png)
Figure: Techniques d'exploration de données
1. Apprentissage supervisé
L'apprentissage supervisé forme un modèle sur des données étiquetées, où chaque entrée a une sortie connue correspondante. Le modèle apprend à partir de ces exemples à prédire les résultats pour de nouvelles données inédites. Cette approche est couramment utilisée dans les tâches de classification, de régression et de prévision de séries temporelles.
Figure - Techniques d'apprentissage automatique supervisé] (https://assets.zilliz.com/Figure_Supervised_machine_learning_techniques_ac73a06b9a.png)
Figure: Techniques d'apprentissage automatique supervisé
Arbres de décision:** Modèle basé sur des règles qui divise les données en sous-ensembles plus petits sur la base des valeurs des caractéristiques, formant une structure arborescente pour la prise de décision.
Forêts aléatoires:** Ensemble d'arbres de décision multiples qui améliore la précision et réduit l'ajustement excessif en calculant la moyenne des prédictions de plusieurs modèles.
Arbres à gradient boosté (GBT):** Une approche séquentielle des arbres de décision qui corrige les erreurs précédentes à chaque itération, ce qui permet d'obtenir de meilleures performances prédictives.
Machines à vecteurs de support (SVM):** Algorithme de classification qui trouve la frontière optimale (hyperplan) pour séparer les différentes catégories de données.
K-Voisins les plus proches (K-NN): Algorithme basé sur la distance qui classifie les nouveaux points de données en fonction de la classe majoritaire de leurs voisins les plus proches.
Réseaux neuronaux](https://zilliz.com/learn/Neural-Networks-and-Embeddings-for-Language-Models):** Modèles multicouches inspirés du cerveau humain qui apprennent des relations complexes entre les données d'entrée et de sortie.
Régression vectorielle de soutien (SVR):** Variante du SVM utilisée pour prédire des valeurs continues au lieu d'étiquettes catégoriques.
2. Apprentissage non supervisé
L'apprentissage non supervisé analyse les données sans sorties étiquetées, en identifiant les structures et les relations cachées au sein d'un ensemble de données. Il est couramment utilisé pour le regroupement, la détection des anomalies et la réduction de la dimensionnalité.
Figure - Techniques d'apprentissage automatique non supervisé](https://assets.zilliz.com/Figure_Unsupervised_Machine_Learning_Techniques_ecd834bff8.png)
Figure: Techniques d'apprentissage automatique non supervisé
K-Means Clustering](https://zilliz.com/blog/k-means-clustering): Algorithme de partitionnement qui divise les données en K grappes en assignant chaque point au centre de la grappe le plus proche.
Clustering hiérarchique:** Construit une hiérarchie de clusters par des méthodes ascendantes (agglomérantes) ou descendantes (divisives).
DBSCAN (Density-Based Spatial Clustering): regroupe les points de données densément peuplés tout en traitant les valeurs aberrantes comme du bruit, ce qui le rend utile pour les distributions de données irrégulières.
Analyse en composantes principales (ACP): Technique de réduction de la dimensionnalité qui transforme les données en un espace de dimension inférieure tout en préservant la variance.
Autoencodeurs](https://zilliz.com/ai-faq/what-is-an-autoencoder): Type de réseau neuronal qui apprend des représentations compressées de données pour la détection d'anomalies et l'extraction de caractéristiques.
Association Rule Mining: Identifie les relations entre les éléments d'un ensemble de données, couramment utilisé dans l'analyse du panier de la ménagère.
Algorithme d'Apriori:** Technique d'exploration des motifs fréquents qui permet de trouver des relations entre les éléments en identifiant de manière itérative les ensembles d'éléments fréquents.
Algorithme FP-Growth:** Une alternative plus efficace à Apriori qui utilise une structure arborescente (FP-tree) pour extraire les motifs fréquents en réduisant les calculs.
3. Apprentissage semi-supervisé
L'apprentissage semi-supervisé est une approche hybride qui combine une petite quantité de données étiquetées avec une grande quantité de données non étiquetées afin d'améliorer la précision de l'apprentissage. Cette technique est utile lorsque l'étiquetage des données est coûteux ou prend du temps.
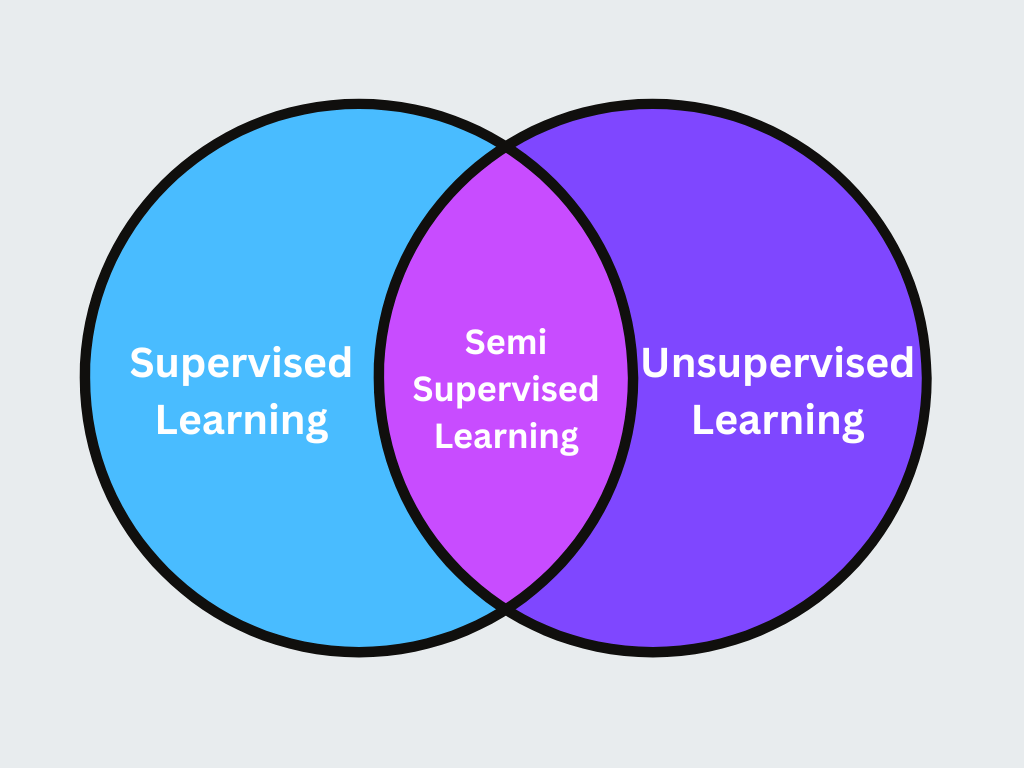 Figure- Apprentissage semi-supervisé.png
Figure- Apprentissage semi-supervisé.png
Figure: Apprentissage semi-supervisé
Un modèle est d'abord formé sur des données étiquetées, puis fait des prédictions sur des données non étiquetées, en ajoutant les prédictions les plus fiables à l'ensemble de données étiquetées pour une formation plus poussée.
Apprentissage semi-supervisé basé sur un graphe:** Il utilise des structures de graphe pour propager les étiquettes à travers un réseau de points de données liés, ce qui est couramment utilisé dans les [systèmes de recommandation] (https://zilliz.com/learn/Introduction-to-Recommendation-systems).
Les Réseaux Adversariaux Génératifs (GAN): Les GAN génèrent de nouveaux échantillons étiquetés afin d'améliorer l'apprentissage dans les scénarios avec peu d'étiquettes, ce qui les rend utiles dans la reconnaissance d'images et de la parole.
Régularisation de la cohérence:** Garantit que les prédictions d'un modèle restent cohérentes même lorsque de légères variations sont introduites dans l'entrée, améliorant ainsi la robustesse de l'apprentissage semi-supervisé.
