




Comment choisir le bon mode de déploiement de Milvus pour vos applications d'IA ?
Milvus est une base de données vectorielles open-source qui stocke, indexe et récupère des vector embeddings à l'échelle du milliard. Il s'agit également d'un composant indispensable de la génération augmentée de récupération (RAG), une technique populaire et efficace pour atténuer les problèmes d'hallucination dans les grands modèles de langage (LLMs).
Contrairement à d'autres projets de recherche vectorielle open-source tels que Qdrant, Weaviate et Chroma, Milvus offre aux développeurs trois options de déploiement majeures adaptées à différentes tailles d'ensembles de données, de cas d'utilisation et d'exigences commerciales. Si la multiplicité des choix est un avantage, elle peut aussi être un peu écrasante. De nombreux développeurs ne savent pas comment sélectionner le meilleur mode de déploiement pour leurs applications d'IA spécifiques. Dans ce billet de blog, nous fournirons un guide clair et détaillé pour vous aider à choisir la bonne version de Milvus pour vos projets.
Milvus Lite vs. Standalone vs. Distributed
Milvus propose trois options de déploiement : [Milvus Lite, Standalone et Distributed] (https://milvus.io/docs/install-overview.md)**.
Milvus Lite
Milvus Lite est une bibliothèque Python et une version ultra-légère de Milvus. Elle est parfaite pour le prototypage rapide dans les environnements Python ou notebook et pour les expériences locales à petite échelle. Vous pouvez l'installer directement via le paquet pymilvus avec une simple ligne de pip install pymilvus. Il n'est pas nécessaire de faire tourner un serveur séparé, et il gère la persistance des données en utilisant des fichiers locaux, ce qui le rend facile à mettre en place et à utiliser.
Milvus autonome
Milvus Standalone est l'option de déploiement à nœud unique pour Milvus, utilisant un modèle client-serveur. Vous pouvez le considérer comme l'équivalent Milvus de MySQL, tandis que Milvus Lite est comme SQLite. Tous les composants de Milvus Standalone sont regroupés dans une image Docker, ce qui simplifie le déploiement du serveur. L'exécution d'une instance unique de Milvus Standalone sur une machine dotée d'une mémoire suffisante conviendra à la plupart des projets qui ne nécessitent pas une mise à l'échelle importante. En outre, Milvus Standalone offre une haute disponibilité avec un mode de sauvegarde primaire, ce qui en fait un choix fiable pour les environnements de production.
Milvus Distribué
Milvus Distributed est le mode distribué de Milvus, idéal pour les utilisateurs professionnels qui construisent des systèmes de bases de données vectorielles à grande échelle ou des plates-formes de données vectorielles. Il adopte une architecture native dans le nuage avec une séparation lecture-écriture pour optimiser les performances. Les composants clés de Milvus Distributed sont équipés de sauvegardes intégrées et d'instances supplémentaires, de sorte qu'en cas de défaillance d'une partie, les autres peuvent prendre le relais de manière transparente, garantissant ainsi que le système reste ininterrompu. Ce niveau de redondance améliore la fiabilité et garantit une [disponibilité continue] (https://zilliz.com/learn/ensuring-high-availability-of-vector-databases). Parmi les trois options de déploiement, Milvus Distributed offre la scalabilité et la disponibilité les plus élevées. Il offre également une élasticité au niveau des composants, ce qui vous permet de faire évoluer indépendamment le proxy, les nœuds de requête et les nœuds d'index en fonction des exigences de charge spécifiques de votre entreprise.
Le tableau ci-dessous résume et compare les principales fonctionnalités de Milvus Lite, Milvus Standalone et Milvus Distributed.
