




Comment choisir le meilleur modèle d’embedding pour le RAG en 2026 : 10 modèles évalués
TL;DR : Nous avons testé 10 modèles d'embedding dans quatre scénarios de production que les benchmarks publics ne couvrent pas : récupération cross-modale, récupération cross-lingue, récupération d'informations clés et compression dimensionnelle. Aucun modèle ne gagne partout. Gemini Embedding 2 est le meilleur modèle polyvalent. L'open source Qwen3-VL-2B surpasse les API propriétaires sur les tâches cross-modales. Si vous devez compresser les dimensions pour économiser du stockage, choisissez Voyage Multimodal 3.5 ou Jina Embeddings v4.
Pourquoi MTEB ne suffit pas pour choisir un modèle d'embedding
La plupart des prototypes RAG commencent avec text-embedding-3-small d'OpenAI. Il est peu coûteux, facile à intégrer et suffisamment performant pour la récupération de texte en anglais. Mais le RAG en production dépasse vite ce cadre. Votre pipeline récupère des images, des PDF, des documents multilingues — et un modèle d'embedding uniquement textuel ne suffit plus.
Le classement MTEB vous indique qu'il existe de meilleures options. Le problème ? MTEB ne teste que la récupération de texte monolingue. Il ne couvre pas la récupération cross-modale (requêtes textuelles sur des collections d'images), la recherche cross-lingue (une requête en chinois trouvant un document en anglais), la précision sur les documents longs, ni la perte de qualité lorsque vous tronquez les dimensions d'embedding pour économiser du stockage dans votre base de données vectorielle.
Alors, quel modèle d'embedding devriez-vous utiliser ? Cela dépend de vos types de données, de vos langues, de la longueur de vos documents et de votre besoin éventuel de compression dimensionnelle. Nous avons construit un benchmark appelé CCKM et testé 10 modèles publiés entre 2025 et 2026 précisément selon ces dimensions.
Qu'est-ce que le benchmark CCKM ?
CCKM (Cross-modal, Cross-lingual, Key information, MRL) teste quatre capacités que les benchmarks standards ne couvrent pas :
| Dimension | Ce qu'elle teste | Pourquoi c'est important |
|---|---|---|
| Récupération cross-modale | Faire correspondre des descriptions textuelles à la bonne image en présence de distracteurs quasi identiques | Les pipelines RAG multimodaux ont besoin d'embeddings textuels et visuels dans le même espace vectoriel |
| Récupération cross-lingue | Trouver le bon document en anglais à partir d'une requête en chinois, et inversement | Les bases de connaissances en production sont souvent multilingues |
| Récupération d'informations clés | Localiser un fait spécifique enfoui dans un document de 4K à 32K caractères (aiguille dans une botte de foin) | Les systèmes RAG traitent fréquemment des documents longs comme des contrats et des articles de recherche |
| Compression dimensionnelle MRL | Mesurer la perte de qualité du modèle lorsque vous tronquez les embeddings à 256 dimensions | Moins de dimensions = coût de stockage plus faible dans votre base de données vectorielle, mais à quel coût en qualité ? |
MTEB ne couvre rien de tout cela. MMEB ajoute le multimodal mais omet les négatifs difficiles, de sorte que les modèles obtiennent des scores élevés sans prouver qu'ils gèrent les distinctions subtiles. CCKM est conçu pour couvrir ce qui leur manque.
Quels modèles d'embedding avons-nous testés ? Gemini Embedding 2, Jina Embeddings v4, et plus encore
Nous avons testé 10 modèles couvrant à la fois des services API et des options open source, plus CLIP ViT-L-14 comme référence de 2021.
| Modèle | Source | Paramètres | Dimensions | Modalité | Trait clé |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Non divulgué | 3072 | Texte / image / vidéo / audio / PDF | Toutes modalités, couverture la plus large | |
| Jina Embeddings v4 | Jina AI | 3,8B | 2048 | Texte / image / PDF | Adaptateurs MRL + LoRA |
| Voyage Multimodal 3.5 | Voyage AI (MongoDB) | Non divulgué | 1024 | Texte / image / vidéo | Équilibré sur l’ensemble des tâches |
| Qwen3-VL-Embedding-2B | Alibaba Qwen | 2B | 2048 | Texte / image / vidéo | Open source, multimodal léger |
| Jina CLIP v2 | Jina AI | ~1B | 1024 | Texte / image | Architecture CLIP modernisée |
| Cohere Embed v4 | Cohere | Non divulgué | Fixe | Texte | Recherche d’entreprise |
| OpenAI text-embedding-3-large | OpenAI | Non divulgué | 3072 | Texte | Le plus largement utilisé |
| BGE-M3 | BAAI | 568M | 1024 | Texte | Open source, plus de 100 langues |
| mxbai-embed-large | Mixedbread AI | 335M | 1024 | Texte | Léger, axé sur l’anglais |
| nomic-embed-text | Nomic AI | 137M | 768 | Texte | Ultra-léger |
| CLIP ViT-L-14 | OpenAI (2021) | 428M | 768 | Texte / image | Référence |
Recherche intermodale : quels modèles gèrent la recherche texte-vers-image ?
Si votre pipeline RAG gère des images en parallèle du texte, le modèle d’embedding doit placer les deux modalités dans le même espace vectoriel. Pensez à la recherche d’images en e-commerce, aux bases de connaissances mixtes image-texte, ou à tout système dans lequel une requête textuelle doit trouver la bonne image.
Méthode
Nous avons pris 200 paires image-texte de COCO val2017. Pour chaque image, GPT-4o-mini a généré une description détaillée. Ensuite, nous avons rédigé 3 négatifs difficiles par image — des descriptions qui diffèrent de la bonne par seulement un ou deux détails. Le modèle doit trouver la bonne correspondance dans un ensemble de 200 images et 600 leurres.
Un exemple tiré du jeu de données :
 Valises vintage en cuir brun avec des autocollants de voyage incluant California et Cuba, placées sur un porte-bagages métallique contre un ciel bleu — utilisées comme image de test dans le benchmark de recherche intermodale
Valises vintage en cuir brun avec des autocollants de voyage incluant California et Cuba, placées sur un porte-bagages métallique contre un ciel bleu — utilisées comme image de test dans le benchmark de recherche intermodale
Description correcte : "L’image présente des valises vintage en cuir brun avec divers autocollants de voyage incluant 'California', 'Cuba' et 'New York', placées sur un porte-bagages métallique contre un ciel bleu dégagé."
Négatif difficile : Même phrase, mais "California" devient "Florida" et "blue sky" devient "overcast sky." Le modèle doit réellement comprendre les détails de l’image pour les distinguer.
Notation :
- Générer des embeddings pour toutes les images et tout le texte (200 descriptions correctes + 600 négatifs difficiles).
