




Von der Extraktion zu Erkenntnissen: ETL verstehen

Von der Extraktion zu Erkenntnissen: ETL verstehen
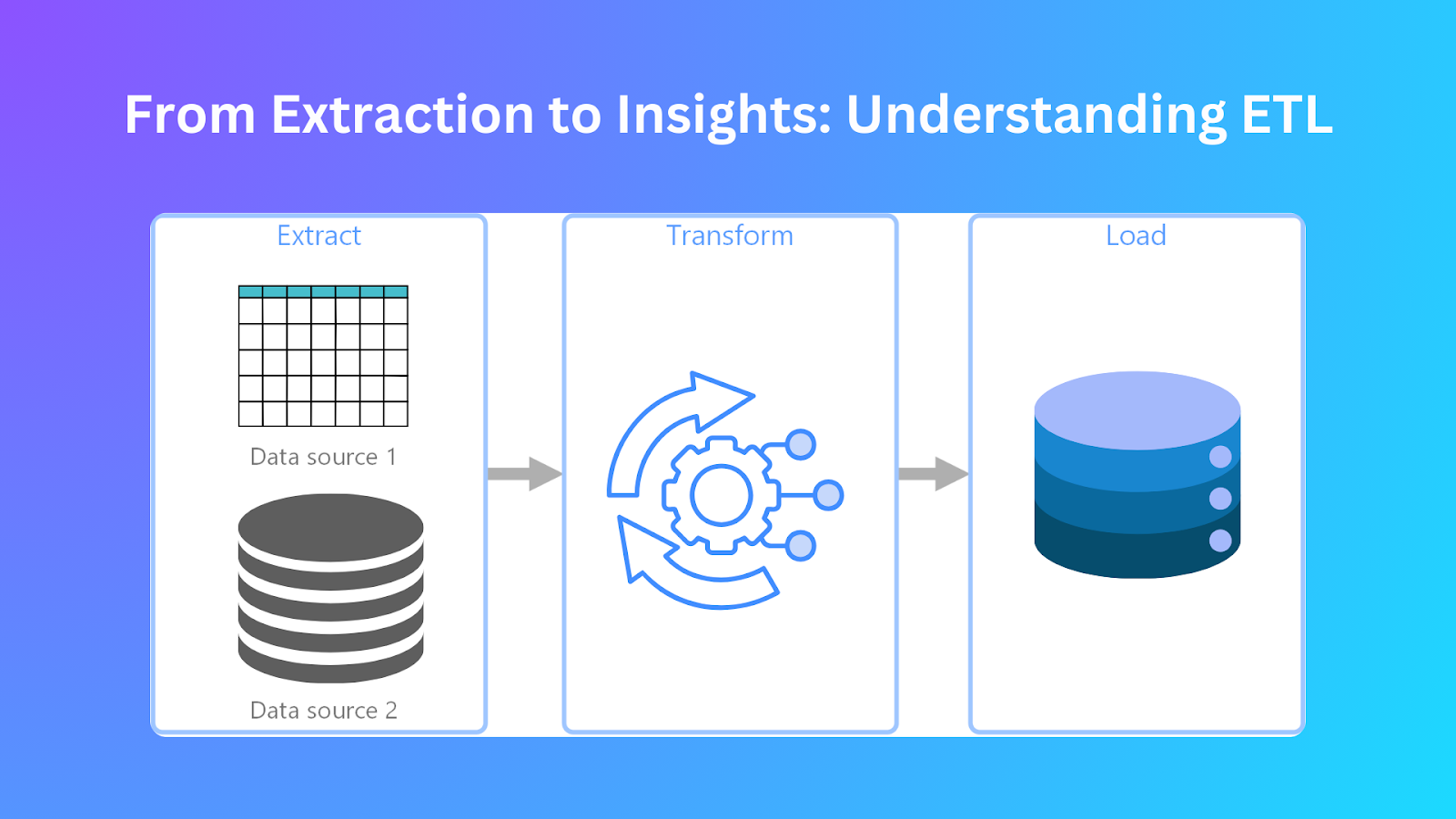 ETL-Pipeline.png
ETL-Pipeline.png
Wie wandeln Unternehmen riesige Rohdaten Datensätze in aussagekräftige Erkenntnisse um? Welche Schritte unternehmen Unternehmen, um Daten vor der Analyse zu integrieren und zu verfeinern? Die Antwort liegt in Extrahieren, Transformieren und Laden (ETL).
ETL ist der Schlüssel zum modernen Datenmanagement. Es ermöglicht Unternehmen, Daten zu sammeln, zu verarbeiten und für die Analyse zu laden. ETL extrahiert Informationen aus verschiedenen Ressourcen, modifiziert sie, um Fehler zu beseitigen, und speichert sie dann in einer zentralen Datenbank. Dieser Prozess ermöglicht verfeinerte, genaue und organisierte Informationen, die die Entscheidungsfindung im Unternehmen unterstützen.
Daten ohne ETL sind aufgrund ihrer verstreuten und verzerrten Natur schwer zu analysieren. Ineffiziente Daten können zu Fehlern führen, die sich auf verschiedene Aspekte wie Kundenbeziehungen oder die betriebliche Leistung auswirken. ETL behebt schlechte Datenqualität durch die Automatisierung von Arbeitsabläufen und die Wahrung der Datenintegrität. Dies hilft dem Unternehmen, die Berichterstattung zu rationalisieren, die Analyse zu verbessern und die Entscheidungsfindung zu optimieren.
Da Unternehmen alles datengesteuert machen, ist das Verständnis von ETL von entscheidender Bedeutung. Ganz gleich, ob Sie mit strukturierten [Datenbanken] (https://docs.zilliz.com/docs/database), Cloud-Systemen oder Echtzeit-Analysen arbeiten, ETL garantiert die Integration und Verarbeitung von Qualitätsdaten.
In diesem Beitrag wird erörtert, wie ETL funktioniert, welche Auswirkungen es hat und wie ein Unternehmen es optimal nutzen kann. Außerdem werden wir die besten Tools vorstellen, die Sie verwenden können, um Ihren ETL-Prozess reibungsloser zu gestalten.
Was ist ETL (Extrahieren, Transformieren und Laden)?
ETL ist der zentrale Datenverwaltungs- und Integrationsprozess. Er beginnt mit der Extraktion von Daten aus verschiedenen Quellen, bevor sie in ein geeignetes Format umgewandelt werden, um sie in Zielsysteme wie Data Warehouses oder Data Lakes zu laden. Unternehmen erreichen eine Datenkonsolidierung, indem sie getrennte Datenquellen zur Unterstützung von Analysen in einem einzigen Repository zusammenführen.
ETL ist das Rückgrat für die Wahrung der Datenkonsistenz, -qualität und -zugänglichkeit unabhängig von System- oder Plattformunterschieden. Dieser Ansatz eignet sich für zahlreiche Branchen, darunter das Finanzwesen, das Gesundheitswesen und der elektronische Handel.
Unternehmen nutzen diese Methode, um ihre Daten zu organisieren und Inkonsistenzen zu beseitigen, was die Entscheidungsfähigkeit verbessert. Moderne ETL-Tools können sowohl strukturierte als auch unstrukturierte Daten effizient verarbeiten.
Ein gut durchdachtes ETL-Pipeline-System ermöglicht es Unternehmen, Trends zu analysieren und neue Erkenntnisse zu gewinnen. Der automatisierte Arbeitsablauf steigert die betriebliche Effizienz durch Automatisierung der Datenverarbeitung. Unternehmen nutzen ETL, um eine einheitliche Ansicht zu erstellen, die eine genaue Berichterstattung und strategische Planung unterstützt.
Wie funktioniert ETL?
Die Datenverarbeitung durch ETL folgt einem dreistufigen Prozess, der in jeder Phase Genauigkeit und Effizienz gewährleistet. Diese Stufen sind:
Extraktion
Die ETL-Pipeline beginnt mit der Datenextraktion als erster Stufe. In dieser Phase werden Daten aus verschiedenen Quellen gesammelt, bevor sie zu Verarbeitungszwecken zusammengeführt werden. Durch den Extraktionsprozess erhalten Unternehmen vollständige Datensätze aus ihren verschiedenen Systemen, zu denen Datenbanken, Flat Files, Cloud-Speicher und APIs gehören. Hier sind einige der Schritte in der Datenextraktionsphase:
Identifizierung der Datenquelle: Im ersten Schritt der Extraktion wird ermittelt, wo sich die Daten befinden. Die Daten können aus relationalen Datenbanken wie MySQL und PostgreSQL, aus NoSQL-Datenbanken wie MongoDB und Cassandra, aus APIs von Drittanbietern, aus CSV- oder [JSON]-Dateien(https://docs.zilliz.com/docs/data-import-json) und aus Streaming-Datenplattformen stammen. Der Aufbau einer effektiven ETL-Pipeline erfordert die richtige Identifizierung geeigneter Datenquellen.
Datenabruf: Die Datenabrufmethoden hängen von den Geschäftsanforderungen und den verfügbaren Systemfunktionen ab. Die Daten können auf zwei Arten abgerufen werden: entweder vollständig oder inkrementell. Bei der vollständigen Extraktion werden alle Daten aus den Quellen gesammelt, während bei der inkrementellen Extraktion nur die Änderungen seit der letzten Extraktion erfasst werden. Die inkrementelle Extraktion wird bevorzugt, weil sie die Verarbeitungsdauer verkürzt und die Belastung der Quellsysteme verringert.
Behandlung von Datendiskrepanzen: Die extrahierten Daten können leere Felder, inkonsistente Datentypen und Strukturformate enthalten. Unternehmen sollten vor Beginn der Transformationsphase Vorverarbeitungsprüfungen durchführen, um Inkonsistenzen zu erkennen und zu behandeln.
Transformation
Nach der Extraktion müssen die Daten transformiert werden, um die Kompatibilität mit dem Schema des Zielsystems zu gewährleisten und Geschäftsregeln anzuwenden. Dieser Transformationsprozess führt zu einer verbesserten Datenqualität, konsistenten Daten und erhöhter Benutzerfreundlichkeit. Hier sind einige der Möglichkeiten zur Transformation Ihrer Daten:
Datenbereinigung: Dies ist eines der grundlegenden Transformationsverfahren. Sie erfordert das Entfernen von Duplikaten, die Imputation von Werten für fehlende Daten und die Standardisierung von Namenskonventionen. Dies trägt dazu bei, Berichte zu erstellen, die sowohl präzise als auch fehlerfrei sind.
Datenintegration: Die Daten stammen aus mehreren Quellen, die unterschiedliche Datenstrukturen enthalten. Durch die Datenintegration wird aus verschiedenen separaten Datensätzen eine einzige kohärente Datenansicht erstellt. Der Prozess umfasst die Zuordnung verschiedener Spaltennamen, den Abgleich von Zeitzonenunterschieden und die Gewährleistung der referentiellen Integrität.
Datenaggregation: Sie hilft, Daten für eine effiziente Analyse zusammenzufassen. Unternehmen benötigen häufig Berichte, die regionale Umsatzsummen, durchschnittliche Kundenausgaben pro Quartal und monatliche Umsatzmuster enthalten. Der Aggregationsprozess ermöglicht schnellere Datenabfragen und vereinfacht die Interpretation der Daten.
Datenkonvertierung: Mehrere Datentypen müssen konvertiert werden, damit sie mit dem gewünschten System kompatibel sind. Die Standardisierung der Datenformate ist von entscheidender Bedeutung, während die Normalisierung von Textfeldern und die Umwandlung von Einheiten für numerische Daten den Prozess vervollständigen. Der Datenumwandlungsprozess stellt sicher, dass alle geladenen Daten genau mit den analytischen Anforderungen übereinstimmen.
Anwendung von Geschäftsregeln: Unternehmen erstellen in der Regel Geschäftsregeln für Datenumwandlungsprozesse. Ein Finanzinstitut verwendet Transaktionsschwellenwerte, um Kategorien zu entwickeln, und [E-Commerce]-Unternehmen (https://zilliz.com/customers/ecommerce-saas) teilen ihre Kunden auf der Grundlage ihrer Kaufaktivitäten in Segmente ein. Die definierten Regeln schaffen Wert, indem sie unverarbeitete Daten in funktionale Kategorien einteilen.
Laden
Die transformierten Daten müssen in ein Zielsystem geladen werden, bei dem es sich um ein Data Warehouse, einen Data Lake oder eine analytische Datenbank handeln kann. Durch den Ladevorgang wird die Ebene festgelegt, auf der die Daten effizient abgefragt und analysiert werden können.
Laden in das Zielsystem: Bei vollständigen Ladevorgängen erhält das Zielsystem alle Daten in einem Arbeitsgang. Diese Methode wird vor allem bei der ersten Datenmigration oder bei der Bearbeitung kleinerer Datenbestände eingesetzt. Eine andere Möglichkeit besteht darin, nur neue Datensätze und Aktualisierungen aus dem Quellsystem zu laden. Diese Methode verkürzt die Verarbeitungsdauer und macht die Vorgänge effizienter.
Indizierung und Partitionierung: Datenindizierungsmethoden und Partitionierungstechniken beschleunigen die Leistung des Systems bei der Datensuche. Partitionierungstechniken teilen Datensammlungen in kleinere Segmente auf, was die Abfrageleistung verbessert und die Daten besser verwaltbar macht.
Unternehmen legen Backup-Strategien fest, um ihre Daten vor Verlusten bei Systemausfällen zu schützen. Mit dieser Methode wird der Datenschutz aufrechterhalten und die Datenverfügbarkeit zu jeder Zeit gewährleistet.
Vergleich: ETL vs. ELT
Die Datenintegration stützt sich auf ETL (Extract, Transform, Load) und ELT (Extract, Load, Transform) als primäre Methoden zur Übertragung von Daten aus verschiedenen Quellen in Data Warehouses oder Data Lakes. Die beiden Methoden haben das gleiche Ziel: einen effizienten Datentransfer. Bei der Verarbeitung und Anpassung an moderne Datensysteme funktionieren sie jedoch unterschiedlich. Hier ist der Vergleich zwischen ihnen:
| Aspekt | ETL | ELT |
| Prozessreihenfolge | Extrahieren -> Transformieren -> Laden | Extrahieren -> Laden -> Transformieren |
| Transformation | Transformation erfolgt vor dem Laden in das Zielsystem | Transformation erfolgt nach dem Laden in das Zielsystem |
| Datenspeicherung | Daten werden während der Transformation in einem temporären Staging-Bereich gespeichert | Daten werden im Zielsystem gespeichert, und die Transformation erfolgt vor Ort |
| Datenverarbeitung | Daten werden in Stapeln verarbeitet, und die Verarbeitung erfolgt in der Regel linear | Daten werden in Echtzeit oder nahezu in Echtzeit verarbeitet, und die Verarbeitung kann parallel erfolgen |
| Skalierbarkeit | Weniger skalierbar aufgrund der Notwendigkeit eines Bereitstellungsbereichs und der Stapelverarbeitung | Besser skalierbar aufgrund der Möglichkeit, Daten in Echtzeit und parallel zu verarbeiten |
| Kosten | Kann aufgrund der Notwendigkeit eines Bereitstellungsbereichs und der Stapelverarbeitung kostspieliger sein | Kann aufgrund der Fähigkeit, Daten in Echtzeit und parallel zu verarbeiten, weniger kostspielig sein |
| Flexibilität | Weniger flexibel durch die starre Prozessreihenfolge | Flexibler durch die Möglichkeit, jederzeit Transformationen durchzuführen |
| Anwendungsfälle | Geeignet für Stapelverarbeitung, Data Warehousing und Business Intelligence | Geeignet für Echtzeit-Analysen, Datenintegration und Big Data-Verarbeitung |
RTL vs. ELT | Quelle
Vorteile und Herausforderungen
ETL unterstützt zwar das Extrahieren, Transformieren und Laden von Daten, hat aber auch Vorteile und Herausforderungen. Werfen wir einen Blick auf diese:
Vorteile
Datenverfolgung: ETL-Prozesse verfolgen die Datenbewegung von den Quellen zu den Zielen. Zu ihren Hauptfunktionen gehören die Identifizierung von Fehlern, die Aufrechterhaltung der Integrität und die Sicherstellung der Einhaltung der Genauigkeit.
Historische Datenerhaltung: Der ETL-Prozess erfasst Momentaufnahmen der Daten auf ihrem Weg und ermöglicht es Unternehmen, historische Informationen zu erhalten, die für Trendanalysen und Berichte erforderlich sind. Unternehmen können Daten nachverfolgen, während sie Vergleiche anstellen, um ihren Entscheidungsprozess zu unterstützen.
Komplexe Datentransformation: ETL-Tools eignen sich hervorragend für die Ausführung komplexer Datentransformationen, einschließlich Aggregationsprozessen, Datentypkonvertierungen und der Implementierung von Geschäftslogik. Die Funktionen des Systems erleichtern die Datenbereinigung, indem sie strukturierte und standardisierte Informationen erzeugen, bevor das Zielsystem sie erhält.
Datenanreicherung: Der Prozess der Datenanreicherung im Rahmen von ETL ermöglicht es Unternehmen, Informationen aus verschiedenen externen Datenbanken zu kombinieren und so die Qualität und Vollständigkeit von Datensätzen zu verbessern. Die Einbeziehung von Kontextinformationen durch Anreicherung erhöht den analytischen Einblick, indem den Daten ein Mehrwert für die Entscheidungsfindung hinzugefügt wird.
Effiziente Stapelverarbeitung: ETL-Workflows erreichen maximale Effizienz durch Batch-Verarbeitung, die große Datenmengen während geplanter Schwachlastzeiten verarbeitet. Der Prozess minimiert die Auswirkungen auf die Systemleistung während der regulären Geschäftszeiten und verwaltet gleichzeitig effizient große Datensätze.
Herausforderungen
Einschränkungen der Echtzeit-Integration: Herkömmliche ETL-Prozesse integrieren Daten in geplanten Stapeln, wodurch Echtzeitdatenanforderungen eingeschränkt werden. Unternehmen, die sofortige Analyse- und Entscheidungsfindungsfunktionen benötigen, stoßen aufgrund der mit herkömmlichen ETL-Prozessen verbundenen Verzögerungen auf Herausforderungen.
Ressourcenintensive Operationen: Die Rechenanforderungen für ETL-Workloads werden besonders anspruchsvoll, wenn Datenumwandlungs- und Ladeprozesse stattfinden. Die hohe Auslastung von CPU und Speicherressourcen verringert die Geschwindigkeit der Systemoperationen und beeinträchtigt somit die Leistung.
Komplexität der Fehlerbehandlung: Das Fehlermanagement wird schwierig, da ETL-Pipelines mit zahlreichen Datenquellen und komplizierten Transformationsregeln umgehen müssen. Robuste Überwachungswerkzeuge und Debugging-Systeme sind erforderlich, um Inkonsistenzen zu erkennen, fehlende Daten zu verarbeiten und die Qualität zu verwalten.
Skalierbarkeitsbeschränkungen: Das wachsende Datenvolumen stellt eine Herausforderung für die Skalierbarkeit dar, so dass ETL-Prozesse entweder neue Investitionen in die Infrastruktur erfordern oder neu gestaltete Architekturen einsetzen müssen. Wenn die Datenoptimierung unzureichend ist, kann das wachsende Datenvolumen zu Verarbeitungsverzögerungen und Einschränkungen der Systemleistung führen.
Abhängigkeitsmanagement: Die verschiedenen Phasen von ETL-Workflows sind voneinander abhängig, so dass ein Ausfall in einem Schritt einen Kaskadeneffekt in der gesamten Pipeline auslösen kann. Um Betriebsunterbrechungen zu vermeiden, erfordert ein effektives Management von Abhängigkeiten eine gründliche Zeitplanung sowie Überwachungssysteme und Pläne für Fehlerbehebungsmechanismen.
Anwendungsfälle und Tools
Der ETL-Prozess ist eine grundlegende betriebliche Anforderung für zahlreiche Branchen und trägt zu einer effizienten Datenintegration und -analyse bei. Hier sind einige der Anwendungsfälle und Tools:
Anwendungsfälle
Einzelhandel: Der ETL-Prozess ermöglicht es Einzelhandelsgeschäften, Daten aus dem Kassensystem zu sammeln, die sie mit den Bestandsdaten abgleichen, bevor sie in einer einheitlichen Datenbank gespeichert werden. Das System ermöglicht die Verfolgung von Verkaufsdaten, die Lagerverwaltung und ein besseres Kundenverständnis.
Finanzen: Finanzinstitute verwenden ETL-Methoden, um Transaktionsdaten aus mehreren Systemen zusammenzuführen, bevor sie sie umwandeln und in integrierte Datenspeichersysteme laden. Der Konsolidierungsprozess ermöglicht es Unternehmen, Betrug effektiv zu erkennen, Risiken zu verwalten und konforme Berichte zu erstellen.
Gesundheitswesen: Organisationen des Gesundheitswesens setzen ETL-Prozesse ein, um Daten aus elektronischen Patientenakten (EMR), klinischen Datenbanken und Verwaltungssystemen zusammenzuführen. Die Systemintegration ermöglicht ein besseres Management der Patientenversorgung mit Verbesserungen der betrieblichen Effizienz und unterstützt gleichzeitig fundierte Entscheidungsprozesse.
Beliebte ETL-Tools
AWS Glue](https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html): Ein serverloser Datenintegrationsdienst, der die Verbindung zu über 70 verschiedenen Datenquellen ermöglicht. Er bietet einen zentralisierten Datenkatalog, eine serverlose Umgebung und anpassbare Skripte.
Apache NiFi: Es handelt sich um ein Open-Source-System, das durch seine ETL-Funktionalität eine automatisierte Datenflussverarbeitung ermöglicht. Das System bietet einen benutzerfreundlichen webbasierten Zugriff, sofortige Verarbeitungsfunktionen und umfangreiche Anpassungsoptionen, die komplexe Datenroutingvorgänge unterstützen.
Matillion: Ein Cloud-natives ETL-Tool, das nahtlos auf den wichtigsten Cloud-basierten Datenplattformen funktioniert. Es bietet Funktionen wie generative KI, vorgefertigte Konnektoren und kollaborative Workflows.
Die Tools und ihre Anwendungen zeigen, wie wichtig ETL-Methoden für die Umwandlung von Rohdaten in praktische Erkenntnisse in verschiedenen Geschäftsbereichen sind.
FAQs
- Was ist der Hauptzweck von ETL?
ETL dient dazu, Daten aus verschiedenen Quellen in einem einzigen, einheitlichen Speicher zusammenzuführen. Der Arbeitsablauf der Datenverarbeitung umfasst drei Stufen: Die Daten werden aus den Quellen extrahiert und dann für den betrieblichen Bedarf umgewandelt, bevor sie in ein Analysesystem geladen werden.
- Was ist der Unterschied zwischen ETL und ELT?
Der ETL-Prozess beginnt mit der Extraktion von Daten aus den Quellsystemen, bevor sie in einen Staging-Bereich transformiert werden, um sie in das Zielsystem zu laden. Die Daten werden dann in das Zielsystem geladen, und die Umwandlungen werden direkt auf diesem System durchgeführt.
- Was sind einige der häufigsten Herausforderungen bei der Implementierung von ETL-Prozessen?
Die Implementierung von ETL-Verfahren ist mit zahlreichen Hindernissen konfrontiert, da sie ein effektives Datenmanagement aus verschiedenen Quellen, eine Qualitätskontrolle und eine effiziente Handhabung großer Datenmengen erfordert. Diese Herausforderungen führen zu Leistungsproblemen, die eine gründliche Ressourcenplanung erfordern, um sie effektiv zu lösen.
- Können ETL-Prozesse automatisiert werden?
ETL-Tools bieten Automatisierungsmöglichkeiten durch Planungs- und Workflow-Management-Funktionen zur Ausführung von Datentransferprozessen. Die Automatisierung ermöglicht effiziente Abläufe durch automatische Datenverarbeitung, die die menschliche Beteiligung reduziert und gleichzeitig eine konsistente Datenqualität gewährleistet, damit die Datensätze für die Analyse aktuell bleiben.
- Warum ist die Datentransformation bei ETL wichtig?
Die Datentransformation innerhalb von ETL-Vorgängen ist entscheidend für die Bereinigung, Standardisierung und Formatierung von Daten, die aus verschiedenen Quellen stammen. Der Datenumwandlungsprozess stellt sicher, dass das Zielsystem genaue und konsistente Daten für Analysen und Berichte erhält, die zuverlässige Geschäftsentscheidungen unterstützen.
Verwandte Ressourcen
Welche Rolle spielt ETL bei der Datenbewegung? (https://zilliz.com/ai-faq/what-is-the-role-of-etl-in-data-movement)
Welche Rolle spielt ETL bei der Verarbeitung großer Datenmengen? (https://zilliz.com/ai-faq/what-is-the-role-of-etl-in-big-data-processing)
Welche Rolle spielt ETL bei der Datenanalyse?](https://zilliz.com/ai-faq/what-is-the-role-of-etl-in-data-analytics)
Wie integriert man Daten aus verschiedenen Quellen für Analysen?](https://zilliz.com/ai-faq/how-do-you-integrate-data-from-multiple-sources-for-analytics)
Wie synchronisiert man Daten zwischen relationalen und NoSQL-Datenbanken?](https://zilliz.com/ai-faq/how-do-you-synchronize-data-between-relational-and-nosql-databases)
- Was ist ETL (Extrahieren, Transformieren und Laden)?
- Wie funktioniert ETL?
- Vergleich: ETL vs. ELT
- Vorteile und Herausforderungen
- Anwendungsfälle und Tools
- FAQs
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren