




Dimensionality Reduction: Simplificación de datos complejos para facilitar el análisis
**La reducción de la dimensionalidad es un proceso utilizado en la ciencia de datos y el aprendizaje automático para reducir el número de variables, o "dimensiones", en un conjunto de datos, conservando la mayor cantidad de información relevante posible. Esta reducción simplifica el análisis, la visualización y el procesamiento de los datos, especialmente en conjuntos de datos de gran dimensión. Técnicas como el análisis de componentes principales (ACP) y la incrustación estocástica de vecinos distribuida (t-SNE) identifican patrones y relaciones en los datos, proyectándolos en menos dimensiones. Al descartar las características menos significativas, la reducción de la dimensionalidad ayuda a mejorar la eficiencia computacional y mitiga el sobreajuste, por lo que resulta esencial para gestionar datos complejos, sobre todo en campos como el análisis de imágenes y textos.
Dimensionality Reduction: Simplificación de datos complejos para facilitar el análisis
La reducción de la dimensionalidad simplifica un conjunto de datos reduciendo el número de variables de entrada o características y conservando la información importante. Desempeña un papel fundamental en la ciencia de datos y el aprendizaje automático. Facilita el trabajo con grandes conjuntos de datos, mejora el rendimiento de los modelos y ahorra valiosos recursos informáticos.
Imagine que tiene una hoja de cálculo grande y compleja llena de muchas columnas de datos. Si algunas de esas columnas no son útiles o deben aclararse para el análisis, la reducción de la dimensionalidad las recorta para facilitar el reconocimiento de patrones.
La maldición de la dimensionalidad
La maldición de la dimensionalidad se refiere a los problemas que surgen al analizar y organizar datos en espacios de alta dimensión. A medida que aumenta el número de características (o dimensiones), el volumen del espacio se expande tan rápidamente que los datos disponibles se vuelven dispersos. Esta escasez dificulta que los algoritmos encuentren patrones significativos, lo que hace que el análisis de datos sea ineficaz y poco fiable.
Para entender el impacto, imagine que intenta medir la distancia entre puntos en un espacio unidimensional, como una línea recta. Los puntos están lo suficientemente cerca como para poder medirlos fácilmente. Si se amplía a dos dimensiones, como una hoja de papel plana, los puntos se extienden más. Si se amplía a tres dimensiones, como una habitación, los puntos se dispersan aún más. A medida que aumentan las dimensiones, los puntos se separan tanto que parecen casi aislados, y calcular la distancia resulta menos útil. Esto ocurre en los datos de alta dimensión, donde las técnicas habituales de análisis de datos pueden dejar de funcionar eficazmente porque las relaciones entre los puntos de datos se diluyen, como se muestra en la figura.
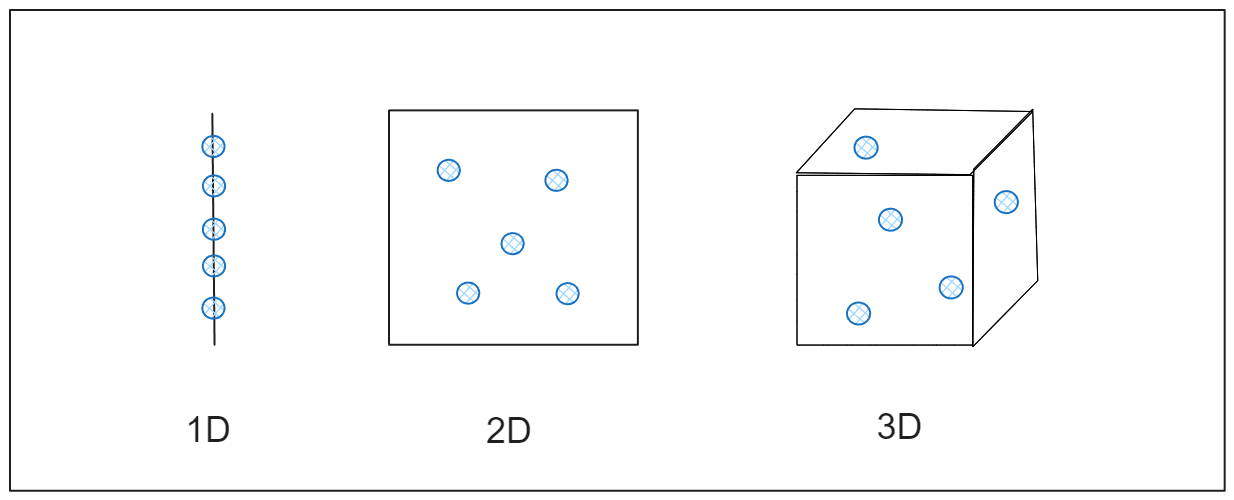 Figura- Cómo se expanden los datos a través de las dimensiones.png
Figura- Cómo se expanden los datos a través de las dimensiones.png
Figura: Cómo se expanden los datos a través de las dimensiones
Una analogía sencilla es encontrar amigos en un parque. Si tú y tus amigos estáis repartidos por un parque pequeño, podéis localizaros rápidamente. Pero imagine que el parque crece hasta alcanzar el tamaño de una gran ciudad. Ahora, incluso con el mismo número de amigos, encontrar a uno se convierte en un reto porque todos están demasiado lejos. Del mismo modo, en espacios de grandes dimensiones, los puntos de datos se dispersan, lo que dificulta a los algoritmos organizarlos o analizarlos con eficacia.
Técnicas clave de reducción de la dimensionalidad
Aunque existen diferentes estrategias para la reducción de la dimensionalidad, pueden clasificarse a grandes rasgos en dos tipos principales: Selección de características y Extracción de características. Ambos métodos pretenden simplificar los datos, pero de formas distintas.
Selección de características
La selección de características reduce la dimensionalidad seleccionando un subconjunto de las características más relevantes del conjunto de datos original. En lugar de transformar los datos, este método mantiene las características tal cual, pero elimina las que no contribuyen significativamente al análisis o al rendimiento del modelo. El objetivo es eliminar las características redundantes o irrelevantes para simplificar y facilitar el trabajo con el conjunto de datos.
Existen tres métodos habituales de selección de características:
Métodos de filtro**: Utilizan pruebas estadísticas para clasificar las características en función de su importancia. Algunos ejemplos son las puntuaciones de correlación, la ganancia de información y las pruebas de chi-cuadrado. Son sencillos y funcionan independientemente del modelo de aprendizaje automático.
Métodos envolventes**: Evalúan diferentes subconjuntos de características y utilizan el rendimiento del modelo para determinar la mejor combinación. Aunque son más precisos, pueden ser costosos desde el punto de vista informático. Técnicas como la eliminación recursiva de características (RFE), la selección hacia delante y la eliminación hacia atrás entran en esta categoría.
Métodos integrados**: Estas técnicas integran la selección de características en el proceso de entrenamiento del modelo. Modelos como los árboles de decisión, la regresión Lasso y la regresión ridge identifican automáticamente las características importantes como parte de su entrenamiento.
Extracción de características
La extracción de características transforma las características originales en un espacio de menor dimensión, creando nuevas características que siguen capturando la información esencial. Este método resulta útil para comprimir los datos sin perder las relaciones significativas entre las características. A diferencia de la selección de características, la extracción de características crea representaciones completamente nuevas de los datos.
Las técnicas más utilizadas son el análisis de componentes principales (PCA), la incrustación estocástica de vecinos distribuida en t (t-SNE) y el análisis discriminante lineal (LDA). Analicémoslas en detalle.
Análisis de componentes principales (PCA)
El análisis de componentes principales (ACP) es una técnica muy utilizada para reducir la dimensionalidad. Su objetivo principal es simplificar un gran conjunto de variables en un conjunto más pequeño que siga capturando la mayor parte de la información de los datos originales.
