




Verständnis des CURE-Algorithmus: Eine umfassende Untersuchung des Clusterings mit Repräsentanten
 Visuelle Darstellung des Clusterings
Visuelle Darstellung des Clusterings
Abbildung 1: Visuelle Darstellung des Clusterings
Wie können Unternehmen sich im ständig wandelnden Markt zurechtfinden und Kunden mit ähnlichen Mustern effektiv gruppieren? Traditionelle Clustering-Methoden stoßen beim Umgang mit unregelmäßigen Datenformen und Ausreißern oft an ihre Grenzen. Die Komplexität moderner Datensätze erfordert intelligentere, anpassungsfähigere Lösungen.
Hier kommt der CURE-Algorithmus (Clustering Using Representatives) ins Spiel, eine effektive Methode, die die Einschränkungen standardmäßiger Clustering-Ansätze adressiert. CURE verwendet eine Auswahl repräsentativer Punkte, um sich von klassischen Clustering-Methoden zu unterscheiden, und verbessert so seine Intelligenz beim Erkennen komplexer Datenverteilungen. Diese repräsentativen Punkte bewegen sich näher zum Mittelwert des Clusters, wodurch der Algorithmus fortschrittlicher wird, da er mit beliebig geformten Clustern umgehen kann.
CURE kann bei Anwendung auf große Datensätze rechenintensiv werden. Trotzdem bleibt sein Ansatz zur Behandlung von Anomalien und komplexen Clustern äußerst effektiv. Lassen Sie uns die Funktionsweise des CURE-Algorithmus besprechen, indem wir seinen Kernansatz, seine Vorteile und praktischen Anwendungen untersuchen. Außerdem gehen wir auf die Herausforderungen ein, denen Sie bei der Implementierung von CURE begegnen können.
Was ist der CURE-Algorithmus?
Der CURE-Algorithmus verwendet einen hierarchischen Clustering-Ansatz, der komplexe Clusterformen identifiziert und effektiv mit Ausreißern umgeht. ****Im Gegensatz zu zentroidbasierten Algorithmen wie k-means stellt CURE Cluster mithilfe mehrerer repräsentativer Punkte dar. Diese Punkte bewegen sich mit einem festen Schrumpffaktor in Richtung der Cluster-Mittelwerte, um robuste Cluster-Repräsentationen zu erzeugen.
CURE zeigt eine bessere Flexibilität als k-means, da sein Design es ermöglicht, mit verschiedenen unregelmäßigen Datensatztypen zu arbeiten. Seine Fähigkeit, traditionelle Algorithmusbeschränkungen hinsichtlich konvexer oder äquidistanter Cluster zu überwinden, führt zur präzisen Erkennung von Clustergrenzen und -formen.
Wie es funktioniert
CURE-Algorithmen umfassen mehrere Schritte, um die endgültige Ausgabe zu erzeugen. Lassen Sie uns aufdecken, wie sie Daten auswählen, um einen ausreißerfreien Cluster zu erstellen.
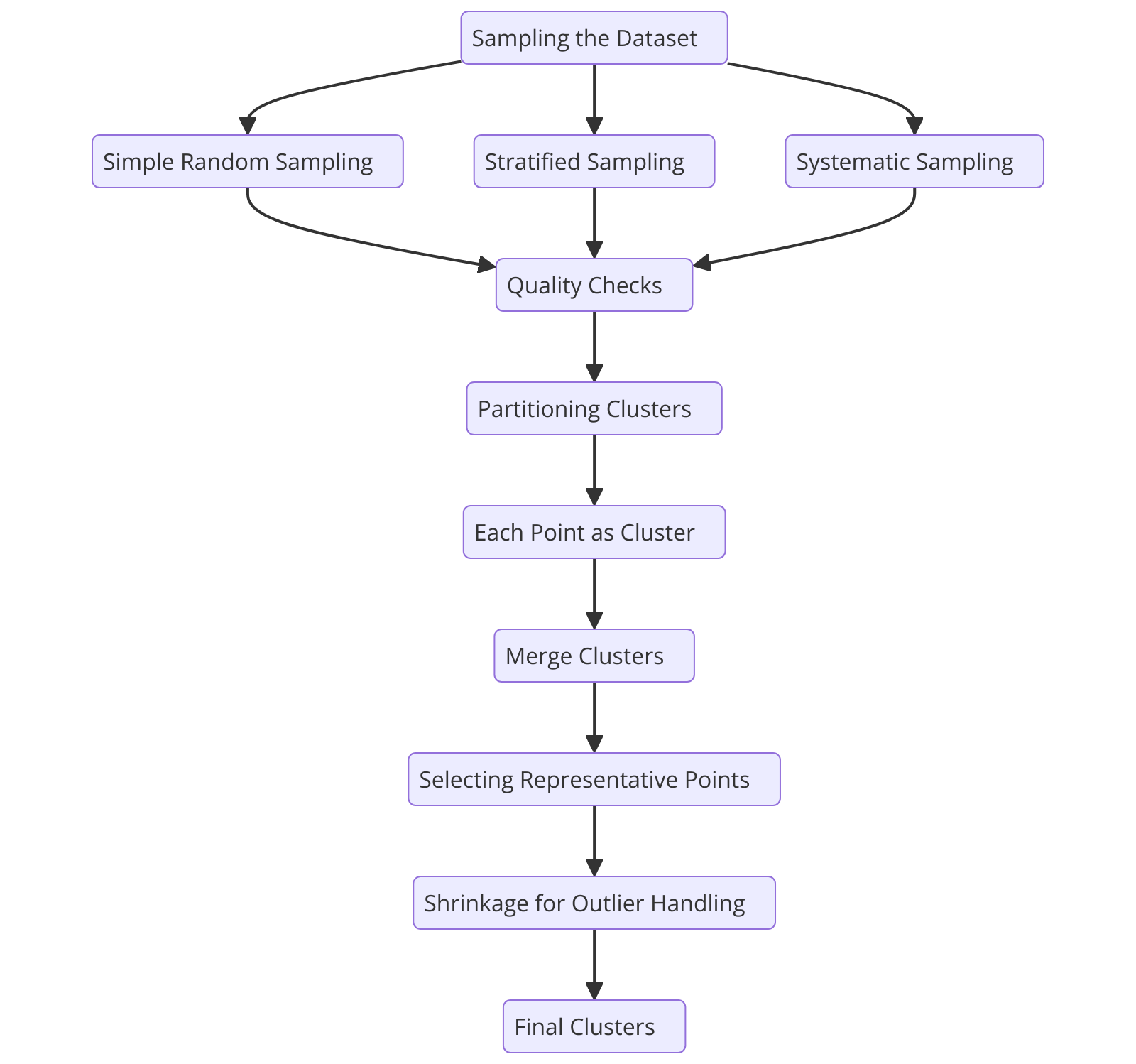 Prozessablauf des CURE-Clustering-Algorithmus
Prozessablauf des CURE-Clustering-Algorithmus
Abbildung 2: Prozessablauf des CURE-Clustering-Algorithmus
Prozessablauf des CURE-Clustering-Algorithmus
Um zu verstehen, wie der CURE-Algorithmus funktioniert, zerlegen wir seinen Prozess Schritt für Schritt, beginnend mit dem Sampling des Datensatzes.
Sampling des Datensatzes
CURE beginnt mit der Auswahl einer repräsentativen Zufallsstichprobe aus dem Datensatz. Der Sampling-Prozess verringert die Anzahl der Datenpunkte, beschleunigt die Berechnungsgeschwindigkeit und erhält gleichzeitig die Cluster-Integrität.
Einfaches zufälliges Sampling ermöglicht eine schnelle Implementierung, erfasst jedoch entscheidende Randfälle nicht. Dies führt zu einer unzureichenden Repräsentation von Minderheitengruppen in unausgewogenen Datensätzen. Stratifiziertes Sampling wird notwendig, wenn die proportionale Verteilung verschiedener Klassen in den Daten beibehalten werden muss.
Diese Methode stellt sicher, dass alle bedeutenden kleinen Teilmengen der Daten für die Analyse sichtbar bleiben. Eine weitere Methode ist systematisches Sampling, das Datenpunkte über ein regelmäßiges Intervallsystem auswählt. Systematisches Sampling eignet sich hervorragend für Zeitreihen und geordnete Daten, da es die zeitliche Natur und das sequenzielle Ordnungsmuster in Datensätzen bewahrt.
Qualitätsprüfungen verifizieren nach der Erhebung die Übereinstimmung der Stichprobe mit der Verteilung des ursprünglichen Datensatzes. Der Vergleich von Mittelwerten, Varianzniveaus und Verteilungsmerkmalen hilft dabei, die Ähnlichkeiten zwischen der gewonnenen Stichprobe und dem vollständigen ursprünglichen Datensatz zu bewerten. Strenge Sampling-Strategien, die von CURE implementiert werden, ermöglichen es dem anschließenden Clustering, die Komplexität und Vielfalt des gesamten Datensatzes genau abzubilden.
Partitionierung von Clustern
Nach dem Sampling des Datensatzes wendet CURE eine hierarchische Methode an, die die Daten in handhabbare Teilmengen unterteilt. Insbesondere verwendet es eine Bottom-up-Merging-Strategie für das Clustering. Der Algorithmus misst Ähnlichkeiten zwischen Datenpunkten durch Distanzmetriken, die die euklidische Distanz oder die Manhattan-Distanz verwenden. Die Distanzberechnungsmetriken sind wesentlich, um die Nähe von Punkten zu bestimmen und gleichzeitig eine solide Grundlage für ein effektives Zusammenführen von Clustern zu schaffen.
Zu Beginn des Prozesses fungiert jeder Datenpunkt als eigener Cluster, um die feingranulare Natur der Daten darzustellen. Der Algorithmus führt aufeinanderfolgende Cluster-Zusammenführungen anhand von Nähekriterien durch, um ähnliche Punkte zu gruppieren. Der Algorithmus setzt die Cluster-Zusammenführungsoperationen fort, bis eine definierte Anzahl von Clustern erreicht ist oder eine alternative Abbruchbedingung aktiviert wird.
Der Gruppenauswahlprozess in CURE erzeugt Cluster, die mit den natürlichen Kategorien übereinstimmen, die in den Daten vorhanden sind. Durch die Verwendung hierarchischer Partitionierung überwindet CURE die Einschränkungen traditioneller Clustering-Algorithmen, die voraussetzen, dass Cluster konvexe Formen haben.
Auswahl repräsentativer Punkte
CURE wählt mehrere repräsentative Punkte aus, um jeden Cluster darzustellen, anstatt von einem einzelnen Schwerpunkt abhängig zu sein. Diese Punkte, die sorgfältig aus dem Cluster ausgewählt werden, erfassen seine räumliche Ausdehnung und Struktur. CURE erreicht eine bessere Erkennung von Clustergrenzen und ein besseres Verständnis der internen Struktur, indem mehrere Punkte zur Darstellung jedes Clusters verwendet werden.
Nach der Auswahl repräsentativer Punkte bewegt der Algorithmus sie mit einem festgelegten Schrumpfungsbetrag in Richtung des Cluster-Mittels. Das Schrumpfungsverfahren macht den Algorithmus weniger reaktiv gegenüber Ausreißern, indem entfernte Punkte in Richtung der zentralen Punkte des Clusters bewegt werden.
Der Erfolg des Algorithmus hängt stark davon ab, wie viele repräsentative Punkte während der Ausführung verwendet werden. Die angemessene Auswahl repräsentativer Punkte ist entscheidend. Die Verwendung weniger repräsentativer Punkte kann die Komplexität des Clusters möglicherweise nicht erfassen, während die Verwendung zu vieler die Rechenkosten erhöhen kann.
Zusammenführen von Clustern
Nach der Identifizierung der repräsentativen Punkte führt der Algorithmus Cluster mithilfe eines systematischen iterativen Ansatzes zusammen. Das Verfahren hängt von der Messung der Distanz zwischen repräsentativen Punkten verschiedener Cluster ab. Vordefinierte Metriken, wie die euklidische Distanz, werden zur Messung von Distanzen verwendet, wodurch Konflikte bei der Suche nach den nächstgelegenen Clustern vermieden werden.
Der Algorithmus identifiziert bei jedem Bewertungsschritt, welche Clusterpaare die geringste Distanz auf Basis der Trennung der repräsentativen Punkte aufweisen. Der Algorithmus trifft genaue Entscheidungen zum Zusammenführen von Clustern und bewahrt dabei räumliche Beziehungen und natürliche Datenanordnungsmuster innerhalb der Cluster.
Der Prozess iteriert, bis bestimmte vorgegebene Cluster erreicht sind oder ein anderes Abbruchkriterium erfüllt ist. Das Abbruchkriterium hängt von Faktoren wie der Mindestdistanz zwischen Clustern oder der maximal zulässigen Ähnlichkeit innerhalb von Clustern ab. Dies stellt sicher, dass die erzeugten Cluster den natürlichen Gruppierungen in den Daten entsprechen und flexibel genug sind, um unregelmäßige und komplexe Formen zu erfassen.
Umgang mit Ausreißern
Wenn Ausreißer vorhanden sind, werden die Ergebnisse verzerrt, da sie falsche Clusterformen verursachen und die Datenstruktur fehlinterpretieren. Der CURE-Algorithmus löst diese Einschränkungen durch die Verwendung mehrerer repräsentativer Punkte, die die tatsächliche Form und Verteilung der Cluster genau identifizieren.
Der Schrumpfungsmechanismus stellt einen weiteren grundlegenden Fortschritt in CURE dar, der das System widerstandsfähiger macht und seine Ausgereiftheit erhöht. Diese gezielte Anpassung verringert die Empfindlichkeit des Algorithmus gegenüber Extremwerten, indem repräsentative Punkte in Richtung der Clusterzentren bewegt werden.
Der Schrumpfungsfaktor ist ein Tuning-Parameter, der es Benutzern ermöglicht, seinen Wert entsprechend den Eigenschaften des Datensatzes anzupassen. Dies ermöglicht eine flexible Abschwächung von Ausreißern bei gleichzeitiger Wahrung der natürlichen Clustergrenzen.
Vergleich mit anderen Clustering-Methoden
Der innovative Ansatz des CURE-Algorithmus unterscheidet ihn von anderen beliebten Clustering-Techniken. Hier ist ein tiefergehender Vergleich:
| Aspekt | CURE | k-means | DBSCAN |
| Repräsentation | Mehrere repräsentative Punkte | Einzelner Zentroid | Dichtebasiert |
| Ausreißerbehandlung | Hervorragend | Schlecht | Gut |
| Formflexibilität | Beliebige Formen | Nur konvexe Formen | Beliebige Formen |
| Skalierbarkeit | Hoch (mit Sampling) | Hoch | Moderat |
| Komplexität | Höher | Niedriger | Moderat |
Vorteile und Herausforderungen
Bei der Anwendung auf reale Szenarien bietet CURE eine Mischung aus Vorteilen und Herausforderungen. Lassen Sie uns besprechen, wie CURE Mehrwert bieten kann und gleichzeitig bestimmte Hürden in praktischen Anwendungen mit sich bringt.
Vorteile
Skalierbarkeit: CURE erreicht Skalierbarkeit durch seine Datensampling-Strategie, die den Rechenaufwand reduziert, ohne die Präzisionsgenauigkeit der Cluster zu beeinträchtigen.
Robustheit: CURE erhöht die Robustheit, indem es mehrere repräsentative Punkte verwendet, um die Form und Struktur eines Clusters zu erfassen. Dadurch liefert das Clustering zuverlässige und stabile Ergebnisse, selbst wenn die Daten verrauscht und inkonsistent sind.
Vielseitigkeit: CURE erfasst Cluster beliebiger Form und behandelt Unregelmäßigkeiten oder nicht-konvexe Strukturen. Dies ist besonders nützlich bei vielfältigen Datensätzen, bei denen traditionelle Techniken wie k-means sie nicht genau darstellen können.
Herausforderungen
Parametersensitivität: Der Algorithmus erfordert eine präzise Parameteranpassung für den Schrumpffaktor und die Anzahl der repräsentativen Punkte. Das richtige Gleichgewicht zu finden, ist entscheidend für optimale Leistung und erfordert sowohl Experimente als auch Domänenexpertise.
Sampling-Verzerrung: Unzureichende Sampling-Techniken führen zu ungenauer Clusterbildung und schlechten Ergebnissen. Die Aufrechterhaltung unverzerrter repräsentativer Stichproben ist wesentlich, um sicherzustellen, dass Datensatzstrukturen intakt bleiben.
Rechenanforderungen: Die Skalierbarkeitsherausforderungen von CURE nehmen bei großen, hochdimensionalen oder unstrukturierten Datensätzen zu, da mehrere Distanzbewertungen erforderlich sind. Techniken wie PCA und paralleles Rechnen können die Dimensionalität reduzieren, wodurch die Rechenkosten gesenkt und gleichzeitig wichtige Beziehungen erhalten bleiben.
Anwendungsfälle
Um die praktische Wirkung des CURE-Algorithmus zu verstehen, betrachten wir, wie er reale Clustering-Herausforderungen in verschiedenen Bereichen lösen kann.
Anomalieerkennung
CURE identifiziert effektiv Anomalien, indem typische Transaktionen gruppiert und unregelmäßige isoliert werden, die auf Betrug hinweisen können. Dies ermöglicht Finanzinstituten, verdächtige Aktivitäten schnell zu erkennen und ihre Sicherheitsmaßnahmen zu verbessern.
Marktsegmentierung
Im Marketing kann CURE Kunden anhand von Attributen wie Kaufverhalten, Demografie und Präferenzen segmentieren. Dies ermöglicht gezielte Marketingkampagnen, verbessert die Kundenbindung und sagt zukünftige Trends voraus. Beispielsweise können hochwertige Kunden für exklusive Angebote geclustert werden, um die Loyalität zu erhöhen.
Geodatenanalyse
Stadtplaner können CURE implementieren, um Regionen mit ähnlichen Klimabedingungen, Bevölkerungsdichten oder Infrastrukturentwicklungen zu kategorisieren. Umweltwissenschaftler können es nutzen, um Gebiete nach ihrer Biodiversität und Ressourcenverfügbarkeit zu clustern, während sie Ökosysteme untersuchen.
Dokument-Clustering
CURE zeigt eine ausgezeichnete Wirksamkeit im Text Mining, indem es umfangreiche Dokumentkataloge auf Grundlage ihrer Standardthemen und -inhalte gruppiert. Suchmaschinen nutzen diese Methode, um präzise Ergebniskategorien zu erstellen, die es Nutzern ermöglichen, relevante Inhalte schnell zu finden.
CURE ermöglicht es Empfehlungssystemen, Artikel und Forschungsarbeiten mit ähnlichen Themen zu identifizieren. Dies führt zu personalisierten, sinnvollen Empfehlungen für Nutzer. CURE kann vielfältige Textstrukturen effektiv clustern, um präzise Gruppierungsergebnisse unabhängig von der Komplexität und Größe hochdimensionaler Datensätze aufrechtzuerhalten. Der Algorithmus passt sich gut an mehrsprachige Textdatensätze und heterogene Dateneinträge an und positioniert sich damit als wesentliche Lösung für moderne Information-Retrieval-Plattformen.
Fazit
Der CURE-Clustering-Algorithmus stellt einen bedeutenden Durchbruch bei Clustering-Methoden dar. Er bietet eine effektive und skalierbare Lösung für moderne Datenprobleme. Der Algorithmus verwendet repräsentative Punkte zusammen mit hierarchischen Prinzipien, um traditionelle Clustering-Einschränkungen zu überwinden und gleichzeitig flexible und genaue Ergebnisse sicherzustellen. Während der Algorithmus Herausforderungen bei der Parameteroptimierung und den Rechenanforderungen gegenübersteht, ist seine Fähigkeit, verrauschte Daten und komplexe Muster zu verwalten, für mehrere Geschäftsbereiche unerlässlich.
Die wachsende Komplexität von Datensätzen wird den Bedarf an flexiblen Clustering-Algorithmen wie CURE in Zukunft weiter erhöhen. Data Scientists und Machine-Learning-Praktiker, die die Prinzipien von CURE verstehen, werden in der Lage sein, ihr Potenzial zur Gewinnung aussagekräftiger Erkenntnisse aus komplexen Datensätzen zu maximieren.
FAQs
- Was macht CURE im Vergleich zu k-means einzigartig?
CURE unterscheidet sich von k-means dadurch, dass es mehrere repräsentative Punkte anstelle eines einzelnen Cluster-Zentroids verwendet. Die Methode ermöglicht die Erkennung unregelmäßiger Clusterformen und nichtlinearer Muster in komplexen Datensätzen, ohne konvexe Clusterannahmen zu erfordern.
- Wie verarbeitet CURE große Datensätze?
CURE verwaltet große Datensätze durch Random-Sampling-Techniken, die den Rechenverarbeitungsaufwand minimieren. Die Sampling-Strategie ermöglicht es dem Algorithmus, reduzierte Daten-Teilmengen zu verarbeiten und dabei die Integrität der Clusterbeziehungen zu bewahren.
- Welche Rolle spielt der Shrink-Faktor in CURE?
Der CURE-Shrink-Faktor steuert die Entfernung, um die sich repräsentative Punkte in Richtung der mittleren Position ihres Clusters bewegen. Dieser Faktor ermöglicht es Nutzern, optimale Ergebnisse zwischen Genauigkeit und Robustheit zu erzielen. Der Erfolg von CURE-Implementierungen hängt stark davon ab, den richtigen Shrink-Faktor für jeden Datensatz zu finden.
- Kann CURE mit hochdimensionalen Daten arbeiten?
Die Verwendung von CURE-Algorithmen auf hochdimensionalen Daten erfordert eine vorherige Vorverarbeitung durch Techniken wie PCA. Die Verarbeitung hochdimensionaler Daten erfordert eine effiziente Dimensionsreduktion, um wesentliche Muster zu finden, selbst wenn die Einfachheit der Daten erhalten bleibt.
- Was sind die typischen Anwendungen von CURE?
Zu den typischen Anwendungen von CURE gehören Anomalieerkennung, Marktsegmentierung, georäumliche Analyse und Dokument-Clustering-Analyse. Es kann ungewöhnliche Finanzmuster zur Betrugserkennung identifizieren, Kunden nach Verhalten gruppieren und Regionen anhand von Merkmalen analysieren.
Verwandte Ressourcen
https://zilliz.com/ai-faq/how-are-embeddings-used-for-clustering
https://zilliz.com/ai-faq/how-does-clustering-improve-vector-search
https://zilliz.com/ai-faq/how-does-swarm-intelligence-improve-data-clustering
https://zilliz.com/ai-faq/what-is-graph-clustering-in-knowledge-graphs
https://zilliz.com/ai-faq/what-are-the-most-common-algorithms-for-anomaly-detection
- Verständnis des CURE-Algorithmus: Eine umfassende Untersuchung des Clusterings mit Repräsentanten
- Was ist der CURE-Algorithmus?
- Wie es funktioniert
- Prozessablauf des CURE-Clustering-Algorithmus
- Vergleich mit anderen Clustering-Methoden
- Vorteile und Herausforderungen
- Anwendungsfälle
- Fazit
- FAQs
- Verwandte Ressourcen
Inhalte
Kostenlos starten, einfach skalieren
Testen Sie die vollständig verwaltete Vektordatenbank, die für Ihre GenAI-Anwendungen entwickelt wurde.
Zilliz Cloud kostenlos ausprobieren