




Mit KI deinen Promi-Stylisten finden (Teil I)
Der Artikel wurde ursprünglich auf der Website des AI Accelerator Institute veröffentlicht und wird hier mit Genehmigung erneut veröffentlicht.
Ich trage bei meinen Vorträgen sehr gern rosa Hosen, was zu einem meiner Markenzeichen geworden ist. Ich besitze mehrere Paare, was viele Diskussionen über Mode und Stil ausgelöst hat. Kürzlich war ich an einem Projekt namens "Fashion AI" beteiligt, bei dem wir ein feinabgestimmtes Modell nutzen, um Kleidung in Bildern zu segmentieren. Anschließend schneiden wir jeden gelabelten Artikel aus und ändern die Größe der Bilder auf dieselbe Größe. Schließlich speichern wir die aus diesen Bildern generierten Embeddings in Milvus, einer Open-Source-Vektordatenbank, die Milliarden von Vektor-Embeddings speichern und abfragen kann.
Um die am besten passenden Artikel in unserer Datenbank zu finden, wenden wir dieselben Transformationen auf das Bild und die Abfrage entlang derselben Vektoren an. Für jede Abfrage gibt dieses Projekt drei Ergebnisse zurück. Sie können die Ergebnisse nach Ihren Vorlieben interpretieren. Sie können auch bestimmen, welcher Prominente Ihnen am nächsten kommt. Sie können den häufigsten ersten Platz, die niedrigste aggregierte Distanz oder den insgesamt häufigsten wählen.
Sie können die Bilder hier finden. Zusätzlich zu den Bildern benötigen Sie eine aktualisierte Python-Version und pip install milvus pymilvus torch torchvision matplotlib. Wir verwenden das clothing segmenter model von Mateusz Dziemian auf Hugging Face sowie dieses ResNet50-Modell von Nvidia auf PyTorch für Bildsegmentierung und Embeddings.
In diesem Beitrag besprechen wir, wie Sie Bildsegmentierung für Modeartikel generieren, Ihre Bilddaten zu Milvus hinzufügen und herausfinden, welchem Prominenten Ihr Kleid am ähnlichsten ist.
Bildsegmentierung für Kleidungsstücke
Um Bildsegmentierung durchzuführen, habe ich drei Modelle auf Hugging Face gefunden, die man sich ansehen sollte.
Das segformer_b2_clothes von Mateusz Dziemian
Das YOLOS-Fashionpedia von Valentina Feruere
Das Fashion-CLIP-Modell von Patrick John Chia
Ich habe mich letztendlich für das "segformer"-Modell entschieden. Es bietet eine genaue Segmentierung für verschiedene Kleidungsstücke und identifiziert 18 Arten von "Objekten." Zum Beispiel erkennt es "upper clothes" für jede Art von Oberteilen, "dress," "left shoe," "right shoe," "hat," und viele weitere Kleidungsstücke. Darüber hinaus kann es Dinge wie "face," "hair," "right leg," und "left leg." erkennen. Die vollständige Liste der 18 Objekttypen finden Sie hier.
Wir beginnen damit, die notwendigen Pakete für die Bildbearbeitung in diesem Projekt zu importieren. Dazu gehören torch für die Merkmalsextraktion, das segformer-Objekt aus transformers, matplotlib und einige torchvision-Importe wie Resize, masks_to_boxes und crop.
import torch
from torch import nn, tensor
from transformers import AutoFeatureExtractor, SegformerForSemanticSegmentation
import matplotlib.pyplot as plt
from torchvision.transforms import Resize
import torchvision.transforms as T
from torchvision.ops import masks_to_boxes
from torchvision.transforms.functional import crop
Segmentierungsmasken mit Hugging Face generieren
Es gibt viele Ansätze, Ihr Bild zu segmentieren, abhängig davon, welches Modell Sie verwenden und was es erkennt. Für dieses Beispiel gibt unser Modell ein 18-schichtiges Bild zurück, eines für jeden Objekttyp, einschließlich des Hintergrunds. Die erste Funktion, die wir schreiben müssen, ist eine, die dieses Bild generiert.