| Milvus Lite Capacités | Milvus Standalone | Milvus Distributed | Milvus Distributed | SDK | Python |
| SDK | Python | Python, Go, Java, Node.js, C#, RESTful | Python, Go, Java, Node.js, C#, RESTful | ||
| Vecteurs densesVecteurs éparsVecteurs binaires Scalaires booléens Scalaires entiers Scalaires flottants Strings Arrays JSON | Vecteurs denses Vecteurs épars Vecteurs binaires Scalaires booléens Scalaires entiers Scalaires flottants Strings Arrays JSON | Vecteurs denses Vecteurs épars Vecteurs binaires Scalaires booléens Scalaires entiers Scalaires flottants Strings Arrays JSON | Vecteurs denses Vecteurs épars Vecteurs binaires Scalaires booléens Scalaires entiers Scalaires flottants Strings Arrays JSON | Vecteurs épars Vecteurs épars Vecteurs épars | |
| Recherche vectorielle (ANN) Recherche vectorielle filtrée Recherche de plage Recherche hybride Requête d'expression scalaire Requête clé primaire (get) | Recherche vectorielle (ANN) Recherche vectorielle filtrée Recherche de plage Requête d'expression scalaire Requête clé primaire (get) | Recherche vectorielle (ANN) Recherche vectorielle filtrée Requête de plage Requête d'expression scalaire Requête clé primaire (get) | Recherche vectorielle filtrée Requête d'expression scalaire Requête clé primaire (get) | ||
| Recherche vectorielle filtrée Recherche vectorielle hybride Recherche d'expressions hybrides Requête par clé primaire (get) | Capacités CRUD de base | ✔️ | ✔️ | ✔️ | ✔️ |
| RBAC (contrôle d'accès basé sur les rôles) | RBAC (contrôle d'accès basé sur les rôles) Sharding Partition Partition Key Physical resource grouping | ||||
| La cohérence entre les ressources physiques et les ressources matérielles est un facteur déterminant de la cohérence entre les ressources physiques et les ressources matérielles. |
Tableau : Comparaison de Milvus Lite, Milvus Standalone et Milvus Distributed Tableau : Comparaison de Milvus Lite, Milvus Standalone et Milvus Distributed.
Comment sélectionner le bon déploiement de Milvus pour chaque étape du développement
Le choix de l'option de déploiement Milvus appropriée dépend du stade de développement de votre application. Ces étapes comprennent le prototypage rapide, le déploiement de production précoce et le déploiement de production à grande échelle. Examinons chaque étape en détail.
Milvus Lite pour le prototypage rapide d'applications d'IA
Lors du développement et du prototypage d'applications d'IA telles qu'un assistant personnel, un moteur de [recherche sémantique] (https://zilliz.com/glossary/semantic-search) ou un RAG de bout en bout, la vitesse et la flexibilité de l'application sont généralement prioritaires par rapport aux performances et à la stabilité. Milvus Lite est donc un choix idéal à ce stade. Il vous permet de créer rapidement une fonctionnalité de bout en bout dans un environnement de bloc-notes et de mener des expériences légères axées sur le test de l'efficacité.
Transition vers Milvus Standalone pour la validation sur de grands ensembles de données
Milvus Standalone est l'étape logique suivante si vous avez besoin de valider vos résultats sur un grand ensemble de données. Milvus Lite et Standalone sont conçus pour fonctionner ensemble de manière transparente, offrant une transition facile du prototypage local à la validation basée sur le serveur. Comme Milvus Lite, Standalone et Distributed partagent la même interface client, vous pouvez réutiliser la même logique métier pour les validations de données locales et à grande échelle. En outre, Milvus Standalone prend en charge plusieurs utilisateurs, ce qui permet aux équipes de développement agiles de collaborer ou de partager des données à l'aide d'une instance unique.
Milvus Standalone pour un déploiement de production précoce
Aux premiers stades de la production d'applications, lorsque votre projet vient d'être lancé et qu'il est encore en train de trouver sa place sur le marché, les demandes commerciales et les volumes de données sont relativement faibles. L'accent doit être mis sur l'efficacité et la compétitivité de l'entreprise plutôt que sur l'infrastructure. Milvus Standalone est bien adapté à cette phase. Pour les services en ligne, le déploiement de Milvus dans un mode de sauvegarde primaire à haute disponibilité garantit la fiabilité. Pour les environnements de test, un déploiement à un seul nœud est généralement suffisant.
**Remarque : Milvus Standalone n'offre pas d'isolation des ressources physiques entre les tables. Si vous avez deux applications critiques et sensibles aux performances, il est préférable d'isoler leurs données à l'aide d'instances Milvus Standalone distinctes. Bien que cela puisse entraîner une certaine inefficacité des ressources, cela reste plus rentable que de gérer une configuration Milvus Distribuée à ce stade.