- Texte-vers-image (t2i) : Chaque description recherche la correspondance la plus proche parmi 200 images. Un point est attribué si le meilleur résultat est correct.
- Image-vers-texte (i2t) : Chaque image recherche la correspondance la plus proche parmi les 800 textes. Un point est attribué uniquement si le meilleur résultat est la description correcte, et non un négatif difficile.
- Score final : hard_avg_R@1 = (précision t2i + précision i2t) / 2
Résultats
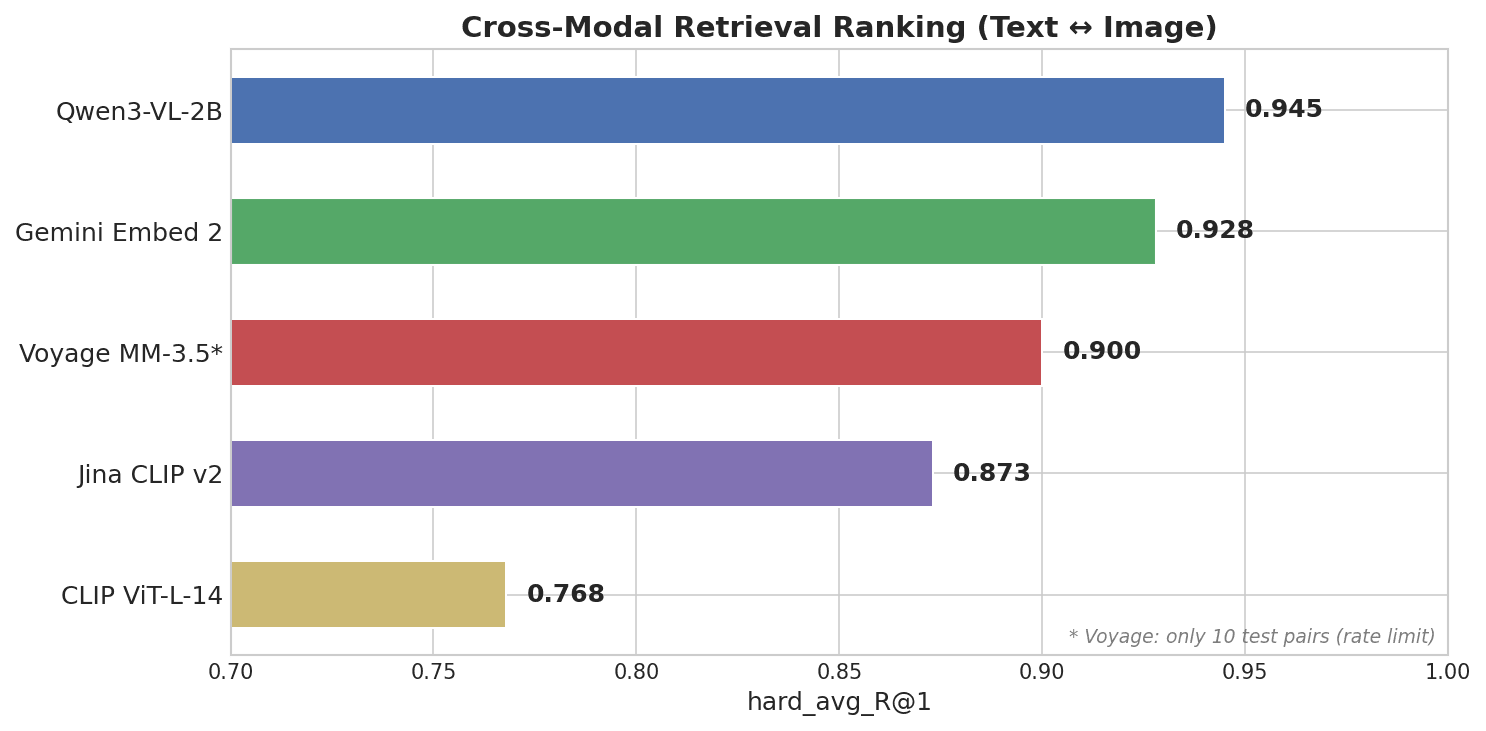 Graphique à barres horizontales montrant le classement de la recherche intermodale : Qwen3-VL-2B en tête avec 0,945, suivi de Gemini Embed 2 avec 0,928, Voyage MM-3.5 avec 0,900, Jina CLIP v2 avec 0,873, et CLIP ViT-L-14 avec 0,768
Graphique à barres horizontales montrant le classement de la recherche intermodale : Qwen3-VL-2B en tête avec 0,945, suivi de Gemini Embed 2 avec 0,928, Voyage MM-3.5 avec 0,900, Jina CLIP v2 avec 0,873, et CLIP ViT-L-14 avec 0,768
Qwen3-VL-2B, un modèle open source de 2B paramètres de l’équipe Qwen d’Alibaba, est arrivé premier — devant toutes les API propriétaires.
Le modality gap explique l’essentiel de la différence. Les modèles d’embedding projettent le texte et les images dans le même espace vectoriel, mais en pratique les deux modalités ont tendance à se regrouper dans des régions différentes. Le modality gap mesure la distance L2 entre ces deux groupes. Écart plus faible = recherche intermodale plus facile.
