




Wie Airtable mit Milvus eine Vektorinfrastruktur aufgebaut und skaliert hat

Abfragen mit niedriger Latenz
Vorhersehbare Leistung ist entscheidend für das Vertrauen der Nutzer
Schreibvorgänge mit hohem Durchsatz
Datenbestände ändern sich ständig, und Embeddings müssen synchron bleiben
Horizontale Skalierbarkeit
das System muss Millionen unabhängiger Basen unterstützen
Dieser Beitrag wurde ursprünglich im Airtable Medium Kanal veröffentlicht und wird hier mit Genehmigung erneut veröffentlicht.
Als sich die semantische Suche bei Airtable von einem Konzept zu einer zentralen Produktfunktion entwickelte, stand das Data-Infrastructure-Team vor der Herausforderung, sie zu skalieren. Wie in unserem vorherigen Beitrag zum Aufbau des Embedding-Systems beschrieben, hatten wir bereits eine robuste, letztendlich konsistente Anwendungsschicht entworfen, um den Lebenszyklus der Embeddings zu verwalten. Doch ein entscheidendes Element fehlte noch in unserem Architekturdiagramm: die Vektordatenbank selbst.
Wir benötigten eine Storage Engine, die Milliarden von Embeddings indexieren und bereitstellen, massive Mandantenfähigkeit unterstützen und Leistungs- sowie Verfügbarkeitsziele in einer verteilten Cloud-Umgebung einhalten konnte. Dies ist die Geschichte, wie wir unsere Vektorsuchplattform konzipiert, gehärtet und weiterentwickelt haben, damit sie zu einer zentralen Säule des Infrastruktur-Stacks von Airtable wurde.
Hintergrund
Bei Airtable ist es unser Ziel, Kunden dabei zu helfen, auf leistungsstarke und intuitive Weise mit ihren Daten zu arbeiten. Mit dem Aufkommen zunehmend leistungsfähiger und präziser LLMs sind Funktionen, die die semantische Bedeutung Ihrer Daten nutzen, zu einem Kernbestandteil unseres Produkts geworden.
Wie wir semantische Suche nutzen
Omni (Airtables AI Chat) beantwortet echte Fragen aus großen Datensätzen
Stellen Sie sich vor, Sie stellen Ihrer Base (Datenbank) mit einer halben Million Zeilen eine Frage in natürlicher Sprache und erhalten eine korrekte, kontextreiche Antwort. Zum Beispiel:
„Was sagen Kunden in letzter Zeit über die Akkulaufzeit?“
Bei kleinen Datensätzen ist es möglich, alle Zeilen direkt an ein LLM zu senden. Im großen Maßstab wird das schnell undurchführbar. Stattdessen benötigten wir ein System, das Folgendes leisten kann:
- Die semantische Absicht einer Anfrage verstehen
- Die relevantesten Zeilen über Vektorähnlichkeitssuche abrufen
- Diese Zeilen einem LLM als Kontext bereitstellen
Diese Anforderung prägte nahezu jede folgende Designentscheidung: Omni musste sich sofort verfügbar und intelligent anfühlen, selbst bei sehr großen Bases.
Empfehlungen für verknüpfte Datensätze: Bedeutung statt exakter Übereinstimmungen
Semantische Suche verbessert auch eine zentrale Airtable-Funktion: verknüpfte Datensätze. Benutzer benötigen Beziehungsvorschläge basierend auf Kontext statt auf exakten Textübereinstimmungen. Beispielsweise könnte eine Projektbeschreibung eine Beziehung zu „Team Infrastructure“ implizieren, ohne jemals genau diesen Ausdruck zu verwenden.
Die Bereitstellung dieser On-Demand-Vorschläge erfordert hochwertigen semantischen Abruf mit konsistenter, vorhersehbarer Latenz.
Unsere Designprioritäten
Um diese und weitere Funktionen zu unterstützen, haben wir das System an 4 Zielen ausgerichtet:
- Abfragen mit niedriger Latenz (500 ms p99): vorhersehbare Leistung ist entscheidend für das Vertrauen der Benutzer
- Schreibvorgänge mit hohem Durchsatz: Bases ändern sich ständig, und Embeddings müssen synchron bleiben
- Horizontale Skalierbarkeit: das System muss Millionen unabhängiger Bases unterstützen
- Self-Hosting: Alle Kundendaten müssen innerhalb der von Airtable kontrollierten Infrastruktur bleiben
Diese Ziele prägten jede folgende Architekturentscheidung.
Evaluierung von Anbietern für Vektordatenbanken
Ende 2024 bewerteten wir mehrere Optionen für Vektordatenbanken und entschieden uns schließlich auf Grundlage von drei zentralen Anforderungen für Milvus.
- Erstens priorisierten wir eine selbst gehostete Lösung, um Datenschutz zu gewährleisten und die feinkörnige Kontrolle über unsere Infrastruktur zu behalten.
- Zweitens erforderte unsere schreibintensive Workload und unsere sprunghaften Abfragemuster ein System, das elastisch skalieren und gleichzeitig niedrige, vorhersehbare Latenz beibehalten konnte.
- Schließlich erforderte unsere Architektur eine starke Isolation über Millionen von Kundenmandanten hinweg.
Milvus erwies sich als die beste Wahl: Seine verteilte Natur unterstützt massive Mandantenfähigkeit und ermöglicht es uns, Ingestion, Indexierung und Abfrageausführung unabhängig voneinander zu skalieren, wodurch Leistung bereitgestellt wird und die Kosten zugleich vorhersehbar bleiben.
Architekturdesign
Nach der Auswahl einer Technologie mussten wir dann eine Architektur bestimmen, um Airtables einzigartige Datenform abzubilden: Millionen unterschiedlicher „Bases“, die verschiedenen Kunden gehören.
Die Partitionierungsherausforderung
Wir bewerteten zwei primäre Strategien zur Datenpartitionierung:
Option 1: Gemeinsame Partitionen
Mehrere Bases teilen sich eine Partition, und Abfragen werden durch Filtern nach einer Base-ID eingegrenzt. Dies verbessert die Ressourcennutzung, bringt jedoch zusätzlichen Filteraufwand mit sich und macht das Löschen von Bases komplexer.
Option 2: Eine Base pro Partition
Jede Airtable-Base wird ihrer eigenen physischen Partition in Milvus zugeordnet. Dies bietet starke Isolation, ermöglicht schnelles und einfaches Löschen von Bases und vermeidet die Leistungseinbußen durch Filterung nach der Abfrage.
Endgültige Strategie
Wir entschieden uns wegen der Einfachheit und starken Isolation für Option 2. Frühe Tests zeigten jedoch, dass das Erstellen von 100k Partitionen in einer einzigen Milvus-Collection zu einer erheblichen Leistungsverschlechterung führte:
- Die Latenz bei der Partitionserstellung stieg von ~20 ms auf ~250 ms
- Die Ladezeiten von Partitionen überschritten 30 Sekunden
Um dies zu beheben, begrenzten wir die Anzahl der Partitionen pro Collection. Für jeden Milvus-Cluster erstellen wir 400 Collections mit jeweils höchstens 1.000 Partitionen. Dadurch wird die Gesamtzahl der Bases pro Cluster auf 400k begrenzt, und neue Cluster werden bereitgestellt, sobald zusätzliche Kunden aufgenommen werden.
Indizierung & Recall
Die Wahl des Index stellte sich als einer der folgenreichsten Kompromisse in unserem System heraus. Wenn eine Partition geladen wird, wird ihr Index im Speicher oder auf der Festplatte zwischengespeichert. Um ein Gleichgewicht zwischen Recall-Rate, Indexgröße und Leistung zu finden, benchmarkten wir mehrere Indextypen.
- IVF-SQ8: Bot einen kleinen Speicherbedarf, aber einen geringeren Recall.
- HNSW: Liefert den besten Recall (99%-100%), ist aber speicherhungrig.
- DiskANN: Bietet einen ähnlichen Recall wie HNSW, jedoch mit höherer Abfragelatenz
Letztendlich wählten wir HNSW wegen seines überlegenen Recalls und seiner Leistungsmerkmale.
Die Anwendungsschicht
Auf hoher Ebene umfasst Airtables semantische Suchpipeline zwei zentrale Abläufe:
- Ingestion-Ablauf: Airtable-Zeilen in Embeddings umwandeln und in Milvus speichern
- Abfrageablauf: Nutzerabfragen einbetten, relevante Zeilen-IDs abrufen und dem LLM Kontext bereitstellen
Beide Abläufe müssen kontinuierlich und zuverlässig im großen Maßstab betrieben werden, und wir gehen unten auf jeden ein. Wir gehen unten auf jeden ein.
Ingestion-Ablauf: Milvus mit Airtable synchron halten
Wenn ein Nutzer Omni öffnet, beginnt Airtable damit, seine Base mit Milvus zu synchronisieren. Wir erstellen eine Partition und verarbeiten dann die Zeilen in Blöcken, erzeugen Embeddings und führen Upserts in Milvus durch. Von da an erfassen wir alle an der Base vorgenommenen Änderungen und re-embedden und upserten diese Zeilen, um die Daten konsistent zu halten.
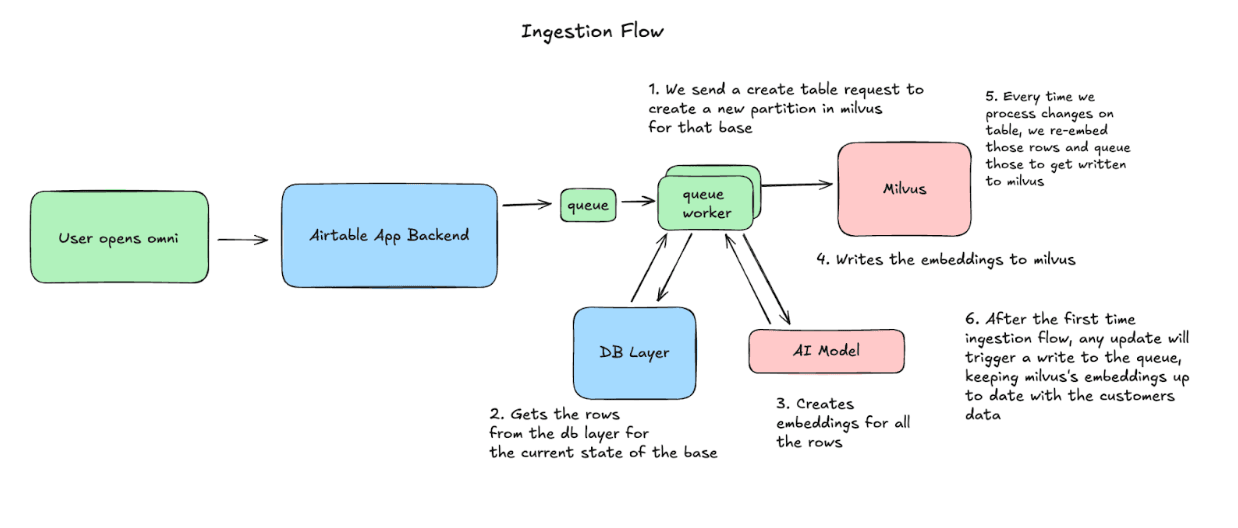
Abfrageablauf: Wie wir die Daten verwenden
Auf der Abfrageseite betten wir die Anfrage des Nutzers ein und senden sie an Milvus, um die relevantesten Zeilen-IDs abzurufen. Anschließend holen wir die neuesten Versionen dieser Zeilen und fügen sie als Kontext in die Anfrage an das LLM ein.
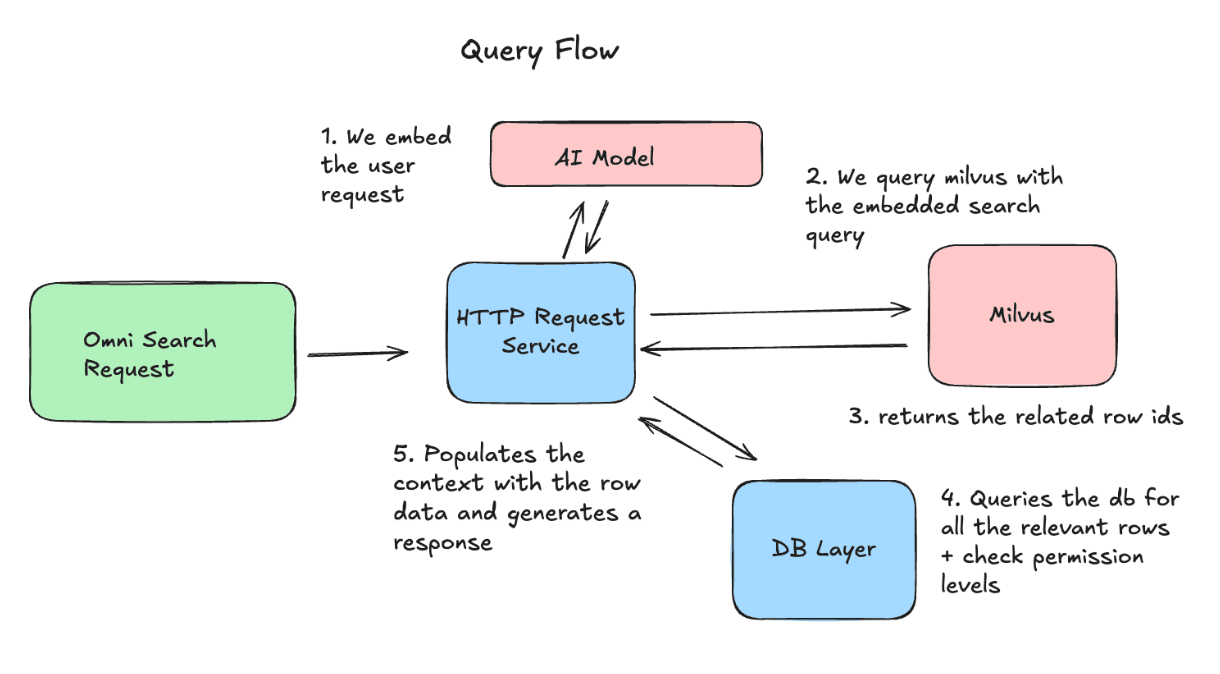
Betriebliche Herausforderungen & Wie wir sie gelöst haben
Eine Architektur für semantische Suche zu entwickeln, ist eine Herausforderung; sie zuverlässig für Hunderttausende von Bases zu betreiben, ist eine andere. Unten finden sich einige wichtige betriebliche Erkenntnisse, die wir auf dem Weg gewonnen haben.
Deployment
Wir deployen Milvus über seine Kubernetes-CRD mit dem Milvus operator, wodurch wir Cluster deklarativ definieren und verwalten können. Jede Änderung, ob es sich um ein Konfigurationsupdate, eine Client-Verbesserung oder ein Milvus-Upgrade handelt, durchläuft Unit-Tests und einen On-Demand-Lasttest, der Produktionsverkehr simuliert, bevor sie für Nutzer ausgerollt wird.
In Version 2.5 besteht der Milvus-Cluster aus diesen Kernkomponenten:
- Query Nodes halten die Vektorindizes im Arbeitsspeicher und führen Vektorsuchen aus
- Data Nodes übernehmen Ingestion und Kompaktierung und persistieren neue Daten im Speicher
- Index Nodes erstellen und pflegen Vektorindizes, damit die Suche auch bei wachsender Datenmenge schnell bleibt
- Der Coordinator Node orchestriert alle Cluster-Aktivitäten und die Shard-Zuweisung
- Proxy Nodes leiten API-Traffic weiter und verteilen die Last über die Nodes
- Kafka stellt das Log-/Streaming-Rückgrat für interne Nachrichten und Datenflüsse bereit
- Etcd speichert Cluster-Metadaten und den Koordinationszustand
Mit CRD-gesteuerter Automatisierung und einer rigorosen Test-Pipeline können wir Updates schnell und sicher ausrollen.
Observability: Systemzustand End-to-End verstehen
Wir überwachen das System auf zwei Ebenen, um sicherzustellen, dass die semantische Suche schnell und vorhersehbar bleibt.
Auf Infrastrukturebene verfolgen wir CPU-, Speicherauslastung und Pod-Zustand über alle Milvus-Komponenten hinweg. Diese Signale zeigen uns, ob der Cluster innerhalb sicherer Grenzen arbeitet, und helfen uns, Probleme wie Ressourcensättigung oder fehlerhafte Nodes zu erkennen, bevor sie Nutzer beeinträchtigen.
Auf Service-Ebene konzentrieren wir uns darauf, wie gut jede Base mit unseren Ingestion- und Query-Workloads Schritt hält. Metriken wie Kompaktierungs- und Indexierungsdurchsatz geben uns Einblick darin, wie effizient Daten aufgenommen werden. Query-Erfolgsraten und Latenz geben uns ein Verständnis der Nutzererfahrung beim Abfragen der Daten, und das Partitionswachstum zeigt uns, wie unsere Daten wachsen, sodass wir benachrichtigt werden, wenn wir skalieren müssen.
Node-Rotation
Aus Sicherheits- und Compliance-Gründen rotieren wir regelmäßig Kubernetes-Nodes. In einem Vektorsuch-Cluster ist das nicht trivial:
- Während die Query Nodes rotiert werden, gleicht der Coordinator die In-Memory-Daten zwischen den Query Nodes neu aus
- Kafka und Etcd speichern zustandsbehaftete Informationen und benötigen Quorum und kontinuierliche Verfügbarkeit
Wir begegnen dem mit strikten Disruption Budgets und einer Rotationsrichtlinie von jeweils einem Node. Dem Milvus-Coordinator wird Zeit gegeben, den Ausgleich vorzunehmen, bevor der nächste Node ausgetauscht wird. Diese sorgfältige Orchestrierung erhält die Zuverlässigkeit, ohne unsere Geschwindigkeit zu verlangsamen.
Auslagern kalter Partitionen
Einer unserer größten operativen Erfolge war die Erkenntnis, dass unsere Daten klare Hot-/Cold-Zugriffsmuster aufweisen. Durch die Analyse der Nutzung stellten wir fest, dass nur ~25% der Daten in Milvus in einer bestimmten Woche geschrieben oder gelesen werden. Milvus ermöglicht es uns, ganze Partitionen auszulagern und so Arbeitsspeicher auf den Query Nodes freizugeben. Wenn diese Daten später benötigt werden, können wir sie innerhalb von Sekunden wieder laden. Dadurch können wir heiße Daten im Arbeitsspeicher halten und den Rest auslagern, was Kosten senkt und es uns ermöglicht, im Laufe der Zeit effizienter zu skalieren.
Datenwiederherstellung
Bevor wir Milvus breit ausrollten, brauchten wir die Gewissheit, dass wir uns schnell von jedem Ausfallszenario erholen können. Während die meisten Probleme durch die integrierte Fehlertoleranz des Clusters abgedeckt sind, planten wir auch für seltene Fälle, in denen Daten beschädigt werden könnten oder das System in einen nicht wiederherstellbaren Zustand geraten könnte.
In solchen Situationen ist unser Wiederherstellungspfad unkompliziert. Zuerst starten wir einen frischen Milvus-Cluster, damit wir den Traffic nahezu sofort wieder bedienen können. Sobald der neue Cluster live ist, betten wir die am häufigsten genutzten Bases proaktiv neu ein und verarbeiten den Rest dann nach Bedarf, wenn darauf zugegriffen wird. Das minimiert die Ausfallzeit für die am häufigsten abgerufenen Daten, während das System schrittweise einen konsistenten semantischen Index neu aufbaut.
Wie geht es weiter
Unsere Arbeit mit Milvus hat eine starke Grundlage für semantische Suche bei Airtable geschaffen: Sie ermöglicht schnelle, aussagekräftige KI-Erlebnisse in großem Maßstab. Mit diesem System sind wir nun dabei, umfangreichere Retrieval-Pipelines und tiefere KI-Integrationen im gesamten Produkt zu erkunden. Es liegt noch viel spannende Arbeit vor uns, und wir fangen gerade erst an.
Vielen Dank an alle ehemaligen und aktuellen Airtablets in Data Infrastructure und im gesamten Unternehmen, die zu diesem Projekt beigetragen haben: Alex Sorokin, Andrew Wang, Aria Malkani, Cole Dearmon-Moore, Nabeel Farooqui, Will Powelson, Xiaobing Xia.
Über Airtable
Airtable ist eine führende Plattform für digitale Betriebsabläufe, die es Organisationen ermöglicht, benutzerdefinierte Apps zu erstellen, Workflows zu automatisieren und gemeinsame Daten auf Enterprise-Niveau zu verwalten. Airtable wurde entwickelt, um komplexe, funktionsübergreifende Prozesse zu unterstützen, und hilft Teams dabei, flexible Systeme für Planung, Koordination und Ausführung auf einer gemeinsamen Quelle der Wahrheit aufzubauen. Während Airtable seine KI-gestützte Plattform erweitert, spielen Technologien wie Milvus eine wichtige Rolle bei der Stärkung der Retrieval-Infrastruktur, die erforderlich ist, um schnellere, intelligentere Produkterlebnisse bereitzustellen.
- Hintergrund
- Wie wir semantische Suche nutzen
- Unsere Designprioritäten
- Evaluierung von Anbietern für Vektordatenbanken
- Architekturdesign
- Die Partitionierungsherausforderung
- Indizierung & Recall
- Die Anwendungsschicht
- Ingestion-Ablauf: Milvus mit Airtable synchron halten
- Abfrageablauf: Wie wir die Daten verwenden
- Betriebliche Herausforderungen & Wie wir sie gelöst haben
- Observability: Systemzustand End-to-End verstehen
- Node-Rotation
- Auslagern kalter Partitionen
- Datenwiederherstellung
- Wie geht es weiter
- Über Airtable
Inhalte
Anwendungsfall
Branche
AI-SaaS