Vous pouvez continuer à utiliser Milvus Lite pour des tâches de débogage spécifiques, mais évitez de le faire dans l'environnement de production où Milvus Standalone est déployé, car cela pourrait introduire des risques en termes de performances et de stabilité.
Milvus Distributed pour un déploiement de production à grande échelle
Lorsque vos données dépassent la capacité d'un seul serveur ou se développent rapidement, il est temps de préparer l'évolutivité future. Milvus Distributed devient essentiel à ce stade.
Cette meilleure pratique consiste à exécuter simultanément les instances Milvus Standalone et Milvus Distributed au début et à transférer progressivement le trafic de données de Standalone à Distributed. Veillez à surveiller le système pendant au moins un mois jusqu'à ce que Milvus Distributed fonctionne de manière stable.
Au cours de cette phase, vous devrez également améliorer votre gestion des opérations. Milvus Distribué prend en charge Prometheus en mode natif et propose des outils de gestion tels que [Attu] (https://zilliz.com/attu). Bien que Milvus fournisse une large gamme d'outils opérationnels dédiés et d'[intégrations à l'écosystème] (https://zilliz.com/product/integrations), la gestion d'un grand système distribué peut s'avérer difficile. Nous vous encourageons à rejoindre la communauté Milvus ouverte et active pour demander de l'aide, contribuer au code, assister à des événements et apporter de nombreuses autres contributions précieuses.
Comment choisir le bon déploiement pour vos ensembles de données vectorielles
Milvus est conçu pour s'adapter à votre projet et propose différents modes de déploiement pour répondre à l'évolution des exigences de votre jeu de données. Pour clarifier leurs différences, nous allons comparer Milvus Lite, Standalone et Distributed entre eux et, plus important encore, avec d'autres bases de données vectorielles open-source sur le marché, comme Chroma, Weaviate et Qdrant.
Chroma** a gagné en popularité auprès des développeurs depuis l'année dernière, en particulier pour les projets à petite échelle. Comme Milvus Lite, Chroma est une base de données vectorielle légère. Il convient mieux aux applications qui traitent moins de centaines de milliers de vecteurs. Chroma offre des fonctionnalités de base telles que l'insertion de données vectorielles et la recherche de similarités, ce qui en fait une option légère pour un prototypage rapide. Cependant, son ensemble de fonctionnalités limité et son manque de préparation à la production signifient que même Milvus Lite offre des capacités plus robustes.
Pour les solutions prêtes pour la production, Milvus Standalone et Distributed, ainsi que Weaviate et Qdrant, sont des choix plus solides. Weaviate est réputé pour son intégration avec les applications d'intelligence artificielle, offrant une prise en charge native de divers modèles en amont. Quant à Qdrant, il se concentre sur les fonctionnalités de base des bases de données vectorielles, en mettant l'accent sur les performances de la recherche vectorielle. Toutefois, selon VectorDBBench, un outil d'évaluation comparative des bases de données vectorielles open-source, Milvus surpasse toujours Qdrant en termes de performances de recherche, ce qui en fait un concurrent de premier plan dans ce domaine.
Voici une ventilation des échelles de données appropriées pour chaque base de données vectorielle :
Figure 2- Milvus vs. Chroma vs. Qdrant vs. Weaviate pour le stockage et l'extraction de données vectorielles](https://assets.zilliz.com/Figure_2_Milvus_vs_Chroma_vs_Qdrant_vs_Weaviate_for_vector_storage_and_retrieval_5877bdd81a.png)
Milvus Lite et Chroma** sont idéaux pour la mise à l'échelle des données jusqu'à un million de vecteurs. Ils sont conçus pour être faciles à utiliser, sacrifiant certaines capacités du système pour plus de simplicité.
Milvus Standalone, Weaviate et Qdrant** : Elles sont idéales pour les échelles de données qui vont d'un million à des dizaines de millions de vecteurs. Ces bases de données trouvent un équilibre entre la puissance du système et la facilité d'utilisation, ce qui les rend adaptées aux premières étapes de la production.
Milvus Distributed : Conçue pour gérer des échelles de données de dizaines de millions et plus. La communauté Milvus a validé sa prise en charge des cas d'utilisation à l'échelle du milliard, et elle est maintenant mise en œuvre pour des situations impliquant des dizaines de milliards de vecteurs.
Bien que d'autres bases de données vectorielles comme Chroma, Weaviate et Qdrant aient leurs points forts, elles sont souvent loin d'offrir le même niveau de flexibilité, d'évolutivité et de support à long terme que Milvus. Au fur et à mesure que votre projet se développe, le changement de base de données vectorielles peut devenir coûteux et complexe. Milvus, avec ses options de déploiement polyvalentes, prend en charge des flux de travail mixtes sur différentes échelles de données, garantissant ainsi que votre solution de base de données ne sera pas dépassée.
Milvus Lite, Standalone et Distributed Composants sous-jacents
Milvus offre une expérience utilisateur cohérente et une évolution uniforme dans ses trois modes de déploiement grâce aux composants sous-jacents partagés. Cette conception garantit que vous bénéficiez de la même fonctionnalité de base, que vous utilisiez Milvus Lite pour des tâches légères ou Milvus Distributed pour des opérations à grande échelle.
Le diagramme ci-dessous illustre les composants fonctionnels couverts par chacun des modes de déploiement de Milvus :
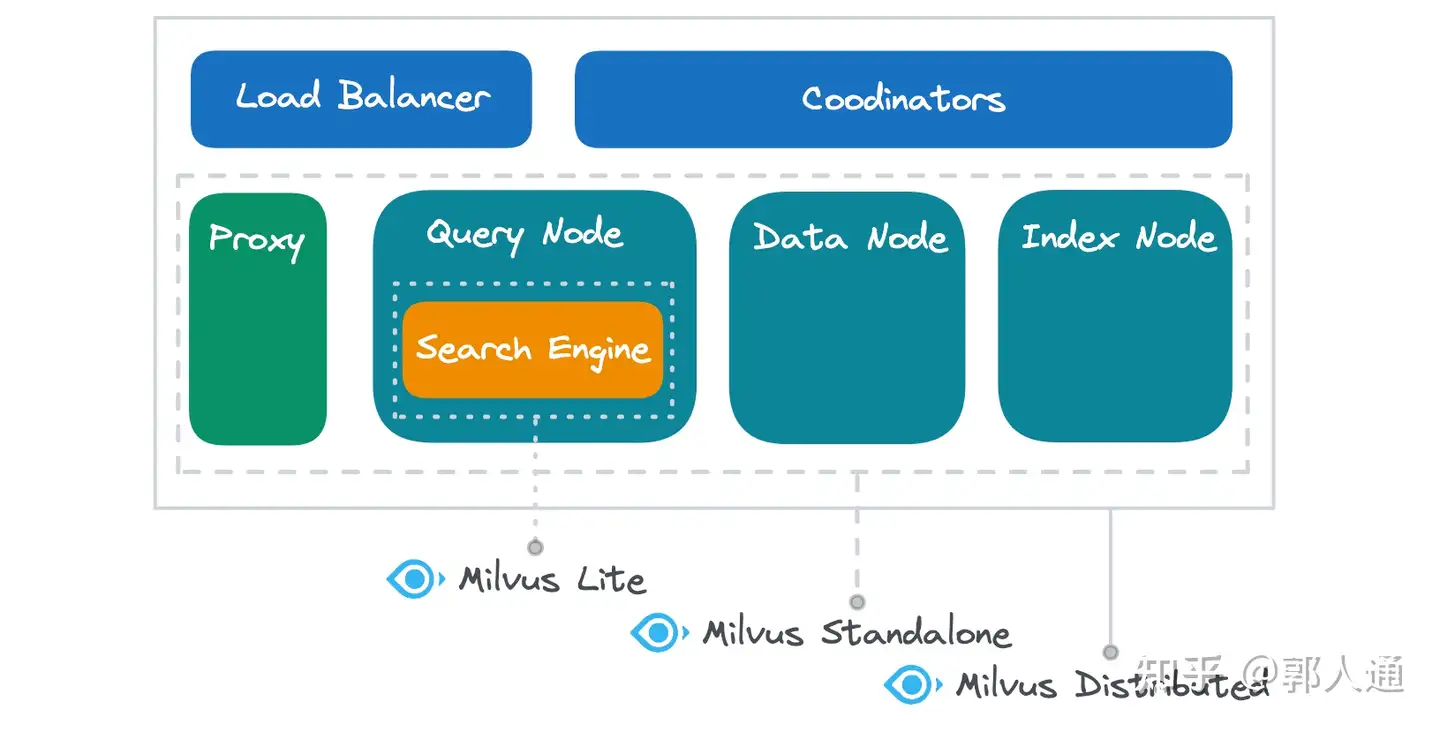 Figure 2- Milvus Lite vs. Standalone vs. Distributed sur les composants sous-jacents
Figure 2- Milvus Lite vs. Standalone vs. Distributed sur les composants sous-jacents
Milvus Lite encapsule principalement le moteur de recherche tout en offrant des implémentations locales pour des tâches essentielles telles que l'insertion de données, la persistance, la construction d'index et la gestion des métadonnées. Considérez Milvus Lite comme une bibliothèque puissante plutôt que comme un simple outil. Comparé à des bibliothèques plus basiques comme Chroma, le moteur de recherche de Milvus Lite offre des performances et des capacités d'interrogation supérieures, ce qui le rend idéal pour les encastrements vectoriels. Si vous recherchez une alternative à FAISS ou HNSWLib, Milvus Lite est un candidat de choix, car elle intègre en natif les principales bibliothèques d'algorithmes vector search et a fait l'objet d'une optimisation poussée en termes de performances et de fonctionnalités.
Milvus Standalone comprend tous les composants fonctionnels du système Milvus, à l'exception de l'équilibrage de charge et de la gestion multi-nœuds (coordinateurs). Ces composants fonctionnent dans le même environnement Docker, ce qui facilite une communication locale efficace et minimise la latence du serveur.
Milvus Distribué dispose d'une gamme complète de composants fonctionnels. Alors que les modes autonome et distribué contiennent tous deux un proxy, un nœud de requête, un nœud de données et un nœud d'index avec des fonctionnalités identiques, Milvus Distributed offre une plus grande flexibilité de déploiement. Chaque composant fonctionnel peut être déployé plusieurs fois pour gérer des charges plus importantes, et plusieurs composants peuvent être déployés sur le même nœud physique pour partager les ressources ou sur des nœuds différents pour assurer l'isolation des ressources. En outre, le mode distribué permet une mise à l'échelle indépendante de chaque composant, ce qui vous permet de vous adapter à des caractéristiques de charge variables et d'améliorer efficacement l'utilisation des ressources.
Résumé
Dans cet article, nous avons exploré les trois options de déploiement offertes par Milvus : Milvus Lite, Standalone et Distributed. Chaque mode de déploiement est conçu pour répondre à différentes étapes de développement, tailles de données et [cas d'utilisation] (https://zilliz.com/vector-database-use-cases), garantissant que Milvus peut s'adapter à votre projet.
Milvus Lite** est idéal pour le prototypage rapide et les expériences à petite échelle dans les environnements Python. Il est facile à configurer et à utiliser, ce qui le rend parfait pour les développeurs qui ont besoin d'une solution légère mais puissante pour les tests et le développement.
Milvus Standalone** est l'étape suivante pour ceux qui sont prêts à passer du prototypage à la production. Cette option de déploiement à nœud unique fournit tous les composants nécessaires aux premiers environnements de production, en équilibrant les performances et l'efficacité des ressources. Elle est bien adaptée aux projets dont la taille des données est modérée et dont les demandes des utilisateurs augmentent.
Milvus Distributed** est conçu pour les déploiements de production à grande échelle qui requièrent une haute disponibilité, une grande évolutivité et une grande flexibilité. C'est le choix par excellence pour les entreprises et les applications traitant des quantités massives de données, garantissant que votre base de données vectorielle peut évoluer avec les besoins de votre entreprise.
Autres ressources

Continuer à lire

What Is a Vector Lakebase?
A Vector Lakebase is a unified, lake-native data architecture for AI that combines vector-database-grade serving with open lake storage, reusable lake-level indexes, and a shared semantic layer.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.

Why Deepseek is Waking up AI Giants Like OpenAI And Why You Should Care
Discover how DeepSeek R1's open-source AI model with superior reasoning capabilities and lower costs is disrupting the AI landscape and challenging tech giants like OpenAI.