




RAG agentique local avec LangGraph et Llama 3.2
Mise à jour le 25 septembre 2024 avec Llama 3.2
Dans ce billet, nous allons démontrer comment construire des agents qui peuvent appeler intelligemment des outils pour effectuer des tâches spécifiques en utilisant LangGraph et Llama 3, tout en tirant parti de Milvus Lite pour un stockage efficace des données. Ces agents rassemblent plusieurs capacités importantes, notamment la planification, la mémoire et l'appel d'outils, afin d'améliorer les performances des systèmes de génération augmentée par récupération (RAG).
Introduction à LangGraph et Llama 3
LangGraph est une extension de LangChain, conçue pour construire des applications multi-acteurs robustes et avec état avec des [grands modèles de langage] (https://zilliz.com/glossary/large-language-models-(llms)) (LLMs). Alors que LangChain offre un cadre pour l'intégration des LLM dans divers flux de travail, LangGraph va plus loin en modélisant les tâches sous forme de nœuds et d'arêtes dans une structure de graphe. Cela permet des flux de contrôle plus complexes, permettant aux LLM de planifier, d'apprendre et de s'adapter à la tâche à accomplir. LangGraph offre la flexibilité nécessaire pour mettre en œuvre des systèmes dans lesquels les agents utilisent un raisonnement en plusieurs étapes, en sélectionnant dynamiquement les bons outils pour chaque étape. En outre, LangGraph peut être utilisé pour construire des agents RAG fiables qui suivent un flux de contrôle défini par l'utilisateur à chaque fois qu'ils sont exécutés, garantissant ainsi la cohérence et la prévisibilité de leurs réponses.
LangGraph permet également d'obtenir des comportements plus complexes, semblables à ceux des agents, en permettant l'incorporation de cycles dans les flux de travail. Ces cycles permettent aux agents de revenir aux étapes précédentes si nécessaire, ce qui permet des ajustements dynamiques des actions qu'ils entreprennent sur la base de nouvelles informations ou réflexions. Il en résulte des agents plus intelligents, capables d'affiner leur raisonnement au fil du temps, ce qui permet de créer des systèmes RAG plus robustes et plus adaptatifs.
Llama 3, un grand modèle de langage open-source, sert de moteur de raisonnement central à la mémoire de l'agent. Combiné à LangGraph, Llama 3 peut analyser les entrées, décider des actions à entreprendre et invoquer les outils nécessaires. Plutôt que de se contenter de générer du texte, Llama 3 - alimenté par LangGraph - permet aux agents de planifier, d'exécuter et de réfléchir à leurs actions, ce qui les rend plus intelligents et plus compétents.
Dans ce billet, nous allons montrer comment créer un système langgraphique agentic rag en utilisant LangGraph avec Llama 3 et Milvus Lite. Cette configuration vous permet de tout exécuter localement sans avoir besoin de serveurs externes, ce qui la rend idéale pour les utilisateurs soucieux de leur vie privée et pour les environnements hors ligne.
Construction d'un agent d'appel d'outils avec LangGraph
Le flux de travail de LangGraph est construit autour du concept de nœuds, où chaque nœud représente une tâche ou un outil spécifique. Ces tâches peuvent comprendre l'appel de LLM, la [récupération d'informations] (https://zilliz.com/learn/what-is-information-retrieval) ou l'invocation d'outils personnalisés. Dans un agent d'appel d'outil, deux éléments clés sont en jeu :
Nœud LLM: Ce nœud décide de l'outil à utiliser en fonction des données fournies par l'utilisateur. Il analyse la requête et fournit le nom de l'outil et les arguments pertinents.
**Ce nœud prend le nom de l'outil et les arguments du nœud LLM, invoque l'outil approprié et renvoie le résultat au nœud LLM.
En structurant les tâches (comme la recherche sur le web) sous forme de nœuds et d'arêtes, LangGraph permet la création de flux de travail intelligents, à plusieurs étapes, où les LLM peuvent raisonner sur les questions des utilisateurs concernant les actions à entreprendre, les outils à utiliser, les réponses à apporter aux questions et la manière d'affiner leurs réponses. Milvus Lite joue un rôle clé ici en fournissant un stockage et une récupération efficaces des [données vectorisées] (https://zilliz.com/learn/an-ultimate-guide-to-vectorizing-structured-data) au niveau local.
Comment Milvus Lite améliore les agents locaux d'appel d'outils
Milvus Lite est une version locale et légère de Milvus qui ne nécessite pas Docker ou Kubernetes pour fonctionner. Il est donc facile d'exécuter Milvus sur votre ordinateur portable, votre bloc-notes Jupyter ou même dans Google Colab. Le déploiement local de Milvus Lite vous permet de stocker des vecteurs générés à partir de différentes sources web ou de documents sans avoir besoin de recourir à des [bases de données] externes (https://zilliz.com/glossary/ai-database). Il s'intègre parfaitement à LangGraph pour gérer les recherches de vecteurs, ce qui en fait une solution idéale pour les systèmes locaux RAG.
Par exemple, Milvus Lite peut être utilisé pour stocker des documents indexés qui sont récupérés par l'agent lors d'une recherche sur le web. Lorsque l'agent demande des informations, la base de données vectorielle permet une récupération rapide et précise des documents pertinents.
Création d'un système RAG local avec LangGraph et Llama 3
Nous utilisons LangGraph pour construire un agent RAG local personnalisé alimenté par Llama 3.2 qui utilise différentes approches :
Nous implémentons chaque approche sous la forme d'un flux de contrôle dans LangGraph :
Routage (RAG adaptatif) - Permet à l'agent d'acheminer intelligemment les requêtes des utilisateurs vers la méthode de recherche la plus appropriée en fonction de la question elle-même. Le nœud LLM analyse la requête et, en fonction des mots-clés ou de la structure de la question, il peut l'acheminer vers des nœuds de recherche spécifiques.
Exemple 1 : Les questions nécessitant des réponses factuelles peuvent être acheminées vers un nœud de recherche documentaire interrogeant une base de connaissances pré-indexée (alimentée par Milvus).
Exemple 2 : Les questions ouvertes et créatives peuvent être dirigées vers le LLM pour des tâches de génération.
La fonction de secours (RAG correctif)** - garantit que l'agent dispose d'un plan de secours si ses méthodes de recherche initiales ne fournissent pas de résultats pertinents. Supposons que les nœuds de recherche initiaux (par exemple, la recherche de documents dans la base de connaissances) ne renvoient pas de réponses satisfaisantes (sur la base du score de pertinence ou des seuils de confiance). Dans ce cas, l'agent se rabat sur un nœud de recherche sur le web.
- Le nœud de recherche web peut utiliser des API de recherche externes.
Autocorrection (Self-RAG)** - Permet à l'agent d'identifier et de corriger ses propres erreurs ou résultats trompeurs. Le nœud LLM génère une réponse qui est ensuite acheminée vers un autre nœud pour évaluation. Ce nœud d'évaluation peut utiliser différentes techniques :
Réflexion : L'agent peut vérifier sa réponse par rapport à la requête originale pour voir si elle aborde tous les aspects.
Analyse du score de confiance : Le LLM peut attribuer un score de confiance à sa réponse. Si le score est inférieur à un certain seuil, la réponse est renvoyée au LLM pour révision.
Idées générales pour les agents
Le mécanisme d'autocorrection est une forme de réflexion dans laquelle l'agent LangGraph réfléchit à sa recherche et à ses générations. Il met en boucle les informations à évaluer et permet à l'agent de faire preuve d'une forme de réflexion rudimentaire, en améliorant la qualité de ses résultats au fil du temps.
L'agent ne se contente pas de réagir à la requête ; il établit un processus étape par étape pour récupérer ou générer la meilleure réponse.
Utilisation d'outils -** Le flux de contrôle de l'agent LangGraph comprend des nœuds spécifiques pour différents outils. Il peut s'agir de nœuds de recherche pour la base de connaissances (par exemple, Milvus), démontrant sa capacité à puiser dans un vaste réservoir d'informations, et de nœuds de recherche sur le web pour les informations externes.
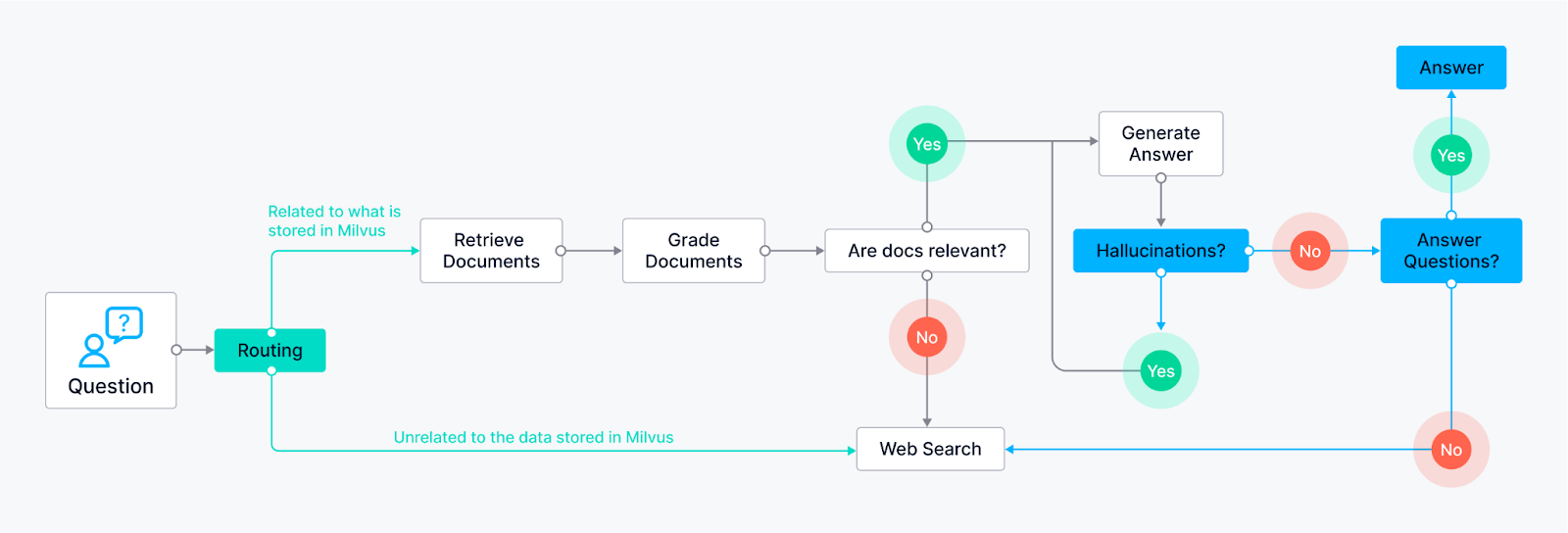
Exemples d'agents
Pour montrer les capacités de nos agents LLM, examinons deux composants clés : le Hallucination Grader et le Answer Grader. Bien que le code complet soit disponible au bas de ce billet, ces extraits permettront de mieux comprendre comment ces agents fonctionnent dans le cadre de LangChain.
Graduateur d'hallucinations
L'évaluateur d'hallucinations tente de résoudre un problème courant avec les LLM : les hallucinations, où le modèle génère des réponses qui semblent plausibles mais qui manquent de fondement factuel. Cet agent agit comme un vérificateur de faits, évaluant si la réponse du LLM s'aligne sur un ensemble fourni de documents extraits de Milvus.
### Hallucination Grader
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template="""Vous êtes un correcteur qui évalue si
si une réponse est fondée sur un ensemble de faits. Donnez un score binaire "oui" ou "non" pour indiquer
si la réponse est basée sur / soutenue par un ensemble de faits. Fournir le score binaire sous la forme d'un JSON avec une
clé unique "score", sans préambule ni explication.
Voici les faits :
{documents}
Voici la réponse :
{génération}
""",
input_variables=["génération", "documents"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents" : docs, "generation" : generation})
Answer Grader
Après l'évaluateur d'hallucinations, un autre agent intervient. Cet agent vérifie un autre aspect crucial : s'assurer que la réponse du LLM répond directement à la question originale de l'utilisateur. Il utilise le même LLM mais avec une invite différente, spécifiquement conçue pour évaluer la pertinence de la réponse par rapport à la question.
def grade_generation_v_documents_et_question(state) :
"""
Détermine si la génération est ancrée dans le document et répond aux questions.
Args :
state (dict) : L'état actuel du graphe
Retourne :
str : Décision pour le prochain noeud à appeler
"""
print("---VÉRIFIER LES HALLUCINATIONS---")
question = state["question"]
documents = état["documents"]
generation = state["generation"]
score = hallucination_grader.invoke({"documents" : documents, "generation" : generation})
note = score['score']
# Vérifier l'hallucination
si note == "yes" :
print("---DECISION : GENERATION IS GROUND IN DOCUMENTS---")
# Vérifier la réponse aux questions
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"question" : question, "generation" : generation})
note = score['score']
if grade == "yes" :
print("---DECISION : GENERATION ADAPTE LA QUESTION---")
return "utile"
else :
print("---DECISION : LA GENERATION NE REPOND PAS A LA QUESTION---")
retour "pas utile"
else :
pprint("---DECISION : LA GENERATION N'EST PAS FONDEE SUR DES DOCUMENTS, RE-TEMPS---")
return "not supported"
Vous pouvez voir dans le code ci-dessus que nous vérifions les prédictions du LLM que nous utilisons comme classificateur.
Compilation du graphe LangGraph
Ceci compilera tous les agents que nous avons définis et rendra possible l'utilisation de différents outils pour votre système RAG.
# Compiler
app = workflow.compile()
# Test
from pprint import pprint
inputs = {"question" : "Qu'est-ce que l'ingénierie rapide ?"}
for output in app.stream(inputs) :
for key, value in output.items() :
pprint(f "Finished running : {key} :")
pprint(value["generation"])
'Finished running : generate:'
('L'ingénierie des messages-guides est le processus de communication avec les '
'modèles linguistiques (LLM) afin d'orienter leur comportement vers les résultats souhaités sans '
'mettre à jour les poids du modèle. Elle se concentre sur l'alignement et l'orientation du modèle, '
'nécessitant des expérimentations et des heuristiques en raison des effets variables entre les '
'modèles. L'objectif est d'améliorer la génération de textes contrôlables en optimisant les invites pour des applications spécifiques.
'pour des applications spécifiques.')
Conclusion
Dans ce billet de blog, nous avons montré comment construire un système RAG en utilisant des agents avec LangChain/ LangGraph, Llama 3.2, et Milvus. Ces agents permettent aux LLM d'avoir des capacités de planification, de mémoire et d'utilisation d'outils différents, ce qui peut conduire à des réponses plus robustes et plus informatives.
Prochaines étapes d'amélioration
Bien que la mise en œuvre actuelle du système agentic RAG soit efficace pour les flux de travail locaux à agent unique, il existe plusieurs directions intéressantes pour l'amélioration et l'innovation.
Coordination multi-agents: Actuellement, LangGraph est utilisé pour concevoir des systèmes mono-agents qui fonctionnent dans le cadre d'un flux de contrôle prédéfini, comme une recherche sur le web. Cependant, une progression naturelle serait d'étendre ce système pour prendre en charge plusieurs agents travaillant en parallèle ou en coordination. Dans les scénarios où une tâche nécessite des connaissances spécialisées ou des sources de recherche multiples, les agents peuvent traiter en collaboration différentes parties de la tâche. Par exemple, un agent pourrait se concentrer sur la recherche d'informations factuelles, tandis qu'un autre s'occuperait des tâches créatives ou de l'interaction avec l'utilisateur, et qu'un troisième évaluerait la qualité globale du résultat. De tels systèmes multi-agents permettraient des opérations plus complexes, conduisant à une efficacité et une précision accrues dans le traitement de diverses requêtes.
Mises à jour des Données en temps réel** : ** Une autre amélioration potentielle pourrait consister à permettre aux agents de mettre à jour leurs sources de données en temps réel. Actuellement, Milvus Lite sert de base de connaissances statique ; cependant, dans les domaines dynamiques, les informations peuvent rapidement devenir obsolètes. Les agents pourraient être conçus pour surveiller et mettre à jour en permanence leur magasin de vecteurs local avec des données fraîches provenant du Web ou d'autres API, afin de garantir que les résultats du système restent pertinents et à jour. Par exemple, si un agent est interrogé sur les derniers cours de la bourse ou les dernières nouvelles, il pourrait automatiquement récupérer les données les plus récentes, ce qui rendrait le système beaucoup plus adaptable et utile dans des environnements en évolution rapide.
Amélioration de la réflexion et de l'auto-amélioration: Bien que le mécanisme de réflexion actuel soit utile, il est possible de l'améliorer en termes d'autocorrection. Les futures versions de l'agent pourraient intégrer des techniques plus avancées, telles que l'apprentissage par renforcement ou les mécanismes d'apprentissage continu, permettant à l'agent d'apprendre de ses expériences passées et de ses erreurs au fil du temps. En permettant à la mémoire de l'agent de travailler à l'amélioration itérative de la qualité de ses réponses, nous pourrions obtenir un système qui non seulement récupère et génère des réponses de haute qualité, mais qui affine également ses processus sur la base du retour d'information.
En intégrant ces prochaines étapes, nous pouvons considérablement améliorer les capacités des systèmes de RAG agentiques, en les rendant plus flexibles, plus adaptatifs et plus efficaces dans la résolution de tâches complexes dans une variété d'industries.
N'hésitez pas à consulter le code disponible dans le [Milvus Bootcamp repository] (https://github.com/milvus-io/bootcamp/tree/master/bootcamp/RAG/advanced_rag).
Si vous avez apprécié cet article de blog montrant comment construire langgraph agentic rag, pensez à nous donner une étoile sur , et partagez vos expériences avec la communauté en rejoignant nos
Ceci est inspiré par le Dépôt Github de Meta avec des recettes pour l'utilisation de Llama 3.

Continuer à lire

Why and How to Migrate from Self-Hosted Milvus to Zilliz Cloud
A simple, step-by-step guide to migrating from Milvus to Zilliz Cloud. Learn both endpoint and backup methods for a smooth, scalable vector database migration.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.