Para entender el ACP de forma sencilla, piense en un conjunto de datos como un objeto multidimensional, como una nube de puntos en el espacio. El ACP encuentra las direcciones (o ejes) en las que los datos varían más y los proyecta sobre estos nuevos ejes. El primer eje, denominado componente principal, recoge la mayor varianza (o dispersión) de los datos. El segundo eje recoge la siguiente mayor varianza, y así sucesivamente. Al centrarse sólo en los primeros componentes, el ACP reduce el número de dimensiones, manteniendo intacta la estructura principal de los datos.
Los siguientes diagramas muestran cómo funciona el PCA para simplificar los datos. A la izquierda, hay un diagrama de dispersión de puntos repartidos en dos direcciones. PCA encuentra la dirección principal en la que los datos varían más, mostrada por la flecha negra. El lado derecho muestra los datos aplanados a lo largo de esta dirección.
Figura- PCA resalta la dirección principal de la variación de los datos..png](https://assets.zilliz.com/Figure_PCA_highlighting_the_main_direction_of_data_variation_0c1b1ee8ac.png)
Figura: PCA resaltando la dirección principal de la variación de los datos.
De nuevo, a la izquierda, se ven los datos repartidos en dos dimensiones. La flecha negra señala la dirección principal de la variación. A la derecha, los datos se comprimen en esta línea, reduciéndolos a una forma más simple. Este proceso facilita el trabajo con los datos, pero mantiene los patrones principales.
Figura - Representación simplificada de datos con PCA.png](https://assets.zilliz.com/Figure_Simplified_Data_Representation_with_PCA_f7d49bc32b.png)
Figura: Representación simplificada de datos con PCA
**Ventajas de utilizar PCA
Reduce la Complejidad**: La simplificación de conjuntos de datos con muchas variables hace que el análisis sea más rápido y eficiente.
Elimina el ruido**: El ACP filtra el ruido y la información irrelevante manteniendo los componentes con mayor varianza.
Mejora la visualización**: El PCA ayuda a visualizar datos de alta dimensión en dos o tres dimensiones, revelando patrones que de otro modo podrían quedar ocultos.
**Desventajas del uso de PCA
Pérdida de información**: Algunos datos pueden perderse durante la reducción de dimensionalidad, afectando al rendimiento del modelo.
Mayor dificultad de interpretación**: Las nuevas características creadas por PCA son combinaciones de las características originales, lo que dificulta su interpretación significativa.
Supone linealidad**: El ACP funciona mejor cuando las relaciones entre las variables son lineales, lo que no siempre es cierto.
**Aplicaciones prácticas
Compresión de imágenes**: Reduce el tamaño de los archivos de imagen conservando las características visuales clave.
Finanzas**: Simplifica conjuntos de datos complejos para identificar patrones en los movimientos de las cotizaciones bursátiles.
Genética**: Analiza grandes conjuntos de datos genómicos para descubrir estructuras de datos significativas.
Versatilidad**: Útil para simplificar e interpretar datos de alta dimensión en diversos campos.
t-Distributed Stochastic Neighbor Embedding (t-SNE).
t-Distributed Stochastic Neighbor Embedding (t-SNE) visualiza datos de alta dimensión. Proyecta los datos en dos o tres dimensiones para identificar conglomerados y patrones. t-SNE es muy valorado por su capacidad para mantener las relaciones locales entre los puntos de datos, lo que ayuda a revelar la estructura subyacente del conjunto de datos. Este método es más adecuado para conjuntos de datos en el espacio tridimensional.
Figura: izquierda: puntos de datos en 3D, derecha: resultado de la proyección en 2D de PCA.png](https://assets.zilliz.com/Figure_left_swiss_roll_3_D_data_points_right_2_D_projection_result_from_PCA_6f208edc87.png)
Figura: izquierda: puntos de datos 3D del rodillo suizo, derecha: resultado de la proyección 2D del ACP
**Ventajas de utilizar t-SNE
Conservar la estructura local**: t-SNE destaca por mantener los puntos de datos cercanos en el espacio de dimensiones inferiores, lo que lo hace eficaz para visualizar los conglomerados.
