




Évaluation du RAG à l'aide des ragas
*Cet article a été rédigé par Christy Bergman, Shahul Es et Jithin James.
La récupération est un élément crucial des systèmes d'IA générative, et ses défis sont particulièrement évidents dans Retrieval Augmented Generation (RAG). La Génération Augmentée de Récupération améliore les chatbots alimentés par l'IA en générant des réponses basées sur des données étendues sur lesquelles de grands modèles de langage (LLM ont été entraînés. Malgré la sophistication des systèmes RAG, la précision de la recherche reste un obstacle important, comme le montrent les faibles scores obtenus lors de tests tels que WikiEval. Pour surmonter ces difficultés, il est essentiel d'établir un cadre d'évaluation complet et de procéder à des expériences approfondies afin d'affiner les paramètres des RAG et d'obtenir des performances optimales.
**Toutefois, avant de procéder à des expériences avec les RAG, il faut pouvoir évaluer les expériences qui ont donné les meilleurs résultats.
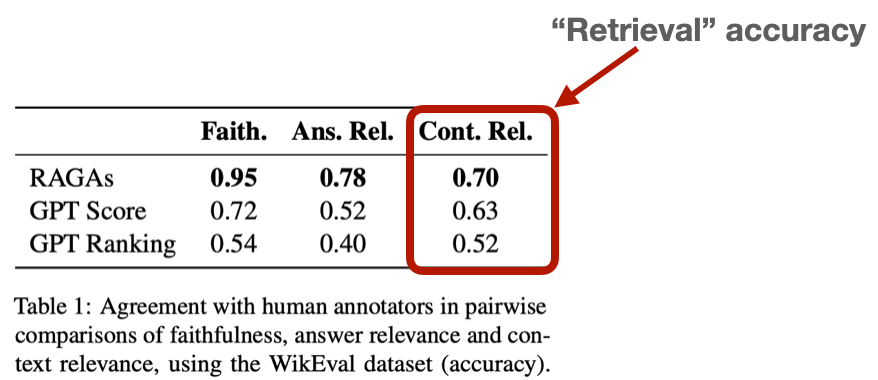
Source de l'image : https://arxiv.org/abs/2309.15217
Qu'est-ce que les ragas ?
Ragas est un cadre d'évaluation spécialisé conçu pour évaluer les performances des systèmes [Retrieval Augmented Generation] (https://zilliz.com/vector-database-use-cases/llm-retrieval-augmented-generation) (RAG). Il fournit une approche structurée pour évaluer l'efficacité des implémentations RAG en s'appuyant sur de grands modèles de langage (LLM) avancés en tant que juges. Ragas se concentre sur l'automatisation du processus d'évaluation, offrant des solutions évolutives et rentables pour évaluer les réponses générées par l'IA. Le cadre vise à corriger les biais et à offrir des scores continus et explicables pour les résultats en langage naturel. Ragas simplifie l'évaluation des systèmes complexes de RAG en fournissant des mesures intuitives et en rationalisant le processus d'évaluation de la qualité de la recherche.
Importance de l'évaluation des systèmes RAG
L'évaluation efficace des systèmes de RAG est essentielle pour affiner les réponses de l'IA. Un cadre d'évaluation solide garantit que les expériences produisent des résultats fiables et que l'IA fournit des réponses précises et adaptées au contexte. L'automatisation du processus d'évaluation peut rationaliser et accélérer cette tâche, la rendant plus rentable et plus évolutive.
Tirer parti des LLM en tant que juges
L'utilisation de grands modèles de langage (LLM) tels que GPT-4 pour [l'évaluation] (https://arxiv.org/pdf/2306.05685) a gagné en popularité en raison de leur capacité à évaluer divers aspects de la qualité de la recherche, y compris la pertinence et la précision. Bien qu'il puisse sembler inhabituel de faire évaluer un LLM par un autre, la recherche indique que GPT-4 s'aligne sur les évaluations humaines dans environ 80% des cas, ce qui correspond à la "limite bayésienne " de l'accord humain. Cette méthode automatise le processus d'évaluation, offrant une évolutivité et réduisant les coûts par rapport à l'étiquetage humain manuel.
Approches de l'évaluation basée sur le LLM
Il existe deux approches principales pour utiliser les LLM comme juges pour [l'évaluation RAG] (https://zilliz.com/blog/how-to-evaluate-retrieval-augmented-generation-rag-applications) :
MT-Bench utilise un LLM pour juger seulement les paires question-réponse qui sont vérifiées comme vérité de terrain humaine. Les humains vérifient d'abord les questions et les réponses pour s'assurer que les questions sont suffisamment complexes pour faire des tests valables avant que le LLM n'utilise les 80 paires Q-A pour évaluer différents décodeurs (composants génératifs de l'IA). [Papier, code, tableau de classement] (https://huggingface.co/spaces/lmsys/mt-bench).
Ragas est construit sur l'idée que les LLMs peuvent évaluer efficacement la sortie du langage naturel en formant des paradigmes qui surmontent les biais de l'utilisation des LLMs comme juges directement et en fournissant des scores continus qui sont explicables et intuitifs à comprendre). Paper, Code, Docs.
Le reste de ce blog présente Ragas, qui met l'accent sur l'automatisation et l'extensibilité des évaluations RAG.
Données d'évaluation nécessaires pour Ragas
Selon la [documentation Ragas] (https://docs.ragas.io/en/stable/howtos/applications/data_preparation.html), votre évaluation du pipeline RAG aura besoin de quatre points de données clés.
Question : La question posée.
Contextes : Les morceaux de texte de vos données qui correspondent le mieux à la signification de la question.
Réponse : Réponse générée par votre chatbot RAG à la question.
Réponse de base : Réponse attendue à la question.
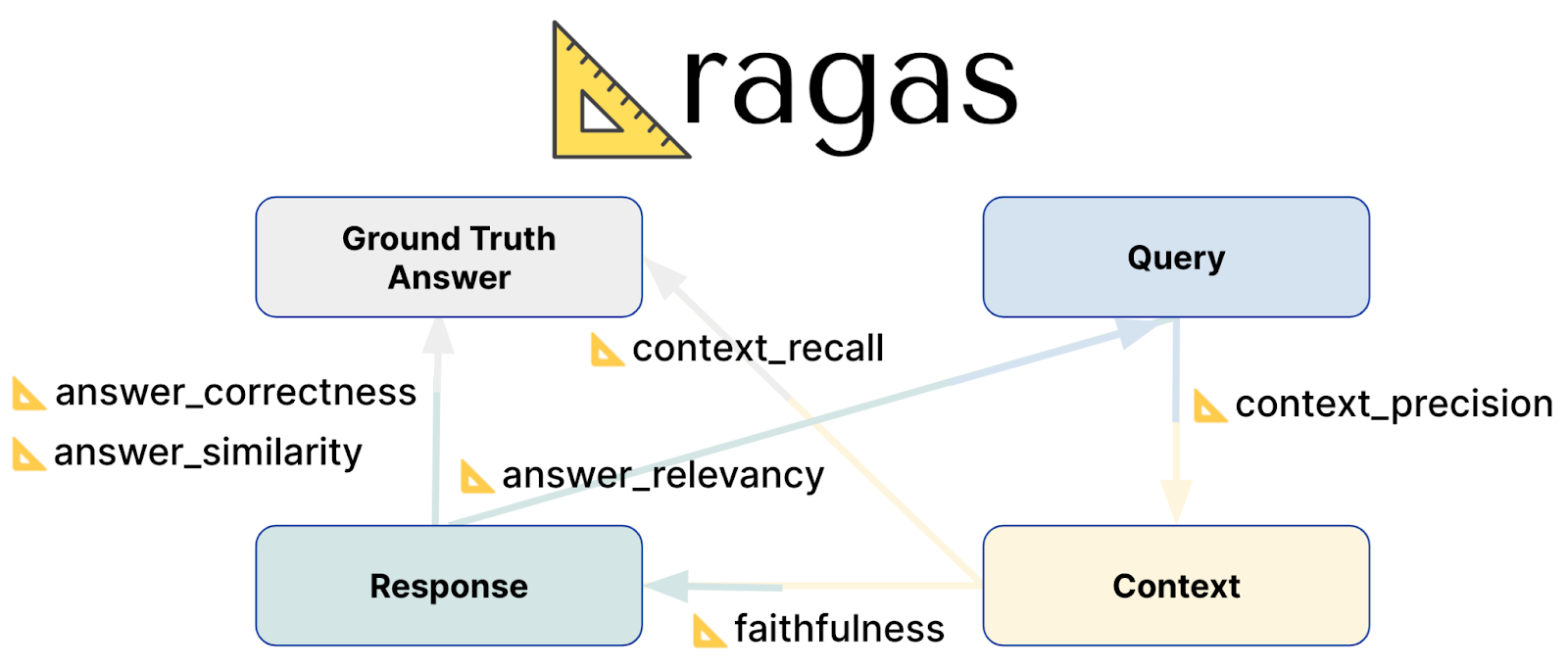 Ragas Evaluation Metrics
Ragas Evaluation Metrics
Principales mesures d'évaluation
Vous trouverez des explications pour chaque mesure d'évaluation, y compris les formules sous-jacentes, dans la documentation. Par exemple, fidélité. Ragas fournit une série de scores d'évaluation pour mesurer l'efficacité des systèmes RAG :
Fidélité : Ce score évalue la précision avec laquelle la réponse générée reflète l'information dans le contexte fourni. Il mesure l'exactitude factuelle de la réponse, en veillant à ce qu'elle corresponde au contexte à partir duquel elle a été dérivée. Les scores vont de 0 à 1, les valeurs les plus élevées indiquant une plus grande précision et une plus grande cohérence.