Die Funktion get_segmentation erfordert drei Parameter: einen Feature-Extractor, ein Modell und ein Bild. Zuerst erzeugt sie Eingabefeatures mithilfe des Bildes und des Extractors. Dann ruft sie die Modellausgabe ab und wandelt sie in Logits um. Anschließend skaliert sie die Logits mittels bilinearer PyTorch-Interpolation hoch. Schließlich nimmt die Funktion nur die maximale Vorhersage für jedes Pixel in den hochskalierten Samples, um eine Segmentierungsmaske zu erstellen.
def get_segmentation(extractor, model, image):
inputs = extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits.cpu()
upsampled_logits = nn.functional.interpolate(
logits,
size=image.size[::-1],
mode="bilinear",
align_corners=False,
)
pred_seg = upsampled_logits.argmax(dim=1)[0]
return pred_seg
Als Referenz sehen die Bilder in upsampled_logits so aus:
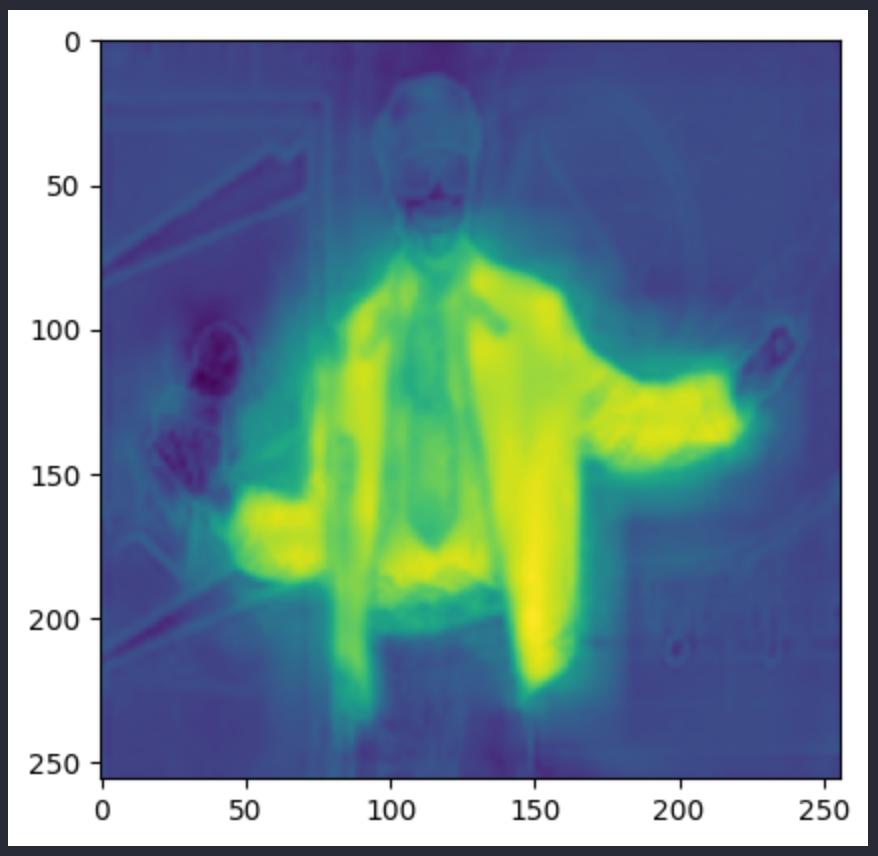
Während das pred_seg-Bild so aussieht: (dies sind zwei verschiedene Bilder, obwohl beide Andre 3000 zeigen).
Von hier aus ist es unkompliziert, die Segmentierungsmasken zu erhalten. Wir ermitteln alle eindeutigen Werte in der Segmentierung; in diesem Modell können es höchstens 18 sein. Wir verwerfen den ersten Eintrag, der den Hintergrund darstellt. Um die Masken zu erstellen, extrahieren wir die Pixel in der Segmentierung, die denselben Wert wie die Objekt-ID haben. Ich lasse diese Funktion sowohl die Masken als auch die IDs zurückgeben, damit wir beides nachverfolgen können.
# returns two lists masks (tensor) and obj_ids (int)
# "mattmdjaga/segformer_b2_clothes" from hugging face
def get_masks(segmentation):
obj_ids = torch.unique(segmentation)
obj_ids = obj_ids[1:]
masks = segmentation == obj_ids[:, None, None]
return masks, obj_ids
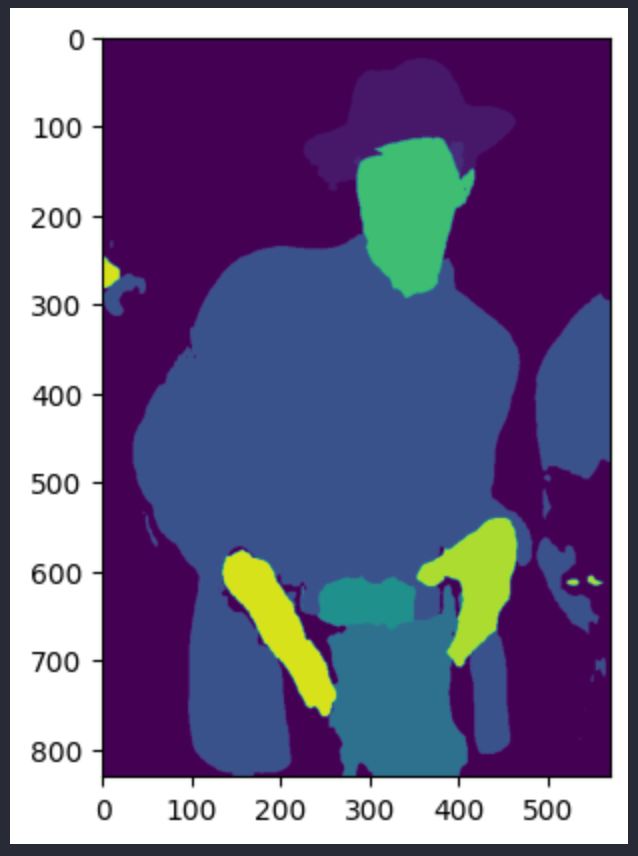
Diese Funktion erstellt Masken, die so aussehen (Masken für Haare und Oberbekleidung gezeigt):

Bilder mit Pytorch-Transforms zuschneiden und skalieren
Wir können nun mit den Masken und Objekt-IDs der Funktion get_masks sowie dem Originalbild für jedes erkannte Objekt ein neues Bild erstellen. Dann rufen wir die magische Funktion masks_to_boxes auf, die wir zuvor aus torchvision.ops importiert haben, um die erstellten Masken in Bounding Boxes umzuwandeln.
Als Nächstes erstellen wir eine Liste von Boxen zum Zuschneiden und konvertieren das Box-Koordinatensystem in das crop-Koordinatensystem. Die Boxen werden als Werte in der Form (x1, x2, y1, y2) zurückgegeben. Die Funktion crop hingegen erwartet eine Eingabe in der Form (top, left, height, width).
Bevor wir die Bilder zuschneiden, definieren wir außerdem eine Preprocessing-Funktion. Wir möchten jedes Bild auf 256x256 skalieren und in PyTorch-Tensoren umwandeln (derzeit PIL Images). Jetzt ist es Zeit, die Bilder zuzuschneiden. Wir durchlaufen die Crop-Boxen und rufen die Funktion crop auf dem Bild mit den zuvor erhaltenen Werten auf. Dann fügen wir das vorverarbeitete Bild als Wert, der dem Schlüsselwert der Segmentierungs-ID entspricht, zu einem Dictionary hinzu. Am Ende der Funktion geben wir dieses Dictionary zurück.
def crop_images(masks, obj_ids, img):
boxes = masks_to_boxes(masks)
crop_boxes = []
for box in boxes:
crop_box = tensor([box[0], box[1], box[2]-box[0], box[3]-box[1]])
crop_boxes.append(crop_box)
preprocess = T.Compose([
T.Resize(size=(256, 256)),
T.ToTensor()
])
cropped_images = {}
for i in range(len(crop_boxes)):
crop_box = crop_boxes[i]
cropped = crop(img, crop_box[1].item(), crop_box[0].item(), crop_box[3].item(), crop_box[2].item())
cropped_images[obj_ids[i].item()] = preprocess(cropped)
return cropped_images
Unten sehen Sie ein Beispiel für die Boxen, die wir zuschneiden und für die wir separate Bilder erstellen, wobei Drake in einem Feuer-Output verwendet wird.

Bilddaten zu einer Vektordatenbank hinzufügen
Nachdem wir nun alle Bilder segmentiert und zugeschnitten haben, fügen wir sie zu Milvus, unserer Vektordatenbank, hinzu. Damit du schnell mit Milvus loslegen kannst, verwenden wir in diesem Beispiel Milvus Lite, eine leichtgewichtige Version von Milvus, um eine Instanz von Milvus in unserem Notebook auszuführen. Anschließend verwenden wir pymilvus, um eine Verbindung zum von Milvus Lite bereitgestellten Standardserver herzustellen.
Wir nutzen diesen Abschnitt außerdem, um einige Konstanten einzurichten. Definieren wir die Anzahl der Dimensionen in einem Vektor (aus dem Nvidia-ResNet50-Modell), die Batch-Größe, den Namen unserer Collection und die Anzahl der zurückzugebenden Ergebnisse. Abschließend führen wir eine ssl-Funktion aus, um einen nicht verifizierten Kontext zu erstellen, damit wir das Modell von PyTorch abrufen können.
from milvus import default_server
from pymilvus import utility, connections
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
DIMENSION = 2048
BATCH_SIZE = 128
COLLECTION_NAME = "fashion"
TOP_K = 3
# run this before importing th resnet50 model if you run into an SSL certificate URLError
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
Dein Schema definieren, um Metadaten in einer Vektordatenbank zu speichern
Schritt eins: Definiere dein Schema. Das Schema wird verwendet, um die in der Vektordatenbank gespeicherten Daten zu organisieren. Das Feld id ist eine reguläre Schlüssel-ID in SQL- oder NoSQL-Datenbanken, während die anderen Felder SQL-ähnliche Definitionen in ihren Datentypen haben (int64, varchar, float usw.).
Für dieses Beispiel speichern wir den Dateipfad, den Namen der prominenten Person und die Segmentierungs-ID als Metadaten. In Zukunft können wir weitere Felder hinzufügen, etwa die Position von Bounding Boxes oder Masken. Sobald wir das FieldSchema definiert haben, definieren wir ein CollectionSchema und erstellen anschließend eine Collection in Milvus auf Grundlage des angegebenen Schemas und Collection-Namens.
Nachdem wir nun eine Collection haben, definieren wir ihren Index. Diese Indexparameter sind ziemlich grundlegend. Wir verwenden IVF Flat mit 128 Zentroiden und L2 als Distanzmetrik. Wir erstellen den Index in unserer Collection und geben dabei an, dass das Feld embedding dasjenige ist, auf dem operiert werden soll. Anschließend laden wir die Collection in den Speicher, damit sie einsatzbereit ist.
from pymilvus import FieldSchema, CollectionSchema, Collection, DataType
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name='filepath', dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name="name", dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name="seg_id", dtype=DataType.INT64),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()
Deine Vektoreinbettungen aus Nvidias ResNet50 erhalten
Der erste Schritt in diesem Abschnitt besteht darin, das Modell zu laden. Wir laden Nvidias ResNet50-Modell aus PyTorch und entfernen dann die Ausgabeschicht. Vektoreinbettungen sind die Ausgabe der vorletzten Schicht in einem Modell.
# Load the embedding model with the last layer removed
embeddings_model = torch.hub.load('NVIDIA/DeepLearningExamples:torchhub', 'nvidia_resnet50', pretrained=True)
embeddings_model = torch.nn.Sequential(*(list(embeddings_model.children())[:-1]))
embeddings_model.eval()
Diese Funktion ist dafür verantwortlich, die Vektoreinbettungen zu empfangen und die Daten in Milvus einzufügen. Sie akzeptiert drei Parameter: die Daten, das Collection-Objekt und ein Modell, in diesem Fall das Einbettungsmodell. Um nachzuverfolgen, wie die Daten verarbeitet werden, während wir sie unserer Vektordatenbank hinzufügen, habe ich mehrere Print-Anweisungen hinzugefügt.
Zusätzlich zum Ausgeben von Debugging-Daten stapeln wir alle Werte in data[0] in einen Tensor und entfernen dann mithilfe der Funktion squeeze alle Dimensionen der Größe 1 aus der Ausgabe. Dann fügen wir eine neue Liste ein, die aus den letzten drei Einträgen des ursprünglichen Datenbatches besteht, gefolgt vom Ausgabetensor, der in eine Liste konvertiert wurde. Diese entsprechen dem Dateipfad, dem Namen, der Segmentierungs-ID und dem 2048-dimensionalen Embedding.
def embed_insert(data, collection, model):
with torch.no_grad():
print(len(data[0]))
print(data[0][0].size())
output = model(torch.stack(data[0])).squeeze()
print(type(output))
print(len(output))
print(len(output[0]))
print(output[0])
collection.insert([data[1], data[2], data[3], output.tolist()])
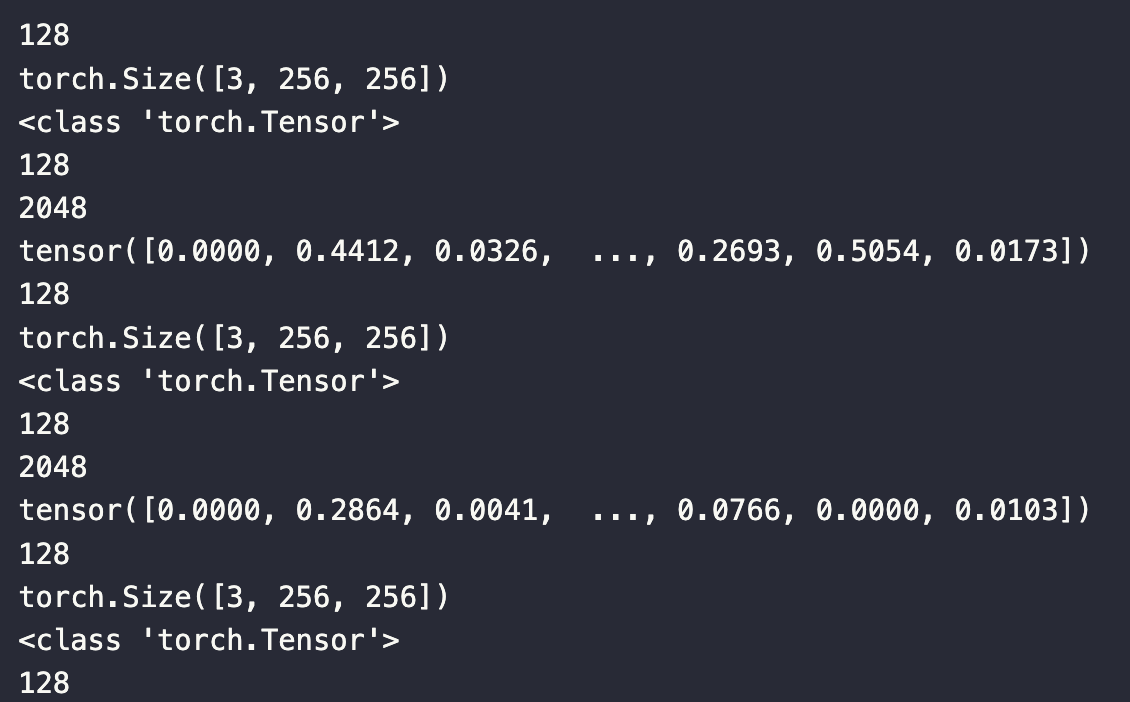
Die ausgegebenen Daten sehen aus wie das unten gezeigte Bild. Jeder Datenbatch hat bis zum Ende eine Größe von 128, wobei jeder Eintrag die Größe 3x256x256 hat. Die Ausgabe ist ein PyTorch Tensor der Länge 128, wobei jeder Eintrag in der Ausgabe die Länge 2048 hat. Der ausgegebene Tensor ist die Ausgabe des ersten Eintrags im Datenbatch.
Speichern deiner Bilddaten in einer Vektordatenbank
Erinnerst du dich an das Extraktor- und Segmentierungsmodell, über das wir vorhin gesprochen haben? Hier verwenden wir sie. Wir verwenden dieses vortrainierte segformer-Modell von Hugging Face. Nachdem wir die Modelle geladen haben, legen wir alle Dateipfade in eine Liste, um sie zu durchlaufen.
extractor = AutoFeatureExtractor.from_pretrained("mattmdjaga/segformer_b2_clothes")
model = SegformerForSemanticSegmentation.from_pretrained("mattmdjaga/segformer_b2_clothes")
import os
image_paths = []
for celeb in os.listdir("./photos"):
for image in os.listdir(f"./photos/{celeb}/"):
# print(image)
image_paths.append(f"./photos/{celeb}/{image}")
Milvus erwartet eine Liste von Listen als Eingabe. In diesem Beispiel verwenden wir eine Liste aus 4 Listen, die dem Bild, dem Dateipfad, dem Namen und der Segmentierungs-ID entsprechen. In der Funktion embed_insert konvertieren wir das Bild in ein Vektor-Embedding. Anschließend durchlaufen wir jeden Dateipfad zu den Bildern, erfassen ihre Segmentierungsmasken und schneiden sie zu. Schließlich fügen wir die Bilder mit ihren Metadaten zum Datenbatch hinzu.
Alle 128 Bilder betten wir sie ein und fügen sie in Milvus ein und leeren dann den Datenbatch. Am Ende der Schleife betten wir den Rest des Datenbatches ein, fügen ihn in Milvus ein und flushen ihn, um die Indizierung abzuschließen. Auf einem M1 2021 Mac mit 16 GB RAM dauert dieser Prozess ungefähr 8 Minuten.
from PIL import Image
data_batch = [[], [], [], []]
for path in image_paths:
image = Image.open(path)
path_split = path.split("/")
name = " ".join(path_split[2].split("_"))
segmentation = get_segmentation(extractor, model, image)
masks, ids = get_masks(segmentation)
cropped_images = crop_images(masks, ids, image)
for key, image in cropped_images.items():
data_batch[0].append(image)
data_batch[1].append(path)
data_batch[2].append(name)
data_batch[3].append(key)
if len(data_batch[0]) % BATCH_SIZE == 0:
embed_insert(data_batch, collection, embeddings_model)
data_batch = [[], [], [], []]
if len(data_batch[0]) != 0:
embed_insert(data_batch, collection, embeddings_model)
collection.flush()
Finde heraus, welchen Prominenten du dich beim Kleidungsstil am ähnlichsten anziehst
Mit diesem Setup kannst du viel machen. Ich werde in einem kommenden Beitrag zusätzliche Methoden zum Abgleichen und Bewerten deiner Modeentscheidungen bereitstellen. In diesem Beispiel erhalten wir die drei besten Bilder basierend auf jedem segmentierten Kleidungsstück. Wir verwenden ein paar Beispiele von Taylor Swift und erhalten einen perfekten Recall.
Embeddings für deine Eingabebilder generieren
Ähnlich wie wir Bilder in die Datenbank laden, müssen wir Eingabebilder verarbeiten. Die Funktion zum Einbetten von Suchbildern nimmt zwei Parameter entgegen: data und das (Embedding-)Modell. Wir verwenden das Modell, um die Embeddings zu erhalten, glätten oder komprimieren sie abhängig von der Anzahl der abgefragten Bilder, konvertieren sie in eine Liste und geben sie zurück.
def embed_search_images(data, model):
with torch.no_grad():
print(len(data[0]))
print(data[0][0].size())
output = model(torch.stack(data))
print(type(output))
print(len(output))
print(len(output[0]))
print(output[0])
if len(output) > 1:
return output.squeeze().tolist()
Else:
return torch.flatten(output, start_dim=1).tolist()
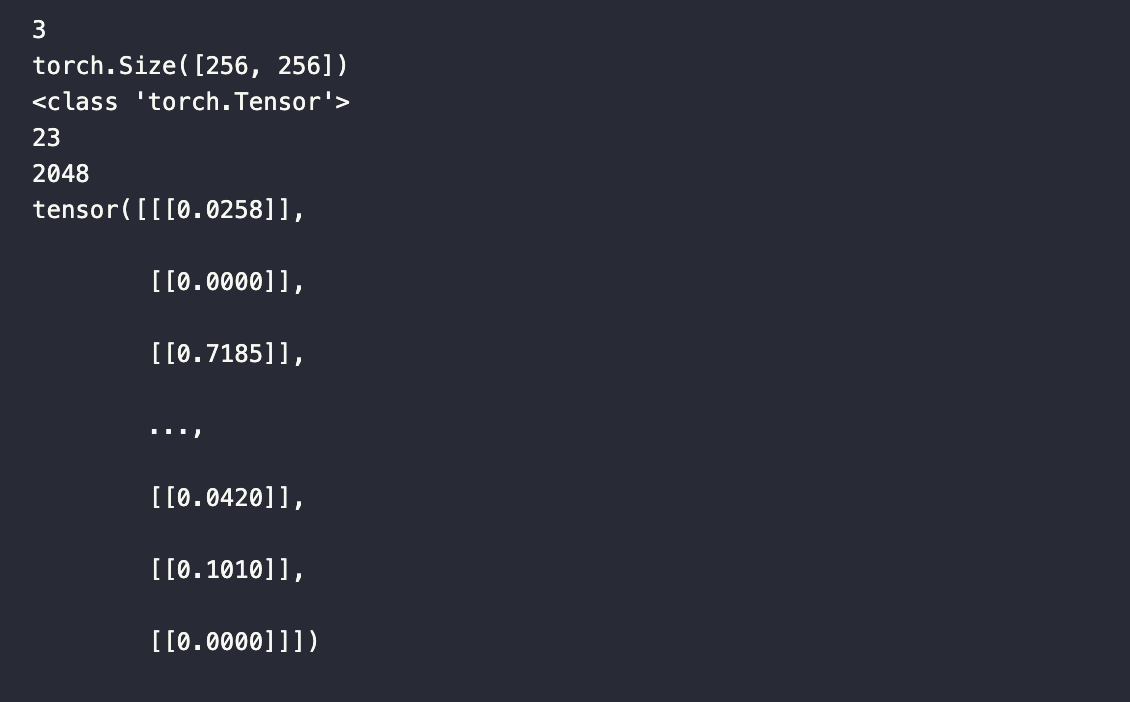
Ähnlich wie bei der Funktion embed_insert habe ich hier mehrere print-Anweisungen hinzugefügt, um die Daten im Blick zu behalten. Wie unten gezeigt, ist das an diese Funktion übergebene data im Wesentlichen das Objekt data[0], im Vergleich zur Funktion embed_insert.
Um die Datenbank abzufragen, benötigen wir nur die Vektor-Embeddings, die wir auf ähnliche Weise erhalten können wie beim Hinzufügen von Bildern zu Milvus. Es ist jedoch nützlich, diese anderen Variablen im Speicher zu behalten, um spätere Vergleiche zu erleichtern.
# data_batch[0] is a list of tensors
# data_batch[1] is a list of filepaths to the images (string)
# data_batch[2] is a list of the names of the people in the images (string)
# data_batch[3] is a list of segmentation keys (int)
data_batch = [[], [], [], []]
search_paths = ["./photos/Taylor_Swift/Taylor_Swift_3.jpg", "./photos/Taylor_Swift/Taylor_Swift_8.jpg"]
for path in search_paths:
image = Image.open(path)
path_split = path.split("/")
name = " ".join(path_split[2].split("_"))
segmentation = get_segmentation(extractor, model, image)
masks, ids = get_masks(segmentation)
cropped_images = crop_images(masks, ids, image)
for key, image in cropped_images.items():
data_batch[0].append(image)
data_batch[1].append(path)
data_batch[2].append(name)
data_batch[3].append(key)
embeds = embed_search_images(data_batch[0], embeddings_model)
Abfragen der Vektordatenbank
Nachdem wir nun die Embeddings haben, können wir die Datenbank abfragen. Zum Spaß füge ich das Modul time hinzu, um zu verfolgen, wie lange diese Abfragen dauern. In diesem Beispiel messen wir die Abfragezeit für 23 2048-dimensionale Vektoren. Um Milvus abzufragen, verwenden wir einfach die Funktion search mit den oben generierten Embeddings.
import time
start = time.time()
res = collection.search(embeds,
anns_field='embedding',
param={"metric_type": "L2",
"params": {"nprobe": 10}},
limit=TOP_K,
output_fields=['filepath'])
finish = time.time()
print(finish - start)
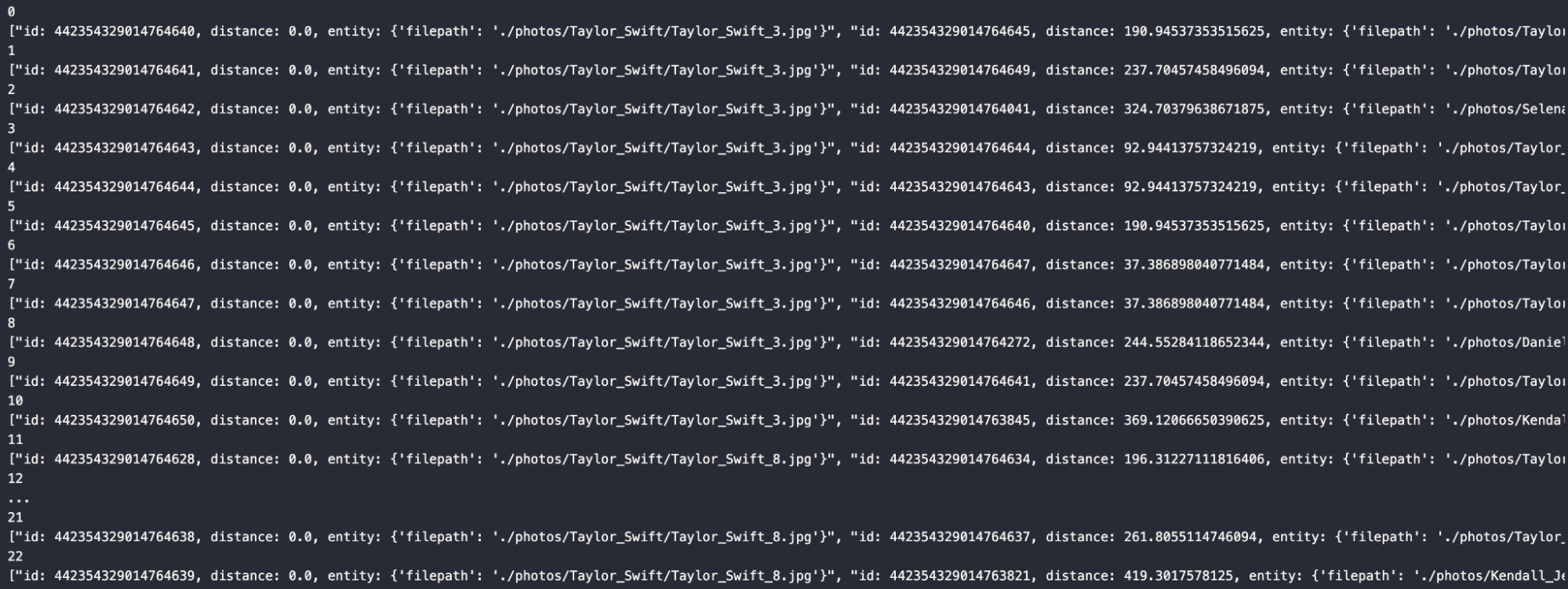
Nachdem wir die Ergebnisse durchlaufen haben, können wir die generierte Antwort sehen, die im Bild unter dem Code gezeigt wird.
for index, result in enumerate(res):
print(index)
print(result)
Zusammenfassung
Das war alles für diesen Abschnitt. Du bist jetzt bereit, beliebige Bilder von dir selbst oder deinen Freunden (mit Erlaubnis!) mit einigen Prominenten zu vergleichen, darunter Taylor Swift, Drake und Andre 3000. Beginne dazu damit, eine Segmentierung der Kleidungsstücke im Bild mithilfe eines auf Hugging Face gefundenen Modells zu erhalten.
Mit den Segmentierungen zur Hand nimmst du jede eindeutige Segmentierung aus dem Bild und schneidest sie in separate Bilder zu. Bevor du diese zugeschnittenen Bilder in die Vektordatenbank einfügst, ändere ihre Größe und wandle sie in Tensoren um. Führe sie dann durch ein ResNet50-Embeddings-Modell von Nvidia, um die zu speichernden Vektor-Embeddings zu erhalten.
Führen Sie für die Abfrage ein ähnliches Verfahren wie beim Laden der Vektoren durch. In diesem Beispiel sind wir nur bis zum Abrufen der Abfrageergebnisse gegangen. Um weiterzugehen, speichern Sie die Bounding Boxes oder Masken in der Vektordatenbank und rufen Sie sie ab, um bestimmte Treffer anzuzeigen. Alternativ können Sie die Eingabebilder erneut durch das Modell laufen lassen und dasselbe tun. Da wir alles lokal erledigen, können wir lokalen Speicher verwenden.
Ich hoffe, Ihnen hat das gefallen. Sie können sich gerne mit mir vernetzen und Ihr Feedback teilen. Bitte lassen Sie mich auch wissen, welchem Celebrity Ihr Kleidungsstil am meisten ähnelt!
Und vergessen Sie nicht, sich Teil II dieser Reihe anzusehen!

Weiterlesen

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.

Why Not All VectorDBs Are Agent-Ready
Explore why choosing the right vector database is critical for scaling AI agents, and why traditional solutions fall short in production.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.