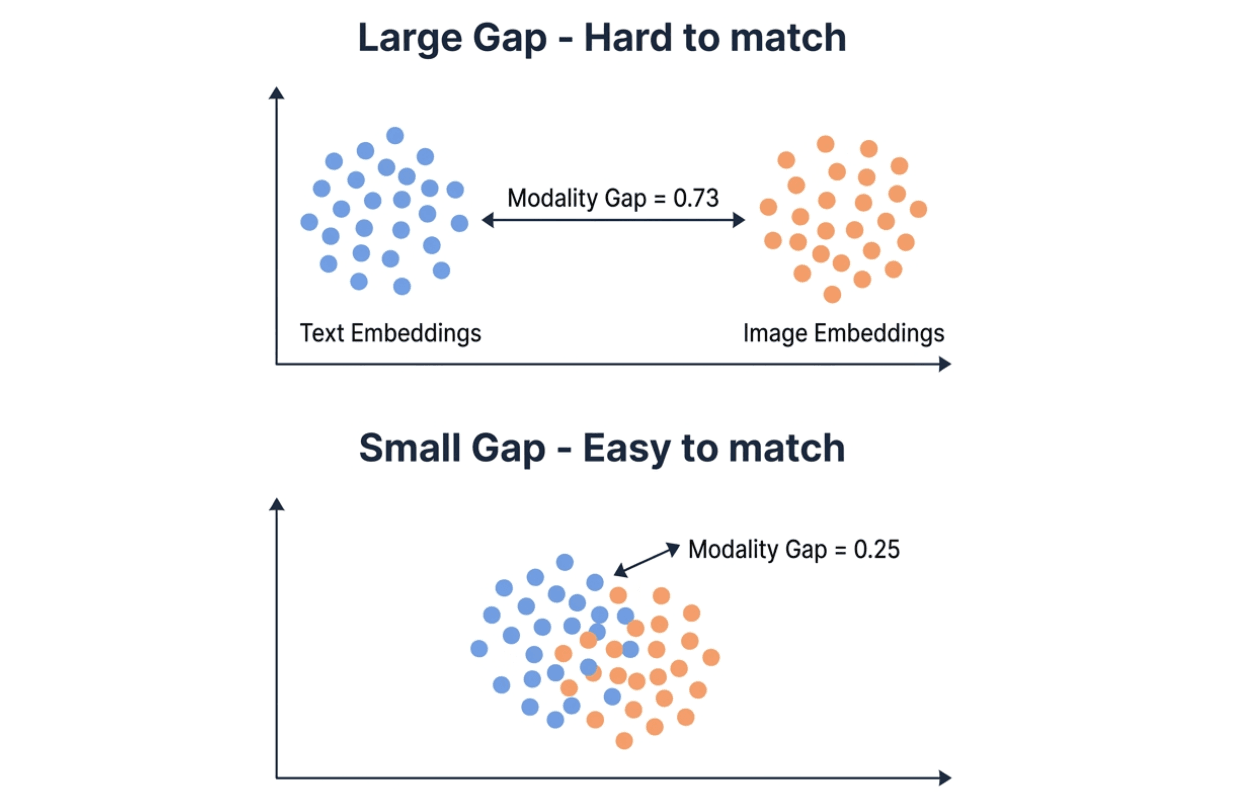 Visualisation comparant un grand écart de modalité (0,73, clusters d’embeddings texte et image très éloignés) à un petit écart de modalité (0,25, clusters qui se chevauchent) — un écart plus faible facilite la mise en correspondance intermodale
Visualisation comparant un grand écart de modalité (0,73, clusters d’embeddings texte et image très éloignés) à un petit écart de modalité (0,25, clusters qui se chevauchent) — un écart plus faible facilite la mise en correspondance intermodale
| Modèle | Score (R@1) | Écart de modalité | Params |
|---|---|---|---|
| Qwen3-VL-2B | 0.945 | 0.25 | 2B (open-source) |
| Gemini Embedding 2 | 0.928 | 0.73 | Inconnu (fermé) |
| Voyage Multimodal 3.5 | 0.900 | 0.59 | Inconnu (fermé) |
| Jina CLIP v2 | 0.873 | 0.87 | ~1B |
| CLIP ViT-L-14 | 0.768 | 0.83 | 428M |
L’écart de modalité de Qwen est de 0,25 — environ un tiers des 0,73 de Gemini. Dans une base de données vectorielle comme Milvus, un faible écart de modalité signifie que vous pouvez stocker les embeddings de texte et d’image dans la même collection et effectuer une recherche directement sur les deux. Un écart important peut rendre la recherche de similarité intermodale moins fiable, et vous pourriez avoir besoin d’une étape de reclassement pour compenser.
Récupération interlingue : quels modèles alignent le sens entre les langues ?
Les bases de connaissances multilingues sont courantes en production. Un utilisateur pose une question en chinois, mais la réponse se trouve dans un document en anglais — ou inversement. Le modèle d’embedding doit aligner le sens entre les langues, pas seulement au sein d’une seule.
Méthode
Nous avons construit 166 paires de phrases parallèles en chinois et en anglais sur trois niveaux de difficulté :
 Niveaux de difficulté interlingue : le niveau Facile associe des traductions littérales comme 我爱你 à I love you ; le niveau Moyen associe des phrases paraphrasées comme 这道菜太咸了 à This dish is too salty avec des négatifs difficiles ; le niveau Difficile associe des idiomes chinois comme 画蛇添足 à gilding the lily avec des négatifs difficiles sémantiquement différents
Niveaux de difficulté interlingue : le niveau Facile associe des traductions littérales comme 我爱你 à I love you ; le niveau Moyen associe des phrases paraphrasées comme 这道菜太咸了 à This dish is too salty avec des négatifs difficiles ; le niveau Difficile associe des idiomes chinois comme 画蛇添足 à gilding the lily avec des négatifs difficiles sémantiquement différents
Chaque langue reçoit également 152 distracteurs négatifs difficiles.
Notation :
- Générer des embeddings pour tous les textes chinois (166 corrects + 152 distracteurs) et tous les textes anglais (166 corrects + 152 distracteurs).
- Chinois → Anglais : Chaque phrase chinoise recherche sa traduction correcte parmi 318 textes anglais.
- Anglais → Chinois : Même chose dans l’autre sens.
- Score final : hard_avg_R@1 = (précision zh→en + précision en→zh) / 2
Résultats
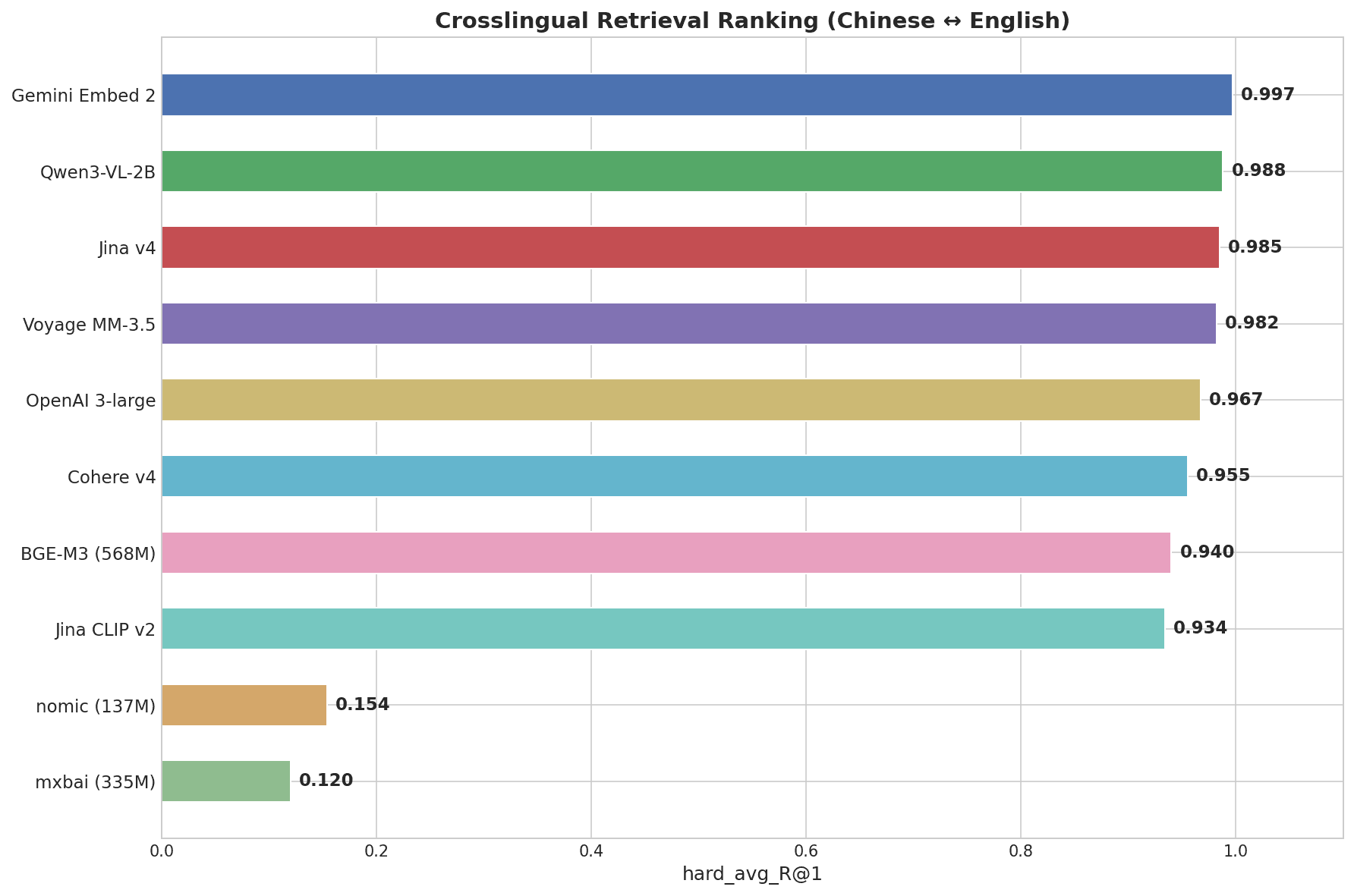 Graphique à barres horizontales montrant le classement de la récupération interlingue : Gemini Embed 2 est en tête à 0,997, suivi de Qwen3-VL-2B à 0,988, Jina v4 à 0,985, Voyage MM-3.5 à 0,982, jusqu’à mxbai à 0,120
Graphique à barres horizontales montrant le classement de la récupération interlingue : Gemini Embed 2 est en tête à 0,997, suivi de Qwen3-VL-2B à 0,988, Jina v4 à 0,985, Voyage MM-3.5 à 0,982, jusqu’à mxbai à 0,120
Gemini Embedding 2 a obtenu 0,997 — le score le plus élevé de tous les modèles testés. C’est le seul modèle à avoir obtenu un score parfait de 1,000 sur le niveau Difficile, où des paires comme "画蛇添足" → "gilding the lily" nécessitent une véritable compréhension sémantique entre les langues, et non une simple correspondance de motifs.
| Modèle | Score (R@1) | Facile | Moyen | Difficile (idiomes) |
|---|---|---|---|---|
| Gemini Embedding 2 | 0.997 | 1.000 | 1.000 | 1.000 |
| Qwen3-VL-2B | 0.988 | 1.000 | 1.000 | 0.969 |
| Jina Embeddings v4 | 0.985 | 1.000 | 1.000 | 0.969 |
| Voyage Multimodal 3.5 | 0.982 | 1.000 | 1.000 | 0.938 |
| OpenAI 3-large | 0.967 | 1.000 | 1.000 | 0.906 |
| Cohere Embed v4 | 0.955 | 1.000 | 0.980 | 0.875 |
| BGE-M3 (568M) | 0.940 | 1.000 | 0.960 | 0.844 |
| nomic-embed-text (137M) | 0.154 | 0.300 | 0.120 | 0.031 |
| mxbai-embed-large (335M) | 0.120 | 0.220 | 0.080 | 0.031 |
Les 7 meilleurs modèles dépassent tous 0,93 sur le score global — la vraie différenciation se produit au niveau Difficile (idiomes chinois). nomic-embed-text et mxbai-embed-large, deux modèles légers axés sur l’anglais, obtiennent des scores proches de zéro sur les tâches interlingues.
Récupération d’informations clés : les modèles peuvent-ils trouver une aiguille dans un document de 32K tokens ?
Les systèmes RAG traitent souvent des documents longs — contrats juridiques, articles de recherche, rapports internes contenant des données non structurées. La question est de savoir si un modèle d’embedding peut encore trouver un fait précis enfoui dans des milliers de caractères de texte environnant.
Méthode
Nous avons pris des articles Wikipédia de longueurs variées (4K à 32K caractères) comme botte de foin et y avons inséré un seul fait fabriqué — l’aiguille — à différentes positions : début, 25 %, 50 %, 75 % et fin. Le modèle doit déterminer, sur la base d’un embedding de requête, quelle version du document contient l’aiguille.
Exemple :
- Aiguille : "The Meridian Corporation reported quarterly revenue of $847.3 million in Q3 2025."
- Requête : "Quel était le chiffre d’affaires trimestriel de Meridian Corporation ?"
- Botte de foin : Un article Wikipédia de 32 000 caractères sur la photosynthèse, avec l’aiguille cachée quelque part à l’intérieur.
Notation :
- Générer des embeddings pour la requête, le document avec l’aiguille et le document sans.
- Si la requête est plus similaire au document contenant l’aiguille, compter cela comme un succès.
- Calculer la précision moyenne sur toutes les longueurs de document et positions de l’aiguille.
- Métriques finales : overall_accuracy et degradation_rate (la baisse de précision entre le document le plus court et le plus long).
Résultats
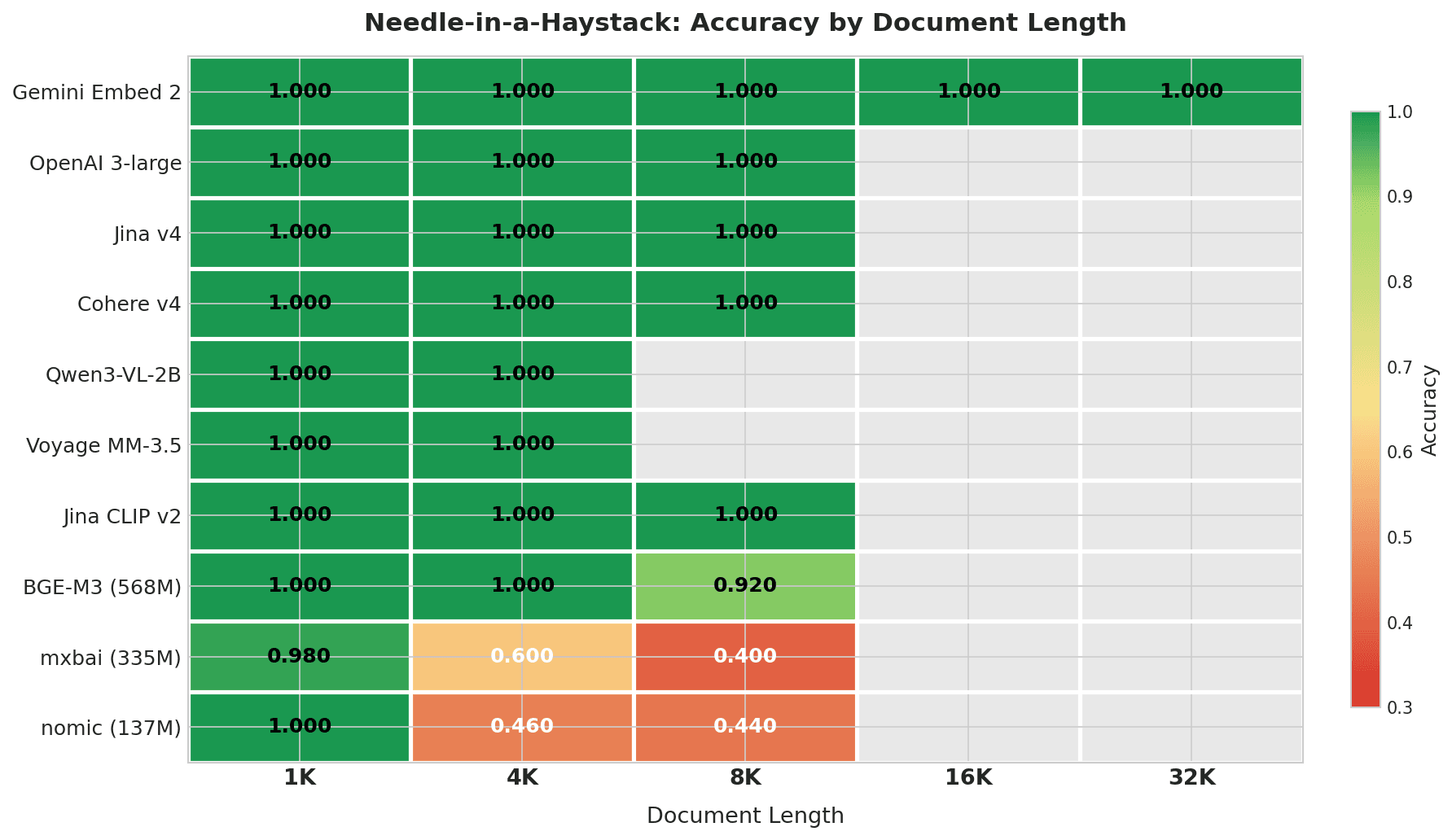 Carte thermique montrant la précision Needle-in-a-Haystack par longueur de document : Gemini Embed 2 obtient 1.000 sur toutes les longueurs jusqu’à 32K ; les 7 meilleurs modèles obtiennent un score parfait dans leurs fenêtres de contexte ; mxbai et nomic se dégradent fortement à partir de 4K+
Carte thermique montrant la précision Needle-in-a-Haystack par longueur de document : Gemini Embed 2 obtient 1.000 sur toutes les longueurs jusqu’à 32K ; les 7 meilleurs modèles obtiennent un score parfait dans leurs fenêtres de contexte ; mxbai et nomic se dégradent fortement à partir de 4K+
Gemini Embedding 2 est le seul modèle testé sur toute la plage 4K–32K, et il a obtenu un score parfait à chaque longueur. Aucun autre modèle de ce test n’a une fenêtre de contexte atteignant 32K.
| Modèle | 1K | 4K | 8K | 16K | 32K | Global | Dégradation |
|---|---|---|---|---|---|---|---|
| Gemini Embedding 2 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 0% |
| OpenAI 3-large | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Jina Embeddings v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Cohere Embed v4 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| Qwen3-VL-2B | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Voyage Multimodal 3.5 | 1.000 | 1.000 | — | — | — | 1.000 | 0% |
| Jina CLIP v2 | 1.000 | 1.000 | 1.000 | — | — | 1.000 | 0% |
| BGE-M3 (568M) | 1.000 | 1.000 | 0.920 | — | — | 0.973 | 8% |
| mxbai-embed-large (335M) | 0.980 | 0.600 | 0.400 | — | — | 0.660 | 58% |
| nomic-embed-text (137M) | 1.000 | 0.460 | 0.440 | — | — | 0.633 | 56% |
"—" signifie que la longueur du document dépasse la fenêtre de contexte du modèle.
Les 7 meilleurs modèles obtiennent un score parfait dans leurs fenêtres de contexte. BGE-M3 commence à fléchir à 8K (0.920). Les modèles légers (mxbai et nomic) chutent à 0.4–0.6 dès 4K caractères — soit environ 1 000 tokens. Pour mxbai, cette baisse reflète en partie sa fenêtre de contexte de 512 tokens, qui tronque la majeure partie du document.
Compression dimensionnelle MRL : quelle qualité perdez-vous à 256 dimensions ?
Matryoshka Representation Learning (MRL) est une technique d’entraînement qui rend les N premières dimensions d’un vecteur significatives par elles-mêmes. Prenez un vecteur de 3072 dimensions, tronquez-le à 256, et il conserve encore l’essentiel de sa qualité sémantique. Moins de dimensions signifie des coûts de stockage et de mémoire plus faibles dans votre base de données vectorielle — passer de 3072 à 256 dimensions représente une réduction du stockage par 12.
 Illustration montrant la troncature dimensionnelle MRL : 3072 dimensions à pleine qualité, 1024 à 95 %, 512 à 90 %, 256 à 85 % — avec 12x d’économies de stockage à 256 dimensions
Illustration montrant la troncature dimensionnelle MRL : 3072 dimensions à pleine qualité, 1024 à 95 %, 512 à 90 %, 256 à 85 % — avec 12x d’économies de stockage à 256 dimensions
Méthode
Nous avons utilisé 150 paires de phrases issues du benchmark STS-B, chacune avec un score de similarité annoté par des humains (0–5). Pour chaque modèle, nous avons généré des embeddings en dimensions complètes, puis les avons tronqués à 1024, 512 et 256.
 Exemples de données STS-B montrant des paires de phrases avec des scores de similarité humains : Une fille se coiffe vs Une fille se brosse les cheveux obtient 2,5 ; Un groupe d’hommes joue au football sur la plage vs Un groupe de garçons joue au football sur la plage obtient 3,6
Exemples de données STS-B montrant des paires de phrases avec des scores de similarité humains : Une fille se coiffe vs Une fille se brosse les cheveux obtient 2,5 ; Un groupe d’hommes joue au football sur la plage vs Un groupe de garçons joue au football sur la plage obtient 3,6
Notation :
- À chaque niveau de dimension, calculez la similarité cosinus entre les embeddings de chaque paire de phrases.
- Comparez le classement de similarité du modèle au classement humain à l’aide du ρ de Spearman (corrélation de rang).
Qu’est-ce que le ρ de Spearman ? Il mesure à quel point deux classements concordent. Si les humains classent la paire A comme la plus similaire, B en deuxième, C comme la moins similaire — et que les similarités cosinus du modèle produisent le même ordre A > B > C — alors ρ se rapproche de 1,0. Un ρ de 1,0 signifie un accord parfait. Un ρ de 0 signifie aucune corrélation.
Métriques finales : spearman_rho (plus élevé est meilleur) et min_viable_dim (la plus petite dimension où la qualité reste dans une marge de 5 % de la performance en dimension complète).
Résultats
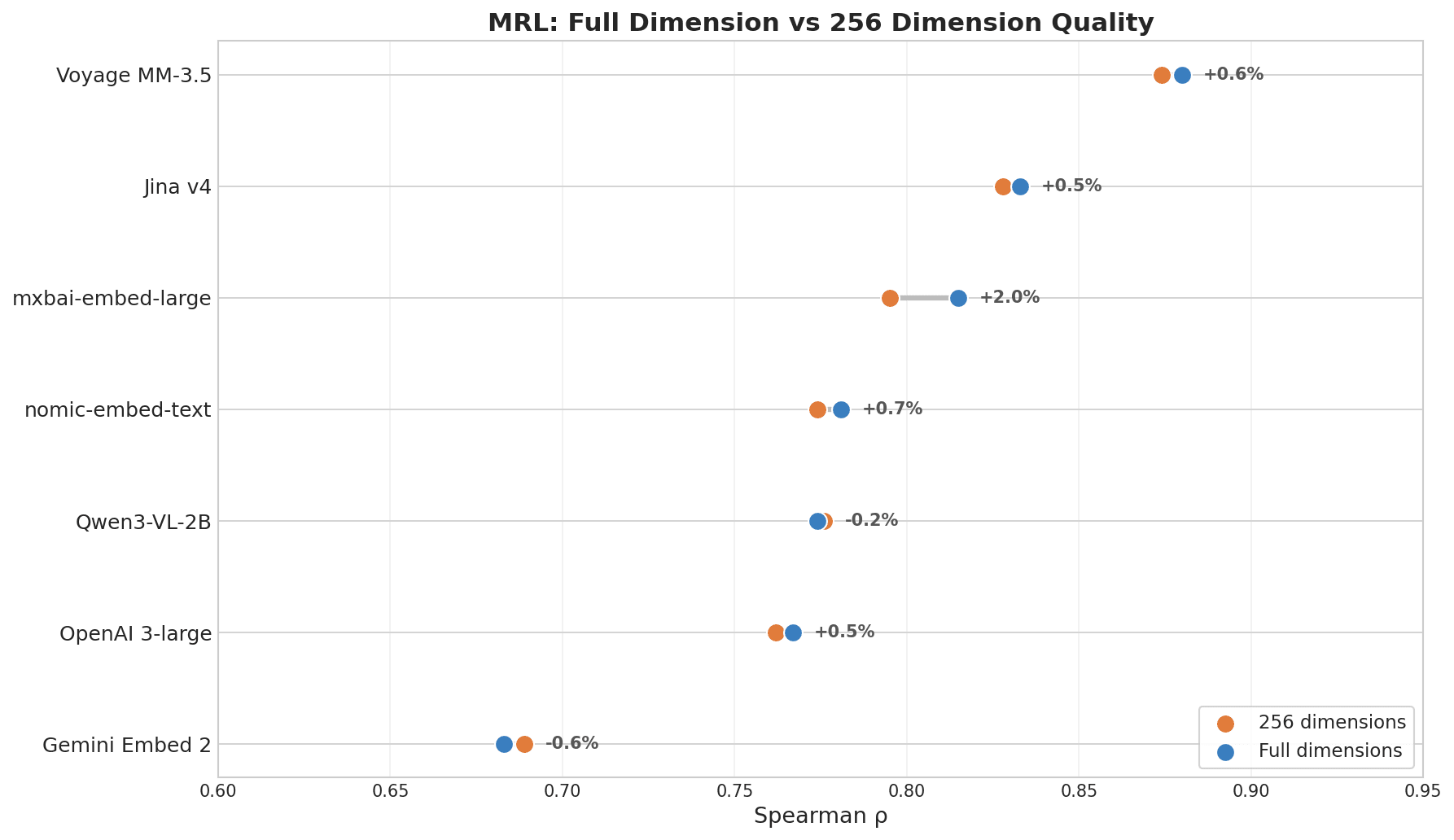 Nuage de points montrant la qualité MRL en dimension complète vs en 256 dimensions : Voyage MM-3.5 est en tête avec un changement de +0,6 %, Jina v4 +0,5 %, tandis que Gemini Embed 2 affiche -0,6 % en bas
Nuage de points montrant la qualité MRL en dimension complète vs en 256 dimensions : Voyage MM-3.5 est en tête avec un changement de +0,6 %, Jina v4 +0,5 %, tandis que Gemini Embed 2 affiche -0,6 % en bas
Si vous prévoyez de réduire les coûts de stockage dans Milvus ou une autre base de données vectorielle en tronquant les dimensions, ce résultat est important.
| Modèle | ρ (dim complète) | ρ (256 dim) | Dégradation |
|---|---|---|---|
| Voyage Multimodal 3.5 | 0.880 | 0.874 | 0.7% |
| Jina Embeddings v4 | 0.833 | 0.828 | 0.6% |
| mxbai-embed-large (335M) | 0.815 | 0.795 | 2.5% |
| nomic-embed-text (137M) | 0.781 | 0.774 | 0.8% |
| OpenAI 3-large | 0.767 | 0.762 | 0.6% |
| Gemini Embedding 2 | 0.683 | 0.689 | -0.8% |
Voyage et Jina v4 sont en tête parce qu’ils ont tous deux été explicitement entraînés avec MRL comme objectif. La compression des dimensions a peu à voir avec la taille du modèle — ce qui compte, c’est de savoir si le modèle a été entraîné pour cela.
Une remarque sur le score de Gemini : le classement MRL reflète la capacité d’un modèle à préserver la qualité après troncature, et non la qualité de sa recherche en dimension complète. La recherche en dimension complète de Gemini est solide — les résultats interlingues et d’informations clés l’ont déjà prouvé. Il n’a simplement pas été optimisé pour la réduction de dimension. Si vous n’avez pas besoin de compression des dimensions, cette métrique ne vous concerne pas.
Quel modèle d’embedding devriez-vous utiliser ?
Aucun modèle ne gagne partout. Voici le tableau de bord complet :
| Modèle | Paramètres | Cross-Modal | Cross-Lingual | Infos clés | MRL ρ |
|---|---|---|---|---|---|
| Gemini Embedding 2 | Non divulgué | 0.928 | 0.997 | 1.000 | 0.668 |
| Voyage Multimodal 3.5 | Non divulgué | 0.900 | 0.982 | 1.000 | 0.880 |
| Jina Embeddings v4 | 3.8B | — | 0.985 | 1.000 | 0.833 |
| Qwen3-VL-2B | 2B | 0.945 | 0.988 | 1.000 | 0.774 |
| OpenAI 3-large | Non divulgué | — | 0.967 | 1.000 | 0.760 |
| Cohere Embed v4 | Non divulgué | — | 0.955 | 1.000 | — |
| Jina CLIP v2 | ~1B | 0.873 | 0.934 | 1.000 | — |
| BGE-M3 | 568M | — | 0.940 | 0.973 | 0.744 |
| mxbai-embed-large | 335M | — | 0.120 | 0.660 | 0.815 |
| nomic-embed-text | 137M | — | 0.154 | 0.633 | 0.780 |
| CLIP ViT-L-14 | 428M | 0.768 | 0.030 | — | — |
"—" signifie que le modèle ne prend pas en charge cette modalité ou cette capacité. CLIP est une référence de 2021 fournie à titre indicatif.
Voici ce qui ressort :
- Intermodal : Qwen3-VL-2B (0,945) premier, Gemini (0,928) deuxième, Voyage (0,900) troisième. Un modèle open-source de 2B a battu toutes les API propriétaires. Le facteur décisif était l’écart de modalité, pas le nombre de paramètres.
- Interlingue : Gemini (0,997) mène — le seul modèle à obtenir un score parfait sur l’alignement au niveau des idiomes. Les 8 meilleurs modèles dépassent tous 0,93. Les modèles légers uniquement en anglais obtiennent un score proche de zéro.
- Informations clés : Les API et les grands modèles open-source obtiennent un score parfait jusqu’à 8K. Les modèles sous 335M commencent à se dégrader à 4K. Gemini est le seul modèle qui gère 32K avec un score parfait.
- Compression dimensionnelle MRL : Voyage (0,880) et Jina v4 (0,833) mènent, perdant moins de 1 % à 256 dimensions. Gemini (0,668) arrive dernier — performant en dimension complète, mais pas optimisé pour la troncature.
Comment choisir : un organigramme décisionnel
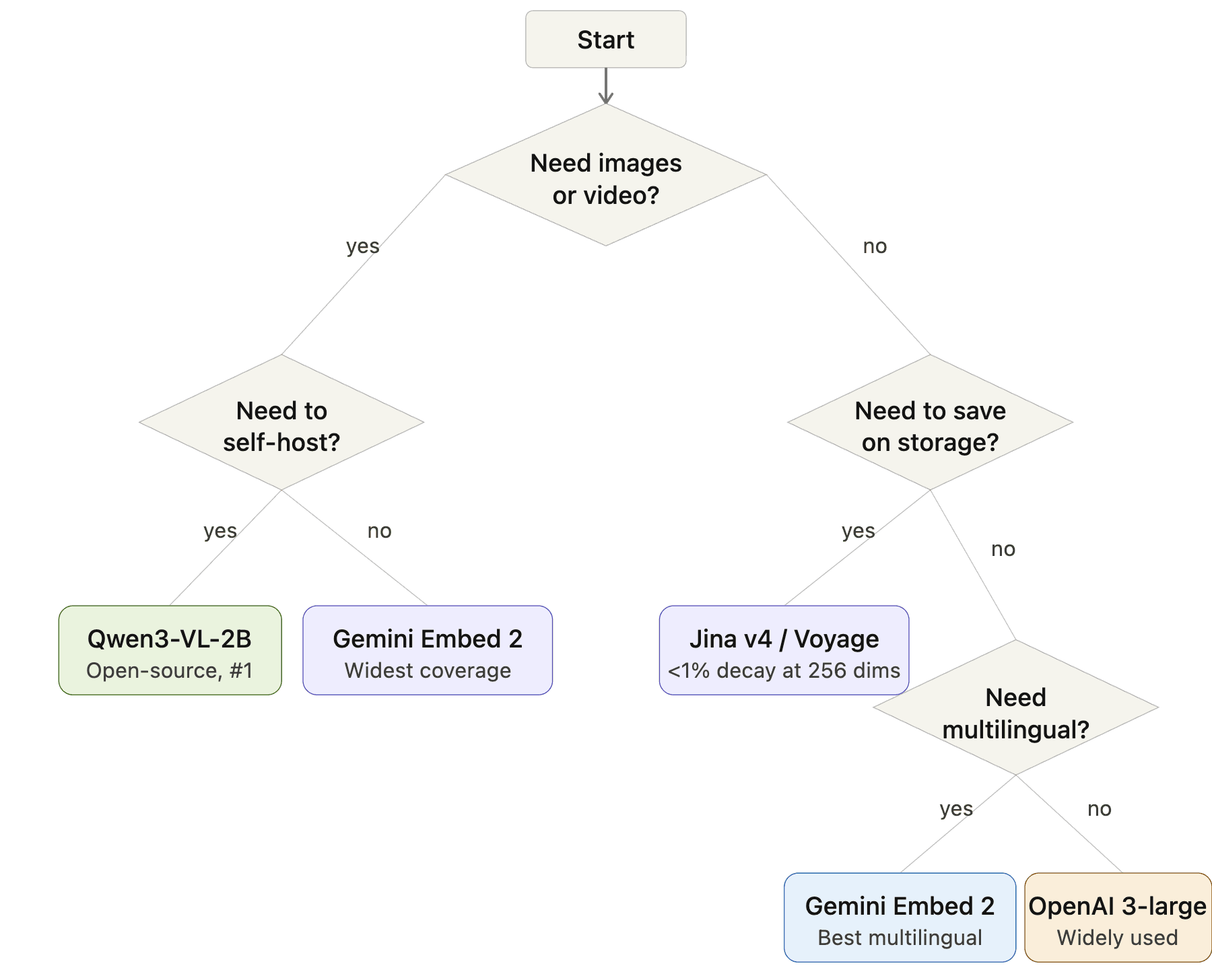 Organigramme de sélection du modèle d’embedding : Départ → Besoin d’images ou de vidéo ? → Oui : Besoin d’auto-héberger ? → Oui : Qwen3-VL-2B, Non : Gemini Embedding 2. Pas d’images → Besoin d’économiser du stockage ? → Oui : Jina v4 ou Voyage, Non : Besoin de multilingue ? → Oui : Gemini Embedding 2, Non : OpenAI 3-large
Organigramme de sélection du modèle d’embedding : Départ → Besoin d’images ou de vidéo ? → Oui : Besoin d’auto-héberger ? → Oui : Qwen3-VL-2B, Non : Gemini Embedding 2. Pas d’images → Besoin d’économiser du stockage ? → Oui : Jina v4 ou Voyage, Non : Besoin de multilingue ? → Oui : Gemini Embedding 2, Non : OpenAI 3-large
Le meilleur modèle généraliste : Gemini Embedding 2
Dans l’ensemble, Gemini Embedding 2 est le modèle globalement le plus solide de ce benchmark.
Points forts : Premier en interlingue (0,997) et en récupération d’informations clés (1,000 sur toutes les longueurs jusqu’à 32K). Deuxième en intermodal (0,928). Couverture de modalités la plus large — cinq modalités (texte, image, vidéo, audio, PDF), là où la plupart des modèles plafonnent à trois.
Faiblesses : Dernier en compression MRL (ρ = 0,668). Dépassé en intermodal par le modèle open-source Qwen3-VL-2B.
Si vous n’avez pas besoin de compression dimensionnelle, Gemini n’a pas de véritable concurrent sur la combinaison interlingue + récupération de documents longs. Mais pour la précision intermodale ou l’optimisation du stockage, des modèles spécialisés font mieux.
Limites
- Nous n’avons pas inclus tous les modèles dignes d’intérêt — NV-Embed-v2 de NVIDIA et v5-text de Jina figuraient sur la liste, mais n’ont pas été retenus pour cette série.
- Nous nous sommes concentrés sur les modalités texte et image ; l’embedding de vidéo, d’audio et de PDF (malgré les revendications de prise en charge de certains modèles) n’a pas été couvert.
- La récupération de code et d’autres scénarios propres à des domaines spécifiques étaient hors périmètre.
- Les tailles d’échantillon étaient relativement faibles, de sorte que les écarts de classement serrés entre les modèles peuvent relever du bruit statistique.
Les résultats de cet article seront obsolètes d’ici un an. De nouveaux modèles sortent constamment, et le classement est rebattu à chaque publication. L’investissement le plus durable consiste à construire votre propre pipeline d’évaluation — définissez vos types de données, vos schémas de requêtes, les longueurs de vos documents, puis soumettez les nouveaux modèles à vos propres tests lorsqu’ils sortent. Les benchmarks publics comme MTEB, MMTEB et MMEB méritent d’être surveillés, mais la décision finale doit toujours venir de vos propres données.
Notre code de benchmark est open-source sur GitHub — forkez-le et adaptez-le à votre cas d’usage.
Une fois votre modèle d’embedding choisi, il vous faut un endroit où stocker et rechercher ces vecteurs à grande échelle. Milvus est la base de données vectorielle open-source la plus largement adoptée au monde, avec 43K+ étoiles GitHub, conçue exactement pour cela — elle prend en charge les dimensions tronquées par MRL, les collections multimodales mixtes, la recherche hybride combinant vecteurs denses et creux, et passe d’un ordinateur portable à des milliards de vecteurs.
- Commencez avec le guide de démarrage rapide de Milvus, ou installez avec
pip install pymilvus. - Rejoignez le Slack Milvus ou le Discord Milvus pour poser des questions sur l’intégration des modèles d’embedding, les stratégies d’indexation vectorielle ou le passage à l’échelle en production.
- Réservez une session gratuite Milvus Office Hours pour passer en revue votre architecture RAG — nous pouvons vous aider avec le choix du modèle, la conception du schéma de collection et l’optimisation des performances.
- Si vous préférez éviter le travail d’infrastructure, Zilliz Cloud (Milvus managé) propose une offre gratuite pour commencer.
Quelques questions qui reviennent lorsque les ingénieurs choisissent un modèle d’embedding pour un RAG en production :
Q : Dois-je utiliser un modèle d’embedding multimodal même si je n’ai que des données textuelles pour le moment ?
Cela dépend de votre feuille de route. Si votre pipeline ajoutera probablement des images, des PDF ou d’autres modalités dans les 6 à 12 prochains mois, commencer avec un modèle multimodal comme Gemini Embedding 2 ou Voyage Multimodal 3.5 évite une migration douloureuse plus tard — vous n’aurez pas besoin de ré-encoder l’ensemble de votre jeu de données. Si vous êtes sûr que cela restera uniquement du texte dans un avenir prévisible, un modèle axé sur le texte comme OpenAI 3-large ou Cohere Embed v4 vous offrira un meilleur rapport prix/performances.
Q : Quelle quantité de stockage la compression de dimension MRL permet-elle réellement d’économiser dans une base de données vectorielle ?
Passer de 3072 dimensions à 256 dimensions représente une réduction de 12x du stockage par vecteur. Pour une collection Milvus avec 100 millions de vecteurs en float32, cela correspond à environ 1,14 To → 95 Go. L’important est que tous les modèles ne gèrent pas bien la troncature — Voyage Multimodal 3.5 et Jina Embeddings v4 perdent moins de 1 % de qualité à 256 dimensions, tandis que d’autres se dégradent de manière significative.
Q : Qwen3-VL-2B est-il vraiment meilleur que Gemini Embedding 2 pour la recherche cross-modale ?
Dans notre benchmark, oui — Qwen3-VL-2B a obtenu 0,945 contre 0,928 pour Gemini sur une récupération cross-modale difficile avec des distracteurs quasi identiques. La raison principale est l’écart de modalité beaucoup plus faible de Qwen (0,25 contre 0,73), ce qui signifie que les embeddings de texte et d’image se regroupent plus près les uns des autres dans l’espace vectoriel. Cela dit, Gemini couvre cinq modalités tandis que Qwen en couvre trois, donc si vous avez besoin d’embedding audio ou PDF, Gemini est la seule option.
Q : Puis-je utiliser ces modèles d’embedding directement avec Milvus ?
Oui. Tous ces modèles produisent des vecteurs float standard, que vous pouvez insérer dans Milvus et rechercher avec la similarité cosinus, la distance L2 ou le produit scalaire. PyMilvus fonctionne avec n’importe quel modèle d’embedding — générez vos vecteurs avec le SDK du modèle, puis stockez-les et recherchez-les dans Milvus. Pour les vecteurs tronqués par MRL, définissez simplement la dimension de la collection sur votre cible (par exemple, 256) lors de la création de la collection.

Continuer à lire

We spent 8 years making vector databases faster. Then we stopped.
Rarely queried embeddings still need to stay searchable. See how Vector Lakebase enables on-demand vector search without always-on compute costs.

How to Build an Enterprise-Ready RAG Pipeline on AWS with Bedrock, Zilliz Cloud, and LangChain
Build production-ready enterprise RAG with AWS Bedrock, Nova models, Zilliz Cloud, and LangChain. Complete tutorial with deployable code.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.