Útil para datos complejos**: Es particularmente bueno para manejar relaciones no lineales y explorar patrones intrincados en los datos.
Excelente para la visualización**: t-SNE produce gráficos de dispersión visualmente intuitivos y atractivos que ayudan a comprender la disposición de los datos.
**Desventajas del uso de t-SNE
Uso intensivo de recursos informáticos**: Ejecutar t-SNE puede ser lento y consumir muchos recursos, especialmente para grandes conjuntos de datos.
Requiere ajustar los parámetros**: Parámetros como la perplejidad y la tasa de aprendizaje deben ajustarse cuidadosamente, y los resultados pueden variar significativamente en función de estos ajustes.
Distorsiona la estructura global**: Aunque t-SNE conserva bien las relaciones locales, puede distorsionar la estructura global de los datos y hacerla menos útil para comprender las relaciones a gran escala.
**Aplicaciones prácticas
Visualización de datos de alta dimensión**: Útil para explorar estructuras de conglomerados.
Reconocimiento de imágenes**: Visualiza la distribución de las características de la imagen.
Procesamiento del lenguaje natural (PLN)](https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing): Explora la incrustación de palabras.
Genómica**: Identifica grupos de datos genéticos significativos.
Popularidad**: Ampliamente utilizado por los científicos de datos para obtener información visual a pesar de sus limitaciones.
Análisis discriminante lineal (LDA)
A diferencia del ACP, el objetivo del LDA es maximizar la separación entre las distintas clases de los datos. Para ello, proyecta los datos en un espacio de dimensiones inferiores que separa mejor las categorías en función de sus etiquetas.
El LDA se suele utilizar en situaciones en las que el objetivo principal es la clasificación de datos. Es especialmente útil cuando se trata de conjuntos de datos que tienen límites de clase claros. Algunas aplicaciones prácticas son el reconocimiento facial, el diagnóstico médico y la clasificación de textos.
¿En qué se diferencia el LDA del PCA?
Objetivo**: LDA se centra en maximizar la separabilidad de clases, mientras que PCA pretende capturar la mayor varianza de los datos sin tener en cuenta las etiquetas de clase.
Supervisado vs. No supervisado**: LDA es una técnica supervisada que utiliza etiquetas de clase en sus cálculos. El PCA, en cambio, es no supervisado y no utiliza ninguna información de etiquetas.
Varianza de datos**: El LDA reduce las dimensiones encontrando los ejes que maximizan la distancia entre las medias de las distintas clases y minimizan la dispersión dentro de cada clase. PCA no tiene en cuenta la información de clase y su único objetivo es reducir la redundancia en los datos.
Otras técnicas y métodos emergentes
Además de las técnicas tradicionales de reducción de la dimensionalidad, como PCA, t-SNE y LDA, existen otros métodos y tendencias emergentes que están ganando terreno en el análisis de datos.
Autocodificadores
Los autocodificadores son redes neuronales utilizadas para el aprendizaje no supervisado cuyo objetivo es comprimir los datos en una representación de menor dimensión y luego reconstruirlos a su forma original. La red consta de un codificador que reduce la dimensionalidad y un decodificador que reconstruye la entrada a partir de la representación comprimida. Los autocodificadores son útiles para manejar relaciones no lineales en los datos y pueden aprender representaciones de características complejas.
Análisis de componentes independientes (ICA)
El análisis de componentes independientes (ICA) es una técnica computacional para separar una señal multivariante en componentes aditivos independientes. A diferencia del ACP, que se centra en la varianza, el ICA busca fuentes estadísticamente independientes. Este método se utiliza a menudo en aplicaciones como la separación ciega de fuentes, por ejemplo para aislar distintas fuentes de audio de una grabación mezclada.
Aproximación y Proyección de Múltiples Uniformes (UMAP)
Uniform Manifold Approximation and Projection (UMAP) es una técnica relativamente nueva de reducción de la dimensionalidad que preserva las estructuras locales y globales de los datos. Se basa en el aprendizaje de múltiples y su objetivo es mantener las relaciones entre los puntos de datos durante el proceso de reducción. UMAP es más rápida y a menudo produce mejores visualizaciones en comparación con t-SNE.
Ventajas de la reducción de la dimensionalidad
La reducción de la dimensionalidad ofrece varias ventajas clave que mejoran el análisis de conjuntos de datos complejos:
Modelos simplificados**: Un menor número de características conduce a modelos más sencillos que son más fáciles de entrenar y analizar, lo que puede ser crucial para aplicaciones sensibles al tiempo.
Reduce los requisitos de almacenamiento y computación**: El manejo de datos de menor dimensión se traduce en menos almacenamiento y tiempos de procesamiento más rápidos, lo que puede reducir los costes operativos, especialmente con grandes conjuntos de datos.
Mejora el rendimiento de los modelos**: Al considerar las características más significativas, los modelos pueden ser más precisos y robustos, ya que es menos probable que se vean afectados por datos irrelevantes.
Mejora la interpretabilidad**: Reducir las dimensiones puede ayudar a resaltar las relaciones esenciales en los datos que ayudan a las partes interesadas a comprender las decisiones del modelo y los patrones subyacentes.
Facilita la visualización de los datos: La transformación de datos de alta dimensión en dos o tres dimensiones permite representaciones visuales más claras, ayudando a descubrir ideas que pueden no ser evidentes en dimensiones más altas.
Ayuda a reducir el ruido**: Al eliminar las dimensiones menos importantes, la reducción de la dimensionalidad puede disminuir la cantidad de ruido, lo que resulta en conjuntos de datos más limpios que contribuyen a análisis más fiables.
Ayuda a mejorar la ingeniería de características**: El proceso puede ayudar a identificar las características más impactantes, proporcionando oportunidades para crear características mejoradas que pueden conducir a un mejor rendimiento del modelo.
Permite una creación de prototipos más rápida**: Con menos dimensiones a tener en cuenta, los científicos de datos pueden iterar rápidamente en el desarrollo de modelos para probarlos y perfeccionarlos con rapidez.
Desafíos de la reducción de la dimensionalidad
Las técnicas de reducción de la dimensionalidad plantean varios retos que hay que tener muy en cuenta:
Riesgo de perder información importante**: La reducción de dimensiones puede descartar inadvertidamente características esenciales, lo que puede afectar negativamente al rendimiento del modelo y llevar a una interpretación errónea de los resultados.
Elección de la técnica adecuada**: La eficacia de los métodos de reducción de la dimensionalidad varía en función de la naturaleza del conjunto de datos y de los objetivos analíticos específicos. Esta variabilidad hace que sea crucial comprender los puntos fuertes y las limitaciones de cada técnica para evitar resultados ineficaces.
Coste computacional**: Técnicas como t-SNE pueden consumir muchos recursos y ser menos viables para grandes conjuntos de datos. Los requisitos de tiempo y memoria pueden limitar considerablemente su aplicabilidad en situaciones en las que el tiempo es un factor importante.
Equilibrio entre reducción y precisión**: Conseguir el nivel adecuado de reducción de la dimensionalidad al tiempo que se garantiza que el modelo conserva suficiente información para realizar predicciones precisas es un reto constante. Una reducción excesiva puede simplificar demasiado los datos y mermar la capacidad del modelo para captar la complejidad necesaria.