Pertinence de la réponse : Cette mesure de pertinence de la réponse évalue dans quelle mesure la réponse générée répond à l'invite. Elle se concentre sur l'exhaustivité et la pertinence de la réponse, pénalisant les réponses incomplètes ou redondantes. Le score de pertinence est dérivé de la question, du contexte et de la réponse, les scores les plus élevés reflétant un meilleur alignement avec l'invite.
Rappel de contexte : Le rappel de contexte mesure l'efficacité de la correspondance entre le contexte récupéré et la réponse réelle. Il calcule la proportion d'éléments pertinents qui ont été retrouvés avec succès par rapport à ce qui était attendu. Les scores vont de 0 à 1, les valeurs les plus élevées indiquant qu'une plus grande partie du contexte pertinent a été retrouvée.
Précision du contexte : Cette mesure évalue si les éléments contextuels les plus pertinents sont mieux classés que les moins pertinents. Elle vérifie si tous les éléments contextuels pertinents apparaissent en tête de liste. La précision du contexte est déterminée à l'aide de la question, de la vérité de terrain et des contextes, les scores les plus élevés indiquant un meilleur classement des informations pertinentes.
- Pertinence du contexte** : Ce score de pertinence du contexte évalue le degré de pertinence du contexte retrouvé par rapport à la question. Il mesure la mesure dans laquelle le contexte correspond à l'intention de la requête. La métrique va de 0 à 1, les valeurs les plus élevées indiquant que le contexte est plus pertinent par rapport à la question.
Rappel d'entités contextuelles : Cette métrique calcule dans quelle mesure le contexte récupéré capture les entités mentionnées dans la vérité de terrain. Elle mesure la proportion d'entités trouvées à la fois dans le contexte et dans la vérité de terrain par rapport au nombre total d'entités dans la vérité de terrain. Des scores plus élevés indiquent une meilleure capture des entités importantes dans le contexte.
Des détails sur le calcul de ces mesures peuvent être trouvés dans leur [article] (https://arxiv.org/abs/2309.15217).
Exemple de code d'évaluation RAG
Ce code d'évaluation suppose que vous avez déjà une démo RAG. Pour ma démo, j'ai créé un chatbot RAG en utilisant Milvus Technical documentation et la base de données vectorielle Milvus pour la recherche. Le code complet de ma démo RAG notebook et Eval notebooks se trouve sur GitHub.
En utilisant cette démo RAG, je lui ai posé des questions, j'ai obtenu les contextes RAG de Milvus, et j'ai généré des réponses de bot à partir d'un LLM (voir les 2 dernières colonnes ci-dessous). En outre, j'ai fourni des réponses de "vérité de terrain" aux mêmes questions (colonne "contextes" ci-dessous).
Vous devez installer OpenAI, (HuggingFace) dataset, ragas, langchain, et pandas.
# ! pip install openai dataset ragas langchain pandas
import pandas as pd
eval_df = pd.read_csv("data/milvus_ground_truth.csv")
display(eval_df.head())

Convertit le dataframe pandas en un jeu de données HuggingFace.
from datasets import Dataset
def assemble_ragas_dataset(input_df) :
liste_de_questions, liste_de_vérités, liste_de_contextes = [], [], []
question_list = input_df.Question.to_list()
truth_list = eval_df.ground_truth_answer.to_list()
context_list = input_df.Custom_RAG_context.to_list()
context_list = [[context] for context in context_list]
rag_answer_list = input_df.Custom_RAG_answer.to_list()
# Créer un jeu de données HuggingFace à partir des listes de vérité terrain.
ragas_ds = Dataset.from_dict({"question" : question_list,
"contextes" : context_list,
"answer" : rag_answer_list,
"ground_truth" : truth_list
})
return ragas_ds
# Créer un jeu de données Ragas HuggingFace à partir du fichier pandas df.
ragas_input_ds = assemble_ragas_dataset(eval_df)
display(ragas_input_ds)

Le modèle LLM par défaut utilisé par Ragas est gpt-3.5-turbo-16k d'OpenAI et le modèle d'intégration par défaut est text-embedding-ada-002. Vous pouvez changer les deux modèles pour ce que vous voulez.
Je vais changer le modèle LLM-as-judge en gpt-3.5-turbo car le dernier blog d'OpenAI a annoncé que c'était le moins cher. J'ai également changé le modèle d'intégration en text-embedding-3-small depuis que le blog a indiqué que ces nouvelles intégrations supportent le mode de compression.
Dans le code ci-dessous, je n'utilise que les métriques d'évaluation RAG context pour me concentrer sur la mesure de la qualité de récupération des documents pertinents.
import os, openai, pprint
from openai import OpenAI
# Sauvegarder la clé api dans une variable env.
openai_api_key=os.environ['OPENAI_API_KEY']
# Choisissez les métriques que vous voulez voir.
from ragas.metrics import ( context_recall, context_precision, faithfulness, )
metrics = ['context_recall', 'context_precision', 'faithfulness']
# Modifie la méthode llm-as-critic.
from ragas.llms import llm_factory
LLM_NAME = "gpt-3.5-turbo"
ragas_llm = llm_factory(model=LLM_NAME)
# Changer aussi les embeddings.
from langchain_openai.embeddings import OpenAIEmbeddings
from ragas.embeddings import LangchainEmbeddingsWrapper
lc_embeddings = OpenAIEmbeddings( model="text-embedding-3-small", dimensions=512 )
ragas_emb = LangchainEmbeddingsWrapper(embeddings=lc_embeddings)
# Modifier les modèles par défaut utilisés pour chaque métrique.
for metric in metrics :
globals()[metric].llm = ragas_llm
globals()[metric].embeddings = ragas_emb
# Évaluer le jeu de données.
from ragas import evaluate
ragas_result = evaluate( ragas_input_ds,
metrics=[ context_precision, context_recall, faithfulness, ],
llm=ragas_llm,
)
# Visualiser les évaluations.
ragas_output_df = ragas_result.to_pandas()
ragas_output_df.head()

Vous pouvez voir le code complet de ma démo RAG notebook et Eval notebooks sur GitHub.
Conclusion
Ce blog a exploré les défis actuels de la recherche dans l'IA générative, en mettant particulièrement l'accent sur les techniques de génération augmentée de recherche ([RAG]) (https://zilliz.com/learn/guide-to-chunking-strategies-for-rag) pour faire progresser les systèmes d'IA en langage naturel. Une expérimentation efficace est essentielle pour optimiser les paramètres de la RAG en fonction de données et de cas d'utilisation spécifiques, afin de garantir les meilleures performances. L'évaluation des systèmes RAG peut maintenant être grandement améliorée par l'automatisation en utilisant les LLM comme évaluateurs. Nous avons abordé les principales mesures d'évaluation des RAG et leurs méthodes de calcul, en donnant un aperçu de leurs applications pratiques. En outre, un exemple de mise en œuvre utilisant la base de données vectorielle Milvus ainsi que le paquetage Ragas a été mis en évidence, démontrant comment ces outils peuvent être utilisés efficacement pour améliorer et mettre à l'échelle vos cadres d'évaluation RAG. Cette approche permet non seulement de rationaliser le processus d'évaluation, mais aussi de renforcer l'efficacité globale de la recherche contextuelle dans les solutions basées sur l'IA. Pour aller plus loin, envisagez d'étudier les applications du monde réel, de relever les défis, d'explorer les orientations futures, d'adhérer aux meilleures pratiques et d'accéder à des ressources supplémentaires pour approfondir votre compréhension de l'évaluation des systèmes RAG et de l'affinement de votre pipeline RAG.

Continuer à lire

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).