




Dimensionalitätsreduktion: Vereinfachung komplexer Daten für eine einfache Analyse
TL;DR: Die Dimensionalitätsreduktion ist ein Verfahren, das in der Datenwissenschaft und beim maschinellen Lernen eingesetzt wird, um die Anzahl der Variablen oder "Dimensionen" in einem Datensatz zu reduzieren und dabei so viele relevante Informationen wie möglich zu erhalten. Diese Reduzierung vereinfacht die Datenanalyse, Visualisierung und Verarbeitung, insbesondere bei hochdimensionalen Datensätzen. Techniken wie die Hauptkomponentenanalyse (PCA) und t-Distributed Stochastic Neighbor Embedding (t-SNE) identifizieren Muster und Beziehungen innerhalb der Daten und projizieren sie auf weniger Dimensionen. Durch den Verzicht auf weniger aussagekräftige Merkmale trägt die Dimensionalitätsreduzierung zur Verbesserung der Recheneffizienz bei und verringert die Überanpassung, was sie für die Verwaltung komplexer Daten, insbesondere in Bereichen wie der Bild- und Textanalyse, unerlässlich macht.
Dimensionalitätsreduktion: Vereinfachung komplexer Daten für eine einfache Analyse
Die Dimensionalitätsreduktion vereinfacht einen Datensatz, indem sie die Anzahl der Eingabevariablen oder Merkmale reduziert, während wichtige Informationen erhalten bleiben. Sie spielt eine wichtige Rolle in der Datenwissenschaft und beim maschinellen Lernen. Sie macht die Arbeit mit großen Datensätzen überschaubarer, verbessert die Modellleistung und spart wertvolle Rechenressourcen.
Stellen Sie sich eine große, komplexe Tabelle vor, die mit vielen Datenspalten gefüllt ist. Wenn einige dieser Spalten nicht hilfreich sind oder für die Analyse geklärt werden müssen, werden sie durch Dimensionalitätsreduktion beschnitten, um die Mustererkennung zu erleichtern.
Der Fluch der Dimensionalität
Der [Fluch der Dimensionalität] (https://zilliz.com/glossary/curse-of-dimensionality-in-machine-learning) bezieht sich auf die Probleme, die bei der Analyse und Organisation von Daten in hochdimensionalen Räumen auftreten. Wenn die Anzahl der Merkmale (oder Dimensionen) zunimmt, vergrößert sich das Volumen des Raums so schnell, dass die verfügbaren Daten spärlich werden. Diese Spärlichkeit erschwert es den Algorithmen, sinnvolle Muster zu finden, was die Datenanalyse ineffizient und unzuverlässig macht.
Um die Auswirkungen zu verstehen, stellen Sie sich vor, Sie versuchen, den Abstand zwischen Punkten in einem eindimensionalen Raum zu messen, z. B. eine gerade Linie. Die Punkte liegen nahe genug beieinander, um leicht gemessen werden zu können. Erweitert man diesen Raum auf zwei Dimensionen, wie z. B. ein flaches Blatt Papier, so breiten sich die Punkte weiter aus. Wenn man sich auf drei Dimensionen ausdehnt, z. B. auf einen Raum, werden sie noch weiter verteilt. Wenn die Dimensionen weiter zunehmen, liegen die Punkte so weit auseinander, dass sie fast isoliert erscheinen, und die Berechnung des Abstands wird weniger nützlich. Dies geschieht bei hochdimensionalen Daten, bei denen gängige Datenanalysetechniken möglicherweise nicht mehr effektiv funktionieren, weil die Beziehungen zwischen den Datenpunkten verwässert werden, wie in der Abbildung dargestellt.
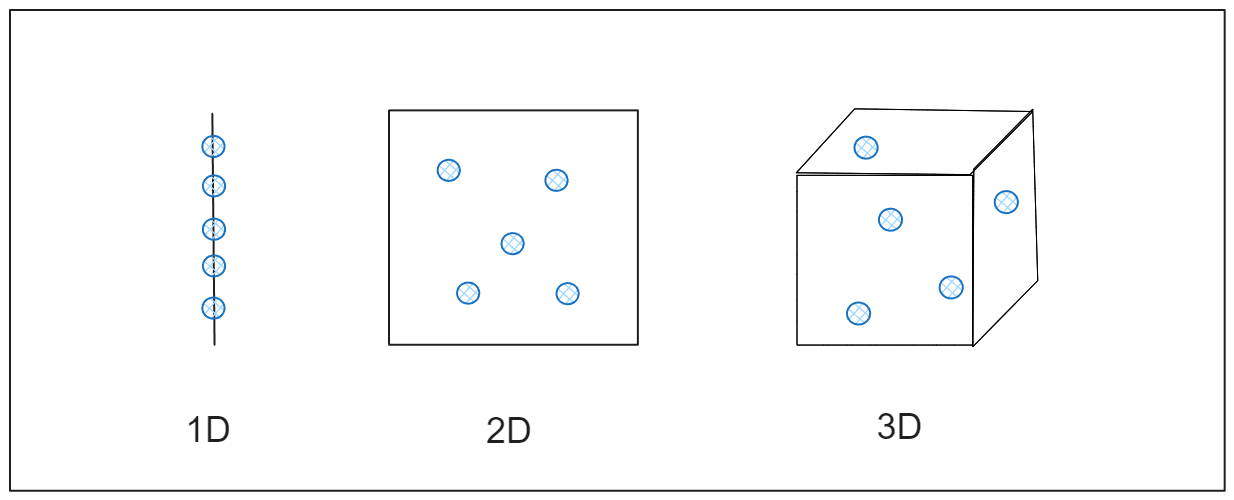 Abbildung- Wie sich Daten über Dimensionen hinweg ausdehnen.png
Abbildung- Wie sich Daten über Dimensionen hinweg ausdehnen.png
Abbildung: Wie sich Daten über die Dimensionen hinweg ausdehnen
Eine einfache Analogie ist die Suche nach Freunden in einem Park. Wenn Sie und Ihre Freunde in einem kleinen Park verstreut sind, können Sie einander schnell ausfindig machen. Aber stellen Sie sich vor, der Park würde auf die Größe einer Großstadt anwachsen. Jetzt wird es selbst bei gleicher Anzahl von Freunden schwierig, einen zu finden, weil alle zu weit voneinander entfernt sind. Ähnlich verhält es sich mit hochdimensionalen Räumen, in denen die Datenpunkte verstreut sind, so dass es für Algorithmen schwierig ist, sie effizient zu organisieren oder zu analysieren.
Schlüsseltechniken zur Dimensionalitätsreduktion
Obwohl es verschiedene [Strategien zur Dimensionalitätsreduzierung] (https://zilliz.com/learn/streamlining-data-strategies-for-reducing-dimensionality) gibt, kann man sie grob in zwei Haupttypen einteilen: Feature Selection und Feature Extraction. Beide Methoden zielen auf eine Vereinfachung der Daten ab, allerdings auf unterschiedliche Weise.
Merkmalsauswahl
Bei der Merkmalsauswahl wird die Dimensionalität reduziert, indem eine Teilmenge der wichtigsten Merkmale aus dem ursprünglichen Datensatz ausgewählt wird. Anstatt die Daten umzuwandeln, werden bei diesem Ansatz die Merkmale unverändert beibehalten, aber diejenigen entfernt, die nicht wesentlich zur Analyse oder zur Modellleistung beitragen. Ziel ist es, redundante oder irrelevante Merkmale zu entfernen, um den Datensatz zu vereinfachen und leichter zu bearbeiten.
Es gibt drei gängige Methoden für die Merkmalsauswahl:
Filtermethoden: Diese verwenden statistische Tests, um Merkmale nach ihrer Wichtigkeit zu ordnen. Beispiele hierfür sind Korrelationswerte, Informationsgewinn und Chi-Quadrat-Tests. Sie sind einfach und funktionieren unabhängig vom maschinellen Lernmodell.
Wrapper-Methoden: Diese bewerten verschiedene Untergruppen von Merkmalen und verwenden die Modellleistung, um die beste Kombination zu ermitteln. Obwohl sie genauer sind, können sie rechenintensiv sein. Techniken wie rekursive Merkmalseliminierung (RFE), Vorwärtsselektion und Rückwärtseliminierung fallen in diese Kategorie.
Eingebettete Methoden: Bei diesen Verfahren wird die Merkmalsauswahl in den Modellbildungsprozess integriert. Modelle wie Entscheidungsbäume, Lasso-Regression und Ridge-Regression identifizieren automatisch wichtige Merkmale als Teil ihrer Ausbildung.
Merkmalsextraktion
Bei der Merkmalsextraktion werden die ursprünglichen Merkmale in einen niedrigdimensionalen Raum transformiert, wobei neue Merkmale entstehen, die dennoch die wesentlichen Informationen erfassen. Dieser Ansatz ist nützlich, wenn Sie Daten komprimieren und gleichzeitig sinnvolle Beziehungen zwischen den Merkmalen beibehalten wollen. Im Gegensatz zur Merkmalsauswahl werden bei der Merkmalsextraktion völlig neue Darstellungen der Daten erstellt.
Die am häufigsten verwendeten Techniken sind die Hauptkomponentenanalyse (PCA), die t-verteilte stochastische Nachbarschaftseinbettung (t-SNE) und die lineare Diskriminanzanalyse (LDA). Lassen Sie uns diese im Detail besprechen.
Hauptkomponentenanalyse (PCA)
Die Hauptkomponentenanalyse (PCA) ist ein beliebtes Verfahren zur Dimensionalitätsreduktion. Ihr Hauptzweck ist die Vereinfachung eines großen Satzes von Variablen in einen kleineren Satz, der immer noch den größten Teil der Informationen in den ursprünglichen Daten erfasst.
Um die PCA zu verstehen, muss man sich einen Datensatz als ein mehrdimensionales Objekt vorstellen, wie eine Wolke von Punkten im Raum. Die PCA findet die Richtungen (oder Achsen), in denen die Daten am stärksten variieren, und projiziert die Daten auf diese neuen Achsen. Die erste Achse, die sogenannte Hauptkomponente, erfasst die größte Varianz (oder Streuung) in den Daten. Die zweite Achse erfasst die nächstgrößere Varianz, und so weiter. Durch die Konzentration auf nur die ersten paar Komponenten reduziert die PCA die Anzahl der Dimensionen, während die Hauptstruktur der Daten erhalten bleibt.
Die folgenden Diagramme zeigen, wie die PCA zur Vereinfachung der Daten beiträgt. Auf der linken Seite sehen Sie ein Streudiagramm mit Punkten, die in zwei Richtungen verteilt sind. Die PCA findet die Hauptrichtung, in der die Daten am stärksten variieren, was durch den schwarzen Pfeil angezeigt wird. Die rechte Seite zeigt, wie die Daten entlang dieser Richtung abgeflacht werden.
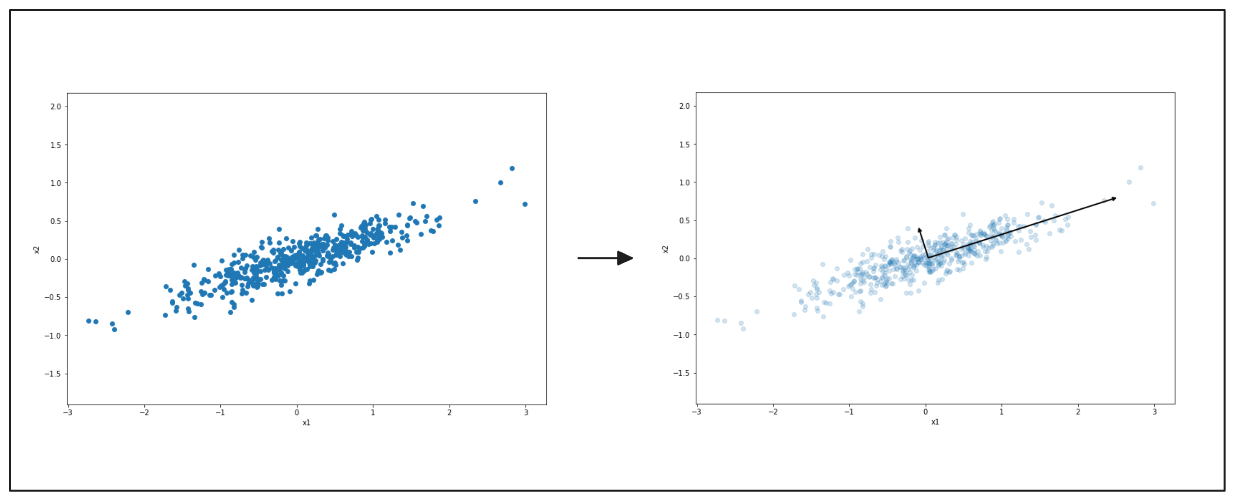 Abbildung- PCA hebt die Hauptrichtung der Datenvariation hervor..png
Abbildung- PCA hebt die Hauptrichtung der Datenvariation hervor..png
Abbildung: PCA zur Hervorhebung der Hauptrichtung der Datenvariation.
Auf der linken Seite sehen Sie wieder die Verteilung der Daten in zwei Dimensionen. Der schwarze Pfeil weist auf die Hauptrichtung der Variation hin. Auf der rechten Seite werden die Daten auf diese Linie komprimiert und damit auf eine einfachere Form reduziert. Dieses Verfahren erleichtert die Arbeit mit den Daten, wobei die Hauptmuster erhalten bleiben.
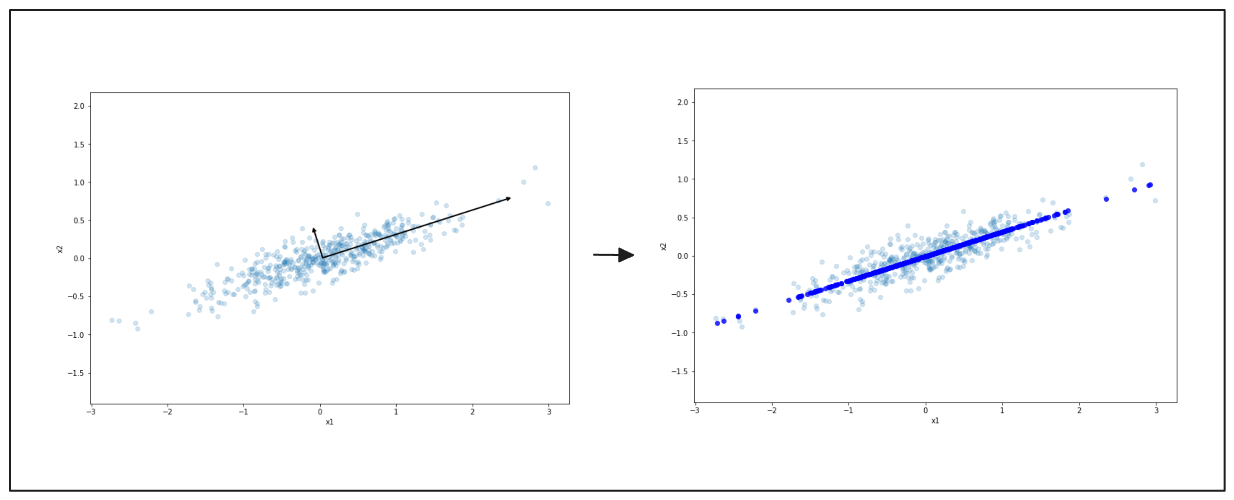 Abbildung - Vereinfachte Datendarstellung mit PCA.png
Abbildung - Vereinfachte Datendarstellung mit PCA.png
Abbildung: Vereinfachte Datendarstellung mit PCA
Vorteile der Verwendung von PCA
Verringerung der Komplexität: Durch die Vereinfachung von Datensätzen mit vielen Variablen wird die Analyse schneller und effizienter.
Entfernt Rauschen: Die PCA filtert Rauschen und irrelevante Informationen heraus, indem sie die Komponenten mit der größten Varianz beibehält.
Verbessert die Visualisierung: Die PCA hilft bei der Visualisierung hochdimensionaler Daten in zwei oder drei Dimensionen und enthüllt Muster, die sonst verborgen bleiben würden.
Nachteile der Verwendung von PCA
Verlust von Informationen: Einige Daten können während der Dimensionalitätsreduktion verloren gehen, was die Modellleistung beeinträchtigt.
Schwierigere Interpretierbarkeit: Die durch die PCA erzeugten neuen Merkmale sind Kombinationen aus den ursprünglichen Merkmalen, was ihre sinnvolle Interpretation erschwert.
Setzt Linearität voraus: Die PCA funktioniert am besten, wenn die Beziehungen zwischen den Variablen linear sind, was nicht immer der Fall ist.
Praktische Anwendungen
Bildkomprimierung: Verringert die Größe von Bilddateien unter Beibehaltung wichtiger visueller Merkmale.
Finanzen: Vereinfacht komplexe Datensätze, um Muster in Aktienkursbewegungen zu erkennen.
Genetik: Analysiert große genomische Datensätze, um sinnvolle Datenstrukturen aufzudecken.
Vielseitigkeit: Nützlich für die Vereinfachung und Interpretation von hochdimensionalen Daten in verschiedenen Bereichen.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
t-Distributed Stochastic Neighbor Embedding (t-SNE) visualisiert hochdimensionale Daten. Es projiziert Daten in zwei oder drei Dimensionen, um Cluster und Muster zu identifizieren. t-SNE wird weithin für seine Fähigkeit geschätzt, die lokalen Beziehungen zwischen Datenpunkten beizubehalten, was dazu beiträgt, die zugrunde liegende Struktur des Datensatzes aufzudecken. Diese Methode ist besser für Datensätze im 3D-Raum geeignet.
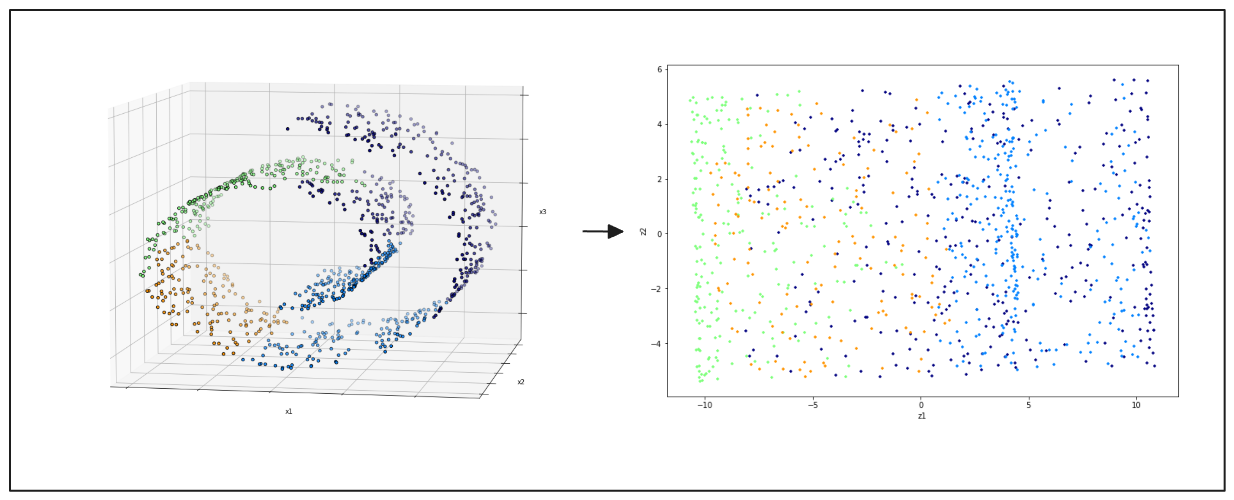 Abbildung- links- Schweizer Rolle 3D-Datenpunkte, rechts- 2D-Projektionsergebnis von PCA.png
Abbildung- links- Schweizer Rolle 3D-Datenpunkte, rechts- 2D-Projektionsergebnis von PCA.png
Abbildung: links: 3D-Datenpunkte der Schweizer Rolle, rechts: 2D-Projektionsergebnis der PCA
Vorteile der Verwendung von t-SNE
Erhaltung der lokalen Struktur: t-SNE zeichnet sich dadurch aus, dass nahe beieinander liegende Datenpunkte im niedrigdimensionalen Raum nahe beieinander bleiben, wodurch es sich gut für die Visualisierung von Clustern eignet.
Nützlich für komplexe Daten: Es eignet sich besonders gut für den Umgang mit nichtlinearen Beziehungen und die Erforschung komplexer Muster in Daten.
Großartig für die Visualisierung: t-SNE erzeugt visuell intuitive und ansprechende Streudiagramme, die das Verständnis des Datenlayouts erleichtern.
Nachteile der Verwendung von t-SNE
Berechnungsintensiv: Die Ausführung von t-SNE kann langsam und ressourcenintensiv sein, insbesondere bei großen Datensätzen.
Erfordert Parameterabstimmung: Parameter wie Perplexität und Lernrate müssen sorgfältig eingestellt werden, und die Ergebnisse können je nach diesen Einstellungen erheblich variieren.
Verfälscht die globale Struktur: Während t-SNE lokale Beziehungen gut bewahrt, kann es die globale Struktur der Daten verzerren und ist daher für das Verständnis großräumiger Beziehungen weniger nützlich.
Praktische Anwendungen
Hochdimensionale Datenvisualisierung: Nützlich für die Untersuchung von Clusterstrukturen.
Bilderkennung: Visualisiert die Verteilung von Bildmerkmalen.
Natürliche Sprachverarbeitung (NLP)](https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing): Erforscht Worteinbettungen.
Genomik: Identifiziert aussagekräftige genetische Datencluster.
Beliebtheit: Wird von Datenwissenschaftlern trotz Einschränkungen häufig für visuelle Einblicke verwendet.
Lineare Diskriminanzanalyse (LDA)
Im Gegensatz zur PCA zielt die LDA darauf ab, die Trennung zwischen verschiedenen Klassen in den Daten zu maximieren. Dies geschieht durch Projektion der Daten auf einen niedrigdimensionalen Raum, der die Kategorien auf der Grundlage ihrer Bezeichnungen am besten trennt.
LDA wird häufig in Szenarien verwendet, in denen die [Datenklassifizierung] (https://zilliz.com/glossary/classification) das primäre Ziel ist. Sie ist besonders nützlich, wenn es um Datensätze geht, die klare Klassengrenzen haben. Zu den praktischen Anwendungen gehören Gesichtserkennung, medizinische Diagnose und Textklassifizierung.
Wie unterscheidet sich LDA von PCA?
Zielsetzung: LDA konzentriert sich auf die Maximierung der Klassentrennbarkeit, während PCA darauf abzielt, die größte Varianz in den Daten zu erfassen, ohne die Klassenbezeichnungen zu berücksichtigen.
Überwacht vs. Unüberwacht: LDA ist eine [überwachte Technik] (https://zilliz.com/glossary/supervised-machine-learning), die bei ihren Berechnungen Klassenbezeichnungen verwendet. PCA hingegen ist unbeaufsichtigt und verwendet keine Label-Informationen.
Datenvarianz: LDA reduziert die Dimensionen, indem sie die Achsen findet, die den Abstand zwischen den Mittelwerten der verschiedenen Klassen maximieren, während die Streuung innerhalb jeder Klasse minimiert wird. Die PCA berücksichtigt keine Klasseninformationen und ihr einziges Ziel ist es, die Redundanz in den Daten zu reduzieren.
Andere Techniken und neue Methoden
Neben den traditionellen Techniken zur Dimensionalitätsreduzierung wie PCA, t-SNE und LDA gewinnen mehrere andere Methoden und neue Trends in der Datenanalyse an Bedeutung.
Autoencoder
Autoencoder sind [neuronale Netze] (https://zilliz.com/glossary/neural-networks), die für unüberwachtes Lernen verwendet werden und darauf abzielen, Daten in eine niedrigdimensionale Darstellung zu komprimieren und dann wieder in ihre ursprüngliche Form zu rekonstruieren. Das Netzwerk besteht aus einem Encoder, der die Dimensionalität reduziert, und einem Decoder, der die Eingabe aus der komprimierten Darstellung rekonstruiert. Autoencoder sind nützlich für den Umgang mit nichtlinearen Beziehungen in Daten und können komplexe Merkmalsdarstellungen erlernen.
Unabhängige Komponentenanalyse (ICA)
Die Independent Component Analysis (ICA) ist eine Rechentechnik zur Aufteilung eines multivariaten Signals in additive, unabhängige Komponenten. Im Gegensatz zur PCA, die sich auf die Varianz konzentriert, sucht die ICA nach statistisch unabhängigen Quellen. Diese Methode wird häufig bei Anwendungen wie der blinden Quellentrennung eingesetzt, z. B. bei der Isolierung verschiedener Audioquellen aus einer gemischten Aufnahme.
Uniform Manifold Approximation and Projection (UMAP)
Uniform Manifold Approximation and Projection (UMAP) ist eine relativ neue Technik zur Dimensionalitätsreduktion, die sowohl lokale als auch globale Strukturen in den Daten bewahrt. Sie basiert auf dem Lernen von Mannigfaltigkeiten und zielt darauf ab, die Beziehungen zwischen Datenpunkten während des Reduktionsprozesses zu erhalten. UMAP ist schneller und liefert im Vergleich zu t-SNE oft bessere Visualisierungen.
Vorteile der Dimensionalitätsreduktion
Die Dimensionalitätsreduktion bietet mehrere entscheidende Vorteile, die die Analyse komplexer Datensätze verbessern:
Vereinfachte Modelle: Weniger Merkmale führen zu einfacheren Modellen, die leichter zu trainieren und zu analysieren sind, was für zeitkritische Anwendungen entscheidend sein kann.
Reduzierung der Speicher- und Rechenanforderungen: Die Verarbeitung von Daten mit niedrigeren Dimensionen führt zu weniger Speicherplatzbedarf und schnelleren Verarbeitungszeiten, was die Betriebskosten senken kann, insbesondere bei großen Datensätzen.
Verbessert die Modellleistung: Durch die Berücksichtigung der wichtigsten Merkmale können Modelle genauer und robuster werden, da sie weniger wahrscheinlich durch irrelevante Daten beeinträchtigt werden.
Verbessert die Interpretierbarkeit: Die Reduzierung der Dimensionen kann dazu beitragen, wesentliche Beziehungen in den Daten hervorzuheben, die den Beteiligten helfen, Modellentscheidungen und die zugrunde liegenden Muster zu verstehen.
Erleichtert die Datenvisualisierung: Die Umwandlung hochdimensionaler Daten in zwei oder drei Dimensionen ermöglicht klarere visuelle Darstellungen und hilft bei der Entdeckung von Erkenntnissen, die in höheren Dimensionen möglicherweise nicht ersichtlich sind.
Hilft bei der Rauschunterdrückung: Durch das Entfernen weniger wichtiger Dimensionen kann die Dimensionalitätsreduzierung die Menge des Rauschens verringern, was zu saubereren Datensätzen führt, die zu zuverlässigeren Analysen beitragen.
Unterstützt verbessertes Feature Engineering: Der Prozess kann dabei helfen, die wichtigsten Merkmale zu identifizieren, und bietet Möglichkeiten zur Erstellung verbesserter Merkmale, die zu einer besseren Modellleistung führen können.
Ermöglicht schnelleres Prototyping: Da weniger Dimensionen zu berücksichtigen sind, können Datenwissenschaftler die Modellentwicklung schnell iterieren, um Modelle schnell zu testen und zu verfeinern.
Herausforderungen bei der Dimensionalitätsreduktion
Techniken zur Dimensionalitätsreduktion sind mit verschiedenen Herausforderungen verbunden, die sorgfältig bedacht werden müssen:
Risiko des Verlusts wichtiger Informationen: Bei der Reduzierung der Dimensionen können unbeabsichtigt wesentliche Merkmale unberücksichtigt bleiben, was sich negativ auf die Modellleistung auswirken und zu Fehlinterpretationen der Ergebnisse führen kann.
Auswahl der richtigen Technik: Die Wirksamkeit der Methoden zur Dimensionalitätsreduktion hängt von der Art des Datensatzes und den spezifischen Analysezielen ab. Aufgrund dieser Variabilität ist es von entscheidender Bedeutung, die Stärken und Grenzen der einzelnen Techniken zu kennen, um unwirksame Ergebnisse zu vermeiden.
Berechnungsaufwand: Techniken wie t-SNE können ressourcenintensiv sein und sind für große Datensätze weniger gut geeignet. Der Zeit- und Speicherbedarf kann ihre Anwendbarkeit in zeitkritischen Szenarien erheblich einschränken.
Gleichgewicht zwischen Reduktion und Genauigkeit: Es ist eine ständige Herausforderung, das richtige Maß an Dimensionalitätsreduktion zu erreichen und gleichzeitig sicherzustellen, dass das Modell genügend Informationen für genaue Vorhersagen enthält. Eine zu starke Reduktion kann die Daten zu sehr vereinfachen und die Fähigkeit des Modells beeinträchtigen, die notwendige Komplexität zu erfassen.
Anwendungen der Dimensionalitätsreduktion in verschiedenen Branchen
Techniken zur Dimensionalitätsreduktion werden in verschiedenen Bereichen eingesetzt, um die Datenanalyse zu verbessern und die Modellleistung zu erhöhen. Hier sind einige praktische Szenarien, in denen diese Methoden häufig eingesetzt werden:
Bildverarbeitung: In Bereichen wie der Computer Vision hilft die Dimensionalitätsreduktion bei der Komprimierung von Bilddaten unter Beibehaltung wesentlicher Merkmale. Bei der Gesichtserkennung kann die PCA beispielsweise Tausende von Pixelwerten auf kleinere Merkmale reduzieren, wodurch die Verarbeitung beschleunigt wird, ohne dass wichtige Details verloren gehen. Auch in der medizinischen Bildgebung hebt die Dimensionalitätsreduktion wichtige Bereiche in MRT-Scans für eine schnellere Analyse hervor.
Natürliche Sprachverarbeitung: Die Dimensionalitätsreduktion wird verwendet, um hochdimensionale Textdaten zu vereinfachen, wie z. B. Worteinbettungen. Methoden wie t-SNE helfen bei der Visualisierung von Wortbeziehungen und Clustern und unterstützen die Stimmungsanalyse und Themenmodellierung.
Genomik: In der Bioinformatik sind Techniken zur Dimensionalitätsreduzierung für die Analyse genetischer Daten unerlässlich, bei denen die Anzahl der Variablen (Gene) extrem hoch sein kann. Die Reduzierung der Dimensionen hilft bei der Identifizierung wichtiger genetischer Marker, die mit Krankheiten in Verbindung stehen.
Finanzwesen: Die Dimensionalitätsreduzierung hilft beim Risikomanagement und bei der Portfolio-Optimierung durch Vereinfachung großer Datensätze von Finanzindikatoren. Analysten können die wichtigsten Merkmale auswählen, die das Marktverhalten beeinflussen.
Empfehlungssysteme] (https://zilliz.com/learn/Introduction-to-Recommendation-systems): Bei der kollaborativen und inhaltsbasierten Filterung hilft die Dimensionalitätsreduzierung bei der Entwicklung effizienterer Empfehlungsalgorithmen, indem sie zugrundeliegende Muster in den Benutzerpräferenzen und Artikelmerkmalen identifiziert.
Gesundheitswesen: Die Analyse von Patientendaten umfasst oft hochdimensionale Datensätze. Die Dimensionalitätsreduktion hilft bei der Identifizierung signifikanter Faktoren, die sich auf die Ergebnisse der Patienten auswirken, und verbessert die Vorhersagemodelle für den Krankheitsverlauf.
Marketing-Analytik: Im Marketing ist das Verständnis des Kundenverhaltens entscheidend. Die Dimensionalitätsreduzierung ermöglicht es Unternehmen, Kunden auf einfache Weise zu segmentieren, indem die Komplexität der Kundendaten reduziert wird, was zu gezielten Marketingstrategien führt.
Fertigung und Qualitätskontrolle: In industriellen Anwendungen hilft die Dimensionalitätsreduktion bei der Analyse von Maschinensensordaten, um Muster und Anomalien zu erkennen, was zu einer besseren Qualitätskontrolle und vorausschauenden Wartung führt.
Wie verbessert die Dimensionalitätsreduktion die Leistung von Vektordatenbanken?
Die Dimensionalitätsreduzierung verbessert die Leistung von Vektordatenbanken wie Milvus (entwickelt von den Ingenieuren von Zilliz), die für die Verwaltung umfangreicher unstrukturierter Daten und ihrer hochdimensionalen Vektordarstellungen konzipiert sind, erheblich. So sind sie miteinander verknüpft:
Effiziente Datenspeicherung: Milvus kann hochdimensionale Vektordaten speichern, die von maschinellen Lernmodellen erzeugt wurden. Die Anwendung von Techniken zur Dimensionalitätsreduktion, wie PCA oder t-SNE, hilft bei der Komprimierung dieser Vektoren, wodurch die Speicheranforderungen reduziert und die Abrufgeschwindigkeit verbessert werden.
Verbesserte Abfrageleistung: Die Suche in hochdimensionalen Daten kann in einer Vektordatenbank rechenintensiv sein. Durch die Dimensionalitätsreduktion wird die Dimensionalität der Vektoren minimiert, was die [Ähnlichkeitssuche] (https://zilliz.com/blog/similarity-metrics-for-vector-search) und die [Nächste-Nachbar-Abfrage] (https://zilliz.com/glossary/anns) beschleunigt.
Verbesserte Datenvisualisierung: Bei der Verwendung von Zilliz oder Milvus zur Datenanalyse können Techniken zur Dimensionalitätsreduktion die Visualisierung komplexer Datensätze erleichtern. Auf diese Weise können die Benutzer Datenverteilungen, Beziehungen und Muster in den hochdimensionalen Daten, die in der Datenbank gespeichert sind, besser verstehen.
Erleichterung von Workflows für maschinelles Lernen: In Pipelines für maschinelles Lernen kann die Dimensionalitätsreduktion dazu beitragen, die Vorverarbeitung von Daten zu rationalisieren. Durch die Verringerung der Komplexität der Eingangsmerkmale wird das Training von Modellen für maschinelles Lernen verbessert, was zu einer höheren Leistung und besseren Interpretierbarkeit führt.
Schlussfolgerung
Die Dimensionalitätsreduktion ist eine wichtige Technik in der Datenwissenschaft und im maschinellen Lernen, die komplexe Datensätze vereinfacht und dabei wesentliche Informationen bewahrt. Die Verringerung der Anzahl der Merkmale verbessert die Modellleistung, erleichtert die Visualisierung und erleichtert die Datenanalyse in verschiedenen Bereichen. Trotz der Herausforderungen, die mit der Dimensionalitätsreduktion verbunden sind, wie z. B. das Risiko des Verlusts wichtiger Informationen und die Notwendigkeit einer sorgfältigen Auswahl der Technik, sind die Vorteile der Dimensionalitätsreduktion von unschätzbarem Wert für die Gewinnung von Erkenntnissen und die Verbesserung der Effizienz von Analyseprozessen.
FAQs zur Dimensionalitätsreduktion
- Was ist Dimensionalitätsreduktion?
Die Dimensionalitätsreduzierung ist eine Technik, die dazu dient, die Anzahl der Merkmale oder Dimensionen in einem Datensatz zu reduzieren und dabei so viele relevante Informationen wie möglich zu erhalten. Diese Vereinfachung macht die Analyse, Visualisierung und Modellierung komplexer Daten einfacher.
- Warum ist Dimensionalitätsreduktion in der Datenwissenschaft wichtig?
Sie trägt dazu bei, die Modellleistung zu verbessern, den Speicher- und Rechenaufwand zu verringern, die Datenvisualisierung zu verbessern und die Modellinterpretation zu vereinfachen, was sie für eine effiziente Datenanalyse in verschiedenen Anwendungen unerlässlich macht.
- Was sind einige gängige Techniken zur Dimensionalitätsreduktion?
Zu den gängigen Techniken gehören die Hauptkomponentenanalyse (PCA), die t-verteilte stochastische Nachbarschaftseinbettung (t-SNE), die lineare Diskriminanzanalyse (LDA), Methoden zur Auswahl von Merkmalen und neue Techniken wie Autocoder und UMAP.
- Was sind die Herausforderungen bei der Dimensionalitätsreduktion?
Zu den Herausforderungen gehören das Risiko, wichtige Informationen zu verlieren, die Schwierigkeit, die richtige Technik für bestimmte Datensätze zu wählen, die Rechenkosten bestimmter Methoden und die Abwägung zwischen Dimensionalitätsreduktion und Modellgenauigkeit.
- Wie profitiert die Dimensionalitätsreduktion von Vektordatenbanken wie Milvus?
Die Dimensionalitätsreduktion verbessert die Leistung von Vektordatenbanken, indem sie die Datenspeicherung optimiert, die Abfrageleistung steigert, die Datenvisualisierung erleichtert und die Arbeitsabläufe beim maschinellen Lernen rationalisiert.
Verwandte Ressourcen
Fortgeschrittene Abfragetechniken in Vektordatenbanken](https://zilliz.com/learn/advanced-querying-techniques-in-vector-databases)
Rationalisierung von Daten: Effektive Strategien zur Reduzierung der Dimensionalität](https://zilliz.com/learn/streamlining-data-strategies-for-reducing-dimensionality)
Der Fluch der Dimensionalität beim maschinellen Lernen](https://zilliz.com/glossary/curse-of-dimensionality-in-machine-learning)
Batch vs. Layer Normalization - Effizienz in neuronalen Netzen freisetzen](https://zilliz.com/learn/layer-vs-batch-normalization-unlocking-efficiency-in-neural-networks)
- Der Fluch der Dimensionalität
- Schlüsseltechniken zur Dimensionalitätsreduktion
- Andere Techniken und neue Methoden
- Vorteile der Dimensionalitätsreduktion
- Herausforderungen bei der Dimensionalitätsreduktion
- Anwendungen der Dimensionalitätsreduktion in verschiedenen Branchen
- Wie verbessert die Dimensionalitätsreduktion die Leistung von Vektordatenbanken?
- Schlussfolgerung
- FAQs zur Dimensionalitätsreduktion
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren