




Classification en apprentissage automatique : Tout ce qu'il faut savoir

Classification en apprentissage automatique : Tout ce qu'il faut savoir
Qu'est-ce que la classification ?
La classification est une approche d'apprentissage automatique supervisée qui permet de classer les données dans des catégories prédéfinies. Étant donné une entrée, un modèle de classification prédit la catégorie ou l'étiquette à laquelle l'entrée appartient. Il s'agit de l'une des tâches les plus courantes de l'apprentissage automatique et elle est utilisée dans de nombreuses applications du monde réel, de la détection des spams dans les courriers électroniques aux diagnostics médicaux.
Par exemple, si vous disposez d'un ensemble de données d'e-mails, un modèle de classification peut apprendre à étiqueter chaque e-mail comme "spam" ou "non spam".
Comment fonctionne la classification ?
Dans la classification, un modèle d'apprentissage automatique est formé sur un ensemble de données pour classer les données dans des classes prédéfinies sur la base de caractéristiques d'entrée. Le modèle est formé à l'aide d'un ensemble de données étiquetées, où chaque entrée est associée à une étiquette de sortie. Le modèle apprend les schémas des données au cours de la formation et utilise ces schémas pour prédire les étiquettes de nouvelles données inédites.
Par exemple, imaginez que vous soyez chargé de déterminer si un courriel est du spam. Au cours de la phase de formation, le modèle est alimenté en courriels avec leurs étiquettes ("spam" ou "non spam"). Il analyse des caractéristiques telles que la présence de certains mots clés ou l'adresse de l'expéditeur afin d'identifier des modèles. Une fois le modèle formé, il analyse les mêmes caractéristiques et prédit l'appartenance à la catégorie "spam" ou "non spam" à l'arrivée d'un nouvel e-mail.
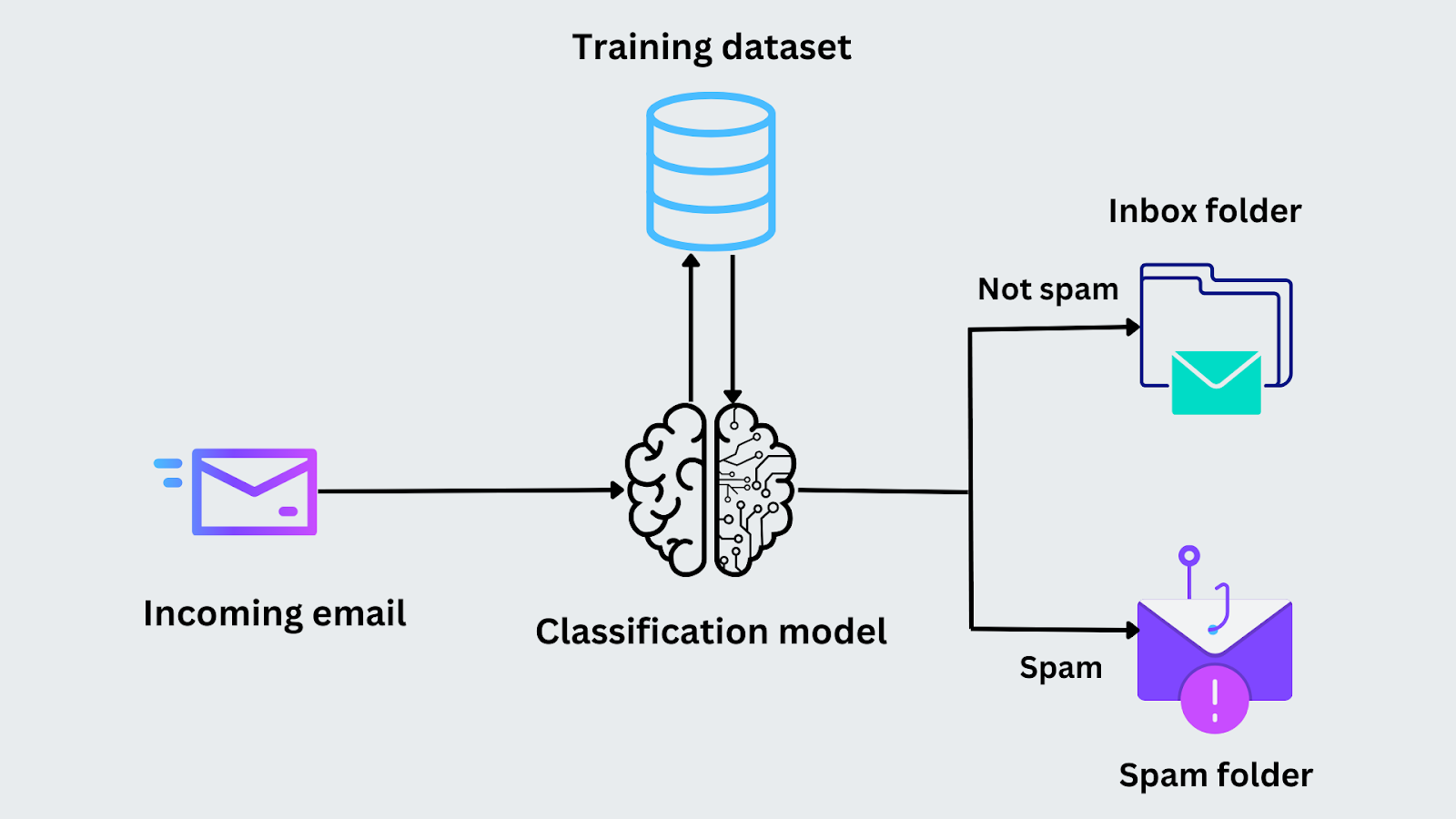 Figure- Processus de classification des courriels.png
Figure- Processus de classification des courriels.png
Figure: Processus de classification des courriels
Types de classification
Les problèmes de classification se présentent sous différentes formes en fonction de la nature des données et du nombre de classes. Voici les types les plus courants :
Classification binaire
On parle de classification binaire lorsqu'il n'y a que deux classes ou résultats possibles. Le modèle prédit à laquelle des deux catégories l'entrée appartient. Un exemple classique est la détection des spams. Le modèle doit décider si un courriel entrant est un "spam" ou un "non spam". Comme il n'y a que deux options, il s'agit d'une tâche de classification binaire.
Classification multi-classe
Dans la classification multi-classe, le modèle prédit une étiquette parmi plus de deux catégories possibles. Chaque entrée est affectée à une seule classe. Un bon exemple est la [reconnaissance d'images] (https://zilliz.com/learn/what-is-computer-vision#How-Computer-Vision-Works), où le modèle peut classer une image comme "chat", "chien" ou "oiseau". Contrairement à la classification binaire, le modèle traite plusieurs classes distinctes et doit identifier la bonne pour chaque entrée.
Classification multi-label
La classification multi-étiquettes est une classification dans laquelle chaque entrée peut appartenir à plusieurs classes simultanément. Par exemple, lors de l'étiquetage d'une photo, celle-ci peut être étiquetée simultanément "coucher de soleil", "plage" et "personnes". Chaque étiquette représente une classe différente et le modèle apprend à prédire toutes les étiquettes pertinentes pour une entrée. Cette méthode diffère de la classification multiclasse, car plusieurs étiquettes peuvent être attribuées à la même entrée.
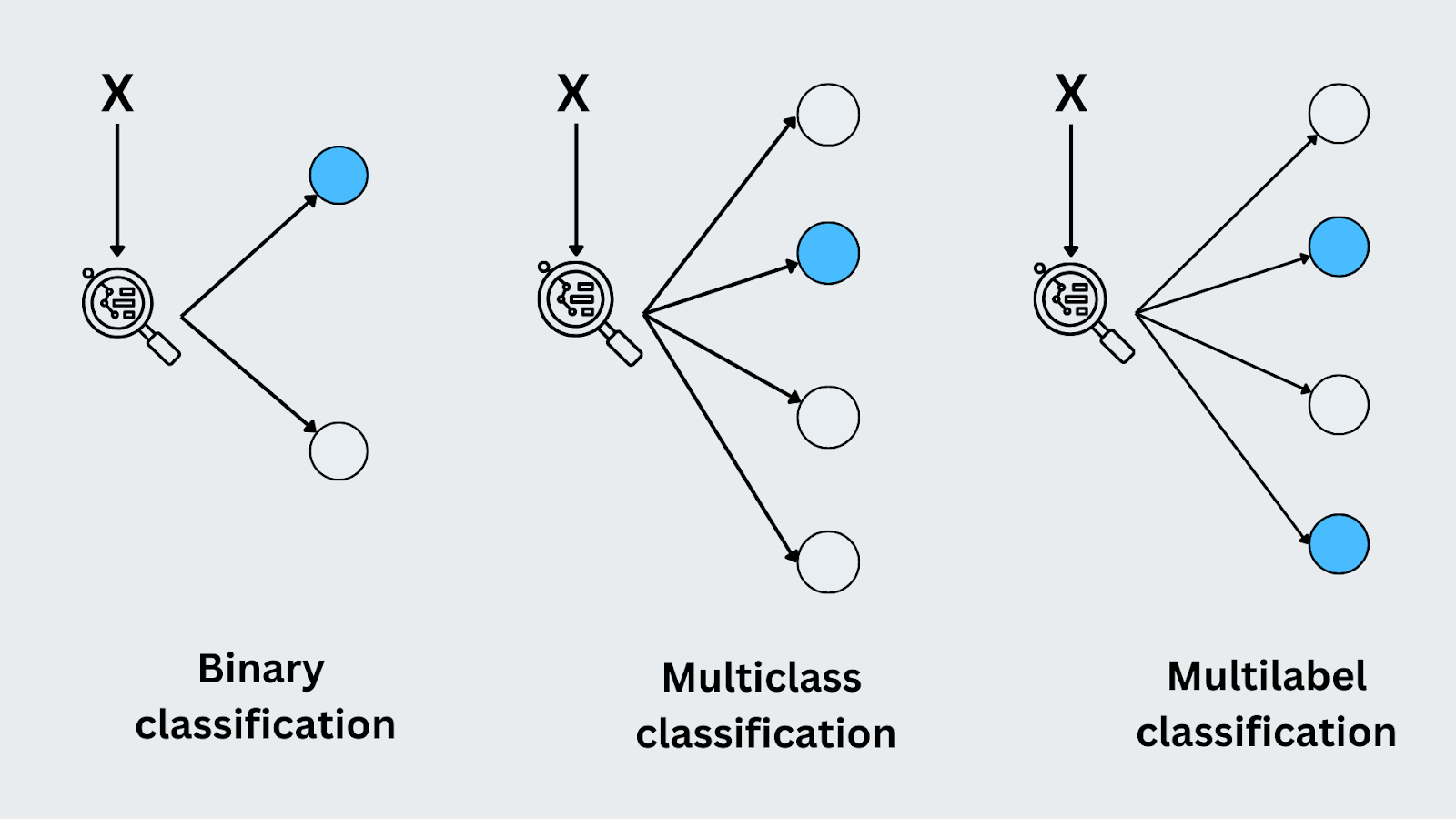 Figure- Types de classification.png
Figure- Types de classification.png
Figure: Types de classification
Les apprenants dans les algorithmes de classification
Dans l'apprentissage automatique, les algorithmes de classification peuvent être classés en fonction de la manière dont ils généralisent à partir des données d'apprentissage. Il s'agit des apprenants paresseux et des apprenants enthousiastes. La distinction entre ces deux types d'algorithmes réside dans le moment et la manière dont ils traitent les données pour faire des prédictions.
Apprenants paresseux
Les apprenants paresseux sont des algorithmes qui retardent la généralisation jusqu'à ce qu'ils reçoivent une demande de prédiction. Ils ne construisent pas de modèle pendant la phase d'apprentissage ; ils stockent les données d'apprentissage et n'effectuent des calculs que lorsqu'une nouvelle entrée doit être classée.
Exemples d'algorithmes : [k-Nearest Neighbors (k-NN)] (https://zilliz.com/blog/k-nearest-neighbor-algorithm-for-machine-learning), Case-based Reasoning (CBR).
Apprenants enthousiastes
Les apprenants enthousiastes, en revanche, tentent de construire un modèle général immédiatement pendant la phase de formation. Ils analysent les données de formation, apprennent les modèles sous-jacents, puis rejettent les données de formation. Une fois le modèle construit, il peut rapidement prédire de nouvelles données.
Exemples d'algorithmes : Arbres de décision, forêt aléatoire, machines à vecteurs de support (SVM), régression logistique.
| Les algorithmes d'apprentissage sont les suivants : Aspect | Apprenants paresseux | Apprenants enthousiastes | Création de modèles |
| Création d'un modèle - Aucun modèle n'est construit pendant la formation ; le modèle mémorise les données. | Le modèle est généralisé pendant la formation. | ||
| Durée de la formation - Courte durée de la formation ; ne construit pas de modèle. | La durée de la formation est plus longue ; un modèle est construit sur la base des données. | ||
| Temps de prédiction - Il fait des prédictions plus lentes car il traite les données au moment de l'interrogation. | Il fait des prédictions plus rapides, car le modèle est préconstruit. | ||
| Exigences en matière de mémoire | Exigences en matière de mémoire plus élevées ; stockage de l'ensemble des données. | La mémoire requise est plus faible ; seuls les paramètres du modèle sont stockés. | |
| Exemple d'algorithmes : k-NN, raisonnement à partir de cas, arbres de décision, régression logistique, forêt aléatoire, etc. |
**Tableau : **Apprenants paresseux vs apprenants enthousiastes
Algorithmes de classification
Examinons maintenant quelques algorithmes de classification couramment utilisés.
Régression logistique
La régression logistique utilise uniquement les probabilités pour prédire l'étiquette dans une tâche de classification binaire. Contrairement à la régression linéaire, qui prédit des valeurs continues, la régression logistique prédit des probabilités pour deux classes en faisant correspondre les sorties à une plage comprise entre 0 et 1 à l'aide de la fonction logistique (sigmoïde). Elle est largement utilisée dans les cas où les résultats sont binaires, comme les scénarios oui/non ou 0/1.
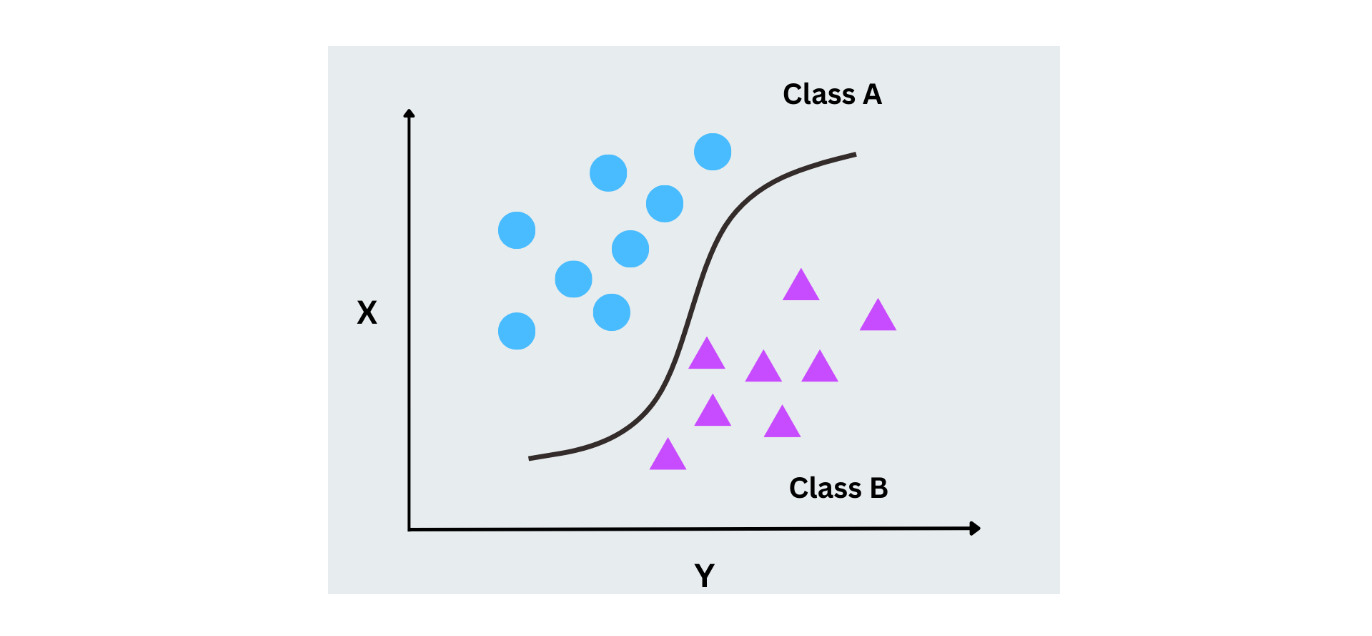 Figure- Logistic regression working.png
Figure- Logistic regression working.png
Figure- Régression logistique en fonctionnement
Arbres de décision
Un arbre de décision est un modèle qui divise les données en fonction des valeurs des caractéristiques, en créant des branches pour chaque décision possible. Chaque nœud représente une caractéristique et les branches représentent les décisions basées sur la valeur de cette caractéristique. Le processus se poursuit jusqu'à ce que l'algorithme décide des nœuds feuilles de la classe prédite. Les arbres de décision sont faciles à interpréter et peuvent gérer des tâches de classification binaire et multiclasse.
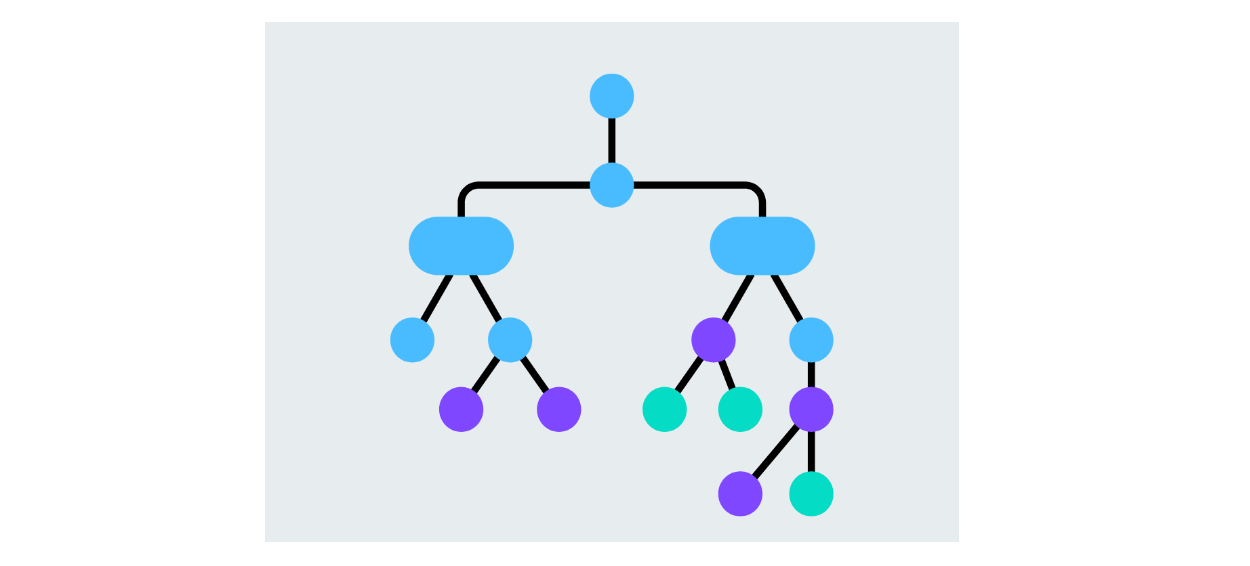 Figure- Decision tree structure.png
Figure- Decision tree structure.png
Figure: Structure de l'arbre de décision
Forêt aléatoire
La forêt aléatoire améliore les arbres de décision en construisant plusieurs arbres et en combinant leurs prédictions. Chaque arbre de la forêt est construit à partir d'un sous-ensemble aléatoire de données et de caractéristiques. La prédiction finale est faite en faisant la moyenne des résultats (pour les tâches de régression) ou par vote majoritaire (pour les tâches de classification). Cela permet de réduire l'ajustement excessif et d'augmenter la précision.
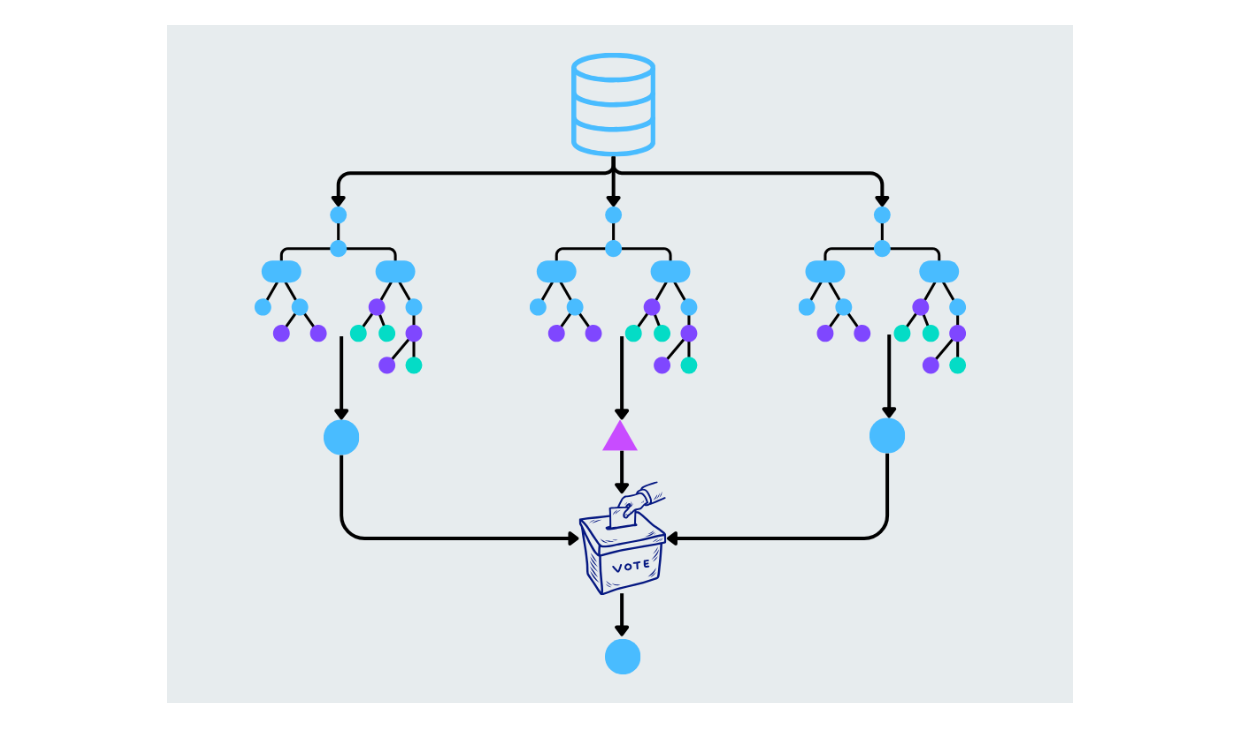 Figure- Random forest working.png
Figure- Random forest working.png
Figure: Forêt aléatoire en fonctionnement
Machines à vecteurs de support (SVM)
Les machines à vecteurs de support fonctionnent en trouvant l'hyperplan optimal qui sépare les points de données des différentes classes. Cet hyperplan est une ligne en deux dimensions, mais les SVM peuvent également traiter des données à haute dimension. L'idée principale est de maximiser la marge entre les points de données les plus proches de chaque classe (vecteurs de support). Les SVM fonctionnent bien pour les problèmes de classification binaire et multiclasse, en particulier lorsque les données ne sont pas linéairement séparables.
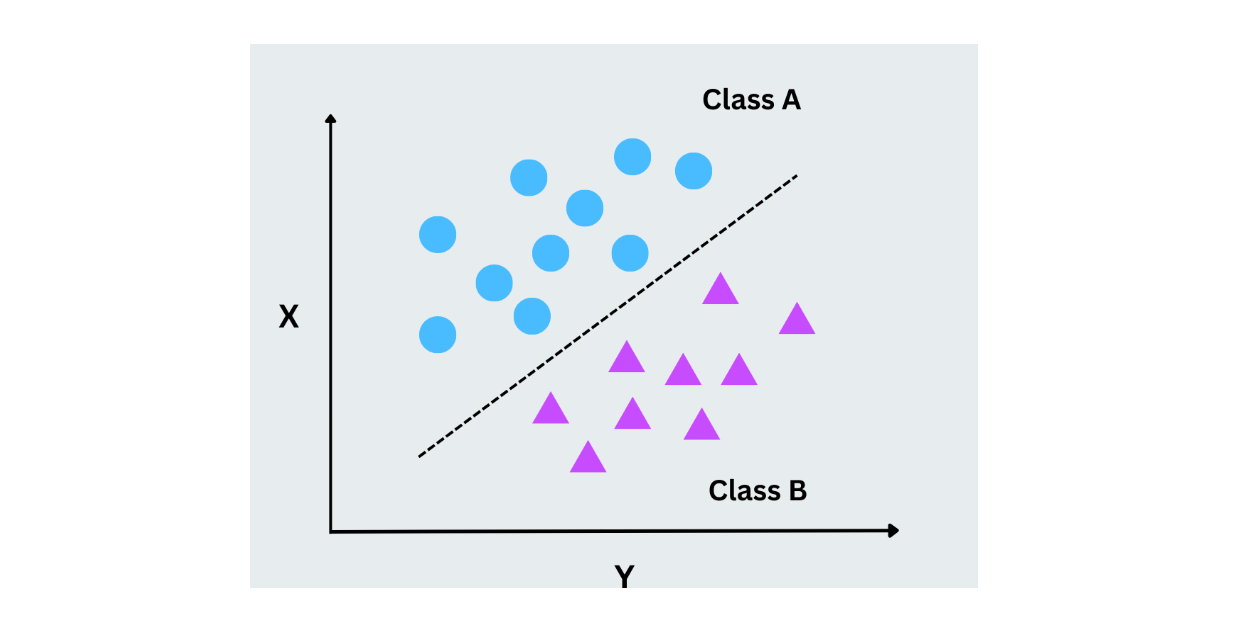 Figure- SVM working.png
Figure- SVM working.png
Figure- SVM en fonctionnement
Voisins les plus proches (k-NN)
L'algorithme [k-NN] (https://zilliz.com/blog/k-nearest-neighbor-algorithm-for-machine-learning) classe les points de données en fonction des classes des k plus proches voisins. Lors de l'introduction d'un nouveau point de données, l'algorithme examine les k points les plus proches (sur la base d'une métrique de similarité telle que la distance euclidienne) et attribue au nouveau point la classe majoritaire. Il s'agit d'un algorithme d'apprentissage simple, basé sur des instances, utile pour les petits ensembles de données.
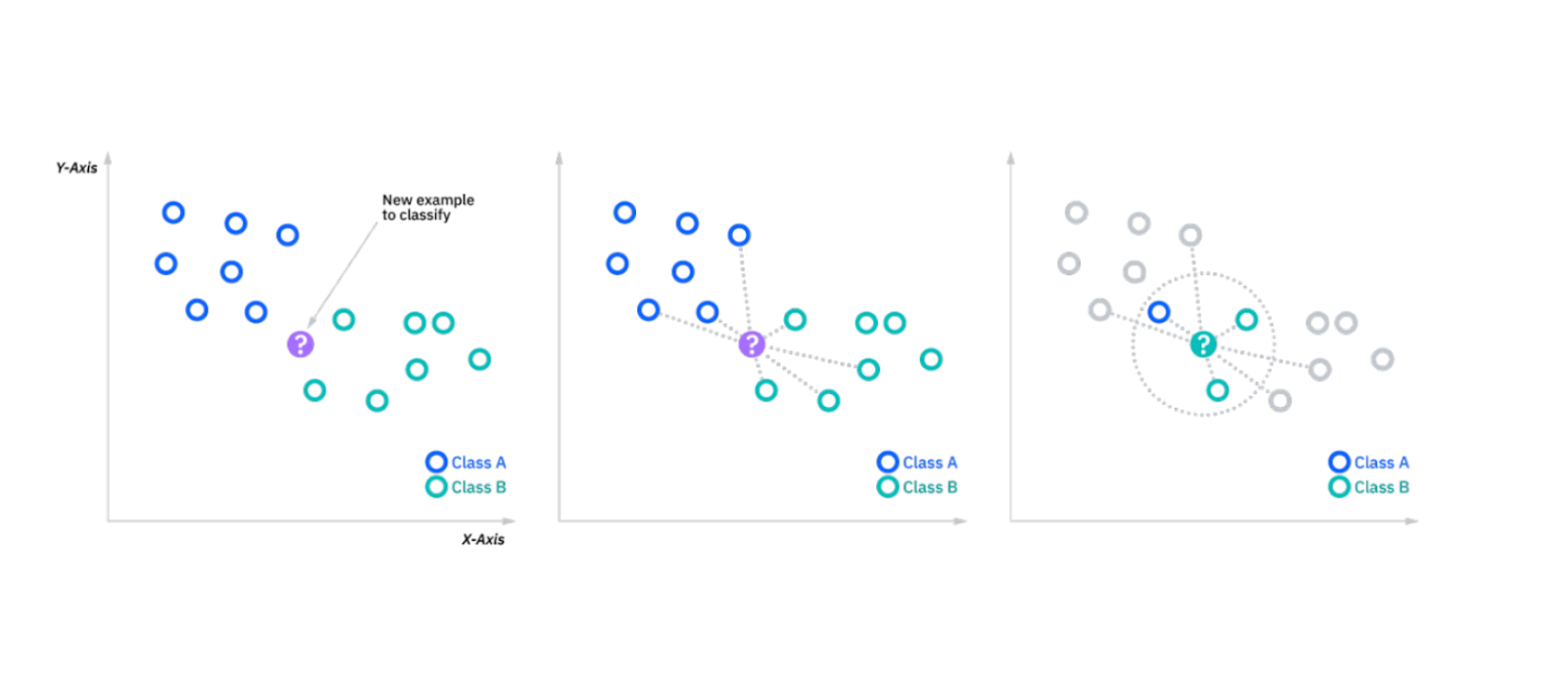 Figure- kNN algorithm working.png
Figure- kNN algorithm working.png
Figure: Algorithme kNN en fonctionnement
Naive Bayes
L'algorithme Naive Bayes est basé sur le théorème de Bayes et suppose que les caractéristiques des données sont indépendantes les unes des autres (d'où le terme "naïf"). Malgré cette hypothèse, il donne de bons résultats dans diverses tâches du monde réel, en particulier lorsque les données présentent des caractéristiques catégorielles. Il fonctionne en calculant la probabilité de chaque classe compte tenu des données d'entrée et en attribuant la classe ayant la probabilité la plus élevée.
P(C|X) = P(X|C) . P(C)P(X))
Ici, P(C∣X) est la probabilité postérieure de la classe compte tenu de l'entrée, P(X∣C) est la vraisemblance de l'entrée compte tenu de la classe, P(C) est la probabilité antérieure de la classe et P(X) est la probabilité de l'entrée. Naive Bayes sélectionne la classe dont la probabilité a posteriori est la plus élevée pour la classification sur la base des caractéristiques observées.
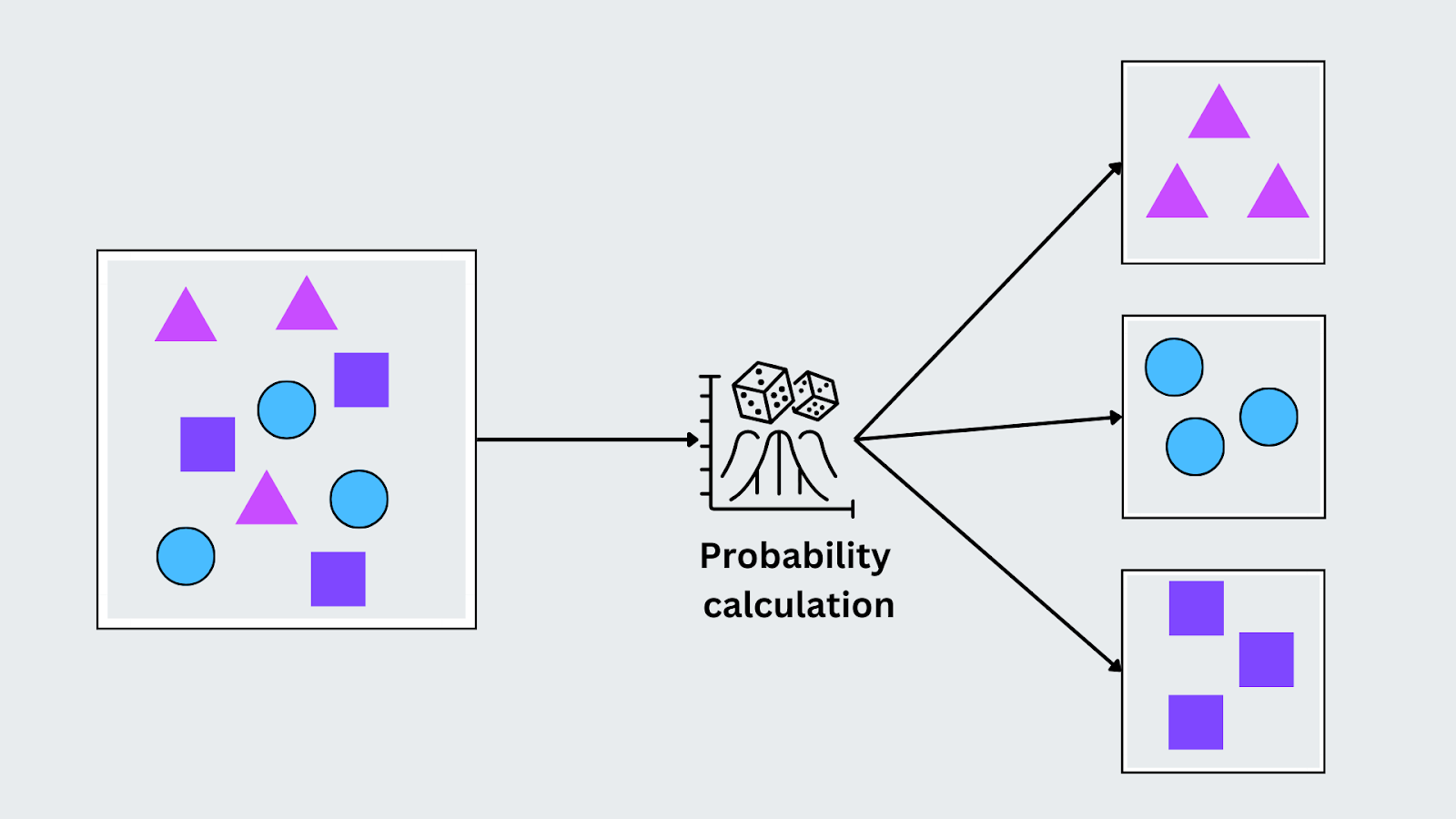 Figure- Fonctionnement de l'algorithme de Naive Bayes.png
Figure- Fonctionnement de l'algorithme de Naive Bayes.png
Figure: Algorithme de Naive Bayes en fonctionnement
Mesures d'évaluation de la classification
Précision
La précision est l'indicateur le plus simple et mesure la fréquence à laquelle les prédictions du modèle sont correctes. Elle est déterminée en divisant le nombre de cas correctement prédits par le nombre total de cas.
Formule :
Précision = (Vrais positifs + Vrais négatifs)/Nombre total d'instances
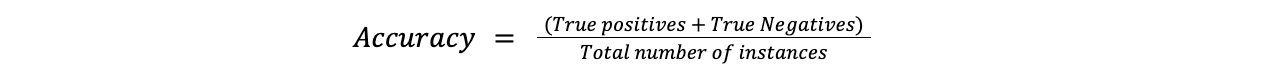 accuracy.png
accuracy.png
Précision
La précision mesure le nombre d'instances positives prédites qui sont réellement positives. La précision est importante dans les situations où les faux positifs sont coûteux. Par exemple, le fait de prédire qu'une transaction normale est frauduleuse dans le cadre de la détection des fraudes peut entraîner l'insatisfaction du client.
Formule :
Précision = Vrais positifs/(Vrais positifs + Faux positifs)
 precision.png
precision.png
Rappel
Le rappel mesure la proportion de cas positifs identifiés avec précision comme étant positifs. Le rappel est utile dans les cas où l'absence d'une instance positive est coûteuse. Par exemple, l'absence de diagnostic (faux négatif) est beaucoup plus problématique dans la détection des maladies qu'une fausse alarme.
Formule:
Rappel = Vrais positifs/(Vrais positifs + Faux négatifs)
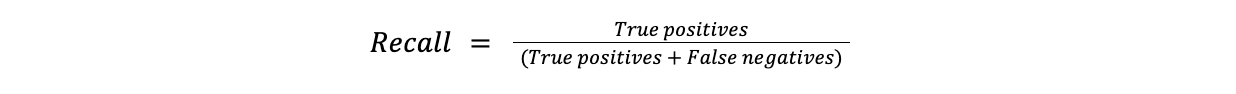 recall.png
recall.png
F1-Score
Le score F1 est la moyenne harmonique de la précision et du rappel. Il est utile lorsqu'il est nécessaire d'équilibrer la précision et le rappel, en particulier lorsque l'un est plus important que l'autre.
Formule :
F1Score = 2x(Précision x Rappel)/(Précision + Rappel)
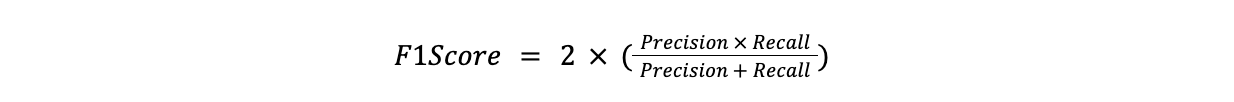 FI score.png
FI score.png
Cas d'utilisation de la classification dans le monde réel
Les modèles de classification sont largement utilisés dans divers secteurs d'activité pour résoudre des problèmes concrets. Voici quelques exemples pratiques :
Diagnostic médical: Les modèles d'apprentissage automatique aident les médecins à classer les données des patients comme "maladie" ou "pas de maladie". Par exemple, les modèles sont utilisés pour prédire si un patient souffre de diabète en se basant sur les dossiers médicaux.
Analyse des sentiments: Les entreprises utilisent l'analyse des sentiments pour comprendre les réactions des clients. Par exemple, un modèle peut analyser les commentaires sur les produits et les classer comme positifs, négatifs ou neutres, aidant ainsi les entreprises à améliorer leurs offres en fonction de l'opinion des clients.
Détection des fraudes: Les banques et les institutions financières utilisent des modèles de classification pour détecter les transactions frauduleuses. Le modèle apprend des modèles à partir des données des transactions et les classe comme "frauduleuses" ou "légitimes" afin d'éviter les pertes financières.
Reconnaissance d'objets dans les images: Les modèles de reconnaissance d'objets identifient des éléments d'image spécifiques dans des secteurs tels que la fabrication et la sécurité. Par exemple, un modèle peut classer des images de produits sur une chaîne de montage, garantissant que seuls les articles correctement assemblés passent l'inspection.
Reconnaissance faciale: Les systèmes de reconnaissance faciale sont utilisés dans les domaines de la sécurité et de l'authentification. Ces modèles classent les images de visages pour identifier ou vérifier l'identité d'une personne, ce qui est couramment utilisé pour déverrouiller les smartphones, les systèmes de présence numérique ou les contrôles de sécurité dans les aéroports.
Reconnaissance vocale: Les modèles de reconnaissance vocale convertissent le langage parlé en texte ou en commandes. Par exemple, les assistants virtuels tels que Siri ou Alexa classent les mots prononcés en commandes afin que les utilisateurs puissent interagir avec les appareils par la voix.
Tests de diagnostic médical: Les modèles d'apprentissage automatique aident à interpréter les tests de diagnostic tels que les radiographies ou les IRM. Ils classent les images médicales comme "normales" ou "anormales", aidant les radiologues à établir des diagnostics plus rapides et plus précis.
**Les plateformes de commerce électronique utilisent des modèles de classification pour prédire le comportement des clients. Ces modèles classent les utilisateurs selon qu'ils sont "susceptibles d'acheter" ou "peu susceptibles d'acheter" afin de faire des recommandations personnalisées en matière de marketing et de produits.
Catégorisation des produits: Les détaillants utilisent l'apprentissage automatique pour classer automatiquement des produits tels que "électronique", "vêtements" ou "articles ménagers" en fonction de leur description. Cela permet de rationaliser la gestion des stocks et d'améliorer les expériences de recherche des clients.
Classification des logiciels malveillants: Dans le domaine de la cybersécurité, les modèles de classification détectent et classent les logiciels malveillants. En analysant les schémas de comportement des logiciels, ces modèles classent les programmes comme "sûrs" ou "malveillants" afin de protéger les systèmes contre les cybermenaces.
Défis courants en matière de classification
Lors de l'élaboration de modèles de classification, plusieurs problèmes peuvent se poser et affecter les performances du modèle. Voici trois défis courants :
Surajustement
[Overfitting] (https://zilliz.com/learn/understanding-regularization-in-nueral-networks) signifie qu'un modèle fonctionne bien sur les données d'apprentissage mais ne parvient pas à se généraliser à de nouvelles données inédites. Cela se produit lorsque le modèle devient trop complexe et commence à capturer le bruit ou des détails spécifiques de l'ensemble d'apprentissage plutôt que les modèles sous-jacents.
Déséquilibre des données
Il y a déséquilibre des données lorsqu'une classe l'emporte largement sur les autres. Par exemple, dans la détection des fraudes, les transactions frauduleuses peuvent ne représenter que 1 % des données, ce qui conduit le modèle à privilégier fortement la classe majoritaire. Cela peut entraîner une mauvaise détection de la classe minoritaire.
Bruit dans les données
Le bruit fait référence à des erreurs aléatoires ou à des informations non pertinentes dans les données qui peuvent perturber le modèle. Les données bruitées peuvent inclure des exemples mal étiquetés, des valeurs aberrantes ou des caractéristiques non pertinentes qui ne contribuent pas à la tâche de classification. La présence de bruit peut réduire les performances du modèle et rendre plus difficile la détection de modèles.
Classification vs. régression
La classification et la régression sont deux types d'algorithmes d'apprentissage supervisé, mais ils sont utilisés pour différents types de tâches. Vous trouverez ci-dessous une comparaison entre la classification et la régression sur la base de différents aspects :
| Aspect | Classification | Régression |
| La classification et la régression ont pour but de prédire des étiquettes ou des catégories discrètes. | Prédire des valeurs numériques continues. | |
| Les résultats de la régression sont des valeurs numériques continues. | Continu : valeurs telles que "prix" ou "température". | |
| Exemple de tâche | Classification des courriers électroniques en "spam" ou "non spam". | Prédire les prix des maisons en fonction de leurs caractéristiques. |
| Algorithmes utilisés | Régression logistique, arbres de décision, forêt aléatoire, etc. | Régression linéaire, régression Ridge, régression polynomiale, etc. |
| Les mesures d'évaluation sont les suivantes : précision, exactitude, rappel, score F1, ROC-AUC, etc. | Erreur quadratique moyenne (MSE), R-carré, erreur absolue moyenne (MAE). | |
| La cible est catégorique (par exemple, les étiquettes de classe). | La cible est continue (par exemple, des nombres réels). | |
| La cible est continue (par exemple, des nombres réels). | La cible est continue (par exemple, des nombres réels). | |
| Les cas d'utilisation dans le monde réel La détection des spams, la détection des fraudes, la classification des maladies. | La prédiction des ventes, le cours des actions et les prévisions météorologiques. | |
| La modélisation ComplexiIt peut traiter des sorties binaires et multiclasses. | Il est généralement plus simple lorsqu'il s'agit de prédire une valeur continue. |
Tableau : Classification et régression
Comment Milvus aide-t-il dans les tâches de classification ?
Avec l'augmentation du volume et de la complexité des données, les méthodes traditionnelles de gestion et d'interrogation des grands ensembles de données peuvent devenir lentes et inefficaces. C'est là que Zilliz, avec sa base de données vectorielles haute performance et open-source [Milvus] (https://zilliz.com/what-is-milvus), joue un rôle essentiel.
Les tâches de classification, telles que la reconnaissance d'images, la détection d'objets, la recherche de similarités vidéo, la détection de spam et les systèmes de recommandation, nécessitent souvent le traitement de représentations à haute dimension de données non structurées, telles que les enchâssements de texte, les caractéristiques d'image ou les vecteurs audio. Milvus est spécialement conçu pour gérer et rechercher efficacement dans ces grands volumes de données vectorielles.
Avantages de Milvus pour la classification
Gestion des données à haute dimension : Dans la classification, les modèles reposent souvent sur des données vectorisées (par exemple, les enchâssements de mots ou les vecteurs de caractéristiques d'images) pour effectuer des prédictions. Milvus est optimisé pour stocker et gérer ces vecteurs afin d'accéder rapidement à de grands ensembles de données pendant la formation et l'inférence des modèles.
Recherche rapide de similitudes : Les modèles de classification doivent souvent trouver les points de données les plus proches dans un ensemble de données. Milvus accélère ce processus en effectuant des recherches de similarité rapides sur les données vectorielles, ce qui facilite la classification des nouvelles entrées en fonction de leurs voisins les plus proches.
Évolutivité pour les grands ensembles de données : Milvus garantit que les performances restent rapides et efficaces à mesure que les ensembles de données de classification augmentent. Milvus évolue de manière transparente pour que les tâches de classification s'exécutent sans problème même avec de grandes quantités de données, qu'il s'agisse de millions de vecteurs de produits, d'incrustations d'images ou de milliers d'incrustations d'images.
Conclusion
La classification est une technique d'apprentissage automatique qui permet de prédire des étiquettes ou des catégories de données dans diverses applications du monde réel, de la détection de la fraude à la reconnaissance d'images. L'élaboration et le déploiement réussis de modèles de classification nécessitent le traitement de grandes quantités de données, souvent des vecteurs à haute dimension. Milvus offre un stockage efficace, une récupération rapide et une évolutivité pour les données vectorielles. Il améliore les performances des tâches de classification grâce à des recherches de similarité rapides et s'adapte en douceur à la croissance des ensembles de données. Avec Milvus, les développeurs peuvent facilement relever les défis des tâches de classification à grande échelle, ce qui en fait un outil puissant dans le domaine de l'apprentissage automatique.
FAQ sur la classification
Qu'est-ce que la classification dans l'apprentissage automatique?
La classification dans l'apprentissage automatique est le processus de prédiction d'une catégorie ou d'une étiquette pour une entrée donnée sur la base de ses caractéristiques. Un modèle est formé à l'aide de données étiquetées afin d'apprendre des modèles, puis de classer de nouvelles données inédites dans des classes prédéfinies, telles que "spam" ou "non spam".
- En quoi un algorithme de classification diffère-t-il d'un algorithme de régression ?
Les algorithmes de classification prédisent des résultats catégoriques (comme des classes ou des étiquettes), tandis que les algorithmes de régression prédisent des valeurs numériques continues. Par exemple, la classification peut déterminer si un courrier électronique est un spam, tandis que la régression peut prévoir le prix d'une maison.
- Pourquoi la préparation des données est-elle importante dans les tâches de classification ?
La préparation des données permet de s'assurer que les données d'entrée sont propres, structurées et prêtes à être traitées par le modèle. Elle traite les valeurs manquantes, normalise les données et sélectionne les caractéristiques les plus pertinentes. Une bonne préparation améliore la précision et les performances du modèle.
Comment Milvus aide-t-il dans les tâches de classification?
Milvus** est une base de données vectorielles open-source qui stocke et recherche efficacement des données à haute dimension, telles que des images ou des textes intégrés. Elle accélère la classification grâce à sa recherche de similarité efficace, qui facilite le traitement de grands ensembles de données dans des tâches telles que la reconnaissance d'images et les systèmes de recommandation.
- Quels sont les défis courants en matière de classification et comment les relever ?
Les défis les plus courants sont le surajustement, le déséquilibre des données et le bruit dans les données. Ces problèmes peuvent être résolus à l'aide de techniques telles que la régularisation, les méthodes de rééchantillonnage (par exemple, SMOTE), les stratégies de réduction du bruit et une infrastructure évolutive telle que Milvus pour gérer efficacement les grands ensembles de données.
Ressources connexes
Qu'est-ce que la détection d'objets ? un guide complet](https://zilliz.com/learn/what-is-object-detection)
Qu'est-ce que l'algorithme K-Nearest Neighbors (KNN) dans l'apprentissage automatique ?](https://zilliz.com/blog/k-nearest-neighbor-algorithm-for-machine-learning)
Qu'est-ce qu'une base de données vectorielle et comment fonctionne-t-elle ? ](https://zilliz.com/learn/what-is-vector-database)
- Qu'est-ce que la classification ?
- Comment fonctionne la classification ?
- Types de classification
- Les apprenants dans les algorithmes de classification
- Algorithmes de classification
- Mesures d'évaluation de la classification
- Cas d'utilisation de la classification dans le monde réel
- Défis courants en matière de classification
- Classification vs. régression
- Comment Milvus aide-t-il dans les tâches de classification ?
- Conclusion
- FAQ sur la classification
- Ressources connexes
Contenu
Commencez gratuitement, évoluez facilement
Essayez la base de données vectorielle entièrement managée conçue pour vos applications GenAI.
Essayer Zilliz Cloud gratuitement