4. Détection des anomalies et analyse des valeurs aberrantes
La détection des anomalies permet d'identifier les points de données qui s'écartent de manière significative des schémas normaux. Ces algorithmes sont couramment utilisés dans la [détection des fraudes] (https://zilliz.com/ai-faq/can-anomaly-detection-be-used-for-fraud-detection), la cybersécurité et la détection des défaillances industrielles.
Figure - Détection d'anomalie](https://assets.zilliz.com/Figure_Anomaly_detection_b7353e3dd5.png)
Figure: Détection d'anomalies
Méthode Z-Score:** Détecte les valeurs aberrantes en mesurant le nombre d'écarts types d'un point par rapport à la moyenne.
L'intervalle interquartile (IQR):** identifie les valeurs aberrantes en analysant l'intervalle entre le premier et le troisième quartile, ce qui permet de repérer les valeurs extrêmes.
Isolation Forest: Modèle arborescent qui permet d'isoler plus rapidement les anomalies en répartissant les points de données de manière aléatoire.
Facteur d'aberration locale (LOF):** Mesure la densité relative des points de données afin d'identifier les anomalies dans un ensemble de données.
SVM à classe unique:** Variante du SVM conçue pour détecter les écarts par rapport à la classe majoritaire, couramment utilisée pour la détection des fraudes.
Détection d'anomalies basée sur un autoencodeur:** Utilise l'apprentissage profond pour reconstruire les données d'entrée, signalant les anomalies lorsque l'erreur de reconstruction est élevée.
Applications de l'exploration de données dans tous les secteurs d'activité
L'exploration de données est utilisée dans divers secteurs pour analyser de vastes ensembles de données, découvrir des modèles et améliorer la prise de décision. Vous trouverez ci-dessous quelques cas d'utilisation spécifiques à l'industrie :
1. La finance
Détection de la fraude:** Les banques utilisent l'exploration de données pour analyser les modèles de transaction et détecter les activités suspectes, telles que des comportements de dépenses inhabituels ou plusieurs tentatives de connexion infructueuses.
Les institutions financières évaluent le niveau de risque d'un emprunteur en analysant son historique de crédit, ses revenus et ses remboursements antérieurs.
Trading algorithmique:** Les entreprises d'investissement utilisent l'analyse prédictive pour analyser les tendances du marché et automatiser les stratégies de trading à haute fréquence.
2. Santé
Les hôpitaux analysent les dossiers des patients et leurs symptômes afin de prédire les maladies à un stade précoce, ce qui permet d'améliorer les plans de traitement et de réduire le nombre d'hospitalisations.
Découverte et développement de médicaments:** Les sociétés pharmaceutiques utilisent l'exploration de données pour identifier des candidats médicaments potentiels en analysant les données génétiques et les données d'essais cliniques.
Prédiction des réadmissions de patients:** Les prestataires de soins de santé analysent les antécédents des patients pour prédire la probabilité d'une réadmission et prendre des mesures préventives.
3. Commerce électronique et vente au détail
Recommandations personnalisées:** Les détaillants en ligne analysent l'historique de navigation et d'achat des clients pour leur proposer des recommandations de produits sur mesure.
Stratégies de prix dynamiques:** Les plateformes de commerce électronique ajustent les prix en fonction de la demande, des prix des concurrents et du comportement des clients.
Les détaillants utilisent l'exploration de données pour identifier les clients qui risquent de partir et leur proposer des offres spéciales pour les fidéliser.
4. Cybersécurité
Systèmes de détection d'intrusion (IDS):** Les organisations utilisent l'exploration de données pour détecter des activités inhabituelles sur le réseau, telles que des tentatives d'accès non autorisé ou des infections par des logiciels malveillants.
Les équipes de sécurité analysent les données historiques des attaques afin de prédire et de prévenir les cyber-menaces futures.
Détection du phishing et de la fraude:** Les modèles d'apprentissage automatique identifient les tentatives de phishing en analysant les modèles d'e-mails, les URL et les comportements de l'expéditeur.
5. Fabrication et IoT industriel
Maintenance prédictive: Les usines analysent les données des capteurs des machines pour prévoir les pannes avant qu'elles ne se produisent, réduisant ainsi les temps d'arrêt et les coûts de réparation.
Optimisation de la chaîne d'approvisionnement:** Les fabricants utilisent l'exploration de données pour prévoir les fluctuations de la demande, optimiser les stocks et réduire les déchets.
Contrôle de la qualité et détection des défauts:** L'analyse des données permet d'identifier rapidement les défauts de production en détectant les anomalies dans les processus de fabrication.
6. Télécommunications
Optimisation du réseau:** Les entreprises de télécommunications analysent les schémas d'utilisation afin d'optimiser l'allocation de la bande passante et de réduire les encombrements.
Segmentation et fidélisation de la clientèle:** Les opérateurs classent les clients en fonction de leur comportement d'utilisation et proposent des plans personnalisés pour améliorer la fidélisation.
Détection des spams et des robocalls:** Les techniques d'exploration des données permettent de filtrer les spams et les messages en se basant sur les schémas d'appel et les rapports des utilisateurs.
7. Énergie et services publics
Les entreprises du secteur de l'énergie analysent les modèles de consommation passés afin de prévoir la demande future et d'optimiser les performances du réseau.
Détection des pannes dans les réseaux électriques:** Les capteurs surveillent les lignes électriques et détectent les anomalies afin d'éviter les pannes et d'améliorer la maintenance.
Analyse des compteurs intelligents:** Les fournisseurs de services publics utilisent l'exploration de données pour détecter des schémas inhabituels de consommation d'énergie et identifier les vols potentiels d'énergie.
8. L'éducation
Les écoles analysent les données relatives aux élèves afin d'identifier les élèves à risque et de leur fournir un soutien pédagogique personnalisé.
Systèmes d'apprentissage adaptatif:** Les plateformes éducatives utilisent l'exploration de données pour personnaliser le matériel d'apprentissage en fonction des forces et des faiblesses de l'élève.
Systèmes de recommandation de cours:** Les universités analysent les performances des étudiants pour leur recommander des cours adaptés en fonction de leurs centres d'intérêt et de leurs objectifs de carrière.
Avantages du Data Mining
Les entreprises et les chercheurs découvrent des modèles cachés:** Aide les entreprises et les chercheurs à découvrir des informations qui ne sont pas immédiatement évidentes dans les données brutes.
Améliore la prise de décision:** Fournit des informations fondées sur des données qui améliorent la planification stratégique et la précision des prévisions.
Analyse automatisée des tendances:** Cet outil identifie les tendances et les changements dans le comportement des consommateurs, les conditions du marché et les modèles financiers sans intervention manuelle.
Personnalisation accrue des clients:** Permet un marketing hautement ciblé en analysant les préférences des clients et leurs interactions passées.
Optimise les opérations commerciales:** Améliore l'efficacité de la chaîne d'approvisionnement, réduit les déchets et augmente la productivité en prédisant la demande et les besoins en ressources.
Amélioration des diagnostics médicaux:** Aide à la détection précoce des maladies et à l'élaboration de plans de traitement personnalisés grâce à l'analyse des données des patients.
Accélère la recherche scientifique:** Accélère la découverte de médicaments, l'analyse génétique et la modélisation climatique en analysant rapidement de vastes ensembles de données.
Comment Milvus contribue-t-il à l'exploration de données ?
L'exploration de données nécessite souvent l'analyse de vastes quantités de données structurées et non structurées (https://zilliz.com/learn/introduction-to-unstructured-data) afin de découvrir des modèles significatifs. Les bases de données relationnelles traditionnelles ont du mal à gérer les données non structurées et de haute dimension, ce qui les rend inefficaces pour les applications modernes telles que les systèmes de recommandation, la détection d'anomalies et la recherche sémantique. Milvus, une base de données vectorielle open-source développée par Zilliz ****engineers, est spécialement conçue pour traiter des données à grande échelle et à haute dimension, ce qui en fait un outil puissant pour les tâches d'exploration de données.
1. Traitement des données à haute dimension
Les applications modernes d'exploration de données s'appuient sur des données à haute dimension, telles que les [enchâssements] d'images (https://zilliz.com/glossary/vector-embeddings), les représentations textuelles et les [données de séries temporelles] (https://zilliz.com/learn/time-series-embedding-data-analysis), afin d'extraire des informations utiles. Les bases de données relationnelles traditionnelles sont inefficaces pour traiter ces types de données, car elles sont conçues pour des tableaux structurés plutôt que pour des représentations vectorielles multidimensionnelles.
Milvus fournit une base de données vectorielle dédiée pour stocker et gérer les enchâssements à haute dimension, ce qui en fait un composant d'infrastructure essentiel pour l'exploration de données pilotée par l'IA.
Il prend en charge différents formats de données, notamment les vecteurs denses et épars, afin de garantir la flexibilité des différents modèles d'apprentissage automatique et d'apprentissage profond.
Les structures optimisées d'indexation vectorielle (telles que IVF, HNSW et PQ) améliorent l'efficacité du stockage, en réduisant la redondance et en améliorant les performances des requêtes dans les grands ensembles de données.
Les capacités de traitement par lots et de parallélisation permettent d'insérer et d'extraire rapidement des millions de vecteurs pour les applications d'intelligence artificielle qui nécessitent des mises à jour continues.
**Par exemple, une société d'analyse vidéo stocke des encastrements image par image dans Milvus, ce qui permet une recherche et une récupération efficaces basées sur le contenu pour l'étiquetage et la classification automatisés des vidéos.
2. Évolutivité pour les applications d'exploration de Big Data
Le Big Data Mining nécessite des bases de données capables de s'adapter à des volumes croissants d'informations. Milvus fournit :
une [architecture native dans le nuage] (https://zilliz.com/cloud) pour les déploiements à grande échelle dans des environnements distribués.
Une utilisation efficace des ressources pour des performances d'interrogation rentables, même sur des ensembles de données massifs.
Il est facile à intégrer aux pipelines d'exploration de données basés sur l'IA car il est intégré aux cadres d'apprentissage automatique tels que TensorFlow, PyTorch et Hugging Face.
**Par exemple, en génomique, Milvus stocke et recherche des enchâssements de séquences d'ADN pour aider les chercheurs à trouver rapidement des similitudes génétiques dans des millions d'enregistrements.
3. Recherche sémantique et de similarité efficace
[Les recherches sémantiques (https://zilliz.com/glossary/semantic-search) et de similarité (https://zilliz.com/learn/vector-similarity-search) sont essentielles pour les applications modernes d'exploration de données qui impliquent des données non structurées, telles que des images, du texte et des supports multimédias. Contrairement aux recherches traditionnelles basées sur des mots-clés, la recherche par similarité s'appuie sur des vecteurs intégrés pour extraire les résultats les plus pertinents en se basant sur la signification plutôt que sur les correspondances exactes.
Milvus permet d'effectuer des recherches de similarité très performantes en s'appuyant sur l'intégration de vecteurs. Il permet aux utilisateurs de trouver des résultats basés sur le contexte plutôt que sur des mots exacts.
Il prend en charge les algorithmes de recherche [Approximate Nearest Neighbor (ANN)] (https://zilliz.com/blog/ANN-machine-learning), tels que HNSW, IVF et PQ, afin d'accélérer la recherche dans les ensembles de données à grande échelle.
Les capacités de recherche multimodale permettent d'effectuer des recherches interdomaines dans le texte, les images et les vidéos, ce qui en fait un outil idéal pour les systèmes de recommandation, la recherche de contenu et les applications NLP.
**Par exemple, un système de recherche de documents juridiques peut utiliser Milvus pour récupérer des jurisprudences basées sur la signification sémantique plutôt que sur de simples correspondances de mots-clés, améliorant ainsi la précision de la recherche juridique.
Conclusion
L'exploration de données est un processus transformateur qui transforme de vastes ensembles de données en informations exploitables, stimulant ainsi l'innovation dans les secteurs de la finance et des soins de santé. Les organisations peuvent découvrir des modèles cachés, optimiser les opérations et prendre des décisions basées sur les données en exploitant des techniques avancées telles que l'apprentissage supervisé et non supervisé, la détection d'anomalies et l'exploration de modèles fréquents. Milvus améliore ces capacités en fournissant une plateforme robuste pour le stockage et l'extraction de données à haute dimension, permettant des recherches sémantiques et de similarité efficaces. Sa capacité à s'adapter de manière transparente aux applications big data en fait un outil inestimable pour les besoins modernes en matière d'exploration de données.
FAQ sur le Data Mining
**1. Quelles sont les principales techniques utilisées en data mining ?
L'exploration de données fait appel à diverses techniques, notamment l'apprentissage supervisé (arbres de décision, SVM, réseaux neuronaux), l'apprentissage non supervisé (regroupement, extraction de règles d'association), la détection d'anomalies et l'extraction de motifs fréquents (Apriori, FP-Growth). Chaque technique permet d'extraire des informations utiles à partir de grands ensembles de données.
**2. En quoi le data mining diffère-t-il de l'analyse traditionnelle des données ?
L'analyse traditionnelle des données repose sur des requêtes prédéfinies et une interprétation humaine, tandis que le data mining utilise des algorithmes automatisés pour découvrir des modèles, des tendances et des relations cachés dans les données. L'exploration de données est également plus évolutive, ce qui la rend adaptée au traitement des données volumineuses et des applications d'intelligence artificielle.
**3. Quels sont les plus grands défis du data mining ?
Parmi les principaux défis du data mining figurent le traitement des données bruyantes et incomplètes, les problèmes de confidentialité et de sécurité des données, la gestion de la complexité informatique et l'adaptation à des ensembles de données massifs. Un prétraitement efficace et l'utilisation de modèles d'intelligence artificielle avancés permettent d'atténuer ces problèmes.
**4. Comment le data mining est-il utilisé dans les applications du monde réel ?
Le data mining est largement utilisé pour la détection des fraudes dans le secteur bancaire, les systèmes de recommandation dans le commerce électronique, la maintenance prédictive dans l'industrie manufacturière, le diagnostic des maladies dans le secteur de la santé et la détection des menaces en matière de cybersécurité. Il aide les organisations à optimiser la prise de décision et à automatiser les processus.
**5. Quel rôle jouent les bases de données vectorielles dans l'exploration de données ?
Les bases de données vectorielles, comme Milvus, permettent de stocker et d'extraire efficacement des données à haute dimension, ce qui accélère la recherche de similitudes, le regroupement et la détection d'anomalies. Ces bases de données sont utiles pour les applications basées sur l'intelligence artificielle, telles que la reconnaissance d'images, le traitement du langage naturel et les systèmes de recommandation.
Ressources connexes
Qu'est-ce qu'une base de données vectorielle et comment fonctionne-t-elle ?](https://zilliz.com/learn/what-is-vector-database)
Classification dans l'apprentissage automatique : tout ce que vous devez savoir] (https://zilliz.com/glossary/classification)
Qu'est-ce que la détection d'objets ? un guide complet] (https://zilliz.com/learn/what-is-object-detection)
Créer des applications d'IA avec Retrieval Augmented Generation (RAG)
[Réduction de la dimensionnalité : simplifier les données complexes pour faciliter l'analyse] (https://zilliz.com/glossary/dimensionality-reduction)
- Qu'est-ce que le Data Mining ?
- Comment fonctionne le data mining ?
- Techniques et algorithmes d'exploration de données
- Applications de l'exploration de données dans tous les secteurs d'activité
- Avantages du Data Mining
- Comment Milvus contribue-t-il à l'exploration de données ?
- Conclusion
- FAQ sur le Data Mining
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement