




Exa baut Entity-Suchmaschine für KI-Agenten mit Zilliz Cloud
<200 ms Suchlatenz
Exas neuronale Suchlatenz wurde mit Zilliz' hybrider Suche von Sekunden auf unter 200 ms reduziert
Hohe Zuverlässigkeit
Nahezu keine betrieblichen Vorfälle, wodurch Engineering-Zeit für die Produktarbeit frei wird
Keine Ausfallzeit bei Schemaänderungen
Neue filterbare Felder und Metadaten können hinzugefügt werden, ohne Indizes neu zu erstellen oder Sammlungen offline zu nehmen
We believe AI agents will become a fundamental interface for how people work, learn, and make decisions, and that only happens if those systems can access real-world information with speed, precision, and trust. That’s what we’re building at Exa. Aside from web search, Exa also operates entity search, and Zilliz Cloud has been an important part of that journey, giving us the retrieval performance and operational simplicity we need to scale our entity search product quickly and confidently.
Jeffrey Wang
Die Suche für KI-Agenten klingt wie eine natürliche Erweiterung der Websuche, doch in der Praxis erfordert sie einen anderen Produktstandard. Agenten benötigen nicht nur Links; sie brauchen fundierte, aktuelle, strukturierte Informationen, die schnell genug bereitgestellt werden, um reale Workflows zu unterstützen, von Sprachinteraktionen bis hin zu tiefgehenden Rechercheaufgaben.
Exa baut genau diese Art von Suchmaschine für KI. Die Search API bietet Entwicklern Zugriff auf hochwertige Websuche mit niedriger Latenz über ein breites Spektrum von Rechenlatenzen hinweg, von Sofortsuche für Sprachagenten bis hin zu tiefergehender Recherche mit strukturierten Ausgaben und Anreicherungen. Exa bedient Kunden von KI-nativen Startups wie Cursor und Lovable bis hin zu Unternehmen wie AWS, die alle auf fundierten, realweltlichen Kontext für agentengesteuerte Workflows angewiesen sind.
Während Exa in die Entitätensuche für Unternehmen, Personen und Code expandiert, stand es vor einer spezielleren Infrastrukturherausforderung: Wie lassen sich hybride Retrieval-Verfahren, umfangreiches Metadata-Filtering, häufige Aktualisierungen und Latenz im Millisekundenbereich unterstützen, ohne den Engineering-Fokus von der zentralen Suchmaschine abzulenken? Genau diese Rolle spielt Zilliz Cloud (fully managed Milvus) in der folgenden Geschichte.
| 200ms Niedrige Suchlatenz | Hybride Suche, die Dense Vectors, Sparse Vectors, RRF-Reranking und Metadata-Filter in einem einzigen API-Aufruf kombiniert. Exa Instant reduzierte die Latenz der neuronalen Suche von Sekunden auf unter 200ms |
| Hohe Zuverlässigkeit | Der Managed Service hat nahezu null Betriebsstörungen geliefert und dadurch Engineering-Zeit für Produktarbeit freigesetzt |
| Keine Downtime bei Schemaänderungen | Neue filterbare Felder und Metadaten können hinzugefügt werden, ohne Indizes neu aufzubauen oder Collections offline zu nehmen |
Unten finden Sie das Skript aus einem Gespräch mit Exa über seine Produktmission, den Wandel von allgemeiner Websuche hin zu Entitätensuche und darüber, wie Zilliz Cloud in diese Entwicklung passt.
1. Exas Produktversprechen: fundierte Suche für KI-Agenten
Wir begannen damit, Exa zu bitten, das Produkt zu beschreiben, das es entwickelt, sowie die Kunden, die es bedient, denn dieser Kontext erklärt, warum Retrieval-Qualität und Latenz für das Unternehmen keine zweitrangigen Aspekte sind.
Q: Welches Produkt oder welchen Service bietet Exa an, und wer sind Ihre primären Kunden?
Exa: Exa baut die Suchmaschine für KI. Wir haben eine Search API entwickelt, die Entwicklern Zugriff auf hochwertige Websuche mit niedriger Latenz für ihre Agenten ermöglicht. Unsere API bietet Suche über das gesamte Spektrum der Rechenlatenz hinweg, von sofortigen (<200ms) Suchen für Sprachagenten bis hin zu tiefergehender Recherche mit strukturierten Ausgaben und Anreicherungen. Wir sind auf Code-Suche, niedrige Latenz sowie Personen-/Unternehmenssuche spezialisiert, mit Hervorhebungen, die Token-Effizienz sicherstellen.
Wir haben unsere Suchmaschine von Grund auf mit neuartigen neuronalen Architekturen aufgebaut, statt uns auf Legacy-Suchmaschinen zu verlassen. Eine eigene Suchmaschine zu entwickeln erfordert alles vom Training von Embedding-Modellen und Rerankern bis hin zum Crawling und Indexieren von Milliarden von Webseiten. Diese End-to-End-Verantwortung ermöglicht es uns, jede Ebene des Stacks auf Qualität und Geschwindigkeit zu optimieren. Beim jüngsten Launch von Exa Instant haben wir beispielsweise eine Suchlatenz von <200ms erreicht – eine deutliche Verbesserung, die neuronale Suche als Echtzeit-Baustein für KI-Agenten praktikabel macht. Die Kombination aus Qualität, Geschwindigkeit und Anpassbarkeit ist ein entscheidendes Unterscheidungsmerkmal.
Unsere Kunden reichen von KI-nativen Unternehmen wie Cursor und Lovable bis hin zu großen Enterprises. Jedes Unternehmen, das Agenten nutzt, um Wissensarbeit voranzutreiben, benötigt fundierten Kontext, um auf die reale Welt zu reagieren. Daher arbeiten wir unabhängig von der Unternehmensgröße mit Teams zusammen, die agentengesteuerte Workflows priorisieren.
2. Der Wendepunkt: von Websuche zu Entitätensuche
Dieser Produktkontext verdeutlicht auch, warum Exas Datenbankentscheidung nicht darin bestand, seinen zentralen Search Stack zu ersetzen. Vector Search war bereits grundlegend für das Unternehmen. Die eigentliche Veränderung kam, als die Entitätensuche neue Anforderungen mit sich brachte.
F: An welchem Punkt Ihrer Produktreise haben Sie erkannt, dass Sie eine Vektordatenbank benötigen?
Exa: Da unsere Suchmaschine auf Embeddings und Vektorähnlichkeit aufgebaut war, war die Vektorsuche von Anfang an ein integraler Bestandteil von Exas Tech-Stack. Als wir in die Entitätssuche expandierten, mussten wir unsere Vektordatenbank-Infrastruktur aktualisieren, um die strukturierten Ausgaben und Anreicherungen zu unterstützen, die wir nun anboten.
Die Entitätssuche erfordert umfangreiche Metadatenschemata, häufige Datenaktualisierungen und verwaltete Skalierbarkeit. Unsere interne Datenbank war für diese aktualisierten Anforderungen optimiert, aber wir wollten die Iterationsgeschwindigkeit über diese Entitätssuchschicht hinweg weiter verbessern, was uns dazu veranlasste, Zilliz Cloud zu nutzen. Unser zentraler Webindex verbleibt auf unserer internen Infrastruktur, und Zilliz Cloud wurde speziell hinzugezogen, um diese Entitätssuchschicht zu betreiben.
F: Welche Herausforderungen oder Anforderungen hatten Sie mit Ihrer vorherigen Lösung?
Exa: Als wir mit dem Aufbau der Entitätssuche begannen, waren die Anforderungen sehr unterschiedlich: hybride Suche, die dichte und spärliche Vektoren kombiniert, umfangreiche und sich häufig ändernde Metadatenschemata sowie der operative Aufwand für die Verwaltung mehrerer spezialisierter Collections. Wir suchten nach einer verwalteten Lösung, die es unseren Ingenieuren ermöglicht, schnell zu iterieren und schnelle Antworten in großem Maßstab zu unterstützen.
F: Welche konkreten Anwendungsfälle lösen Sie mit Vektorsuche/Vektordatenbank?
Exa: Heute betreibt Zilliz Cloud unsere Entitätssuchschicht und dient sowohl als primärer Index als auch als Aktualitäts-Cache über Entitäts-Collections hinweg, während unser Haupt-Webindex auf separater interner Infrastruktur läuft. Jede Vertikale erfordert latenzarme, gefilterte Suche über häufig aktualisierte Daten, wobei Zilliz’ verwaltetes hybrides Retrieval und Hot-Upsert-Funktionen die Ergebnisse aktuell halten, ohne Indizes neu aufzubauen. Diese Vertikalen fließen direkt in unsere Search API ein, daher sind Geschwindigkeit und Recall geschäftskritisch.
3. Was Exa von einer verwalteten Vektor-Retrieval-Schicht benötigte
Sobald die Entitätssuche zu einer eigenständigen Schicht wurde, ging es bei der Bewertung wirklich um die Passung: Konnte ein verwaltetes System Exas Anspruch an Suchqualität unterstützen, ohne das Team auszubremsen oder architektonische Kompromisse zu erzwingen?
F: Welche Vektordatenbanken haben Sie evaluiert, bevor Sie sich für Zilliz Cloud entschieden haben? Was waren die wichtigsten Kriterien bei Ihrer Bewertung?
Exa: Als wir mit dem Aufbau der Entitätssuche begannen, waren die Anforderungen sehr unterschiedlich: hybride Suche, die dichte und spärliche Vektoren kombiniert, umfangreiche, sich häufig ändernde Metadatenschemata sowie der operative Aufwand für die Verwaltung mehrerer spezialisierter Collections. Wir suchten nach einer verwalteten Lösung, die es unseren Ingenieuren ermöglicht, schnell zu iterieren und schnelle Antworten in großem Maßstab zu unterstützen.
Wir haben alle wichtigen Vektordatenbank-Optionen in diesem Bereich geprüft. Unsere wichtigsten Kriterien waren:
Unterstützung für hybride Suche: Native Fähigkeit, dichte semantische Vektoren mit spärlichen Keyword-Vektoren in einer einzigen Abfrage zu kombinieren, mit integriertem Reranking
Abfragelatenz: Konsistent schnelle Antworten über Collections mit zig Millionen Vektoren hinweg
Umfangreiches Metadaten-Filtering: Komplexe Filter auf strukturierten Feldern, ohne die Suchleistung zu beeinträchtigen
Skalierbarkeit: Nahtlose Skalierung, wenn wir neue Verticals und Datenquellen hinzufügen
Zilliz Cloud erfüllte alle Anforderungen, und seine Leistung bei Benchmarks für hybride Suche lag klar vor dem Feld.
F: Wie haben Sie zum ersten Mal von Zilliz Cloud / Milvus gehört?
Exa: Wir kennen Milvus schon seit langer Zeit, da es eine der ausgereiftesten Open-Source-Vektordatenbanken ist, und als Team, das Vektorsuche lebt und atmet, kommt man kaum daran vorbei. Als wir begannen, unsere Infrastruktur für die Entitätssuche abzustecken, stach Zilliz Cloud als das natürliche verwaltete Angebot auf Basis von Milvus hervor, mit Performance-Verbesserungen auf Enterprise-Niveau.
F: Was ist Ihnen während Ihrer Bewertung an Zilliz Cloud aufgefallen? Was waren die wichtigsten Gründe, die Sie dazu veranlasst haben, Zilliz Cloud zu wählen?
Exa: Ein paar Dinge fielen sofort auf.
Native hybride Suche: Zilliz Cloud unterstützt dichte und spärliche Vektorsuche in einem einzigen API-Aufruf, mit integrierten Reranking-Strategien (RRF, gewichtet). Dies war eine harte Anforderung für mehrere Wettbewerber, und wir unterstützten es nicht nativ.
Performance in großem Maßstab – ihre Cardinal-Indexierungs-Engine liefert konstant schnelle Abfragezeiten, selbst wenn unsere Collections auf Hunderte Millionen Vektoren anwachsen.
Ausgereiftes Filtering – die Fähigkeit, Vektorsuche mit komplexen Metadatenfiltern in einer einzigen Anfrage zu kombinieren, ohne Performance-Einbruch.
In Bezug auf die entscheidenden Faktoren für die Einführung:
Geschwindigkeit – die Abfragelatenz von Zilliz Cloud erfüllte unsere strengen Anforderungen an die Produktionssuche. Unsere Nutzer erwarten Ergebnisse in Millisekunden, und Zilliz kann dies unterstützen.
Hybride Suchfunktionen – die Fähigkeit, dichte semantische Suche mit spärlichem BM25-Keyword-Matching zu verschmelzen und Reciprocal Rank Fusion (RRF)-Reranking in einem einzigen API-Aufruf anzuwenden, war wichtig für die Suchqualität.
Betriebliche Einfachheit – als vollständig verwalteter Service ermöglicht Zilliz Cloud unserem Team, sich auf den Aufbau besserer Sucherlebnisse zu konzentrieren und Verbesserungen an der Vektordatenbank-Infrastruktur in großem Maßstab schnell zu iterieren.
4. Wie die Architektur von Zilliz und Exa zusammenpasst
Q: Wie passt Zilliz Cloud in eure Architektur?
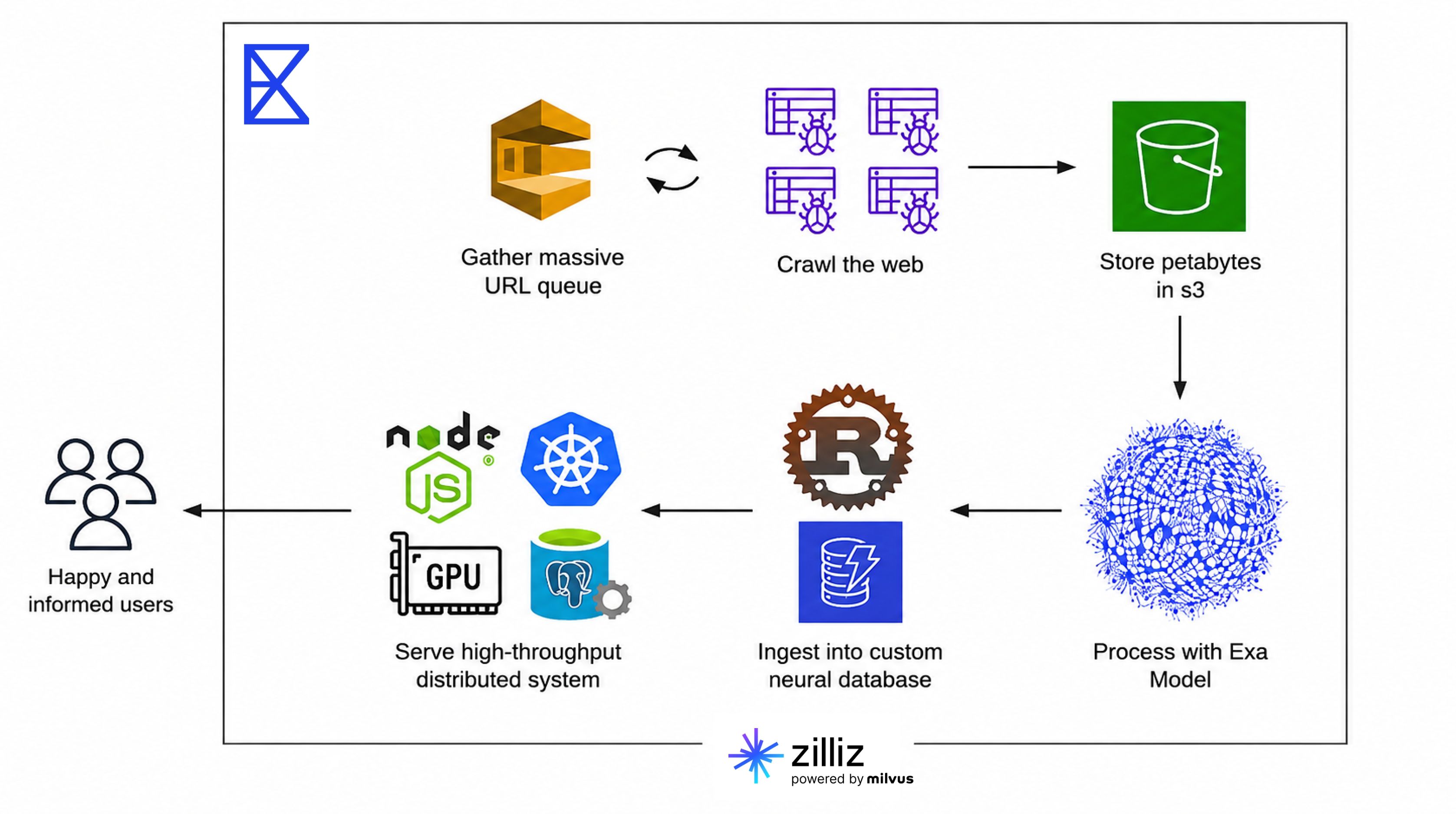
Exa: Unsere Entity-Search-Architektur umfasst drei Ebenen: Ingestion, Suche und API.
Bei der Ingestion reichern wir Entity-Daten an und betten sie mithilfe unserer eigenen ML-Pipelines ein, dann upserten wir dichte und spärliche Vektoren in Zilliz Cloud.
In der Suche generiert unser Backend Embeddings aus Nutzeranfragen und sendet hybride Suchanfragen an Zilliz Cloud, wobei semantisches und Keyword-Matching mit RRF-Reranking kombiniert werden.
In der API-Ebene werden Ergebnisse mit strukturierten Metadaten angereichert und über unsere Search API und unser Websets-Produkt bereitgestellt. Zilliz Cloud steht im Zentrum des Retrievals für diesen Workflow: Es speichert alle Entity-Vektoren und Metadaten und übernimmt die Suche mit niedriger Latenz. Unser primärer Webindex wird auf einer separaten, intern entwickelten Infrastruktur aufgebaut und verwaltet.
Q: Wie waren die Erfahrungen eures Teams mit Zilliz Cloud oder Milvus?
Exa: Die API ist intuitiv, die Dokumentation ist solide, und das System war in der Produktion zuverlässig. Die Lernkurve war minimal, weil die Milvus-Konzepte: Collections, Indizes, Suchparameter, gut zu unserer bestehenden Denkweise über Vektorsuche passen. Die verwaltete Natur von Zilliz Cloud bedeutet, dass wir nur sehr wenige betriebliche Vorfälle bewältigen mussten.
Q: Wie war die Erfahrung bei der Integration von Zilliz Cloud mit AWS oder anderen Cloud-Services?
Exa: Nahtlos. Wir betreiben unsere Infrastruktur hauptsächlich auf AWS, und Zilliz Cloud fügt sich sauber in diesen AWS-nativen Stack ein. Da es auf AWS läuft, ist die Netzwerklatenz zwischen unseren EKS-Services und Zilliz Cloud minimal.
5. Was sich nach der Einführung geändert hat
Q: Was sind die 3 wichtigsten Vorteile, die ihr gesehen habt? Könnt ihr messbare Kennzahlen oder Verbesserungen teilen?
Exa: Der erste Vorteil war die Entwicklungsgeschwindigkeit: Der verwaltete Service und die saubere API bedeuteten, dass unser Team neue Entity-Search-Vertikalen schnell ausliefern konnte, ohne zusätzliche Infrastruktur aufzubauen oder zu verwalten.
Darüber hinaus waren Schema-Flexibilität und Anpassungsfähigkeit sehr wichtig, da sich diese vertikalen Datensätze weiterentwickeln, und die Suchqualität durch Autoindex war in der Praxis ebenfalls wertvoll.
Q: Welche Funktionen von Zilliz Cloud findet ihr am wertvollsten?
Exa: Zwei Dinge stechen im täglichen Gebrauch am meisten hervor.
Filtering ohne Performance-Einbruch: Komplexe Metadatenfilter, die mit vernachlässigbarem Latenzeinfluss auf die Vektorsuche gelegt werden.
Schnelle vertikale Launches: Verwaltete Skalierung ermöglicht es uns, neue Such-Vertikalen schnell auszuliefern, ohne jedes Mal neue Infrastruktur aufzubauen.
Erste Schritte mit Zilliz Cloud
Zilliz ist der Entwickler von Milvus, der weltweit beliebtesten Open-Source-Vektordatenbank, und Zilliz Cloud, dem vollständig verwalteten Vektordatenbankdienst, der auf Milvus basiert. Zilliz Cloud ermöglicht es Unternehmen, produktionsreife KI-Anwendungen mit leistungsstarker Vektorsuche, hybrider Abfrage sowie Sicherheit und Compliance auf Unternehmensniveau zu entwickeln.
- Starten Sie kostenlos mit Zilliz Cloud mit einem Guthaben von 100 USD bei der Registrierung mit einer geschäftlichen E-Mail-Adresse
- 1. Exas Produktversprechen: fundierte Suche für KI-Agenten
- 2. Der Wendepunkt: von Websuche zu Entitätensuche
- 3. Was Exa von einer verwalteten Vektor-Retrieval-Schicht benötigte
- 4. Wie die Architektur von Zilliz und Exa zusammenpasst
- 5. Was sich nach der Einführung geändert hat
- Erste Schritte mit Zilliz Cloud
Inhalte
Anwendungsfall
Branche
KI-Infrastruktur