




Retrieval-Augmented Generation auf Notion-Dokumenten via LangChain
Dieser Artikel wurde ursprünglich in The Sequence veröffentlicht und wird hier mit Genehmigung erneut veröffentlicht.
Hast du Notion-Dokumente, zu denen du ein Sprachmodell für dich Abfragen durchführen lassen möchtest? Lass uns eine grundlegende App vom Typ Retrieval Augmented Generation (RAG) mit LangChain und Milvus bauen. Wir verwenden LangChain als operatives Framework und Milvus als Similarity Engine. Das Notebook zu diesem Blog findest du auf colab.
In diesem Tutorial gehen wir Folgendes durch:
Überblick über LangChain Self Querying
Arbeiten mit Notion-Dokumenten in LangChain
Ingestieren deiner Notion-Dokumente
Speichern deiner Notion-Dokumente
Abfragen deiner Notion-Dokumente
Zusammenfassung zum Abfragen von Notion-Dokumenten mit LangChain und Milvus
Überblick über LangChain Self Querying
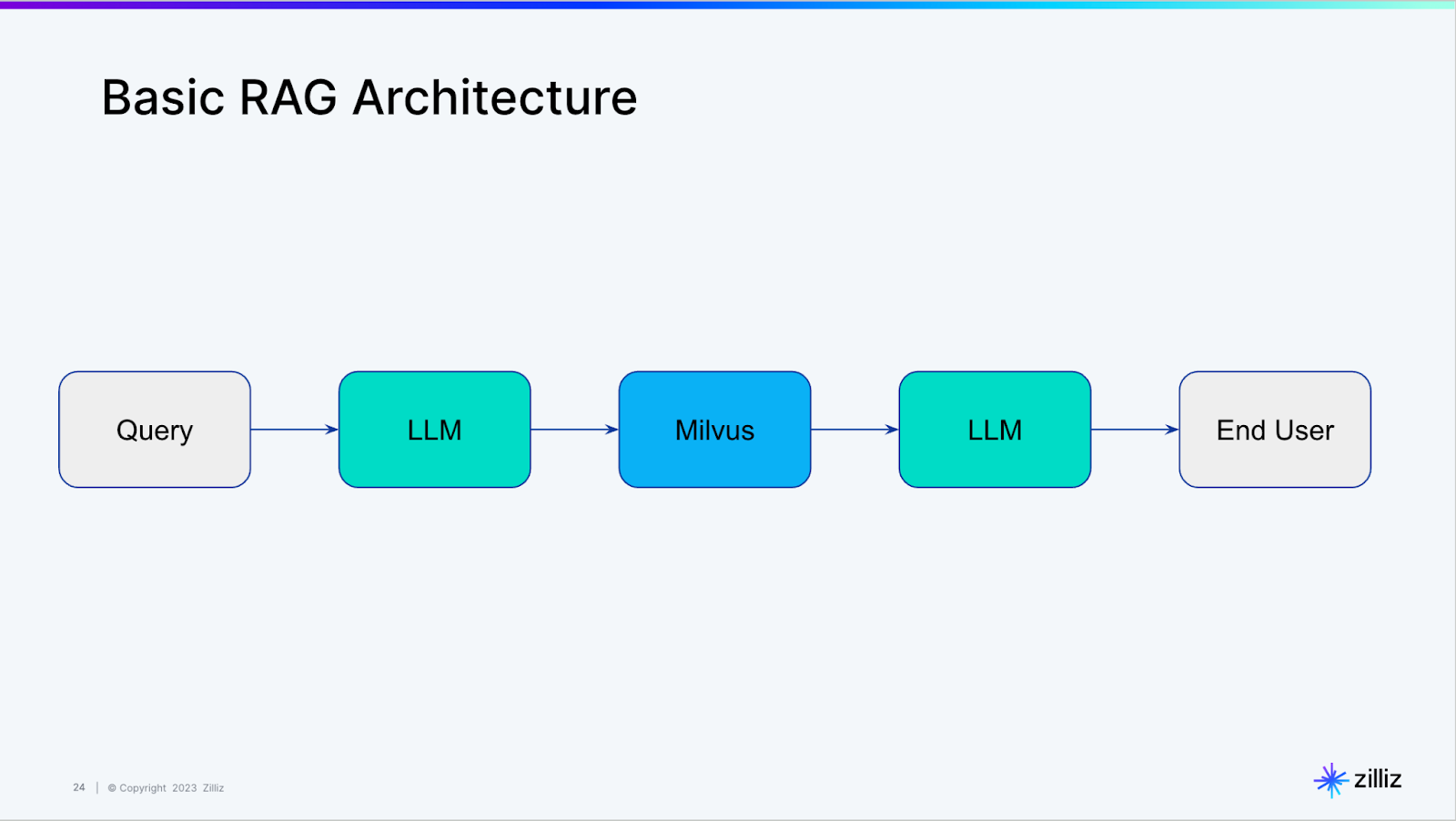
Wir haben kürzlich behandelt, wie man LangChain verwendet, um eine Vektordatenbank abzufragen, eine Einführung in das, was LangChain als „Self-Querying“ bezeichnet. Hinter den Kulissen erstellt die Self-Querying-Funktionalität in LangChain eine grundlegende RAG-Architektur wie die unten gezeigte.
Arbeiten mit Notion-Dokumenten in LangChain
Ich werde dies in drei Schritte aufteilen: Ingestieren, Speichern und Abfragen. Das Ingestieren umfasst das Abrufen deiner Notion-Dokumente und das Laden der Inhalte in den Speicher. Das Speichern umfasst das Hochfahren einer Vektordatenbank (Milvus), das Vektorisieren der Dokumente, das Einfügen in die Vektordatenbank, und das Abfragen umfasst das Stellen einer Frage zu deinen Notion-Dokumenten.
Ingestieren deiner Notion-Dokumente
Wir verwenden den NotionDirectoryLoader von LangChain, um die Dokumente in den Speicher zu laden. Wir geben den Pfad zu unseren Dokumenten an und rufen die Funktion load auf, um sie zu erhalten. Sobald die Dokumente in den Speicher geladen sind, greifen wir auf die Markdown-Datei zu, in diesem Fall nur eine.
Als Nächstes verwenden wir den Markdown-Header-Textsplitter von LangChain. Wir übergeben ihm eine Liste von Trennzeichen, nach denen aufgeteilt werden soll, und übergeben dann die zuvor benannte md_file, um unsere Aufteilungen zu erhalten. Wenn du deine Liste headers_to_split_on definierst, stelle sicher, dass du die Header verwendest, die du in deinem Notion-Dokument verwendest, nicht nur die Beispiele, die ich bereitgestellt habe.
# Load Notion page as a markdownfile file
from langchain.document_loaders import NotionDirectoryLoader
path='./notion_docs'
loader = NotionDirectoryLoader(path)
docs = loader.load()
md_file=docs[0].page_content
# Let's create groups based on the section headers in our page
from langchain.text_splitter import MarkdownHeaderTextSplitter
headers_to_split_on = [
("##", "Section"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(md_file)
Im untenstehenden Code führen wir unsere Aufteilungen durch und untersuchen sie. Wir verwenden LangChains RecursiveCharacterTextSplitter, der einige verschiedene Zeichen testet, nach denen aufgeteilt werden kann. Die vier standardmäßig zu prüfenden Zeichen sind ein Zeilenumbruch, ein doppelter Zeilenumbruch, ein Leerzeichen oder kein Leerzeichen. Du kannst auch entscheiden, deine eigenen mit einem separators-Parameter zu übergeben, den wir diesmal nicht verwendet haben.
Die zwei wesentlichen Hyperparameter, die beim Chunking deines Notion-Dokuments definiert werden müssen, sind die Chunk-Größe und die Chunk-Überlappung. Für dieses Beispiel verwenden wir eine Chunk-Größe von 64 und eine Überlappung von 8. In Zukunft werden wir das Testen dieser Werte und das Finden guter Werte behandeln. Sobald wir den Textsplitter definiert haben, rufen wir seine Funktionen split_documents auf, um alle unsere Document-Aufteilungen zu erhalten.
# Definieren unseres Text-Splitters
from langchain.text_splitter import RecursiveCharacterTextSplitter
chunk_size = 64
chunk_overlap = 8
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
all_splits = text_splitter.split_documents(md_header_splits)
all_splits
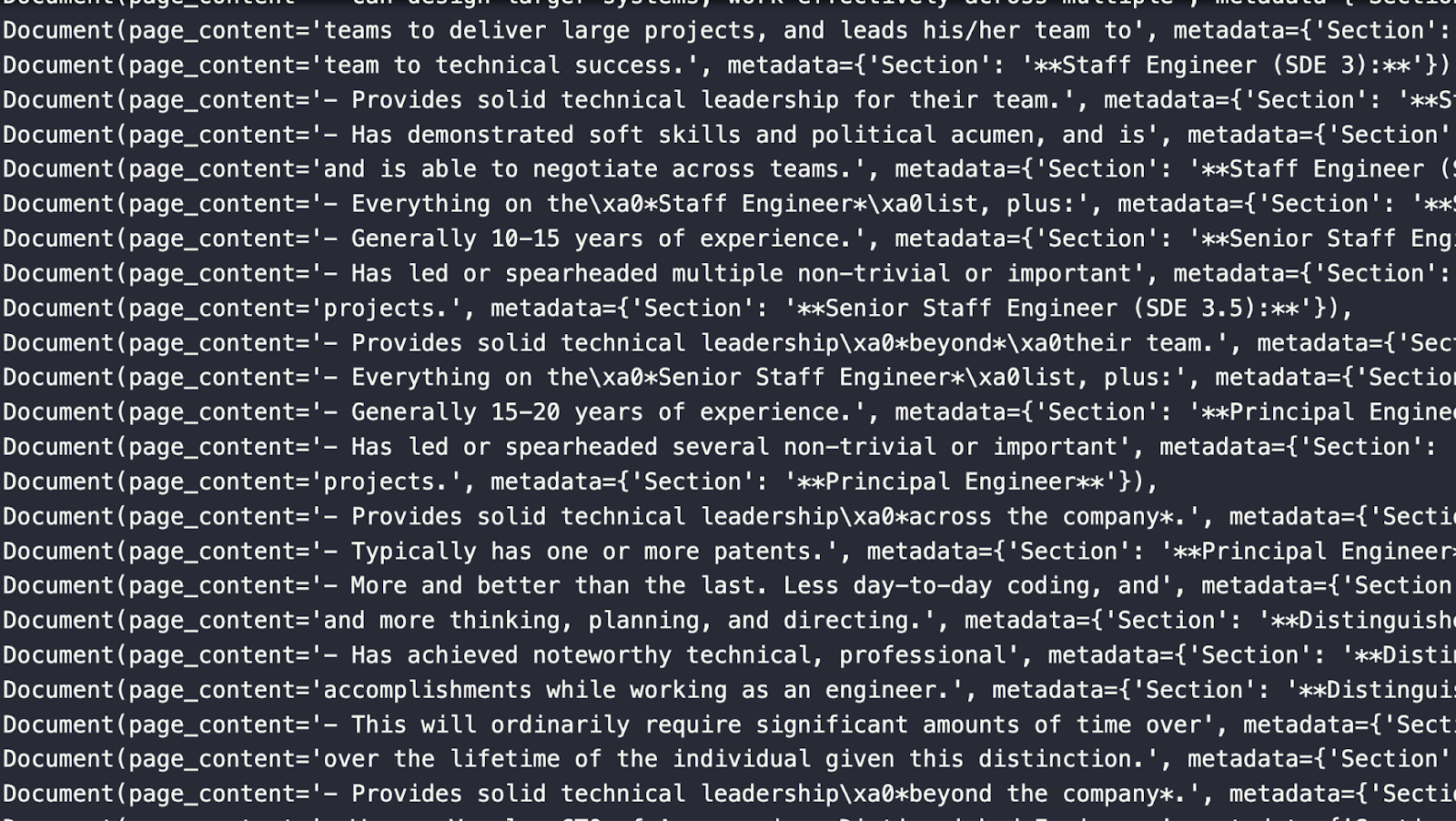
Das folgende Bild zeigt einige Document-Objekte aus der obigen Aufteilung. Beachte, dass es den Seiteninhalt und die Metadaten enthält, einschließlich des Abschnitts, aus dem der Inhalt entnommen wurde.
Speichern deiner Notion-Dokumente
Nachdem alle Dokumente geladen und aufgeteilt wurden, ist es an der Zeit, diese Aufteilungen zu speichern. Zuerst starten wir unsere Vektordatenbank direkt in unserem Notebook mit Milvus Lite. Außerdem müssen wir die notwendigen LangChain-Module abrufen – Milvus und OpenAIEmbeddings.
Nach den Imports und dem Starten der Vektordatenbank verwenden wir das Milvus-Modul von LangChain, um aus unseren Dokumenten eine Collection zu erstellen. Wir müssen ihm die Dokumentliste, die zu verwendenden Embeddings, die Verbindungsparameter und (optional) einen Collection-Namen übergeben.
from milvus import default_server
default_server.start()
from langchain.vectorstores import Milvus
from langchain.embeddings import OpenAIEmbeddings
vectordb = Milvus.from_documents(documents=all_splits,
embedding=OpenAIEmbeddings(),
connection_args={"host": "127.0.0.1", "port": default_server.listen_port},
collection_name="EngineeringNotionDoc")
Abfragen deiner Notion-Dokumente
Alles ist eingerichtet und bereit für Abfragen. Für diesen Abschnitt benötigen wir drei weitere Imports aus LangChain – OpenAI für den Zugriff auf GPT, den SelfQueryRetriever, um unser grundlegendes RAG zu erstellen, und das Objekt „Attribute info“, um die Metadaten zu übergeben. Zum Start definieren wir einige Metadaten. Für dieses Beispiel nur die Abschnitte, die wir bisher verwendet haben.
Wir geben dem Self-Query-Retriever außerdem eine Beschreibung der Dokumente. In diesem Fall einfach „Hauptabschnitte des Dokuments“. Direkt bevor wir unseren Self-Query-Retriever instanziieren, setzen wir eine GPT-Version mit Temperatur 0 auf eine llm-Variable. Mit dem LLM, der Vektordatenbank, der Dokumentbeschreibung und den Metadatenfeldern bereit definieren wir den Self-Query-Retriever.
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_fields_info = [
AttributeInfo(
name="Section",
description="Part of the document that the text comes from",
type="string or list[string]"
),
]
document_content_description = "Major sections of the document"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm, vectordb, document_content_description, metadata_fields_info, verbose=True)
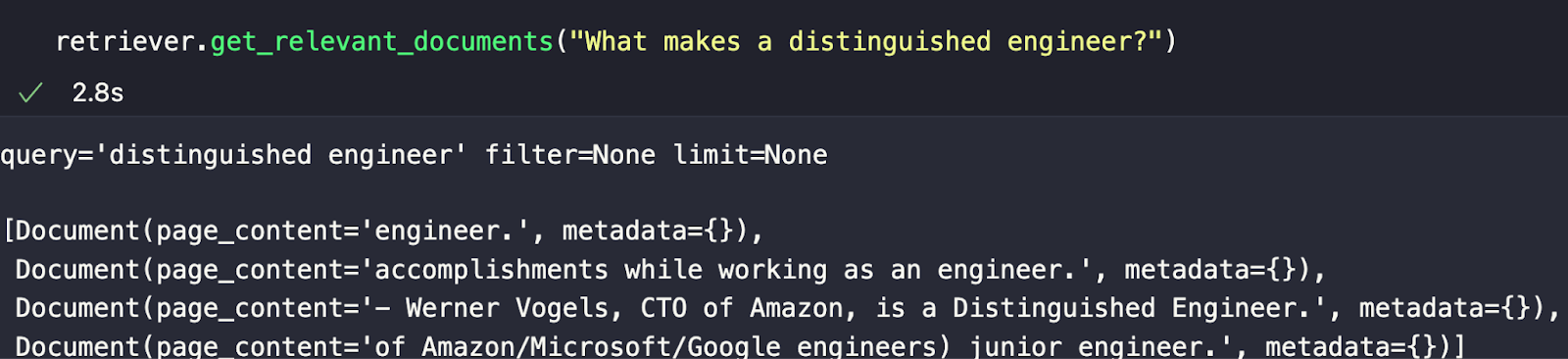
retriever.get_relevant_documents("What makes a distinguished engineer?")
Mein gewähltes Beispiel lautet „What makes a distinguished engineer?“ Anhand der Antwort im folgenden Bild können wir die semantisch ähnlichsten zurückgegebenen Chunks sehen. Wie wir sehen können, bedeutet die Tatsache, dass sie die semantisch ähnlichsten Antworten sind, nicht, dass sie die richtigen sind. In zukünftigen Beiträgen werden wir behandeln, wie man mit Chunking und anderen Techniken experimentiert, um unsere Antworten zu verbessern.
Zusammenfassung zum Abfragen von Notion-Dokumenten in LangChain
In diesem Tutorial haben wir behandelt, wie man ein Notion-Dokument in Abschnitte lädt und parst, um es in einer grundlegenden RAG-Architektur abzufragen. Wir haben LangChain als Orchestrierungsframework und Milvus als unsere Vektordatenbank verwendet. LangChain setzt die Teile zusammen, und Milvus treibt die Ähnlichkeitssuche an.
Um dieses Tutorial weiterzuführen, gibt es viele Dinge, die wir testen können. Beispiele für zwei zu prüfende Hyperparameter sind die Chunk-Größe und die Überlappungsgröße zwischen Chunks. Wir können diese verwenden, um unsere Antworten und deren Aussehen zu optimieren. Neben der Optimierung müssen wir auch die Antworten bewerten.
In zukünftigen Tutorials werden wir uns verschiedene Chunking-Strategien ansehen. Nicht nur das, sondern wir werden uns auch eingehender mit Embeddings, Aufteilungsstrategien und Evaluierung befassen.

Weiterlesen

Zilliz Cloud Now Available in AWS Asia Pacific (Seoul)
Zilliz Cloud is now available in AWS Seoul — low-latency vector search, in-country data residency, and one-step migration for Korean AI teams. 31 regions across 5 clouds.

Data Deduplication at Trillion Scale: How to Solve the Biggest Bottleneck of LLM Training
Explore how MinHash LSH and Milvus handle data deduplication at the trillion-scale level, solving key bottlenecks in LLM training for improved AI model performance.
Milvus/Zilliz + Surveillance: How Vector Databases Transform Multi-Camera Tracking
See how Milvus vector database enhances multi-camera tracking with similarity-based matching for better surveillance in retail, warehouses and transport hubs.