Aplicaciones de la reducción de la dimensionalidad en diversas industrias
Las técnicas de reducción de la dimensionalidad encuentran aplicaciones en diversos campos, mejorando el análisis de datos y el rendimiento de los modelos. A continuación se describen algunas situaciones prácticas en las que suelen utilizarse estos métodos:
Procesamiento de imágenes**: En campos como la visión por ordenador, la reducción de la dimensionalidad ayuda a comprimir los datos de las imágenes conservando sus características esenciales. Por ejemplo, en el reconocimiento facial, PCA puede reducir miles de valores de píxeles a características más pequeñas, acelerando el procesamiento sin perder detalles críticos. Del mismo modo, en el campo de la imagen médica, la reducción de la dimensionalidad resalta las áreas importantes en las resonancias magnéticas para agilizar el análisis.
Procesamiento del lenguaje natural**: La reducción de la dimensionalidad se utiliza para simplificar los datos de texto de alta dimensión, como las incrustaciones de palabras. Métodos como t-SNE ayudan a visualizar las relaciones entre palabras y los clusters, facilitando el análisis de sentimientos y el modelado de temas.
Genómica**: En bioinformática, las técnicas de reducción de la dimensionalidad son esenciales para analizar datos genéticos, en los que el número de variables (genes) puede ser muy elevado. La reducción de dimensiones ayuda a identificar marcadores genéticos clave relacionados con enfermedades.
Finanzas**: La reducción de la dimensionalidad ayuda en la gestión de riesgos y la optimización de carteras simplificando grandes conjuntos de datos de indicadores financieros. Los analistas pueden elegir las características más relevantes que influyen en el comportamiento del mercado.
Sistemas de recomendación**](https://zilliz.com/learn/Introduction-to-Recommendation-systems): En el filtrado colaborativo y basado en el contenido, la reducción de la dimensionalidad ayuda a crear algoritmos de recomendación más eficaces identificando patrones subyacentes en las preferencias de los usuarios y las características de los artículos.
Atención sanitaria**: El análisis de datos de pacientes suele implicar conjuntos de datos de gran dimensión. La reducción de la dimensionalidad ayuda a identificar factores significativos que afectan a los resultados de los pacientes, mejorando los modelos de predicción de la progresión de la enfermedad.
Análisis de marketing**: En marketing, comprender el comportamiento de los clientes es crucial. La reducción de la dimensionalidad permite a las empresas segmentar fácilmente a los clientes reduciendo la complejidad de sus datos, lo que conduce a estrategias de marketing específicas.
Fabricación y control de calidad**: En las aplicaciones industriales, la reducción de la dimensionalidad ayuda a analizar los datos de los sensores de las máquinas para identificar patrones y anomalías, lo que permite mejorar el control de calidad y el mantenimiento predictivo.
¿Cómo mejora la reducción de la dimensionalidad el rendimiento de las bases de datos vectoriales?
La reducción de la dimensionalidad mejora significativamente el rendimiento de las bases de datos vectoriales como Milvus (creada por los ingenieros de Zilliz), que está diseñada para gestionar datos no estructurados a gran escala y sus representaciones vectoriales de alta dimensión. He aquí cómo están interconectados:
Almacenamiento eficaz de datos: Milvus puede almacenar datos vectoriales de alta dimensión generados por modelos de aprendizaje automático. La aplicación de técnicas de reducción de la dimensionalidad, como PCA o t-SNE, ayuda a comprimir estos vectores, reduciendo los requisitos de almacenamiento y mejorando la velocidad de recuperación.
Mejora del rendimiento de las consultas**: En una base de datos vectorial, la búsqueda en datos de alta dimensionalidad puede requerir un gran esfuerzo informático. La reducción de la dimensionalidad minimiza la dimensionalidad de los vectores, lo que acelera las búsquedas de similitud y las consultas del vecino más cercano.
Visualización de datos mejorada**: Al utilizar Zilliz o Milvus para el análisis de datos, las técnicas de reducción de la dimensionalidad pueden facilitar la visualización de conjuntos de datos complejos. Esto permite a los usuarios comprender mejor las distribuciones de datos, las relaciones y los patrones dentro de los datos de alta dimensionalidad almacenados en la base de datos.
Facilitar los flujos de trabajo de aprendizaje automático**: En los procesos de aprendizaje automático, la reducción de la dimensionalidad puede ayudar a agilizar el preprocesamiento de datos. La reducción de la complejidad de las características de entrada mejora el entrenamiento de los modelos de aprendizaje automático, lo que se traduce en una mejora del rendimiento y la interpretabilidad.
Conclusión
La reducción de la dimensionalidad es una técnica importante en la ciencia de datos y el aprendizaje automático que simplifica conjuntos de datos complejos preservando la información esencial. La reducción del número de características mejora el rendimiento del modelo, facilita la visualización y facilita el análisis de datos en diversos campos. A pesar de sus dificultades, como el riesgo de perder información importante y la necesidad de seleccionar cuidadosamente la técnica, los beneficios de la reducción de la dimensionalidad la hacen inestimable para descubrir ideas y mejorar la eficiencia de los procesos analíticos.
Preguntas frecuentes sobre la reducción de la dimensionalidad
- ¿Qué es la reducción de la dimensionalidad?
La reducción de la dimensionalidad es una técnica que se utiliza para reducir el número de características o dimensiones de un conjunto de datos conservando toda la información relevante posible. Esta simplificación facilita el análisis, la visualización y el modelado de datos complejos.
- ¿Por qué es importante la reducción dimensional en la ciencia de datos?
Ayuda a mejorar el rendimiento de los modelos, reduce los requisitos de almacenamiento y computación, mejora la visualización de los datos y simplifica la interpretación de los modelos, por lo que resulta esencial para un análisis eficaz de los datos en diversas aplicaciones.
- ¿Cuáles son algunas de las técnicas más comunes para la reducción de la dimensionalidad?
Entre las técnicas más comunes se encuentran el análisis de componentes principales (PCA), la incrustación estocástica de vecinos distribuida en t (t-SNE), el análisis discriminante lineal (LDA), los métodos de selección de características y técnicas emergentes como los autoencoders y los UMAP.
- ¿Cuáles son los retos asociados a la reducción de la dimensionalidad?
Entre los retos cabe citar el riesgo de perder información importante, la dificultad de elegir la técnica adecuada para conjuntos de datos específicos, los costes computacionales de determinados métodos y el equilibrio entre la reducción de la dimensionalidad y la precisión del modelo.
- ¿Cómo beneficia la reducción de la dimensionalidad a las bases de datos vectoriales como Milvus?
La reducción de la dimensionalidad mejora el rendimiento de las bases de datos vectoriales optimizando el almacenamiento de los datos, mejorando el rendimiento de las consultas, facilitando la visualización de los datos y agilizando los flujos de trabajo del aprendizaje automático.
Recursos relacionados
Técnicas avanzadas de consulta en bases de datos vectoriales](https://zilliz.com/learn/advanced-querying-techniques-in-vector-databases)
Racionalización de datos: estrategias eficaces para reducir la dimensionalidad](https://zilliz.com/learn/streamlining-data-strategies-for-reducing-dimensionality)
La maldición de la dimensionalidad en el aprendizaje automático](https://zilliz.com/glossary/curse-of-dimensionality-in-machine-learning)
Batch vs. Layer Normalization - Unlocking Efficiency in Neural Networks](https://zilliz.com/learn/layer-vs-batch-normalization-unlocking-efficiency-in-neural-networks)
Qué es Milvus](https://zilliz.com/what-is-milvus)
- La maldición de la dimensionalidad
- Técnicas clave de reducción de la dimensionalidad
- Otras técnicas y métodos emergentes
- Ventajas de la reducción de la dimensionalidad
- Desafíos de la reducción de la dimensionalidad
- Aplicaciones de la reducción de la dimensionalidad en diversas industrias
- ¿Cómo mejora la reducción de la dimensionalidad el rendimiento de las bases de datos vectoriales?
- Conclusión
- Preguntas frecuentes sobre la reducción de la dimensionalidad
- Recursos relacionados
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis