




Zilliz x Galileo: Die Kraft von Vektor-Embeddings
Unstrukturierte Daten sind überall. IDC hat geschätzt, dass wir bis 2025 über 175 Zettabyte (21 Nullen) an Daten haben werden. 80 % davon sind unstrukturierte Daten. Unstrukturierte Daten sind Daten, die in kein vorgegebenes Format passen — sie folgen keinem vordefinierten Datenmodell oder Schema. Sie treten häufig in Form von Text, Bildern, Audio und Videos auf, können aber auch verschiedene andere Bedingungen abdecken.
Was ist ein Vektor-Embedding?
Auf der grundlegendsten Ebene sind Vektor-Embeddings eine numerische Datendarstellung. Ein Vektor-Embedding besteht typischerweise aus Hunderten oder Tausenden von Floats. Die hohe Dimensionalität ermöglicht es Vektor-Embeddings, komplexe Daten wie Bilder, Audio und Text zu speichern. Sie können Vektor-Embeddings aus trainierten Machine-Learning-Modellen extrahieren. Die meisten in der Produktion verwendeten neuronalen Netzwerke haben viele Schichten, jede mit Hunderten von Neuronen. Wenn ein Datenpunkt durch die Feed-Forward-Funktion des neuronalen Netzwerks läuft, erzeugt jede Schicht eine Ausgabe. Typischerweise führen diese Netzwerke eine Klassifizierung durch, die von der letzten Schicht des Netzwerks erstellt wird. Das Vektor-Embedding, das die Daten repräsentiert, ist die Ausgabe der letzten verborgenen Schicht, womit normalerweise die vorletzte Schicht gemeint ist.
Wie können Sie mit Vektor-Embeddings arbeiten?
Vektor-Embeddings sind de facto die Methode, um mit unstrukturierten Daten zu arbeiten. Wenn Sie Daten haben, die Sie vergleichen möchten, empfehlen wir Ihnen, dies mithilfe von Vektor-Embeddings zu tun. Vektor-Embeddings werden aus neuronalen Netzwerken generiert, indem die Ausgabe der vorletzten Schicht eines neuronalen Netzwerks genommen und als Vektor-Embedding der Eingabe verwendet wird. Bei der Generierung von Embedding-Vektoren gibt es mehrere Faktoren zu berücksichtigen. Ihre wichtigsten Überlegungen sind die Größe der Embeddings, die Daten für das Modelltraining und die Datenqualität. Sie müssen sicherstellen, dass Ihre Vektoren eine sinnvolle Größe haben.
Verwendung von Vektor-Embeddings zum Debuggen Ihrer Trainingsdaten
Datenfehler finden
Die Anfangsphase der Modellentwicklung befasst sich hauptsächlich mit der Bewältigung von Herausforderungen der "Datenkuratierung". Das Hauptziel in dieser Phase ist es, einen optimalen Datensatz für Modelltraining und -evaluierung zu erstellen. Galileo, eine algorithmische LLM Ops-Plattform für Unternehmen, verwendet Embeddings zur Erkennung von Datenfehlern durch Clustering.
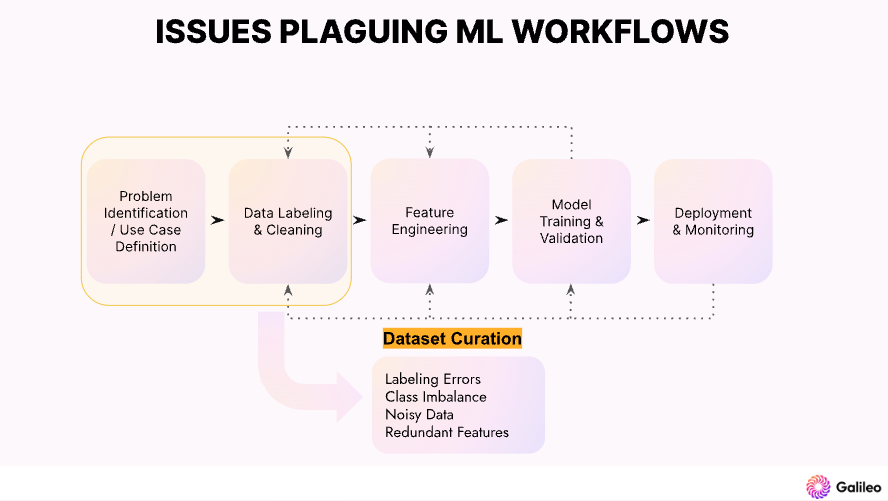
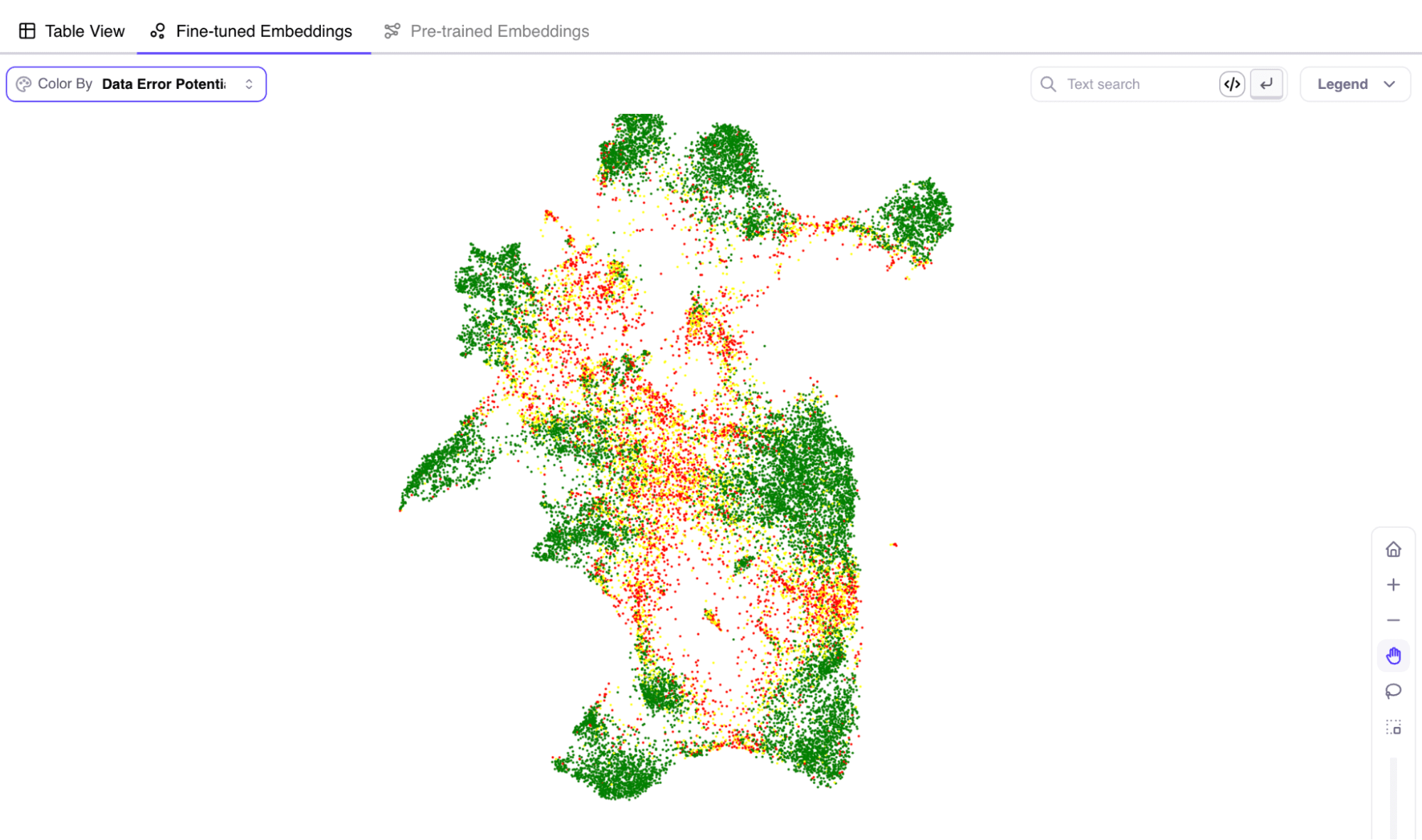
Galileo hat die einzigartige Fähigkeit, Fehler mit einem Score namens Data Error Potential (DEP) anzuzeigen. DEP bietet ein Werkzeug, um Daten, die bei der Untersuchung der Fehler Ihres Modells am schwierigsten und lohnenswertesten zu erkunden sind, schnell zu sortieren und hervorzuheben.
Wenn es um das Debuggen Ihrer Datenfehler geht, gibt es zwei Arten von Lösungen.
Stichproben finden, die in Ihren Trainingsdaten nicht vorhanden sind
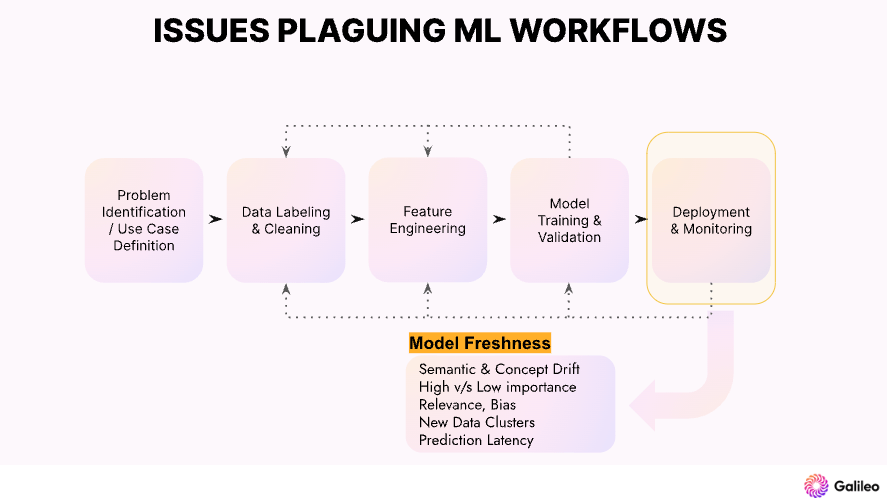
Sobald das Modell bereitgestellt ist und mit realen Daten interagiert, kommt es zu einer Verschiebung der Traffic-Muster. Galileo kann Model Drift erkennen, indem es Embeddings nutzt, um die Leistung von ML-Modellen kontinuierlich zu überwachen. Die abgedrifteten Stichproben können annotiert und den Trainingsdaten hinzugefügt werden, um eine robustere Leistung zu erzielen.
Halluzinationen in Daten finden
KI-Halluzination bezieht sich auf Situationen, in denen die KI Informationen generiert, die plausibel klingen mögen, aber falsch sind oder keinen Bezug zum Kontext haben. Dieses Problem tritt typischerweise aufgrund von Design-Biases der KI, unzureichendem Verständnis der realen Welt oder unvollständigen Trainingsdaten auf.
Um dieses Problem anzugehen, ist Galileo aktiv an embedding-basierten Techniken beteiligt, um Fälle von KI-Halluzinationen zu identifizieren. Dieser Ansatz hilft dabei, Fehler in den Daten aufzudecken, und trägt dazu bei, genauere und zuverlässigere KI-Modelle zu trainieren.
Fehler in Retrieval Augmented Generation finden
(RAG)Retrieval Augmented Generation (RAG) ist eine beliebte Technik zur Entwicklung von Frage-Antwort-Systemen und Chatbots. Ein häufiges Problem bei diesem Ansatz ist jedoch das Auftreten von schlechtem Retrieval, was dazu führt, dass falsche Antworten gegeben werden. Galileo entwickelt einen Kontextrelevanz-Score zur Erkennung des falschen Kontexts mithilfe embedding-basierter Techniken, um dieses Problem anzugehen. Manchmal kann die Generierung selbst dann Halluzinationen enthalten, wenn die Relevanz korrekt ist. Galileo wird einen Groundedness-Score bereitstellen, der misst, ob die Antwort des Modells auf den Informationen basiert, die dem Modell im Kontextfenster gegeben wurden.
 Die leistungsstarken Algorithmen in Galileo können Fehler auf Token-Ebene anzeigen, was Anwendungen dabei helfen kann, Halluzinationen zu vermeiden.
Die leistungsstarken Algorithmen in Galileo können Fehler auf Token-Ebene anzeigen, was Anwendungen dabei helfen kann, Halluzinationen zu vermeiden.

Vektor-Embeddings indizieren, speichern und abfragen
Auch wenn es hervorragend ist, Embeddings zu haben, müssen Sie in der Lage sein, sie zu verwenden. Am besten wäre es, etwas zu haben, um Ihre Vektoren zu indizieren, zu speichern und abzufragen. Genau darum geht es bei Vektordatenbanken. Vektordatenbanken sind speziell für das Indizieren, Speichern und Abfragen von Vektordaten entwickelt. Die Fähigkeit zum Indizieren, Speichern und Abfragen macht Vektordatenbanken zu einem starken Kandidaten für den Einsatz in LLM-Anwendungen. Sie eignen sich perfekt zum Speichern der semantischen Bedeutung von Dokumenten und Abfragen sowie als Cache für FAQs. Ein perfektes Beispiel dafür, wie Vektor-Embeddings mit LLM-Apps verwendet werden können, ist OSSChat, eine Anwendung, mit der Sie mit Open-Source-Softwaredokumentation „chatten“ können.

Einer der wichtigsten Aspekte einer praktischen Q/A-Anwendung ist die Verwendung geeigneter Vektor-Embeddings. Um die Dokumente abzufragen, benötigen wir den latenten Vektorraum der Abfragen. Wir verwenden ein LLM wie ChatGPT, um Fragen auf der Grundlage einer Reihe von Dokumenten zu generieren. Anschließend indizieren und speichern wir diese Embeddings, um sie abzufragen, wenn der Benutzer Fragen stellt.
Zusammenfassung der Leistungsfähigkeit von Vektor-Embeddings
Unstrukturierte Daten sind die häufigste Datenart der Welt. Traditionell war es schwierig, mit unstrukturierten Daten zu arbeiten, weil sie keiner vorgegebenen Struktur entsprechen. Deep Learning ist leistungsfähiger und weitverbreiteter geworden und hat daher eine Lösung für die Arbeit mit unstrukturierten Daten hervorgebracht, indem es sie in Vektoren umwandelt.
Vektor-Embeddings ermöglichen es Ihnen, mit Dingen zu rechnen, die ursprünglich keine Zahlen sind. In diesem Beitrag haben wir Vektor-Embeddings vorgestellt, wie man mit ihnen arbeitet, und vier konkrete Möglichkeiten, Vektoren im aktuellen Machine-Learning-Paradigma zu verwenden. Sie können Vektor-Embeddings verwenden, um Datenfehler zu finden, Beispiele zu finden, die in Ihren Trainingsdaten nicht vorhanden sind, Halluzinationen zu erkennen und Fehler in Retrieval Augmented Generation zu beheben.
Die Leistungsfähigkeit von Vektor-Embeddings lässt sich an dieser breiten Palette von Anwendungsfällen erkennen. Die effektivste Art, mit ihnen zu arbeiten, besteht darin, eine Vektordatenbank wie Milvus oder Zilliz Cloud zu verwenden, um die Vektoren zu speichern, zu indizieren und abzufragen.
Nehmen Sie an unserem kommenden Webinar mit Galileo teil
Nehmen Sie am 12. Oktober gemeinsam mit Vikram Chatterji von Galileo und Yujian Tang von Zilliz an einem Deep Dive in RAG und LLM-Management teil. Dieses Webinar wird Ihnen umsetzbare Erkenntnisse und Methoden vermitteln, um Ihre LLM-Pipelines und die Ausgabequalität zu verbessern. Es verspricht eine informative Sitzung für alle Data Scientists und Machine-Learning-Ingenieure zu werden, die nach Frameworks und Tools zur Optimierung der RAG- und LLM-Leistung suchen.

Weiterlesen

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

Vector Databases vs. Object-Relational Databases
Use a vector database for AI-powered similarity search; use an object-relational database for complex data modeling with both relational integrity and object-oriented features.